
Uploading the Model
Browse files- .gitattributes +1 -0
- .gitignore +169 -0
- .timetracker +1 -0
- assets/benchmark.png +0 -0
- assets/channel_mixing.gif +0 -0
- assets/current_loss.png +0 -0
- assets/gpt2_124M_loss.png +0 -0
- assets/inference-time.png +0 -0
- assets/nanoRWKV-loss.png +0 -0
- assets/nanoRWKV.png +0 -0
- assets/nanorwkv.jpg +0 -0
- assets/time_mixing.gif +3 -0
- bench.py +117 -0
- benchmark_inference_time.py +130 -0
- config/eval_gpt2.py +8 -0
- config/eval_rwkv4_169m.py +7 -0
- config/eval_rwkv4_430m.py +6 -0
- config/finetune_shakespeare.py +25 -0
- config/train_gpt2.py +26 -0
- config/train_rwkv.py +35 -0
- config/train_shakespeare_char.py +37 -0
- configurator.py +47 -0
- data/openwebtext/prepare.py +80 -0
- data/openwebtext/readme.md +15 -0
- data/shakespeare/prepare.py +33 -0
- data/shakespeare/readme.md +9 -0
- data/shakespeare_char/prepare.py +68 -0
- data/shakespeare_char/readme.md +9 -0
- generate.py +84 -0
- modelGenerate.py +442 -0
- modeling_rwkv.py +687 -0
- out/.keep +0 -0
- sample.py +101 -0
- scaling_laws.ipynb +0 -0
- train.py +363 -0
- transformer_sizing.ipynb +402 -0
.gitattributes
CHANGED
|
@@ -34,3 +34,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
*.ipynb linguist-generated
|
|
|
|
|
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
*.ipynb linguist-generated
|
| 37 |
+
assets/time_mixing.gif filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,169 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
|
| 6 |
+
# C extensions
|
| 7 |
+
*.so
|
| 8 |
+
|
| 9 |
+
# Distribution / packaging
|
| 10 |
+
.Python
|
| 11 |
+
build/
|
| 12 |
+
develop-eggs/
|
| 13 |
+
dist/
|
| 14 |
+
downloads/
|
| 15 |
+
eggs/
|
| 16 |
+
.eggs/
|
| 17 |
+
lib/
|
| 18 |
+
lib64/
|
| 19 |
+
parts/
|
| 20 |
+
sdist/
|
| 21 |
+
var/
|
| 22 |
+
wheels/
|
| 23 |
+
share/python-wheels/
|
| 24 |
+
*.egg-info/
|
| 25 |
+
.installed.cfg
|
| 26 |
+
*.egg
|
| 27 |
+
MANIFEST
|
| 28 |
+
|
| 29 |
+
# PyInstaller
|
| 30 |
+
# Usually these files are written by a python script from a template
|
| 31 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 32 |
+
*.manifest
|
| 33 |
+
*.spec
|
| 34 |
+
|
| 35 |
+
# Installer logs
|
| 36 |
+
pip-log.txt
|
| 37 |
+
pip-delete-this-directory.txt
|
| 38 |
+
|
| 39 |
+
# Unit test / coverage reports
|
| 40 |
+
htmlcov/
|
| 41 |
+
.tox/
|
| 42 |
+
.nox/
|
| 43 |
+
.coverage
|
| 44 |
+
.coverage.*
|
| 45 |
+
.cache
|
| 46 |
+
nosetests.xml
|
| 47 |
+
coverage.xml
|
| 48 |
+
*.cover
|
| 49 |
+
*.py,cover
|
| 50 |
+
.hypothesis/
|
| 51 |
+
.pytest_cache/
|
| 52 |
+
cover/
|
| 53 |
+
|
| 54 |
+
# Translations
|
| 55 |
+
*.mo
|
| 56 |
+
*.pot
|
| 57 |
+
|
| 58 |
+
# Django stuff:
|
| 59 |
+
*.log
|
| 60 |
+
local_settings.py
|
| 61 |
+
db.sqlite3
|
| 62 |
+
db.sqlite3-journal
|
| 63 |
+
|
| 64 |
+
# Flask stuff:
|
| 65 |
+
instance/
|
| 66 |
+
.webassets-cache
|
| 67 |
+
|
| 68 |
+
# Scrapy stuff:
|
| 69 |
+
.scrapy
|
| 70 |
+
|
| 71 |
+
# Sphinx documentation
|
| 72 |
+
docs/_build/
|
| 73 |
+
|
| 74 |
+
# PyBuilder
|
| 75 |
+
.pybuilder/
|
| 76 |
+
target/
|
| 77 |
+
|
| 78 |
+
# Jupyter Notebook
|
| 79 |
+
.ipynb_checkpoints
|
| 80 |
+
|
| 81 |
+
# IPython
|
| 82 |
+
profile_default/
|
| 83 |
+
ipython_config.py
|
| 84 |
+
|
| 85 |
+
# pyenv
|
| 86 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 87 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 88 |
+
# .python-version
|
| 89 |
+
|
| 90 |
+
# pipenv
|
| 91 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 92 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 93 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 94 |
+
# install all needed dependencies.
|
| 95 |
+
#Pipfile.lock
|
| 96 |
+
|
| 97 |
+
# poetry
|
| 98 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 99 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 100 |
+
# commonly ignored for libraries.
|
| 101 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 102 |
+
#poetry.lock
|
| 103 |
+
|
| 104 |
+
# pdm
|
| 105 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 106 |
+
#pdm.lock
|
| 107 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 108 |
+
# in version control.
|
| 109 |
+
# https://pdm.fming.dev/#use-with-ide
|
| 110 |
+
.pdm.toml
|
| 111 |
+
|
| 112 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 113 |
+
__pypackages__/
|
| 114 |
+
|
| 115 |
+
# Celery stuff
|
| 116 |
+
celerybeat-schedule
|
| 117 |
+
celerybeat.pid
|
| 118 |
+
|
| 119 |
+
# SageMath parsed files
|
| 120 |
+
*.sage.py
|
| 121 |
+
|
| 122 |
+
# Environments
|
| 123 |
+
.env
|
| 124 |
+
.venv
|
| 125 |
+
env/
|
| 126 |
+
venv/
|
| 127 |
+
ENV/
|
| 128 |
+
env.bak/
|
| 129 |
+
venv.bak/
|
| 130 |
+
|
| 131 |
+
# Spyder project settings
|
| 132 |
+
.spyderproject
|
| 133 |
+
.spyproject
|
| 134 |
+
|
| 135 |
+
# Rope project settings
|
| 136 |
+
.ropeproject
|
| 137 |
+
|
| 138 |
+
# mkdocs documentation
|
| 139 |
+
/site
|
| 140 |
+
|
| 141 |
+
# mypy
|
| 142 |
+
.mypy_cache/
|
| 143 |
+
.dmypy.json
|
| 144 |
+
dmypy.json
|
| 145 |
+
|
| 146 |
+
# Pyre type checker
|
| 147 |
+
.pyre/
|
| 148 |
+
|
| 149 |
+
# pytype static type analyzer
|
| 150 |
+
.pytype/
|
| 151 |
+
|
| 152 |
+
# Cython debug symbols
|
| 153 |
+
cython_debug/
|
| 154 |
+
|
| 155 |
+
# PyCharm
|
| 156 |
+
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
| 157 |
+
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
| 158 |
+
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
| 159 |
+
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
| 160 |
+
#.idea/
|
| 161 |
+
|
| 162 |
+
/data/summary/*
|
| 163 |
+
/data/tinystories-15k/*
|
| 164 |
+
/out/*.pt
|
| 165 |
+
/venv/
|
| 166 |
+
/keysModel.py
|
| 167 |
+
/model.py
|
| 168 |
+
/*.txt
|
| 169 |
+
/trainKaggle.py
|
.timetracker
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"total":626936,"sessions":[{"begin":"2024-03-19T15:28:08+07:00","end":"2024-03-19T16:59:43+07:00","duration":5494},{"begin":"2024-03-24T22:41:12+07:00","end":"2024-03-24T23:05:12+07:00","duration":1439},{"begin":"2024-03-26T08:49:00+07:00","end":"2024-03-26T10:38:06+07:00","duration":6546},{"begin":"2024-03-26T23:06:50+07:00","end":"2024-03-26T23:35:02+07:00","duration":1691},{"begin":"2024-03-26T23:51:53+07:00","end":"2024-03-27T00:28:51+07:00","duration":2218},{"begin":"2024-03-27T00:32:45+07:00","end":"2024-03-27T12:27:12+07:00","duration":42866},{"begin":"2024-03-28T10:46:58+07:00","end":"2024-03-28T13:00:02+07:00","duration":7983},{"begin":"2024-03-28T16:28:10+07:00","end":"2024-03-29T08:42:21+07:00","duration":58451},{"begin":"2024-03-29T20:37:47+07:00","end":"2024-03-30T14:44:24+07:00","duration":65196},{"begin":"2024-03-30T14:44:24+07:00","end":"2024-03-31T16:45:41+07:00","duration":93676},{"begin":"2024-03-31T17:03:36+07:00","end":"2024-03-31T17:04:06+07:00","duration":30},{"begin":"2024-03-31T17:04:13+07:00","end":"2024-04-01T15:02:44+07:00","duration":79111},{"begin":"2024-04-02T12:23:23+07:00","end":"2024-04-05T13:13:59+07:00","duration":262235}]}
|
assets/benchmark.png
ADDED

|
assets/channel_mixing.gif
ADDED

|
assets/current_loss.png
ADDED
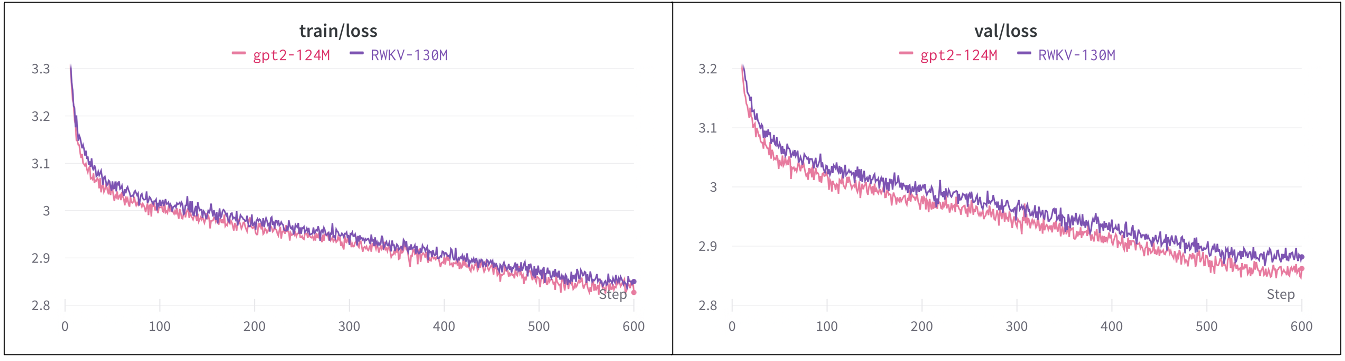
|
assets/gpt2_124M_loss.png
ADDED

|
assets/inference-time.png
ADDED
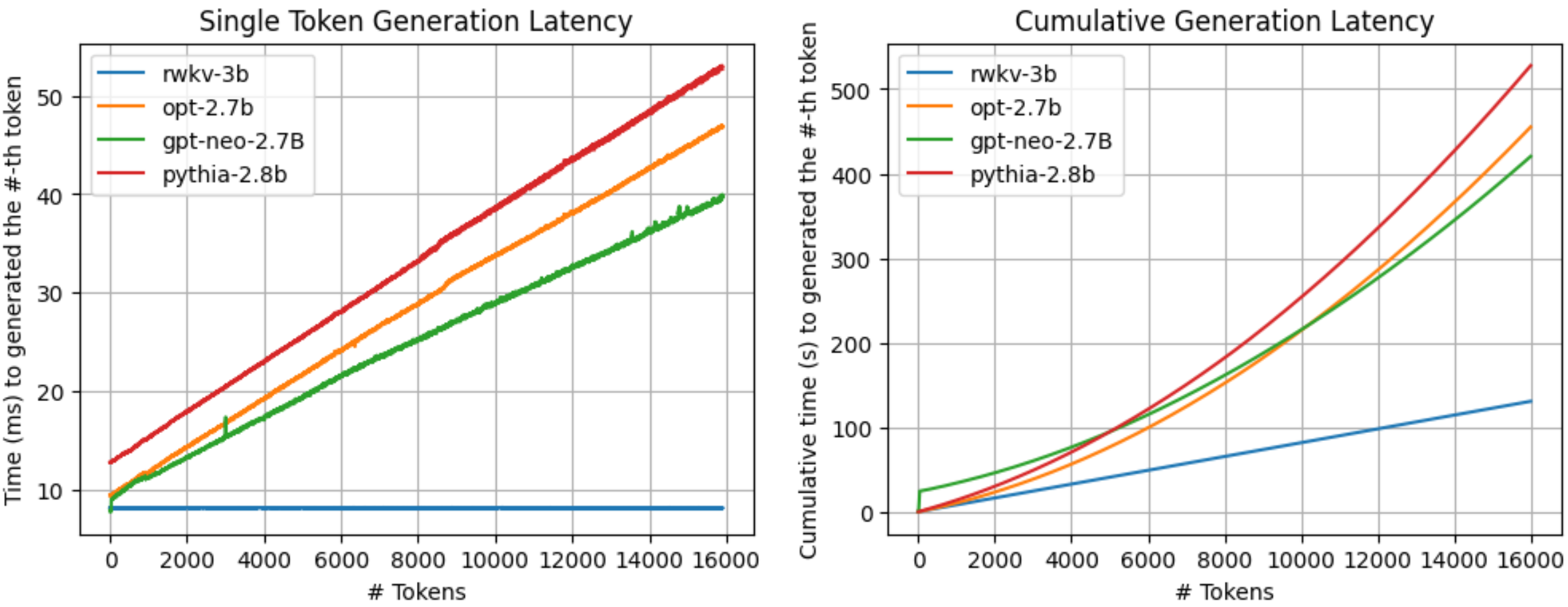
|
assets/nanoRWKV-loss.png
ADDED
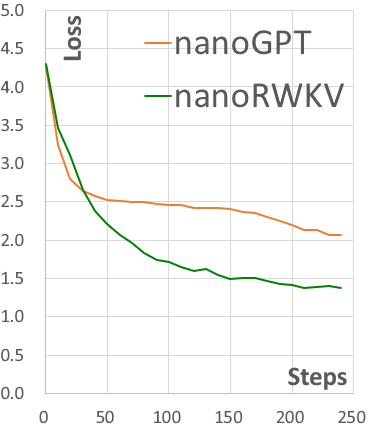
|
assets/nanoRWKV.png
ADDED

|
assets/nanorwkv.jpg
ADDED

|
assets/time_mixing.gif
ADDED

|
Git LFS Details
|
bench.py
ADDED
|
@@ -0,0 +1,117 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
A much shorter version of train.py for benchmarking
|
| 3 |
+
"""
|
| 4 |
+
import os
|
| 5 |
+
from contextlib import nullcontext
|
| 6 |
+
import numpy as np
|
| 7 |
+
import time
|
| 8 |
+
import torch
|
| 9 |
+
from modeling_gpt import GPTConfig, GPT
|
| 10 |
+
|
| 11 |
+
# -----------------------------------------------------------------------------
|
| 12 |
+
batch_size = 12
|
| 13 |
+
block_size = 1024
|
| 14 |
+
bias = False
|
| 15 |
+
real_data = True
|
| 16 |
+
seed = 1337
|
| 17 |
+
device = 'cuda' # examples: 'cpu', 'cuda', 'cuda:0', 'cuda:1', etc.
|
| 18 |
+
dtype = 'bfloat16' if torch.cuda.is_bf16_supported() else 'float16' # 'float32' or 'bfloat16' or 'float16'
|
| 19 |
+
compile = True # use PyTorch 2.0 to compile the model to be faster
|
| 20 |
+
profile = False # use pytorch profiler, or just simple benchmarking?
|
| 21 |
+
exec(open('configurator.py').read()) # overrides from command line or config file
|
| 22 |
+
# -----------------------------------------------------------------------------
|
| 23 |
+
|
| 24 |
+
torch.manual_seed(seed)
|
| 25 |
+
torch.cuda.manual_seed(seed)
|
| 26 |
+
torch.backends.cuda.matmul.allow_tf32 = True # allow tf32 on matmul
|
| 27 |
+
torch.backends.cudnn.allow_tf32 = True # allow tf32 on cudnn
|
| 28 |
+
device_type = 'cuda' if 'cuda' in device else 'cpu' # for later use in torch.autocast
|
| 29 |
+
ptdtype = {'float32': torch.float32, 'bfloat16': torch.bfloat16, 'float16': torch.float16}[dtype]
|
| 30 |
+
ctx = nullcontext() if device_type == 'cpu' else torch.amp.autocast(device_type=device_type, dtype=ptdtype)
|
| 31 |
+
|
| 32 |
+
# data loading init
|
| 33 |
+
if real_data:
|
| 34 |
+
dataset = 'openwebtext'
|
| 35 |
+
data_dir = os.path.join('data', dataset)
|
| 36 |
+
train_data = np.memmap(os.path.join(data_dir, 'train.bin'), dtype=np.uint16, mode='r')
|
| 37 |
+
def get_batch(split):
|
| 38 |
+
data = train_data # note ignore split in benchmarking script
|
| 39 |
+
ix = torch.randint(len(data) - block_size, (batch_size,))
|
| 40 |
+
x = torch.stack([torch.from_numpy((data[i:i+block_size]).astype(np.int64)) for i in ix])
|
| 41 |
+
y = torch.stack([torch.from_numpy((data[i+1:i+1+block_size]).astype(np.int64)) for i in ix])
|
| 42 |
+
x, y = x.pin_memory().to(device, non_blocking=True), y.pin_memory().to(device, non_blocking=True)
|
| 43 |
+
return x, y
|
| 44 |
+
else:
|
| 45 |
+
# alternatively, if fixed data is desired to not care about data loading
|
| 46 |
+
x = torch.randint(50304, (batch_size, block_size), device=device)
|
| 47 |
+
y = torch.randint(50304, (batch_size, block_size), device=device)
|
| 48 |
+
get_batch = lambda split: (x, y)
|
| 49 |
+
|
| 50 |
+
# model init
|
| 51 |
+
gptconf = GPTConfig(
|
| 52 |
+
block_size = block_size, # how far back does the model look? i.e. context size
|
| 53 |
+
n_layer = 12, n_head = 12, n_embd = 768, # size of the model
|
| 54 |
+
dropout = 0, # for determinism
|
| 55 |
+
bias = bias,
|
| 56 |
+
)
|
| 57 |
+
model = GPT(gptconf)
|
| 58 |
+
model.to(device)
|
| 59 |
+
|
| 60 |
+
optimizer = model.configure_optimizers(weight_decay=1e-2, learning_rate=1e-4, betas=(0.9, 0.95), device_type=device_type)
|
| 61 |
+
|
| 62 |
+
if compile:
|
| 63 |
+
print("Compiling model...")
|
| 64 |
+
model = torch.compile(model) # pytorch 2.0
|
| 65 |
+
|
| 66 |
+
if profile:
|
| 67 |
+
# useful docs on pytorch profiler:
|
| 68 |
+
# - tutorial https://pytorch.org/tutorials/intermediate/tensorboard_profiler_tutorial.html
|
| 69 |
+
# - api https://pytorch.org/docs/stable/profiler.html#torch.profiler.profile
|
| 70 |
+
wait, warmup, active = 5, 5, 5
|
| 71 |
+
num_steps = wait + warmup + active
|
| 72 |
+
with torch.profiler.profile(
|
| 73 |
+
activities=[torch.profiler.ProfilerActivity.CPU, torch.profiler.ProfilerActivity.CUDA],
|
| 74 |
+
schedule=torch.profiler.schedule(wait=wait, warmup=warmup, active=active, repeat=1),
|
| 75 |
+
on_trace_ready=torch.profiler.tensorboard_trace_handler('./bench_log'),
|
| 76 |
+
record_shapes=False,
|
| 77 |
+
profile_memory=False,
|
| 78 |
+
with_stack=False, # incurs an additional overhead, disable if not needed
|
| 79 |
+
with_flops=True,
|
| 80 |
+
with_modules=False, # only for torchscript models atm
|
| 81 |
+
) as prof:
|
| 82 |
+
|
| 83 |
+
X, Y = get_batch('train')
|
| 84 |
+
for k in range(num_steps):
|
| 85 |
+
with ctx:
|
| 86 |
+
logits, loss = model(X, Y)
|
| 87 |
+
X, Y = get_batch('train')
|
| 88 |
+
optimizer.zero_grad(set_to_none=True)
|
| 89 |
+
loss.backward()
|
| 90 |
+
optimizer.step()
|
| 91 |
+
lossf = loss.item()
|
| 92 |
+
print(f"{k}/{num_steps} loss: {lossf:.4f}")
|
| 93 |
+
|
| 94 |
+
prof.step() # notify the profiler at end of each step
|
| 95 |
+
|
| 96 |
+
else:
|
| 97 |
+
|
| 98 |
+
# simple benchmarking
|
| 99 |
+
torch.cuda.synchronize()
|
| 100 |
+
for stage, num_steps in enumerate([10, 20]): # burnin, then benchmark
|
| 101 |
+
t0 = time.time()
|
| 102 |
+
X, Y = get_batch('train')
|
| 103 |
+
for k in range(num_steps):
|
| 104 |
+
with ctx:
|
| 105 |
+
logits, loss = model(X, Y)
|
| 106 |
+
X, Y = get_batch('train')
|
| 107 |
+
optimizer.zero_grad(set_to_none=True)
|
| 108 |
+
loss.backward()
|
| 109 |
+
optimizer.step()
|
| 110 |
+
lossf = loss.item()
|
| 111 |
+
print(f"{k}/{num_steps} loss: {lossf:.4f}")
|
| 112 |
+
torch.cuda.synchronize()
|
| 113 |
+
t1 = time.time()
|
| 114 |
+
dt = t1-t0
|
| 115 |
+
mfu = model.estimate_mfu(batch_size * 1 * num_steps, dt)
|
| 116 |
+
if stage == 1:
|
| 117 |
+
print(f"time per iteration: {dt/num_steps*1000:.4f}ms, MFU: {mfu*100:.2f}%")
|
benchmark_inference_time.py
ADDED
|
@@ -0,0 +1,130 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
os.environ["TOKENIZERS_PARALLELISM"] = "false"
|
| 3 |
+
from torch.profiler import ProfilerActivity, profile, record_function
|
| 4 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer, AutoConfig
|
| 5 |
+
from torch import nn
|
| 6 |
+
import torch
|
| 7 |
+
torch.set_float32_matmul_precision('high')
|
| 8 |
+
import json
|
| 9 |
+
from argparse import ArgumentParser
|
| 10 |
+
|
| 11 |
+
def sample(outputs):
|
| 12 |
+
next_token_logits = outputs.logits[:, -1, :]
|
| 13 |
+
probs = nn.functional.softmax(next_token_logits, dim=-1)
|
| 14 |
+
next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
|
| 15 |
+
return next_tokens
|
| 16 |
+
|
| 17 |
+
if __name__ == "__main__":
|
| 18 |
+
parser = ArgumentParser()
|
| 19 |
+
parser.add_argument("--device",default='cuda')
|
| 20 |
+
parser.add_argument("--model",required=True)
|
| 21 |
+
parser.add_argument("--use_cache",action='store_true')
|
| 22 |
+
parser.add_argument("--max_new_tokens",type=int,default=16_000)
|
| 23 |
+
parser.add_argument("--output_path")
|
| 24 |
+
args = parser.parse_args()
|
| 25 |
+
|
| 26 |
+
prompt = 'hello' ## dummpy input
|
| 27 |
+
|
| 28 |
+
config = AutoConfig.from_pretrained(args.model)
|
| 29 |
+
config.max_position_embeddings = args.max_new_tokens+10
|
| 30 |
+
model = AutoModelForCausalLM.from_config(config)
|
| 31 |
+
model.eval()
|
| 32 |
+
model = model.to(args.device)
|
| 33 |
+
model = torch.compile(model)
|
| 34 |
+
model_size = sum(p.numel() for p in model.parameters())
|
| 35 |
+
tokenizer = AutoTokenizer.from_pretrained(args.model)
|
| 36 |
+
tokenized_prompt = tokenizer(prompt, return_tensors="pt")
|
| 37 |
+
tokenized_prompt = tokenized_prompt['input_ids'].to(args.device)
|
| 38 |
+
|
| 39 |
+
model_input = {
|
| 40 |
+
"input_ids":tokenized_prompt,
|
| 41 |
+
"use_cache":args.use_cache,
|
| 42 |
+
}
|
| 43 |
+
|
| 44 |
+
cache_name = "state" if args.model.startswith("RWKV") else "past_key_values"
|
| 45 |
+
model_input[cache_name]=None
|
| 46 |
+
|
| 47 |
+
os.makedirs(os.path.dirname(args.output_path),exist_ok=True)
|
| 48 |
+
writer = open(args.output_path,'w')
|
| 49 |
+
for tok_idx in range(args.max_new_tokens):
|
| 50 |
+
with torch.no_grad():
|
| 51 |
+
if args.use_cache and model_input[cache_name] is not None:model_input["input_ids"] = tokenized_prompt[:,-1:].to(args.device)
|
| 52 |
+
else:model_input["input_ids"] = tokenized_prompt.to(args.device)
|
| 53 |
+
with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA], profile_memory=True, record_shapes=False) as prof:
|
| 54 |
+
with record_function("model_inference"):
|
| 55 |
+
output = model.forward(**model_input)
|
| 56 |
+
|
| 57 |
+
model_input[cache_name]=getattr(output,cache_name)
|
| 58 |
+
next_tokens = sample(output)
|
| 59 |
+
tokenized_prompt = torch.cat([tokenized_prompt.cpu(), next_tokens[:, None].cpu()], dim=-1)
|
| 60 |
+
|
| 61 |
+
full_profile = next(event for event in prof.key_averages() if event.key == 'model_inference')
|
| 62 |
+
writer.write(json.dumps({
|
| 63 |
+
"model_name": args.model,
|
| 64 |
+
"model_size": model_size,
|
| 65 |
+
"token_id": tok_idx,
|
| 66 |
+
"strategy": args.device,
|
| 67 |
+
"cpu_time": full_profile.cpu_time,
|
| 68 |
+
"cuda_time": full_profile.cuda_time,
|
| 69 |
+
"cpu_memory_usage": full_profile.cpu_memory_usage,
|
| 70 |
+
"cuda_memory_usage": full_profile.cuda_memory_usage,
|
| 71 |
+
"self_cpu_memory_usage": full_profile.self_cpu_memory_usage,
|
| 72 |
+
"self_cuda_memory_usage": full_profile.self_cuda_memory_usage,
|
| 73 |
+
"max_memory_allocated":torch.cuda.max_memory_allocated(),
|
| 74 |
+
})+'\n'
|
| 75 |
+
)
|
| 76 |
+
torch.cuda.empty_cache()
|
| 77 |
+
|
| 78 |
+
writer.close()
|
| 79 |
+
|
| 80 |
+
"""
|
| 81 |
+
python benchmark_inference_time.py --model RWKV/rwkv-4-3b-pile --use_cache --output_path data/inference_time/rwkv-3b.jsonl
|
| 82 |
+
python benchmark_inference_time.py --model RWKV/rwkv-4-7b-pile --use_cache --output_path data/inference_time/rwkv-7b.jsonl
|
| 83 |
+
python benchmark_inference_time.py --model RWKV/rwkv-4-14b-pile --use_cache --output_path data/inference_time/rwkv-14b.jsonl
|
| 84 |
+
python benchmark_inference_time.py --model facebook/opt-2.7b --use_cache --output_path data/inference_time/opt-2.7b.jsonl
|
| 85 |
+
python benchmark_inference_time.py --model facebook/opt-6.7b --use_cache --output_path data/inference_time/opt-6.7b.jsonl
|
| 86 |
+
python benchmark_inference_time.py --model EleutherAI/pythia-2.8b --use_cache --output_path data/inference_time/pythia-2.8b.jsonl
|
| 87 |
+
python benchmark_inference_time.py --model EleutherAI/pythia-6.9b --use_cache --output_path data/inference_time/pythia-6.9b.jsonl
|
| 88 |
+
python benchmark_inference_time.py --model EleutherAI/gpt-neo-2.7B --use_cache --output_path data/inference_time/gpt-neo-2.7B.jsonl
|
| 89 |
+
|
| 90 |
+
############# Poltting Code ##############
|
| 91 |
+
import numpy as np
|
| 92 |
+
import json
|
| 93 |
+
def get_jsonl(f): return [json.loads(x) for x in open(f).readlines()]
|
| 94 |
+
import matplotlib.pyplot as plt
|
| 95 |
+
fig, (ax1,ax2,ax3) = plt.subplots(1, 3,figsize=(18, 4))
|
| 96 |
+
|
| 97 |
+
for model_name in [
|
| 98 |
+
"rwkv-3b",
|
| 99 |
+
# "rwkv-7b",
|
| 100 |
+
# "rwkv-14b",
|
| 101 |
+
"opt-2.7b",
|
| 102 |
+
"gpt-neo-2.7B",
|
| 103 |
+
"pythia-2.8b"
|
| 104 |
+
]:
|
| 105 |
+
data = get_jsonl(f"data/inference_time/{model_name}.jsonl")
|
| 106 |
+
cuda_time = [x['cuda_time'] for x in data]
|
| 107 |
+
cumulative_time = np.cumsum(cuda_time)/(1000*1000)
|
| 108 |
+
memory_usage = [x['max_memory_allocated']/(2**10)/(2**10)/(2**10) for x in data]
|
| 109 |
+
ax1.plot([x/1000 for x in cuda_time][100:],label=model_name)
|
| 110 |
+
ax2.plot(cumulative_time,label=model_name)
|
| 111 |
+
ax3.plot(memory_usage,label=model_name)
|
| 112 |
+
|
| 113 |
+
ax1.set_xlabel("# Tokens")
|
| 114 |
+
ax1.set_ylabel("Time (ms) to generated the #-th token")
|
| 115 |
+
ax1.grid()
|
| 116 |
+
ax1.legend()
|
| 117 |
+
ax1.set_title("Single Token Generation Latency")
|
| 118 |
+
|
| 119 |
+
ax2.set_xlabel("# Tokens")
|
| 120 |
+
ax2.set_ylabel("Cumulative time (s) to generated the #-th token")
|
| 121 |
+
ax2.grid()
|
| 122 |
+
ax2.legend()
|
| 123 |
+
ax2.set_title("Cumulative Generation Latency")
|
| 124 |
+
|
| 125 |
+
ax3.set_xlabel("# Tokens")
|
| 126 |
+
ax3.set_ylabel("Memory usage (GB)")
|
| 127 |
+
ax3.grid()
|
| 128 |
+
ax3.legend()
|
| 129 |
+
ax3.set_title("Memory usage in Generation")
|
| 130 |
+
"""
|
config/eval_gpt2.py
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# evaluate the base gpt2
|
| 2 |
+
# n_layer=12, n_head=12, n_embd=768
|
| 3 |
+
# 124M parameters
|
| 4 |
+
batch_size = 8
|
| 5 |
+
eval_iters = 500 # use more iterations to get good estimate
|
| 6 |
+
eval_only = True
|
| 7 |
+
wandb_log = False
|
| 8 |
+
init_from = 'gpt2'
|
config/eval_rwkv4_169m.py
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# evaluate the RWKV-4-169M
|
| 2 |
+
batch_size = 8
|
| 3 |
+
eval_iters = 500 # use more iterations to get good estimate
|
| 4 |
+
eval_only = True
|
| 5 |
+
wandb_log = False
|
| 6 |
+
dtype = 'float16' # v100 doesn't support bf16
|
| 7 |
+
init_from = 'RWKV/rwkv-4-169m-pile'
|
config/eval_rwkv4_430m.py
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
batch_size = 8
|
| 2 |
+
eval_iters = 500 # use more iterations to get good estimate
|
| 3 |
+
eval_only = True
|
| 4 |
+
wandb_log = False
|
| 5 |
+
init_from = 'RWKV/rwkv-4-430m-pile'
|
| 6 |
+
dtype = 'float16' # v100 doesn't support bf16
|
config/finetune_shakespeare.py
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import time
|
| 2 |
+
|
| 3 |
+
out_dir = 'out-shakespeare'
|
| 4 |
+
eval_interval = 5
|
| 5 |
+
eval_iters = 40
|
| 6 |
+
wandb_log = False # feel free to turn on
|
| 7 |
+
wandb_project = 'shakespeare'
|
| 8 |
+
wandb_run_name = 'ft-' + str(time.time())
|
| 9 |
+
|
| 10 |
+
dataset = 'shakespeare'
|
| 11 |
+
init_from = 'gpt2-xl' # this is the largest GPT-2 model
|
| 12 |
+
|
| 13 |
+
# only save checkpoints if the validation loss improves
|
| 14 |
+
always_save_checkpoint = False
|
| 15 |
+
|
| 16 |
+
# the number of examples per iter:
|
| 17 |
+
# 1 batch_size * 32 grad_accum * 1024 tokens = 32,768 tokens/iter
|
| 18 |
+
# shakespeare has 301,966 tokens, so 1 epoch ~= 9.2 iters
|
| 19 |
+
batch_size = 1
|
| 20 |
+
gradient_accumulation_steps = 32
|
| 21 |
+
max_iters = 20
|
| 22 |
+
|
| 23 |
+
# finetune at constant LR
|
| 24 |
+
learning_rate = 3e-5
|
| 25 |
+
decay_lr = False
|
config/train_gpt2.py
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# config for training GPT-2 (124M) down to very nice loss of ~2.85 on 1 node of 8X A100 40GB
|
| 2 |
+
# launch as the following (e.g. in a screen session) and wait ~5 days:
|
| 3 |
+
# $ torchrun --standalone --nproc_per_node=8 train.py config/train_gpt2.py
|
| 4 |
+
|
| 5 |
+
wandb_log = True
|
| 6 |
+
wandb_project = 'nanoRWKV'
|
| 7 |
+
wandb_run_name='gpt2-124M'
|
| 8 |
+
|
| 9 |
+
# these make the total batch size be ~0.5M
|
| 10 |
+
# 12 batch size * 1024 block size * 5 gradaccum * 8 GPUs = 491,520
|
| 11 |
+
batch_size = 12
|
| 12 |
+
block_size = 1024
|
| 13 |
+
gradient_accumulation_steps = 5 * 8
|
| 14 |
+
|
| 15 |
+
# this makes total number of tokens be 300B
|
| 16 |
+
max_iters = 600000
|
| 17 |
+
lr_decay_iters = 600000
|
| 18 |
+
dtype = 'float16'
|
| 19 |
+
|
| 20 |
+
# eval stuff
|
| 21 |
+
eval_interval = 1000
|
| 22 |
+
eval_iters = 200
|
| 23 |
+
log_interval = 10
|
| 24 |
+
|
| 25 |
+
# weight decay
|
| 26 |
+
weight_decay = 1e-1
|
config/train_rwkv.py
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# config for training GPT-2 (124M) down to very nice loss of ~2.85 on 1 node of 8X A100 40GB
|
| 2 |
+
# launch as the following (e.g. in a screen session) and wait ~5 days:
|
| 3 |
+
# $ torchrun --standalone --nproc_per_node=8 train.py config/train_gpt2.py
|
| 4 |
+
|
| 5 |
+
wandb_log = True
|
| 6 |
+
wandb_project = 'nanoRWKV'
|
| 7 |
+
wandb_run_name='RWKV-130M'
|
| 8 |
+
|
| 9 |
+
# these make the total batch size be ~0.5M
|
| 10 |
+
# 12 batch size * 1024 block size * 5 gradaccum * 8 GPUs = 491,520
|
| 11 |
+
batch_size = 12
|
| 12 |
+
block_size = 1024
|
| 13 |
+
gradient_accumulation_steps = 5 * 8
|
| 14 |
+
|
| 15 |
+
# rwkv specific parameters
|
| 16 |
+
dtype = 'float16' # v100 doesn't support bf16
|
| 17 |
+
model_type = 'rwkv'
|
| 18 |
+
# beta1 = 0.9
|
| 19 |
+
# beta2 = 0.99
|
| 20 |
+
# learning_rate = 8e-4
|
| 21 |
+
# min_lr = 1e-5
|
| 22 |
+
# warmup_iters = 0
|
| 23 |
+
|
| 24 |
+
weight_decay = 1e-1
|
| 25 |
+
use_customized_cuda_kernel = True
|
| 26 |
+
|
| 27 |
+
# this makes total number of tokens be 300B
|
| 28 |
+
max_iters = 600000
|
| 29 |
+
lr_decay_iters = 600000
|
| 30 |
+
|
| 31 |
+
# eval stuff
|
| 32 |
+
eval_interval = 1000
|
| 33 |
+
eval_iters = 200
|
| 34 |
+
log_interval = 10
|
| 35 |
+
|
config/train_shakespeare_char.py
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# train a miniature character-level shakespeare model
|
| 2 |
+
# good for debugging and playing on macbooks and such
|
| 3 |
+
|
| 4 |
+
out_dir = 'out-shakespeare-char'
|
| 5 |
+
eval_interval = 250 # keep frequent because we'll overfit
|
| 6 |
+
eval_iters = 200
|
| 7 |
+
log_interval = 10 # don't print too too often
|
| 8 |
+
|
| 9 |
+
# we expect to overfit on this small dataset, so only save when val improves
|
| 10 |
+
always_save_checkpoint = False
|
| 11 |
+
|
| 12 |
+
wandb_log = False # override via command line if you like
|
| 13 |
+
wandb_project = 'shakespeare-char'
|
| 14 |
+
wandb_run_name = 'mini-gpt'
|
| 15 |
+
|
| 16 |
+
dataset = 'shakespeare_char'
|
| 17 |
+
gradient_accumulation_steps = 1
|
| 18 |
+
batch_size = 64
|
| 19 |
+
block_size = 256 # context of up to 256 previous characters
|
| 20 |
+
|
| 21 |
+
# baby GPT model :)
|
| 22 |
+
n_layer = 6
|
| 23 |
+
n_head = 6
|
| 24 |
+
n_embd = 384
|
| 25 |
+
dropout = 0.2
|
| 26 |
+
|
| 27 |
+
learning_rate = 1e-3 # with baby networks can afford to go a bit higher
|
| 28 |
+
max_iters = 5000
|
| 29 |
+
lr_decay_iters = 5000 # make equal to max_iters usually
|
| 30 |
+
min_lr = 1e-4 # learning_rate / 10 usually
|
| 31 |
+
beta2 = 0.99 # make a bit bigger because number of tokens per iter is small
|
| 32 |
+
|
| 33 |
+
warmup_iters = 100 # not super necessary potentially
|
| 34 |
+
|
| 35 |
+
# on macbook also add
|
| 36 |
+
# device = 'cpu' # run on cpu only
|
| 37 |
+
# compile = False # do not torch compile the model
|
configurator.py
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Poor Man's Configurator. Probably a terrible idea. Example usage:
|
| 3 |
+
$ python train.py config/override_file.py --batch_size=32
|
| 4 |
+
this will first run config/override_file.py, then override batch_size to 32
|
| 5 |
+
|
| 6 |
+
The code in this file will be run as follows from e.g. train.py:
|
| 7 |
+
>>> exec(open('configurator.py').read())
|
| 8 |
+
|
| 9 |
+
So it's not a Python module, it's just shuttling this code away from train.py
|
| 10 |
+
The code in this script then overrides the globals()
|
| 11 |
+
|
| 12 |
+
I know people are not going to love this, I just really dislike configuration
|
| 13 |
+
complexity and having to prepend config. to every single variable. If someone
|
| 14 |
+
comes up with a better simple Python solution I am all ears.
|
| 15 |
+
"""
|
| 16 |
+
|
| 17 |
+
import sys
|
| 18 |
+
from ast import literal_eval
|
| 19 |
+
|
| 20 |
+
for arg in sys.argv[1:]:
|
| 21 |
+
if '=' not in arg:
|
| 22 |
+
# assume it's the name of a config file
|
| 23 |
+
assert not arg.startswith('--')
|
| 24 |
+
config_file = arg
|
| 25 |
+
print(f"Overriding config with {config_file}:")
|
| 26 |
+
with open(config_file) as f:
|
| 27 |
+
print(f.read())
|
| 28 |
+
exec(open(config_file).read())
|
| 29 |
+
else:
|
| 30 |
+
# assume it's a --key=value argument
|
| 31 |
+
assert arg.startswith('--')
|
| 32 |
+
key, val = arg.split('=')
|
| 33 |
+
key = key[2:]
|
| 34 |
+
if key in globals():
|
| 35 |
+
try:
|
| 36 |
+
# attempt to eval it it (e.g. if bool, number, or etc)
|
| 37 |
+
attempt = literal_eval(val)
|
| 38 |
+
except (SyntaxError, ValueError):
|
| 39 |
+
# if that goes wrong, just use the string
|
| 40 |
+
attempt = val
|
| 41 |
+
# ensure the types match ok
|
| 42 |
+
assert type(attempt) == type(globals()[key])
|
| 43 |
+
# cross fingers
|
| 44 |
+
print(f"Overriding: {key} = {attempt}")
|
| 45 |
+
globals()[key] = attempt
|
| 46 |
+
else:
|
| 47 |
+
raise ValueError(f"Unknown config key: {key}")
|
data/openwebtext/prepare.py
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# saves the openwebtext dataset to a binary file for training. following was helpful:
|
| 2 |
+
# https://github.com/HazyResearch/flash-attention/blob/main/training/src/datamodules/language_modeling_hf.py
|
| 3 |
+
|
| 4 |
+
import os
|
| 5 |
+
from tqdm import tqdm
|
| 6 |
+
import numpy as np
|
| 7 |
+
import tiktoken
|
| 8 |
+
from datasets import load_dataset # huggingface datasets
|
| 9 |
+
|
| 10 |
+
# number of workers in .map() call
|
| 11 |
+
# good number to use is ~order number of cpu cores // 2
|
| 12 |
+
num_proc = 8
|
| 13 |
+
|
| 14 |
+
# number of workers in load_dataset() call
|
| 15 |
+
# best number might be different from num_proc above as it also depends on NW speed.
|
| 16 |
+
# it is better than 1 usually though
|
| 17 |
+
num_proc_load_dataset = num_proc
|
| 18 |
+
|
| 19 |
+
if __name__ == '__main__':
|
| 20 |
+
# takes 54GB in huggingface .cache dir, about 8M documents (8,013,769)
|
| 21 |
+
dataset = load_dataset("openwebtext", num_proc=num_proc_load_dataset)
|
| 22 |
+
|
| 23 |
+
# owt by default only contains the 'train' split, so create a test split
|
| 24 |
+
split_dataset = dataset["train"].train_test_split(test_size=0.0005, seed=2357, shuffle=True)
|
| 25 |
+
split_dataset['val'] = split_dataset.pop('test') # rename the test split to val
|
| 26 |
+
|
| 27 |
+
# this results in:
|
| 28 |
+
# >>> split_dataset
|
| 29 |
+
# DatasetDict({
|
| 30 |
+
# train: Dataset({
|
| 31 |
+
# features: ['text'],
|
| 32 |
+
# num_rows: 8009762
|
| 33 |
+
# })
|
| 34 |
+
# val: Dataset({
|
| 35 |
+
# features: ['text'],
|
| 36 |
+
# num_rows: 4007
|
| 37 |
+
# })
|
| 38 |
+
# })
|
| 39 |
+
|
| 40 |
+
# we now want to tokenize the dataset. first define the encoding function (gpt2 bpe)
|
| 41 |
+
enc = tiktoken.get_encoding("gpt2")
|
| 42 |
+
def process(example):
|
| 43 |
+
ids = enc.encode_ordinary(example['text']) # encode_ordinary ignores any special tokens
|
| 44 |
+
ids.append(enc.eot_token) # add the end of text token, e.g. 50256 for gpt2 bpe
|
| 45 |
+
# note: I think eot should be prepended not appended... hmm. it's called "eot" though...
|
| 46 |
+
out = {'ids': ids, 'len': len(ids)}
|
| 47 |
+
return out
|
| 48 |
+
|
| 49 |
+
# tokenize the dataset
|
| 50 |
+
tokenized = split_dataset.map(
|
| 51 |
+
process,
|
| 52 |
+
remove_columns=['text'],
|
| 53 |
+
desc="tokenizing the splits",
|
| 54 |
+
num_proc=num_proc,
|
| 55 |
+
)
|
| 56 |
+
|
| 57 |
+
# concatenate all the ids in each dataset into one large file we can use for training
|
| 58 |
+
for split, dset in tokenized.items():
|
| 59 |
+
arr_len = np.sum(dset['len'], dtype=np.uint64)
|
| 60 |
+
filename = os.path.join(os.path.dirname(__file__), f'{split}.bin')
|
| 61 |
+
dtype = np.uint16 # (can do since enc.max_token_value == 50256 is < 2**16)
|
| 62 |
+
arr = np.memmap(filename, dtype=dtype, mode='w+', shape=(arr_len,))
|
| 63 |
+
total_batches = 1024
|
| 64 |
+
|
| 65 |
+
idx = 0
|
| 66 |
+
for batch_idx in tqdm(range(total_batches), desc=f'writing {filename}'):
|
| 67 |
+
# Batch together samples for faster write
|
| 68 |
+
batch = dset.shard(num_shards=total_batches, index=batch_idx, contiguous=True).with_format('numpy')
|
| 69 |
+
arr_batch = np.concatenate(batch['ids'])
|
| 70 |
+
# Write into mmap
|
| 71 |
+
arr[idx : idx + len(arr_batch)] = arr_batch
|
| 72 |
+
idx += len(arr_batch)
|
| 73 |
+
arr.flush()
|
| 74 |
+
|
| 75 |
+
# train.bin is ~17GB, val.bin ~8.5MB
|
| 76 |
+
# train has ~9B tokens (9,035,582,198)
|
| 77 |
+
# val has ~4M tokens (4,434,897)
|
| 78 |
+
|
| 79 |
+
# to read the bin files later, e.g. with numpy:
|
| 80 |
+
# m = np.memmap('train.bin', dtype=np.uint16, mode='r')
|
data/openwebtext/readme.md
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
## openwebtext dataset
|
| 3 |
+
|
| 4 |
+
after running `prepare.py` (preprocess) we get:
|
| 5 |
+
|
| 6 |
+
- train.bin is ~17GB, val.bin ~8.5MB
|
| 7 |
+
- train has ~9B tokens (9,035,582,198)
|
| 8 |
+
- val has ~4M tokens (4,434,897)
|
| 9 |
+
|
| 10 |
+
this came from 8,013,769 documents in total.
|
| 11 |
+
|
| 12 |
+
references:
|
| 13 |
+
|
| 14 |
+
- OpenAI's WebText dataset is discussed in [GPT-2 paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf)
|
| 15 |
+
- [OpenWebText](https://skylion007.github.io/OpenWebTextCorpus/) dataset
|
data/shakespeare/prepare.py
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import requests
|
| 3 |
+
import tiktoken
|
| 4 |
+
import numpy as np
|
| 5 |
+
|
| 6 |
+
# download the tiny shakespeare dataset
|
| 7 |
+
input_file_path = os.path.join(os.path.dirname(__file__), 'input.txt')
|
| 8 |
+
if not os.path.exists(input_file_path):
|
| 9 |
+
data_url = 'https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt'
|
| 10 |
+
with open(input_file_path, 'w') as f:
|
| 11 |
+
f.write(requests.get(data_url).text)
|
| 12 |
+
|
| 13 |
+
with open(input_file_path, 'r') as f:
|
| 14 |
+
data = f.read()
|
| 15 |
+
n = len(data)
|
| 16 |
+
train_data = data[:int(n*0.9)]
|
| 17 |
+
val_data = data[int(n*0.9):]
|
| 18 |
+
|
| 19 |
+
# encode with tiktoken gpt2 bpe
|
| 20 |
+
enc = tiktoken.get_encoding("gpt2")
|
| 21 |
+
train_ids = enc.encode_ordinary(train_data)
|
| 22 |
+
val_ids = enc.encode_ordinary(val_data)
|
| 23 |
+
print(f"train has {len(train_ids):,} tokens")
|
| 24 |
+
print(f"val has {len(val_ids):,} tokens")
|
| 25 |
+
|
| 26 |
+
# export to bin files
|
| 27 |
+
train_ids = np.array(train_ids, dtype=np.uint16)
|
| 28 |
+
val_ids = np.array(val_ids, dtype=np.uint16)
|
| 29 |
+
train_ids.tofile(os.path.join(os.path.dirname(__file__), 'train.bin'))
|
| 30 |
+
val_ids.tofile(os.path.join(os.path.dirname(__file__), 'val.bin'))
|
| 31 |
+
|
| 32 |
+
# train.bin has 301,966 tokens
|
| 33 |
+
# val.bin has 36,059 tokens
|
data/shakespeare/readme.md
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
# tiny shakespeare
|
| 3 |
+
|
| 4 |
+
Tiny shakespeare, of the good old char-rnn fame :)
|
| 5 |
+
|
| 6 |
+
After running `prepare.py`:
|
| 7 |
+
|
| 8 |
+
- train.bin has 301,966 tokens
|
| 9 |
+
- val.bin has 36,059 tokens
|
data/shakespeare_char/prepare.py
ADDED
|
@@ -0,0 +1,68 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Prepare the Shakespeare dataset for character-level language modeling.
|
| 3 |
+
So instead of encoding with GPT-2 BPE tokens, we just map characters to ints.
|
| 4 |
+
Will save train.bin, val.bin containing the ids, and meta.pkl containing the
|
| 5 |
+
encoder and decoder and some other related info.
|
| 6 |
+
"""
|
| 7 |
+
import os
|
| 8 |
+
import pickle
|
| 9 |
+
import requests
|
| 10 |
+
import numpy as np
|
| 11 |
+
|
| 12 |
+
# download the tiny shakespeare dataset
|
| 13 |
+
input_file_path = os.path.join(os.path.dirname(__file__), 'input.txt')
|
| 14 |
+
if not os.path.exists(input_file_path):
|
| 15 |
+
data_url = 'https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt'
|
| 16 |
+
with open(input_file_path, 'w') as f:
|
| 17 |
+
f.write(requests.get(data_url).text)
|
| 18 |
+
|
| 19 |
+
with open(input_file_path, 'r') as f:
|
| 20 |
+
data = f.read()
|
| 21 |
+
print(f"length of dataset in characters: {len(data):,}")
|
| 22 |
+
|
| 23 |
+
# get all the unique characters that occur in this text
|
| 24 |
+
chars = sorted(list(set(data)))
|
| 25 |
+
vocab_size = len(chars)
|
| 26 |
+
print("all the unique characters:", ''.join(chars))
|
| 27 |
+
print(f"vocab size: {vocab_size:,}")
|
| 28 |
+
|
| 29 |
+
# create a mapping from characters to integers
|
| 30 |
+
stoi = { ch:i for i,ch in enumerate(chars) }
|
| 31 |
+
itos = { i:ch for i,ch in enumerate(chars) }
|
| 32 |
+
def encode(s):
|
| 33 |
+
return [stoi[c] for c in s] # encoder: take a string, output a list of integers
|
| 34 |
+
def decode(l):
|
| 35 |
+
return ''.join([itos[i] for i in l]) # decoder: take a list of integers, output a string
|
| 36 |
+
|
| 37 |
+
# create the train and test splits
|
| 38 |
+
n = len(data)
|
| 39 |
+
train_data = data[:int(n*0.9)]
|
| 40 |
+
val_data = data[int(n*0.9):]
|
| 41 |
+
|
| 42 |
+
# encode both to integers
|
| 43 |
+
train_ids = encode(train_data)
|
| 44 |
+
val_ids = encode(val_data)
|
| 45 |
+
print(f"train has {len(train_ids):,} tokens")
|
| 46 |
+
print(f"val has {len(val_ids):,} tokens")
|
| 47 |
+
|
| 48 |
+
# export to bin files
|
| 49 |
+
train_ids = np.array(train_ids, dtype=np.uint16)
|
| 50 |
+
val_ids = np.array(val_ids, dtype=np.uint16)
|
| 51 |
+
train_ids.tofile(os.path.join(os.path.dirname(__file__), 'train.bin'))
|
| 52 |
+
val_ids.tofile(os.path.join(os.path.dirname(__file__), 'val.bin'))
|
| 53 |
+
|
| 54 |
+
# save the meta information as well, to help us encode/decode later
|
| 55 |
+
meta = {
|
| 56 |
+
'vocab_size': vocab_size,
|
| 57 |
+
'itos': itos,
|
| 58 |
+
'stoi': stoi,
|
| 59 |
+
}
|
| 60 |
+
with open(os.path.join(os.path.dirname(__file__), 'meta.pkl'), 'wb') as f:
|
| 61 |
+
pickle.dump(meta, f)
|
| 62 |
+
|
| 63 |
+
# length of dataset in characters: 1115394
|
| 64 |
+
# all the unique characters:
|
| 65 |
+
# !$&',-.3:;?ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz
|
| 66 |
+
# vocab size: 65
|
| 67 |
+
# train has 1003854 tokens
|
| 68 |
+
# val has 111540 tokens
|
data/shakespeare_char/readme.md
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
# tiny shakespeare, character-level
|
| 3 |
+
|
| 4 |
+
Tiny shakespeare, of the good old char-rnn fame :) Treated on character-level.
|
| 5 |
+
|
| 6 |
+
After running `prepare.py`:
|
| 7 |
+
|
| 8 |
+
- train.bin has 1,003,854 tokens
|
| 9 |
+
- val.bin has 111,540 tokens
|
generate.py
ADDED
|
@@ -0,0 +1,84 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import argparse
|
| 3 |
+
import tiktoken
|
| 4 |
+
import torch
|
| 5 |
+
import time
|
| 6 |
+
|
| 7 |
+
from modelGenerate import GPT
|
| 8 |
+
from dataclasses import dataclass
|
| 9 |
+
|
| 10 |
+
# Parse command-line arguments
|
| 11 |
+
parser = argparse.ArgumentParser()
|
| 12 |
+
parser.add_argument('--prompt', type=str, required=True,
|
| 13 |
+
help='Prompt for generation')
|
| 14 |
+
parser.add_argument('--max_num_tokens', type=int, default=100,
|
| 15 |
+
help='Maximum number of tokens to generate')
|
| 16 |
+
parser.add_argument('--model_name', type=str, required=True,
|
| 17 |
+
help='Name of the model checkpoint')
|
| 18 |
+
args = parser.parse_args()
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
@dataclass
|
| 22 |
+
class GPTConfig:
|
| 23 |
+
block_size: int = 1024
|
| 24 |
+
|
| 25 |
+
# GPT-2 vocab_size of 50257, padded up to nearest multiple of 64 for efficiency
|
| 26 |
+
vocab_size: int = 50304
|
| 27 |
+
|
| 28 |
+
n_layer: int = 8
|
| 29 |
+
n_head: int = 8
|
| 30 |
+
n_embd: int = 768
|
| 31 |
+
|
| 32 |
+
num_experts: int = 4
|
| 33 |
+
num_active_experts: int = 4
|
| 34 |
+
expert_dim: int = 512
|
| 35 |
+
dim: int = 768
|
| 36 |
+
|
| 37 |
+
dropout: float = 0.0
|
| 38 |
+
|
| 39 |
+
# True: bias in Linears and LayerNorms, like GPT-2. False: a bit better and faster
|
| 40 |
+
bias: bool = False
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
# Load the model checkpoint
|
| 44 |
+
ckpt_path = os.path.join('./out', f'{args.model_name}.pt')
|
| 45 |
+
checkpoint = torch.load(ckpt_path,torch.device('cpu'))
|
| 46 |
+
print(checkpoint['config'])
|
| 47 |
+
model_args = checkpoint['model_args']
|
| 48 |
+
gptconf = GPTConfig(**model_args)
|
| 49 |
+
model = GPT(gptconf)
|
| 50 |
+
model.load_state_dict(checkpoint['model'])
|
| 51 |
+
# model.cuda()
|
| 52 |
+
model.eval()
|
| 53 |
+
|
| 54 |
+
# Encode the prompt using tiktoken
|
| 55 |
+
enc = tiktoken.get_encoding("gpt2")
|
| 56 |
+
prompt_ids = enc.encode_ordinary(args.prompt)
|
| 57 |
+
|
| 58 |
+
# Measure inference time
|
| 59 |
+
start_time = time.time() # Get the current time before generating text
|
| 60 |
+
generated = model.generate(torch.tensor(
|
| 61 |
+
[prompt_ids], device='cpu'), max_new_tokens=args.max_num_tokens)
|
| 62 |
+
end_time = time.time() # Get the current time after generating text
|
| 63 |
+
inference_time = end_time - start_time # Calculate inference time in seconds
|
| 64 |
+
|
| 65 |
+
# Convert seconds to more readable format
|
| 66 |
+
if inference_time >= 3600:
|
| 67 |
+
hours = int(inference_time // 3600)
|
| 68 |
+
minutes = int((inference_time % 3600) // 60)
|
| 69 |
+
seconds = int(inference_time % 60)
|
| 70 |
+
inference_time_str = f"{hours} hours {minutes} minutes {seconds} seconds"
|
| 71 |
+
elif inference_time >= 60:
|
| 72 |
+
minutes = int(inference_time // 60)
|
| 73 |
+
seconds = int(inference_time % 60)
|
| 74 |
+
inference_time_str = f"{minutes} minutes {seconds} seconds"
|
| 75 |
+
else:
|
| 76 |
+
seconds = int(inference_time)
|
| 77 |
+
inference_time_str = f"{seconds} seconds"
|
| 78 |
+
|
| 79 |
+
output = enc.decode(generated[0].tolist())
|
| 80 |
+
|
| 81 |
+
print(f"Prompt: {args.prompt}")
|
| 82 |
+
print(f"Generated text: {output}")
|
| 83 |
+
print(f"Generated text length: {len(output)}")
|
| 84 |
+
print(f"Inference time: {inference_time_str}")
|
modelGenerate.py
ADDED
|
@@ -0,0 +1,442 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
|
| 5 |
+
from torch.nn import functional as F
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class LayerNorm(nn.Module):
|
| 9 |
+
""" LayerNorm but with an optional bias. PyTorch doesn't support simply bias=False """
|
| 10 |
+
|
| 11 |
+
def __init__(self, ndim, bias):
|
| 12 |
+
super().__init__()
|
| 13 |
+
self.weight = nn.Parameter(torch.ones(ndim))
|
| 14 |
+
self.bias = nn.Parameter(torch.zeros(ndim)) if bias else None
|
| 15 |
+
|
| 16 |
+
def forward(self, input):
|
| 17 |
+
return F.layer_norm(input, self.weight.shape, self.weight, self.bias, 1e-5)
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class RWKV_TimeMix_x051a(nn.Module):
|
| 21 |
+
|
| 22 |
+
def __init__(self, config, layer_id):
|
| 23 |
+
super().__init__()
|
| 24 |
+
assert config.n_embd % config.n_head == 0
|
| 25 |
+
|
| 26 |
+
self.head_size = config.n_embd // config.n_head
|
| 27 |
+
self.n_head = config.n_head
|
| 28 |
+
|
| 29 |
+
with torch.no_grad():
|
| 30 |
+
ratio_0_to_1 = layer_id / (config.n_layer - 1) # 0 to 1
|
| 31 |
+
ratio_1_to_almost0 = 1.0 - (layer_id / config.n_layer) # 1 to ~0
|
| 32 |
+
ddd = torch.ones(1, 1, config.n_embd)
|
| 33 |
+
for i in range(config.n_embd):
|
| 34 |
+
ddd[0, 0, i] = i / config.n_embd
|
| 35 |
+
|
| 36 |
+
self.time_maa_k = nn.Parameter(
|
| 37 |
+
1.0 - torch.pow(ddd, ratio_1_to_almost0))
|
| 38 |
+
self.time_maa_v = nn.Parameter(
|
| 39 |
+
1.0 - (torch.pow(ddd, ratio_1_to_almost0) + 0.3 * ratio_0_to_1))
|
| 40 |
+
self.time_maa_r = nn.Parameter(
|
| 41 |
+
1.0 - torch.pow(ddd, 0.5 * ratio_1_to_almost0))
|
| 42 |
+
self.time_maa_g = nn.Parameter(
|
| 43 |
+
1.0 - torch.pow(ddd, 0.5 * ratio_1_to_almost0))
|
| 44 |
+
|
| 45 |
+
decay_speed = torch.ones(self.n_head)
|
| 46 |
+
for h in range(self.n_head):
|
| 47 |
+
decay_speed[h] = -6 + 5 * \
|
| 48 |
+
(h / (self.n_head - 1)) ** (0.7 + 1.3 * ratio_0_to_1)
|
| 49 |
+
self.time_decay = nn.Parameter(decay_speed.unsqueeze(-1))
|
| 50 |
+
|
| 51 |
+
tmp = torch.zeros(self.n_head)
|
| 52 |
+
for h in range(self.n_head):
|
| 53 |
+
tmp[h] = ratio_0_to_1 * (1 - (h / (self.n_head - 1)))
|
| 54 |
+
self.time_faaaa = nn.Parameter(tmp.unsqueeze(-1))
|
| 55 |
+
|
| 56 |
+
self.time_shift = nn.ZeroPad2d((0, 0, 1, -1))
|
| 57 |
+
|
| 58 |
+
self.receptance = nn.Linear(
|
| 59 |
+
config.n_embd, config.n_embd, bias=config.bias)
|
| 60 |
+
self.key = nn.Linear(config.n_embd, config.n_embd, bias=config.bias)
|
| 61 |
+
self.value = nn.Linear(config.n_embd, config.n_embd, bias=config.bias)
|
| 62 |
+
self.gate = nn.Linear(config.n_embd, config.n_embd, bias=config.bias)
|
| 63 |
+
|
| 64 |
+
self.output = nn.Linear(config.n_embd, config.n_embd, bias=config.bias)
|
| 65 |
+
self.ln_x = nn.GroupNorm(self.n_head, config.n_embd, eps=(1e-5)*64)
|
| 66 |
+
|
| 67 |
+
self.dropout = nn.Dropout(config.dropout)
|
| 68 |
+
|
| 69 |
+
def forward(self, x):
|
| 70 |
+
B, T, C = x.size() # batch size, sequence length, embedding dimensionality (n_embd)
|
| 71 |
+
H, N = self.n_head, self.head_size
|
| 72 |
+
if T % 256 == 0:
|
| 73 |
+
Q = 256
|
| 74 |
+
elif T % 128 == 0:
|
| 75 |
+
Q = 128
|
| 76 |
+
else:
|
| 77 |
+
Q = T
|
| 78 |
+
assert T % Q == 0
|
| 79 |
+
|
| 80 |
+
xx = self.time_shift(x) - x
|
| 81 |
+
xk = x + xx * self.time_maa_k
|
| 82 |
+
xv = x + xx * self.time_maa_v
|
| 83 |
+
xr = x + xx * self.time_maa_r
|
| 84 |
+
xg = x + xx * self.time_maa_g
|
| 85 |
+
r = self.receptance(xr).view(B, T, H, N).transpose(1, 2) # receptance
|
| 86 |
+
k = self.key(xk).view(B, T, H, N).permute(0, 2, 3, 1) # key
|
| 87 |
+
v = self.value(xv).view(B, T, H, N).transpose(1, 2) # value
|
| 88 |
+
g = F.silu(self.gate(xg)) # extra gate
|
| 89 |
+
|
| 90 |
+
w = torch.exp(-torch.exp(self.time_decay.float())) # time_decay
|
| 91 |
+
u = self.time_faaaa.float() # time_first
|
| 92 |
+
|
| 93 |
+
ws = w.pow(Q).view(1, H, 1, 1)
|
| 94 |
+
|
| 95 |
+
ind = torch.arange(
|
| 96 |
+
Q-1, -1, -1, device=r.device).unsqueeze(0).repeat(H, 1)
|
| 97 |
+
w = w.repeat(1, Q).pow(ind)
|
| 98 |
+
|
| 99 |
+
wk = w.view(1, H, 1, Q)
|
| 100 |
+
wb = wk.transpose(-2, -1).flip(2)
|
| 101 |
+
|
| 102 |
+
w = torch.cat([w[:, 1:], u], dim=1)
|
| 103 |
+
w = F.pad(w, (0, Q))
|
| 104 |
+
w = torch.tile(w, [Q])
|
| 105 |
+
w = w[:, :-Q].view(-1, Q, 2*Q - 1)
|
| 106 |
+
w = w[:, :, Q-1:].view(1, H, Q, Q)
|
| 107 |
+
|
| 108 |
+
w = w.to(dtype=r.dtype) # the decay matrix
|
| 109 |
+
wk = wk.to(dtype=r.dtype)
|
| 110 |
+
wb = wb.to(dtype=r.dtype)
|
| 111 |
+
ws = ws.to(dtype=r.dtype)
|
| 112 |
+
|
| 113 |
+
state = torch.zeros(B, H, N, N, device=r.device,
|
| 114 |
+
dtype=r.dtype) # state
|
| 115 |
+
y = torch.empty(B, H, T, N, device=r.device, dtype=r.dtype) # output
|
| 116 |
+
|
| 117 |
+
for i in range(T // Q): # the rwkv-x051a operator
|
| 118 |
+
rr = r[:, :, i*Q:i*Q+Q, :]
|
| 119 |
+
kk = k[:, :, :, i*Q:i*Q+Q]
|
| 120 |
+
vv = v[:, :, i*Q:i*Q+Q, :]
|
| 121 |
+
y[:, :, i*Q:i*Q+Q, :] = ((rr @ kk) * w) @ vv + (rr @ state) * wb
|
| 122 |
+
state = ws * state + (kk * wk) @ vv
|
| 123 |
+
|
| 124 |
+
y = y.transpose(1, 2).contiguous().view(B * T, C)
|
| 125 |
+
y = self.ln_x(y).view(B, T, C) * g
|
| 126 |
+
|
| 127 |
+
# output projection
|
| 128 |
+
y = self.dropout(self.output(y))
|
| 129 |
+
return y
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
class RWKV_ChannelMix_x051a(nn.Module):
|
| 133 |
+
|
| 134 |
+
def __init__(self, config, layer_id):
|
| 135 |
+
super().__init__()
|
| 136 |
+
|
| 137 |
+
self.time_shift = nn.ZeroPad2d((0, 0, 1, -1))
|
| 138 |
+
with torch.no_grad():
|
| 139 |
+
ratio_1_to_almost0 = 1.0 - (layer_id / config.n_layer)
|
| 140 |
+
ddd = torch.ones(1, 1, config.n_embd)
|
| 141 |
+
for i in range(config.n_embd):
|
| 142 |
+
ddd[0, 0, i] = i / config.n_embd
|
| 143 |
+
self.time_maa_k = nn.Parameter(
|
| 144 |
+
1.0 - torch.pow(ddd, ratio_1_to_almost0))
|
| 145 |
+
self.time_maa_r = nn.Parameter(
|
| 146 |
+
1.0 - torch.pow(ddd, ratio_1_to_almost0))
|
| 147 |
+
|
| 148 |
+
self.key = nn.Linear(config.n_embd, 3 *
|
| 149 |
+
config.n_embd, bias=config.bias)
|
| 150 |
+
self.value = nn.Linear(
|
| 151 |
+
3 * config.n_embd, config.n_embd, bias=config.bias)
|
| 152 |
+
self.receptance = nn.Linear(
|
| 153 |
+
config.n_embd, config.n_embd, bias=config.bias)
|
| 154 |
+
self.dropout = nn.Dropout(config.dropout)
|
| 155 |
+
|
| 156 |
+
def forward(self, x):
|
| 157 |
+
xx = self.time_shift(x) - x
|
| 158 |
+
xk = x + xx * self.time_maa_k
|
| 159 |
+
xr = x + xx * self.time_maa_r
|
| 160 |
+
|
| 161 |
+
x = self.key(xk)
|
| 162 |
+
x = torch.relu(x) ** 2
|
| 163 |
+
x = self.value(x)
|
| 164 |
+
x = torch.sigmoid(self.receptance(xr)) * x
|
| 165 |
+
x = self.dropout(x)
|
| 166 |
+
return x
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
class RMSNorm(nn.Module):
|
| 170 |
+
def __init__(self, dim, eps=1e-8):
|
| 171 |
+
super().__init__()
|
| 172 |
+
self.scale = dim ** -0.5
|
| 173 |
+
self.eps = eps
|
| 174 |
+
|
| 175 |
+
def forward(self, x):
|
| 176 |
+
norm = torch.norm(x, dim=-1, keepdim=True) * self.scale
|
| 177 |
+
return x / (norm + self.eps)
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
class GroupedQAttention(nn.Module):
|
| 181 |
+
def __init__(self, dim, num_heads, groups=4):
|
| 182 |
+
super().__init__()
|
| 183 |
+
self.num_heads = num_heads
|
| 184 |
+
self.groups = groups
|
| 185 |
+
|
| 186 |
+
self.qkvw = nn.Linear(dim, dim * 4, bias=False)
|
| 187 |
+
self.out = nn.Linear(dim, dim, bias=False)
|
| 188 |
+
|
| 189 |
+
def forward(self, x):
|
| 190 |
+
batch, seq_len, dim = x.shape
|
| 191 |
+
qkvw = self.qkvw(x) # GENERATE
|
| 192 |
+
qkvw_gropus = torch.chunk(qkvw, self.groups, dim=-1) # GENERATE
|
| 193 |
+
q, k, v, w = [t.chunk(self.groups, dim=-1) for t in qkvw_gropus]
|
| 194 |
+
|
| 195 |
+
q, k, v, w = [
|
| 196 |
+
torch.cat([qi, ki, vi, wi], dim=0)
|
| 197 |
+
for qi, ki, vi, wi in zip(q, k, v, w)
|
| 198 |
+
]
|
| 199 |
+
|
| 200 |
+
q, k, v = map(
|
| 201 |
+
lambda t: t.view(batch * self.groups, self.num_heads, -1,
|
| 202 |
+
dim // self.num_heads // self.groups).transpose(1, 2),
|
| 203 |
+
[q, k, v]
|
| 204 |
+
)
|
| 205 |
+
w = w.view(batch * self.groups, self.num_heads, -
|
| 206 |
+
1, dim // self.num_heads // self.groups)
|
| 207 |
+
|
| 208 |
+
attn_output = (q @ k.transpose(-2, -1)) * \
|
| 209 |
+
(dim // self.num_heads // self.groups) ** -0.5
|
| 210 |
+
attn_output = attn_output.softmax(dim=-1)
|
| 211 |
+
attn_output = (attn_output @ v).transpose(1,
|
| 212 |
+
2).reshape(batch, seq_len, dim)
|
| 213 |
+
return self.out(attn_output * w.reshape(batch, seq_len, dim))
|
| 214 |
+
|
| 215 |
+
|
| 216 |
+
class SlidingWindowAttention(nn.Module):
|
| 217 |
+
def __init__(self, dim, window_size, num_heads):
|
| 218 |
+
super().__init__()
|
| 219 |
+
self.dim = dim
|
| 220 |
+
self.window_size = window_size
|
| 221 |
+
self.num_heads = num_heads
|
| 222 |
+
self.head_dim = dim // num_heads
|
| 223 |
+
|
| 224 |
+
self.qkv = nn.Linear(dim, dim * 3, bias=False)
|
| 225 |
+
self.proj = nn.Linear(dim, dim, bias=False)
|
| 226 |
+
|
| 227 |
+
def forward(self, x):
|
| 228 |
+
B, N, C = x.shape
|
| 229 |
+
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads,
|
| 230 |
+
self.head_dim).permute(2, 0, 3, 1, 4)
|
| 231 |
+
q, k, v = qkv[0], qkv[1], qkv[2]
|
| 232 |
+
|
| 233 |
+
q = q * self.head_dim ** -0.5
|
| 234 |
+
|
| 235 |
+
# Pad to multiple of window size
|
| 236 |
+
padding = (self.window_size - N % self.window_size) % self.window_size
|
| 237 |
+
q = F.pad(q, (0, 0, 0, padding))
|
| 238 |
+
k = F.pad(k, (0, 0, 0, padding))
|
| 239 |
+
v = F.pad(v, (0, 0, 0, padding))
|
| 240 |
+
|
| 241 |
+
# Reshape to sliding windows
|
| 242 |
+
q = q.reshape(B * self.num_heads, self.window_size, -1)
|
| 243 |
+
k = k.reshape(B * self.num_heads, self.window_size, -1)
|
| 244 |
+
v = v.reshape(B * self.num_heads, self.window_size, -1)
|
| 245 |
+
|
| 246 |
+
attn = q @ k.transpose(-2, -1)
|
| 247 |
+
attn = attn.softmax(dim=-1)
|
| 248 |
+
attn = attn @ v
|
| 249 |
+
|
| 250 |
+
attn = attn.reshape(B, self.num_heads, N + padding, self.head_dim)
|
| 251 |
+
attn = attn[:, :, :N, :].permute(0, 2, 1, 3).reshape(B, N, C)
|
| 252 |
+
return self.proj(attn)
|
| 253 |
+
|
| 254 |
+
|
| 255 |
+
class TinyMoE(nn.Module):
|
| 256 |
+
def __init__(self, dim, num_experts, num_active_experts, expert_dim, dropout=0.0, expert_capacity_scale=1.0, aux_loss_weight=0.1):
|
| 257 |
+
super().__init__()
|
| 258 |
+
self.dim = dim
|
| 259 |
+
self.num_experts = num_experts
|
| 260 |
+
self.num_active_experts = num_active_experts
|
| 261 |
+
self.expert_dim = expert_dim
|
| 262 |
+
self.dropout = nn.Dropout(dropout)
|
| 263 |
+
self.gate = nn.Linear(dim, num_experts)
|
| 264 |
+
self.expert_capacity_scale = expert_capacity_scale
|
| 265 |
+
self.scaled_expert_dim = int(expert_dim * self.expert_capacity_scale)
|
| 266 |
+
self.experts = nn.ModuleList(
|
| 267 |
+
[nn.Linear(dim, self.scaled_expert_dim) for _ in range(num_active_experts)])
|
| 268 |
+
self.fc = nn.Linear(self.scaled_expert_dim, dim)
|
| 269 |
+
|
| 270 |
+
# Auxiliary loss
|
| 271 |
+
self.aux_loss_weight = aux_loss_weight
|
| 272 |
+
self.expert_diversity_loss = nn.MSELoss()
|
| 273 |
+
|
| 274 |
+
def forward(self, x):
|
| 275 |
+
b, n, d = x.shape
|
| 276 |
+
|
| 277 |
+
# Compute attention scores
|
| 278 |
+
scores = self.gate(x).view(b, n, self.num_experts)
|
| 279 |
+
scores = F.softmax(scores, dim=-1)
|
| 280 |
+
|
| 281 |
+
# Apply dropout to the attention scores
|
| 282 |
+
scores = self.dropout(scores)
|
| 283 |
+
|
| 284 |
+
# Compute the weighted sum of expert outputs
|
| 285 |
+
expert_outputs = torch.stack(
|
| 286 |
+
[exp(x.view(b * n, d)) for exp in self.experts], dim=1)
|
| 287 |
+
expert_outputs = expert_outputs.view(
|
| 288 |
+
b, n, self.num_active_experts, self.scaled_expert_dim)
|
| 289 |
+
weighted_outputs = (
|
| 290 |
+
expert_outputs * scores[:, :, :self.num_active_experts].unsqueeze(-1)).sum(dim=2)
|
| 291 |
+
|
| 292 |
+
# Apply the final linear layer
|
| 293 |
+
output = self.fc(weighted_outputs)
|
| 294 |
+
|
| 295 |
+
# Auxiliary loss: Expert diversity
|
| 296 |
+
# (b, num_active_experts, scaled_expert_dim)
|
| 297 |
+
expert_activations = expert_outputs.mean(dim=1)
|
| 298 |
+
expert_diversity_loss = self.expert_diversity_loss(expert_activations.transpose(
|
| 299 |
+
0, 1), torch.zeros_like(expert_activations.transpose(0, 1)))
|
| 300 |
+
|
| 301 |
+
return output, expert_diversity_loss * self.aux_loss_weight
|
| 302 |
+
|
| 303 |
+
def set_expert_capacity(self, expert_capacity_scale):
|
| 304 |
+
self.expert_capacity_scale = expert_capacity_scale
|
| 305 |
+
self.scaled_expert_dim = int(
|
| 306 |
+
self.expert_dim * self.expert_capacity_scale)
|
| 307 |
+
self.experts = nn.ModuleList([nn.Linear(
|
| 308 |
+
self.dim, self.scaled_expert_dim) for _ in range(self.num_active_experts)])
|
| 309 |
+
self.fc = nn.Linear(self.scaled_expert_dim, self.dim)
|
| 310 |
+
|
| 311 |
+
|
| 312 |
+
class Block(nn.Module):
|
| 313 |
+
|
| 314 |
+
def __init__(self, config, layer_id):
|
| 315 |
+
super().__init__()
|
| 316 |
+
self.ln_1 = RMSNorm(config.n_embd)
|
| 317 |
+
self.ln_2 = RMSNorm(config.n_embd)
|
| 318 |
+
|
| 319 |
+
# stay in here because this is a core component
|
| 320 |
+
self.tmix = RWKV_TimeMix_x051a(config, layer_id)
|
| 321 |
+
|
| 322 |
+
# Add GroupedQAttention instance
|
| 323 |
+
self.grouped_attn = GroupedQAttention(config.n_embd, config.n_head)
|
| 324 |
+
|
| 325 |
+
# stay in here because this is a core component
|
| 326 |
+
self.cmix = RWKV_ChannelMix_x051a(config, layer_id)
|
| 327 |
+
|
| 328 |
+
self.sliding_attn = SlidingWindowAttention(
|
| 329 |
+
config.n_embd, window_size=256, num_heads=config.n_head)
|
| 330 |
+
|
| 331 |
+
self.moe = TinyMoE(config.dim, config.num_experts, config.num_active_experts,
|
| 332 |
+
config.expert_dim, config.dropout, expert_capacity_scale=1.2, aux_loss_weight=0.01)
|
| 333 |
+
|
| 334 |
+
def forward(self, x):
|
| 335 |
+
x = x + self.tmix(self.ln_1(x))
|
| 336 |
+
x = x + self.cmix(self.ln_2(x))
|
| 337 |
+
x = x + self.sliding_attn(x) # Apply sliding window attention
|
| 338 |
+
x = x + self.grouped_attn(self.tmix(x)) # Apply GroupedQAttention
|
| 339 |
+
# x = x + self.moe(x) # Apply TinyMoE
|
| 340 |
+
moe_output, aux_loss = self.moe(x)
|
| 341 |
+
x = x + moe_output
|
| 342 |
+
return x
|
| 343 |
+
|
| 344 |
+
|
| 345 |
+
class GPT(nn.Module):
|
| 346 |
+
|
| 347 |
+
def __init__(self, config):
|
| 348 |
+
super().__init__()
|
| 349 |
+
assert config.vocab_size is not None
|
| 350 |
+
assert config.block_size is not None
|
| 351 |
+
self.config = config
|
| 352 |
+
|
| 353 |
+
self.transformer = nn.ModuleDict(dict(
|
| 354 |
+
wte=nn.Embedding(config.vocab_size, config.n_embd),
|
| 355 |
+
wpe=nn.Embedding(config.block_size, config.n_embd),
|
| 356 |
+
drop=nn.Dropout(config.dropout),
|
| 357 |
+
h=nn.ModuleList([Block(config, i) for i in range(config.n_layer)]),
|
| 358 |
+
ln_f=LayerNorm(config.n_embd, bias=config.bias),
|
| 359 |
+
))
|
| 360 |
+
self.lm_head = nn.Linear(
|
| 361 |
+
self.config.n_embd, self.config.vocab_size, bias=False)
|
| 362 |
+
self.transformer.wte.weight = self.lm_head.weight
|
| 363 |
+
|
| 364 |
+
# init all weights
|
| 365 |
+
self.apply(self._init_weights)
|
| 366 |
+
|
| 367 |
+
# apply special scaled init to the residual projections, per GPT-2 paper
|
| 368 |
+
for pn, p in self.named_parameters():
|
| 369 |
+
if pn.endswith('tmix.output.weight'):
|
| 370 |
+
torch.nn.init.normal_(
|
| 371 |
+
p, mean=0.0, std=0.02/math.sqrt(2 * self.config.n_layer))
|
| 372 |
+
|
| 373 |
+
# report number of parameters
|
| 374 |
+
print("number of parameters: %.2fM" % (self.get_num_params()/1e6,))
|
| 375 |
+
|
| 376 |
+
def get_num_params(self, non_embedding=True):
|
| 377 |
+
n_params = sum(p.numel() for p in self.parameters())
|
| 378 |
+
if non_embedding:
|
| 379 |
+
n_params -= self.transformer.wpe.weight.numel()
|
| 380 |
+
return n_params
|
| 381 |
+
|
| 382 |
+
def _init_weights(self, module):
|
| 383 |
+
if isinstance(module, nn.Linear):
|
| 384 |
+
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
|
| 385 |
+
if module.bias is not None:
|
| 386 |
+
torch.nn.init.zeros_(module.bias)
|
| 387 |
+
elif isinstance(module, nn.Embedding):
|
| 388 |
+
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
|
| 389 |
+
|
| 390 |
+
def forward(self, idx, targets=None):
|
| 391 |
+
device = idx.device
|
| 392 |
+
b, t = idx.size()
|
| 393 |
+
assert t <= self.config.block_size, f"Cannot forward sequence of length {t}, block size is only {self.config.block_size}"
|
| 394 |
+
pos = torch.arange(0, t, dtype=torch.long, device=device) # shape (t)
|
| 395 |
+
|
| 396 |
+
# forward the GPT model itself
|
| 397 |
+
# token embeddings of shape (b, t, n_embd)
|
| 398 |
+
tok_emb = self.transformer.wte(idx)
|
| 399 |
+
|
| 400 |
+
# position embeddings of shape (t, n_embd)
|
| 401 |
+
pos_emb = self.transformer.wpe(pos)
|
| 402 |
+
x = self.transformer.drop(tok_emb + pos_emb)
|
| 403 |
+
for block in self.transformer.h:
|
| 404 |
+
x = block(x)
|
| 405 |
+
x = self.transformer.ln_f(x)
|
| 406 |
+
|
| 407 |
+
if targets is not None:
|
| 408 |
+
# if we are given some desired targets also calculate the loss
|
| 409 |
+
logits = self.lm_head(x)
|
| 410 |
+
loss = F.cross_entropy(
|
| 411 |
+
logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-1)
|
| 412 |
+
else:
|
| 413 |
+
# inference-time mini-optimization: only forward the lm_head on the very last position
|
| 414 |
+
# note: using list [-1] to preserve the time dim
|
| 415 |
+
logits = self.lm_head(x[:, [-1], :])
|
| 416 |
+
loss = None
|
| 417 |
+
|
| 418 |
+
return logits, loss
|
| 419 |
+
|
| 420 |
+
@torch.no_grad()
|
| 421 |
+
def generate(self, idx, max_new_tokens, top_k=None):
|
| 422 |
+
|
| 423 |
+
for _ in range(max_new_tokens):
|
| 424 |
+
# if the sequence context is growing too long we must crop it at block_size
|
| 425 |
+
idx_cond = idx if idx.size(
|
| 426 |
+
1) <= self.config.block_size else idx[:, -self.config.block_size:]
|
| 427 |
+
# forward the model to get the logits for the index in the sequence
|
| 428 |
+
logits, _ = self(idx_cond)
|
| 429 |
+
# pluck the logits at the final step and scale by desired temperature
|
| 430 |
+
logits = logits[:, -1, :]
|
| 431 |
+
# optionally crop the logits to only the top k options
|
| 432 |
+
if top_k is not None:
|
| 433 |
+
v, _ = torch.topk(logits, min(top_k, logits.size(-1)))
|
| 434 |
+
logits[logits < v[:, [-1]]] = -float('Inf')
|
| 435 |
+
# apply softmax to convert logits to (normalized) probabilities
|
| 436 |
+
probs = F.softmax(logits, dim=-1)
|
| 437 |
+
# sample from the distribution
|
| 438 |
+
idx_next = torch.multinomial(probs, num_samples=1)
|
| 439 |
+
# append sampled index to the running sequence and continue
|
| 440 |
+
idx = torch.cat((idx, idx_next), dim=1)
|
| 441 |
+
|
| 442 |
+
return idx
|
modeling_rwkv.py
ADDED
|
@@ -0,0 +1,687 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Full definition of a RWKV Language Model, all of it in this single file.
|
| 3 |
+
References:
|
| 4 |
+
1) the official RWKV PyTorch implementation released by Bo Peng:
|
| 5 |
+
https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v4neo/src/model.py
|
| 6 |
+
2) huggingface/transformers PyTorch implementation:
|
| 7 |
+
https://github.com/huggingface/transformers/blob/main/src/transformers/models/rwkv/modeling_rwkv.py
|
| 8 |
+
"""
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
import math,time
|
| 12 |
+
import os
|
| 13 |
+
import inspect
|
| 14 |
+
from dataclasses import dataclass
|
| 15 |
+
|
| 16 |
+
import torch
|
| 17 |
+
import torch.nn as nn
|
| 18 |
+
from torch.nn import functional as F
|
| 19 |
+
|
| 20 |
+
PREV_X_TIME = 0
|
| 21 |
+
NUM_STATE = 1
|
| 22 |
+
DEN_STATE = 2
|
| 23 |
+
MAX_STATE = 3
|
| 24 |
+
PREV_X_CHANNEL = 4
|
| 25 |
+
|
| 26 |
+
# copied from nanoGPT
|
| 27 |
+
class LayerNorm(nn.Module):
|
| 28 |
+
""" LayerNorm but with an optional bias. PyTorch doesn't support simply bias=False """
|
| 29 |
+
|
| 30 |
+
def __init__(self, ndim, bias):
|
| 31 |
+
super().__init__()
|
| 32 |
+
self.weight = nn.Parameter(torch.ones(ndim))
|
| 33 |
+
self.bias = nn.Parameter(torch.zeros(ndim)) if bias else None
|
| 34 |
+
|
| 35 |
+
def forward(self, input):
|
| 36 |
+
return F.layer_norm(input, self.weight.shape, self.weight, self.bias, 1e-5)
|
| 37 |
+
|
| 38 |
+
# learn from GPT-4
|
| 39 |
+
from unittest.mock import patch
|
| 40 |
+
class CudaNotAvailable:
|
| 41 |
+
def __enter__(self):
|
| 42 |
+
self.patcher = patch("torch.cuda.is_available", return_value=False)
|
| 43 |
+
self.patcher.start()
|
| 44 |
+
|
| 45 |
+
def __exit__(self, exc_type, exc_value, traceback):
|
| 46 |
+
self.patcher.stop()
|
| 47 |
+
|
| 48 |
+
# https://github.com/BlinkDL/RWKV-LM/blob/cca1b5e8e597cf40675882bb10b46287c844e35c/RWKV-v4/src/model.py#L21
|
| 49 |
+
class L2Wrap(torch.autograd.Function):
|
| 50 |
+
@staticmethod
|
| 51 |
+
def forward(ctx, loss, y):
|
| 52 |
+
ctx.save_for_backward(y)
|
| 53 |
+
return loss
|
| 54 |
+
@staticmethod
|
| 55 |
+
def backward(ctx, grad_output):
|
| 56 |
+
y = ctx.saved_tensors[0]
|
| 57 |
+
# to encourage the logits to be close to 0
|
| 58 |
+
factor = 1e-4 / (y.shape[0] * y.shape[1])
|
| 59 |
+
maxx, ids = torch.max(y, -1, keepdim=True)
|
| 60 |
+
gy = torch.zeros_like(y)
|
| 61 |
+
gy.scatter_(-1, ids, maxx * factor)
|
| 62 |
+
return (grad_output, gy)
|
| 63 |
+
|
| 64 |
+
class ChannelMixing(nn.Module):
|
| 65 |
+
def __init__(self,config,layer_id):
|
| 66 |
+
super().__init__()
|
| 67 |
+
self.time_shift = nn.ZeroPad2d((0, 0, 1, -1))
|
| 68 |
+
self.layer_id = layer_id
|
| 69 |
+
|
| 70 |
+
n_embd = config.n_embd
|
| 71 |
+
intermediate_size = (
|
| 72 |
+
config.intermediate_size if config.intermediate_size is not None else 4 * n_embd
|
| 73 |
+
)
|
| 74 |
+
|
| 75 |
+
## Learnable Matrix
|
| 76 |
+
self.key_proj = nn.Linear(n_embd,intermediate_size,bias=False)
|
| 77 |
+
self.value_proj = nn.Linear(intermediate_size,n_embd,bias=False)
|
| 78 |
+
self.receptance_proj = nn.Linear(n_embd,n_embd,bias=False)
|
| 79 |
+
|
| 80 |
+
## Learnable Vector
|
| 81 |
+
self.time_mix_key = nn.Parameter(torch.empty(1, 1, n_embd))
|
| 82 |
+
self.time_mix_receptance = nn.Parameter(torch.empty(1, 1, n_embd))
|
| 83 |
+
|
| 84 |
+
def forward(self,x,state=None):
|
| 85 |
+
# x = (Batch,Time,Channel)
|
| 86 |
+
if state is not None:
|
| 87 |
+
prev_x = state[self.layer_id,:,[PREV_X_CHANNEL],:]
|
| 88 |
+
state[self.layer_id,:,[PREV_X_CHANNEL],:] = x
|
| 89 |
+
else:
|
| 90 |
+
prev_x = self.time_shift(x)
|
| 91 |
+
|
| 92 |
+
## R
|
| 93 |
+
receptance = x * self.time_mix_receptance + prev_x * (1 - self.time_mix_receptance)
|
| 94 |
+
receptance = self.receptance_proj(receptance)
|
| 95 |
+
receptance = F.sigmoid(receptance)
|
| 96 |
+
|
| 97 |
+
# K
|
| 98 |
+
key = x * self.time_mix_key + prev_x * (1 - self.time_mix_key)
|
| 99 |
+
key = self.key_proj(key)
|
| 100 |
+
|
| 101 |
+
# V
|
| 102 |
+
value = self.value_proj(torch.square(torch.relu(key)))
|
| 103 |
+
|
| 104 |
+
## output
|
| 105 |
+
out = receptance * value
|
| 106 |
+
return out, state
|
| 107 |
+
|
| 108 |
+
class TimeMixing(nn.Module):
|
| 109 |
+
def __init__(self,config,layer_id):
|
| 110 |
+
super().__init__()
|
| 111 |
+
self.config = config
|
| 112 |
+
self.time_shift = nn.ZeroPad2d((0, 0, 1, -1))
|
| 113 |
+
self.layer_id = layer_id
|
| 114 |
+
|
| 115 |
+
n_embd = config.n_embd
|
| 116 |
+
attn_sz = n_embd
|
| 117 |
+
|
| 118 |
+
## learnable matrix
|
| 119 |
+
self.key_proj = nn.Linear(n_embd, attn_sz, bias=False)
|
| 120 |
+
self.value_proj = nn.Linear(n_embd, attn_sz, bias=False)
|
| 121 |
+
self.receptance_proj = nn.Linear(n_embd, attn_sz, bias=False)
|
| 122 |
+
self.output_proj = nn.Linear(attn_sz, n_embd, bias=False)
|
| 123 |
+
|
| 124 |
+
## learnable vector
|
| 125 |
+
self.time_decay = nn.Parameter(torch.empty(attn_sz))
|
| 126 |
+
self.time_first = nn.Parameter(torch.empty(attn_sz))
|
| 127 |
+
self.time_mix_key = nn.Parameter(torch.empty(1, 1, n_embd))
|
| 128 |
+
self.time_mix_value = nn.Parameter(torch.empty(1, 1, n_embd))
|
| 129 |
+
self.time_mix_receptance = nn.Parameter(torch.empty(1, 1, n_embd))
|
| 130 |
+
|
| 131 |
+
def forward(self,x,state=None):
|
| 132 |
+
# x = (Batch,Time,Channel)
|
| 133 |
+
if state is not None:
|
| 134 |
+
prev_x = state[self.layer_id,:,[PREV_X_TIME],:]
|
| 135 |
+
state[self.layer_id,:,[PREV_X_TIME],:] = x
|
| 136 |
+
else:
|
| 137 |
+
prev_x = self.time_shift(x)
|
| 138 |
+
|
| 139 |
+
# K
|
| 140 |
+
key = x * self.time_mix_key + prev_x * (1 - self.time_mix_key)
|
| 141 |
+
key = self.key_proj(key)
|
| 142 |
+
|
| 143 |
+
# V
|
| 144 |
+
value = x * self.time_mix_value + prev_x * (1 - self.time_mix_value)
|
| 145 |
+
value = self.value_proj(value)
|
| 146 |
+
|
| 147 |
+
# R
|
| 148 |
+
receptance = x * self.time_mix_receptance + prev_x * (1 - self.time_mix_receptance)
|
| 149 |
+
receptance = self.receptance_proj(receptance)
|
| 150 |
+
receptance = F.sigmoid(receptance)
|
| 151 |
+
|
| 152 |
+
# WKV
|
| 153 |
+
wkv, state = self.wkv_function(key,value,use_customized_cuda_kernel=self.config.use_customized_cuda_kernel,state=state)
|
| 154 |
+
|
| 155 |
+
# RWKV
|
| 156 |
+
rwkv = receptance * wkv
|
| 157 |
+
rwkv = self.output_proj(rwkv)
|
| 158 |
+
|
| 159 |
+
return rwkv, state
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
def wkv_function(self,key,value,use_customized_cuda_kernel,state=None):
|
| 163 |
+
|
| 164 |
+
## essentially, this customized cuda kernel delivers a faster for loop across time steps
|
| 165 |
+
## only for training and evaluating loss and ppl
|
| 166 |
+
if state is None and use_customized_cuda_kernel:
|
| 167 |
+
B, T, C = key.size()
|
| 168 |
+
return WKVKernel.apply(B, T, C, self.time_decay, self.time_first, key, value), None
|
| 169 |
+
|
| 170 |
+
## raw wkv function (from Huggingface Implementation)
|
| 171 |
+
## only for generation (because using raw pytorch for loop to train the model would be super super slow)
|
| 172 |
+
else:
|
| 173 |
+
_, seq_length, _ = key.size()
|
| 174 |
+
output = torch.zeros_like(key)
|
| 175 |
+
|
| 176 |
+
debug_mode = False
|
| 177 |
+
if state is None:
|
| 178 |
+
## only for debug purpose when use_customized_cuda_kernel=False and state is None
|
| 179 |
+
debug_mode = True
|
| 180 |
+
num_state = torch.zeros_like(key[:, 0], dtype=torch.float32)
|
| 181 |
+
den_state = torch.zeros_like(key[:, 0], dtype=torch.float32)
|
| 182 |
+
max_state = torch.zeros_like(key[:, 0], dtype=torch.float32) - 1e38
|
| 183 |
+
else:
|
| 184 |
+
num_state = state[self.layer_id,:,NUM_STATE,:]
|
| 185 |
+
den_state = state[self.layer_id,:,DEN_STATE,:]
|
| 186 |
+
max_state = state[self.layer_id,:,MAX_STATE,:]
|
| 187 |
+
|
| 188 |
+
time_decay = -torch.exp(self.time_decay)
|
| 189 |
+
|
| 190 |
+
for current_index in range(seq_length):
|
| 191 |
+
current_key = key[:, current_index].float()
|
| 192 |
+
current_value = value[:, current_index]
|
| 193 |
+
|
| 194 |
+
# wkv computation at time t
|
| 195 |
+
max_for_output = torch.maximum(max_state, current_key + self.time_first)
|
| 196 |
+
e1 = torch.exp(max_state - max_for_output)
|
| 197 |
+
e2 = torch.exp(current_key + self.time_first - max_for_output)
|
| 198 |
+
numerator = e1 * num_state + e2 * current_value
|
| 199 |
+
denominator = e1 * den_state + e2
|
| 200 |
+
output[:, current_index] = (numerator / denominator).to(output.dtype)
|
| 201 |
+
|
| 202 |
+
# Update state for next iteration
|
| 203 |
+
max_for_state = torch.maximum(max_state + time_decay, current_key)
|
| 204 |
+
e1 = torch.exp(max_state + time_decay - max_for_state)
|
| 205 |
+
e2 = torch.exp(current_key - max_for_state)
|
| 206 |
+
num_state = e1 * num_state + e2 * current_value
|
| 207 |
+
den_state = e1 * den_state + e2
|
| 208 |
+
max_state = max_for_state
|
| 209 |
+
|
| 210 |
+
if debug_mode:
|
| 211 |
+
return output, None
|
| 212 |
+
|
| 213 |
+
else:
|
| 214 |
+
state[self.layer_id,:,NUM_STATE,:] = num_state
|
| 215 |
+
state[self.layer_id,:,DEN_STATE,:] = den_state
|
| 216 |
+
state[self.layer_id,:,MAX_STATE,:] = max_state
|
| 217 |
+
|
| 218 |
+
return output, state
|
| 219 |
+
|
| 220 |
+
class Block(nn.Module):
|
| 221 |
+
|
| 222 |
+
def __init__(self, config,layer_id):
|
| 223 |
+
super().__init__()
|
| 224 |
+
self.ln_1 = LayerNorm(config.n_embd, bias=config.bias)
|
| 225 |
+
self.attn = TimeMixing(config,layer_id)
|
| 226 |
+
self.ln_2 = LayerNorm(config.n_embd, bias=config.bias)
|
| 227 |
+
self.ffn = ChannelMixing(config,layer_id)
|
| 228 |
+
|
| 229 |
+
def forward(self, x, state = None):
|
| 230 |
+
# state: [batch_size, 5 , n_embd]
|
| 231 |
+
|
| 232 |
+
# time mixing
|
| 233 |
+
residual = x
|
| 234 |
+
x,state = self.attn(self.ln_1(x),state=state)
|
| 235 |
+
x = x + residual
|
| 236 |
+
|
| 237 |
+
# channel mixing
|
| 238 |
+
residual = x
|
| 239 |
+
x, state = self.ffn(self.ln_2(x),state=state)
|
| 240 |
+
x = x + residual
|
| 241 |
+
|
| 242 |
+
return x, state
|
| 243 |
+
|
| 244 |
+
@dataclass
|
| 245 |
+
class RWKVConfig:
|
| 246 |
+
block_size: int = 1024 # same as nanoGPT
|
| 247 |
+
vocab_size: int = 50304 # GPT-2 vocab_size of 50257, padded up to nearest multiple of 64 for efficiency
|
| 248 |
+
n_layer: int = 12
|
| 249 |
+
n_embd: int = 768
|
| 250 |
+
bias: bool = True # bias in LayerNorms, in RWKV, all bias in Linear is False
|
| 251 |
+
intermediate_size: int = None # intermediate_size in channel-mixing
|
| 252 |
+
use_customized_cuda_kernel: bool = True
|
| 253 |
+
dtype: str = "float16" ## bfloat16 is not supported in V100
|
| 254 |
+
rescale_every: int = 6 ## mysterious trick, only applies when inference
|
| 255 |
+
|
| 256 |
+
class RWKV(nn.Module):
|
| 257 |
+
|
| 258 |
+
def __init__(self, config,lr_init=0.0008):
|
| 259 |
+
super().__init__()
|
| 260 |
+
assert config.vocab_size is not None
|
| 261 |
+
assert config.block_size is not None
|
| 262 |
+
self.config = config
|
| 263 |
+
self.lr_init = lr_init ## used to initialize embedding parameters
|
| 264 |
+
self.rwkv = nn.ModuleDict(dict(
|
| 265 |
+
wte = nn.Embedding(config.vocab_size, config.n_embd),
|
| 266 |
+
ln_p = LayerNorm(config.n_embd, bias=config.bias),
|
| 267 |
+
h = nn.ModuleList([Block(config,layer_id) for layer_id in range(config.n_layer)]),
|
| 268 |
+
ln_f = LayerNorm(config.n_embd, bias=config.bias),
|
| 269 |
+
))
|
| 270 |
+
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
|
| 271 |
+
|
| 272 |
+
self.apply(self._init_weights)
|
| 273 |
+
print("number of parameters: %.2fM" % (self.get_num_params()/1e6,))
|
| 274 |
+
|
| 275 |
+
if self.config.use_customized_cuda_kernel:
|
| 276 |
+
## load customized cuda kernel
|
| 277 |
+
self.load_cuda_kernel(config.dtype)
|
| 278 |
+
|
| 279 |
+
def get_num_params(self, non_embedding=True):
|
| 280 |
+
"""
|
| 281 |
+
Return the number of parameters in the model.
|
| 282 |
+
For non-embedding count (default), the token embeddings get subtracted.
|
| 283 |
+
"""
|
| 284 |
+
n_params = sum(p.numel() for p in self.parameters())
|
| 285 |
+
if non_embedding:
|
| 286 |
+
n_params -= self.rwkv.wte.weight.numel()
|
| 287 |
+
return n_params
|
| 288 |
+
|
| 289 |
+
def _init_weights(self, module):
|
| 290 |
+
|
| 291 |
+
## initialize Vector Parameters in TimeMixing
|
| 292 |
+
if isinstance(module,TimeMixing):
|
| 293 |
+
layer_id = module.layer_id
|
| 294 |
+
n_layer = self.config.n_layer
|
| 295 |
+
n_embd = self.config.n_embd
|
| 296 |
+
attn_sz = n_embd
|
| 297 |
+
|
| 298 |
+
with torch.no_grad():
|
| 299 |
+
ratio_0_to_1 = layer_id / (n_layer - 1) # 0 to 1
|
| 300 |
+
ratio_1_to_almost0 = 1.0 - (layer_id / n_layer) # 1 to ~0
|
| 301 |
+
ddd = torch.ones(1, 1, n_embd)
|
| 302 |
+
for i in range(n_embd):
|
| 303 |
+
ddd[0, 0, i] = i / n_embd
|
| 304 |
+
|
| 305 |
+
decay_speed = torch.ones(attn_sz)
|
| 306 |
+
for h in range(attn_sz):
|
| 307 |
+
decay_speed[h] = -5 + 8 * (h / (attn_sz - 1)) ** (0.7 + 1.3 * ratio_0_to_1)
|
| 308 |
+
module.time_decay = nn.Parameter(decay_speed)
|
| 309 |
+
|
| 310 |
+
zigzag = torch.tensor([(i + 1) % 3 - 1 for i in range(attn_sz)]) * 0.5
|
| 311 |
+
module.time_first = nn.Parameter(torch.ones(attn_sz) * math.log(0.3) + zigzag)
|
| 312 |
+
module.time_mix_key = nn.Parameter(torch.pow(ddd, ratio_1_to_almost0))
|
| 313 |
+
module.time_mix_value = nn.Parameter(torch.pow(ddd, ratio_1_to_almost0) + 0.3 * ratio_0_to_1)
|
| 314 |
+
module.time_mix_receptance = nn.Parameter(torch.pow(ddd, 0.5 * ratio_1_to_almost0))
|
| 315 |
+
|
| 316 |
+
## initialize Vector Parameters in ChannelMixing
|
| 317 |
+
elif isinstance(module,ChannelMixing):
|
| 318 |
+
layer_id = module.layer_id
|
| 319 |
+
n_layer = self.config.n_layer
|
| 320 |
+
n_embd = self.config.n_embd
|
| 321 |
+
|
| 322 |
+
with torch.no_grad(): # fancy init of time_mix
|
| 323 |
+
ratio_1_to_almost0 = 1.0 - (layer_id / n_layer) # 1 to ~0
|
| 324 |
+
ddd = torch.ones(1, 1, n_embd)
|
| 325 |
+
for i in range(n_embd):
|
| 326 |
+
ddd[0, 0, i] = i / n_embd
|
| 327 |
+
module.time_mix_key = nn.Parameter(torch.pow(ddd, ratio_1_to_almost0))
|
| 328 |
+
module.time_mix_receptance = nn.Parameter(torch.pow(ddd, ratio_1_to_almost0))
|
| 329 |
+
|
| 330 |
+
## initialize Linear Layer and Embedding Layer
|
| 331 |
+
elif isinstance(module,(nn.Embedding,nn.Linear)):
|
| 332 |
+
weight = module.weight
|
| 333 |
+
shape = weight.shape
|
| 334 |
+
gain = 1.0
|
| 335 |
+
scale = 1.0
|
| 336 |
+
|
| 337 |
+
## get the current name of the parameters
|
| 338 |
+
for _name,_parameters in self.named_parameters():
|
| 339 |
+
if id(_parameters) == id(weight):
|
| 340 |
+
current_module_name = _name
|
| 341 |
+
|
| 342 |
+
# print(current_module_name)
|
| 343 |
+
|
| 344 |
+
## Embedding
|
| 345 |
+
if isinstance(module, nn.Embedding):
|
| 346 |
+
gain = math.sqrt(max(shape[0], shape[1]))
|
| 347 |
+
scale = -1 * self.lr_init
|
| 348 |
+
|
| 349 |
+
## Linear
|
| 350 |
+
elif isinstance(module,nn.Linear):
|
| 351 |
+
if shape[0] > shape[1]:
|
| 352 |
+
gain = math.sqrt(shape[0] / shape[1])
|
| 353 |
+
|
| 354 |
+
## initialize some matrix to be all ZEROS
|
| 355 |
+
for name in [".attn.key_proj.", ".attn.receptance_proj.", ".attn.output_proj.",
|
| 356 |
+
".ffn.value_proj.", ".ffn.receptance_proj."]:
|
| 357 |
+
if name in current_module_name:
|
| 358 |
+
scale = 0
|
| 359 |
+
|
| 360 |
+
if current_module_name == 'lm_head.weight':
|
| 361 |
+
scale = 0.5
|
| 362 |
+
|
| 363 |
+
if scale == 0:
|
| 364 |
+
nn.init.zeros_(weight)
|
| 365 |
+
elif scale < 0:
|
| 366 |
+
nn.init.uniform_(weight, a=scale, b=-scale)
|
| 367 |
+
else:
|
| 368 |
+
nn.init.orthogonal_(weight, gain=gain * scale)
|
| 369 |
+
|
| 370 |
+
def forward(self, idx, targets=None, state=None, return_state=False):
|
| 371 |
+
|
| 372 |
+
device = idx.device
|
| 373 |
+
b, t = idx.size()
|
| 374 |
+
assert t <= self.config.block_size, f"Cannot forward sequence of length {t}, block size is only {self.config.block_size}"
|
| 375 |
+
|
| 376 |
+
x = self.rwkv.wte(idx)
|
| 377 |
+
x = self.rwkv.ln_p(x)
|
| 378 |
+
# x = self.rwkv.drop(x)
|
| 379 |
+
for block_idx,block in enumerate(self.rwkv.h):
|
| 380 |
+
x, state = block(x,state)
|
| 381 |
+
if state is not None: ## in generation mode
|
| 382 |
+
if (
|
| 383 |
+
self.config.rescale_every > 0
|
| 384 |
+
and (block_idx + 1) % self.config.rescale_every == 0
|
| 385 |
+
):
|
| 386 |
+
x = x/2
|
| 387 |
+
x = self.rwkv.ln_f(x)
|
| 388 |
+
|
| 389 |
+
if targets is not None:
|
| 390 |
+
# if we are given some desired targets also calculate the loss
|
| 391 |
+
logits = self.lm_head(x)
|
| 392 |
+
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-1)
|
| 393 |
+
if self.training:
|
| 394 |
+
loss = L2Wrap.apply(loss,logits) # from RWKV-LM
|
| 395 |
+
else:
|
| 396 |
+
# inference-time mini-optimization: only forward the lm_head on the very last position
|
| 397 |
+
logits = self.lm_head(x[:, [-1], :]) # note: using list [-1] to preserve the time dim
|
| 398 |
+
loss = None
|
| 399 |
+
|
| 400 |
+
if return_state:
|
| 401 |
+
return logits, loss, state
|
| 402 |
+
else:
|
| 403 |
+
return logits, loss
|
| 404 |
+
|
| 405 |
+
def crop_block_size(self, block_size):
|
| 406 |
+
assert block_size <= self.config.block_size
|
| 407 |
+
self.config.block_size = block_size
|
| 408 |
+
|
| 409 |
+
@classmethod
|
| 410 |
+
def from_pretrained(cls, model_type,use_customized_cuda_kernel=True,dtype="float16"):
|
| 411 |
+
assert model_type in {
|
| 412 |
+
'RWKV/rwkv-4-169m-pile',
|
| 413 |
+
"RWKV/rwkv-4-430m-pile",
|
| 414 |
+
"RWKV/rwkv-4-1b5-pile",
|
| 415 |
+
"RWKV/rwkv-4-3b-pile",
|
| 416 |
+
"RWKV/rwkv-4-7b-pile",
|
| 417 |
+
"RWKV/rwkv-raven-7b",
|
| 418 |
+
"RWKV/rwkv-raven-1b5",
|
| 419 |
+
"RWKV/rwkv-raven-3b",
|
| 420 |
+
"RWKV/rwkv-4-14b-pile",
|
| 421 |
+
}
|
| 422 |
+
print("loading weights from pretrained RWKV: %s" % model_type)
|
| 423 |
+
|
| 424 |
+
# init a huggingface/transformers model
|
| 425 |
+
from transformers import RwkvForCausalLM,RwkvConfig
|
| 426 |
+
hf_config = RwkvConfig.from_pretrained(model_type)
|
| 427 |
+
with CudaNotAvailable(): ## avoid HF load kernel
|
| 428 |
+
hf_model = RwkvForCausalLM.from_pretrained(model_type)
|
| 429 |
+
|
| 430 |
+
# create a from-scratch initialized RWKV model
|
| 431 |
+
config = {
|
| 432 |
+
"vocab_size":50277,
|
| 433 |
+
"n_layer":hf_config.num_hidden_layers,
|
| 434 |
+
"n_embd":hf_config.hidden_size,
|
| 435 |
+
"intermediate_size":hf_config.intermediate_size,
|
| 436 |
+
"use_customized_cuda_kernel":use_customized_cuda_kernel,
|
| 437 |
+
"dtype": dtype,
|
| 438 |
+
}
|
| 439 |
+
config = RWKVConfig(**config)
|
| 440 |
+
model = RWKV(config)
|
| 441 |
+
num_layers = config.n_layer
|
| 442 |
+
## create mapping from the parameter name in RWKV to that of HF-RWKV
|
| 443 |
+
mapping = {
|
| 444 |
+
"rwkv.wte.weight":"rwkv.embeddings.weight",
|
| 445 |
+
"rwkv.ln_p.weight":"rwkv.blocks.0.pre_ln.weight",
|
| 446 |
+
"rwkv.ln_p.bias":"rwkv.blocks.0.pre_ln.bias",
|
| 447 |
+
"rwkv.ln_f.weight":"rwkv.ln_out.weight",
|
| 448 |
+
"rwkv.ln_f.bias":"rwkv.ln_out.bias",
|
| 449 |
+
"lm_head.weight":"head.weight",
|
| 450 |
+
**{f"rwkv.h.{layer_id}.ln_{norm_id}.weight":f"rwkv.blocks.{layer_id}.ln{norm_id}.weight" for layer_id in range(num_layers) for norm_id in [1,2]},
|
| 451 |
+
**{f"rwkv.h.{layer_id}.ln_{norm_id}.bias":f"rwkv.blocks.{layer_id}.ln{norm_id}.bias" for layer_id in range(num_layers) for norm_id in [1,2]},
|
| 452 |
+
**{f"rwkv.h.{layer_id}.attn.{_type}":f"rwkv.blocks.{layer_id}.attention.{_type}" for layer_id in range(num_layers) for _type in ["time_decay","time_first",'time_mix_key','time_mix_value',"time_mix_receptance"]},
|
| 453 |
+
**{f"rwkv.h.{layer_id}.attn.{_type}_proj.weight":f"rwkv.blocks.{layer_id}.attention.{_type}.weight" for layer_id in range(num_layers) for _type in ["key","value",'receptance',"output"]},
|
| 454 |
+
**{f"rwkv.h.{layer_id}.ffn.{_type}":f"rwkv.blocks.{layer_id}.feed_forward.{_type}" for layer_id in range(num_layers) for _type in ['time_mix_key',"time_mix_receptance"]},
|
| 455 |
+
**{f"rwkv.h.{layer_id}.ffn.{_type}_proj.weight":f"rwkv.blocks.{layer_id}.feed_forward.{_type}.weight" for layer_id in range(num_layers) for _type in ["key","value",'receptance']},
|
| 456 |
+
}
|
| 457 |
+
|
| 458 |
+
mapped_set = [mapping[x] for x in model.state_dict().keys()]
|
| 459 |
+
assert set(mapped_set) == set(hf_model.state_dict().keys())
|
| 460 |
+
sd = model.state_dict()
|
| 461 |
+
hf_sd = hf_model.state_dict()
|
| 462 |
+
|
| 463 |
+
for k1,k2 in mapping.items():
|
| 464 |
+
assert sd[k1].shape == hf_sd[k2].shape,(k1,k2)
|
| 465 |
+
sd[k1].copy_(hf_sd[k2])
|
| 466 |
+
return model
|
| 467 |
+
|
| 468 |
+
# def configure_optimizers(self,weight_decay,learning_rate,betas,device_type):
|
| 469 |
+
# # lr_1x = set()
|
| 470 |
+
# # lr_2x = set()
|
| 471 |
+
# # lr_3x = set()
|
| 472 |
+
# # for n, p in self.named_parameters():
|
| 473 |
+
# # if "time_mix" in n:lr_1x.add(n)
|
| 474 |
+
# # elif "time_decay" in n:lr_2x.add(n)
|
| 475 |
+
# # elif "time_first" in n:lr_3x.add(n)
|
| 476 |
+
# # else:lr_1x.add(n)
|
| 477 |
+
# # lr_1x = sorted(list(lr_1x))
|
| 478 |
+
# # lr_2x = sorted(list(lr_2x))
|
| 479 |
+
# # lr_3x = sorted(list(lr_3x))
|
| 480 |
+
|
| 481 |
+
# # param_dict = {n: p for n, p in self.named_parameters()}
|
| 482 |
+
# # optim_groups = [
|
| 483 |
+
# # {"params": [param_dict[n] for n in lr_1x], "weight_decay": 0.0, "my_lr_scale": 1.0},
|
| 484 |
+
# # {"params": [param_dict[n] for n in lr_2x], "weight_decay": 0.0, "my_lr_scale": 2.0},
|
| 485 |
+
# # {"params": [param_dict[n] for n in lr_3x], "weight_decay": 0.0, "my_lr_scale": 3.0},
|
| 486 |
+
# # ]
|
| 487 |
+
|
| 488 |
+
# optim_groups = [{"params": [p for n, p in self.named_parameters()], "weight_decay": 0.0},]
|
| 489 |
+
# fused_available = 'fused' in inspect.signature(torch.optim.AdamW).parameters
|
| 490 |
+
# use_fused = fused_available and device_type == 'cuda'
|
| 491 |
+
# extra_args = dict(fused=True) if use_fused else dict()
|
| 492 |
+
# optimizer = torch.optim.Adam(optim_groups, lr=learning_rate, betas=betas, eps=1e-8, weight_decay=weight_decay,amsgrad=False,**extra_args)
|
| 493 |
+
|
| 494 |
+
# return optimizer
|
| 495 |
+
def configure_optimizers(self, weight_decay, learning_rate, betas, device_type):
|
| 496 |
+
# start with all of the candidate parameters
|
| 497 |
+
param_dict = {pn: p for pn, p in self.named_parameters()}
|
| 498 |
+
# filter out those that do not require grad
|
| 499 |
+
param_dict = {pn: p for pn, p in param_dict.items() if p.requires_grad}
|
| 500 |
+
# create optim groups. Any parameters that is 2D will be weight decayed, otherwise no.
|
| 501 |
+
# i.e. all weight tensors in matmuls + embeddings decay, all biases and layernorms don't.
|
| 502 |
+
decay_params = [p for n, p in param_dict.items() if p.dim() >= 2]
|
| 503 |
+
nodecay_params = [p for n, p in param_dict.items() if p.dim() < 2]
|
| 504 |
+
optim_groups = [
|
| 505 |
+
{'params': decay_params, 'weight_decay': weight_decay},
|
| 506 |
+
{'params': nodecay_params, 'weight_decay': 0.0}
|
| 507 |
+
]
|
| 508 |
+
num_decay_params = sum(p.numel() for p in decay_params)
|
| 509 |
+
num_nodecay_params = sum(p.numel() for p in nodecay_params)
|
| 510 |
+
print(f"num decayed parameter tensors: {len(decay_params)}, with {num_decay_params:,} parameters")
|
| 511 |
+
print(f"num non-decayed parameter tensors: {len(nodecay_params)}, with {num_nodecay_params:,} parameters")
|
| 512 |
+
# Create AdamW optimizer and use the fused version if it is available
|
| 513 |
+
fused_available = 'fused' in inspect.signature(torch.optim.AdamW).parameters
|
| 514 |
+
use_fused = fused_available and device_type == 'cuda'
|
| 515 |
+
extra_args = dict(fused=True) if use_fused else dict()
|
| 516 |
+
optimizer = torch.optim.AdamW(optim_groups, lr=learning_rate, betas=betas, **extra_args)
|
| 517 |
+
print(f"using fused AdamW: {use_fused}")
|
| 518 |
+
|
| 519 |
+
return optimizer
|
| 520 |
+
|
| 521 |
+
def estimate_mfu(self, fwdbwd_per_iter, dt):
|
| 522 |
+
""" estimate model flops utilization (MFU) in units of A100 bfloat16 peak FLOPS """
|
| 523 |
+
# first estimate the number of flops we do per iteration.
|
| 524 |
+
# see RWKV paper Appendix C as ref: https://arxiv.org/abs/2305.13048
|
| 525 |
+
cfg = self.config
|
| 526 |
+
L, V, D = cfg.n_layer, cfg.vocab_size, cfg.n_embd
|
| 527 |
+
# Note there is a typo in the RWKV paper. Forward pass is 2*fn, forward
|
| 528 |
+
# and backward is 6*fn.
|
| 529 |
+
flops_per_token = 2*(V*D + 13*(V**2)*L)
|
| 530 |
+
flops_per_fwdbwd = 3*flops_per_token
|
| 531 |
+
flops_per_iter = flops_per_fwdbwd * fwdbwd_per_iter
|
| 532 |
+
# express our flops throughput as ratio of A100 bfloat16 peak flops
|
| 533 |
+
flops_achieved = flops_per_iter * (1.0/dt) # per second
|
| 534 |
+
# https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/a100/pdf/nvidia-a100-datasheet.pdf
|
| 535 |
+
if cfg.dtype == 'bfloat16':
|
| 536 |
+
flops_promised = 312e12 # A100 GPU bfloat16 peak flops is 312 TFLOPS
|
| 537 |
+
elif cfg.dtype == 'float16':
|
| 538 |
+
flops_promised = 312e12 # A100 GPU float16 peak flops is 312 TFLOPS
|
| 539 |
+
else: #dtype == float32
|
| 540 |
+
flops_promised = 19.5e12 # A100 GPU float32 peak flops is 19.5 TFLOPS
|
| 541 |
+
mfu = flops_achieved / flops_promised
|
| 542 |
+
return mfu
|
| 543 |
+
|
| 544 |
+
def init_state(self,batch_size,device):
|
| 545 |
+
|
| 546 |
+
n_state = len([PREV_X_TIME,NUM_STATE,DEN_STATE,MAX_STATE,PREV_X_CHANNEL])
|
| 547 |
+
state = torch.zeros(
|
| 548 |
+
(self.config.n_layer,batch_size,n_state,self.config.n_embd),
|
| 549 |
+
dtype=torch.float32, device=device,
|
| 550 |
+
)
|
| 551 |
+
state[:,:,MAX_STATE,:] -= 1e30
|
| 552 |
+
|
| 553 |
+
return state
|
| 554 |
+
|
| 555 |
+
def scale_parameters(self):
|
| 556 |
+
if self.config.rescale_every > 0:
|
| 557 |
+
with torch.no_grad():
|
| 558 |
+
for block_id,block in enumerate(self.rwkv.h):
|
| 559 |
+
block.attn.output_proj.weight.div_(2 ** int(block_id // self.config.rescale_every))
|
| 560 |
+
block.ffn.value_proj.weight.div_(2 ** int(block_id // self.config.rescale_every))
|
| 561 |
+
self.scaled = True
|
| 562 |
+
|
| 563 |
+
def unscale_parameters(self):
|
| 564 |
+
if self.config.rescale_every > 0 and self.scaled:
|
| 565 |
+
with torch.no_grad():
|
| 566 |
+
for block_id,block in enumerate(self.rwkv.h):
|
| 567 |
+
block.attn.output_proj.weight.mul_(2 ** int(block_id // self.config.rescale_every))
|
| 568 |
+
block.ffn.value_proj.weight.mul_(2 ** int(block_id // self.config.rescale_every))
|
| 569 |
+
|
| 570 |
+
@torch.no_grad()
|
| 571 |
+
def generate(self, idx, max_new_tokens, temperature=1.0, top_k=None):
|
| 572 |
+
"""
|
| 573 |
+
idx: (batch_size,seq_len)
|
| 574 |
+
"""
|
| 575 |
+
batch_size,seq_len = idx.shape
|
| 576 |
+
state = self.init_state(batch_size,idx.device)
|
| 577 |
+
for seq_id in range(seq_len):
|
| 578 |
+
logits, _, state = self(idx[:,[seq_id]], state = state, return_state=True)
|
| 579 |
+
|
| 580 |
+
for _ in range(max_new_tokens):
|
| 581 |
+
# pluck the logits at the final step and scale by desired temperature
|
| 582 |
+
logits = logits[:, -1, :] / temperature
|
| 583 |
+
# optionally crop the logits to only the top k options
|
| 584 |
+
if top_k is not None:
|
| 585 |
+
v, _ = torch.topk(logits, min(top_k, logits.size(-1)))
|
| 586 |
+
logits[logits < v[:, [-1]]] = -float('Inf')
|
| 587 |
+
# apply softmax to convert logits to (normalized) probabilities
|
| 588 |
+
probs = F.softmax(logits, dim=-1)
|
| 589 |
+
# sample from the distribution
|
| 590 |
+
idx_next = torch.multinomial(probs, num_samples=1)
|
| 591 |
+
# append sampled index to the running sequence and continue
|
| 592 |
+
idx = torch.cat((idx, idx_next), dim=1)
|
| 593 |
+
logits, _, state = self(idx_next, state=state, return_state=True)
|
| 594 |
+
return idx
|
| 595 |
+
|
| 596 |
+
def load_cuda_kernel(self,dtype):
|
| 597 |
+
|
| 598 |
+
from torch.utils.cpp_extension import load
|
| 599 |
+
T_MAX = self.config.block_size
|
| 600 |
+
RWKV_FLOAT_MODE = dtype
|
| 601 |
+
if RWKV_FLOAT_MODE == "bfloat16":
|
| 602 |
+
wkv_cuda = load(name=f"wkv_{T_MAX}_bf16", sources=["cuda/wkv_op_bf16.cpp", "cuda/wkv_cuda_bf16.cu"], verbose=True, extra_cuda_cflags=["-t 4", "-std=c++17", "-res-usage", "--maxrregcount 60", "--use_fast_math", "-O3", "-Xptxas -O3", "--extra-device-vectorization", f"-DTmax={T_MAX}"])
|
| 603 |
+
class WKV(torch.autograd.Function):
|
| 604 |
+
@staticmethod
|
| 605 |
+
def forward(ctx, B, T, C, w, u, k, v):
|
| 606 |
+
ctx.B = B
|
| 607 |
+
ctx.T = T
|
| 608 |
+
ctx.C = C
|
| 609 |
+
assert T <= T_MAX
|
| 610 |
+
assert B * C % min(C, 32) == 0
|
| 611 |
+
w = -torch.exp(w.float().contiguous())
|
| 612 |
+
u = u.contiguous().bfloat16()
|
| 613 |
+
k = k.contiguous()
|
| 614 |
+
v = v.contiguous()
|
| 615 |
+
y = torch.empty((B, T, C), device=w.device, memory_format=torch.contiguous_format, dtype=torch.bfloat16)
|
| 616 |
+
wkv_cuda.forward(B, T, C, w, u, k, v, y)
|
| 617 |
+
ctx.save_for_backward(w, u, k, v, y)
|
| 618 |
+
return y
|
| 619 |
+
@staticmethod
|
| 620 |
+
def backward(ctx, gy):
|
| 621 |
+
B = ctx.B
|
| 622 |
+
T = ctx.T
|
| 623 |
+
C = ctx.C
|
| 624 |
+
assert T <= T_MAX
|
| 625 |
+
assert B * C % min(C, 32) == 0
|
| 626 |
+
w, u, k, v, y = ctx.saved_tensors
|
| 627 |
+
gw = torch.empty((B, C), device=gy.device, memory_format=torch.contiguous_format, dtype=torch.bfloat16)
|
| 628 |
+
gu = torch.empty((B, C), device=gy.device, memory_format=torch.contiguous_format, dtype=torch.bfloat16)
|
| 629 |
+
gk = torch.empty((B, T, C), device=gy.device, memory_format=torch.contiguous_format, dtype=torch.bfloat16)
|
| 630 |
+
gv = torch.empty((B, T, C), device=gy.device, memory_format=torch.contiguous_format, dtype=torch.bfloat16)
|
| 631 |
+
wkv_cuda.backward(B, T, C, w, u, k, v, y, gy.contiguous(), gw, gu, gk, gv)
|
| 632 |
+
gw = torch.sum(gw, dim=0)
|
| 633 |
+
gu = torch.sum(gu, dim=0)
|
| 634 |
+
return (None, None, None, gw, gu, gk, gv)
|
| 635 |
+
else:
|
| 636 |
+
wkv_cuda = load(name=f"wkv_{T_MAX}", sources=["cuda/wkv_op.cpp", "cuda/wkv_cuda.cu"], verbose=True, extra_cuda_cflags=["-res-usage", "--maxrregcount 60", "--use_fast_math", "-O3", "-Xptxas -O3", "--extra-device-vectorization", f"-DTmax={T_MAX}"])
|
| 637 |
+
class WKV(torch.autograd.Function):
|
| 638 |
+
@staticmethod
|
| 639 |
+
def forward(ctx, B, T, C, w, u, k, v):
|
| 640 |
+
ctx.B = B
|
| 641 |
+
ctx.T = T
|
| 642 |
+
ctx.C = C
|
| 643 |
+
assert T <= T_MAX
|
| 644 |
+
assert B * C % min(C, 32) == 0
|
| 645 |
+
if "32" in RWKV_FLOAT_MODE:
|
| 646 |
+
w = -torch.exp(w.contiguous())
|
| 647 |
+
u = u.contiguous()
|
| 648 |
+
k = k.contiguous()
|
| 649 |
+
v = v.contiguous()
|
| 650 |
+
else:
|
| 651 |
+
w = -torch.exp(w.float().contiguous())
|
| 652 |
+
u = u.float().contiguous()
|
| 653 |
+
k = k.float().contiguous()
|
| 654 |
+
v = v.float().contiguous()
|
| 655 |
+
y = torch.empty((B, T, C), device=w.device, memory_format=torch.contiguous_format)
|
| 656 |
+
wkv_cuda.forward(B, T, C, w, u, k, v, y)
|
| 657 |
+
ctx.save_for_backward(w, u, k, v, y)
|
| 658 |
+
if "32" in RWKV_FLOAT_MODE:
|
| 659 |
+
return y
|
| 660 |
+
elif RWKV_FLOAT_MODE == "float16":
|
| 661 |
+
return y.half()
|
| 662 |
+
|
| 663 |
+
@staticmethod
|
| 664 |
+
def backward(ctx, gy):
|
| 665 |
+
B = ctx.B
|
| 666 |
+
T = ctx.T
|
| 667 |
+
C = ctx.C
|
| 668 |
+
assert T <= T_MAX
|
| 669 |
+
assert B * C % min(C, 32) == 0
|
| 670 |
+
w, u, k, v, y = ctx.saved_tensors
|
| 671 |
+
gw = torch.empty((B, C), device=gy.device, memory_format=torch.contiguous_format)
|
| 672 |
+
gu = torch.empty((B, C), device=gy.device, memory_format=torch.contiguous_format)
|
| 673 |
+
gk = torch.empty((B, T, C), device=gy.device, memory_format=torch.contiguous_format)
|
| 674 |
+
gv = torch.empty((B, T, C), device=gy.device, memory_format=torch.contiguous_format)
|
| 675 |
+
if "32" in RWKV_FLOAT_MODE:
|
| 676 |
+
wkv_cuda.backward(B, T, C, w, u, k, v, y, gy.contiguous(), gw, gu, gk, gv)
|
| 677 |
+
else:
|
| 678 |
+
wkv_cuda.backward(B, T, C, w, u, k, v, y, gy.float().contiguous(), gw, gu, gk, gv)
|
| 679 |
+
gw = torch.sum(gw, dim=0)
|
| 680 |
+
gu = torch.sum(gu, dim=0)
|
| 681 |
+
if "32" in RWKV_FLOAT_MODE:
|
| 682 |
+
return (None, None, None, gw, gu, gk, gv)
|
| 683 |
+
elif RWKV_FLOAT_MODE == "float16":
|
| 684 |
+
return (None, None, None, gw.half(), gu.half(), gk.half(), gv.half())
|
| 685 |
+
|
| 686 |
+
global WKVKernel
|
| 687 |
+
WKVKernel = WKV
|
out/.keep
ADDED
|
File without changes
|
sample.py
ADDED
|
@@ -0,0 +1,101 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Sample from a trained model
|
| 3 |
+
"""
|
| 4 |
+
import os
|
| 5 |
+
import pickle
|
| 6 |
+
from contextlib import nullcontext
|
| 7 |
+
import torch
|
| 8 |
+
import tiktoken
|
| 9 |
+
from modeling_gpt import GPTConfig, GPT
|
| 10 |
+
from modeling_rwkv import RWKV,RWKVConfig
|
| 11 |
+
|
| 12 |
+
# -----------------------------------------------------------------------------
|
| 13 |
+
init_from = 'resume' # either 'resume' (from an out_dir) or a gpt2 variant (e.g. 'gpt2-xl')
|
| 14 |
+
out_dir = 'out' # ignored if init_from is not 'resume'
|
| 15 |
+
start = "\n" # or "<|endoftext|>" or etc. Can also specify a file, use as: "FILE:prompt.txt"
|
| 16 |
+
num_samples = 10 # number of samples to draw
|
| 17 |
+
max_new_tokens = 500 # number of tokens generated in each sample
|
| 18 |
+
temperature = 0.8 # 1.0 = no change, < 1.0 = less random, > 1.0 = more random, in predictions
|
| 19 |
+
top_k = 200 # retain only the top_k most likely tokens, clamp others to have 0 probability
|
| 20 |
+
seed = 1337
|
| 21 |
+
device = 'cuda' # examples: 'cpu', 'cuda', 'cuda:0', 'cuda:1', etc.
|
| 22 |
+
dtype = 'bfloat16' if torch.cuda.is_bf16_supported() else 'float16' # 'float32' or 'bfloat16' or 'float16'
|
| 23 |
+
compile = False # use PyTorch 2.0 to compile the model to be faster
|
| 24 |
+
exec(open('configurator.py').read()) # overrides from command line or config file
|
| 25 |
+
# -----------------------------------------------------------------------------
|
| 26 |
+
|
| 27 |
+
torch.manual_seed(seed)
|
| 28 |
+
torch.cuda.manual_seed(seed)
|
| 29 |
+
torch.backends.cuda.matmul.allow_tf32 = True # allow tf32 on matmul
|
| 30 |
+
torch.backends.cudnn.allow_tf32 = True # allow tf32 on cudnn
|
| 31 |
+
device_type = 'cuda' if 'cuda' in device else 'cpu' # for later use in torch.autocast
|
| 32 |
+
ptdtype = {'float32': torch.float32, 'bfloat16': torch.bfloat16, 'float16': torch.float16}[dtype]
|
| 33 |
+
ctx = nullcontext() if device_type == 'cpu' else torch.amp.autocast(device_type=device_type, dtype=ptdtype)
|
| 34 |
+
|
| 35 |
+
# model
|
| 36 |
+
if init_from == 'resume':
|
| 37 |
+
# init from a model saved in a specific directory
|
| 38 |
+
ckpt_path = os.path.join(out_dir, 'ckpt.pt')
|
| 39 |
+
checkpoint = torch.load(ckpt_path, map_location=device)
|
| 40 |
+
gptconf = GPTConfig(**checkpoint['model_args'])
|
| 41 |
+
model = GPT(gptconf)
|
| 42 |
+
state_dict = checkpoint['model']
|
| 43 |
+
unwanted_prefix = '_orig_mod.'
|
| 44 |
+
for k,v in list(state_dict.items()):
|
| 45 |
+
if k.startswith(unwanted_prefix):
|
| 46 |
+
state_dict[k[len(unwanted_prefix):]] = state_dict.pop(k)
|
| 47 |
+
model.load_state_dict(state_dict)
|
| 48 |
+
elif init_from.startswith('gpt2'):
|
| 49 |
+
# init from a given GPT-2 model
|
| 50 |
+
model = GPT.from_pretrained(init_from, dict(dropout=0.0))
|
| 51 |
+
elif init_from.startswith("RWKV"):
|
| 52 |
+
model = RWKV.from_pretrained(init_from,use_customized_cuda_kernel=False,dtype=dtype)
|
| 53 |
+
model.scale_parameters()
|
| 54 |
+
|
| 55 |
+
model.eval()
|
| 56 |
+
model.to(device)
|
| 57 |
+
if compile:
|
| 58 |
+
model = torch.compile(model) # requires PyTorch 2.0 (optional)
|
| 59 |
+
|
| 60 |
+
# look for the meta pickle in case it is available in the dataset folder
|
| 61 |
+
load_meta = False
|
| 62 |
+
if init_from == 'resume' and 'config' in checkpoint and 'dataset' in checkpoint['config']: # older checkpoints might not have these...
|
| 63 |
+
meta_path = os.path.join('data', checkpoint['config']['dataset'], 'meta.pkl')
|
| 64 |
+
load_meta = os.path.exists(meta_path)
|
| 65 |
+
if load_meta:
|
| 66 |
+
print(f"Loading meta from {meta_path}...")
|
| 67 |
+
with open(meta_path, 'rb') as f:
|
| 68 |
+
meta = pickle.load(f)
|
| 69 |
+
# TODO want to make this more general to arbitrary encoder/decoder schemes
|
| 70 |
+
stoi, itos = meta['stoi'], meta['itos']
|
| 71 |
+
encode = lambda s: [stoi[c] for c in s]
|
| 72 |
+
decode = lambda l: ''.join([itos[i] for i in l])
|
| 73 |
+
elif init_from.startswith("gpt2"):
|
| 74 |
+
# ok let's assume gpt-2 encodings by default
|
| 75 |
+
print("No meta.pkl found, assuming GPT-2 encodings...")
|
| 76 |
+
enc = tiktoken.get_encoding("gpt2")
|
| 77 |
+
encode = lambda s: enc.encode(s, allowed_special={"<|endoftext|>"})
|
| 78 |
+
decode = lambda l: enc.decode(l)
|
| 79 |
+
elif init_from.startswith("RWKV"):
|
| 80 |
+
print("No meta.pkl found, assuming RWKV encodings...")
|
| 81 |
+
from transformers import AutoTokenizer
|
| 82 |
+
os.environ["TOKENIZERS_PARALLELISM"] = "false"
|
| 83 |
+
toker = AutoTokenizer.from_pretrained(init_from)
|
| 84 |
+
encode = lambda s:toker.encode(s)
|
| 85 |
+
decode = lambda s:toker.decode(s)
|
| 86 |
+
|
| 87 |
+
# encode the beginning of the prompt
|
| 88 |
+
if start.startswith('FILE:'):
|
| 89 |
+
with open(start[5:], 'r', encoding='utf-8') as f:
|
| 90 |
+
start = f.read()
|
| 91 |
+
start_ids = encode(start)
|
| 92 |
+
x = (torch.tensor(start_ids, dtype=torch.long, device=device)[None, ...])
|
| 93 |
+
# x = torch.tensor(start_ids, dtype=torch.long, device=device)[None, ...].repeat(12,1)
|
| 94 |
+
|
| 95 |
+
# run generation
|
| 96 |
+
with torch.no_grad():
|
| 97 |
+
with ctx:
|
| 98 |
+
for k in range(num_samples):
|
| 99 |
+
y = model.generate(x, max_new_tokens, temperature=temperature, top_k=top_k)
|
| 100 |
+
print(decode(y[0].tolist()))
|
| 101 |
+
print('---------------')
|
scaling_laws.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
train.py
ADDED
|
@@ -0,0 +1,363 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
This training script can be run both on a single gpu in debug mode,
|
| 3 |
+
and also in a larger training run with distributed data parallel (ddp).
|
| 4 |
+
|
| 5 |
+
To run on a single GPU, example:
|
| 6 |
+
$ python train.py --batch_size=32 --compile=False
|
| 7 |
+
|
| 8 |
+
To run with DDP on 4 gpus on 1 node, example:
|
| 9 |
+
$ torchrun --standalone --nproc_per_node=4 train.py
|
| 10 |
+
|
| 11 |
+
To run with DDP on 4 gpus across 2 nodes, example:
|
| 12 |
+
- Run on the first (master) node with example IP 123.456.123.456:
|
| 13 |
+
$ torchrun --nproc_per_node=8 --nnodes=2 --node_rank=0 --master_addr=123.456.123.456 --master_port=1234 train.py
|
| 14 |
+
- Run on the worker node:
|
| 15 |
+
$ torchrun --nproc_per_node=8 --nnodes=2 --node_rank=1 --master_addr=123.456.123.456 --master_port=1234 train.py
|
| 16 |
+
(If your cluster does not have Infiniband interconnect prepend NCCL_IB_DISABLE=1)
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
import os
|
| 20 |
+
import time
|
| 21 |
+
import math,json
|
| 22 |
+
import pickle
|
| 23 |
+
from contextlib import nullcontext
|
| 24 |
+
import tiktoken
|
| 25 |
+
|
| 26 |
+
import numpy as np
|
| 27 |
+
import torch
|
| 28 |
+
from torch.nn.parallel import DistributedDataParallel as DDP
|
| 29 |
+
from torch.distributed import init_process_group, destroy_process_group
|
| 30 |
+
|
| 31 |
+
from modeling_gpt import GPTConfig, GPT
|
| 32 |
+
from modeling_rwkv import RWKVConfig,RWKV
|
| 33 |
+
from transformers import AutoTokenizer
|
| 34 |
+
os.environ["TOKENIZERS_PARALLELISM"] = "false"
|
| 35 |
+
# -----------------------------------------------------------------------------
|
| 36 |
+
# default config values designed to train a gpt2 (124M) on OpenWebText
|
| 37 |
+
# I/O
|
| 38 |
+
out_dir = 'out'
|
| 39 |
+
eval_interval = 2000
|
| 40 |
+
log_interval = 1
|
| 41 |
+
eval_iters = 200
|
| 42 |
+
eval_only = False # if True, script exits right after the first eval
|
| 43 |
+
always_save_checkpoint = True # if True, always save a checkpoint after each eval
|
| 44 |
+
init_from = 'scratch' # 'scratch' or 'resume' or 'gpt2*'
|
| 45 |
+
# wandb logging
|
| 46 |
+
wandb_log = False # disabled by default
|
| 47 |
+
wandb_project = 'owt'
|
| 48 |
+
wandb_run_name = 'gpt2' # 'run' + str(time.time())
|
| 49 |
+
# data
|
| 50 |
+
dataset = 'openwebtext'
|
| 51 |
+
gradient_accumulation_steps = 5 * 8 # used to simulate larger batch sizes
|
| 52 |
+
batch_size = 12 # if gradient_accumulation_steps > 1, this is the micro-batch size
|
| 53 |
+
block_size = 1024
|
| 54 |
+
# model
|
| 55 |
+
n_layer = 12
|
| 56 |
+
n_head = 12
|
| 57 |
+
n_embd = 768
|
| 58 |
+
dropout = 0.0 # for pretraining 0 is good, for finetuning try 0.1+
|
| 59 |
+
bias = False # do we use bias inside LayerNorm and Linear layers?
|
| 60 |
+
# adamw optimizer
|
| 61 |
+
learning_rate = 6e-4 # max learning rate
|
| 62 |
+
max_iters = 600000 # total number of training iterations
|
| 63 |
+
weight_decay = 1e-1
|
| 64 |
+
beta1 = 0.9
|
| 65 |
+
beta2 = 0.95
|
| 66 |
+
grad_clip = 1.0 # clip gradients at this value, or disable if == 0.0
|
| 67 |
+
# learning rate decay settings
|
| 68 |
+
decay_lr = True # whether to decay the learning rate
|
| 69 |
+
warmup_iters = 2000 # how many steps to warm up for
|
| 70 |
+
lr_decay_iters = 600000 # should be ~= max_iters per Chinchilla
|
| 71 |
+
min_lr = 6e-5 # minimum learning rate, should be ~= learning_rate/10 per Chinchilla
|
| 72 |
+
# DDP settings
|
| 73 |
+
backend = 'nccl' # 'nccl', 'gloo', etc.
|
| 74 |
+
# system
|
| 75 |
+
device = 'cuda' # examples: 'cpu', 'cuda', 'cuda:0', 'cuda:1' etc., or try 'mps' on macbooks
|
| 76 |
+
dtype = 'bfloat16' if torch.cuda.is_bf16_supported() else 'float16' # 'float32', 'bfloat16', or 'float16', the latter will auto implement a GradScaler
|
| 77 |
+
compile = True # use PyTorch 2.0 to compile the model to be faster
|
| 78 |
+
# model
|
| 79 |
+
model_type = 'gpt'
|
| 80 |
+
use_customized_cuda_kernel = True
|
| 81 |
+
# -----------------------------------------------------------------------------
|
| 82 |
+
config_keys = [k for k,v in globals().items() if not k.startswith('_') and isinstance(v, (int, float, bool, str))]
|
| 83 |
+
exec(open('configurator.py').read()) # overrides from command line or config file
|
| 84 |
+
config = {k: globals()[k] for k in config_keys} # will be useful for logging
|
| 85 |
+
print(json.dumps(config,indent=4))
|
| 86 |
+
# -----------------------------------------------------------------------------
|
| 87 |
+
|
| 88 |
+
# various inits, derived attributes, I/O setup
|
| 89 |
+
ddp = int(os.environ.get('RANK', -1)) != -1 # is this a ddp run?
|
| 90 |
+
if ddp:
|
| 91 |
+
init_process_group(backend=backend)
|
| 92 |
+
ddp_rank = int(os.environ['RANK'])
|
| 93 |
+
ddp_local_rank = int(os.environ['LOCAL_RANK'])
|
| 94 |
+
ddp_world_size = int(os.environ['WORLD_SIZE'])
|
| 95 |
+
device = f'cuda:{ddp_local_rank}'
|
| 96 |
+
torch.cuda.set_device(device)
|
| 97 |
+
master_process = ddp_rank == 0 # this process will do logging, checkpointing etc.
|
| 98 |
+
seed_offset = ddp_rank # each process gets a different seed
|
| 99 |
+
# world_size number of processes will be training simultaneously, so we can scale
|
| 100 |
+
# down the desired gradient accumulation iterations per process proportionally
|
| 101 |
+
assert gradient_accumulation_steps % ddp_world_size == 0
|
| 102 |
+
gradient_accumulation_steps //= ddp_world_size
|
| 103 |
+
else:
|
| 104 |
+
# if not ddp, we are running on a single gpu, and one process
|
| 105 |
+
master_process = True
|
| 106 |
+
seed_offset = 0
|
| 107 |
+
ddp_world_size = 1
|
| 108 |
+
tokens_per_iter = gradient_accumulation_steps * ddp_world_size * batch_size * block_size
|
| 109 |
+
print(f"tokens per iteration will be: {tokens_per_iter:,}")
|
| 110 |
+
|
| 111 |
+
if master_process:
|
| 112 |
+
os.makedirs(out_dir, exist_ok=True)
|
| 113 |
+
torch.manual_seed(1337 + seed_offset)
|
| 114 |
+
torch.backends.cuda.matmul.allow_tf32 = True # allow tf32 on matmul
|
| 115 |
+
torch.backends.cudnn.allow_tf32 = True # allow tf32 on cudnn
|
| 116 |
+
device_type = 'cuda' if 'cuda' in device else 'cpu' # for later use in torch.autocast
|
| 117 |
+
# note: float16 data type will automatically use a GradScaler
|
| 118 |
+
ptdtype = {'float32': torch.float32, 'bfloat16': torch.bfloat16, 'float16': torch.float16}[dtype]
|
| 119 |
+
ctx = nullcontext() if device_type == 'cpu' else torch.amp.autocast(device_type=device_type, dtype=ptdtype)
|
| 120 |
+
|
| 121 |
+
# poor man's data loader
|
| 122 |
+
data_dir = os.path.join('data', dataset)
|
| 123 |
+
train_data = np.memmap(os.path.join(data_dir, 'train.bin'), dtype=np.uint16, mode='r')
|
| 124 |
+
val_data = np.memmap(os.path.join(data_dir, 'val.bin'), dtype=np.uint16, mode='r')
|
| 125 |
+
def get_batch(split):
|
| 126 |
+
data = train_data if split == 'train' else val_data
|
| 127 |
+
ix = torch.randint(len(data) - block_size, (batch_size,))
|
| 128 |
+
|
| 129 |
+
x = [torch.from_numpy((data[i:i+block_size]).astype(np.int64)) for i in ix]
|
| 130 |
+
y = [torch.from_numpy((data[i+1:i+1+block_size]).astype(np.int64)) for i in ix]
|
| 131 |
+
|
| 132 |
+
x = torch.stack(x)
|
| 133 |
+
y = torch.stack(y)
|
| 134 |
+
|
| 135 |
+
if device_type == 'cuda':
|
| 136 |
+
# pin arrays x,y, which allows us to move them to GPU asynchronously (non_blocking=True)
|
| 137 |
+
x, y = x.pin_memory().to(device, non_blocking=True), y.pin_memory().to(device, non_blocking=True)
|
| 138 |
+
else:
|
| 139 |
+
x, y = x.to(device), y.to(device)
|
| 140 |
+
return x, y
|
| 141 |
+
|
| 142 |
+
# init these up here, can override if init_from='resume' (i.e. from a checkpoint)
|
| 143 |
+
iter_num = 0
|
| 144 |
+
best_val_loss = 1e9
|
| 145 |
+
|
| 146 |
+
# attempt to derive vocab_size from the dataset
|
| 147 |
+
meta_path = os.path.join(data_dir, 'meta.pkl')
|
| 148 |
+
meta_vocab_size = None
|
| 149 |
+
if os.path.exists(meta_path):
|
| 150 |
+
with open(meta_path, 'rb') as f:
|
| 151 |
+
meta = pickle.load(f)
|
| 152 |
+
meta_vocab_size = meta['vocab_size']
|
| 153 |
+
print(f"found vocab_size = {meta_vocab_size} (inside {meta_path})")
|
| 154 |
+
|
| 155 |
+
# model init
|
| 156 |
+
if model_type == 'gpt':
|
| 157 |
+
LLM = GPT
|
| 158 |
+
LLMConfig = GPTConfig
|
| 159 |
+
model_args = dict(n_layer=n_layer, n_head=n_head, n_embd=n_embd, block_size=block_size,
|
| 160 |
+
bias=bias, vocab_size=None, dropout=dropout) # start with model_args from command line
|
| 161 |
+
elif model_type == 'rwkv':
|
| 162 |
+
LLM = RWKV
|
| 163 |
+
LLMConfig = RWKVConfig
|
| 164 |
+
model_args = dict(n_layer=n_layer, n_embd=n_embd, block_size=block_size,
|
| 165 |
+
bias=bias, vocab_size=None, dtype=dtype,use_customized_cuda_kernel=use_customized_cuda_kernel) # start with model_args from command line
|
| 166 |
+
|
| 167 |
+
if init_from == 'scratch':
|
| 168 |
+
# init a new model from scratch
|
| 169 |
+
print("Initializing a new model from scratch")
|
| 170 |
+
# determine the vocab size we'll use for from-scratch training
|
| 171 |
+
if meta_vocab_size is None:
|
| 172 |
+
print("defaulting to vocab_size of GPT-2 to 50304 (50257 rounded up for efficiency)")
|
| 173 |
+
model_args['vocab_size'] = meta_vocab_size if meta_vocab_size is not None else 50304
|
| 174 |
+
model = LLM(LLMConfig(**model_args))
|
| 175 |
+
elif init_from == 'resume':
|
| 176 |
+
print(f"Resuming training from {out_dir}")
|
| 177 |
+
# resume training from a checkpoint.
|
| 178 |
+
ckpt_path = os.path.join(out_dir, 'ckpt.pt')
|
| 179 |
+
checkpoint = torch.load(ckpt_path, map_location=device)
|
| 180 |
+
checkpoint_model_args = checkpoint['model_args']
|
| 181 |
+
# force these config attributes to be equal otherwise we can't even resume training
|
| 182 |
+
# the rest of the attributes (e.g. dropout) can stay as desired from command line
|
| 183 |
+
for k in ['n_layer', 'n_head', 'n_embd', 'block_size', 'bias', 'vocab_size']:
|
| 184 |
+
model_args[k] = checkpoint_model_args[k]
|
| 185 |
+
# create the model
|
| 186 |
+
gptconf = GPTConfig(**model_args)
|
| 187 |
+
model = GPT(gptconf)
|
| 188 |
+
state_dict = checkpoint['model']
|
| 189 |
+
# fix the keys of the state dictionary :(
|
| 190 |
+
# honestly no idea how checkpoints sometimes get this prefix, have to debug more
|
| 191 |
+
unwanted_prefix = '_orig_mod.'
|
| 192 |
+
for k,v in list(state_dict.items()):
|
| 193 |
+
if k.startswith(unwanted_prefix):
|
| 194 |
+
state_dict[k[len(unwanted_prefix):]] = state_dict.pop(k)
|
| 195 |
+
model.load_state_dict(state_dict)
|
| 196 |
+
iter_num = checkpoint['iter_num']
|
| 197 |
+
best_val_loss = checkpoint['best_val_loss']
|
| 198 |
+
elif init_from.startswith('gpt2'):
|
| 199 |
+
print(f"Initializing from OpenAI GPT-2 weights: {init_from}")
|
| 200 |
+
# initialize from OpenAI GPT-2 weights
|
| 201 |
+
override_args = dict(dropout=dropout)
|
| 202 |
+
model = GPT.from_pretrained(init_from, override_args)
|
| 203 |
+
# read off the created config params, so we can store them into checkpoint correctly
|
| 204 |
+
for k in ['n_layer', 'n_head', 'n_embd', 'block_size', 'bias', 'vocab_size']:
|
| 205 |
+
model_args[k] = getattr(model.config, k)
|
| 206 |
+
|
| 207 |
+
elif init_from.startswith('RWKV'):
|
| 208 |
+
model = RWKV.from_pretrained(init_from,dtype=dtype,use_customized_cuda_kernel=use_customized_cuda_kernel)
|
| 209 |
+
enc = tiktoken.get_encoding("gpt2")
|
| 210 |
+
val_data_text = enc.decode(val_data)
|
| 211 |
+
toker = AutoTokenizer.from_pretrained(init_from)
|
| 212 |
+
val_data_rwkv = np.array(toker.encode(val_data_text))
|
| 213 |
+
val_data = val_data_rwkv
|
| 214 |
+
|
| 215 |
+
|
| 216 |
+
# crop down the model block size if desired, using model surgery
|
| 217 |
+
if block_size < model.config.block_size:
|
| 218 |
+
model.crop_block_size(block_size)
|
| 219 |
+
model_args['block_size'] = block_size # so that the checkpoint will have the right value
|
| 220 |
+
model.to(device)
|
| 221 |
+
|
| 222 |
+
# initialize a GradScaler. If enabled=False scaler is a no-op
|
| 223 |
+
scaler = torch.cuda.amp.GradScaler(enabled=(dtype == 'float16'))
|
| 224 |
+
|
| 225 |
+
# optimizer
|
| 226 |
+
optimizer = model.configure_optimizers(weight_decay, learning_rate, (beta1, beta2), device_type)
|
| 227 |
+
if init_from == 'resume':
|
| 228 |
+
optimizer.load_state_dict(checkpoint['optimizer'])
|
| 229 |
+
checkpoint = None # free up memory
|
| 230 |
+
|
| 231 |
+
# compile the model
|
| 232 |
+
if compile:
|
| 233 |
+
print("compiling the model... (takes a ~minute)")
|
| 234 |
+
unoptimized_model = model
|
| 235 |
+
model = torch.compile(model) # requires PyTorch 2.0
|
| 236 |
+
|
| 237 |
+
# wrap model into DDP container
|
| 238 |
+
if ddp:
|
| 239 |
+
model = DDP(model, device_ids=[ddp_local_rank])
|
| 240 |
+
|
| 241 |
+
# helps estimate an arbitrarily accurate loss over either split using many batches
|
| 242 |
+
@torch.no_grad()
|
| 243 |
+
def estimate_loss():
|
| 244 |
+
out = {}
|
| 245 |
+
model.eval()
|
| 246 |
+
for split in ['train', 'val']:
|
| 247 |
+
losses = torch.zeros(eval_iters)
|
| 248 |
+
for k in range(eval_iters):
|
| 249 |
+
X, Y = get_batch(split)
|
| 250 |
+
with ctx:
|
| 251 |
+
logits, loss = model(X, Y)
|
| 252 |
+
losses[k] = loss.item()
|
| 253 |
+
out[split] = losses.mean()
|
| 254 |
+
model.train()
|
| 255 |
+
return out
|
| 256 |
+
|
| 257 |
+
# learning rate decay scheduler (cosine with warmup)
|
| 258 |
+
def get_lr(it):
|
| 259 |
+
# 1) linear warmup for warmup_iters steps
|
| 260 |
+
if it < warmup_iters:
|
| 261 |
+
return learning_rate * it / warmup_iters
|
| 262 |
+
# 2) if it > lr_decay_iters, return min learning rate
|
| 263 |
+
if it > lr_decay_iters:
|
| 264 |
+
return min_lr
|
| 265 |
+
# 3) in between, use cosine decay down to min learning rate
|
| 266 |
+
decay_ratio = (it - warmup_iters) / (lr_decay_iters - warmup_iters)
|
| 267 |
+
assert 0 <= decay_ratio <= 1
|
| 268 |
+
coeff = 0.5 * (1.0 + math.cos(math.pi * decay_ratio)) # coeff ranges 0..1
|
| 269 |
+
return min_lr + coeff * (learning_rate - min_lr)
|
| 270 |
+
|
| 271 |
+
# logging
|
| 272 |
+
if wandb_log and master_process:
|
| 273 |
+
import wandb
|
| 274 |
+
wandb.init(project=wandb_project, name=wandb_run_name, config=config)
|
| 275 |
+
|
| 276 |
+
# training loop
|
| 277 |
+
X, Y = get_batch('train') # fetch the very first batch
|
| 278 |
+
t0 = time.time()
|
| 279 |
+
local_iter_num = 0 # number of iterations in the lifetime of this process
|
| 280 |
+
raw_model = model.module if ddp else model # unwrap DDP container if needed
|
| 281 |
+
running_mfu = -1.0
|
| 282 |
+
while True:
|
| 283 |
+
|
| 284 |
+
# determine and set the learning rate for this iteration
|
| 285 |
+
lr = get_lr(iter_num) if decay_lr else learning_rate
|
| 286 |
+
for param_group in optimizer.param_groups:
|
| 287 |
+
param_group['lr'] = lr
|
| 288 |
+
|
| 289 |
+
# evaluate the loss on train/val sets and write checkpoints
|
| 290 |
+
if iter_num % eval_interval == 0 and master_process:
|
| 291 |
+
losses = estimate_loss()
|
| 292 |
+
print(f"step {iter_num}: train loss {losses['train']:.4f}, val loss {losses['val']:.4f}")
|
| 293 |
+
if wandb_log:
|
| 294 |
+
wandb.log({
|
| 295 |
+
"iter": iter_num,
|
| 296 |
+
"train/loss": losses['train'],
|
| 297 |
+
"val/loss": losses['val'],
|
| 298 |
+
"lr": lr,
|
| 299 |
+
"mfu": running_mfu*100, # convert to percentage
|
| 300 |
+
})
|
| 301 |
+
if losses['val'] < best_val_loss or always_save_checkpoint:
|
| 302 |
+
best_val_loss = losses['val']
|
| 303 |
+
if iter_num > 0:
|
| 304 |
+
checkpoint = {
|
| 305 |
+
'model': raw_model.state_dict(),
|
| 306 |
+
'optimizer': optimizer.state_dict(),
|
| 307 |
+
'model_args': model_args,
|
| 308 |
+
'iter_num': iter_num,
|
| 309 |
+
'best_val_loss': best_val_loss,
|
| 310 |
+
'config': config,
|
| 311 |
+
}
|
| 312 |
+
print(f"saving checkpoint to {out_dir}")
|
| 313 |
+
torch.save(checkpoint, os.path.join(out_dir, 'ckpt.pt'))
|
| 314 |
+
if iter_num == 0 and eval_only:
|
| 315 |
+
break
|
| 316 |
+
|
| 317 |
+
# forward backward update, with optional gradient accumulation to simulate larger batch size
|
| 318 |
+
# and using the GradScaler if data type is float16
|
| 319 |
+
for micro_step in range(gradient_accumulation_steps):
|
| 320 |
+
if ddp:
|
| 321 |
+
# in DDP training we only need to sync gradients at the last micro step.
|
| 322 |
+
# the official way to do this is with model.no_sync() context manager, but
|
| 323 |
+
# I really dislike that this bloats the code and forces us to repeat code
|
| 324 |
+
# looking at the source of that context manager, it just toggles this variable
|
| 325 |
+
model.require_backward_grad_sync = (micro_step == gradient_accumulation_steps - 1)
|
| 326 |
+
with ctx:
|
| 327 |
+
logits, loss = model(X, Y)
|
| 328 |
+
loss = loss / gradient_accumulation_steps # scale the loss to account for gradient accumulation
|
| 329 |
+
# immediately async prefetch next batch while model is doing the forward pass on the GPU
|
| 330 |
+
X, Y = get_batch('train')
|
| 331 |
+
# backward pass, with gradient scaling if training in fp16
|
| 332 |
+
scaler.scale(loss).backward()
|
| 333 |
+
# clip the gradient
|
| 334 |
+
if grad_clip != 0.0:
|
| 335 |
+
scaler.unscale_(optimizer)
|
| 336 |
+
torch.nn.utils.clip_grad_norm_(model.parameters(), grad_clip)
|
| 337 |
+
# step the optimizer and scaler if training in fp16
|
| 338 |
+
scaler.step(optimizer)
|
| 339 |
+
scaler.update()
|
| 340 |
+
# flush the gradients as soon as we can, no need for this memory anymore
|
| 341 |
+
optimizer.zero_grad(set_to_none=True)
|
| 342 |
+
|
| 343 |
+
# timing and logging
|
| 344 |
+
t1 = time.time()
|
| 345 |
+
dt = t1 - t0
|
| 346 |
+
t0 = t1
|
| 347 |
+
if iter_num % log_interval == 0 and master_process:
|
| 348 |
+
# get loss as float. note: this is a CPU-GPU sync point
|
| 349 |
+
# scale up to undo the division above, approximating the true total loss (exact would have been a sum)
|
| 350 |
+
lossf = loss.item() * gradient_accumulation_steps
|
| 351 |
+
if local_iter_num >= 5: # let the training loop settle a bit
|
| 352 |
+
mfu = raw_model.estimate_mfu(batch_size * gradient_accumulation_steps, dt)
|
| 353 |
+
running_mfu = mfu if running_mfu == -1.0 else 0.9*running_mfu + 0.1*mfu
|
| 354 |
+
print(f"iter {iter_num}: loss {lossf:.4f}, time {dt*1000:.2f}ms, mfu {running_mfu*100:.2f}%")
|
| 355 |
+
iter_num += 1
|
| 356 |
+
local_iter_num += 1
|
| 357 |
+
|
| 358 |
+
# termination conditions
|
| 359 |
+
if iter_num > max_iters:
|
| 360 |
+
break
|
| 361 |
+
|
| 362 |
+
if ddp:
|
| 363 |
+
destroy_process_group()
|
transformer_sizing.ipynb
ADDED
|
@@ -0,0 +1,402 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"attachments": {},
|
| 5 |
+
"cell_type": "markdown",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"### Transformer Theoretical Model\n",
|
| 9 |
+
"\n",
|
| 10 |
+
"This notebook stores a bunch of analysis about a Transformer, e.g. estimates the number of FLOPs, parameters, peak memory footprint, checkpoint size, etc."
|
| 11 |
+
]
|
| 12 |
+
},
|
| 13 |
+
{
|
| 14 |
+
"cell_type": "code",
|
| 15 |
+
"execution_count": 1,
|
| 16 |
+
"metadata": {},
|
| 17 |
+
"outputs": [],
|
| 18 |
+
"source": [
|
| 19 |
+
"from collections import OrderedDict"
|
| 20 |
+
]
|
| 21 |
+
},
|
| 22 |
+
{
|
| 23 |
+
"cell_type": "code",
|
| 24 |
+
"execution_count": 2,
|
| 25 |
+
"metadata": {},
|
| 26 |
+
"outputs": [],
|
| 27 |
+
"source": [
|
| 28 |
+
"# config_args = {\n",
|
| 29 |
+
"# 'gpt2': dict(n_layer=12, n_head=12, n_embd=768), # 124M params\n",
|
| 30 |
+
"# 'gpt2-medium': dict(n_layer=24, n_head=16, n_embd=1024), # 350M params\n",
|
| 31 |
+
"# 'gpt2-large': dict(n_layer=36, n_head=20, n_embd=1280), # 774M params\n",
|
| 32 |
+
"# 'gpt2-xl': dict(n_layer=48, n_head=25, n_embd=1600), # 1558M params\n",
|
| 33 |
+
"# }[model_type]\n",
|
| 34 |
+
"\n",
|
| 35 |
+
"block_size = 1024\n",
|
| 36 |
+
"vocab_size = 50257\n",
|
| 37 |
+
"n_layer = 12\n",
|
| 38 |
+
"n_head = 12\n",
|
| 39 |
+
"n_embd = 768\n",
|
| 40 |
+
"bias = False\n",
|
| 41 |
+
"assert not bias, \"this notebook assumes bias=False just for simplicity\""
|
| 42 |
+
]
|
| 43 |
+
},
|
| 44 |
+
{
|
| 45 |
+
"cell_type": "code",
|
| 46 |
+
"execution_count": 3,
|
| 47 |
+
"metadata": {},
|
| 48 |
+
"outputs": [
|
| 49 |
+
{
|
| 50 |
+
"name": "stdout",
|
| 51 |
+
"output_type": "stream",
|
| 52 |
+
"text": [
|
| 53 |
+
"we see: 124337664, expected: 124337664, match: True\n",
|
| 54 |
+
"name params ratio (%) \n",
|
| 55 |
+
"emebedding/position 786432 0.6325\n",
|
| 56 |
+
"embedding/token 38597376 31.0424\n",
|
| 57 |
+
"embedding 39383808 31.6749\n",
|
| 58 |
+
"attention/ln 768 0.0006\n",
|
| 59 |
+
"attention/kqv 1769472 1.4231\n",
|
| 60 |
+
"attention/proj 589824 0.4744\n",
|
| 61 |
+
"attention 2360064 1.8981\n",
|
| 62 |
+
"mlp/ln 768 0.0006\n",
|
| 63 |
+
"mlp/ffw 2359296 1.8975\n",
|
| 64 |
+
"mlp/proj 2359296 1.8975\n",
|
| 65 |
+
"mlp 4719360 3.7956\n",
|
| 66 |
+
"block 7079424 5.6937\n",
|
| 67 |
+
"transformer 84953088 68.3245\n",
|
| 68 |
+
"ln_f 768 0.0006\n",
|
| 69 |
+
"dense 0 0.0000\n",
|
| 70 |
+
"total 124337664 100.0000\n"
|
| 71 |
+
]
|
| 72 |
+
}
|
| 73 |
+
],
|
| 74 |
+
"source": [
|
| 75 |
+
"def params():\n",
|
| 76 |
+
" \"\"\" estimates the number of parameters in the model\"\"\"\n",
|
| 77 |
+
" out = OrderedDict()\n",
|
| 78 |
+
"\n",
|
| 79 |
+
" # token and position embeddings\n",
|
| 80 |
+
" out['emebedding/position'] = n_embd * block_size\n",
|
| 81 |
+
" out['embedding/token'] = n_embd * vocab_size\n",
|
| 82 |
+
" out['embedding'] = out['emebedding/position'] + out['embedding/token']\n",
|
| 83 |
+
"\n",
|
| 84 |
+
" # attention blocks\n",
|
| 85 |
+
" out['attention/ln'] = n_embd # note, bias=False in our LN\n",
|
| 86 |
+
" out['attention/kqv'] = n_embd * 3*n_embd\n",
|
| 87 |
+
" out['attention/proj'] = n_embd**2\n",
|
| 88 |
+
" out['attention'] = out['attention/ln'] + out['attention/kqv'] + out['attention/proj']\n",
|
| 89 |
+
"\n",
|
| 90 |
+
" # MLP blocks\n",
|
| 91 |
+
" ffw_size = 4*n_embd # feed forward size\n",
|
| 92 |
+
" out['mlp/ln'] = n_embd\n",
|
| 93 |
+
" out['mlp/ffw'] = n_embd * ffw_size\n",
|
| 94 |
+
" out['mlp/proj'] = ffw_size * n_embd\n",
|
| 95 |
+
" out['mlp'] = out['mlp/ln'] + out['mlp/ffw'] + out['mlp/proj']\n",
|
| 96 |
+
" \n",
|
| 97 |
+
" # the transformer and the rest of it\n",
|
| 98 |
+
" out['block'] = out['attention'] + out['mlp']\n",
|
| 99 |
+
" out['transformer'] = n_layer * out['block']\n",
|
| 100 |
+
" out['ln_f'] = n_embd # final layernorm\n",
|
| 101 |
+
" out['dense'] = 0 # 0 because of parameter sharing. This layer uses the weights from the embedding layer\n",
|
| 102 |
+
"\n",
|
| 103 |
+
" # total\n",
|
| 104 |
+
" out['total'] = out['embedding'] + out['transformer'] + out['ln_f'] + out['dense']\n",
|
| 105 |
+
"\n",
|
| 106 |
+
" return out\n",
|
| 107 |
+
"\n",
|
| 108 |
+
"# compare our param count to that reported by PyTorch\n",
|
| 109 |
+
"p = params()\n",
|
| 110 |
+
"params_total = p['total']\n",
|
| 111 |
+
"print(f\"we see: {params_total}, expected: {124337664}, match: {params_total == 124337664}\")\n",
|
| 112 |
+
"# create a header\n",
|
| 113 |
+
"print(f\"{'name':20s} {'params':10s} {'ratio (%)':10s}\")\n",
|
| 114 |
+
"for k,v in p.items():\n",
|
| 115 |
+
" print(f\"{k:20s} {v:10d} {v/params_total*100:10.4f}\")\n",
|
| 116 |
+
" "
|
| 117 |
+
]
|
| 118 |
+
},
|
| 119 |
+
{
|
| 120 |
+
"cell_type": "code",
|
| 121 |
+
"execution_count": 4,
|
| 122 |
+
"metadata": {},
|
| 123 |
+
"outputs": [
|
| 124 |
+
{
|
| 125 |
+
"name": "stdout",
|
| 126 |
+
"output_type": "stream",
|
| 127 |
+
"text": [
|
| 128 |
+
"est checkpoint size: 1.49 GB\n",
|
| 129 |
+
"measured with wc -c ckpt.pt: 1542470366\n",
|
| 130 |
+
"fluff ratio: 103.38%\n"
|
| 131 |
+
]
|
| 132 |
+
}
|
| 133 |
+
],
|
| 134 |
+
"source": [
|
| 135 |
+
"# we can now calculate the size of each checkpoint\n",
|
| 136 |
+
"# params are stored in fp32, and the AdamW optimizer has 2 additional buffers per param for statistics\n",
|
| 137 |
+
"params_bytes = params_total*4\n",
|
| 138 |
+
"params_and_buffers_bytes = params_bytes + 2*params_bytes\n",
|
| 139 |
+
"print(f\"est checkpoint size: {params_and_buffers_bytes/1e9:.2f} GB\")\n",
|
| 140 |
+
"measured_bytes = 1542470366 # from wc -c ckpt.pt\n",
|
| 141 |
+
"print(f\"measured with wc -c ckpt.pt: {measured_bytes}\")\n",
|
| 142 |
+
"print(f\"fluff ratio: {measured_bytes/params_and_buffers_bytes*100:.2f}%\")"
|
| 143 |
+
]
|
| 144 |
+
},
|
| 145 |
+
{
|
| 146 |
+
"attachments": {},
|
| 147 |
+
"cell_type": "markdown",
|
| 148 |
+
"metadata": {},
|
| 149 |
+
"source": [
|
| 150 |
+
"We can also estimate the ratio of our GPU memory that will be taken up just by the weights and the buffers inside the AdamW optimizer"
|
| 151 |
+
]
|
| 152 |
+
},
|
| 153 |
+
{
|
| 154 |
+
"cell_type": "code",
|
| 155 |
+
"execution_count": 5,
|
| 156 |
+
"metadata": {},
|
| 157 |
+
"outputs": [
|
| 158 |
+
{
|
| 159 |
+
"name": "stdout",
|
| 160 |
+
"output_type": "stream",
|
| 161 |
+
"text": [
|
| 162 |
+
"memory ratio taken up just for parameters: 3.73%\n"
|
| 163 |
+
]
|
| 164 |
+
}
|
| 165 |
+
],
|
| 166 |
+
"source": [
|
| 167 |
+
"gpu_memory = 40e9 # 40 GB A100 GPU, roughly\n",
|
| 168 |
+
"print(f\"memory ratio taken up just for parameters: {params_and_buffers_bytes / gpu_memory * 100:.2f}%\")"
|
| 169 |
+
]
|
| 170 |
+
},
|
| 171 |
+
{
|
| 172 |
+
"attachments": {},
|
| 173 |
+
"cell_type": "markdown",
|
| 174 |
+
"metadata": {},
|
| 175 |
+
"source": [
|
| 176 |
+
"i.e. not that much of the memory for this tiny model, most of the memory is activations (forward and backward). This of course changes dramatically for larger and larger models."
|
| 177 |
+
]
|
| 178 |
+
},
|
| 179 |
+
{
|
| 180 |
+
"attachments": {},
|
| 181 |
+
"cell_type": "markdown",
|
| 182 |
+
"metadata": {},
|
| 183 |
+
"source": [
|
| 184 |
+
"Let's estimate FLOPs for a single forward pass."
|
| 185 |
+
]
|
| 186 |
+
},
|
| 187 |
+
{
|
| 188 |
+
"cell_type": "code",
|
| 189 |
+
"execution_count": 6,
|
| 190 |
+
"metadata": {},
|
| 191 |
+
"outputs": [
|
| 192 |
+
{
|
| 193 |
+
"name": "stdout",
|
| 194 |
+
"output_type": "stream",
|
| 195 |
+
"text": [
|
| 196 |
+
"name flops ratio (%) \n",
|
| 197 |
+
"attention/kqv 3623878656 1.2426\n",
|
| 198 |
+
"attention/scores 1610612736 0.5522\n",
|
| 199 |
+
"attention/reduce 1610612736 0.5522\n",
|
| 200 |
+
"attention/proj 1207959552 0.4142\n",
|
| 201 |
+
"attention 8053063680 2.7612\n",
|
| 202 |
+
"mlp/ffw1 4831838208 1.6567\n",
|
| 203 |
+
"mlp/ffw2 4831838208 1.6567\n",
|
| 204 |
+
"mlp 9663676416 3.3135\n",
|
| 205 |
+
"block 17716740096 6.0747\n",
|
| 206 |
+
"transformer 212600881152 72.8963\n",
|
| 207 |
+
"dense 79047426048 27.1037\n",
|
| 208 |
+
"forward_total 291648307200 100.0000\n",
|
| 209 |
+
"backward_total 583296614400 200.0000\n",
|
| 210 |
+
"total 874944921600 300.0000\n"
|
| 211 |
+
]
|
| 212 |
+
}
|
| 213 |
+
],
|
| 214 |
+
"source": [
|
| 215 |
+
"def flops():\n",
|
| 216 |
+
" # we only count Weight FLOPs, all other layers (LayerNorm, Softmax, etc) are effectively irrelevant\n",
|
| 217 |
+
" # we count actual FLOPs, not MACs. Hence 2* all over the place\n",
|
| 218 |
+
" # basically for any matrix multiply A (BxC) @ B (CxD) -> (BxD) flops are 2*B*C*D\n",
|
| 219 |
+
"\n",
|
| 220 |
+
" out = OrderedDict()\n",
|
| 221 |
+
" head_size = n_embd // n_head\n",
|
| 222 |
+
"\n",
|
| 223 |
+
" # attention blocks\n",
|
| 224 |
+
" # 1) the projection to key, query, values\n",
|
| 225 |
+
" out['attention/kqv'] = 2 * block_size * (n_embd * 3*n_embd)\n",
|
| 226 |
+
" # 2) calculating the attention scores\n",
|
| 227 |
+
" out['attention/scores'] = 2 * block_size * block_size * n_embd\n",
|
| 228 |
+
" # 3) the reduction of the values (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)\n",
|
| 229 |
+
" out['attention/reduce'] = 2 * n_head * (block_size * block_size * head_size)\n",
|
| 230 |
+
" # 4) the final linear projection\n",
|
| 231 |
+
" out['attention/proj'] = 2 * block_size * (n_embd * n_embd)\n",
|
| 232 |
+
" out['attention'] = sum(out['attention/'+k] for k in ['kqv', 'scores', 'reduce', 'proj'])\n",
|
| 233 |
+
"\n",
|
| 234 |
+
" # MLP blocks\n",
|
| 235 |
+
" ffw_size = 4*n_embd # feed forward size\n",
|
| 236 |
+
" out['mlp/ffw1'] = 2 * block_size * (n_embd * ffw_size)\n",
|
| 237 |
+
" out['mlp/ffw2'] = 2 * block_size * (ffw_size * n_embd)\n",
|
| 238 |
+
" out['mlp'] = out['mlp/ffw1'] + out['mlp/ffw2']\n",
|
| 239 |
+
"\n",
|
| 240 |
+
" # the transformer and the rest of it\n",
|
| 241 |
+
" out['block'] = out['attention'] + out['mlp']\n",
|
| 242 |
+
" out['transformer'] = n_layer * out['block']\n",
|
| 243 |
+
" out['dense'] = 2 * block_size * (n_embd * vocab_size)\n",
|
| 244 |
+
"\n",
|
| 245 |
+
" # forward,backward,total\n",
|
| 246 |
+
" out['forward_total'] = out['transformer'] + out['dense']\n",
|
| 247 |
+
" out['backward_total'] = 2 * out['forward_total'] # use common estimate of bwd = 2*fwd\n",
|
| 248 |
+
" out['total'] = out['forward_total'] + out['backward_total']\n",
|
| 249 |
+
"\n",
|
| 250 |
+
" return out\n",
|
| 251 |
+
" \n",
|
| 252 |
+
"# compare our param count to that reported by PyTorch\n",
|
| 253 |
+
"f = flops()\n",
|
| 254 |
+
"flops_total = f['forward_total']\n",
|
| 255 |
+
"print(f\"{'name':20s} {'flops':14s} {'ratio (%)':10s}\")\n",
|
| 256 |
+
"for k,v in f.items():\n",
|
| 257 |
+
" print(f\"{k:20s} {v:14d} {v/flops_total*100:10.4f}\")\n",
|
| 258 |
+
" "
|
| 259 |
+
]
|
| 260 |
+
},
|
| 261 |
+
{
|
| 262 |
+
"cell_type": "code",
|
| 263 |
+
"execution_count": 7,
|
| 264 |
+
"metadata": {},
|
| 265 |
+
"outputs": [
|
| 266 |
+
{
|
| 267 |
+
"name": "stdout",
|
| 268 |
+
"output_type": "stream",
|
| 269 |
+
"text": [
|
| 270 |
+
"palm_flops: 875062886400, flops: 874944921600, ratio: 1.0001\n"
|
| 271 |
+
]
|
| 272 |
+
}
|
| 273 |
+
],
|
| 274 |
+
"source": [
|
| 275 |
+
"# now here is an estimate copy pasted from the PaLM paper\n",
|
| 276 |
+
"# this formula is often used to calculate MFU (model flops utilization)\n",
|
| 277 |
+
"def palm_flops():\n",
|
| 278 |
+
" \"\"\"estimate of the model flops following PaLM paper formula\"\"\"\n",
|
| 279 |
+
" # non-embedding model parameters. note that we do not subtract the\n",
|
| 280 |
+
" # embedding/token params because those are tied and get used in the last layer.\n",
|
| 281 |
+
" N = params()['total'] - params()['emebedding/position']\n",
|
| 282 |
+
" L, H, Q, T = n_layer, n_head, n_embd//n_head, block_size\n",
|
| 283 |
+
" mf_per_token = 6*N + 12*L*H*Q*T\n",
|
| 284 |
+
" mf = mf_per_token * block_size\n",
|
| 285 |
+
" return mf\n",
|
| 286 |
+
"\n",
|
| 287 |
+
"print(f\"palm_flops: {palm_flops():d}, flops: {flops()['total']:d}, ratio: {palm_flops()/flops()['total']:.4f}\")"
|
| 288 |
+
]
|
| 289 |
+
},
|
| 290 |
+
{
|
| 291 |
+
"attachments": {},
|
| 292 |
+
"cell_type": "markdown",
|
| 293 |
+
"metadata": {},
|
| 294 |
+
"source": [
|
| 295 |
+
"Ok they are quite similar, giving some confidence that my math in flops() function was ~ok. Now, A100 is cited at 312TFLOPS bfloat16 on tensor cores. So what is our model flops utilization (MFU)? I trained the model above with a batch_size of 20 and grad_accum of 5, which runs in about 755ms on a single A100 GPU. We get:"
|
| 296 |
+
]
|
| 297 |
+
},
|
| 298 |
+
{
|
| 299 |
+
"cell_type": "code",
|
| 300 |
+
"execution_count": 8,
|
| 301 |
+
"metadata": {},
|
| 302 |
+
"outputs": [
|
| 303 |
+
{
|
| 304 |
+
"name": "stdout",
|
| 305 |
+
"output_type": "stream",
|
| 306 |
+
"text": [
|
| 307 |
+
"fraction of A100 used: 37.14%\n"
|
| 308 |
+
]
|
| 309 |
+
}
|
| 310 |
+
],
|
| 311 |
+
"source": [
|
| 312 |
+
"# here is what we currently roughly measure\n",
|
| 313 |
+
"batch_size = 20 * 5 # 5 is grad_accum, so total batch size is 100\n",
|
| 314 |
+
"measured_time = 0.755 # in seconds per iteration\n",
|
| 315 |
+
"measured_throughput = batch_size / measured_time\n",
|
| 316 |
+
"flops_achieved = f['total'] * measured_throughput\n",
|
| 317 |
+
"\n",
|
| 318 |
+
"# A100 is cited to be 312 TFLOPS of bloat16 running on tensor cores\n",
|
| 319 |
+
"a100_flops_promised = 312e12\n",
|
| 320 |
+
"\n",
|
| 321 |
+
"# the fraction of the A100 that we are using:\n",
|
| 322 |
+
"print(f\"fraction of A100 used: {flops_achieved / a100_flops_promised * 100:.2f}%\")"
|
| 323 |
+
]
|
| 324 |
+
},
|
| 325 |
+
{
|
| 326 |
+
"attachments": {},
|
| 327 |
+
"cell_type": "markdown",
|
| 328 |
+
"metadata": {},
|
| 329 |
+
"source": [
|
| 330 |
+
"For reference, we'd prefer to be somewhere around 50%+, and not just for a single GPU but for an entire DDP run. So we still have some work to do, but at least we're within a factor of ~2X of what is achievable with this GPU."
|
| 331 |
+
]
|
| 332 |
+
},
|
| 333 |
+
{
|
| 334 |
+
"cell_type": "code",
|
| 335 |
+
"execution_count": 9,
|
| 336 |
+
"metadata": {},
|
| 337 |
+
"outputs": [
|
| 338 |
+
{
|
| 339 |
+
"name": "stdout",
|
| 340 |
+
"output_type": "stream",
|
| 341 |
+
"text": [
|
| 342 |
+
"time needed to train the model: 3.46 days\n"
|
| 343 |
+
]
|
| 344 |
+
}
|
| 345 |
+
],
|
| 346 |
+
"source": [
|
| 347 |
+
"# Finally let's check out the 6ND approximation as total cost of training in FLOPs\n",
|
| 348 |
+
"model_size = params()['total'] # this is number of parameters, N\n",
|
| 349 |
+
"tokens_num = 300e9 # 300B tokens, this is dataset size in tokens, D\n",
|
| 350 |
+
"a100_flops = 312e12 # 312 TFLOPS\n",
|
| 351 |
+
"assumed_mfu = 0.3 # assume this model flops utilization (take the current 37% from above and add some DDP overhead)\n",
|
| 352 |
+
"flops_throughput = a100_flops * 8 * assumed_mfu # assume an 8XA100 node at 30% utilization\n",
|
| 353 |
+
"flops_needed = 6 * model_size * tokens_num # 6ND\n",
|
| 354 |
+
"time_needed_s = flops_needed / flops_throughput # in seconds\n",
|
| 355 |
+
"print(f\"time needed to train the model: {time_needed_s/3600/24:.2f} days\")"
|
| 356 |
+
]
|
| 357 |
+
},
|
| 358 |
+
{
|
| 359 |
+
"attachments": {},
|
| 360 |
+
"cell_type": "markdown",
|
| 361 |
+
"metadata": {},
|
| 362 |
+
"source": [
|
| 363 |
+
"This is not a bad estimate at all. I trained this model and it converged in roughly 4 days. Btw as a good reference for where 6ND comes from and some intuition around it I recommend [Dzmitry's post](https://medium.com/@dzmitrybahdanau/the-flops-calculus-of-language-model-training-3b19c1f025e4)."
|
| 364 |
+
]
|
| 365 |
+
},
|
| 366 |
+
{
|
| 367 |
+
"attachments": {},
|
| 368 |
+
"cell_type": "markdown",
|
| 369 |
+
"metadata": {},
|
| 370 |
+
"source": [
|
| 371 |
+
"Now, FLOPs are just one constraint, the other that we have to keep a close track of is the memory bandwidth. TODO estimate LOAD/STORE costs of our model later."
|
| 372 |
+
]
|
| 373 |
+
}
|
| 374 |
+
],
|
| 375 |
+
"metadata": {
|
| 376 |
+
"kernelspec": {
|
| 377 |
+
"display_name": "pytorch2",
|
| 378 |
+
"language": "python",
|
| 379 |
+
"name": "python3"
|
| 380 |
+
},
|
| 381 |
+
"language_info": {
|
| 382 |
+
"codemirror_mode": {
|
| 383 |
+
"name": "ipython",
|
| 384 |
+
"version": 3
|
| 385 |
+
},
|
| 386 |
+
"file_extension": ".py",
|
| 387 |
+
"mimetype": "text/x-python",
|
| 388 |
+
"name": "python",
|
| 389 |
+
"nbconvert_exporter": "python",
|
| 390 |
+
"pygments_lexer": "ipython3",
|
| 391 |
+
"version": "3.10.8"
|
| 392 |
+
},
|
| 393 |
+
"orig_nbformat": 4,
|
| 394 |
+
"vscode": {
|
| 395 |
+
"interpreter": {
|
| 396 |
+
"hash": "7f5833218766b48e6e35e4452ee875aac0e2188d05bbe5298f2c62b79f08b222"
|
| 397 |
+
}
|
| 398 |
+
}
|
| 399 |
+
},
|
| 400 |
+
"nbformat": 4,
|
| 401 |
+
"nbformat_minor": 2
|
| 402 |
+
}
|