
Update README.md
Browse files
README.md
CHANGED
|
@@ -9,7 +9,7 @@ widget:
|
|
| 9 |
example_title: Children
|
| 10 |
---
|
| 11 |
|
| 12 |
-
# Yolos-small-
|
| 13 |
|
| 14 |
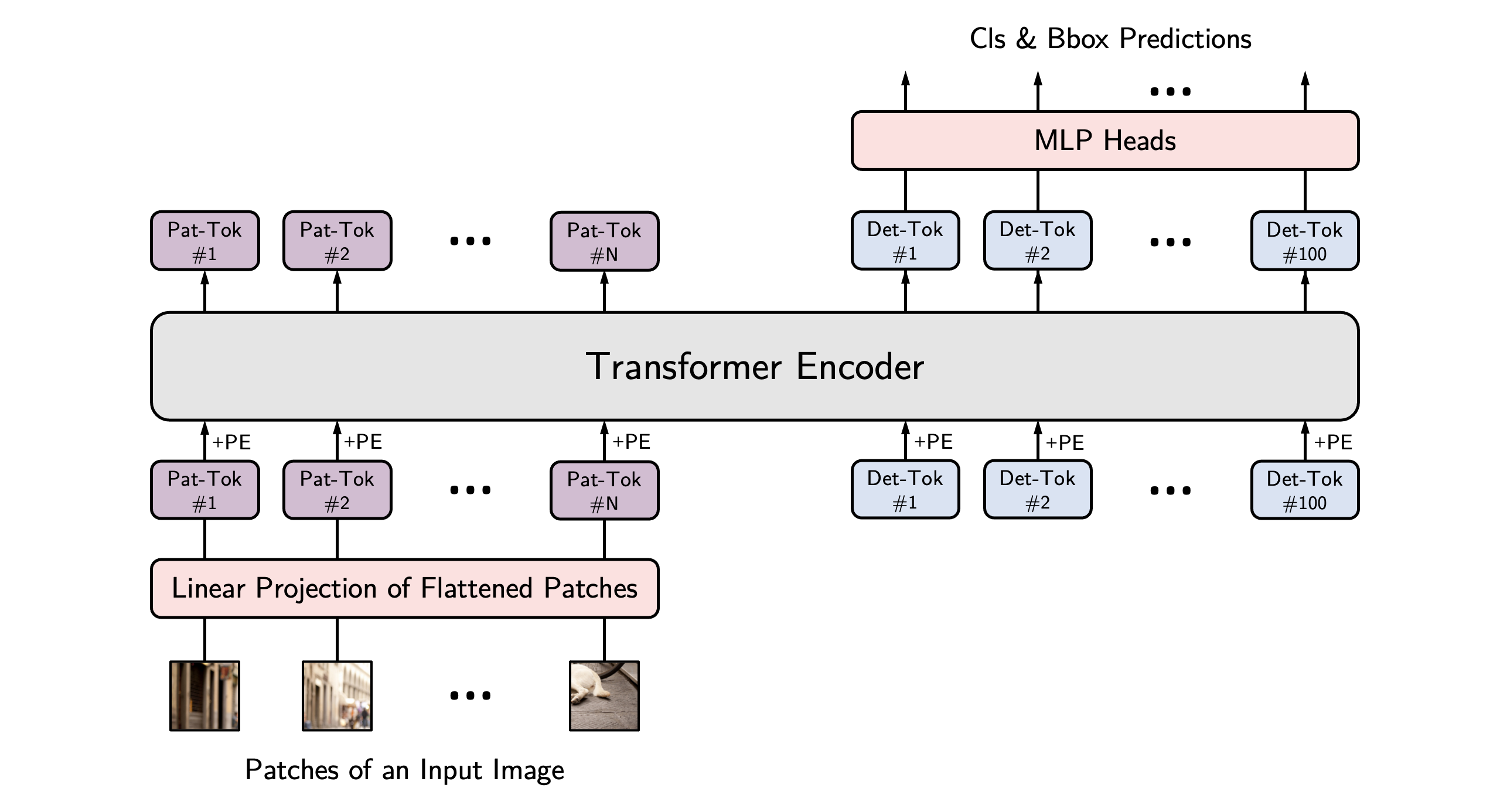
YOLOS model fine-tuned on COCO 2017 object detection (118k annotated images). It was introduced in the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Fang et al. and first released in [this repository](https://github.com/hustvl/YOLOS).
|
| 15 |
|
|
@@ -44,8 +44,8 @@ import requests
|
|
| 44 |
|
| 45 |
url = "https://latestbollyholly.com/wp-content/uploads/2024/02/Jacob-Gooch.jpg"
|
| 46 |
image = Image.open(requests.get(url, stream=True).raw)
|
| 47 |
-
image_processor = AutoImageProcessor.from_pretrained("AdamCodd/yolos-small-
|
| 48 |
-
model = AutoModelForObjectDetection.from_pretrained("AdamCodd/yolos-small-
|
| 49 |
inputs = image_processor(images=image, return_tensors="pt")
|
| 50 |
outputs = model(**inputs)
|
| 51 |
|
|
|
|
| 9 |
example_title: Children
|
| 10 |
---
|
| 11 |
|
| 12 |
+
# Yolos-small-person
|
| 13 |
|
| 14 |
YOLOS model fine-tuned on COCO 2017 object detection (118k annotated images). It was introduced in the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Fang et al. and first released in [this repository](https://github.com/hustvl/YOLOS).
|
| 15 |

|
|
|
|
| 44 |
|
| 45 |
url = "https://latestbollyholly.com/wp-content/uploads/2024/02/Jacob-Gooch.jpg"
|
| 46 |
image = Image.open(requests.get(url, stream=True).raw)
|
| 47 |
+
image_processor = AutoImageProcessor.from_pretrained("AdamCodd/yolos-small-person")
|
| 48 |
+
model = AutoModelForObjectDetection.from_pretrained("AdamCodd/yolos-small-person")
|
| 49 |
inputs = image_processor(images=image, return_tensors="pt")
|
| 50 |
outputs = model(**inputs)
|
| 51 |
|