

Update
Browse files- README.md +3 -3
- comparison.png +0 -0
- config.json +1 -1
- model-00001-of-00004.safetensors +2 -2
- model-00002-of-00004.safetensors +1 -1
- model-00003-of-00004.safetensors +1 -1
- model-00004-of-00004.safetensors +2 -2
- model.safetensors.index.json +1 -1
- special_tokens_map.json +1 -2
- tokenizer_config.json +1 -0
README.md
CHANGED
|
@@ -9,13 +9,13 @@ license: apache-2.0
|
|
| 9 |
<img src="./icon.png" alt="Logo" width="350">
|
| 10 |
</p>
|
| 11 |
|
| 12 |
-
📖 [Technical report](https://arxiv.org/abs/2402.11530) | 🏠 [Code](https://github.com/BAAI-DCAI/Bunny) | 🐰 [3B Demo](https://wisemodel.cn/spaces/baai/Bunny) | 🐰 [8B Demo](https://
|
| 13 |
|
| 14 |
This is Bunny-Llama-3-8B-V.
|
| 15 |
|
| 16 |
-
Bunny is a family of lightweight but powerful multimodal models. It offers multiple plug-and-play vision encoders, like EVA-CLIP, SigLIP and language backbones, including Llama-3-8B, Phi-1.5, StableLM-2 and Phi-2. To compensate for the decrease in model size, we construct more informative training data by curated selection from a broader data source.
|
| 17 |
|
| 18 |
-
We provide Bunny-Llama-3-8B-V, which is built upon [SigLIP](https://huggingface.co/google/siglip-so400m-patch14-384) and [Llama-3-8B](https://huggingface.co/meta-llama/Meta-Llama-3-8B). More details about this model can be found in [GitHub](https://github.com/BAAI-DCAI/Bunny).
|
| 19 |
|
| 20 |

|
| 21 |
|
|
|
|
| 9 |
<img src="./icon.png" alt="Logo" width="350">
|
| 10 |
</p>
|
| 11 |
|
| 12 |
+
📖 [Technical report](https://arxiv.org/abs/2402.11530) | 🏠 [Code](https://github.com/BAAI-DCAI/Bunny) | 🐰 [3B Demo](https://wisemodel.cn/spaces/baai/Bunny) | 🐰 [8B Demo](https://2e09fec5116a0ba343.gradio.live)
|
| 13 |
|
| 14 |
This is Bunny-Llama-3-8B-V.
|
| 15 |
|
| 16 |
+
Bunny is a family of lightweight but powerful multimodal models. It offers multiple plug-and-play vision encoders, like EVA-CLIP, SigLIP and language backbones, including Llama-3-8B, Phi-1.5, StableLM-2, Qwen1.5, MiniCPM and Phi-2. To compensate for the decrease in model size, we construct more informative training data by curated selection from a broader data source.
|
| 17 |
|
| 18 |
+
We provide Bunny-Llama-3-8B-V, which is built upon [SigLIP](https://huggingface.co/google/siglip-so400m-patch14-384) and [Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct). More details about this model can be found in [GitHub](https://github.com/BAAI-DCAI/Bunny).
|
| 19 |
|
| 20 |

|
| 21 |
|
comparison.png
CHANGED
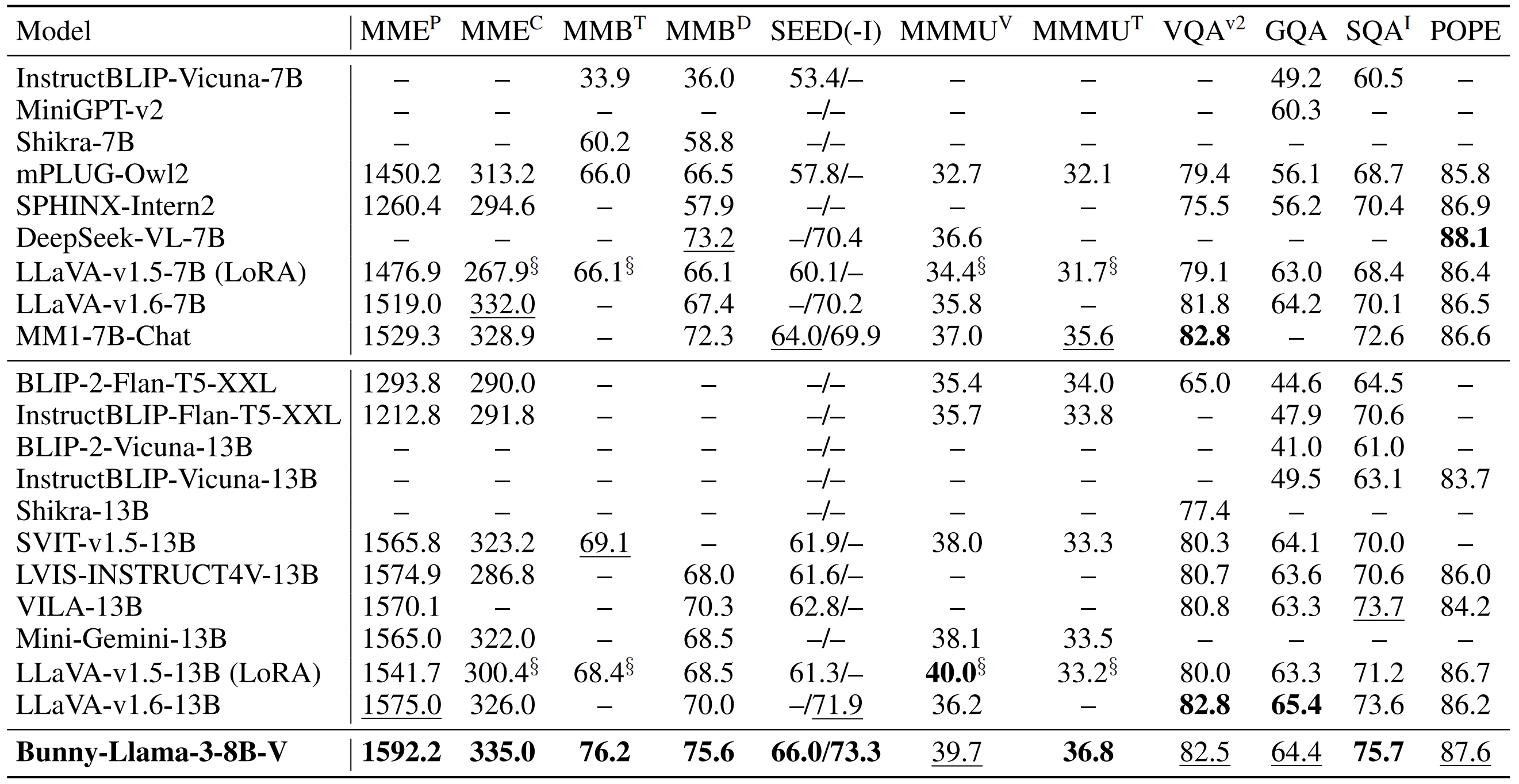
|
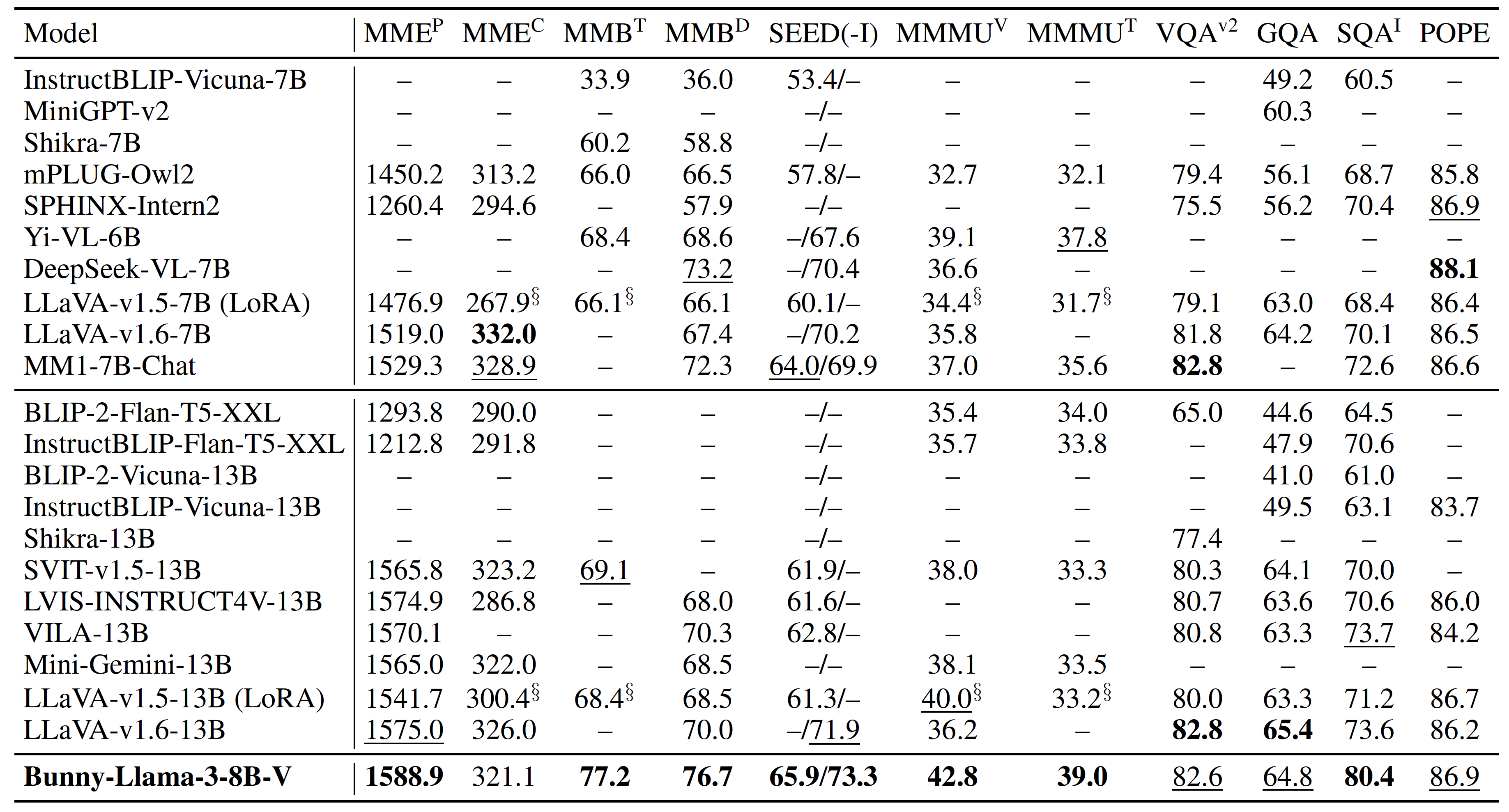
|
config.json
CHANGED
|
@@ -39,5 +39,5 @@
|
|
| 39 |
"unfreeze_vision_tower": true,
|
| 40 |
"use_cache": true,
|
| 41 |
"use_mm_proj": true,
|
| 42 |
-
"vocab_size":
|
| 43 |
}
|
|
|
|
| 39 |
"unfreeze_vision_tower": true,
|
| 40 |
"use_cache": true,
|
| 41 |
"use_mm_proj": true,
|
| 42 |
+
"vocab_size": 128256
|
| 43 |
}
|
model-00001-of-00004.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8b002c3d2062a306cb9317fb6c7d3776d764cee429f6871c97b7d10c474340fd
|
| 3 |
+
size 4976698592
|
model-00002-of-00004.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 4999802616
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c6fbc96f0928d48703340ad0c75639aa2c4468d3908e9da197babcdb27b0b483
|
| 3 |
size 4999802616
|
model-00003-of-00004.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 4915916080
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d98fe9be8120810794a907796857179ae66e3d94a621c66ced5728e3bfbed018
|
| 3 |
size 4915916080
|
model-00004-of-00004.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5aa5017356655dc29634c195c2ca2f515f3f0e1ba4aeac0454af8d946a520744
|
| 3 |
+
size 2067668216
|
model.safetensors.index.json
CHANGED
|
@@ -1,6 +1,6 @@
|
|
| 1 |
{
|
| 2 |
"metadata": {
|
| 3 |
-
"total_size":
|
| 4 |
},
|
| 5 |
"weight_map": {
|
| 6 |
"lm_head.weight": "model-00004-of-00004.safetensors",
|
|
|
|
| 1 |
{
|
| 2 |
"metadata": {
|
| 3 |
+
"total_size": 16959981696
|
| 4 |
},
|
| 5 |
"weight_map": {
|
| 6 |
"lm_head.weight": "model-00004-of-00004.safetensors",
|
special_tokens_map.json
CHANGED
|
@@ -12,6 +12,5 @@
|
|
| 12 |
"normalized": false,
|
| 13 |
"rstrip": false,
|
| 14 |
"single_word": false
|
| 15 |
-
}
|
| 16 |
-
"unk_token": "<unk>"
|
| 17 |
}
|
|
|
|
| 12 |
"normalized": false,
|
| 13 |
"rstrip": false,
|
| 14 |
"single_word": false
|
| 15 |
+
}
|
|
|
|
| 16 |
}
|
tokenizer_config.json
CHANGED
|
@@ -2050,6 +2050,7 @@
|
|
| 2050 |
}
|
| 2051 |
},
|
| 2052 |
"bos_token": "<|begin_of_text|>",
|
|
|
|
| 2053 |
"clean_up_tokenization_spaces": true,
|
| 2054 |
"eos_token": "<|end_of_text|>",
|
| 2055 |
"model_input_names": [
|
|
|
|
| 2050 |
}
|
| 2051 |
},
|
| 2052 |
"bos_token": "<|begin_of_text|>",
|
| 2053 |
+
"chat_template": "{% set loop_messages = messages %}{% for message in loop_messages %}{% set content = '<|start_header_id|>' + message['role'] + '<|end_header_id|>\n\n'+ message['content'] | trim + '<|eot_id|>' %}{% if loop.index0 == 0 %}{% set content = bos_token + content %}{% endif %}{{ content }}{% endfor %}{% if add_generation_prompt %}{{ '<|start_header_id|>assistant<|end_header_id|>\n\n' }}{% endif %}",
|
| 2054 |
"clean_up_tokenization_spaces": true,
|
| 2055 |
"eos_token": "<|end_of_text|>",
|
| 2056 |
"model_input_names": [
|