

60c144bdd893469c8ff3cc966b003f4e04724ba96783f2d38723282d76b9dd62
Browse files- .gitattributes +4 -0
- README.md +346 -3
- added_tokens.json +25 -0
- config.json +57 -0
- configuration_minicpm.py +100 -0
- generation_config.json +6 -0
- image_processing_minicpmv.py +418 -0
- merges.txt +0 -0
- model-00004-of-00004.safetensors +3 -0
- model.safetensors.index.json +796 -0
- modeling_minicpmv.py +403 -0
- modeling_navit_siglip.py +937 -0
- preprocessor_config.json +24 -0
- processing_minicpmv.py +240 -0
- resampler.py +782 -0
- special_tokens_map.json +52 -0
- tokenization_minicpmv_fast.py +66 -0
- tokenizer.json +3 -0
- tokenizer_config.json +235 -0
- vocab.json +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,7 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
*png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
*jpg filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
*gif filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -1,3 +1,346 @@
|
|
| 1 |
-
---
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
pipeline_tag: image-text-to-text
|
| 3 |
+
datasets:
|
| 4 |
+
- openbmb/RLAIF-V-Dataset
|
| 5 |
+
library_name: transformers
|
| 6 |
+
language:
|
| 7 |
+
- multilingual
|
| 8 |
+
tags:
|
| 9 |
+
- minicpm-v
|
| 10 |
+
- vision
|
| 11 |
+
- ocr
|
| 12 |
+
- multi-image
|
| 13 |
+
- video
|
| 14 |
+
- custom_code
|
| 15 |
+
---
|
| 16 |
+
|
| 17 |
+
<h1>A GPT-4V Level MLLM for Single Image, Multi Image and Video on Your Phone</h1>
|
| 18 |
+
|
| 19 |
+
[GitHub](https://github.com/OpenBMB/MiniCPM-V) | [Demo](http://120.92.209.146:8887/)</a>
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
## MiniCPM-V 2.6
|
| 23 |
+
|
| 24 |
+
**MiniCPM-V 2.6** is the latest and most capable model in the MiniCPM-V series. The model is built on SigLip-400M and Qwen2-7B with a total of 8B parameters. It exhibits a significant performance improvement over MiniCPM-Llama3-V 2.5, and introduces new features for multi-image and video understanding. Notable features of MiniCPM-V 2.6 include:
|
| 25 |
+
|
| 26 |
+
- 🔥 **Leading Performance.**
|
| 27 |
+
MiniCPM-V 2.6 achieves an average score of 65.2 on the latest version of OpenCompass, a comprehensive evaluation over 8 popular benchmarks. **With only 8B parameters, it surpasses widely used proprietary models like GPT-4o mini, GPT-4V, Gemini 1.5 Pro, and Claude 3.5 Sonnet** for single image understanding.
|
| 28 |
+
|
| 29 |
+
- 🖼️ **Multi Image Understanding and In-context Learning.** MiniCPM-V 2.6 can also perform **conversation and reasoning over multiple images**. It achieves **state-of-the-art performance** on popular multi-image benchmarks such as Mantis-Eval, BLINK, Mathverse mv and Sciverse mv, and also shows promising in-context learning capability.
|
| 30 |
+
|
| 31 |
+
- 🎬 **Video Understanding.** MiniCPM-V 2.6 can also **accept video inputs**, performing conversation and providing dense captions for spatial-temporal information. It outperforms **GPT-4V, Claude 3.5 Sonnet and LLaVA-NeXT-Video-34B** on Video-MME with/without subtitles.
|
| 32 |
+
|
| 33 |
+
- 💪 **Strong OCR Capability and Others.**
|
| 34 |
+
MiniCPM-V 2.6 can process images with any aspect ratio and up to 1.8 million pixels (e.g., 1344x1344). It achieves **state-of-the-art performance on OCRBench, surpassing proprietary models such as GPT-4o, GPT-4V, and Gemini 1.5 Pro**.
|
| 35 |
+
Based on the the latest [RLAIF-V](https://github.com/RLHF-V/RLAIF-V/) and [VisCPM](https://github.com/OpenBMB/VisCPM) techniques, it features **trustworthy behaviors**, with significantly lower hallucination rates than GPT-4o and GPT-4V on Object HalBench, and supports **multilingual capabilities** on English, Chinese, German, French, Italian, Korean, etc.
|
| 36 |
+
|
| 37 |
+
- 🚀 **Superior Efficiency.**
|
| 38 |
+
In addition to its friendly size, MiniCPM-V 2.6 also shows **state-of-the-art token density** (i.e., number of pixels encoded into each visual token). **It produces only 640 tokens when processing a 1.8M pixel image, which is 75% fewer than most models**. This directly improves the inference speed, first-token latency, memory usage, and power consumption. As a result, MiniCPM-V 2.6 can efficiently support **real-time video understanding** on end-side devices such as iPad.
|
| 39 |
+
|
| 40 |
+
- 💫 **Easy Usage.**
|
| 41 |
+
MiniCPM-V 2.6 can be easily used in various ways: (1) [llama.cpp](https://github.com/OpenBMB/llama.cpp/blob/minicpmv-main/examples/llava/README-minicpmv2.6.md) and [ollama](https://github.com/OpenBMB/ollama/tree/minicpm-v2.6) support for efficient CPU inference on local devices, (2) [int4](https://huggingface.co/openbmb/MiniCPM-V-2_6-int4) and [GGUF](https://huggingface.co/openbmb/MiniCPM-V-2_6-gguf) format quantized models in 16 sizes, (3) [vLLM](https://github.com/OpenBMB/MiniCPM-V/tree/main?tab=readme-ov-file#inference-with-vllm) support for high-throughput and memory-efficient inference, (4) fine-tuning on new domains and tasks, (5) quick local WebUI demo setup with [Gradio](https://github.com/OpenBMB/MiniCPM-V/tree/main?tab=readme-ov-file#chat-with-our-demo-on-gradio) and (6) online web [demo](http://120.92.209.146:8887).
|
| 42 |
+
|
| 43 |
+
### Evaluation <!-- omit in toc -->
|
| 44 |
+
<div align="center">
|
| 45 |
+
<img src="https://github.com/OpenBMB/MiniCPM-V/raw/main/assets/radar_final.png" width=66% />
|
| 46 |
+
</div>
|
| 47 |
+
|
| 48 |
+
Single image results on OpenCompass, MME, MMVet, OCRBench, MMMU, MathVista, MMB, AI2D, TextVQA, DocVQA, HallusionBench, Object HalBench:
|
| 49 |
+
<div align="center">
|
| 50 |
+
|
| 51 |
+

|
| 52 |
+
|
| 53 |
+
</div>
|
| 54 |
+
|
| 55 |
+
<sup>*</sup> We evaluate this benchmark using chain-of-thought prompting.
|
| 56 |
+
|
| 57 |
+
<sup>+</sup> Token Density: number of pixels encoded into each visual token at maximum resolution, i.e., # pixels at maximum resolution / # visual tokens.
|
| 58 |
+
|
| 59 |
+
Note: For proprietary models, we calculate token density based on the image encoding charging strategy defined in the official API documentation, which provides an upper-bound estimation.
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
<details>
|
| 63 |
+
<summary>Click to view multi-image results on Mantis Eval, BLINK Val, Mathverse mv, Sciverse mv, MIRB.</summary>
|
| 64 |
+
<div align="center">
|
| 65 |
+
|
| 66 |
+
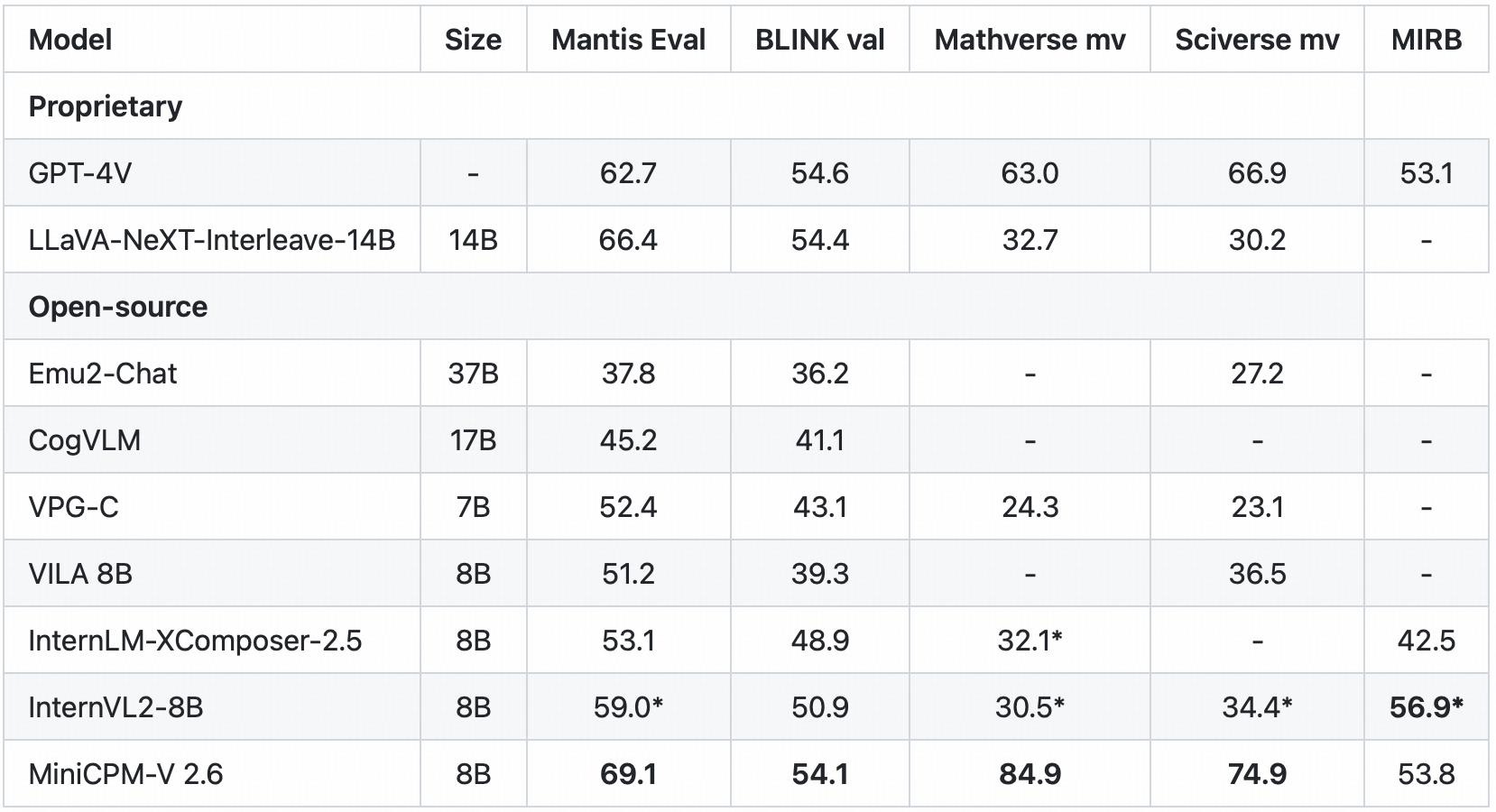
|
| 67 |
+
|
| 68 |
+
</div>
|
| 69 |
+
<sup>*</sup> We evaluate the officially released checkpoint by ourselves.
|
| 70 |
+
</details>
|
| 71 |
+
|
| 72 |
+
<details>
|
| 73 |
+
<summary>Click to view video results on Video-MME and Video-ChatGPT.</summary>
|
| 74 |
+
<div align="center">
|
| 75 |
+
|
| 76 |
+
<!--  -->
|
| 77 |
+

|
| 78 |
+
|
| 79 |
+
</div>
|
| 80 |
+
|
| 81 |
+
</details>
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
<details>
|
| 85 |
+
<summary>Click to view few-shot results on TextVQA, VizWiz, VQAv2, OK-VQA.</summary>
|
| 86 |
+
<div align="center">
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+

|
| 90 |
+
|
| 91 |
+
</div>
|
| 92 |
+
* denotes zero image shot and two additional text shots following Flamingo.
|
| 93 |
+
|
| 94 |
+
<sup>+</sup> We evaluate the pretraining ckpt without SFT.
|
| 95 |
+
</details>
|
| 96 |
+
|
| 97 |
+
### Examples <!-- omit in toc -->
|
| 98 |
+
|
| 99 |
+
<div style="display: flex; flex-direction: column; align-items: center;">
|
| 100 |
+
<img src="https://github.com/OpenBMB/MiniCPM-V/raw/main/assets/minicpmv2_6/multi_img-bike.png" alt="Bike" style="margin-bottom: -20px;">
|
| 101 |
+
<img src="https://github.com/OpenBMB/MiniCPM-V/raw/main/assets/minicpmv2_6/multi_img-menu.png" alt="Menu" style="margin-bottom: -20px;">
|
| 102 |
+
<img src="https://github.com/OpenBMB/MiniCPM-V/raw/main/assets/minicpmv2_6/multi_img-code.png" alt="Code" style="margin-bottom: -20px;">
|
| 103 |
+
<img src="https://github.com/OpenBMB/MiniCPM-V/raw/main/assets/minicpmv2_6/ICL-Mem.png" alt="Mem" style="margin-bottom: -20px;">
|
| 104 |
+
<img src="https://github.com/OpenBMB/MiniCPM-V/raw/main/assets/minicpmv2_6/multiling-medal.png" alt="medal" style="margin-bottom: 10px;">
|
| 105 |
+
</div>
|
| 106 |
+
<details>
|
| 107 |
+
<summary>Click to view more cases.</summary>
|
| 108 |
+
<div style="display: flex; flex-direction: column; align-items: center;">
|
| 109 |
+
<img src="https://github.com/OpenBMB/MiniCPM-V/raw/main/assets/minicpmv2_6/ICL-elec.png" alt="elec" style="margin-bottom: -20px;">
|
| 110 |
+
<img src="https://github.com/OpenBMB/MiniCPM-V/raw/main/assets/minicpmv2_6/multiling-olympic.png" alt="Menu" style="margin-bottom: 10px;">
|
| 111 |
+
</div>
|
| 112 |
+
</details>
|
| 113 |
+
|
| 114 |
+
We deploy MiniCPM-V 2.6 on end devices. The demo video is the raw screen recording on a iPad Pro without edition.
|
| 115 |
+
|
| 116 |
+
<div style="display: flex; justify-content: center;">
|
| 117 |
+
<img src="https://github.com/OpenBMB/MiniCPM-V/raw/main/assets/gif_cases/ai.gif" width="48%" style="margin: 0 10px;"/>
|
| 118 |
+
<img src="https://github.com/OpenBMB/MiniCPM-V/raw/main/assets/gif_cases/beer.gif" width="48%" style="margin: 0 10px;"/>
|
| 119 |
+
</div>
|
| 120 |
+
<div style="display: flex; justify-content: center; margin-top: 20px;">
|
| 121 |
+
<img src="https://github.com/OpenBMB/MiniCPM-V/raw/main/assets/gif_cases/ticket.gif" width="48%" style="margin: 0 10px;"/>
|
| 122 |
+
<img src="https://github.com/OpenBMB/MiniCPM-V/raw/main/assets/gif_cases/wfh.gif" width="48%" style="margin: 0 10px;"/>
|
| 123 |
+
</div>
|
| 124 |
+
|
| 125 |
+
<div style="text-align: center;">
|
| 126 |
+
<video controls autoplay src="https://cdn-uploads.huggingface.co/production/uploads/64abc4aa6cadc7aca585dddf/mXAEFQFqNd4nnvPk7r5eX.mp4"></video>
|
| 127 |
+
<!-- <video controls autoplay src="https://cdn-uploads.huggingface.co/production/uploads/64abc4aa6cadc7aca585dddf/fEWzfHUdKnpkM7sdmnBQa.mp4"></video> -->
|
| 128 |
+
|
| 129 |
+
</div>
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
## Demo
|
| 134 |
+
Click here to try the Demo of [MiniCPM-V 2.6](http://120.92.209.146:8887/).
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
## Usage
|
| 138 |
+
Inference using Huggingface transformers on NVIDIA GPUs. Requirements tested on python 3.10:
|
| 139 |
+
```
|
| 140 |
+
Pillow==10.1.0
|
| 141 |
+
torch==2.1.2
|
| 142 |
+
torchvision==0.16.2
|
| 143 |
+
transformers==4.40.0
|
| 144 |
+
sentencepiece==0.1.99
|
| 145 |
+
decord
|
| 146 |
+
```
|
| 147 |
+
|
| 148 |
+
```python
|
| 149 |
+
# test.py
|
| 150 |
+
import torch
|
| 151 |
+
from PIL import Image
|
| 152 |
+
from transformers import AutoModel, AutoTokenizer
|
| 153 |
+
|
| 154 |
+
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True,
|
| 155 |
+
attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
|
| 156 |
+
model = model.eval().cuda()
|
| 157 |
+
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True)
|
| 158 |
+
|
| 159 |
+
image = Image.open('xx.jpg').convert('RGB')
|
| 160 |
+
question = 'What is in the image?'
|
| 161 |
+
msgs = [{'role': 'user', 'content': [image, question]}]
|
| 162 |
+
|
| 163 |
+
res = model.chat(
|
| 164 |
+
image=None,
|
| 165 |
+
msgs=msgs,
|
| 166 |
+
tokenizer=tokenizer
|
| 167 |
+
)
|
| 168 |
+
print(res)
|
| 169 |
+
|
| 170 |
+
## if you want to use streaming, please make sure sampling=True and stream=True
|
| 171 |
+
## the model.chat will return a generator
|
| 172 |
+
res = model.chat(
|
| 173 |
+
image=None,
|
| 174 |
+
msgs=msgs,
|
| 175 |
+
tokenizer=tokenizer,
|
| 176 |
+
sampling=True,
|
| 177 |
+
stream=True
|
| 178 |
+
)
|
| 179 |
+
|
| 180 |
+
generated_text = ""
|
| 181 |
+
for new_text in res:
|
| 182 |
+
generated_text += new_text
|
| 183 |
+
print(new_text, flush=True, end='')
|
| 184 |
+
```
|
| 185 |
+
|
| 186 |
+
### Chat with multiple images
|
| 187 |
+
<details>
|
| 188 |
+
<summary> Click to show Python code running MiniCPM-V 2.6 with multiple images input. </summary>
|
| 189 |
+
|
| 190 |
+
```python
|
| 191 |
+
import torch
|
| 192 |
+
from PIL import Image
|
| 193 |
+
from transformers import AutoModel, AutoTokenizer
|
| 194 |
+
|
| 195 |
+
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True,
|
| 196 |
+
attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
|
| 197 |
+
model = model.eval().cuda()
|
| 198 |
+
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True)
|
| 199 |
+
|
| 200 |
+
image1 = Image.open('image1.jpg').convert('RGB')
|
| 201 |
+
image2 = Image.open('image2.jpg').convert('RGB')
|
| 202 |
+
question = 'Compare image 1 and image 2, tell me about the differences between image 1 and image 2.'
|
| 203 |
+
|
| 204 |
+
msgs = [{'role': 'user', 'content': [image1, image2, question]}]
|
| 205 |
+
|
| 206 |
+
answer = model.chat(
|
| 207 |
+
image=None,
|
| 208 |
+
msgs=msgs,
|
| 209 |
+
tokenizer=tokenizer
|
| 210 |
+
)
|
| 211 |
+
print(answer)
|
| 212 |
+
```
|
| 213 |
+
</details>
|
| 214 |
+
|
| 215 |
+
### In-context few-shot learning
|
| 216 |
+
<details>
|
| 217 |
+
<summary> Click to view Python code running MiniCPM-V 2.6 with few-shot input. </summary>
|
| 218 |
+
|
| 219 |
+
```python
|
| 220 |
+
import torch
|
| 221 |
+
from PIL import Image
|
| 222 |
+
from transformers import AutoModel, AutoTokenizer
|
| 223 |
+
|
| 224 |
+
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True,
|
| 225 |
+
attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
|
| 226 |
+
model = model.eval().cuda()
|
| 227 |
+
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True)
|
| 228 |
+
|
| 229 |
+
question = "production date"
|
| 230 |
+
image1 = Image.open('example1.jpg').convert('RGB')
|
| 231 |
+
answer1 = "2023.08.04"
|
| 232 |
+
image2 = Image.open('example2.jpg').convert('RGB')
|
| 233 |
+
answer2 = "2007.04.24"
|
| 234 |
+
image_test = Image.open('test.jpg').convert('RGB')
|
| 235 |
+
|
| 236 |
+
msgs = [
|
| 237 |
+
{'role': 'user', 'content': [image1, question]}, {'role': 'assistant', 'content': [answer1]},
|
| 238 |
+
{'role': 'user', 'content': [image2, question]}, {'role': 'assistant', 'content': [answer2]},
|
| 239 |
+
{'role': 'user', 'content': [image_test, question]}
|
| 240 |
+
]
|
| 241 |
+
|
| 242 |
+
answer = model.chat(
|
| 243 |
+
image=None,
|
| 244 |
+
msgs=msgs,
|
| 245 |
+
tokenizer=tokenizer
|
| 246 |
+
)
|
| 247 |
+
print(answer)
|
| 248 |
+
```
|
| 249 |
+
</details>
|
| 250 |
+
|
| 251 |
+
### Chat with video
|
| 252 |
+
<details>
|
| 253 |
+
<summary> Click to view Python code running MiniCPM-V 2.6 with video input. </summary>
|
| 254 |
+
|
| 255 |
+
```python
|
| 256 |
+
import torch
|
| 257 |
+
from PIL import Image
|
| 258 |
+
from transformers import AutoModel, AutoTokenizer
|
| 259 |
+
from decord import VideoReader, cpu # pip install decord
|
| 260 |
+
|
| 261 |
+
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True,
|
| 262 |
+
attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
|
| 263 |
+
model = model.eval().cuda()
|
| 264 |
+
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True)
|
| 265 |
+
|
| 266 |
+
MAX_NUM_FRAMES=64 # if cuda OOM set a smaller number
|
| 267 |
+
|
| 268 |
+
def encode_video(video_path):
|
| 269 |
+
def uniform_sample(l, n):
|
| 270 |
+
gap = len(l) / n
|
| 271 |
+
idxs = [int(i * gap + gap / 2) for i in range(n)]
|
| 272 |
+
return [l[i] for i in idxs]
|
| 273 |
+
|
| 274 |
+
vr = VideoReader(video_path, ctx=cpu(0))
|
| 275 |
+
sample_fps = round(vr.get_avg_fps() / 1) # FPS
|
| 276 |
+
frame_idx = [i for i in range(0, len(vr), sample_fps)]
|
| 277 |
+
if len(frame_idx) > MAX_NUM_FRAMES:
|
| 278 |
+
frame_idx = uniform_sample(frame_idx, MAX_NUM_FRAMES)
|
| 279 |
+
frames = vr.get_batch(frame_idx).asnumpy()
|
| 280 |
+
frames = [Image.fromarray(v.astype('uint8')) for v in frames]
|
| 281 |
+
print('num frames:', len(frames))
|
| 282 |
+
return frames
|
| 283 |
+
|
| 284 |
+
video_path ="video_test.mp4"
|
| 285 |
+
frames = encode_video(video_path)
|
| 286 |
+
question = "Describe the video"
|
| 287 |
+
msgs = [
|
| 288 |
+
{'role': 'user', 'content': frames + [question]},
|
| 289 |
+
]
|
| 290 |
+
|
| 291 |
+
# Set decode params for video
|
| 292 |
+
params={}
|
| 293 |
+
params["use_image_id"] = False
|
| 294 |
+
params["max_slice_nums"] = 2 # use 1 if cuda OOM and video resolution > 448*448
|
| 295 |
+
|
| 296 |
+
answer = model.chat(
|
| 297 |
+
image=None,
|
| 298 |
+
msgs=msgs,
|
| 299 |
+
tokenizer=tokenizer,
|
| 300 |
+
**params
|
| 301 |
+
)
|
| 302 |
+
print(answer)
|
| 303 |
+
```
|
| 304 |
+
</details>
|
| 305 |
+
|
| 306 |
+
|
| 307 |
+
Please look at [GitHub](https://github.com/OpenBMB/MiniCPM-V) for more detail about usage.
|
| 308 |
+
|
| 309 |
+
|
| 310 |
+
## Inference with llama.cpp<a id="llamacpp"></a>
|
| 311 |
+
MiniCPM-V 2.6 can run with llama.cpp. See our fork of [llama.cpp](https://github.com/OpenBMB/llama.cpp/tree/minicpm-v2.5/examples/minicpmv) for more detail.
|
| 312 |
+
|
| 313 |
+
|
| 314 |
+
## Int4 quantized version
|
| 315 |
+
Download the int4 quantized version for lower GPU memory (7GB) usage: [MiniCPM-V-2_6-int4](https://huggingface.co/openbmb/MiniCPM-V-2_6-int4).
|
| 316 |
+
|
| 317 |
+
|
| 318 |
+
## License
|
| 319 |
+
#### Model License
|
| 320 |
+
* The code in this repo is released under the [Apache-2.0](https://github.com/OpenBMB/MiniCPM/blob/main/LICENSE) License.
|
| 321 |
+
* The usage of MiniCPM-V series model weights must strictly follow [MiniCPM Model License.md](https://github.com/OpenBMB/MiniCPM/blob/main/MiniCPM%20Model%20License.md).
|
| 322 |
+
* The models and weights of MiniCPM are completely free for academic research. After filling out a ["questionnaire"](https://modelbest.feishu.cn/share/base/form/shrcnpV5ZT9EJ6xYjh3Kx0J6v8g) for registration, MiniCPM-V 2.6 weights are also available for free commercial use.
|
| 323 |
+
|
| 324 |
+
|
| 325 |
+
#### Statement
|
| 326 |
+
* As an LMM, MiniCPM-V 2.6 generates contents by learning a large mount of multimodal corpora, but it cannot comprehend, express personal opinions or make value judgement. Anything generated by MiniCPM-V 2.6 does not represent the views and positions of the model developers
|
| 327 |
+
* We will not be liable for any problems arising from the use of the MinCPM-V models, including but not limited to data security issues, risk of public opinion, or any risks and problems arising from the misdirection, misuse, dissemination or misuse of the model.
|
| 328 |
+
|
| 329 |
+
## Key Techniques and Other Multimodal Projects
|
| 330 |
+
|
| 331 |
+
👏 Welcome to explore key techniques of MiniCPM-V 2.6 and other multimodal projects of our team:
|
| 332 |
+
|
| 333 |
+
[VisCPM](https://github.com/OpenBMB/VisCPM/tree/main) | [RLHF-V](https://github.com/RLHF-V/RLHF-V) | [LLaVA-UHD](https://github.com/thunlp/LLaVA-UHD) | [RLAIF-V](https://github.com/RLHF-V/RLAIF-V)
|
| 334 |
+
|
| 335 |
+
## Citation
|
| 336 |
+
|
| 337 |
+
If you find our work helpful, please consider citing our papers 📝 and liking this project ❤️!
|
| 338 |
+
|
| 339 |
+
```bib
|
| 340 |
+
@article{yao2024minicpm,
|
| 341 |
+
title={MiniCPM-V: A GPT-4V Level MLLM on Your Phone},
|
| 342 |
+
author={Yao, Yuan and Yu, Tianyu and Zhang, Ao and Wang, Chongyi and Cui, Junbo and Zhu, Hongji and Cai, Tianchi and Li, Haoyu and Zhao, Weilin and He, Zhihui and others},
|
| 343 |
+
journal={arXiv preprint arXiv:2408.01800},
|
| 344 |
+
year={2024}
|
| 345 |
+
}
|
| 346 |
+
```
|
added_tokens.json
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"</box>": 151651,
|
| 3 |
+
"</image>": 151647,
|
| 4 |
+
"</image_id>": 151659,
|
| 5 |
+
"</point>": 151655,
|
| 6 |
+
"</quad>": 151653,
|
| 7 |
+
"</ref>": 151649,
|
| 8 |
+
"</slice>": 151657,
|
| 9 |
+
"<box>": 151650,
|
| 10 |
+
"<image>": 151646,
|
| 11 |
+
"<image_id>": 151658,
|
| 12 |
+
"<point>": 151654,
|
| 13 |
+
"<quad>": 151652,
|
| 14 |
+
"<ref>": 151648,
|
| 15 |
+
"<slice>": 151656,
|
| 16 |
+
"<|endoftext|>": 151643,
|
| 17 |
+
"<|im_end|>": 151645,
|
| 18 |
+
"<|im_start|>": 151644,
|
| 19 |
+
"<|reserved_special_token_0|>": 151660,
|
| 20 |
+
"<|reserved_special_token_1|>": 151661,
|
| 21 |
+
"<|reserved_special_token_2|>": 151662,
|
| 22 |
+
"<|reserved_special_token_3|>": 151663,
|
| 23 |
+
"<|reserved_special_token_4|>": 151664,
|
| 24 |
+
"<|reserved_special_token_5|>": 151665
|
| 25 |
+
}
|
config.json
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "openbmb/MiniCPM-V-2_6",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"MiniCPMV"
|
| 5 |
+
],
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"auto_map": {
|
| 8 |
+
"AutoConfig": "openbmb/MiniCPM-V-2_6--configuration_minicpm.MiniCPMVConfig",
|
| 9 |
+
"AutoModel": "openbmb/MiniCPM-V-2_6--modeling_minicpmv.MiniCPMV",
|
| 10 |
+
"AutoModelForCausalLM": "openbmb/MiniCPM-V-2_6--modeling_minicpmv.MiniCPMV"
|
| 11 |
+
},
|
| 12 |
+
"batch_vision_input": true,
|
| 13 |
+
"bos_token_id": 151643,
|
| 14 |
+
"drop_vision_last_layer": false,
|
| 15 |
+
"eos_token_id": 151645,
|
| 16 |
+
"hidden_act": "silu",
|
| 17 |
+
"hidden_size": 3584,
|
| 18 |
+
"image_size": 448,
|
| 19 |
+
"initializer_range": 0.02,
|
| 20 |
+
"intermediate_size": 18944,
|
| 21 |
+
"max_position_embeddings": 32768,
|
| 22 |
+
"max_window_layers": 28,
|
| 23 |
+
"model_type": "minicpmv",
|
| 24 |
+
"num_attention_heads": 28,
|
| 25 |
+
"num_hidden_layers": 28,
|
| 26 |
+
"num_key_value_heads": 4,
|
| 27 |
+
"patch_size": 14,
|
| 28 |
+
"query_num": 64,
|
| 29 |
+
"rms_norm_eps": 1e-06,
|
| 30 |
+
"rope_scaling": null,
|
| 31 |
+
"rope_theta": 1000000.0,
|
| 32 |
+
"slice_config": {
|
| 33 |
+
"max_slice_nums": 9,
|
| 34 |
+
"model_type": "minicpmv"
|
| 35 |
+
},
|
| 36 |
+
"slice_mode": true,
|
| 37 |
+
"sliding_window": null,
|
| 38 |
+
"tie_word_embeddings": false,
|
| 39 |
+
"torch_dtype": "float16",
|
| 40 |
+
"transformers_version": "4.46.0",
|
| 41 |
+
"use_cache": true,
|
| 42 |
+
"use_image_id": true,
|
| 43 |
+
"use_sliding_window": false,
|
| 44 |
+
"version": 2.6,
|
| 45 |
+
"vision_batch_size": 16,
|
| 46 |
+
"vision_config": {
|
| 47 |
+
"_attn_implementation_autoset": true,
|
| 48 |
+
"hidden_size": 1152,
|
| 49 |
+
"image_size": 980,
|
| 50 |
+
"intermediate_size": 4304,
|
| 51 |
+
"model_type": "siglip_vision_model",
|
| 52 |
+
"num_attention_heads": 16,
|
| 53 |
+
"num_hidden_layers": 27,
|
| 54 |
+
"patch_size": 14
|
| 55 |
+
},
|
| 56 |
+
"vocab_size": 151666
|
| 57 |
+
}
|
configuration_minicpm.py
ADDED
|
@@ -0,0 +1,100 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
""" MiniCPMV model configuration"""
|
| 3 |
+
|
| 4 |
+
import os
|
| 5 |
+
from typing import Union
|
| 6 |
+
|
| 7 |
+
from transformers.utils import logging
|
| 8 |
+
from transformers import Qwen2Config, PretrainedConfig
|
| 9 |
+
from .modeling_navit_siglip import SiglipVisionConfig
|
| 10 |
+
|
| 11 |
+
logger = logging.get_logger(__name__)
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class MiniCPMVSliceConfig(PretrainedConfig):
|
| 15 |
+
model_type = "minicpmv"
|
| 16 |
+
|
| 17 |
+
def __init__(
|
| 18 |
+
self,
|
| 19 |
+
patch_size=14,
|
| 20 |
+
max_slice_nums=9,
|
| 21 |
+
scale_resolution=448,
|
| 22 |
+
**kwargs,
|
| 23 |
+
):
|
| 24 |
+
super().__init__(**kwargs)
|
| 25 |
+
self.patch_size = patch_size
|
| 26 |
+
self.max_slice_nums = max_slice_nums
|
| 27 |
+
self.scale_resolution = scale_resolution
|
| 28 |
+
|
| 29 |
+
@classmethod
|
| 30 |
+
def from_pretrained(cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs) -> "PretrainedConfig":
|
| 31 |
+
cls._set_token_in_kwargs(kwargs)
|
| 32 |
+
|
| 33 |
+
config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
|
| 34 |
+
|
| 35 |
+
if config_dict.get("model_type") == "minicpmv":
|
| 36 |
+
config_dict = config_dict["slice_config"]
|
| 37 |
+
|
| 38 |
+
if "model_type" in config_dict and hasattr(cls, "model_type") and config_dict["model_type"] != cls.model_type:
|
| 39 |
+
logger.warning(
|
| 40 |
+
f"You are using a model of type {config_dict['model_type']} to instantiate a model of type "
|
| 41 |
+
f"{cls.model_type}. This is not supported for all configurations of models and can yield errors."
|
| 42 |
+
)
|
| 43 |
+
|
| 44 |
+
return cls.from_dict(config_dict, **kwargs)
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
class MiniCPMVConfig(Qwen2Config):
|
| 49 |
+
model_type = "minicpmv"
|
| 50 |
+
keys_to_ignore_at_inference = ["past_key_values"]
|
| 51 |
+
|
| 52 |
+
default_vision_config = {
|
| 53 |
+
"hidden_size": 1152,
|
| 54 |
+
"image_size": 980,
|
| 55 |
+
"intermediate_size": 4304,
|
| 56 |
+
"model_type": "siglip",
|
| 57 |
+
"num_attention_heads": 16,
|
| 58 |
+
"num_hidden_layers": 27,
|
| 59 |
+
"patch_size": 14,
|
| 60 |
+
}
|
| 61 |
+
|
| 62 |
+
def __init__(
|
| 63 |
+
self,
|
| 64 |
+
use_cache=True,
|
| 65 |
+
query_num=64,
|
| 66 |
+
image_size=448,
|
| 67 |
+
drop_vision_last_layer=True,
|
| 68 |
+
batch_vision_input=True,
|
| 69 |
+
slice_config=None,
|
| 70 |
+
vision_config=None,
|
| 71 |
+
use_image_id=True,
|
| 72 |
+
vision_batch_size=16,
|
| 73 |
+
**kwargs,
|
| 74 |
+
):
|
| 75 |
+
self.use_cache = use_cache
|
| 76 |
+
self.query_num = query_num
|
| 77 |
+
self.image_size = image_size
|
| 78 |
+
self.drop_vision_last_layer = drop_vision_last_layer
|
| 79 |
+
self.batch_vision_input = batch_vision_input
|
| 80 |
+
self.use_image_id = use_image_id
|
| 81 |
+
self.vision_batch_size = vision_batch_size
|
| 82 |
+
|
| 83 |
+
if slice_config is None:
|
| 84 |
+
self.slice_config = MiniCPMVSliceConfig(max_slice_nums=1)
|
| 85 |
+
else:
|
| 86 |
+
self.slice_config = MiniCPMVSliceConfig(**slice_config)
|
| 87 |
+
self.slice_mode = True
|
| 88 |
+
|
| 89 |
+
# same as HuggingFaceM4/siglip-so400m-14-980-flash-attn2-navit add tgt_sizes
|
| 90 |
+
if vision_config is None:
|
| 91 |
+
self.vision_config = SiglipVisionConfig(**self.default_vision_config)
|
| 92 |
+
logger.info("vision_config is None, using default vision config")
|
| 93 |
+
elif isinstance(vision_config, dict):
|
| 94 |
+
self.vision_config = SiglipVisionConfig(**vision_config)
|
| 95 |
+
elif isinstance(vision_config, SiglipVisionConfig):
|
| 96 |
+
self.vision_config = vision_config
|
| 97 |
+
|
| 98 |
+
self.patch_size = self.vision_config.patch_size
|
| 99 |
+
|
| 100 |
+
super().__init__(**kwargs)
|
generation_config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 151643,
|
| 4 |
+
"eos_token_id": 151645,
|
| 5 |
+
"transformers_version": "4.46.0"
|
| 6 |
+
}
|
image_processing_minicpmv.py
ADDED
|
@@ -0,0 +1,418 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Optional, Union, Dict, Any, List
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
import math
|
| 5 |
+
import PIL.Image
|
| 6 |
+
import PIL.ImageSequence
|
| 7 |
+
import numpy as np
|
| 8 |
+
import PIL
|
| 9 |
+
from PIL import Image
|
| 10 |
+
|
| 11 |
+
from transformers.utils import TensorType, requires_backends, is_torch_dtype, is_torch_device
|
| 12 |
+
from transformers.image_processing_utils import BaseImageProcessor, BatchFeature
|
| 13 |
+
from transformers import AutoImageProcessor
|
| 14 |
+
from transformers.image_transforms import to_channel_dimension_format
|
| 15 |
+
from transformers.image_utils import (
|
| 16 |
+
ImageInput,
|
| 17 |
+
make_list_of_images,
|
| 18 |
+
valid_images,
|
| 19 |
+
is_torch_tensor,
|
| 20 |
+
is_batched,
|
| 21 |
+
to_numpy_array,
|
| 22 |
+
infer_channel_dimension_format,
|
| 23 |
+
ChannelDimension
|
| 24 |
+
)
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def recursive_converter(converter, value):
|
| 28 |
+
if isinstance(value, list):
|
| 29 |
+
new_value = []
|
| 30 |
+
for v in value:
|
| 31 |
+
new_value += [recursive_converter(converter, v)]
|
| 32 |
+
return new_value
|
| 33 |
+
else:
|
| 34 |
+
return converter(value)
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
class MiniCPMVBatchFeature(BatchFeature):
|
| 38 |
+
r"""
|
| 39 |
+
Extend from BatchFeature for supporting various image size
|
| 40 |
+
"""
|
| 41 |
+
def __init__(self, data: Optional[Dict[str, Any]] = None, tensor_type: Union[None, str, TensorType] = None):
|
| 42 |
+
super().__init__(data)
|
| 43 |
+
self.convert_to_tensors(tensor_type=tensor_type)
|
| 44 |
+
|
| 45 |
+
def convert_to_tensors(self, tensor_type: Optional[Union[str, TensorType]] = None):
|
| 46 |
+
if tensor_type is None:
|
| 47 |
+
return self
|
| 48 |
+
|
| 49 |
+
is_tensor, as_tensor = self._get_is_as_tensor_fns(tensor_type)
|
| 50 |
+
|
| 51 |
+
def converter(value):
|
| 52 |
+
try:
|
| 53 |
+
if not is_tensor(value):
|
| 54 |
+
tensor = as_tensor(value)
|
| 55 |
+
return tensor
|
| 56 |
+
except: # noqa E722
|
| 57 |
+
if key == "overflowing_values":
|
| 58 |
+
raise ValueError("Unable to create tensor returning overflowing values of different lengths. ")
|
| 59 |
+
raise ValueError(
|
| 60 |
+
"Unable to create tensor, you should probably activate padding "
|
| 61 |
+
"with 'padding=True' to have batched tensors with the same length."
|
| 62 |
+
)
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
for key, value in self.items():
|
| 66 |
+
self[key] = recursive_converter(converter, value)
|
| 67 |
+
return self
|
| 68 |
+
|
| 69 |
+
def to(self, *args, **kwargs) -> "MiniCPMVBatchFeature":
|
| 70 |
+
requires_backends(self, ["torch"])
|
| 71 |
+
import torch
|
| 72 |
+
|
| 73 |
+
def cast_tensor(v):
|
| 74 |
+
# check if v is a floating point
|
| 75 |
+
if torch.is_floating_point(v):
|
| 76 |
+
# cast and send to device
|
| 77 |
+
return v.to(*args, **kwargs)
|
| 78 |
+
elif device is not None:
|
| 79 |
+
return v.to(device=device)
|
| 80 |
+
else:
|
| 81 |
+
return v
|
| 82 |
+
|
| 83 |
+
new_data = {}
|
| 84 |
+
device = kwargs.get("device")
|
| 85 |
+
# Check if the args are a device or a dtype
|
| 86 |
+
if device is None and len(args) > 0:
|
| 87 |
+
# device should be always the first argument
|
| 88 |
+
arg = args[0]
|
| 89 |
+
if is_torch_dtype(arg):
|
| 90 |
+
# The first argument is a dtype
|
| 91 |
+
pass
|
| 92 |
+
elif isinstance(arg, str) or is_torch_device(arg) or isinstance(arg, int):
|
| 93 |
+
device = arg
|
| 94 |
+
else:
|
| 95 |
+
# it's something else
|
| 96 |
+
raise ValueError(f"Attempting to cast a BatchFeature to type {str(arg)}. This is not supported.")
|
| 97 |
+
# We cast only floating point tensors to avoid issues with tokenizers casting `LongTensor` to `FloatTensor`
|
| 98 |
+
for k, v in self.items():
|
| 99 |
+
new_data[k] = recursive_converter(cast_tensor, v)
|
| 100 |
+
self.data = new_data
|
| 101 |
+
return self
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
class MiniCPMVImageProcessor(BaseImageProcessor):
|
| 105 |
+
model_input_names = ["pixel_values"]
|
| 106 |
+
|
| 107 |
+
def __init__(
|
| 108 |
+
self,
|
| 109 |
+
max_slice_nums=9,
|
| 110 |
+
scale_resolution=448,
|
| 111 |
+
patch_size=14,
|
| 112 |
+
**kwargs):
|
| 113 |
+
super().__init__(**kwargs)
|
| 114 |
+
self.max_slice_nums = max_slice_nums
|
| 115 |
+
self.scale_resolution = scale_resolution
|
| 116 |
+
self.patch_size = patch_size
|
| 117 |
+
self.use_image_id = kwargs.pop("use_image_id", False)
|
| 118 |
+
self.image_feature_size = kwargs.pop("image_feature_size", 64)
|
| 119 |
+
self.im_start_token = kwargs.pop("im_start", "<image>")
|
| 120 |
+
self.im_end_token = kwargs.pop("im_end", "</image>")
|
| 121 |
+
self.slice_start_token = kwargs.pop("slice_start", "<slice>")
|
| 122 |
+
self.slice_end_token = kwargs.pop("slice_end", "</slice>")
|
| 123 |
+
self.unk_token = kwargs.pop("unk", "<unk>")
|
| 124 |
+
self.im_id_start = kwargs.pop("im_id_start", "<image_id>")
|
| 125 |
+
self.im_id_end = kwargs.pop("im_id_end", "</image_id>")
|
| 126 |
+
self.slice_mode = kwargs.pop("slice_mode", True)
|
| 127 |
+
self.mean = np.array(kwargs.pop("norm_mean", [0.5, 0.5, 0.5]))
|
| 128 |
+
self.std = np.array(kwargs.pop("norm_std", [0.5, 0.5, 0.5]))
|
| 129 |
+
self.version = kwargs.pop("version", 2.0)
|
| 130 |
+
|
| 131 |
+
def ensure_divide(self, length, patch_size):
|
| 132 |
+
return max(round(length / patch_size) * patch_size, patch_size)
|
| 133 |
+
|
| 134 |
+
def find_best_resize(self,
|
| 135 |
+
original_size,
|
| 136 |
+
scale_resolution,
|
| 137 |
+
patch_size,
|
| 138 |
+
allow_upscale=False):
|
| 139 |
+
width, height = original_size
|
| 140 |
+
if (width * height >
|
| 141 |
+
scale_resolution * scale_resolution) or allow_upscale:
|
| 142 |
+
r = width / height
|
| 143 |
+
height = int(scale_resolution / math.sqrt(r))
|
| 144 |
+
width = int(height * r)
|
| 145 |
+
best_width = self.ensure_divide(width, patch_size)
|
| 146 |
+
best_height = self.ensure_divide(height, patch_size)
|
| 147 |
+
return (best_width, best_height)
|
| 148 |
+
|
| 149 |
+
def get_refine_size(self,
|
| 150 |
+
original_size,
|
| 151 |
+
grid,
|
| 152 |
+
scale_resolution,
|
| 153 |
+
patch_size,
|
| 154 |
+
allow_upscale=False):
|
| 155 |
+
width, height = original_size
|
| 156 |
+
grid_x, grid_y = grid
|
| 157 |
+
|
| 158 |
+
refine_width = self.ensure_divide(width, grid_x)
|
| 159 |
+
refine_height = self.ensure_divide(height, grid_y)
|
| 160 |
+
|
| 161 |
+
grid_width = refine_width / grid_x
|
| 162 |
+
grid_height = refine_height / grid_y
|
| 163 |
+
|
| 164 |
+
best_grid_size = self.find_best_resize((grid_width, grid_height),
|
| 165 |
+
scale_resolution,
|
| 166 |
+
patch_size,
|
| 167 |
+
allow_upscale=allow_upscale)
|
| 168 |
+
refine_size = (best_grid_size[0] * grid_x, best_grid_size[1] * grid_y)
|
| 169 |
+
return refine_size
|
| 170 |
+
|
| 171 |
+
def split_to_patches(self, image, grid):
|
| 172 |
+
patches = []
|
| 173 |
+
width, height = image.size
|
| 174 |
+
grid_x = int(width / grid[0])
|
| 175 |
+
grid_y = int(height / grid[1])
|
| 176 |
+
for i in range(0, height, grid_y):
|
| 177 |
+
images = []
|
| 178 |
+
for j in range(0, width, grid_x):
|
| 179 |
+
box = (j, i, j + grid_x, i + grid_y)
|
| 180 |
+
patch = image.crop(box)
|
| 181 |
+
images.append(patch)
|
| 182 |
+
patches.append(images)
|
| 183 |
+
return patches
|
| 184 |
+
|
| 185 |
+
def slice_image(
|
| 186 |
+
self, image, max_slice_nums=9, scale_resolution=448, patch_size=14, never_split=False
|
| 187 |
+
):
|
| 188 |
+
original_size = image.size
|
| 189 |
+
source_image = None
|
| 190 |
+
best_grid = self.get_sliced_grid(original_size, max_slice_nums, never_split)
|
| 191 |
+
patches = []
|
| 192 |
+
|
| 193 |
+
if best_grid is None:
|
| 194 |
+
# dont need to slice, upsample
|
| 195 |
+
best_size = self.find_best_resize(
|
| 196 |
+
original_size, scale_resolution, patch_size, allow_upscale=True
|
| 197 |
+
)
|
| 198 |
+
source_image = image.resize(best_size, resample=Image.Resampling.BICUBIC)
|
| 199 |
+
else:
|
| 200 |
+
# source image, down-sampling and ensure divided by patch_size
|
| 201 |
+
best_resize = self.find_best_resize(original_size, scale_resolution, patch_size)
|
| 202 |
+
source_image = image.copy().resize(best_resize, resample=Image.Resampling.BICUBIC)
|
| 203 |
+
refine_size = self.get_refine_size(
|
| 204 |
+
original_size, best_grid, scale_resolution, patch_size, allow_upscale=True
|
| 205 |
+
)
|
| 206 |
+
refine_image = image.resize(refine_size, resample=Image.Resampling.BICUBIC)
|
| 207 |
+
patches = self.split_to_patches(refine_image, best_grid)
|
| 208 |
+
|
| 209 |
+
return source_image, patches, best_grid
|
| 210 |
+
|
| 211 |
+
def get_grid_placeholder(self, grid):
|
| 212 |
+
if grid is None:
|
| 213 |
+
return ""
|
| 214 |
+
slice_image_placeholder = (
|
| 215 |
+
self.slice_start_token
|
| 216 |
+
+ self.unk_token * self.image_feature_size
|
| 217 |
+
+ self.slice_end_token
|
| 218 |
+
)
|
| 219 |
+
|
| 220 |
+
cols = grid[0]
|
| 221 |
+
rows = grid[1]
|
| 222 |
+
slices = []
|
| 223 |
+
for i in range(rows):
|
| 224 |
+
lines = []
|
| 225 |
+
for j in range(cols):
|
| 226 |
+
lines.append(slice_image_placeholder)
|
| 227 |
+
slices.append("".join(lines))
|
| 228 |
+
|
| 229 |
+
slice_placeholder = "\n".join(slices)
|
| 230 |
+
return slice_placeholder
|
| 231 |
+
|
| 232 |
+
def get_image_id_placeholder(self, idx=0):
|
| 233 |
+
return f"{self.im_id_start}{idx}{self.im_id_end}"
|
| 234 |
+
|
| 235 |
+
def get_sliced_images(self, image, max_slice_nums=None):
|
| 236 |
+
slice_images = []
|
| 237 |
+
|
| 238 |
+
if not self.slice_mode:
|
| 239 |
+
return [image]
|
| 240 |
+
|
| 241 |
+
max_slice_nums = self.max_slice_nums if max_slice_nums is None else int(max_slice_nums)
|
| 242 |
+
assert max_slice_nums > 0
|
| 243 |
+
source_image, patches, sliced_grid = self.slice_image(
|
| 244 |
+
image,
|
| 245 |
+
max_slice_nums, # default: 9
|
| 246 |
+
self.scale_resolution, # default: 448
|
| 247 |
+
self.patch_size # default: 14
|
| 248 |
+
)
|
| 249 |
+
|
| 250 |
+
slice_images.append(source_image)
|
| 251 |
+
if len(patches) > 0:
|
| 252 |
+
for i in range(len(patches)):
|
| 253 |
+
for j in range(len(patches[0])):
|
| 254 |
+
slice_images.append(patches[i][j])
|
| 255 |
+
return slice_images
|
| 256 |
+
|
| 257 |
+
def get_sliced_grid(self, image_size, max_slice_nums, nerver_split=False):
|
| 258 |
+
original_width, original_height = image_size
|
| 259 |
+
log_ratio = math.log(original_width / original_height)
|
| 260 |
+
ratio = original_width * original_height / (self.scale_resolution * self.scale_resolution)
|
| 261 |
+
multiple = min(math.ceil(ratio), max_slice_nums)
|
| 262 |
+
if multiple <= 1 or nerver_split:
|
| 263 |
+
return None
|
| 264 |
+
candidate_split_grids_nums = []
|
| 265 |
+
for i in [multiple - 1, multiple, multiple + 1]:
|
| 266 |
+
if i == 1 or i > max_slice_nums:
|
| 267 |
+
continue
|
| 268 |
+
candidate_split_grids_nums.append(i)
|
| 269 |
+
|
| 270 |
+
candidate_grids = []
|
| 271 |
+
for split_grids_nums in candidate_split_grids_nums:
|
| 272 |
+
m = 1
|
| 273 |
+
while m <= split_grids_nums:
|
| 274 |
+
if split_grids_nums % m == 0:
|
| 275 |
+
candidate_grids.append([m, split_grids_nums // m])
|
| 276 |
+
m += 1
|
| 277 |
+
|
| 278 |
+
best_grid = [1, 1]
|
| 279 |
+
min_error = float("inf")
|
| 280 |
+
for grid in candidate_grids:
|
| 281 |
+
error = abs(log_ratio - math.log(grid[0] / grid[1]))
|
| 282 |
+
if error < min_error:
|
| 283 |
+
best_grid = grid
|
| 284 |
+
min_error = error
|
| 285 |
+
|
| 286 |
+
return best_grid
|
| 287 |
+
|
| 288 |
+
def get_slice_image_placeholder(self, image_size, image_idx=0, max_slice_nums=None, use_image_id=None):
|
| 289 |
+
max_slice_nums = self.max_slice_nums if max_slice_nums is None else int(max_slice_nums)
|
| 290 |
+
assert max_slice_nums > 0
|
| 291 |
+
grid = self.get_sliced_grid(image_size=image_size, max_slice_nums=max_slice_nums)
|
| 292 |
+
|
| 293 |
+
image_placeholder = (
|
| 294 |
+
self.im_start_token
|
| 295 |
+
+ self.unk_token * self.image_feature_size
|
| 296 |
+
+ self.im_end_token
|
| 297 |
+
)
|
| 298 |
+
use_image_id = self.use_image_id if use_image_id is None else bool(use_image_id)
|
| 299 |
+
if use_image_id:
|
| 300 |
+
final_placeholder = self.get_image_id_placeholder(image_idx) + image_placeholder
|
| 301 |
+
else:
|
| 302 |
+
final_placeholder = image_placeholder
|
| 303 |
+
|
| 304 |
+
if self.slice_mode:
|
| 305 |
+
final_placeholder = final_placeholder + self.get_grid_placeholder(grid=grid)
|
| 306 |
+
return final_placeholder
|
| 307 |
+
|
| 308 |
+
def to_pil_image(self, image, rescale=None) -> PIL.Image.Image:
|
| 309 |
+
"""
|
| 310 |
+
Converts `image` to a PIL Image. Optionally rescales it and puts the channel dimension back as the last axis if
|
| 311 |
+
needed.
|
| 312 |
+
|
| 313 |
+
Args:
|
| 314 |
+
image (`PIL.Image.Image` or `numpy.ndarray` or `torch.Tensor`):
|
| 315 |
+
The image to convert to the PIL Image format.
|
| 316 |
+
rescale (`bool`, *optional*):
|
| 317 |
+
Whether or not to apply the scaling factor (to make pixel values integers between 0 and 255). Will
|
| 318 |
+
default to `True` if the image type is a floating type, `False` otherwise.
|
| 319 |
+
"""
|
| 320 |
+
if isinstance(image, PIL.Image.Image):
|
| 321 |
+
return image
|
| 322 |
+
if is_torch_tensor(image):
|
| 323 |
+
image = image.numpy()
|
| 324 |
+
|
| 325 |
+
if isinstance(image, np.ndarray):
|
| 326 |
+
if rescale is None:
|
| 327 |
+
# rescale default to the array being of floating type.
|
| 328 |
+
rescale = isinstance(image.flat[0], np.floating)
|
| 329 |
+
# If the channel as been moved to first dim, we put it back at the end.
|
| 330 |
+
if image.ndim == 3 and image.shape[0] in [1, 3]:
|
| 331 |
+
image = image.transpose(1, 2, 0)
|
| 332 |
+
if rescale:
|
| 333 |
+
image = image * 255
|
| 334 |
+
image = image.astype(np.uint8)
|
| 335 |
+
return PIL.Image.fromarray(image)
|
| 336 |
+
return image
|
| 337 |
+
|
| 338 |
+
def reshape_by_patch(self, image):
|
| 339 |
+
"""
|
| 340 |
+
:param image: shape [3, H, W]
|
| 341 |
+
:param patch_size:
|
| 342 |
+
:return: [3, patch_size, HW/patch_size]
|
| 343 |
+
"""
|
| 344 |
+
image = torch.from_numpy(image)
|
| 345 |
+
patch_size = self.patch_size
|
| 346 |
+
patches = torch.nn.functional.unfold(
|
| 347 |
+
image,
|
| 348 |
+
(patch_size, patch_size),
|
| 349 |
+
stride=(patch_size, patch_size)
|
| 350 |
+
)
|
| 351 |
+
|
| 352 |
+
patches = patches.reshape(image.size(0), patch_size, patch_size, -1)
|
| 353 |
+
patches = patches.permute(0, 1, 3, 2).reshape(image.size(0), patch_size, -1)
|
| 354 |
+
return patches.numpy()
|
| 355 |
+
|
| 356 |
+
def preprocess(
|
| 357 |
+
self,
|
| 358 |
+
images: Union[Image.Image, List[Image.Image], List[List[Image.Image]]],
|
| 359 |
+
do_pad: Optional[bool] = True, # TODO: add pad for MiniCPM-Llama3-V-2_5
|
| 360 |
+
max_slice_nums: int = None,
|
| 361 |
+
return_tensors: Optional[Union[str, TensorType]] = None,
|
| 362 |
+
**kwargs
|
| 363 |
+
) -> MiniCPMVBatchFeature:
|
| 364 |
+
if isinstance(images, Image.Image):
|
| 365 |
+
images_list = [[images]]
|
| 366 |
+
elif isinstance(images[0], Image.Image):
|
| 367 |
+
images_list = [images]
|
| 368 |
+
else:
|
| 369 |
+
images_list = images
|
| 370 |
+
|
| 371 |
+
new_images_list = []
|
| 372 |
+
image_sizes_list = []
|
| 373 |
+
tgt_sizes_list = []
|
| 374 |
+
|
| 375 |
+
for _images in images_list:
|
| 376 |
+
if _images is None or len(_images) == 0:
|
| 377 |
+
new_images_list.append([])
|
| 378 |
+
image_sizes_list.append([])
|
| 379 |
+
tgt_sizes_list.append([])
|
| 380 |
+
continue
|
| 381 |
+
if not valid_images(_images):
|
| 382 |
+
raise ValueError(
|
| 383 |
+
"Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
|
| 384 |
+
"torch.Tensor, tf.Tensor or jax.ndarray."
|
| 385 |
+
)
|
| 386 |
+
|
| 387 |
+
_images = [self.to_pil_image(image).convert("RGB") for image in _images]
|
| 388 |
+
input_data_format = infer_channel_dimension_format(np.array(_images[0]))
|
| 389 |
+
|
| 390 |
+
new_images = []
|
| 391 |
+
image_sizes = [image.size for image in _images]
|
| 392 |
+
tgt_sizes = []
|
| 393 |
+
for image in _images:
|
| 394 |
+
image_patches = self.get_sliced_images(image, max_slice_nums)
|
| 395 |
+
image_patches = [to_numpy_array(image).astype(np.float32) / 255 for image in image_patches]
|
| 396 |
+
image_patches = [
|
| 397 |
+
self.normalize(image=image, mean=self.mean, std=self.std, input_data_format=input_data_format)
|
| 398 |
+
for image in image_patches
|
| 399 |
+
]
|
| 400 |
+
image_patches = [
|
| 401 |
+
to_channel_dimension_format(image, ChannelDimension.FIRST, input_channel_dim=input_data_format)
|
| 402 |
+
for image in image_patches
|
| 403 |
+
]
|
| 404 |
+
for slice_image in image_patches:
|
| 405 |
+
new_images.append(self.reshape_by_patch(slice_image))
|
| 406 |
+
tgt_sizes.append(np.array((slice_image.shape[1] // self.patch_size, slice_image.shape[2] // self.patch_size)))
|
| 407 |
+
|
| 408 |
+
if tgt_sizes:
|
| 409 |
+
tgt_sizes = np.vstack(tgt_sizes)
|
| 410 |
+
|
| 411 |
+
new_images_list.append(new_images)
|
| 412 |
+
image_sizes_list.append(image_sizes)
|
| 413 |
+
tgt_sizes_list.append(tgt_sizes)
|
| 414 |
+
return MiniCPMVBatchFeature(
|
| 415 |
+
data={"pixel_values": new_images_list, "image_sizes": image_sizes_list, "tgt_sizes": tgt_sizes_list}, tensor_type=return_tensors
|
| 416 |
+
)
|
| 417 |
+
|
| 418 |
+
AutoImageProcessor.register("MiniCPMVImageProcessor", MiniCPMVImageProcessor)
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model-00004-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:364f4c1f747e4782950f915e6140e6d71187220438457d573ba2ef264fbbd97d
|
| 3 |
+
size 2060016624
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,796 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 16198350304
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"llm.lm_head.weight": "model-00004-of-00004.safetensors",
|
| 7 |
+
"llm.model.embed_tokens.weight": "model-00001-of-00004.safetensors",
|
| 8 |
+
"llm.model.layers.0.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 9 |
+
"llm.model.layers.0.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 10 |
+
"llm.model.layers.0.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 11 |
+
"llm.model.layers.0.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 12 |
+
"llm.model.layers.0.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 13 |
+
"llm.model.layers.0.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 14 |
+
"llm.model.layers.0.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 15 |
+
"llm.model.layers.0.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 16 |
+
"llm.model.layers.0.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 17 |
+
"llm.model.layers.0.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 18 |
+
"llm.model.layers.0.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 19 |
+
"llm.model.layers.0.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 20 |
+
"llm.model.layers.1.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 21 |
+
"llm.model.layers.1.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 22 |
+
"llm.model.layers.1.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 23 |
+
"llm.model.layers.1.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 24 |
+
"llm.model.layers.1.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 25 |
+
"llm.model.layers.1.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 26 |
+
"llm.model.layers.1.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 27 |
+
"llm.model.layers.1.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 28 |
+
"llm.model.layers.1.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 29 |
+
"llm.model.layers.1.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 30 |
+
"llm.model.layers.1.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 31 |
+
"llm.model.layers.1.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 32 |
+
"llm.model.layers.10.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 33 |
+
"llm.model.layers.10.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 34 |
+
"llm.model.layers.10.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 35 |
+
"llm.model.layers.10.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 36 |
+
"llm.model.layers.10.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 37 |
+
"llm.model.layers.10.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 38 |
+
"llm.model.layers.10.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 39 |
+
"llm.model.layers.10.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 40 |
+
"llm.model.layers.10.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 41 |
+
"llm.model.layers.10.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 42 |
+
"llm.model.layers.10.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 43 |
+
"llm.model.layers.10.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 44 |
+
"llm.model.layers.11.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 45 |
+
"llm.model.layers.11.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 46 |
+
"llm.model.layers.11.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 47 |
+
"llm.model.layers.11.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 48 |
+
"llm.model.layers.11.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 49 |
+
"llm.model.layers.11.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 50 |
+
"llm.model.layers.11.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 51 |
+
"llm.model.layers.11.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 52 |
+
"llm.model.layers.11.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 53 |
+
"llm.model.layers.11.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 54 |
+
"llm.model.layers.11.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 55 |
+
"llm.model.layers.11.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 56 |
+
"llm.model.layers.12.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 57 |
+
"llm.model.layers.12.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 58 |
+
"llm.model.layers.12.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 59 |
+
"llm.model.layers.12.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 60 |
+
"llm.model.layers.12.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 61 |
+
"llm.model.layers.12.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 62 |
+
"llm.model.layers.12.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 63 |
+
"llm.model.layers.12.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 64 |
+
"llm.model.layers.12.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 65 |
+
"llm.model.layers.12.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 66 |
+
"llm.model.layers.12.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 67 |
+
"llm.model.layers.12.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 68 |
+
"llm.model.layers.13.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 69 |
+
"llm.model.layers.13.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 70 |
+
"llm.model.layers.13.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 71 |
+
"llm.model.layers.13.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 72 |
+
"llm.model.layers.13.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 73 |
+
"llm.model.layers.13.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 74 |
+
"llm.model.layers.13.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 75 |
+
"llm.model.layers.13.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 76 |
+
"llm.model.layers.13.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 77 |
+
"llm.model.layers.13.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 78 |
+
"llm.model.layers.13.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 79 |
+
"llm.model.layers.13.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 80 |
+
"llm.model.layers.14.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 81 |
+
"llm.model.layers.14.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 82 |
+
"llm.model.layers.14.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 83 |
+
"llm.model.layers.14.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 84 |
+
"llm.model.layers.14.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 85 |
+
"llm.model.layers.14.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 86 |
+
"llm.model.layers.14.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 87 |
+
"llm.model.layers.14.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 88 |
+
"llm.model.layers.14.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 89 |
+
"llm.model.layers.14.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 90 |
+
"llm.model.layers.14.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 91 |
+
"llm.model.layers.14.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 92 |
+
"llm.model.layers.15.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 93 |
+
"llm.model.layers.15.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 94 |
+
"llm.model.layers.15.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 95 |
+
"llm.model.layers.15.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 96 |
+
"llm.model.layers.15.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 97 |
+
"llm.model.layers.15.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 98 |
+
"llm.model.layers.15.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 99 |
+
"llm.model.layers.15.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 100 |
+
"llm.model.layers.15.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 101 |
+
"llm.model.layers.15.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 102 |
+
"llm.model.layers.15.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 103 |
+
"llm.model.layers.15.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 104 |
+
"llm.model.layers.16.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 105 |
+
"llm.model.layers.16.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 106 |
+
"llm.model.layers.16.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 107 |
+
"llm.model.layers.16.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 108 |
+
"llm.model.layers.16.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 109 |
+
"llm.model.layers.16.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 110 |
+
"llm.model.layers.16.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 111 |
+
"llm.model.layers.16.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 112 |
+
"llm.model.layers.16.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 113 |
+
"llm.model.layers.16.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 114 |
+
"llm.model.layers.16.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 115 |
+
"llm.model.layers.16.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 116 |
+
"llm.model.layers.17.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 117 |
+
"llm.model.layers.17.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 118 |
+
"llm.model.layers.17.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 119 |
+
"llm.model.layers.17.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 120 |
+
"llm.model.layers.17.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 121 |
+
"llm.model.layers.17.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 122 |
+
"llm.model.layers.17.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 123 |
+
"llm.model.layers.17.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 124 |
+
"llm.model.layers.17.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 125 |
+
"llm.model.layers.17.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 126 |
+
"llm.model.layers.17.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 127 |
+
"llm.model.layers.17.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 128 |
+
"llm.model.layers.18.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 129 |
+
"llm.model.layers.18.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 130 |
+
"llm.model.layers.18.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 131 |
+
"llm.model.layers.18.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 132 |
+
"llm.model.layers.18.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 133 |
+
"llm.model.layers.18.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 134 |
+
"llm.model.layers.18.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 135 |
+
"llm.model.layers.18.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 136 |
+
"llm.model.layers.18.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 137 |
+
"llm.model.layers.18.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 138 |
+
"llm.model.layers.18.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 139 |
+
"llm.model.layers.18.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 140 |
+
"llm.model.layers.19.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 141 |
+
"llm.model.layers.19.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 142 |
+
"llm.model.layers.19.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 143 |
+
"llm.model.layers.19.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 144 |
+
"llm.model.layers.19.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 145 |
+
"llm.model.layers.19.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 146 |
+
"llm.model.layers.19.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 147 |
+
"llm.model.layers.19.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 148 |
+
"llm.model.layers.19.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 149 |
+
"llm.model.layers.19.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 150 |
+
"llm.model.layers.19.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 151 |
+
"llm.model.layers.19.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 152 |
+
"llm.model.layers.2.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 153 |
+
"llm.model.layers.2.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 154 |
+
"llm.model.layers.2.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 155 |
+
"llm.model.layers.2.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 156 |
+
"llm.model.layers.2.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 157 |
+
"llm.model.layers.2.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 158 |
+
"llm.model.layers.2.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 159 |
+
"llm.model.layers.2.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 160 |
+
"llm.model.layers.2.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 161 |
+
"llm.model.layers.2.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 162 |
+
"llm.model.layers.2.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 163 |
+
"llm.model.layers.2.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 164 |
+
"llm.model.layers.20.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 165 |
+
"llm.model.layers.20.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 166 |
+
"llm.model.layers.20.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 167 |
+
"llm.model.layers.20.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 168 |
+
"llm.model.layers.20.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 169 |
+
"llm.model.layers.20.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 170 |
+
"llm.model.layers.20.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 171 |
+
"llm.model.layers.20.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 172 |
+
"llm.model.layers.20.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 173 |
+
"llm.model.layers.20.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 174 |
+
"llm.model.layers.20.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 175 |
+
"llm.model.layers.20.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 176 |
+
"llm.model.layers.21.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 177 |
+
"llm.model.layers.21.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 178 |
+
"llm.model.layers.21.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 179 |
+
"llm.model.layers.21.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 180 |
+
"llm.model.layers.21.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 181 |
+
"llm.model.layers.21.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 182 |
+
"llm.model.layers.21.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 183 |
+
"llm.model.layers.21.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 184 |
+
"llm.model.layers.21.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 185 |
+
"llm.model.layers.21.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 186 |
+
"llm.model.layers.21.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 187 |
+
"llm.model.layers.21.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 188 |
+
"llm.model.layers.22.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 189 |
+
"llm.model.layers.22.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 190 |
+
"llm.model.layers.22.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 191 |
+
"llm.model.layers.22.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 192 |
+
"llm.model.layers.22.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 193 |
+
"llm.model.layers.22.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 194 |
+
"llm.model.layers.22.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 195 |
+
"llm.model.layers.22.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 196 |
+
"llm.model.layers.22.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 197 |
+
"llm.model.layers.22.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 198 |
+
"llm.model.layers.22.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 199 |
+
"llm.model.layers.22.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 200 |
+
"llm.model.layers.23.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 201 |
+
"llm.model.layers.23.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 202 |
+
"llm.model.layers.23.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 203 |
+
"llm.model.layers.23.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 204 |
+
"llm.model.layers.23.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 205 |
+
"llm.model.layers.23.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 206 |
+
"llm.model.layers.23.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 207 |
+
"llm.model.layers.23.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 208 |
+
"llm.model.layers.23.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 209 |
+
"llm.model.layers.23.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 210 |
+
"llm.model.layers.23.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 211 |
+
"llm.model.layers.23.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 212 |
+
"llm.model.layers.24.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 213 |
+
"llm.model.layers.24.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 214 |
+
"llm.model.layers.24.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 215 |
+
"llm.model.layers.24.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 216 |
+
"llm.model.layers.24.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 217 |
+
"llm.model.layers.24.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 218 |
+
"llm.model.layers.24.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 219 |
+
"llm.model.layers.24.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 220 |
+
"llm.model.layers.24.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 221 |
+
"llm.model.layers.24.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 222 |
+
"llm.model.layers.24.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 223 |
+
"llm.model.layers.24.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 224 |
+
"llm.model.layers.25.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 225 |
+
"llm.model.layers.25.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 226 |
+
"llm.model.layers.25.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 227 |
+
"llm.model.layers.25.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 228 |
+
"llm.model.layers.25.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 229 |
+
"llm.model.layers.25.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 230 |
+
"llm.model.layers.25.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 231 |
+
"llm.model.layers.25.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 232 |
+
"llm.model.layers.25.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 233 |
+
"llm.model.layers.25.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 234 |
+
"llm.model.layers.25.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 235 |
+
"llm.model.layers.25.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 236 |
+
"llm.model.layers.26.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 237 |
+
"llm.model.layers.26.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 238 |
+
"llm.model.layers.26.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 239 |
+
"llm.model.layers.26.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 240 |
+
"llm.model.layers.26.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 241 |
+
"llm.model.layers.26.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 242 |
+
"llm.model.layers.26.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 243 |
+
"llm.model.layers.26.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 244 |
+
"llm.model.layers.26.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 245 |
+
"llm.model.layers.26.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 246 |
+
"llm.model.layers.26.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 247 |
+
"llm.model.layers.26.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 248 |
+
"llm.model.layers.27.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 249 |
+
"llm.model.layers.27.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 250 |
+
"llm.model.layers.27.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 251 |
+
"llm.model.layers.27.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 252 |
+
"llm.model.layers.27.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 253 |
+
"llm.model.layers.27.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 254 |
+
"llm.model.layers.27.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 255 |
+
"llm.model.layers.27.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 256 |
+
"llm.model.layers.27.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 257 |
+
"llm.model.layers.27.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 258 |
+
"llm.model.layers.27.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 259 |
+
"llm.model.layers.27.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 260 |
+
"llm.model.layers.3.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 261 |
+
"llm.model.layers.3.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 262 |
+
"llm.model.layers.3.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 263 |
+
"llm.model.layers.3.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 264 |
+
"llm.model.layers.3.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 265 |
+
"llm.model.layers.3.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 266 |
+
"llm.model.layers.3.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 267 |
+
"llm.model.layers.3.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 268 |
+
"llm.model.layers.3.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 269 |
+
"llm.model.layers.3.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 270 |
+
"llm.model.layers.3.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 271 |
+
"llm.model.layers.3.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 272 |
+
"llm.model.layers.4.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 273 |
+
"llm.model.layers.4.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 274 |
+
"llm.model.layers.4.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 275 |
+
"llm.model.layers.4.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 276 |
+
"llm.model.layers.4.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 277 |
+
"llm.model.layers.4.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 278 |
+
"llm.model.layers.4.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 279 |
+
"llm.model.layers.4.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 280 |
+
"llm.model.layers.4.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 281 |
+
"llm.model.layers.4.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 282 |
+
"llm.model.layers.4.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 283 |
+
"llm.model.layers.4.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 284 |
+
"llm.model.layers.5.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 285 |
+
"llm.model.layers.5.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 286 |
+
"llm.model.layers.5.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 287 |
+
"llm.model.layers.5.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 288 |
+
"llm.model.layers.5.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 289 |
+
"llm.model.layers.5.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 290 |
+
"llm.model.layers.5.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 291 |
+
"llm.model.layers.5.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 292 |
+
"llm.model.layers.5.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 293 |
+
"llm.model.layers.5.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 294 |
+
"llm.model.layers.5.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 295 |
+
"llm.model.layers.5.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 296 |
+
"llm.model.layers.6.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 297 |
+
"llm.model.layers.6.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 298 |
+
"llm.model.layers.6.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 299 |
+
"llm.model.layers.6.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 300 |
+
"llm.model.layers.6.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 301 |
+
"llm.model.layers.6.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 302 |
+
"llm.model.layers.6.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 303 |
+
"llm.model.layers.6.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 304 |
+
"llm.model.layers.6.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 305 |
+
"llm.model.layers.6.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 306 |
+
"llm.model.layers.6.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 307 |
+
"llm.model.layers.6.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 308 |
+
"llm.model.layers.7.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 309 |
+
"llm.model.layers.7.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 310 |
+
"llm.model.layers.7.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 311 |
+
"llm.model.layers.7.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 312 |
+
"llm.model.layers.7.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 313 |
+
"llm.model.layers.7.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 314 |
+
"llm.model.layers.7.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 315 |
+
"llm.model.layers.7.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 316 |
+
"llm.model.layers.7.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 317 |
+
"llm.model.layers.7.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 318 |
+
"llm.model.layers.7.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 319 |
+
"llm.model.layers.7.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 320 |
+
"llm.model.layers.8.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 321 |
+
"llm.model.layers.8.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 322 |
+
"llm.model.layers.8.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 323 |
+
"llm.model.layers.8.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 324 |
+
"llm.model.layers.8.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 325 |
+
"llm.model.layers.8.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 326 |
+
"llm.model.layers.8.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 327 |
+
"llm.model.layers.8.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 328 |
+
"llm.model.layers.8.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 329 |
+
"llm.model.layers.8.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 330 |
+
"llm.model.layers.8.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 331 |
+
"llm.model.layers.8.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 332 |
+
"llm.model.layers.9.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 333 |
+
"llm.model.layers.9.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 334 |
+
"llm.model.layers.9.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 335 |
+
"llm.model.layers.9.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 336 |
+
"llm.model.layers.9.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 337 |
+
"llm.model.layers.9.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 338 |
+
"llm.model.layers.9.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 339 |
+
"llm.model.layers.9.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 340 |
+
"llm.model.layers.9.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 341 |
+
"llm.model.layers.9.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 342 |
+
"llm.model.layers.9.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 343 |
+
"llm.model.layers.9.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 344 |
+
"llm.model.norm.weight": "model-00003-of-00004.safetensors",
|
| 345 |
+
"resampler.attn.in_proj_bias": "model-00004-of-00004.safetensors",
|
| 346 |
+
"resampler.attn.in_proj_weight": "model-00004-of-00004.safetensors",
|
| 347 |
+
"resampler.attn.out_proj.bias": "model-00004-of-00004.safetensors",
|
| 348 |
+
"resampler.attn.out_proj.weight": "model-00004-of-00004.safetensors",
|
| 349 |
+
"resampler.kv_proj.weight": "model-00004-of-00004.safetensors",
|
| 350 |
+
"resampler.ln_kv.bias": "model-00004-of-00004.safetensors",
|
| 351 |
+
"resampler.ln_kv.weight": "model-00004-of-00004.safetensors",
|
| 352 |
+
"resampler.ln_post.bias": "model-00004-of-00004.safetensors",
|
| 353 |
+
"resampler.ln_post.weight": "model-00004-of-00004.safetensors",
|
| 354 |
+
"resampler.ln_q.bias": "model-00004-of-00004.safetensors",
|
| 355 |
+
"resampler.ln_q.weight": "model-00004-of-00004.safetensors",
|
| 356 |
+
"resampler.proj": "model-00004-of-00004.safetensors",
|
| 357 |
+
"resampler.query": "model-00004-of-00004.safetensors",
|
| 358 |
+
"vpm.embeddings.patch_embedding.bias": "model-00004-of-00004.safetensors",
|
| 359 |
+
"vpm.embeddings.patch_embedding.weight": "model-00004-of-00004.safetensors",
|
| 360 |
+
"vpm.embeddings.position_embedding.weight": "model-00004-of-00004.safetensors",
|
| 361 |
+
"vpm.encoder.layers.0.layer_norm1.bias": "model-00004-of-00004.safetensors",
|
| 362 |
+
"vpm.encoder.layers.0.layer_norm1.weight": "model-00004-of-00004.safetensors",
|
| 363 |
+
"vpm.encoder.layers.0.layer_norm2.bias": "model-00004-of-00004.safetensors",
|
| 364 |
+
"vpm.encoder.layers.0.layer_norm2.weight": "model-00004-of-00004.safetensors",
|
| 365 |
+
"vpm.encoder.layers.0.mlp.fc1.bias": "model-00004-of-00004.safetensors",
|
| 366 |
+
"vpm.encoder.layers.0.mlp.fc1.weight": "model-00004-of-00004.safetensors",
|
| 367 |
+
"vpm.encoder.layers.0.mlp.fc2.bias": "model-00004-of-00004.safetensors",
|
| 368 |
+
"vpm.encoder.layers.0.mlp.fc2.weight": "model-00004-of-00004.safetensors",
|
| 369 |
+
"vpm.encoder.layers.0.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
| 370 |
+
"vpm.encoder.layers.0.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 371 |
+
"vpm.encoder.layers.0.self_attn.out_proj.bias": "model-00004-of-00004.safetensors",
|
| 372 |
+
"vpm.encoder.layers.0.self_attn.out_proj.weight": "model-00004-of-00004.safetensors",
|
| 373 |
+
"vpm.encoder.layers.0.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
| 374 |
+
"vpm.encoder.layers.0.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 375 |
+
"vpm.encoder.layers.0.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
| 376 |
+
"vpm.encoder.layers.0.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 377 |
+
"vpm.encoder.layers.1.layer_norm1.bias": "model-00004-of-00004.safetensors",
|
| 378 |
+
"vpm.encoder.layers.1.layer_norm1.weight": "model-00004-of-00004.safetensors",
|
| 379 |
+
"vpm.encoder.layers.1.layer_norm2.bias": "model-00004-of-00004.safetensors",
|
| 380 |
+
"vpm.encoder.layers.1.layer_norm2.weight": "model-00004-of-00004.safetensors",
|
| 381 |
+
"vpm.encoder.layers.1.mlp.fc1.bias": "model-00004-of-00004.safetensors",
|
| 382 |
+
"vpm.encoder.layers.1.mlp.fc1.weight": "model-00004-of-00004.safetensors",
|
| 383 |
+
"vpm.encoder.layers.1.mlp.fc2.bias": "model-00004-of-00004.safetensors",
|
| 384 |
+
"vpm.encoder.layers.1.mlp.fc2.weight": "model-00004-of-00004.safetensors",
|
| 385 |
+
"vpm.encoder.layers.1.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
| 386 |
+
"vpm.encoder.layers.1.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 387 |
+
"vpm.encoder.layers.1.self_attn.out_proj.bias": "model-00004-of-00004.safetensors",
|
| 388 |
+
"vpm.encoder.layers.1.self_attn.out_proj.weight": "model-00004-of-00004.safetensors",
|
| 389 |
+
"vpm.encoder.layers.1.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
| 390 |
+
"vpm.encoder.layers.1.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 391 |
+
"vpm.encoder.layers.1.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
| 392 |
+
"vpm.encoder.layers.1.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 393 |
+
"vpm.encoder.layers.10.layer_norm1.bias": "model-00004-of-00004.safetensors",
|
| 394 |
+
"vpm.encoder.layers.10.layer_norm1.weight": "model-00004-of-00004.safetensors",
|
| 395 |
+
"vpm.encoder.layers.10.layer_norm2.bias": "model-00004-of-00004.safetensors",
|
| 396 |
+
"vpm.encoder.layers.10.layer_norm2.weight": "model-00004-of-00004.safetensors",
|
| 397 |
+
"vpm.encoder.layers.10.mlp.fc1.bias": "model-00004-of-00004.safetensors",
|
| 398 |
+
"vpm.encoder.layers.10.mlp.fc1.weight": "model-00004-of-00004.safetensors",
|
| 399 |
+
"vpm.encoder.layers.10.mlp.fc2.bias": "model-00004-of-00004.safetensors",
|
| 400 |
+
"vpm.encoder.layers.10.mlp.fc2.weight": "model-00004-of-00004.safetensors",
|
| 401 |
+
"vpm.encoder.layers.10.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
| 402 |
+
"vpm.encoder.layers.10.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 403 |
+
"vpm.encoder.layers.10.self_attn.out_proj.bias": "model-00004-of-00004.safetensors",
|
| 404 |
+
"vpm.encoder.layers.10.self_attn.out_proj.weight": "model-00004-of-00004.safetensors",
|
| 405 |
+
"vpm.encoder.layers.10.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
| 406 |
+
"vpm.encoder.layers.10.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 407 |
+
"vpm.encoder.layers.10.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
| 408 |
+
"vpm.encoder.layers.10.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 409 |
+
"vpm.encoder.layers.11.layer_norm1.bias": "model-00004-of-00004.safetensors",
|
| 410 |
+
"vpm.encoder.layers.11.layer_norm1.weight": "model-00004-of-00004.safetensors",
|
| 411 |
+
"vpm.encoder.layers.11.layer_norm2.bias": "model-00004-of-00004.safetensors",
|
| 412 |
+
"vpm.encoder.layers.11.layer_norm2.weight": "model-00004-of-00004.safetensors",
|
| 413 |
+
"vpm.encoder.layers.11.mlp.fc1.bias": "model-00004-of-00004.safetensors",
|
| 414 |
+
"vpm.encoder.layers.11.mlp.fc1.weight": "model-00004-of-00004.safetensors",
|
| 415 |
+
"vpm.encoder.layers.11.mlp.fc2.bias": "model-00004-of-00004.safetensors",
|
| 416 |
+
"vpm.encoder.layers.11.mlp.fc2.weight": "model-00004-of-00004.safetensors",
|
| 417 |
+
"vpm.encoder.layers.11.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
| 418 |
+
"vpm.encoder.layers.11.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 419 |
+
"vpm.encoder.layers.11.self_attn.out_proj.bias": "model-00004-of-00004.safetensors",
|
| 420 |
+
"vpm.encoder.layers.11.self_attn.out_proj.weight": "model-00004-of-00004.safetensors",
|
| 421 |
+
"vpm.encoder.layers.11.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
| 422 |
+
"vpm.encoder.layers.11.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 423 |
+
"vpm.encoder.layers.11.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
| 424 |
+
"vpm.encoder.layers.11.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 425 |
+
"vpm.encoder.layers.12.layer_norm1.bias": "model-00004-of-00004.safetensors",
|
| 426 |
+
"vpm.encoder.layers.12.layer_norm1.weight": "model-00004-of-00004.safetensors",
|
| 427 |
+
"vpm.encoder.layers.12.layer_norm2.bias": "model-00004-of-00004.safetensors",
|
| 428 |
+
"vpm.encoder.layers.12.layer_norm2.weight": "model-00004-of-00004.safetensors",
|
| 429 |
+
"vpm.encoder.layers.12.mlp.fc1.bias": "model-00004-of-00004.safetensors",
|
| 430 |
+
"vpm.encoder.layers.12.mlp.fc1.weight": "model-00004-of-00004.safetensors",
|
| 431 |
+
"vpm.encoder.layers.12.mlp.fc2.bias": "model-00004-of-00004.safetensors",
|
| 432 |
+
"vpm.encoder.layers.12.mlp.fc2.weight": "model-00004-of-00004.safetensors",
|
| 433 |
+
"vpm.encoder.layers.12.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
| 434 |
+
"vpm.encoder.layers.12.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 435 |
+
"vpm.encoder.layers.12.self_attn.out_proj.bias": "model-00004-of-00004.safetensors",
|
| 436 |
+
"vpm.encoder.layers.12.self_attn.out_proj.weight": "model-00004-of-00004.safetensors",
|
| 437 |
+
"vpm.encoder.layers.12.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
| 438 |
+
"vpm.encoder.layers.12.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 439 |
+
"vpm.encoder.layers.12.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
| 440 |
+
"vpm.encoder.layers.12.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 441 |
+
"vpm.encoder.layers.13.layer_norm1.bias": "model-00004-of-00004.safetensors",
|
| 442 |
+
"vpm.encoder.layers.13.layer_norm1.weight": "model-00004-of-00004.safetensors",
|
| 443 |
+
"vpm.encoder.layers.13.layer_norm2.bias": "model-00004-of-00004.safetensors",
|
| 444 |
+
"vpm.encoder.layers.13.layer_norm2.weight": "model-00004-of-00004.safetensors",
|
| 445 |
+
"vpm.encoder.layers.13.mlp.fc1.bias": "model-00004-of-00004.safetensors",
|
| 446 |
+
"vpm.encoder.layers.13.mlp.fc1.weight": "model-00004-of-00004.safetensors",
|
| 447 |
+
"vpm.encoder.layers.13.mlp.fc2.bias": "model-00004-of-00004.safetensors",
|
| 448 |
+
"vpm.encoder.layers.13.mlp.fc2.weight": "model-00004-of-00004.safetensors",
|
| 449 |
+
"vpm.encoder.layers.13.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
| 450 |
+
"vpm.encoder.layers.13.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 451 |
+
"vpm.encoder.layers.13.self_attn.out_proj.bias": "model-00004-of-00004.safetensors",
|
| 452 |
+
"vpm.encoder.layers.13.self_attn.out_proj.weight": "model-00004-of-00004.safetensors",
|
| 453 |
+
"vpm.encoder.layers.13.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
| 454 |
+
"vpm.encoder.layers.13.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 455 |
+
"vpm.encoder.layers.13.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
| 456 |
+
"vpm.encoder.layers.13.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 457 |
+
"vpm.encoder.layers.14.layer_norm1.bias": "model-00004-of-00004.safetensors",
|
| 458 |
+
"vpm.encoder.layers.14.layer_norm1.weight": "model-00004-of-00004.safetensors",
|
| 459 |
+
"vpm.encoder.layers.14.layer_norm2.bias": "model-00004-of-00004.safetensors",
|
| 460 |
+
"vpm.encoder.layers.14.layer_norm2.weight": "model-00004-of-00004.safetensors",
|
| 461 |
+
"vpm.encoder.layers.14.mlp.fc1.bias": "model-00004-of-00004.safetensors",
|
| 462 |
+
"vpm.encoder.layers.14.mlp.fc1.weight": "model-00004-of-00004.safetensors",
|
| 463 |
+
"vpm.encoder.layers.14.mlp.fc2.bias": "model-00004-of-00004.safetensors",
|
| 464 |
+
"vpm.encoder.layers.14.mlp.fc2.weight": "model-00004-of-00004.safetensors",
|
| 465 |
+
"vpm.encoder.layers.14.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
| 466 |
+
"vpm.encoder.layers.14.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 467 |
+
"vpm.encoder.layers.14.self_attn.out_proj.bias": "model-00004-of-00004.safetensors",
|
| 468 |
+
"vpm.encoder.layers.14.self_attn.out_proj.weight": "model-00004-of-00004.safetensors",
|
| 469 |
+
"vpm.encoder.layers.14.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
| 470 |
+
"vpm.encoder.layers.14.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 471 |
+
"vpm.encoder.layers.14.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
| 472 |
+
"vpm.encoder.layers.14.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 473 |
+
"vpm.encoder.layers.15.layer_norm1.bias": "model-00004-of-00004.safetensors",
|
| 474 |
+
"vpm.encoder.layers.15.layer_norm1.weight": "model-00004-of-00004.safetensors",
|
| 475 |
+
"vpm.encoder.layers.15.layer_norm2.bias": "model-00004-of-00004.safetensors",
|
| 476 |
+
"vpm.encoder.layers.15.layer_norm2.weight": "model-00004-of-00004.safetensors",
|
| 477 |
+
"vpm.encoder.layers.15.mlp.fc1.bias": "model-00004-of-00004.safetensors",
|
| 478 |
+
"vpm.encoder.layers.15.mlp.fc1.weight": "model-00004-of-00004.safetensors",
|
| 479 |
+
"vpm.encoder.layers.15.mlp.fc2.bias": "model-00004-of-00004.safetensors",
|
| 480 |
+
"vpm.encoder.layers.15.mlp.fc2.weight": "model-00004-of-00004.safetensors",
|
| 481 |
+
"vpm.encoder.layers.15.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
| 482 |
+
"vpm.encoder.layers.15.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 483 |
+
"vpm.encoder.layers.15.self_attn.out_proj.bias": "model-00004-of-00004.safetensors",
|
| 484 |
+
"vpm.encoder.layers.15.self_attn.out_proj.weight": "model-00004-of-00004.safetensors",
|
| 485 |
+
"vpm.encoder.layers.15.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
| 486 |
+
"vpm.encoder.layers.15.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 487 |
+
"vpm.encoder.layers.15.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
| 488 |
+
"vpm.encoder.layers.15.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 489 |
+
"vpm.encoder.layers.16.layer_norm1.bias": "model-00004-of-00004.safetensors",
|
| 490 |
+
"vpm.encoder.layers.16.layer_norm1.weight": "model-00004-of-00004.safetensors",
|
| 491 |
+
"vpm.encoder.layers.16.layer_norm2.bias": "model-00004-of-00004.safetensors",
|
| 492 |
+
"vpm.encoder.layers.16.layer_norm2.weight": "model-00004-of-00004.safetensors",
|
| 493 |
+
"vpm.encoder.layers.16.mlp.fc1.bias": "model-00004-of-00004.safetensors",
|
| 494 |
+
"vpm.encoder.layers.16.mlp.fc1.weight": "model-00004-of-00004.safetensors",
|
| 495 |
+
"vpm.encoder.layers.16.mlp.fc2.bias": "model-00004-of-00004.safetensors",
|
| 496 |
+
"vpm.encoder.layers.16.mlp.fc2.weight": "model-00004-of-00004.safetensors",
|
| 497 |
+
"vpm.encoder.layers.16.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
| 498 |
+
"vpm.encoder.layers.16.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 499 |
+
"vpm.encoder.layers.16.self_attn.out_proj.bias": "model-00004-of-00004.safetensors",
|
| 500 |
+
"vpm.encoder.layers.16.self_attn.out_proj.weight": "model-00004-of-00004.safetensors",
|
| 501 |
+
"vpm.encoder.layers.16.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
| 502 |
+
"vpm.encoder.layers.16.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 503 |
+
"vpm.encoder.layers.16.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
| 504 |
+
"vpm.encoder.layers.16.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 505 |
+
"vpm.encoder.layers.17.layer_norm1.bias": "model-00004-of-00004.safetensors",
|
| 506 |
+
"vpm.encoder.layers.17.layer_norm1.weight": "model-00004-of-00004.safetensors",
|
| 507 |
+
"vpm.encoder.layers.17.layer_norm2.bias": "model-00004-of-00004.safetensors",
|
| 508 |
+
"vpm.encoder.layers.17.layer_norm2.weight": "model-00004-of-00004.safetensors",
|
| 509 |
+
"vpm.encoder.layers.17.mlp.fc1.bias": "model-00004-of-00004.safetensors",
|
| 510 |
+
"vpm.encoder.layers.17.mlp.fc1.weight": "model-00004-of-00004.safetensors",
|
| 511 |
+
"vpm.encoder.layers.17.mlp.fc2.bias": "model-00004-of-00004.safetensors",
|
| 512 |
+
"vpm.encoder.layers.17.mlp.fc2.weight": "model-00004-of-00004.safetensors",
|
| 513 |
+
"vpm.encoder.layers.17.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
| 514 |
+
"vpm.encoder.layers.17.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 515 |
+
"vpm.encoder.layers.17.self_attn.out_proj.bias": "model-00004-of-00004.safetensors",
|
| 516 |
+
"vpm.encoder.layers.17.self_attn.out_proj.weight": "model-00004-of-00004.safetensors",
|
| 517 |
+
"vpm.encoder.layers.17.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
| 518 |
+
"vpm.encoder.layers.17.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 519 |
+
"vpm.encoder.layers.17.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
| 520 |
+
"vpm.encoder.layers.17.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 521 |
+
"vpm.encoder.layers.18.layer_norm1.bias": "model-00004-of-00004.safetensors",
|
| 522 |
+
"vpm.encoder.layers.18.layer_norm1.weight": "model-00004-of-00004.safetensors",
|
| 523 |
+
"vpm.encoder.layers.18.layer_norm2.bias": "model-00004-of-00004.safetensors",
|
| 524 |
+
"vpm.encoder.layers.18.layer_norm2.weight": "model-00004-of-00004.safetensors",
|
| 525 |
+
"vpm.encoder.layers.18.mlp.fc1.bias": "model-00004-of-00004.safetensors",
|
| 526 |
+
"vpm.encoder.layers.18.mlp.fc1.weight": "model-00004-of-00004.safetensors",
|
| 527 |
+
"vpm.encoder.layers.18.mlp.fc2.bias": "model-00004-of-00004.safetensors",
|
| 528 |
+
"vpm.encoder.layers.18.mlp.fc2.weight": "model-00004-of-00004.safetensors",
|
| 529 |
+
"vpm.encoder.layers.18.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
| 530 |
+
"vpm.encoder.layers.18.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 531 |
+
"vpm.encoder.layers.18.self_attn.out_proj.bias": "model-00004-of-00004.safetensors",
|
| 532 |
+
"vpm.encoder.layers.18.self_attn.out_proj.weight": "model-00004-of-00004.safetensors",
|
| 533 |
+
"vpm.encoder.layers.18.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
| 534 |
+
"vpm.encoder.layers.18.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 535 |
+
"vpm.encoder.layers.18.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
| 536 |
+
"vpm.encoder.layers.18.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 537 |
+
"vpm.encoder.layers.19.layer_norm1.bias": "model-00004-of-00004.safetensors",
|
| 538 |
+
"vpm.encoder.layers.19.layer_norm1.weight": "model-00004-of-00004.safetensors",
|
| 539 |
+
"vpm.encoder.layers.19.layer_norm2.bias": "model-00004-of-00004.safetensors",
|
| 540 |
+
"vpm.encoder.layers.19.layer_norm2.weight": "model-00004-of-00004.safetensors",
|
| 541 |
+
"vpm.encoder.layers.19.mlp.fc1.bias": "model-00004-of-00004.safetensors",
|
| 542 |
+
"vpm.encoder.layers.19.mlp.fc1.weight": "model-00004-of-00004.safetensors",
|
| 543 |
+
"vpm.encoder.layers.19.mlp.fc2.bias": "model-00004-of-00004.safetensors",
|
| 544 |
+
"vpm.encoder.layers.19.mlp.fc2.weight": "model-00004-of-00004.safetensors",
|
| 545 |
+
"vpm.encoder.layers.19.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
| 546 |
+
"vpm.encoder.layers.19.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 547 |
+
"vpm.encoder.layers.19.self_attn.out_proj.bias": "model-00004-of-00004.safetensors",
|
| 548 |
+
"vpm.encoder.layers.19.self_attn.out_proj.weight": "model-00004-of-00004.safetensors",
|
| 549 |
+
"vpm.encoder.layers.19.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
| 550 |
+
"vpm.encoder.layers.19.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 551 |
+
"vpm.encoder.layers.19.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
| 552 |
+
"vpm.encoder.layers.19.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 553 |
+
"vpm.encoder.layers.2.layer_norm1.bias": "model-00004-of-00004.safetensors",
|
| 554 |
+
"vpm.encoder.layers.2.layer_norm1.weight": "model-00004-of-00004.safetensors",
|
| 555 |
+
"vpm.encoder.layers.2.layer_norm2.bias": "model-00004-of-00004.safetensors",
|
| 556 |
+
"vpm.encoder.layers.2.layer_norm2.weight": "model-00004-of-00004.safetensors",
|
| 557 |
+
"vpm.encoder.layers.2.mlp.fc1.bias": "model-00004-of-00004.safetensors",
|
| 558 |
+
"vpm.encoder.layers.2.mlp.fc1.weight": "model-00004-of-00004.safetensors",
|
| 559 |
+
"vpm.encoder.layers.2.mlp.fc2.bias": "model-00004-of-00004.safetensors",
|
| 560 |
+
"vpm.encoder.layers.2.mlp.fc2.weight": "model-00004-of-00004.safetensors",
|
| 561 |
+
"vpm.encoder.layers.2.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
| 562 |
+
"vpm.encoder.layers.2.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 563 |
+
"vpm.encoder.layers.2.self_attn.out_proj.bias": "model-00004-of-00004.safetensors",
|
| 564 |
+
"vpm.encoder.layers.2.self_attn.out_proj.weight": "model-00004-of-00004.safetensors",
|
| 565 |
+
"vpm.encoder.layers.2.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
| 566 |
+
"vpm.encoder.layers.2.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 567 |
+
"vpm.encoder.layers.2.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
| 568 |
+
"vpm.encoder.layers.2.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 569 |
+
"vpm.encoder.layers.20.layer_norm1.bias": "model-00004-of-00004.safetensors",
|
| 570 |
+
"vpm.encoder.layers.20.layer_norm1.weight": "model-00004-of-00004.safetensors",
|
| 571 |
+
"vpm.encoder.layers.20.layer_norm2.bias": "model-00004-of-00004.safetensors",
|
| 572 |
+
"vpm.encoder.layers.20.layer_norm2.weight": "model-00004-of-00004.safetensors",
|
| 573 |
+
"vpm.encoder.layers.20.mlp.fc1.bias": "model-00004-of-00004.safetensors",
|
| 574 |
+
"vpm.encoder.layers.20.mlp.fc1.weight": "model-00004-of-00004.safetensors",
|
| 575 |
+
"vpm.encoder.layers.20.mlp.fc2.bias": "model-00004-of-00004.safetensors",
|
| 576 |
+
"vpm.encoder.layers.20.mlp.fc2.weight": "model-00004-of-00004.safetensors",
|
| 577 |
+
"vpm.encoder.layers.20.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
| 578 |
+
"vpm.encoder.layers.20.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 579 |
+
"vpm.encoder.layers.20.self_attn.out_proj.bias": "model-00004-of-00004.safetensors",
|
| 580 |
+
"vpm.encoder.layers.20.self_attn.out_proj.weight": "model-00004-of-00004.safetensors",
|
| 581 |
+
"vpm.encoder.layers.20.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
| 582 |
+
"vpm.encoder.layers.20.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 583 |
+
"vpm.encoder.layers.20.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
| 584 |
+
"vpm.encoder.layers.20.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 585 |
+
"vpm.encoder.layers.21.layer_norm1.bias": "model-00004-of-00004.safetensors",
|
| 586 |
+
"vpm.encoder.layers.21.layer_norm1.weight": "model-00004-of-00004.safetensors",
|
| 587 |
+
"vpm.encoder.layers.21.layer_norm2.bias": "model-00004-of-00004.safetensors",
|
| 588 |
+
"vpm.encoder.layers.21.layer_norm2.weight": "model-00004-of-00004.safetensors",
|
| 589 |
+
"vpm.encoder.layers.21.mlp.fc1.bias": "model-00004-of-00004.safetensors",
|
| 590 |
+
"vpm.encoder.layers.21.mlp.fc1.weight": "model-00004-of-00004.safetensors",
|
| 591 |
+
"vpm.encoder.layers.21.mlp.fc2.bias": "model-00004-of-00004.safetensors",
|
| 592 |
+
"vpm.encoder.layers.21.mlp.fc2.weight": "model-00004-of-00004.safetensors",
|
| 593 |
+
"vpm.encoder.layers.21.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
| 594 |
+
"vpm.encoder.layers.21.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 595 |
+
"vpm.encoder.layers.21.self_attn.out_proj.bias": "model-00004-of-00004.safetensors",
|
| 596 |
+
"vpm.encoder.layers.21.self_attn.out_proj.weight": "model-00004-of-00004.safetensors",
|
| 597 |
+
"vpm.encoder.layers.21.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
| 598 |
+
"vpm.encoder.layers.21.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 599 |
+
"vpm.encoder.layers.21.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
| 600 |
+
"vpm.encoder.layers.21.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 601 |
+
"vpm.encoder.layers.22.layer_norm1.bias": "model-00004-of-00004.safetensors",
|
| 602 |
+
"vpm.encoder.layers.22.layer_norm1.weight": "model-00004-of-00004.safetensors",
|
| 603 |
+
"vpm.encoder.layers.22.layer_norm2.bias": "model-00004-of-00004.safetensors",
|
| 604 |
+
"vpm.encoder.layers.22.layer_norm2.weight": "model-00004-of-00004.safetensors",
|
| 605 |
+
"vpm.encoder.layers.22.mlp.fc1.bias": "model-00004-of-00004.safetensors",
|
| 606 |
+
"vpm.encoder.layers.22.mlp.fc1.weight": "model-00004-of-00004.safetensors",
|
| 607 |
+
"vpm.encoder.layers.22.mlp.fc2.bias": "model-00004-of-00004.safetensors",
|
| 608 |
+
"vpm.encoder.layers.22.mlp.fc2.weight": "model-00004-of-00004.safetensors",
|
| 609 |
+
"vpm.encoder.layers.22.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
| 610 |
+
"vpm.encoder.layers.22.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 611 |
+
"vpm.encoder.layers.22.self_attn.out_proj.bias": "model-00004-of-00004.safetensors",
|
| 612 |
+
"vpm.encoder.layers.22.self_attn.out_proj.weight": "model-00004-of-00004.safetensors",
|
| 613 |
+
"vpm.encoder.layers.22.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
| 614 |
+
"vpm.encoder.layers.22.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 615 |
+
"vpm.encoder.layers.22.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
| 616 |
+
"vpm.encoder.layers.22.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 617 |
+
"vpm.encoder.layers.23.layer_norm1.bias": "model-00004-of-00004.safetensors",
|
| 618 |
+
"vpm.encoder.layers.23.layer_norm1.weight": "model-00004-of-00004.safetensors",
|
| 619 |
+
"vpm.encoder.layers.23.layer_norm2.bias": "model-00004-of-00004.safetensors",
|
| 620 |
+
"vpm.encoder.layers.23.layer_norm2.weight": "model-00004-of-00004.safetensors",
|
| 621 |
+
"vpm.encoder.layers.23.mlp.fc1.bias": "model-00004-of-00004.safetensors",
|
| 622 |
+
"vpm.encoder.layers.23.mlp.fc1.weight": "model-00004-of-00004.safetensors",
|
| 623 |
+
"vpm.encoder.layers.23.mlp.fc2.bias": "model-00004-of-00004.safetensors",
|
| 624 |
+
"vpm.encoder.layers.23.mlp.fc2.weight": "model-00004-of-00004.safetensors",
|
| 625 |
+
"vpm.encoder.layers.23.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
| 626 |
+
"vpm.encoder.layers.23.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 627 |
+
"vpm.encoder.layers.23.self_attn.out_proj.bias": "model-00004-of-00004.safetensors",
|
| 628 |
+
"vpm.encoder.layers.23.self_attn.out_proj.weight": "model-00004-of-00004.safetensors",
|
| 629 |
+
"vpm.encoder.layers.23.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
| 630 |
+
"vpm.encoder.layers.23.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 631 |
+
"vpm.encoder.layers.23.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
| 632 |
+
"vpm.encoder.layers.23.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 633 |
+
"vpm.encoder.layers.24.layer_norm1.bias": "model-00004-of-00004.safetensors",
|
| 634 |
+
"vpm.encoder.layers.24.layer_norm1.weight": "model-00004-of-00004.safetensors",
|
| 635 |
+
"vpm.encoder.layers.24.layer_norm2.bias": "model-00004-of-00004.safetensors",
|
| 636 |
+
"vpm.encoder.layers.24.layer_norm2.weight": "model-00004-of-00004.safetensors",
|
| 637 |
+
"vpm.encoder.layers.24.mlp.fc1.bias": "model-00004-of-00004.safetensors",
|
| 638 |
+
"vpm.encoder.layers.24.mlp.fc1.weight": "model-00004-of-00004.safetensors",
|
| 639 |
+
"vpm.encoder.layers.24.mlp.fc2.bias": "model-00004-of-00004.safetensors",
|
| 640 |
+
"vpm.encoder.layers.24.mlp.fc2.weight": "model-00004-of-00004.safetensors",
|
| 641 |
+
"vpm.encoder.layers.24.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
| 642 |
+
"vpm.encoder.layers.24.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 643 |
+
"vpm.encoder.layers.24.self_attn.out_proj.bias": "model-00004-of-00004.safetensors",
|
| 644 |
+
"vpm.encoder.layers.24.self_attn.out_proj.weight": "model-00004-of-00004.safetensors",
|
| 645 |
+
"vpm.encoder.layers.24.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
| 646 |
+
"vpm.encoder.layers.24.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 647 |
+
"vpm.encoder.layers.24.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
| 648 |
+
"vpm.encoder.layers.24.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 649 |
+
"vpm.encoder.layers.25.layer_norm1.bias": "model-00004-of-00004.safetensors",
|
| 650 |
+
"vpm.encoder.layers.25.layer_norm1.weight": "model-00004-of-00004.safetensors",
|
| 651 |
+
"vpm.encoder.layers.25.layer_norm2.bias": "model-00004-of-00004.safetensors",
|
| 652 |
+
"vpm.encoder.layers.25.layer_norm2.weight": "model-00004-of-00004.safetensors",
|
| 653 |
+
"vpm.encoder.layers.25.mlp.fc1.bias": "model-00004-of-00004.safetensors",
|
| 654 |
+
"vpm.encoder.layers.25.mlp.fc1.weight": "model-00004-of-00004.safetensors",
|
| 655 |
+
"vpm.encoder.layers.25.mlp.fc2.bias": "model-00004-of-00004.safetensors",
|
| 656 |
+
"vpm.encoder.layers.25.mlp.fc2.weight": "model-00004-of-00004.safetensors",
|
| 657 |
+
"vpm.encoder.layers.25.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
| 658 |
+
"vpm.encoder.layers.25.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 659 |
+
"vpm.encoder.layers.25.self_attn.out_proj.bias": "model-00004-of-00004.safetensors",
|
| 660 |
+
"vpm.encoder.layers.25.self_attn.out_proj.weight": "model-00004-of-00004.safetensors",
|
| 661 |
+
"vpm.encoder.layers.25.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
| 662 |
+
"vpm.encoder.layers.25.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 663 |
+
"vpm.encoder.layers.25.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
| 664 |
+
"vpm.encoder.layers.25.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 665 |
+
"vpm.encoder.layers.26.layer_norm1.bias": "model-00004-of-00004.safetensors",
|
| 666 |
+
"vpm.encoder.layers.26.layer_norm1.weight": "model-00004-of-00004.safetensors",
|
| 667 |
+
"vpm.encoder.layers.26.layer_norm2.bias": "model-00004-of-00004.safetensors",
|
| 668 |
+
"vpm.encoder.layers.26.layer_norm2.weight": "model-00004-of-00004.safetensors",
|
| 669 |
+
"vpm.encoder.layers.26.mlp.fc1.bias": "model-00004-of-00004.safetensors",
|
| 670 |
+
"vpm.encoder.layers.26.mlp.fc1.weight": "model-00004-of-00004.safetensors",
|
| 671 |
+
"vpm.encoder.layers.26.mlp.fc2.bias": "model-00004-of-00004.safetensors",
|
| 672 |
+
"vpm.encoder.layers.26.mlp.fc2.weight": "model-00004-of-00004.safetensors",
|
| 673 |
+
"vpm.encoder.layers.26.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
| 674 |
+
"vpm.encoder.layers.26.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 675 |
+
"vpm.encoder.layers.26.self_attn.out_proj.bias": "model-00004-of-00004.safetensors",
|
| 676 |
+
"vpm.encoder.layers.26.self_attn.out_proj.weight": "model-00004-of-00004.safetensors",
|
| 677 |
+
"vpm.encoder.layers.26.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
| 678 |
+
"vpm.encoder.layers.26.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 679 |
+
"vpm.encoder.layers.26.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
| 680 |
+
"vpm.encoder.layers.26.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 681 |
+
"vpm.encoder.layers.3.layer_norm1.bias": "model-00004-of-00004.safetensors",
|
| 682 |
+
"vpm.encoder.layers.3.layer_norm1.weight": "model-00004-of-00004.safetensors",
|
| 683 |
+
"vpm.encoder.layers.3.layer_norm2.bias": "model-00004-of-00004.safetensors",
|
| 684 |
+
"vpm.encoder.layers.3.layer_norm2.weight": "model-00004-of-00004.safetensors",
|
| 685 |
+
"vpm.encoder.layers.3.mlp.fc1.bias": "model-00004-of-00004.safetensors",
|
| 686 |
+
"vpm.encoder.layers.3.mlp.fc1.weight": "model-00004-of-00004.safetensors",
|
| 687 |
+
"vpm.encoder.layers.3.mlp.fc2.bias": "model-00004-of-00004.safetensors",
|
| 688 |
+
"vpm.encoder.layers.3.mlp.fc2.weight": "model-00004-of-00004.safetensors",
|
| 689 |
+
"vpm.encoder.layers.3.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
| 690 |
+
"vpm.encoder.layers.3.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 691 |
+
"vpm.encoder.layers.3.self_attn.out_proj.bias": "model-00004-of-00004.safetensors",
|
| 692 |
+
"vpm.encoder.layers.3.self_attn.out_proj.weight": "model-00004-of-00004.safetensors",
|
| 693 |
+
"vpm.encoder.layers.3.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
| 694 |
+
"vpm.encoder.layers.3.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 695 |
+
"vpm.encoder.layers.3.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
| 696 |
+
"vpm.encoder.layers.3.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 697 |
+
"vpm.encoder.layers.4.layer_norm1.bias": "model-00004-of-00004.safetensors",
|
| 698 |
+
"vpm.encoder.layers.4.layer_norm1.weight": "model-00004-of-00004.safetensors",
|
| 699 |
+
"vpm.encoder.layers.4.layer_norm2.bias": "model-00004-of-00004.safetensors",
|
| 700 |
+
"vpm.encoder.layers.4.layer_norm2.weight": "model-00004-of-00004.safetensors",
|
| 701 |
+
"vpm.encoder.layers.4.mlp.fc1.bias": "model-00004-of-00004.safetensors",
|
| 702 |
+
"vpm.encoder.layers.4.mlp.fc1.weight": "model-00004-of-00004.safetensors",
|
| 703 |
+
"vpm.encoder.layers.4.mlp.fc2.bias": "model-00004-of-00004.safetensors",
|
| 704 |
+
"vpm.encoder.layers.4.mlp.fc2.weight": "model-00004-of-00004.safetensors",
|
| 705 |
+
"vpm.encoder.layers.4.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
| 706 |
+
"vpm.encoder.layers.4.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 707 |
+
"vpm.encoder.layers.4.self_attn.out_proj.bias": "model-00004-of-00004.safetensors",
|
| 708 |
+
"vpm.encoder.layers.4.self_attn.out_proj.weight": "model-00004-of-00004.safetensors",
|
| 709 |
+
"vpm.encoder.layers.4.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
| 710 |
+
"vpm.encoder.layers.4.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 711 |
+
"vpm.encoder.layers.4.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
| 712 |
+
"vpm.encoder.layers.4.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 713 |
+
"vpm.encoder.layers.5.layer_norm1.bias": "model-00004-of-00004.safetensors",
|
| 714 |
+
"vpm.encoder.layers.5.layer_norm1.weight": "model-00004-of-00004.safetensors",
|
| 715 |
+
"vpm.encoder.layers.5.layer_norm2.bias": "model-00004-of-00004.safetensors",
|
| 716 |
+
"vpm.encoder.layers.5.layer_norm2.weight": "model-00004-of-00004.safetensors",
|
| 717 |
+
"vpm.encoder.layers.5.mlp.fc1.bias": "model-00004-of-00004.safetensors",
|
| 718 |
+
"vpm.encoder.layers.5.mlp.fc1.weight": "model-00004-of-00004.safetensors",
|
| 719 |
+
"vpm.encoder.layers.5.mlp.fc2.bias": "model-00004-of-00004.safetensors",
|
| 720 |
+
"vpm.encoder.layers.5.mlp.fc2.weight": "model-00004-of-00004.safetensors",
|
| 721 |
+
"vpm.encoder.layers.5.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
| 722 |
+
"vpm.encoder.layers.5.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 723 |
+
"vpm.encoder.layers.5.self_attn.out_proj.bias": "model-00004-of-00004.safetensors",
|
| 724 |
+
"vpm.encoder.layers.5.self_attn.out_proj.weight": "model-00004-of-00004.safetensors",
|
| 725 |
+
"vpm.encoder.layers.5.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
| 726 |
+
"vpm.encoder.layers.5.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 727 |
+
"vpm.encoder.layers.5.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
| 728 |
+
"vpm.encoder.layers.5.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 729 |
+
"vpm.encoder.layers.6.layer_norm1.bias": "model-00004-of-00004.safetensors",
|
| 730 |
+
"vpm.encoder.layers.6.layer_norm1.weight": "model-00004-of-00004.safetensors",
|
| 731 |
+
"vpm.encoder.layers.6.layer_norm2.bias": "model-00004-of-00004.safetensors",
|
| 732 |
+
"vpm.encoder.layers.6.layer_norm2.weight": "model-00004-of-00004.safetensors",
|
| 733 |
+
"vpm.encoder.layers.6.mlp.fc1.bias": "model-00004-of-00004.safetensors",
|
| 734 |
+
"vpm.encoder.layers.6.mlp.fc1.weight": "model-00004-of-00004.safetensors",
|
| 735 |
+
"vpm.encoder.layers.6.mlp.fc2.bias": "model-00004-of-00004.safetensors",
|
| 736 |
+
"vpm.encoder.layers.6.mlp.fc2.weight": "model-00004-of-00004.safetensors",
|
| 737 |
+
"vpm.encoder.layers.6.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
| 738 |
+
"vpm.encoder.layers.6.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 739 |
+
"vpm.encoder.layers.6.self_attn.out_proj.bias": "model-00004-of-00004.safetensors",
|
| 740 |
+
"vpm.encoder.layers.6.self_attn.out_proj.weight": "model-00004-of-00004.safetensors",
|
| 741 |
+
"vpm.encoder.layers.6.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
| 742 |
+
"vpm.encoder.layers.6.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 743 |
+
"vpm.encoder.layers.6.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
| 744 |
+
"vpm.encoder.layers.6.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 745 |
+
"vpm.encoder.layers.7.layer_norm1.bias": "model-00004-of-00004.safetensors",
|
| 746 |
+
"vpm.encoder.layers.7.layer_norm1.weight": "model-00004-of-00004.safetensors",
|
| 747 |
+
"vpm.encoder.layers.7.layer_norm2.bias": "model-00004-of-00004.safetensors",
|
| 748 |
+
"vpm.encoder.layers.7.layer_norm2.weight": "model-00004-of-00004.safetensors",
|
| 749 |
+
"vpm.encoder.layers.7.mlp.fc1.bias": "model-00004-of-00004.safetensors",
|
| 750 |
+
"vpm.encoder.layers.7.mlp.fc1.weight": "model-00004-of-00004.safetensors",
|
| 751 |
+
"vpm.encoder.layers.7.mlp.fc2.bias": "model-00004-of-00004.safetensors",
|
| 752 |
+
"vpm.encoder.layers.7.mlp.fc2.weight": "model-00004-of-00004.safetensors",
|
| 753 |
+
"vpm.encoder.layers.7.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
| 754 |
+
"vpm.encoder.layers.7.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 755 |
+
"vpm.encoder.layers.7.self_attn.out_proj.bias": "model-00004-of-00004.safetensors",
|
| 756 |
+
"vpm.encoder.layers.7.self_attn.out_proj.weight": "model-00004-of-00004.safetensors",
|
| 757 |
+
"vpm.encoder.layers.7.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
| 758 |
+
"vpm.encoder.layers.7.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 759 |
+
"vpm.encoder.layers.7.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
| 760 |
+
"vpm.encoder.layers.7.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 761 |
+
"vpm.encoder.layers.8.layer_norm1.bias": "model-00004-of-00004.safetensors",
|
| 762 |
+
"vpm.encoder.layers.8.layer_norm1.weight": "model-00004-of-00004.safetensors",
|
| 763 |
+
"vpm.encoder.layers.8.layer_norm2.bias": "model-00004-of-00004.safetensors",
|
| 764 |
+
"vpm.encoder.layers.8.layer_norm2.weight": "model-00004-of-00004.safetensors",
|
| 765 |
+
"vpm.encoder.layers.8.mlp.fc1.bias": "model-00004-of-00004.safetensors",
|
| 766 |
+
"vpm.encoder.layers.8.mlp.fc1.weight": "model-00004-of-00004.safetensors",
|
| 767 |
+
"vpm.encoder.layers.8.mlp.fc2.bias": "model-00004-of-00004.safetensors",
|
| 768 |
+
"vpm.encoder.layers.8.mlp.fc2.weight": "model-00004-of-00004.safetensors",
|
| 769 |
+
"vpm.encoder.layers.8.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
| 770 |
+
"vpm.encoder.layers.8.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 771 |
+
"vpm.encoder.layers.8.self_attn.out_proj.bias": "model-00004-of-00004.safetensors",
|
| 772 |
+
"vpm.encoder.layers.8.self_attn.out_proj.weight": "model-00004-of-00004.safetensors",
|
| 773 |
+
"vpm.encoder.layers.8.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
| 774 |
+
"vpm.encoder.layers.8.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 775 |
+
"vpm.encoder.layers.8.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
| 776 |
+
"vpm.encoder.layers.8.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 777 |
+
"vpm.encoder.layers.9.layer_norm1.bias": "model-00004-of-00004.safetensors",
|
| 778 |
+
"vpm.encoder.layers.9.layer_norm1.weight": "model-00004-of-00004.safetensors",
|
| 779 |
+
"vpm.encoder.layers.9.layer_norm2.bias": "model-00004-of-00004.safetensors",
|
| 780 |
+
"vpm.encoder.layers.9.layer_norm2.weight": "model-00004-of-00004.safetensors",
|
| 781 |
+
"vpm.encoder.layers.9.mlp.fc1.bias": "model-00004-of-00004.safetensors",
|
| 782 |
+
"vpm.encoder.layers.9.mlp.fc1.weight": "model-00004-of-00004.safetensors",
|
| 783 |
+
"vpm.encoder.layers.9.mlp.fc2.bias": "model-00004-of-00004.safetensors",
|
| 784 |
+
"vpm.encoder.layers.9.mlp.fc2.weight": "model-00004-of-00004.safetensors",
|
| 785 |
+
"vpm.encoder.layers.9.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
| 786 |
+
"vpm.encoder.layers.9.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 787 |
+
"vpm.encoder.layers.9.self_attn.out_proj.bias": "model-00004-of-00004.safetensors",
|
| 788 |
+
"vpm.encoder.layers.9.self_attn.out_proj.weight": "model-00004-of-00004.safetensors",
|
| 789 |
+
"vpm.encoder.layers.9.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
| 790 |
+
"vpm.encoder.layers.9.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 791 |
+
"vpm.encoder.layers.9.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
| 792 |
+
"vpm.encoder.layers.9.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 793 |
+
"vpm.post_layernorm.bias": "model-00004-of-00004.safetensors",
|
| 794 |
+
"vpm.post_layernorm.weight": "model-00004-of-00004.safetensors"
|
| 795 |
+
}
|
| 796 |
+
}
|
modeling_minicpmv.py
ADDED
|
@@ -0,0 +1,403 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
from typing import List, Optional
|
| 3 |
+
import json
|
| 4 |
+
import torch
|
| 5 |
+
import torchvision
|
| 6 |
+
|
| 7 |
+
from threading import Thread
|
| 8 |
+
from copy import deepcopy
|
| 9 |
+
from PIL import Image
|
| 10 |
+
from transformers import AutoProcessor, Qwen2PreTrainedModel, Qwen2ForCausalLM, TextIteratorStreamer
|
| 11 |
+
|
| 12 |
+
from .configuration_minicpm import MiniCPMVConfig
|
| 13 |
+
from .modeling_navit_siglip import SiglipVisionTransformer
|
| 14 |
+
from .resampler import Resampler
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class MiniCPMVPreTrainedModel(Qwen2PreTrainedModel):
|
| 19 |
+
config_class = MiniCPMVConfig
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
class MiniCPMV(MiniCPMVPreTrainedModel):
|
| 23 |
+
def __init__(self, config):
|
| 24 |
+
super().__init__(config)
|
| 25 |
+
self.llm = Qwen2ForCausalLM(config)
|
| 26 |
+
self.vpm = self.init_vision_module()
|
| 27 |
+
self.vision_dim = self.vpm.embed_dim
|
| 28 |
+
self.embed_dim = self.llm.config.hidden_size
|
| 29 |
+
self.resampler = self.init_resampler(self.embed_dim, self.vision_dim)
|
| 30 |
+
self.processor = None
|
| 31 |
+
|
| 32 |
+
self.terminators = ['<|im_end|>', '<|endoftext|>']
|
| 33 |
+
|
| 34 |
+
def init_vision_module(self):
|
| 35 |
+
# same as HuggingFaceM4/siglip-so400m-14-980-flash-attn2-navit add tgt_sizes
|
| 36 |
+
if self.config._attn_implementation == 'flash_attention_2':
|
| 37 |
+
self.config.vision_config._attn_implementation = 'flash_attention_2'
|
| 38 |
+
else:
|
| 39 |
+
# not suport sdpa
|
| 40 |
+
self.config.vision_config._attn_implementation = 'eager'
|
| 41 |
+
model = SiglipVisionTransformer(self.config.vision_config)
|
| 42 |
+
if self.config.drop_vision_last_layer:
|
| 43 |
+
model.encoder.layers = model.encoder.layers[:-1]
|
| 44 |
+
|
| 45 |
+
setattr(model, 'embed_dim', model.embeddings.embed_dim)
|
| 46 |
+
setattr(model, 'patch_size', model.embeddings.patch_size)
|
| 47 |
+
|
| 48 |
+
return model
|
| 49 |
+
|
| 50 |
+
def init_resampler(self, embed_dim, vision_dim):
|
| 51 |
+
return Resampler(
|
| 52 |
+
num_queries=self.config.query_num,
|
| 53 |
+
embed_dim=embed_dim,
|
| 54 |
+
num_heads=embed_dim // 128,
|
| 55 |
+
kv_dim=vision_dim,
|
| 56 |
+
adaptive=True
|
| 57 |
+
)
|
| 58 |
+
|
| 59 |
+
def get_input_embeddings(self):
|
| 60 |
+
return self.llm.get_input_embeddings()
|
| 61 |
+
|
| 62 |
+
def set_input_embeddings(self, value):
|
| 63 |
+
self.llm.embed_tokens = value
|
| 64 |
+
|
| 65 |
+
def get_output_embeddings(self):
|
| 66 |
+
return self.llm.lm_head
|
| 67 |
+
|
| 68 |
+
def set_output_embeddings(self, new_embeddings):
|
| 69 |
+
self.llm.lm_head = new_embeddings
|
| 70 |
+
|
| 71 |
+
def set_decoder(self, decoder):
|
| 72 |
+
self.llm = decoder
|
| 73 |
+
|
| 74 |
+
def get_decoder(self):
|
| 75 |
+
return self.llm
|
| 76 |
+
|
| 77 |
+
def get_vllm_embedding(self, data):
|
| 78 |
+
if 'vision_hidden_states' not in data:
|
| 79 |
+
dtype = self.llm.model.embed_tokens.weight.dtype
|
| 80 |
+
device = self.llm.model.embed_tokens.weight.device
|
| 81 |
+
tgt_sizes = data['tgt_sizes']
|
| 82 |
+
pixel_values_list = data['pixel_values']
|
| 83 |
+
vision_hidden_states = []
|
| 84 |
+
all_pixel_values = []
|
| 85 |
+
img_cnt = []
|
| 86 |
+
for pixel_values in pixel_values_list:
|
| 87 |
+
img_cnt.append(len(pixel_values))
|
| 88 |
+
all_pixel_values.extend([i.flatten(end_dim=1).permute(1, 0) for i in pixel_values])
|
| 89 |
+
|
| 90 |
+
# exist image
|
| 91 |
+
if all_pixel_values:
|
| 92 |
+
tgt_sizes = [tgt_size for tgt_size in tgt_sizes if isinstance(tgt_size, torch.Tensor)]
|
| 93 |
+
tgt_sizes = torch.vstack(tgt_sizes).type(torch.int32)
|
| 94 |
+
|
| 95 |
+
max_patches = torch.max(tgt_sizes[:, 0] * tgt_sizes[:, 1])
|
| 96 |
+
|
| 97 |
+
all_pixel_values = torch.nn.utils.rnn.pad_sequence(all_pixel_values, batch_first=True,
|
| 98 |
+
padding_value=0.0)
|
| 99 |
+
B, L, _ = all_pixel_values.shape
|
| 100 |
+
all_pixel_values = all_pixel_values.permute(0, 2, 1).reshape(B, 3, -1, L)
|
| 101 |
+
|
| 102 |
+
patch_attn_mask = torch.zeros((B, 1, max_patches), dtype=torch.bool, device=device)
|
| 103 |
+
for i in range(B):
|
| 104 |
+
patch_attn_mask[i, 0, :tgt_sizes[i][0] * tgt_sizes[i][1]] = True
|
| 105 |
+
|
| 106 |
+
vision_batch_size = self.config.vision_batch_size
|
| 107 |
+
all_pixel_values = all_pixel_values.type(dtype)
|
| 108 |
+
if B > vision_batch_size:
|
| 109 |
+
hs = []
|
| 110 |
+
for i in range(0, B, vision_batch_size):
|
| 111 |
+
start_idx = i
|
| 112 |
+
end_idx = i + vision_batch_size
|
| 113 |
+
tmp_hs = self.vpm(all_pixel_values[start_idx:end_idx], patch_attention_mask=patch_attn_mask[start_idx:end_idx], tgt_sizes=tgt_sizes[start_idx:end_idx]).last_hidden_state
|
| 114 |
+
hs.append(tmp_hs)
|
| 115 |
+
vision_embedding = torch.cat(hs, dim=0)
|
| 116 |
+
else:
|
| 117 |
+
vision_embedding = self.vpm(all_pixel_values, patch_attention_mask=patch_attn_mask, tgt_sizes=tgt_sizes).last_hidden_state
|
| 118 |
+
vision_embedding = self.resampler(vision_embedding, tgt_sizes)
|
| 119 |
+
|
| 120 |
+
start = 0
|
| 121 |
+
for pixel_values in pixel_values_list:
|
| 122 |
+
img_cnt = len(pixel_values)
|
| 123 |
+
if img_cnt > 0:
|
| 124 |
+
vision_hidden_states.append(vision_embedding[start: start + img_cnt])
|
| 125 |
+
start += img_cnt
|
| 126 |
+
else:
|
| 127 |
+
vision_hidden_states.append([])
|
| 128 |
+
else: # no image
|
| 129 |
+
if self.training:
|
| 130 |
+
dummy_image = torch.zeros(
|
| 131 |
+
(1, 3, 224, 224),
|
| 132 |
+
device=device, dtype=dtype
|
| 133 |
+
)
|
| 134 |
+
tgt_sizes = torch.Tensor([[(224 // self.config.patch_size), math.ceil(224 / self.config.patch_size)]]).type(torch.int32)
|
| 135 |
+
dummy_feature = self.resampler(self.vpm(dummy_image).last_hidden_state, tgt_sizes)
|
| 136 |
+
else:
|
| 137 |
+
dummy_feature = []
|
| 138 |
+
for _ in range(len(pixel_values_list)):
|
| 139 |
+
vision_hidden_states.append(dummy_feature)
|
| 140 |
+
|
| 141 |
+
else:
|
| 142 |
+
vision_hidden_states = data['vision_hidden_states']
|
| 143 |
+
|
| 144 |
+
if hasattr(self.llm.config, 'scale_emb'):
|
| 145 |
+
vllm_embedding = self.llm.model.embed_tokens(data['input_ids']) * self.llm.config.scale_emb
|
| 146 |
+
else:
|
| 147 |
+
vllm_embedding = self.llm.model.embed_tokens(data['input_ids'])
|
| 148 |
+
|
| 149 |
+
vision_hidden_states = [i.type(vllm_embedding.dtype) if isinstance(
|
| 150 |
+
i, torch.Tensor) else i for i in vision_hidden_states]
|
| 151 |
+
|
| 152 |
+
bs = len(data['input_ids'])
|
| 153 |
+
for i in range(bs):
|
| 154 |
+
cur_vs_hs = vision_hidden_states[i]
|
| 155 |
+
if len(cur_vs_hs) > 0:
|
| 156 |
+
cur_vllm_emb = vllm_embedding[i]
|
| 157 |
+
cur_image_bound = data['image_bound'][i]
|
| 158 |
+
if len(cur_image_bound) > 0:
|
| 159 |
+
image_indices = torch.stack(
|
| 160 |
+
[torch.arange(r[0], r[1], dtype=torch.long) for r in cur_image_bound]
|
| 161 |
+
).to(vllm_embedding.device)
|
| 162 |
+
|
| 163 |
+
cur_vllm_emb.scatter_(0, image_indices.view(-1, 1).repeat(1, cur_vllm_emb.shape[-1]),
|
| 164 |
+
cur_vs_hs.view(-1, cur_vs_hs.shape[-1]))
|
| 165 |
+
elif self.training:
|
| 166 |
+
cur_vllm_emb += cur_vs_hs[0].mean() * 0
|
| 167 |
+
|
| 168 |
+
return vllm_embedding, vision_hidden_states
|
| 169 |
+
|
| 170 |
+
def forward(self, data, **kwargs):
|
| 171 |
+
vllm_embedding, vision_hidden_states = self.get_vllm_embedding(data)
|
| 172 |
+
position_ids = data["position_ids"]
|
| 173 |
+
if position_ids.dtype != torch.int64:
|
| 174 |
+
position_ids = position_ids.long()
|
| 175 |
+
|
| 176 |
+
return self.llm(
|
| 177 |
+
input_ids=None,
|
| 178 |
+
position_ids=position_ids,
|
| 179 |
+
inputs_embeds=vllm_embedding,
|
| 180 |
+
**kwargs
|
| 181 |
+
)
|
| 182 |
+
|
| 183 |
+
def _decode(self, inputs_embeds, tokenizer, attention_mask, decode_text=False, **kwargs):
|
| 184 |
+
terminators = [tokenizer.convert_tokens_to_ids(i) for i in self.terminators]
|
| 185 |
+
output = self.llm.generate(
|
| 186 |
+
inputs_embeds=inputs_embeds,
|
| 187 |
+
pad_token_id=0,
|
| 188 |
+
eos_token_id=terminators,
|
| 189 |
+
attention_mask=attention_mask,
|
| 190 |
+
**kwargs
|
| 191 |
+
)
|
| 192 |
+
if decode_text:
|
| 193 |
+
return self._decode_text(output, tokenizer)
|
| 194 |
+
return output
|
| 195 |
+
|
| 196 |
+
def _decode_stream(self, inputs_embeds, tokenizer, **kwargs):
|
| 197 |
+
terminators = [tokenizer.convert_tokens_to_ids(i) for i in self.terminators]
|
| 198 |
+
streamer = TextIteratorStreamer(tokenizer=tokenizer)
|
| 199 |
+
generation_kwargs = {
|
| 200 |
+
'inputs_embeds': inputs_embeds,
|
| 201 |
+
'pad_token_id': 0,
|
| 202 |
+
'eos_token_id': terminators,
|
| 203 |
+
'streamer': streamer
|
| 204 |
+
}
|
| 205 |
+
generation_kwargs.update(kwargs)
|
| 206 |
+
|
| 207 |
+
thread = Thread(target=self.llm.generate, kwargs=generation_kwargs)
|
| 208 |
+
thread.start()
|
| 209 |
+
|
| 210 |
+
return streamer
|
| 211 |
+
|
| 212 |
+
def _decode_text(self, result_ids, tokenizer):
|
| 213 |
+
terminators = [tokenizer.convert_tokens_to_ids(i) for i in self.terminators]
|
| 214 |
+
result_text = []
|
| 215 |
+
for result in result_ids:
|
| 216 |
+
result = result[result != 0]
|
| 217 |
+
if result[0] == tokenizer.bos_id:
|
| 218 |
+
result = result[1:]
|
| 219 |
+
if result[-1] in terminators:
|
| 220 |
+
result = result[:-1]
|
| 221 |
+
result_text.append(tokenizer.decode(result).strip())
|
| 222 |
+
return result_text
|
| 223 |
+
|
| 224 |
+
def generate(
|
| 225 |
+
self,
|
| 226 |
+
input_ids=None,
|
| 227 |
+
pixel_values=None,
|
| 228 |
+
tgt_sizes=None,
|
| 229 |
+
image_bound=None,
|
| 230 |
+
attention_mask=None,
|
| 231 |
+
tokenizer=None,
|
| 232 |
+
vision_hidden_states=None,
|
| 233 |
+
return_vision_hidden_states=False,
|
| 234 |
+
stream=False,
|
| 235 |
+
decode_text=False,
|
| 236 |
+
**kwargs
|
| 237 |
+
):
|
| 238 |
+
assert input_ids is not None
|
| 239 |
+
assert len(input_ids) == len(pixel_values)
|
| 240 |
+
|
| 241 |
+
model_inputs = {
|
| 242 |
+
"input_ids": input_ids,
|
| 243 |
+
"image_bound": image_bound,
|
| 244 |
+
}
|
| 245 |
+
|
| 246 |
+
if vision_hidden_states is None:
|
| 247 |
+
model_inputs["pixel_values"] = pixel_values
|
| 248 |
+
model_inputs['tgt_sizes'] = tgt_sizes
|
| 249 |
+
else:
|
| 250 |
+
model_inputs["vision_hidden_states"] = vision_hidden_states
|
| 251 |
+
|
| 252 |
+
with torch.inference_mode():
|
| 253 |
+
(
|
| 254 |
+
model_inputs["inputs_embeds"],
|
| 255 |
+
vision_hidden_states,
|
| 256 |
+
) = self.get_vllm_embedding(model_inputs)
|
| 257 |
+
|
| 258 |
+
if stream:
|
| 259 |
+
result = self._decode_stream(model_inputs["inputs_embeds"], tokenizer, **kwargs)
|
| 260 |
+
else:
|
| 261 |
+
result = self._decode(model_inputs["inputs_embeds"], tokenizer, attention_mask, decode_text=decode_text, **kwargs)
|
| 262 |
+
|
| 263 |
+
if return_vision_hidden_states:
|
| 264 |
+
return result, vision_hidden_states
|
| 265 |
+
|
| 266 |
+
return result
|
| 267 |
+
|
| 268 |
+
def chat(
|
| 269 |
+
self,
|
| 270 |
+
image,
|
| 271 |
+
msgs,
|
| 272 |
+
tokenizer,
|
| 273 |
+
processor=None,
|
| 274 |
+
vision_hidden_states=None,
|
| 275 |
+
max_new_tokens=2048,
|
| 276 |
+
min_new_tokens=0,
|
| 277 |
+
sampling=True,
|
| 278 |
+
max_inp_length=8192,
|
| 279 |
+
system_prompt='',
|
| 280 |
+
stream=False,
|
| 281 |
+
max_slice_nums=None,
|
| 282 |
+
use_image_id=None,
|
| 283 |
+
**kwargs
|
| 284 |
+
):
|
| 285 |
+
if isinstance(msgs[0], list):
|
| 286 |
+
batched = True
|
| 287 |
+
else:
|
| 288 |
+
batched = False
|
| 289 |
+
msgs_list = msgs
|
| 290 |
+
images_list = image
|
| 291 |
+
|
| 292 |
+
if batched is False:
|
| 293 |
+
images_list, msgs_list = [images_list], [msgs_list]
|
| 294 |
+
else:
|
| 295 |
+
assert images_list is None, "Please integrate image to msgs when using batch inference."
|
| 296 |
+
images_list = [None] * len(msgs_list)
|
| 297 |
+
assert len(images_list) == len(msgs_list), "The batch dim of images_list and msgs_list should be the same."
|
| 298 |
+
|
| 299 |
+
if processor is None:
|
| 300 |
+
if self.processor is None:
|
| 301 |
+
self.processor = AutoProcessor.from_pretrained(self.config._name_or_path, trust_remote_code=True)
|
| 302 |
+
processor = self.processor
|
| 303 |
+
|
| 304 |
+
assert self.config.query_num == processor.image_processor.image_feature_size, "These two values should be the same. Check `config.json` and `preprocessor_config.json`."
|
| 305 |
+
assert self.config.patch_size == processor.image_processor.patch_size, "These two values should be the same. Check `config.json` and `preprocessor_config.json`."
|
| 306 |
+
assert self.config.use_image_id == processor.image_processor.use_image_id, "These two values should be the same. Check `config.json` and `preprocessor_config.json`."
|
| 307 |
+
assert self.config.slice_config.max_slice_nums == processor.image_processor.max_slice_nums, "These two values should be the same. Check `config.json` and `preprocessor_config.json`."
|
| 308 |
+
assert self.config.slice_mode == processor.image_processor.slice_mode, "These two values should be the same. Check `config.json` and `preprocessor_config.json`."
|
| 309 |
+
|
| 310 |
+
prompts_lists = []
|
| 311 |
+
input_images_lists = []
|
| 312 |
+
for image, msgs in zip(images_list, msgs_list):
|
| 313 |
+
if isinstance(msgs, str):
|
| 314 |
+
msgs = json.loads(msgs)
|
| 315 |
+
copy_msgs = deepcopy(msgs)
|
| 316 |
+
|
| 317 |
+
assert len(msgs) > 0, "msgs is empty"
|
| 318 |
+
assert sampling or not stream, "if use stream mode, make sure sampling=True"
|
| 319 |
+
|
| 320 |
+
if image is not None and isinstance(copy_msgs[0]["content"], str):
|
| 321 |
+
copy_msgs[0]["content"] = [image, copy_msgs[0]["content"]]
|
| 322 |
+
|
| 323 |
+
images = []
|
| 324 |
+
for i, msg in enumerate(copy_msgs):
|
| 325 |
+
role = msg["role"]
|
| 326 |
+
content = msg["content"]
|
| 327 |
+
assert role in ["user", "assistant"]
|
| 328 |
+
if i == 0:
|
| 329 |
+
assert role == "user", "The role of first msg should be user"
|
| 330 |
+
if isinstance(content, str):
|
| 331 |
+
content = [content]
|
| 332 |
+
cur_msgs = []
|
| 333 |
+
for c in content:
|
| 334 |
+
if isinstance(c, Image.Image):
|
| 335 |
+
images.append(c)
|
| 336 |
+
cur_msgs.append("(<image>./</image>)")
|
| 337 |
+
elif isinstance(c, str):
|
| 338 |
+
cur_msgs.append(c)
|
| 339 |
+
msg["content"] = "\n".join(cur_msgs)
|
| 340 |
+
|
| 341 |
+
if system_prompt:
|
| 342 |
+
sys_msg = {'role': 'system', 'content': system_prompt}
|
| 343 |
+
copy_msgs = [sys_msg] + copy_msgs
|
| 344 |
+
|
| 345 |
+
prompts_lists.append(processor.tokenizer.apply_chat_template(copy_msgs, tokenize=False, add_generation_prompt=True))
|
| 346 |
+
input_images_lists.append(images)
|
| 347 |
+
|
| 348 |
+
inputs = processor(
|
| 349 |
+
prompts_lists,
|
| 350 |
+
input_images_lists,
|
| 351 |
+
max_slice_nums=max_slice_nums,
|
| 352 |
+
use_image_id=use_image_id,
|
| 353 |
+
return_tensors="pt",
|
| 354 |
+
max_length=max_inp_length
|
| 355 |
+
).to(self.device)
|
| 356 |
+
|
| 357 |
+
if sampling:
|
| 358 |
+
generation_config = {
|
| 359 |
+
"top_p": 0.8,
|
| 360 |
+
"top_k": 100,
|
| 361 |
+
"temperature": 0.7,
|
| 362 |
+
"do_sample": True,
|
| 363 |
+
"repetition_penalty": 1.05
|
| 364 |
+
}
|
| 365 |
+
else:
|
| 366 |
+
generation_config = {
|
| 367 |
+
"num_beams": 3,
|
| 368 |
+
"repetition_penalty": 1.2,
|
| 369 |
+
}
|
| 370 |
+
|
| 371 |
+
if min_new_tokens > 0:
|
| 372 |
+
generation_config['min_new_tokens'] = min_new_tokens
|
| 373 |
+
|
| 374 |
+
generation_config.update(
|
| 375 |
+
(k, kwargs[k]) for k in generation_config.keys() & kwargs.keys()
|
| 376 |
+
)
|
| 377 |
+
|
| 378 |
+
inputs.pop("image_sizes")
|
| 379 |
+
with torch.inference_mode():
|
| 380 |
+
res = self.generate(
|
| 381 |
+
**inputs,
|
| 382 |
+
tokenizer=tokenizer,
|
| 383 |
+
max_new_tokens=max_new_tokens,
|
| 384 |
+
vision_hidden_states=vision_hidden_states,
|
| 385 |
+
stream=stream,
|
| 386 |
+
decode_text=True,
|
| 387 |
+
**generation_config
|
| 388 |
+
)
|
| 389 |
+
|
| 390 |
+
if stream:
|
| 391 |
+
def stream_gen():
|
| 392 |
+
for text in res:
|
| 393 |
+
for term in self.terminators:
|
| 394 |
+
text = text.replace(term, '')
|
| 395 |
+
yield text
|
| 396 |
+
return stream_gen()
|
| 397 |
+
|
| 398 |
+
else:
|
| 399 |
+
if batched:
|
| 400 |
+
answer = res
|
| 401 |
+
else:
|
| 402 |
+
answer = res[0]
|
| 403 |
+
return answer
|
modeling_navit_siglip.py
ADDED
|
@@ -0,0 +1,937 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2024 Google AI and The HuggingFace Team. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
""" PyTorch Siglip model. """
|
| 16 |
+
# Copied from HuggingFaceM4/siglip-so400m-14-980-flash-attn2-navit and add tgt_sizes
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
import os
|
| 20 |
+
import math
|
| 21 |
+
import warnings
|
| 22 |
+
from dataclasses import dataclass
|
| 23 |
+
from typing import Any, Optional, Tuple, Union
|
| 24 |
+
|
| 25 |
+
import numpy as np
|
| 26 |
+
import torch
|
| 27 |
+
import torch.nn.functional as F
|
| 28 |
+
import torch.utils.checkpoint
|
| 29 |
+
from torch import nn
|
| 30 |
+
from torch.nn.init import _calculate_fan_in_and_fan_out
|
| 31 |
+
|
| 32 |
+
from transformers.activations import ACT2FN
|
| 33 |
+
from transformers.modeling_attn_mask_utils import _prepare_4d_attention_mask
|
| 34 |
+
from transformers.modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling
|
| 35 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 36 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 37 |
+
from transformers.utils import (
|
| 38 |
+
ModelOutput,
|
| 39 |
+
add_start_docstrings,
|
| 40 |
+
add_start_docstrings_to_model_forward,
|
| 41 |
+
is_flash_attn_2_available,
|
| 42 |
+
logging,
|
| 43 |
+
replace_return_docstrings,
|
| 44 |
+
)
|
| 45 |
+
from transformers.utils import logging
|
| 46 |
+
|
| 47 |
+
logger = logging.get_logger(__name__)
|
| 48 |
+
|
| 49 |
+
class SiglipVisionConfig(PretrainedConfig):
|
| 50 |
+
r"""
|
| 51 |
+
This is the configuration class to store the configuration of a [`SiglipVisionModel`]. It is used to instantiate a
|
| 52 |
+
Siglip vision encoder according to the specified arguments, defining the model architecture. Instantiating a
|
| 53 |
+
configuration with the defaults will yield a similar configuration to that of the vision encoder of the Siglip
|
| 54 |
+
[google/siglip-base-patch16-224](https://huggingface.co/google/siglip-base-patch16-224) architecture.
|
| 55 |
+
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
| 56 |
+
documentation from [`PretrainedConfig`] for more information.
|
| 57 |
+
Args:
|
| 58 |
+
hidden_size (`int`, *optional*, defaults to 768):
|
| 59 |
+
Dimensionality of the encoder layers and the pooler layer.
|
| 60 |
+
intermediate_size (`int`, *optional*, defaults to 3072):
|
| 61 |
+
Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
|
| 62 |
+
num_hidden_layers (`int`, *optional*, defaults to 12):
|
| 63 |
+
Number of hidden layers in the Transformer encoder.
|
| 64 |
+
num_attention_heads (`int`, *optional*, defaults to 12):
|
| 65 |
+
Number of attention heads for each attention layer in the Transformer encoder.
|
| 66 |
+
num_channels (`int`, *optional*, defaults to 3):
|
| 67 |
+
Number of channels in the input images.
|
| 68 |
+
image_size (`int`, *optional*, defaults to 224):
|
| 69 |
+
The size (resolution) of each image.
|
| 70 |
+
patch_size (`int`, *optional*, defaults to 16):
|
| 71 |
+
The size (resolution) of each patch.
|
| 72 |
+
hidden_act (`str` or `function`, *optional*, defaults to `"gelu_pytorch_tanh"`):
|
| 73 |
+
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
|
| 74 |
+
`"relu"`, `"selu"` and `"gelu_new"` ``"quick_gelu"` are supported.
|
| 75 |
+
layer_norm_eps (`float`, *optional*, defaults to 1e-06):
|
| 76 |
+
The epsilon used by the layer normalization layers.
|
| 77 |
+
attention_dropout (`float`, *optional*, defaults to 0.0):
|
| 78 |
+
The dropout ratio for the attention probabilities.
|
| 79 |
+
Example:
|
| 80 |
+
```python
|
| 81 |
+
>>> from transformers import SiglipVisionConfig, SiglipVisionModel
|
| 82 |
+
>>> # Initializing a SiglipVisionConfig with google/siglip-base-patch16-224 style configuration
|
| 83 |
+
>>> configuration = SiglipVisionConfig()
|
| 84 |
+
>>> # Initializing a SiglipVisionModel (with random weights) from the google/siglip-base-patch16-224 style configuration
|
| 85 |
+
>>> model = SiglipVisionModel(configuration)
|
| 86 |
+
>>> # Accessing the model configuration
|
| 87 |
+
>>> configuration = model.config
|
| 88 |
+
```"""
|
| 89 |
+
|
| 90 |
+
model_type = "siglip_vision_model"
|
| 91 |
+
|
| 92 |
+
def __init__(
|
| 93 |
+
self,
|
| 94 |
+
hidden_size=768,
|
| 95 |
+
intermediate_size=3072,
|
| 96 |
+
num_hidden_layers=12,
|
| 97 |
+
num_attention_heads=12,
|
| 98 |
+
num_channels=3,
|
| 99 |
+
image_size=224,
|
| 100 |
+
patch_size=16,
|
| 101 |
+
hidden_act="gelu_pytorch_tanh",
|
| 102 |
+
layer_norm_eps=1e-6,
|
| 103 |
+
attention_dropout=0.0,
|
| 104 |
+
**kwargs,
|
| 105 |
+
):
|
| 106 |
+
super().__init__(**kwargs)
|
| 107 |
+
|
| 108 |
+
self.hidden_size = hidden_size
|
| 109 |
+
self.intermediate_size = intermediate_size
|
| 110 |
+
self.num_hidden_layers = num_hidden_layers
|
| 111 |
+
self.num_attention_heads = num_attention_heads
|
| 112 |
+
self.num_channels = num_channels
|
| 113 |
+
self.patch_size = patch_size
|
| 114 |
+
self.image_size = image_size
|
| 115 |
+
self.attention_dropout = attention_dropout
|
| 116 |
+
self.layer_norm_eps = layer_norm_eps
|
| 117 |
+
self.hidden_act = hidden_act
|
| 118 |
+
|
| 119 |
+
@classmethod
|
| 120 |
+
def from_pretrained(cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs) -> "PretrainedConfig":
|
| 121 |
+
cls._set_token_in_kwargs(kwargs)
|
| 122 |
+
|
| 123 |
+
config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
|
| 124 |
+
|
| 125 |
+
# get the vision config dict if we are loading from SiglipConfig
|
| 126 |
+
if config_dict.get("model_type") == "siglip":
|
| 127 |
+
config_dict = config_dict["vision_config"]
|
| 128 |
+
|
| 129 |
+
if "model_type" in config_dict and hasattr(cls, "model_type") and config_dict["model_type"] != cls.model_type:
|
| 130 |
+
logger.warning(
|
| 131 |
+
f"You are using a model of type {config_dict['model_type']} to instantiate a model of type "
|
| 132 |
+
f"{cls.model_type}. This is not supported for all configurations of models and can yield errors."
|
| 133 |
+
)
|
| 134 |
+
|
| 135 |
+
return cls.from_dict(config_dict, **kwargs)
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
_CHECKPOINT_FOR_DOC = "google/siglip-base-patch16-224"
|
| 139 |
+
|
| 140 |
+
SIGLIP_PRETRAINED_MODEL_ARCHIVE_LIST = [
|
| 141 |
+
"google/siglip-base-patch16-224",
|
| 142 |
+
# See all SigLIP models at https://huggingface.co/models?filter=siglip
|
| 143 |
+
]
|
| 144 |
+
|
| 145 |
+
if is_flash_attn_2_available():
|
| 146 |
+
from flash_attn import flash_attn_func, flash_attn_varlen_func
|
| 147 |
+
from flash_attn.bert_padding import index_first_axis, pad_input, unpad_input # noqa
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
# Copied from transformers.models.llama.modeling_llama._get_unpad_data
|
| 151 |
+
def _get_unpad_data(attention_mask):
|
| 152 |
+
seqlens_in_batch = attention_mask.sum(dim=-1, dtype=torch.int32)
|
| 153 |
+
indices = torch.nonzero(attention_mask.flatten(), as_tuple=False).flatten()
|
| 154 |
+
max_seqlen_in_batch = seqlens_in_batch.max().item()
|
| 155 |
+
cu_seqlens = F.pad(torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.torch.int32), (1, 0))
|
| 156 |
+
return (
|
| 157 |
+
indices,
|
| 158 |
+
cu_seqlens,
|
| 159 |
+
max_seqlen_in_batch,
|
| 160 |
+
)
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
def _trunc_normal_(tensor, mean, std, a, b):
|
| 164 |
+
# Cut & paste from PyTorch official master until it's in a few official releases - RW
|
| 165 |
+
# Method based on https://people.sc.fsu.edu/~jburkardt/presentations/truncated_normal.pdf
|
| 166 |
+
def norm_cdf(x):
|
| 167 |
+
# Computes standard normal cumulative distribution function
|
| 168 |
+
return (1.0 + math.erf(x / math.sqrt(2.0))) / 2.0
|
| 169 |
+
|
| 170 |
+
if (mean < a - 2 * std) or (mean > b + 2 * std):
|
| 171 |
+
warnings.warn(
|
| 172 |
+
"mean is more than 2 std from [a, b] in nn.init.trunc_normal_. "
|
| 173 |
+
"The distribution of values may be incorrect.",
|
| 174 |
+
stacklevel=2,
|
| 175 |
+
)
|
| 176 |
+
|
| 177 |
+
# Values are generated by using a truncated uniform distribution and
|
| 178 |
+
# then using the inverse CDF for the normal distribution.
|
| 179 |
+
# Get upper and lower cdf values
|
| 180 |
+
l = norm_cdf((a - mean) / std)
|
| 181 |
+
u = norm_cdf((b - mean) / std)
|
| 182 |
+
|
| 183 |
+
# Uniformly fill tensor with values from [l, u], then translate to
|
| 184 |
+
# [2l-1, 2u-1].
|
| 185 |
+
tensor.uniform_(2 * l - 1, 2 * u - 1)
|
| 186 |
+
|
| 187 |
+
# Use inverse cdf transform for normal distribution to get truncated
|
| 188 |
+
# standard normal
|
| 189 |
+
if tensor.dtype in [torch.float16, torch.bfloat16]:
|
| 190 |
+
# The `erfinv_` op is not (yet?) defined in float16+cpu, bfloat16+gpu
|
| 191 |
+
og_dtype = tensor.dtype
|
| 192 |
+
tensor = tensor.to(torch.float32)
|
| 193 |
+
tensor.erfinv_()
|
| 194 |
+
tensor = tensor.to(og_dtype)
|
| 195 |
+
else:
|
| 196 |
+
tensor.erfinv_()
|
| 197 |
+
|
| 198 |
+
# Transform to proper mean, std
|
| 199 |
+
tensor.mul_(std * math.sqrt(2.0))
|
| 200 |
+
tensor.add_(mean)
|
| 201 |
+
|
| 202 |
+
# Clamp to ensure it's in the proper range
|
| 203 |
+
if tensor.dtype == torch.float16:
|
| 204 |
+
# The `clamp_` op is not (yet?) defined in float16+cpu
|
| 205 |
+
tensor = tensor.to(torch.float32)
|
| 206 |
+
tensor.clamp_(min=a, max=b)
|
| 207 |
+
tensor = tensor.to(torch.float16)
|
| 208 |
+
else:
|
| 209 |
+
tensor.clamp_(min=a, max=b)
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
def trunc_normal_tf_(
|
| 213 |
+
tensor: torch.Tensor, mean: float = 0.0, std: float = 1.0, a: float = -2.0, b: float = 2.0
|
| 214 |
+
) -> torch.Tensor:
|
| 215 |
+
"""Fills the input Tensor with values drawn from a truncated
|
| 216 |
+
normal distribution. The values are effectively drawn from the
|
| 217 |
+
normal distribution :math:`\\mathcal{N}(\text{mean}, \text{std}^2)`
|
| 218 |
+
with values outside :math:`[a, b]` redrawn until they are within
|
| 219 |
+
the bounds. The method used for generating the random values works
|
| 220 |
+
best when :math:`a \\leq \text{mean} \\leq b`.
|
| 221 |
+
NOTE: this 'tf' variant behaves closer to Tensorflow / JAX impl where the
|
| 222 |
+
bounds [a, b] are applied when sampling the normal distribution with mean=0, std=1.0
|
| 223 |
+
and the result is subsquently scaled and shifted by the mean and std args.
|
| 224 |
+
Args:
|
| 225 |
+
tensor: an n-dimensional `torch.Tensor`
|
| 226 |
+
mean: the mean of the normal distribution
|
| 227 |
+
std: the standard deviation of the normal distribution
|
| 228 |
+
a: the minimum cutoff value
|
| 229 |
+
b: the maximum cutoff value
|
| 230 |
+
"""
|
| 231 |
+
with torch.no_grad():
|
| 232 |
+
_trunc_normal_(tensor, 0, 1.0, a, b)
|
| 233 |
+
tensor.mul_(std).add_(mean)
|
| 234 |
+
|
| 235 |
+
|
| 236 |
+
def variance_scaling_(tensor, scale=1.0, mode="fan_in", distribution="normal"):
|
| 237 |
+
fan_in, fan_out = _calculate_fan_in_and_fan_out(tensor)
|
| 238 |
+
if mode == "fan_in":
|
| 239 |
+
denom = fan_in
|
| 240 |
+
elif mode == "fan_out":
|
| 241 |
+
denom = fan_out
|
| 242 |
+
elif mode == "fan_avg":
|
| 243 |
+
denom = (fan_in + fan_out) / 2
|
| 244 |
+
|
| 245 |
+
variance = scale / denom
|
| 246 |
+
|
| 247 |
+
if distribution == "truncated_normal":
|
| 248 |
+
# constant is stddev of standard normal truncated to (-2, 2)
|
| 249 |
+
trunc_normal_tf_(tensor, std=math.sqrt(variance) / 0.87962566103423978)
|
| 250 |
+
elif distribution == "normal":
|
| 251 |
+
with torch.no_grad():
|
| 252 |
+
tensor.normal_(std=math.sqrt(variance))
|
| 253 |
+
elif distribution == "uniform":
|
| 254 |
+
bound = math.sqrt(3 * variance)
|
| 255 |
+
with torch.no_grad():
|
| 256 |
+
tensor.uniform_(-bound, bound)
|
| 257 |
+
else:
|
| 258 |
+
raise ValueError(f"invalid distribution {distribution}")
|
| 259 |
+
|
| 260 |
+
|
| 261 |
+
def lecun_normal_(tensor):
|
| 262 |
+
variance_scaling_(tensor, mode="fan_in", distribution="truncated_normal")
|
| 263 |
+
|
| 264 |
+
|
| 265 |
+
def default_flax_embed_init(tensor):
|
| 266 |
+
variance_scaling_(tensor, mode="fan_in", distribution="normal")
|
| 267 |
+
|
| 268 |
+
|
| 269 |
+
@dataclass
|
| 270 |
+
# Copied from transformers.models.clip.modeling_clip.CLIPVisionModelOutput with CLIP->Siglip
|
| 271 |
+
class SiglipVisionModelOutput(ModelOutput):
|
| 272 |
+
"""
|
| 273 |
+
Base class for vision model's outputs that also contains image embeddings of the pooling of the last hidden states.
|
| 274 |
+
Args:
|
| 275 |
+
image_embeds (`torch.FloatTensor` of shape `(batch_size, output_dim)` *optional* returned when model is initialized with `with_projection=True`):
|
| 276 |
+
The image embeddings obtained by applying the projection layer to the pooler_output.
|
| 277 |
+
last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
|
| 278 |
+
Sequence of hidden-states at the output of the last layer of the model.
|
| 279 |
+
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
|
| 280 |
+
Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
|
| 281 |
+
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
|
| 282 |
+
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
|
| 283 |
+
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
|
| 284 |
+
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
|
| 285 |
+
sequence_length)`.
|
| 286 |
+
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
|
| 287 |
+
heads.
|
| 288 |
+
"""
|
| 289 |
+
|
| 290 |
+
image_embeds: Optional[torch.FloatTensor] = None
|
| 291 |
+
last_hidden_state: torch.FloatTensor = None
|
| 292 |
+
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
|
| 293 |
+
attentions: Optional[Tuple[torch.FloatTensor]] = None
|
| 294 |
+
|
| 295 |
+
|
| 296 |
+
class SiglipVisionEmbeddings(nn.Module):
|
| 297 |
+
def __init__(self, config: SiglipVisionConfig):
|
| 298 |
+
super().__init__()
|
| 299 |
+
self.config = config
|
| 300 |
+
self.embed_dim = config.hidden_size
|
| 301 |
+
self.image_size = config.image_size
|
| 302 |
+
self.patch_size = config.patch_size
|
| 303 |
+
|
| 304 |
+
self.patch_embedding = nn.Conv2d(
|
| 305 |
+
in_channels=config.num_channels,
|
| 306 |
+
out_channels=self.embed_dim,
|
| 307 |
+
kernel_size=self.patch_size,
|
| 308 |
+
stride=self.patch_size,
|
| 309 |
+
padding="valid",
|
| 310 |
+
)
|
| 311 |
+
|
| 312 |
+
self.num_patches_per_side = self.image_size // self.patch_size
|
| 313 |
+
self.num_patches = self.num_patches_per_side**2
|
| 314 |
+
self.num_positions = self.num_patches
|
| 315 |
+
self.position_embedding = nn.Embedding(self.num_positions, self.embed_dim)
|
| 316 |
+
|
| 317 |
+
def forward(self, pixel_values: torch.FloatTensor, patch_attention_mask: torch.BoolTensor, tgt_sizes: Optional[torch.IntTensor]=None) -> torch.Tensor:
|
| 318 |
+
batch_size = pixel_values.size(0)
|
| 319 |
+
|
| 320 |
+
patch_embeds = self.patch_embedding(pixel_values)
|
| 321 |
+
embeddings = patch_embeds.flatten(2).transpose(1, 2)
|
| 322 |
+
|
| 323 |
+
max_im_h, max_im_w = pixel_values.size(2), pixel_values.size(3)
|
| 324 |
+
max_nb_patches_h, max_nb_patches_w = max_im_h // self.patch_size, max_im_w // self.patch_size
|
| 325 |
+
boundaries = torch.arange(1 / self.num_patches_per_side, 1.0, 1 / self.num_patches_per_side)
|
| 326 |
+
position_ids = torch.full(
|
| 327 |
+
size=(
|
| 328 |
+
batch_size,
|
| 329 |
+
max_nb_patches_h * max_nb_patches_w,
|
| 330 |
+
),
|
| 331 |
+
fill_value=0,
|
| 332 |
+
)
|
| 333 |
+
|
| 334 |
+
for batch_idx, p_attn_mask in enumerate(patch_attention_mask):
|
| 335 |
+
if tgt_sizes is not None:
|
| 336 |
+
nb_patches_h = tgt_sizes[batch_idx][0]
|
| 337 |
+
nb_patches_w = tgt_sizes[batch_idx][1]
|
| 338 |
+
else:
|
| 339 |
+
nb_patches_h = p_attn_mask[:, 0].sum()
|
| 340 |
+
nb_patches_w = p_attn_mask[0].sum()
|
| 341 |
+
|
| 342 |
+
fractional_coords_h = torch.arange(0, 1 - 1e-6, 1 / nb_patches_h)
|
| 343 |
+
fractional_coords_w = torch.arange(0, 1 - 1e-6, 1 / nb_patches_w)
|
| 344 |
+
|
| 345 |
+
bucket_coords_h = torch.bucketize(fractional_coords_h, boundaries, right=True)
|
| 346 |
+
bucket_coords_w = torch.bucketize(fractional_coords_w, boundaries, right=True)
|
| 347 |
+
|
| 348 |
+
pos_ids = (bucket_coords_h[:, None] * self.num_patches_per_side + bucket_coords_w).flatten()
|
| 349 |
+
position_ids[batch_idx][p_attn_mask.view(-1).cpu()] = pos_ids
|
| 350 |
+
|
| 351 |
+
position_ids = position_ids.to(self.position_embedding.weight.device)
|
| 352 |
+
|
| 353 |
+
embeddings = embeddings + self.position_embedding(position_ids)
|
| 354 |
+
return embeddings
|
| 355 |
+
|
| 356 |
+
|
| 357 |
+
class SiglipAttention(nn.Module):
|
| 358 |
+
"""Multi-headed attention from 'Attention Is All You Need' paper"""
|
| 359 |
+
|
| 360 |
+
# Copied from transformers.models.clip.modeling_clip.CLIPAttention.__init__
|
| 361 |
+
def __init__(self, config):
|
| 362 |
+
super().__init__()
|
| 363 |
+
self.config = config
|
| 364 |
+
self.embed_dim = config.hidden_size
|
| 365 |
+
self.num_heads = config.num_attention_heads
|
| 366 |
+
self.head_dim = self.embed_dim // self.num_heads
|
| 367 |
+
if self.head_dim * self.num_heads != self.embed_dim:
|
| 368 |
+
raise ValueError(
|
| 369 |
+
f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:"
|
| 370 |
+
f" {self.num_heads})."
|
| 371 |
+
)
|
| 372 |
+
self.scale = self.head_dim**-0.5
|
| 373 |
+
self.dropout = config.attention_dropout
|
| 374 |
+
|
| 375 |
+
self.k_proj = nn.Linear(self.embed_dim, self.embed_dim)
|
| 376 |
+
self.v_proj = nn.Linear(self.embed_dim, self.embed_dim)
|
| 377 |
+
self.q_proj = nn.Linear(self.embed_dim, self.embed_dim)
|
| 378 |
+
self.out_proj = nn.Linear(self.embed_dim, self.embed_dim)
|
| 379 |
+
|
| 380 |
+
def forward(
|
| 381 |
+
self,
|
| 382 |
+
hidden_states: torch.Tensor,
|
| 383 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 384 |
+
output_attentions: Optional[bool] = False,
|
| 385 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 386 |
+
"""Input shape: Batch x Time x Channel"""
|
| 387 |
+
|
| 388 |
+
batch_size, q_len, _ = hidden_states.size()
|
| 389 |
+
|
| 390 |
+
query_states = self.q_proj(hidden_states)
|
| 391 |
+
key_states = self.k_proj(hidden_states)
|
| 392 |
+
value_states = self.v_proj(hidden_states)
|
| 393 |
+
|
| 394 |
+
query_states = query_states.view(batch_size, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
| 395 |
+
key_states = key_states.view(batch_size, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
| 396 |
+
value_states = value_states.view(batch_size, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
| 397 |
+
|
| 398 |
+
k_v_seq_len = key_states.shape[-2]
|
| 399 |
+
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) * self.scale
|
| 400 |
+
|
| 401 |
+
if attn_weights.size() != (batch_size, self.num_heads, q_len, k_v_seq_len):
|
| 402 |
+
raise ValueError(
|
| 403 |
+
f"Attention weights should be of size {(batch_size, self.num_heads, q_len, k_v_seq_len)}, but is"
|
| 404 |
+
f" {attn_weights.size()}"
|
| 405 |
+
)
|
| 406 |
+
|
| 407 |
+
if attention_mask is not None:
|
| 408 |
+
if attention_mask.size() != (batch_size, 1, q_len, k_v_seq_len):
|
| 409 |
+
raise ValueError(
|
| 410 |
+
f"Attention mask should be of size {(batch_size, 1, q_len, k_v_seq_len)}, but is {attention_mask.size()}"
|
| 411 |
+
)
|
| 412 |
+
attn_weights = attn_weights + attention_mask
|
| 413 |
+
|
| 414 |
+
# upcast attention to fp32
|
| 415 |
+
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
|
| 416 |
+
attn_weights = nn.functional.dropout(attn_weights, p=self.dropout, training=self.training)
|
| 417 |
+
attn_output = torch.matmul(attn_weights, value_states)
|
| 418 |
+
|
| 419 |
+
if attn_output.size() != (batch_size, self.num_heads, q_len, self.head_dim):
|
| 420 |
+
raise ValueError(
|
| 421 |
+
f"`attn_output` should be of size {(batch_size, self.num_heads, q_len, self.head_dim)}, but is"
|
| 422 |
+
f" {attn_output.size()}"
|
| 423 |
+
)
|
| 424 |
+
|
| 425 |
+
attn_output = attn_output.transpose(1, 2).contiguous()
|
| 426 |
+
attn_output = attn_output.reshape(batch_size, q_len, self.embed_dim)
|
| 427 |
+
|
| 428 |
+
attn_output = self.out_proj(attn_output)
|
| 429 |
+
|
| 430 |
+
return attn_output, attn_weights
|
| 431 |
+
|
| 432 |
+
|
| 433 |
+
class SiglipFlashAttention2(SiglipAttention):
|
| 434 |
+
"""
|
| 435 |
+
Llama flash attention module. This module inherits from `LlamaAttention` as the weights of the module stays
|
| 436 |
+
untouched. The only required change would be on the forward pass where it needs to correctly call the public API of
|
| 437 |
+
flash attention and deal with padding tokens in case the input contains any of them.
|
| 438 |
+
"""
|
| 439 |
+
|
| 440 |
+
def __init__(self, *args, **kwargs):
|
| 441 |
+
super().__init__(*args, **kwargs)
|
| 442 |
+
self.is_causal = False # Hack to make sure we don't use a causal mask
|
| 443 |
+
|
| 444 |
+
def forward(
|
| 445 |
+
self,
|
| 446 |
+
hidden_states: torch.Tensor,
|
| 447 |
+
attention_mask: Optional[torch.LongTensor] = None,
|
| 448 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 449 |
+
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
| 450 |
+
output_attentions: bool = False,
|
| 451 |
+
use_cache: bool = False,
|
| 452 |
+
**kwargs,
|
| 453 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 454 |
+
output_attentions = False
|
| 455 |
+
|
| 456 |
+
bsz, q_len, _ = hidden_states.size()
|
| 457 |
+
|
| 458 |
+
query_states = self.q_proj(hidden_states)
|
| 459 |
+
key_states = self.k_proj(hidden_states)
|
| 460 |
+
value_states = self.v_proj(hidden_states)
|
| 461 |
+
|
| 462 |
+
# Flash attention requires the input to have the shape
|
| 463 |
+
# batch_size x seq_length x head_dim x hidden_dim
|
| 464 |
+
# therefore we just need to keep the original shape
|
| 465 |
+
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
| 466 |
+
key_states = key_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
| 467 |
+
value_states = value_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
| 468 |
+
|
| 469 |
+
kv_seq_len = key_states.shape[-2]
|
| 470 |
+
if past_key_value is not None:
|
| 471 |
+
kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)
|
| 472 |
+
# cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
|
| 473 |
+
# query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
|
| 474 |
+
|
| 475 |
+
# if past_key_value is not None:
|
| 476 |
+
# cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE models
|
| 477 |
+
# key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
|
| 478 |
+
|
| 479 |
+
# TODO: These transpose are quite inefficient but Flash Attention requires the layout [batch_size, sequence_length, num_heads, head_dim]. We would need to refactor the KV cache
|
| 480 |
+
# to be able to avoid many of these transpose/reshape/view.
|
| 481 |
+
query_states = query_states.transpose(1, 2)
|
| 482 |
+
key_states = key_states.transpose(1, 2)
|
| 483 |
+
value_states = value_states.transpose(1, 2)
|
| 484 |
+
|
| 485 |
+
dropout_rate = self.dropout if self.training else 0.0
|
| 486 |
+
|
| 487 |
+
# In PEFT, usually we cast the layer norms in float32 for training stability reasons
|
| 488 |
+
# therefore the input hidden states gets silently casted in float32. Hence, we need
|
| 489 |
+
# cast them back in the correct dtype just to be sure everything works as expected.
|
| 490 |
+
# This might slowdown training & inference so it is recommended to not cast the LayerNorms
|
| 491 |
+
# in fp32. (LlamaRMSNorm handles it correctly)
|
| 492 |
+
|
| 493 |
+
input_dtype = query_states.dtype
|
| 494 |
+
if input_dtype == torch.float32:
|
| 495 |
+
if torch.is_autocast_enabled():
|
| 496 |
+
target_dtype = torch.get_autocast_gpu_dtype()
|
| 497 |
+
# Handle the case where the model is quantized
|
| 498 |
+
elif hasattr(self.config, "_pre_quantization_dtype"):
|
| 499 |
+
target_dtype = self.config._pre_quantization_dtype
|
| 500 |
+
else:
|
| 501 |
+
target_dtype = self.q_proj.weight.dtype
|
| 502 |
+
|
| 503 |
+
logger.warning_once(
|
| 504 |
+
"The input hidden states seems to be silently casted in float32, this might be related to the fact"
|
| 505 |
+
" you have upcasted embedding or layer norm layers in float32. We will cast back the input in"
|
| 506 |
+
f" {target_dtype}."
|
| 507 |
+
)
|
| 508 |
+
|
| 509 |
+
query_states = query_states.to(target_dtype)
|
| 510 |
+
key_states = key_states.to(target_dtype)
|
| 511 |
+
value_states = value_states.to(target_dtype)
|
| 512 |
+
|
| 513 |
+
attn_output = self._flash_attention_forward(
|
| 514 |
+
query_states, key_states, value_states, attention_mask, q_len, dropout=dropout_rate
|
| 515 |
+
)
|
| 516 |
+
|
| 517 |
+
attn_output = attn_output.reshape(bsz, q_len, self.embed_dim).contiguous()
|
| 518 |
+
attn_output = self.out_proj(attn_output)
|
| 519 |
+
|
| 520 |
+
if not output_attentions:
|
| 521 |
+
attn_weights = None
|
| 522 |
+
|
| 523 |
+
return attn_output, attn_weights
|
| 524 |
+
|
| 525 |
+
def _flash_attention_forward(
|
| 526 |
+
self, query_states, key_states, value_states, attention_mask, query_length, dropout=0.0, softmax_scale=None
|
| 527 |
+
):
|
| 528 |
+
"""
|
| 529 |
+
Calls the forward method of Flash Attention - if the input hidden states contain at least one padding token
|
| 530 |
+
first unpad the input, then computes the attention scores and pad the final attention scores.
|
| 531 |
+
Args:
|
| 532 |
+
query_states (`torch.Tensor`):
|
| 533 |
+
Input query states to be passed to Flash Attention API
|
| 534 |
+
key_states (`torch.Tensor`):
|
| 535 |
+
Input key states to be passed to Flash Attention API
|
| 536 |
+
value_states (`torch.Tensor`):
|
| 537 |
+
Input value states to be passed to Flash Attention API
|
| 538 |
+
attention_mask (`torch.Tensor`):
|
| 539 |
+
The padding mask - corresponds to a tensor of size `(batch_size, seq_len)` where 0 stands for the
|
| 540 |
+
position of padding tokens and 1 for the position of non-padding tokens.
|
| 541 |
+
dropout (`int`, *optional*):
|
| 542 |
+
Attention dropout
|
| 543 |
+
softmax_scale (`float`, *optional*):
|
| 544 |
+
The scaling of QK^T before applying softmax. Default to 1 / sqrt(head_dim)
|
| 545 |
+
"""
|
| 546 |
+
|
| 547 |
+
# TODO: Remove the `query_length != 1` check once Flash Attention for RoCm is bumped to 2.1. For details, please see the comment in LlamaFlashAttention2 __init__.
|
| 548 |
+
causal = self.is_causal and query_length != 1
|
| 549 |
+
|
| 550 |
+
# Contains at least one padding token in the sequence
|
| 551 |
+
if attention_mask is not None:
|
| 552 |
+
batch_size = query_states.shape[0]
|
| 553 |
+
query_states, key_states, value_states, indices_q, cu_seq_lens, max_seq_lens = self._upad_input(
|
| 554 |
+
query_states, key_states, value_states, attention_mask, query_length
|
| 555 |
+
)
|
| 556 |
+
|
| 557 |
+
cu_seqlens_q, cu_seqlens_k = cu_seq_lens
|
| 558 |
+
max_seqlen_in_batch_q, max_seqlen_in_batch_k = max_seq_lens
|
| 559 |
+
|
| 560 |
+
attn_output_unpad = flash_attn_varlen_func(
|
| 561 |
+
query_states,
|
| 562 |
+
key_states,
|
| 563 |
+
value_states,
|
| 564 |
+
cu_seqlens_q=cu_seqlens_q,
|
| 565 |
+
cu_seqlens_k=cu_seqlens_k,
|
| 566 |
+
max_seqlen_q=max_seqlen_in_batch_q,
|
| 567 |
+
max_seqlen_k=max_seqlen_in_batch_k,
|
| 568 |
+
dropout_p=dropout,
|
| 569 |
+
softmax_scale=softmax_scale,
|
| 570 |
+
causal=causal,
|
| 571 |
+
)
|
| 572 |
+
|
| 573 |
+
attn_output = pad_input(attn_output_unpad, indices_q, batch_size, query_length)
|
| 574 |
+
else:
|
| 575 |
+
attn_output = flash_attn_func(
|
| 576 |
+
query_states, key_states, value_states, dropout, softmax_scale=softmax_scale, causal=causal
|
| 577 |
+
)
|
| 578 |
+
|
| 579 |
+
return attn_output
|
| 580 |
+
|
| 581 |
+
def _upad_input(self, query_layer, key_layer, value_layer, attention_mask, query_length):
|
| 582 |
+
indices_k, cu_seqlens_k, max_seqlen_in_batch_k = _get_unpad_data(attention_mask)
|
| 583 |
+
batch_size, kv_seq_len, num_key_value_heads, head_dim = key_layer.shape
|
| 584 |
+
|
| 585 |
+
key_layer = index_first_axis(
|
| 586 |
+
key_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k
|
| 587 |
+
)
|
| 588 |
+
value_layer = index_first_axis(
|
| 589 |
+
value_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k
|
| 590 |
+
)
|
| 591 |
+
if query_length == kv_seq_len:
|
| 592 |
+
query_layer = index_first_axis(
|
| 593 |
+
query_layer.reshape(batch_size * kv_seq_len, self.num_heads, head_dim), indices_k
|
| 594 |
+
)
|
| 595 |
+
cu_seqlens_q = cu_seqlens_k
|
| 596 |
+
max_seqlen_in_batch_q = max_seqlen_in_batch_k
|
| 597 |
+
indices_q = indices_k
|
| 598 |
+
elif query_length == 1:
|
| 599 |
+
max_seqlen_in_batch_q = 1
|
| 600 |
+
cu_seqlens_q = torch.arange(
|
| 601 |
+
batch_size + 1, dtype=torch.int32, device=query_layer.device
|
| 602 |
+
) # There is a memcpy here, that is very bad.
|
| 603 |
+
indices_q = cu_seqlens_q[:-1]
|
| 604 |
+
query_layer = query_layer.squeeze(1)
|
| 605 |
+
else:
|
| 606 |
+
# The -q_len: slice assumes left padding.
|
| 607 |
+
attention_mask = attention_mask[:, -query_length:]
|
| 608 |
+
query_layer, indices_q, cu_seqlens_q, max_seqlen_in_batch_q = unpad_input(query_layer, attention_mask)
|
| 609 |
+
|
| 610 |
+
return (
|
| 611 |
+
query_layer,
|
| 612 |
+
key_layer,
|
| 613 |
+
value_layer,
|
| 614 |
+
indices_q,
|
| 615 |
+
(cu_seqlens_q, cu_seqlens_k),
|
| 616 |
+
(max_seqlen_in_batch_q, max_seqlen_in_batch_k),
|
| 617 |
+
)
|
| 618 |
+
|
| 619 |
+
|
| 620 |
+
# Copied from transformers.models.clip.modeling_clip.CLIPMLP with CLIP->Siglip
|
| 621 |
+
class SiglipMLP(nn.Module):
|
| 622 |
+
def __init__(self, config):
|
| 623 |
+
super().__init__()
|
| 624 |
+
self.config = config
|
| 625 |
+
self.activation_fn = ACT2FN[config.hidden_act]
|
| 626 |
+
self.fc1 = nn.Linear(config.hidden_size, config.intermediate_size)
|
| 627 |
+
self.fc2 = nn.Linear(config.intermediate_size, config.hidden_size)
|
| 628 |
+
|
| 629 |
+
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
|
| 630 |
+
hidden_states = self.fc1(hidden_states)
|
| 631 |
+
hidden_states = self.activation_fn(hidden_states)
|
| 632 |
+
hidden_states = self.fc2(hidden_states)
|
| 633 |
+
return hidden_states
|
| 634 |
+
|
| 635 |
+
|
| 636 |
+
# Copied from transformers.models.clip.modeling_clip.CLIPEncoderLayer with CLIP->Siglip
|
| 637 |
+
class SiglipEncoderLayer(nn.Module):
|
| 638 |
+
def __init__(self, config: SiglipVisionConfig):
|
| 639 |
+
super().__init__()
|
| 640 |
+
self.embed_dim = config.hidden_size
|
| 641 |
+
self._use_flash_attention_2 = config._attn_implementation == "flash_attention_2"
|
| 642 |
+
self.self_attn = (
|
| 643 |
+
SiglipAttention(config)
|
| 644 |
+
if not self._use_flash_attention_2
|
| 645 |
+
else SiglipFlashAttention2(config)
|
| 646 |
+
)
|
| 647 |
+
self.layer_norm1 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
|
| 648 |
+
self.mlp = SiglipMLP(config)
|
| 649 |
+
self.layer_norm2 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
|
| 650 |
+
|
| 651 |
+
def forward(
|
| 652 |
+
self,
|
| 653 |
+
hidden_states: torch.Tensor,
|
| 654 |
+
attention_mask: torch.Tensor,
|
| 655 |
+
output_attentions: Optional[bool] = False,
|
| 656 |
+
) -> Tuple[torch.FloatTensor]:
|
| 657 |
+
"""
|
| 658 |
+
Args:
|
| 659 |
+
hidden_states (`torch.FloatTensor`):
|
| 660 |
+
Input to the layer of shape `(batch, seq_len, embed_dim)`.
|
| 661 |
+
attention_mask (`torch.FloatTensor`):
|
| 662 |
+
Attention mask of shape `(batch, 1, q_len, k_v_seq_len)` where padding elements are indicated by very large negative values.
|
| 663 |
+
output_attentions (`bool`, *optional*, defaults to `False`):
|
| 664 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
|
| 665 |
+
returned tensors for more detail.
|
| 666 |
+
"""
|
| 667 |
+
residual = hidden_states
|
| 668 |
+
|
| 669 |
+
hidden_states = self.layer_norm1(hidden_states)
|
| 670 |
+
hidden_states, attn_weights = self.self_attn(
|
| 671 |
+
hidden_states=hidden_states,
|
| 672 |
+
attention_mask=attention_mask,
|
| 673 |
+
output_attentions=output_attentions,
|
| 674 |
+
)
|
| 675 |
+
hidden_states = residual + hidden_states
|
| 676 |
+
|
| 677 |
+
residual = hidden_states
|
| 678 |
+
hidden_states = self.layer_norm2(hidden_states)
|
| 679 |
+
hidden_states = self.mlp(hidden_states)
|
| 680 |
+
hidden_states = residual + hidden_states
|
| 681 |
+
|
| 682 |
+
outputs = (hidden_states,)
|
| 683 |
+
|
| 684 |
+
if output_attentions:
|
| 685 |
+
outputs += (attn_weights,)
|
| 686 |
+
|
| 687 |
+
return outputs
|
| 688 |
+
|
| 689 |
+
|
| 690 |
+
class SiglipPreTrainedModel(PreTrainedModel):
|
| 691 |
+
"""
|
| 692 |
+
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
|
| 693 |
+
models.
|
| 694 |
+
"""
|
| 695 |
+
|
| 696 |
+
config_class = SiglipVisionConfig
|
| 697 |
+
base_model_prefix = "siglip"
|
| 698 |
+
supports_gradient_checkpointing = True
|
| 699 |
+
|
| 700 |
+
def _init_weights(self, module):
|
| 701 |
+
"""Initialize the weights"""
|
| 702 |
+
|
| 703 |
+
if isinstance(module, SiglipVisionEmbeddings):
|
| 704 |
+
width = self.config.hidden_size
|
| 705 |
+
nn.init.normal_(module.position_embedding.weight, std=1 / np.sqrt(width))
|
| 706 |
+
elif isinstance(module, nn.Embedding):
|
| 707 |
+
default_flax_embed_init(module.weight)
|
| 708 |
+
elif isinstance(module, SiglipAttention):
|
| 709 |
+
nn.init.normal_(module.q_proj.weight)
|
| 710 |
+
nn.init.normal_(module.k_proj.weight)
|
| 711 |
+
nn.init.normal_(module.v_proj.weight)
|
| 712 |
+
nn.init.normal_(module.out_proj.weight)
|
| 713 |
+
nn.init.zeros_(module.q_proj.bias)
|
| 714 |
+
nn.init.zeros_(module.k_proj.bias)
|
| 715 |
+
nn.init.zeros_(module.v_proj.bias)
|
| 716 |
+
nn.init.zeros_(module.out_proj.bias)
|
| 717 |
+
elif isinstance(module, SiglipMLP):
|
| 718 |
+
nn.init.normal_(module.fc1.weight)
|
| 719 |
+
nn.init.normal_(module.fc2.weight)
|
| 720 |
+
nn.init.normal_(module.fc1.bias, std=1e-6)
|
| 721 |
+
nn.init.normal_(module.fc2.bias, std=1e-6)
|
| 722 |
+
elif isinstance(module, (nn.Linear, nn.Conv2d)):
|
| 723 |
+
lecun_normal_(module.weight)
|
| 724 |
+
if module.bias is not None:
|
| 725 |
+
nn.init.zeros_(module.bias)
|
| 726 |
+
elif isinstance(module, nn.LayerNorm):
|
| 727 |
+
module.bias.data.zero_()
|
| 728 |
+
module.weight.data.fill_(1.0)
|
| 729 |
+
|
| 730 |
+
|
| 731 |
+
SIGLIP_START_DOCSTRING = r"""
|
| 732 |
+
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
|
| 733 |
+
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
|
| 734 |
+
etc.)
|
| 735 |
+
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
|
| 736 |
+
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
|
| 737 |
+
and behavior.
|
| 738 |
+
Parameters:
|
| 739 |
+
config ([`SiglipVisionConfig`]): Model configuration class with all the parameters of the model.
|
| 740 |
+
Initializing with a config file does not load the weights associated with the model, only the
|
| 741 |
+
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
|
| 742 |
+
"""
|
| 743 |
+
|
| 744 |
+
|
| 745 |
+
SIGLIP_VISION_INPUTS_DOCSTRING = r"""
|
| 746 |
+
Args:
|
| 747 |
+
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
|
| 748 |
+
Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
|
| 749 |
+
[`AutoImageProcessor`]. See [`CLIPImageProcessor.__call__`] for details.
|
| 750 |
+
output_attentions (`bool`, *optional*):
|
| 751 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
|
| 752 |
+
tensors for more detail.
|
| 753 |
+
output_hidden_states (`bool`, *optional*):
|
| 754 |
+
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
|
| 755 |
+
more detail.
|
| 756 |
+
return_dict (`bool`, *optional*):
|
| 757 |
+
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
| 758 |
+
"""
|
| 759 |
+
|
| 760 |
+
|
| 761 |
+
# Copied from transformers.models.clip.modeling_clip.CLIPEncoder with CLIP->Siglip
|
| 762 |
+
class SiglipEncoder(nn.Module):
|
| 763 |
+
"""
|
| 764 |
+
Transformer encoder consisting of `config.num_hidden_layers` self attention layers. Each layer is a
|
| 765 |
+
[`SiglipEncoderLayer`].
|
| 766 |
+
Args:
|
| 767 |
+
config: SiglipConfig
|
| 768 |
+
"""
|
| 769 |
+
|
| 770 |
+
def __init__(self, config: SiglipVisionConfig):
|
| 771 |
+
super().__init__()
|
| 772 |
+
self.config = config
|
| 773 |
+
self.layers = nn.ModuleList([SiglipEncoderLayer(config) for _ in range(config.num_hidden_layers)])
|
| 774 |
+
self.gradient_checkpointing = False
|
| 775 |
+
|
| 776 |
+
# Ignore copy
|
| 777 |
+
def forward(
|
| 778 |
+
self,
|
| 779 |
+
inputs_embeds,
|
| 780 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 781 |
+
output_attentions: Optional[bool] = None,
|
| 782 |
+
output_hidden_states: Optional[bool] = None,
|
| 783 |
+
return_dict: Optional[bool] = None,
|
| 784 |
+
) -> Union[Tuple, BaseModelOutput]:
|
| 785 |
+
r"""
|
| 786 |
+
Args:
|
| 787 |
+
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
|
| 788 |
+
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
|
| 789 |
+
This is useful if you want more control over how to convert `input_ids` indices into associated vectors
|
| 790 |
+
than the model's internal embedding lookup matrix.
|
| 791 |
+
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 792 |
+
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
|
| 793 |
+
- 1 for tokens that are **not masked**,
|
| 794 |
+
- 0 for tokens that are **masked**.
|
| 795 |
+
[What are attention masks?](../glossary#attention-mask)
|
| 796 |
+
output_attentions (`bool`, *optional*):
|
| 797 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
|
| 798 |
+
returned tensors for more detail.
|
| 799 |
+
output_hidden_states (`bool`, *optional*):
|
| 800 |
+
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
|
| 801 |
+
for more detail.
|
| 802 |
+
return_dict (`bool`, *optional*):
|
| 803 |
+
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
| 804 |
+
"""
|
| 805 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 806 |
+
output_hidden_states = (
|
| 807 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 808 |
+
)
|
| 809 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 810 |
+
|
| 811 |
+
encoder_states = () if output_hidden_states else None
|
| 812 |
+
all_attentions = () if output_attentions else None
|
| 813 |
+
|
| 814 |
+
hidden_states = inputs_embeds
|
| 815 |
+
for encoder_layer in self.layers:
|
| 816 |
+
if output_hidden_states:
|
| 817 |
+
encoder_states = encoder_states + (hidden_states,)
|
| 818 |
+
if self.gradient_checkpointing and self.training:
|
| 819 |
+
layer_outputs = self._gradient_checkpointing_func(
|
| 820 |
+
encoder_layer.__call__,
|
| 821 |
+
hidden_states,
|
| 822 |
+
attention_mask,
|
| 823 |
+
output_attentions,
|
| 824 |
+
)
|
| 825 |
+
else:
|
| 826 |
+
layer_outputs = encoder_layer(
|
| 827 |
+
hidden_states,
|
| 828 |
+
attention_mask,
|
| 829 |
+
output_attentions=output_attentions,
|
| 830 |
+
)
|
| 831 |
+
|
| 832 |
+
hidden_states = layer_outputs[0]
|
| 833 |
+
|
| 834 |
+
if output_attentions:
|
| 835 |
+
all_attentions = all_attentions + (layer_outputs[1],)
|
| 836 |
+
|
| 837 |
+
if output_hidden_states:
|
| 838 |
+
encoder_states = encoder_states + (hidden_states,)
|
| 839 |
+
|
| 840 |
+
if not return_dict:
|
| 841 |
+
return tuple(v for v in [hidden_states, encoder_states, all_attentions] if v is not None)
|
| 842 |
+
return BaseModelOutput(
|
| 843 |
+
last_hidden_state=hidden_states, hidden_states=encoder_states, attentions=all_attentions
|
| 844 |
+
)
|
| 845 |
+
|
| 846 |
+
@add_start_docstrings(
|
| 847 |
+
"""The vision model from SigLIP without any head or projection on top.""",
|
| 848 |
+
SIGLIP_START_DOCSTRING
|
| 849 |
+
)
|
| 850 |
+
class SiglipVisionTransformer(SiglipPreTrainedModel):
|
| 851 |
+
config_class = SiglipVisionConfig
|
| 852 |
+
main_input_name = "pixel_values"
|
| 853 |
+
_supports_flash_attn_2 = True
|
| 854 |
+
|
| 855 |
+
def __init__(self, config: SiglipVisionConfig):
|
| 856 |
+
super().__init__(config)
|
| 857 |
+
self.config = config
|
| 858 |
+
embed_dim = config.hidden_size
|
| 859 |
+
|
| 860 |
+
self.embeddings = SiglipVisionEmbeddings(config)
|
| 861 |
+
self.encoder = SiglipEncoder(config)
|
| 862 |
+
self.post_layernorm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
|
| 863 |
+
self._use_flash_attention_2 = config._attn_implementation == "flash_attention_2"
|
| 864 |
+
|
| 865 |
+
# Initialize weights and apply final processing
|
| 866 |
+
self.post_init()
|
| 867 |
+
|
| 868 |
+
def get_input_embeddings(self) -> nn.Module:
|
| 869 |
+
return self.embeddings.patch_embedding
|
| 870 |
+
|
| 871 |
+
@add_start_docstrings_to_model_forward(SIGLIP_VISION_INPUTS_DOCSTRING)
|
| 872 |
+
@replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=SiglipVisionConfig)
|
| 873 |
+
def forward(
|
| 874 |
+
self,
|
| 875 |
+
pixel_values,
|
| 876 |
+
patch_attention_mask: Optional[torch.BoolTensor] = None,
|
| 877 |
+
tgt_sizes: Optional[torch.IntTensor] = None,
|
| 878 |
+
output_attentions: Optional[bool] = None,
|
| 879 |
+
output_hidden_states: Optional[bool] = None,
|
| 880 |
+
return_dict: Optional[bool] = None,
|
| 881 |
+
) -> Union[Tuple, BaseModelOutputWithPooling]:
|
| 882 |
+
r"""
|
| 883 |
+
Returns:
|
| 884 |
+
"""
|
| 885 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 886 |
+
output_hidden_states = (
|
| 887 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 888 |
+
)
|
| 889 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 890 |
+
|
| 891 |
+
batch_size = pixel_values.size(0)
|
| 892 |
+
if patch_attention_mask is None:
|
| 893 |
+
patch_attention_mask = torch.ones(
|
| 894 |
+
size=(
|
| 895 |
+
batch_size,
|
| 896 |
+
pixel_values.size(2) // self.config.patch_size,
|
| 897 |
+
pixel_values.size(3) // self.config.patch_size,
|
| 898 |
+
),
|
| 899 |
+
dtype=torch.bool,
|
| 900 |
+
device=pixel_values.device,
|
| 901 |
+
)
|
| 902 |
+
|
| 903 |
+
hidden_states = self.embeddings(pixel_values=pixel_values, patch_attention_mask=patch_attention_mask, tgt_sizes=tgt_sizes)
|
| 904 |
+
|
| 905 |
+
patch_attention_mask = patch_attention_mask.view(batch_size, -1)
|
| 906 |
+
# The call to `_upad_input` in `_flash_attention_forward` is expensive
|
| 907 |
+
# So when the `patch_attention_mask` is full of 1s (i.e. attending to the whole sequence),
|
| 908 |
+
# avoiding passing the attention_mask, which is equivalent to attending to the full sequence
|
| 909 |
+
if not torch.any(~patch_attention_mask):
|
| 910 |
+
attention_mask=None
|
| 911 |
+
else:
|
| 912 |
+
attention_mask = (
|
| 913 |
+
_prepare_4d_attention_mask(patch_attention_mask, hidden_states.dtype)
|
| 914 |
+
if not self._use_flash_attention_2
|
| 915 |
+
else patch_attention_mask
|
| 916 |
+
)
|
| 917 |
+
|
| 918 |
+
encoder_outputs = self.encoder(
|
| 919 |
+
inputs_embeds=hidden_states,
|
| 920 |
+
attention_mask=attention_mask,
|
| 921 |
+
output_attentions=output_attentions,
|
| 922 |
+
output_hidden_states=output_hidden_states,
|
| 923 |
+
return_dict=return_dict,
|
| 924 |
+
)
|
| 925 |
+
|
| 926 |
+
last_hidden_state = encoder_outputs[0]
|
| 927 |
+
last_hidden_state = self.post_layernorm(last_hidden_state)
|
| 928 |
+
|
| 929 |
+
if not return_dict:
|
| 930 |
+
return (last_hidden_state, None) + encoder_outputs[1:]
|
| 931 |
+
|
| 932 |
+
return BaseModelOutputWithPooling(
|
| 933 |
+
last_hidden_state=last_hidden_state,
|
| 934 |
+
pooler_output=None,
|
| 935 |
+
hidden_states=encoder_outputs.hidden_states,
|
| 936 |
+
attentions=encoder_outputs.attentions,
|
| 937 |
+
)
|
preprocessor_config.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"image_processor_type": "MiniCPMVImageProcessor",
|
| 3 |
+
"auto_map": {
|
| 4 |
+
"AutoProcessor": "processing_minicpmv.MiniCPMVProcessor",
|
| 5 |
+
"AutoImageProcessor": "image_processing_minicpmv.MiniCPMVImageProcessor"
|
| 6 |
+
},
|
| 7 |
+
"processor_class": "MiniCPMVProcessor",
|
| 8 |
+
"max_slice_nums": 9,
|
| 9 |
+
"scale_resolution": 448,
|
| 10 |
+
"patch_size": 14,
|
| 11 |
+
"use_image_id": true,
|
| 12 |
+
"image_feature_size": 64,
|
| 13 |
+
"im_start": "<image>",
|
| 14 |
+
"im_end": "</image>",
|
| 15 |
+
"slice_start": "<slice>",
|
| 16 |
+
"slice_end": "</slice>",
|
| 17 |
+
"unk": "<unk>",
|
| 18 |
+
"im_id_start": "<image_id>",
|
| 19 |
+
"im_id_end": "</image_id>",
|
| 20 |
+
"slice_mode": true,
|
| 21 |
+
"norm_mean": [0.5, 0.5, 0.5],
|
| 22 |
+
"norm_std": [0.5, 0.5, 0.5],
|
| 23 |
+
"version": 2.6
|
| 24 |
+
}
|
processing_minicpmv.py
ADDED
|
@@ -0,0 +1,240 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2024 The HuggingFace Inc. team.
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
"""
|
| 16 |
+
Processor class for MiniCPMV.
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
from typing import List, Optional, Union, Dict, Any
|
| 20 |
+
import torch
|
| 21 |
+
import re
|
| 22 |
+
|
| 23 |
+
from transformers.image_processing_utils import BatchFeature
|
| 24 |
+
from transformers.image_utils import ImageInput
|
| 25 |
+
from transformers.processing_utils import ProcessorMixin
|
| 26 |
+
from transformers.tokenization_utils_base import PaddingStrategy, PreTokenizedInput, TextInput, TruncationStrategy
|
| 27 |
+
from transformers.utils import TensorType, requires_backends, is_torch_dtype, is_torch_device
|
| 28 |
+
|
| 29 |
+
from .image_processing_minicpmv import MiniCPMVBatchFeature
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
class MiniCPMVProcessor(ProcessorMixin):
|
| 33 |
+
r"""
|
| 34 |
+
Constructs a MiniCPMV processor which wraps a MiniCPMV image processor and a MiniCPMV tokenizer into a single processor.
|
| 35 |
+
|
| 36 |
+
[`MiniCPMVProcessor`] offers all the functionalities of [`MiniCPMVImageProcessor`] and [`LlamaTokenizerWrapper`]. See the
|
| 37 |
+
[`~MiniCPMVProcessor.__call__`] and [`~MiniCPMVProcessor.decode`] for more information.
|
| 38 |
+
|
| 39 |
+
Args:
|
| 40 |
+
image_processor ([`MiniCPMVImageProcessor`], *optional*):
|
| 41 |
+
The image processor is a required input.
|
| 42 |
+
tokenizer ([`LlamaTokenizerWrapper`], *optional*):
|
| 43 |
+
The tokenizer is a required input.
|
| 44 |
+
"""
|
| 45 |
+
attributes = ["image_processor", "tokenizer"]
|
| 46 |
+
image_processor_class = "AutoImageProcessor"
|
| 47 |
+
tokenizer_class = "AutoTokenizer"
|
| 48 |
+
|
| 49 |
+
def __init__(self, image_processor=None, tokenizer=None):
|
| 50 |
+
super().__init__(image_processor, tokenizer)
|
| 51 |
+
self.version = image_processor.version
|
| 52 |
+
|
| 53 |
+
def __call__(
|
| 54 |
+
self,
|
| 55 |
+
text: Union[TextInput, PreTokenizedInput, List[TextInput], List[PreTokenizedInput]],
|
| 56 |
+
images: ImageInput = None,
|
| 57 |
+
max_length: Optional[int] = None,
|
| 58 |
+
do_pad: Optional[bool] = True,
|
| 59 |
+
max_slice_nums: int = None,
|
| 60 |
+
use_image_id: bool = None,
|
| 61 |
+
return_tensors: Optional[Union[str, TensorType]] = TensorType.PYTORCH,
|
| 62 |
+
**kwargs
|
| 63 |
+
) -> MiniCPMVBatchFeature:
|
| 64 |
+
|
| 65 |
+
if images is not None:
|
| 66 |
+
image_inputs = self.image_processor(images, do_pad=do_pad, max_slice_nums=max_slice_nums, return_tensors=return_tensors)
|
| 67 |
+
return self._convert_images_texts_to_inputs(image_inputs, text, max_slice_nums=max_slice_nums, use_image_id=use_image_id, max_length=max_length, **kwargs)
|
| 68 |
+
|
| 69 |
+
# Copied from transformers.models.clip.processing_clip.CLIPProcessor.batch_decode with CLIP->Llama
|
| 70 |
+
def batch_decode(self, *args, **kwargs):
|
| 71 |
+
"""
|
| 72 |
+
This method forwards all its arguments to LlamaTokenizerFast's [`~PreTrainedTokenizer.batch_decode`]. Please
|
| 73 |
+
refer to the docstring of this method for more information.
|
| 74 |
+
"""
|
| 75 |
+
output_ids = args[0]
|
| 76 |
+
result_text = []
|
| 77 |
+
for result in output_ids:
|
| 78 |
+
result = result[result != 0]
|
| 79 |
+
if result[0] == self.tokenizer.bos_id:
|
| 80 |
+
result = result[1:]
|
| 81 |
+
if result[-1] == self.tokenizer.eos_id:
|
| 82 |
+
result = result[:-1]
|
| 83 |
+
result_text.append(self.tokenizer.decode(result, *args[1:], **kwargs).strip())
|
| 84 |
+
return result_text
|
| 85 |
+
# return self.tokenizer.batch_decode(*args, **kwargs)
|
| 86 |
+
|
| 87 |
+
# Copied from transformers.models.clip.processing_clip.CLIPProcessor.decode with CLIP->Llama
|
| 88 |
+
def decode(self, *args, **kwargs):
|
| 89 |
+
"""
|
| 90 |
+
This method forwards all its arguments to LlamaTokenizerFast's [`~PreTrainedTokenizer.decode`]. Please refer to
|
| 91 |
+
the docstring of this method for more information.
|
| 92 |
+
"""
|
| 93 |
+
result = args[0]
|
| 94 |
+
result = result[result != 0]
|
| 95 |
+
if result[0] == self.tokenizer.bos_id:
|
| 96 |
+
result = result[1:]
|
| 97 |
+
if result[-1] == self.tokenizer.eos_id or (hasattr(self.tokenizer, "eot_id") and result[-1] == self.tokenizer.eot_id):
|
| 98 |
+
result = result[:-1]
|
| 99 |
+
return self.tokenizer.decode(result, *args[1:], **kwargs).strip()
|
| 100 |
+
|
| 101 |
+
def _convert(
|
| 102 |
+
self, input_str, max_inp_length: Optional[int] = None
|
| 103 |
+
):
|
| 104 |
+
if self.version > 2.5 or not getattr(self.tokenizer, "add_bos_token", False):
|
| 105 |
+
input_ids = self.tokenizer.encode(input_str)
|
| 106 |
+
else:
|
| 107 |
+
input_ids = [self.tokenizer.bos_id] + self.tokenizer.encode(input_str)
|
| 108 |
+
if max_inp_length is not None:
|
| 109 |
+
input_ids = input_ids[:max_inp_length]
|
| 110 |
+
input_ids = torch.tensor(input_ids, dtype=torch.int32)
|
| 111 |
+
|
| 112 |
+
start_cond = (input_ids == self.tokenizer.im_start_id) | (input_ids == self.tokenizer.slice_start_id)
|
| 113 |
+
end_cond = (input_ids == self.tokenizer.im_end_id) | (input_ids == self.tokenizer.slice_end_id)
|
| 114 |
+
|
| 115 |
+
image_start_tokens = torch.where(start_cond)[0]
|
| 116 |
+
image_start_tokens += 1
|
| 117 |
+
image_end_tokens = torch.where(end_cond)[0]
|
| 118 |
+
|
| 119 |
+
valid_image_nums = max(len(image_start_tokens), len(image_end_tokens))
|
| 120 |
+
|
| 121 |
+
image_bounds = torch.hstack(
|
| 122 |
+
[
|
| 123 |
+
image_start_tokens[:valid_image_nums].unsqueeze(-1),
|
| 124 |
+
image_end_tokens[:valid_image_nums].unsqueeze(-1),
|
| 125 |
+
]
|
| 126 |
+
)
|
| 127 |
+
return input_ids, image_bounds
|
| 128 |
+
|
| 129 |
+
def _convert_images_texts_to_inputs(
|
| 130 |
+
self,
|
| 131 |
+
images,
|
| 132 |
+
texts: Union[str, List[str]],
|
| 133 |
+
truncation=None,
|
| 134 |
+
max_length=None,
|
| 135 |
+
max_slice_nums=None,
|
| 136 |
+
use_image_id=None,
|
| 137 |
+
return_tensors=None,
|
| 138 |
+
**kwargs
|
| 139 |
+
):
|
| 140 |
+
if images is None or not len(images):
|
| 141 |
+
model_inputs = self.tokenizer(texts, return_tensors=return_tensors, truncation=truncation, max_length=max_length, **kwargs)
|
| 142 |
+
return MiniCPMVBatchFeature(data={**model_inputs})
|
| 143 |
+
|
| 144 |
+
pattern = "(<image>./</image>)"
|
| 145 |
+
images, image_sizes, tgt_sizes = images["pixel_values"], images["image_sizes"], images["tgt_sizes"]
|
| 146 |
+
|
| 147 |
+
if isinstance(texts, str):
|
| 148 |
+
texts = [texts]
|
| 149 |
+
input_ids_list = []
|
| 150 |
+
image_bounds_list = []
|
| 151 |
+
for index, text in enumerate(texts):
|
| 152 |
+
image_tags = re.findall(pattern, text)
|
| 153 |
+
assert len(image_tags) == len(image_sizes[index])
|
| 154 |
+
text_chunks = text.split(pattern)
|
| 155 |
+
final_text = ""
|
| 156 |
+
for i in range(len(image_tags)):
|
| 157 |
+
final_text = final_text + text_chunks[i] + \
|
| 158 |
+
self.image_processor.get_slice_image_placeholder(
|
| 159 |
+
image_sizes[index][i],
|
| 160 |
+
i,
|
| 161 |
+
max_slice_nums,
|
| 162 |
+
use_image_id
|
| 163 |
+
)
|
| 164 |
+
final_text += text_chunks[-1]
|
| 165 |
+
input_ids, image_bounds = self._convert(final_text, max_length)
|
| 166 |
+
input_ids_list.append(input_ids)
|
| 167 |
+
image_bounds_list.append(image_bounds)
|
| 168 |
+
padded_input_ids, padding_lengths = self.pad(
|
| 169 |
+
input_ids_list,
|
| 170 |
+
padding_side="left"
|
| 171 |
+
)
|
| 172 |
+
for i, length in enumerate(padding_lengths):
|
| 173 |
+
image_bounds_list[i] = image_bounds_list[i] + length
|
| 174 |
+
attention_mask = padded_input_ids.ne(0)
|
| 175 |
+
|
| 176 |
+
return MiniCPMVBatchFeature(data={
|
| 177 |
+
"input_ids": padded_input_ids,
|
| 178 |
+
"attention_mask": attention_mask,
|
| 179 |
+
"pixel_values": images,
|
| 180 |
+
"image_sizes": image_sizes,
|
| 181 |
+
"image_bound": image_bounds_list,
|
| 182 |
+
"tgt_sizes": tgt_sizes
|
| 183 |
+
})
|
| 184 |
+
|
| 185 |
+
@property
|
| 186 |
+
# Copied from transformers.models.clip.processing_clip.CLIPProcessor.model_input_names
|
| 187 |
+
def model_input_names(self):
|
| 188 |
+
tokenizer_input_names = self.tokenizer.model_input_names
|
| 189 |
+
image_processor_input_names = self.image_processor.model_input_names
|
| 190 |
+
return list(dict.fromkeys(tokenizer_input_names + image_processor_input_names))
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
def pad(self, inputs, max_length=None, padding_value=0, padding_side="left"):
|
| 194 |
+
items = []
|
| 195 |
+
if isinstance(inputs[0], list):
|
| 196 |
+
assert isinstance(inputs[0][0], torch.Tensor)
|
| 197 |
+
for it in inputs:
|
| 198 |
+
for tr in it:
|
| 199 |
+
items.append(tr)
|
| 200 |
+
else:
|
| 201 |
+
assert isinstance(inputs[0], torch.Tensor)
|
| 202 |
+
items = inputs
|
| 203 |
+
|
| 204 |
+
batch_size = len(items)
|
| 205 |
+
shape = items[0].shape
|
| 206 |
+
dim = len(shape)
|
| 207 |
+
assert dim <= 2
|
| 208 |
+
if max_length is None:
|
| 209 |
+
max_length = 0
|
| 210 |
+
max_length = max(max_length, max(item.shape[-1] for item in items))
|
| 211 |
+
min_length = min(item.shape[-1] for item in items)
|
| 212 |
+
dtype = items[0].dtype
|
| 213 |
+
|
| 214 |
+
if dim == 0:
|
| 215 |
+
return torch.stack([item for item in items], dim=0), [0]
|
| 216 |
+
elif dim == 1:
|
| 217 |
+
if max_length == min_length:
|
| 218 |
+
return torch.stack([item for item in items], dim=0), [0] * batch_size
|
| 219 |
+
tensor = torch.zeros((batch_size, max_length), dtype=dtype) + padding_value
|
| 220 |
+
else:
|
| 221 |
+
tensor = (
|
| 222 |
+
torch.zeros((batch_size, max_length, shape[-1]), dtype=dtype)
|
| 223 |
+
+ padding_value
|
| 224 |
+
)
|
| 225 |
+
|
| 226 |
+
padding_length = []
|
| 227 |
+
for i, item in enumerate(items):
|
| 228 |
+
if dim == 1:
|
| 229 |
+
if padding_side == "left":
|
| 230 |
+
tensor[i, -len(item) :] = item.clone()
|
| 231 |
+
else:
|
| 232 |
+
tensor[i, : len(item)] = item.clone()
|
| 233 |
+
elif dim == 2:
|
| 234 |
+
if padding_side == "left":
|
| 235 |
+
tensor[i, -len(item) :, :] = item.clone()
|
| 236 |
+
else:
|
| 237 |
+
tensor[i, : len(item), :] = item.clone()
|
| 238 |
+
padding_length.append(tensor.shape[-1] - len(item))
|
| 239 |
+
|
| 240 |
+
return tensor, padding_length
|
resampler.py
ADDED
|
@@ -0,0 +1,782 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from functools import partial
|
| 2 |
+
from typing import Optional, Tuple
|
| 3 |
+
import numpy as np
|
| 4 |
+
import warnings
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
from torch import nn
|
| 8 |
+
from torch import Tensor
|
| 9 |
+
import torch.nn.functional as F
|
| 10 |
+
from torch.nn.functional import *
|
| 11 |
+
from torch.nn.modules.activation import *
|
| 12 |
+
from torch.nn.init import trunc_normal_, constant_, xavier_normal_, xavier_uniform_
|
| 13 |
+
|
| 14 |
+
from transformers.integrations import is_deepspeed_zero3_enabled
|
| 15 |
+
|
| 16 |
+
def get_2d_sincos_pos_embed(embed_dim, image_size):
|
| 17 |
+
"""
|
| 18 |
+
image_size: image_size or (image_height, image_width)
|
| 19 |
+
return:
|
| 20 |
+
pos_embed: [image_height, image_width, embed_dim]
|
| 21 |
+
"""
|
| 22 |
+
if isinstance(image_size, int):
|
| 23 |
+
grid_h_size, grid_w_size = image_size, image_size
|
| 24 |
+
else:
|
| 25 |
+
grid_h_size, grid_w_size = image_size[0], image_size[1]
|
| 26 |
+
|
| 27 |
+
grid_h = np.arange(grid_h_size, dtype=np.float32)
|
| 28 |
+
grid_w = np.arange(grid_w_size, dtype=np.float32)
|
| 29 |
+
grid = np.meshgrid(grid_w, grid_h) # here w goes first
|
| 30 |
+
grid = np.stack(grid, axis=0)
|
| 31 |
+
|
| 32 |
+
pos_embed = get_2d_sincos_pos_embed_from_grid(embed_dim, grid)
|
| 33 |
+
return pos_embed
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def get_2d_sincos_pos_embed_from_grid(embed_dim, grid):
|
| 37 |
+
assert embed_dim % 2 == 0
|
| 38 |
+
|
| 39 |
+
# use half of dimensions to encode grid_h
|
| 40 |
+
emb_h = get_1d_sincos_pos_embed_from_grid_new(embed_dim // 2, grid[0]) # (H, W, D/2)
|
| 41 |
+
emb_w = get_1d_sincos_pos_embed_from_grid_new(embed_dim // 2, grid[1]) # (H, W, D/2)
|
| 42 |
+
|
| 43 |
+
emb = np.concatenate([emb_h, emb_w], axis=-1) # (H, W, D)
|
| 44 |
+
return emb
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def get_1d_sincos_pos_embed_from_grid_new(embed_dim, pos):
|
| 48 |
+
"""
|
| 49 |
+
embed_dim: output dimension for each position
|
| 50 |
+
pos: a list of positions to be encoded: size (H, W)
|
| 51 |
+
out: (H, W, D)
|
| 52 |
+
"""
|
| 53 |
+
assert embed_dim % 2 == 0
|
| 54 |
+
omega = np.arange(embed_dim // 2, dtype=np.float32)
|
| 55 |
+
omega /= embed_dim / 2.
|
| 56 |
+
omega = 1. / 10000 ** omega # (D/2,)
|
| 57 |
+
|
| 58 |
+
out = np.einsum('hw,d->hwd', pos, omega) # (H, W, D/2), outer product
|
| 59 |
+
|
| 60 |
+
emb_sin = np.sin(out) # (H, W, D/2)
|
| 61 |
+
emb_cos = np.cos(out) # (H, W, D/2)
|
| 62 |
+
|
| 63 |
+
emb = np.concatenate([emb_sin, emb_cos], axis=-1) # (H, W, D)
|
| 64 |
+
return emb
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
class Resampler(nn.Module):
|
| 68 |
+
"""
|
| 69 |
+
A 2D perceiver-resampler network with one cross attention layers by
|
| 70 |
+
given learnable queries and 2d sincos pos_emb
|
| 71 |
+
Outputs:
|
| 72 |
+
A tensor with the shape of (batch_size, num_queries, embed_dim)
|
| 73 |
+
"""
|
| 74 |
+
|
| 75 |
+
def __init__(
|
| 76 |
+
self,
|
| 77 |
+
num_queries,
|
| 78 |
+
embed_dim,
|
| 79 |
+
num_heads,
|
| 80 |
+
kv_dim=None,
|
| 81 |
+
norm_layer=partial(nn.LayerNorm, eps=1e-6),
|
| 82 |
+
adaptive=False,
|
| 83 |
+
max_size=(70, 70),
|
| 84 |
+
):
|
| 85 |
+
super().__init__()
|
| 86 |
+
self.num_queries = num_queries
|
| 87 |
+
self.embed_dim = embed_dim
|
| 88 |
+
self.num_heads = num_heads
|
| 89 |
+
self.adaptive = adaptive
|
| 90 |
+
self.max_size = max_size
|
| 91 |
+
|
| 92 |
+
self.query = nn.Parameter(torch.zeros(self.num_queries, embed_dim))
|
| 93 |
+
|
| 94 |
+
if kv_dim is not None and kv_dim != embed_dim:
|
| 95 |
+
self.kv_proj = nn.Linear(kv_dim, embed_dim, bias=False)
|
| 96 |
+
else:
|
| 97 |
+
self.kv_proj = nn.Identity()
|
| 98 |
+
|
| 99 |
+
self.attn = MultiheadAttention(embed_dim, num_heads)
|
| 100 |
+
self.ln_q = norm_layer(embed_dim)
|
| 101 |
+
self.ln_kv = norm_layer(embed_dim)
|
| 102 |
+
|
| 103 |
+
self.ln_post = norm_layer(embed_dim)
|
| 104 |
+
self.proj = nn.Parameter((embed_dim ** -0.5) * torch.randn(embed_dim, embed_dim))
|
| 105 |
+
|
| 106 |
+
self._set_2d_pos_cache(self.max_size)
|
| 107 |
+
|
| 108 |
+
def _set_2d_pos_cache(self, max_size, device='cpu'):
|
| 109 |
+
if is_deepspeed_zero3_enabled():
|
| 110 |
+
device='cuda'
|
| 111 |
+
pos_embed = torch.from_numpy(get_2d_sincos_pos_embed(self.embed_dim, max_size)).float().to(device)
|
| 112 |
+
self.register_buffer("pos_embed", pos_embed, persistent=False)
|
| 113 |
+
|
| 114 |
+
def _adjust_pos_cache(self, tgt_sizes, device):
|
| 115 |
+
max_h = torch.max(tgt_sizes[:, 0])
|
| 116 |
+
max_w = torch.max(tgt_sizes[:, 1])
|
| 117 |
+
if max_h > self.max_size[0] or max_w > self.max_size[1]:
|
| 118 |
+
self.max_size = [max(max_h, self.max_size[0]), max(max_w, self.max_size[1])]
|
| 119 |
+
self._set_2d_pos_cache(self.max_size, device)
|
| 120 |
+
|
| 121 |
+
def _init_weights(self, m):
|
| 122 |
+
if isinstance(m, nn.Linear):
|
| 123 |
+
trunc_normal_(m.weight, std=.02)
|
| 124 |
+
if isinstance(m, nn.Linear) and m.bias is not None:
|
| 125 |
+
nn.init.constant_(m.bias, 0)
|
| 126 |
+
elif isinstance(m, nn.LayerNorm):
|
| 127 |
+
nn.init.constant_(m.bias, 0)
|
| 128 |
+
nn.init.constant_(m.weight, 1.0)
|
| 129 |
+
|
| 130 |
+
def forward(self, x, tgt_sizes=None):
|
| 131 |
+
assert x.shape[0] == tgt_sizes.shape[0]
|
| 132 |
+
bs = x.shape[0]
|
| 133 |
+
|
| 134 |
+
device = x.device
|
| 135 |
+
dtype = x.dtype
|
| 136 |
+
|
| 137 |
+
patch_len = tgt_sizes[:, 0] * tgt_sizes[:, 1]
|
| 138 |
+
|
| 139 |
+
self._adjust_pos_cache(tgt_sizes, device=device)
|
| 140 |
+
|
| 141 |
+
max_patch_len = torch.max(patch_len)
|
| 142 |
+
key_padding_mask = torch.zeros((bs, max_patch_len), dtype=torch.bool, device=device)
|
| 143 |
+
|
| 144 |
+
pos_embed = []
|
| 145 |
+
for i in range(bs):
|
| 146 |
+
tgt_h, tgt_w = tgt_sizes[i]
|
| 147 |
+
pos_embed.append(self.pos_embed[:tgt_h, :tgt_w, :].reshape((tgt_h * tgt_w, -1)).to(dtype)) # patches * D
|
| 148 |
+
key_padding_mask[i, patch_len[i]:] = True
|
| 149 |
+
|
| 150 |
+
pos_embed = torch.nn.utils.rnn.pad_sequence(
|
| 151 |
+
pos_embed, batch_first=True, padding_value=0.0).permute(1, 0, 2) # BLD => L * B * D
|
| 152 |
+
|
| 153 |
+
x = self.kv_proj(x) # B * L * D
|
| 154 |
+
x = self.ln_kv(x).permute(1, 0, 2) # L * B * D
|
| 155 |
+
|
| 156 |
+
q = self.ln_q(self.query) # Q * D
|
| 157 |
+
|
| 158 |
+
out = self.attn(
|
| 159 |
+
self._repeat(q, bs), # Q * B * D
|
| 160 |
+
x + pos_embed, # L * B * D + L * B * D
|
| 161 |
+
x,
|
| 162 |
+
key_padding_mask=key_padding_mask)[0]
|
| 163 |
+
# out: Q * B * D
|
| 164 |
+
x = out.permute(1, 0, 2) # B * Q * D
|
| 165 |
+
|
| 166 |
+
x = self.ln_post(x)
|
| 167 |
+
x = x @ self.proj
|
| 168 |
+
return x
|
| 169 |
+
|
| 170 |
+
def _repeat(self, query, N: int):
|
| 171 |
+
return query.unsqueeze(1).repeat(1, N, 1)
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
class MultiheadAttention(nn.MultiheadAttention):
|
| 175 |
+
def __init__(self, embed_dim, num_heads, dropout=0., bias=True, add_bias_kv=False,
|
| 176 |
+
add_zero_attn=False, kdim=None, vdim=None, batch_first=False, device=None, dtype=None):
|
| 177 |
+
super().__init__(embed_dim, num_heads, dropout, bias, add_bias_kv, add_zero_attn, kdim, vdim, batch_first, device, dtype)
|
| 178 |
+
|
| 179 |
+
# rewrite out_proj layer,with nn.Linear
|
| 180 |
+
self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias, device=device, dtype=dtype)
|
| 181 |
+
|
| 182 |
+
def forward(
|
| 183 |
+
self,
|
| 184 |
+
query: Tensor,
|
| 185 |
+
key: Tensor,
|
| 186 |
+
value: Tensor,
|
| 187 |
+
key_padding_mask: Optional[Tensor] = None,
|
| 188 |
+
need_weights: bool = True,
|
| 189 |
+
attn_mask: Optional[Tensor] = None,
|
| 190 |
+
average_attn_weights: bool = True,
|
| 191 |
+
is_causal : bool = False) -> Tuple[Tensor, Optional[Tensor]]:
|
| 192 |
+
why_not_fast_path = ''
|
| 193 |
+
if ((attn_mask is not None and torch.is_floating_point(attn_mask))
|
| 194 |
+
or (key_padding_mask is not None) and torch.is_floating_point(key_padding_mask)):
|
| 195 |
+
why_not_fast_path = "floating-point masks are not supported for fast path."
|
| 196 |
+
|
| 197 |
+
is_batched = query.dim() == 3
|
| 198 |
+
|
| 199 |
+
key_padding_mask = _canonical_mask(
|
| 200 |
+
mask=key_padding_mask,
|
| 201 |
+
mask_name="key_padding_mask",
|
| 202 |
+
other_type=F._none_or_dtype(attn_mask),
|
| 203 |
+
other_name="attn_mask",
|
| 204 |
+
target_type=query.dtype
|
| 205 |
+
)
|
| 206 |
+
|
| 207 |
+
attn_mask = _canonical_mask(
|
| 208 |
+
mask=attn_mask,
|
| 209 |
+
mask_name="attn_mask",
|
| 210 |
+
other_type=None,
|
| 211 |
+
other_name="",
|
| 212 |
+
target_type=query.dtype,
|
| 213 |
+
check_other=False,
|
| 214 |
+
)
|
| 215 |
+
|
| 216 |
+
|
| 217 |
+
if not is_batched:
|
| 218 |
+
why_not_fast_path = f"input not batched; expected query.dim() of 3 but got {query.dim()}"
|
| 219 |
+
elif query is not key or key is not value:
|
| 220 |
+
# When lifting this restriction, don't forget to either
|
| 221 |
+
# enforce that the dtypes all match or test cases where
|
| 222 |
+
# they don't!
|
| 223 |
+
why_not_fast_path = "non-self attention was used (query, key, and value are not the same Tensor)"
|
| 224 |
+
elif self.in_proj_bias is not None and query.dtype != self.in_proj_bias.dtype:
|
| 225 |
+
why_not_fast_path = f"dtypes of query ({query.dtype}) and self.in_proj_bias ({self.in_proj_bias.dtype}) don't match"
|
| 226 |
+
elif self.in_proj_weight is None:
|
| 227 |
+
why_not_fast_path = "in_proj_weight was None"
|
| 228 |
+
elif query.dtype != self.in_proj_weight.dtype:
|
| 229 |
+
# this case will fail anyway, but at least they'll get a useful error message.
|
| 230 |
+
why_not_fast_path = f"dtypes of query ({query.dtype}) and self.in_proj_weight ({self.in_proj_weight.dtype}) don't match"
|
| 231 |
+
elif self.training:
|
| 232 |
+
why_not_fast_path = "training is enabled"
|
| 233 |
+
elif (self.num_heads % 2) != 0:
|
| 234 |
+
why_not_fast_path = "self.num_heads is not even"
|
| 235 |
+
elif not self.batch_first:
|
| 236 |
+
why_not_fast_path = "batch_first was not True"
|
| 237 |
+
elif self.bias_k is not None:
|
| 238 |
+
why_not_fast_path = "self.bias_k was not None"
|
| 239 |
+
elif self.bias_v is not None:
|
| 240 |
+
why_not_fast_path = "self.bias_v was not None"
|
| 241 |
+
elif self.add_zero_attn:
|
| 242 |
+
why_not_fast_path = "add_zero_attn was enabled"
|
| 243 |
+
elif not self._qkv_same_embed_dim:
|
| 244 |
+
why_not_fast_path = "_qkv_same_embed_dim was not True"
|
| 245 |
+
elif query.is_nested and (key_padding_mask is not None or attn_mask is not None):
|
| 246 |
+
why_not_fast_path = "supplying both src_key_padding_mask and src_mask at the same time \
|
| 247 |
+
is not supported with NestedTensor input"
|
| 248 |
+
elif torch.is_autocast_enabled():
|
| 249 |
+
why_not_fast_path = "autocast is enabled"
|
| 250 |
+
|
| 251 |
+
if not why_not_fast_path:
|
| 252 |
+
tensor_args = (
|
| 253 |
+
query,
|
| 254 |
+
key,
|
| 255 |
+
value,
|
| 256 |
+
self.in_proj_weight,
|
| 257 |
+
self.in_proj_bias,
|
| 258 |
+
self.out_proj.weight,
|
| 259 |
+
self.out_proj.bias,
|
| 260 |
+
)
|
| 261 |
+
# We have to use list comprehensions below because TorchScript does not support
|
| 262 |
+
# generator expressions.
|
| 263 |
+
if torch.overrides.has_torch_function(tensor_args):
|
| 264 |
+
why_not_fast_path = "some Tensor argument has_torch_function"
|
| 265 |
+
elif _is_make_fx_tracing():
|
| 266 |
+
why_not_fast_path = "we are running make_fx tracing"
|
| 267 |
+
elif not all(_check_arg_device(x) for x in tensor_args):
|
| 268 |
+
why_not_fast_path = ("some Tensor argument's device is neither one of "
|
| 269 |
+
f"cpu, cuda or {torch.utils.backend_registration._privateuse1_backend_name}")
|
| 270 |
+
elif torch.is_grad_enabled() and any(_arg_requires_grad(x) for x in tensor_args):
|
| 271 |
+
why_not_fast_path = ("grad is enabled and at least one of query or the "
|
| 272 |
+
"input/output projection weights or biases requires_grad")
|
| 273 |
+
if not why_not_fast_path:
|
| 274 |
+
merged_mask, mask_type = self.merge_masks(attn_mask, key_padding_mask, query)
|
| 275 |
+
|
| 276 |
+
if self.in_proj_bias is not None and self.in_proj_weight is not None:
|
| 277 |
+
return torch._native_multi_head_attention(
|
| 278 |
+
query,
|
| 279 |
+
key,
|
| 280 |
+
value,
|
| 281 |
+
self.embed_dim,
|
| 282 |
+
self.num_heads,
|
| 283 |
+
self.in_proj_weight,
|
| 284 |
+
self.in_proj_bias,
|
| 285 |
+
self.out_proj.weight,
|
| 286 |
+
self.out_proj.bias,
|
| 287 |
+
merged_mask,
|
| 288 |
+
need_weights,
|
| 289 |
+
average_attn_weights,
|
| 290 |
+
mask_type)
|
| 291 |
+
|
| 292 |
+
any_nested = query.is_nested or key.is_nested or value.is_nested
|
| 293 |
+
assert not any_nested, ("MultiheadAttention does not support NestedTensor outside of its fast path. " +
|
| 294 |
+
f"The fast path was not hit because {why_not_fast_path}")
|
| 295 |
+
|
| 296 |
+
if self.batch_first and is_batched:
|
| 297 |
+
# make sure that the transpose op does not affect the "is" property
|
| 298 |
+
if key is value:
|
| 299 |
+
if query is key:
|
| 300 |
+
query = key = value = query.transpose(1, 0)
|
| 301 |
+
else:
|
| 302 |
+
query, key = (x.transpose(1, 0) for x in (query, key))
|
| 303 |
+
value = key
|
| 304 |
+
else:
|
| 305 |
+
query, key, value = (x.transpose(1, 0) for x in (query, key, value))
|
| 306 |
+
|
| 307 |
+
if not self._qkv_same_embed_dim:
|
| 308 |
+
attn_output, attn_output_weights = self.multi_head_attention_forward(
|
| 309 |
+
query, key, value, self.embed_dim, self.num_heads,
|
| 310 |
+
self.in_proj_weight, self.in_proj_bias,
|
| 311 |
+
self.bias_k, self.bias_v, self.add_zero_attn,
|
| 312 |
+
self.dropout, self.out_proj.weight, self.out_proj.bias,
|
| 313 |
+
training=self.training,
|
| 314 |
+
key_padding_mask=key_padding_mask, need_weights=need_weights,
|
| 315 |
+
attn_mask=attn_mask,
|
| 316 |
+
use_separate_proj_weight=True,
|
| 317 |
+
q_proj_weight=self.q_proj_weight, k_proj_weight=self.k_proj_weight,
|
| 318 |
+
v_proj_weight=self.v_proj_weight,
|
| 319 |
+
average_attn_weights=average_attn_weights,
|
| 320 |
+
is_causal=is_causal)
|
| 321 |
+
else:
|
| 322 |
+
attn_output, attn_output_weights = self.multi_head_attention_forward(
|
| 323 |
+
query, key, value, self.embed_dim, self.num_heads,
|
| 324 |
+
self.in_proj_weight, self.in_proj_bias,
|
| 325 |
+
self.bias_k, self.bias_v, self.add_zero_attn,
|
| 326 |
+
self.dropout, self.out_proj.weight, self.out_proj.bias,
|
| 327 |
+
training=self.training,
|
| 328 |
+
key_padding_mask=key_padding_mask,
|
| 329 |
+
need_weights=need_weights,
|
| 330 |
+
attn_mask=attn_mask,
|
| 331 |
+
average_attn_weights=average_attn_weights,
|
| 332 |
+
is_causal=is_causal)
|
| 333 |
+
if self.batch_first and is_batched:
|
| 334 |
+
return attn_output.transpose(1, 0), attn_output_weights
|
| 335 |
+
else:
|
| 336 |
+
return attn_output, attn_output_weights
|
| 337 |
+
|
| 338 |
+
def multi_head_attention_forward(
|
| 339 |
+
self,
|
| 340 |
+
query: Tensor,
|
| 341 |
+
key: Tensor,
|
| 342 |
+
value: Tensor,
|
| 343 |
+
embed_dim_to_check: int,
|
| 344 |
+
num_heads: int,
|
| 345 |
+
in_proj_weight: Optional[Tensor],
|
| 346 |
+
in_proj_bias: Optional[Tensor],
|
| 347 |
+
bias_k: Optional[Tensor],
|
| 348 |
+
bias_v: Optional[Tensor],
|
| 349 |
+
add_zero_attn: bool,
|
| 350 |
+
dropout_p: float,
|
| 351 |
+
out_proj_weight: Tensor,
|
| 352 |
+
out_proj_bias: Optional[Tensor],
|
| 353 |
+
training: bool = True,
|
| 354 |
+
key_padding_mask: Optional[Tensor] = None,
|
| 355 |
+
need_weights: bool = True,
|
| 356 |
+
attn_mask: Optional[Tensor] = None,
|
| 357 |
+
use_separate_proj_weight: bool = False,
|
| 358 |
+
q_proj_weight: Optional[Tensor] = None,
|
| 359 |
+
k_proj_weight: Optional[Tensor] = None,
|
| 360 |
+
v_proj_weight: Optional[Tensor] = None,
|
| 361 |
+
static_k: Optional[Tensor] = None,
|
| 362 |
+
static_v: Optional[Tensor] = None,
|
| 363 |
+
average_attn_weights: bool = True,
|
| 364 |
+
is_causal: bool = False,
|
| 365 |
+
) -> Tuple[Tensor, Optional[Tensor]]:
|
| 366 |
+
tens_ops = (query, key, value, in_proj_weight, in_proj_bias, bias_k, bias_v, out_proj_weight, out_proj_bias)
|
| 367 |
+
|
| 368 |
+
is_batched = _mha_shape_check(query, key, value, key_padding_mask, attn_mask, num_heads)
|
| 369 |
+
|
| 370 |
+
# For unbatched input, we unsqueeze at the expected batch-dim to pretend that the input
|
| 371 |
+
# is batched, run the computation and before returning squeeze the
|
| 372 |
+
# batch dimension so that the output doesn't carry this temporary batch dimension.
|
| 373 |
+
if not is_batched:
|
| 374 |
+
# unsqueeze if the input is unbatched
|
| 375 |
+
query = query.unsqueeze(1)
|
| 376 |
+
key = key.unsqueeze(1)
|
| 377 |
+
value = value.unsqueeze(1)
|
| 378 |
+
if key_padding_mask is not None:
|
| 379 |
+
key_padding_mask = key_padding_mask.unsqueeze(0)
|
| 380 |
+
|
| 381 |
+
# set up shape vars
|
| 382 |
+
tgt_len, bsz, embed_dim = query.shape
|
| 383 |
+
src_len, _, _ = key.shape
|
| 384 |
+
|
| 385 |
+
key_padding_mask = _canonical_mask(
|
| 386 |
+
mask=key_padding_mask,
|
| 387 |
+
mask_name="key_padding_mask",
|
| 388 |
+
other_type=_none_or_dtype(attn_mask),
|
| 389 |
+
other_name="attn_mask",
|
| 390 |
+
target_type=query.dtype
|
| 391 |
+
)
|
| 392 |
+
|
| 393 |
+
if is_causal and attn_mask is None:
|
| 394 |
+
raise RuntimeError(
|
| 395 |
+
"Need attn_mask if specifying the is_causal hint. "
|
| 396 |
+
"You may use the Transformer module method "
|
| 397 |
+
"`generate_square_subsequent_mask` to create this mask."
|
| 398 |
+
)
|
| 399 |
+
|
| 400 |
+
if is_causal and key_padding_mask is None and not need_weights:
|
| 401 |
+
# when we have a kpm or need weights, we need attn_mask
|
| 402 |
+
# Otherwise, we use the is_causal hint go as is_causal
|
| 403 |
+
# indicator to SDPA.
|
| 404 |
+
attn_mask = None
|
| 405 |
+
else:
|
| 406 |
+
attn_mask = _canonical_mask(
|
| 407 |
+
mask=attn_mask,
|
| 408 |
+
mask_name="attn_mask",
|
| 409 |
+
other_type=None,
|
| 410 |
+
other_name="",
|
| 411 |
+
target_type=query.dtype,
|
| 412 |
+
check_other=False,
|
| 413 |
+
)
|
| 414 |
+
|
| 415 |
+
if key_padding_mask is not None:
|
| 416 |
+
# We have the attn_mask, and use that to merge kpm into it.
|
| 417 |
+
# Turn off use of is_causal hint, as the merged mask is no
|
| 418 |
+
# longer causal.
|
| 419 |
+
is_causal = False
|
| 420 |
+
|
| 421 |
+
assert embed_dim == embed_dim_to_check, \
|
| 422 |
+
f"was expecting embedding dimension of {embed_dim_to_check}, but got {embed_dim}"
|
| 423 |
+
if isinstance(embed_dim, torch.Tensor):
|
| 424 |
+
# embed_dim can be a tensor when JIT tracing
|
| 425 |
+
head_dim = embed_dim.div(num_heads, rounding_mode='trunc')
|
| 426 |
+
else:
|
| 427 |
+
head_dim = embed_dim // num_heads
|
| 428 |
+
assert head_dim * num_heads == embed_dim, f"embed_dim {embed_dim} not divisible by num_heads {num_heads}"
|
| 429 |
+
if use_separate_proj_weight:
|
| 430 |
+
# allow MHA to have different embedding dimensions when separate projection weights are used
|
| 431 |
+
assert key.shape[:2] == value.shape[:2], \
|
| 432 |
+
f"key's sequence and batch dims {key.shape[:2]} do not match value's {value.shape[:2]}"
|
| 433 |
+
else:
|
| 434 |
+
assert key.shape == value.shape, f"key shape {key.shape} does not match value shape {value.shape}"
|
| 435 |
+
|
| 436 |
+
#
|
| 437 |
+
# compute in-projection
|
| 438 |
+
#
|
| 439 |
+
if not use_separate_proj_weight:
|
| 440 |
+
assert in_proj_weight is not None, "use_separate_proj_weight is False but in_proj_weight is None"
|
| 441 |
+
q, k, v = _in_projection_packed(query, key, value, in_proj_weight, in_proj_bias)
|
| 442 |
+
else:
|
| 443 |
+
assert q_proj_weight is not None, "use_separate_proj_weight is True but q_proj_weight is None"
|
| 444 |
+
assert k_proj_weight is not None, "use_separate_proj_weight is True but k_proj_weight is None"
|
| 445 |
+
assert v_proj_weight is not None, "use_separate_proj_weight is True but v_proj_weight is None"
|
| 446 |
+
if in_proj_bias is None:
|
| 447 |
+
b_q = b_k = b_v = None
|
| 448 |
+
else:
|
| 449 |
+
b_q, b_k, b_v = in_proj_bias.chunk(3)
|
| 450 |
+
q, k, v = _in_projection(query, key, value, q_proj_weight, k_proj_weight, v_proj_weight, b_q, b_k, b_v)
|
| 451 |
+
|
| 452 |
+
# prep attention mask
|
| 453 |
+
|
| 454 |
+
if attn_mask is not None:
|
| 455 |
+
# ensure attn_mask's dim is 3
|
| 456 |
+
if attn_mask.dim() == 2:
|
| 457 |
+
correct_2d_size = (tgt_len, src_len)
|
| 458 |
+
if attn_mask.shape != correct_2d_size:
|
| 459 |
+
raise RuntimeError(f"The shape of the 2D attn_mask is {attn_mask.shape}, but should be {correct_2d_size}.")
|
| 460 |
+
attn_mask = attn_mask.unsqueeze(0)
|
| 461 |
+
elif attn_mask.dim() == 3:
|
| 462 |
+
correct_3d_size = (bsz * num_heads, tgt_len, src_len)
|
| 463 |
+
if attn_mask.shape != correct_3d_size:
|
| 464 |
+
raise RuntimeError(f"The shape of the 3D attn_mask is {attn_mask.shape}, but should be {correct_3d_size}.")
|
| 465 |
+
else:
|
| 466 |
+
raise RuntimeError(f"attn_mask's dimension {attn_mask.dim()} is not supported")
|
| 467 |
+
|
| 468 |
+
# add bias along batch dimension (currently second)
|
| 469 |
+
if bias_k is not None and bias_v is not None:
|
| 470 |
+
assert static_k is None, "bias cannot be added to static key."
|
| 471 |
+
assert static_v is None, "bias cannot be added to static value."
|
| 472 |
+
k = torch.cat([k, bias_k.repeat(1, bsz, 1)])
|
| 473 |
+
v = torch.cat([v, bias_v.repeat(1, bsz, 1)])
|
| 474 |
+
if attn_mask is not None:
|
| 475 |
+
attn_mask = pad(attn_mask, (0, 1))
|
| 476 |
+
if key_padding_mask is not None:
|
| 477 |
+
key_padding_mask = pad(key_padding_mask, (0, 1))
|
| 478 |
+
else:
|
| 479 |
+
assert bias_k is None
|
| 480 |
+
assert bias_v is None
|
| 481 |
+
|
| 482 |
+
#
|
| 483 |
+
# reshape q, k, v for multihead attention and make em batch first
|
| 484 |
+
#
|
| 485 |
+
q = q.view(tgt_len, bsz * num_heads, head_dim).transpose(0, 1)
|
| 486 |
+
if static_k is None:
|
| 487 |
+
k = k.view(k.shape[0], bsz * num_heads, head_dim).transpose(0, 1)
|
| 488 |
+
else:
|
| 489 |
+
# TODO finish disentangling control flow so we don't do in-projections when statics are passed
|
| 490 |
+
assert static_k.size(0) == bsz * num_heads, \
|
| 491 |
+
f"expecting static_k.size(0) of {bsz * num_heads}, but got {static_k.size(0)}"
|
| 492 |
+
assert static_k.size(2) == head_dim, \
|
| 493 |
+
f"expecting static_k.size(2) of {head_dim}, but got {static_k.size(2)}"
|
| 494 |
+
k = static_k
|
| 495 |
+
if static_v is None:
|
| 496 |
+
v = v.view(v.shape[0], bsz * num_heads, head_dim).transpose(0, 1)
|
| 497 |
+
else:
|
| 498 |
+
# TODO finish disentangling control flow so we don't do in-projections when statics are passed
|
| 499 |
+
assert static_v.size(0) == bsz * num_heads, \
|
| 500 |
+
f"expecting static_v.size(0) of {bsz * num_heads}, but got {static_v.size(0)}"
|
| 501 |
+
assert static_v.size(2) == head_dim, \
|
| 502 |
+
f"expecting static_v.size(2) of {head_dim}, but got {static_v.size(2)}"
|
| 503 |
+
v = static_v
|
| 504 |
+
|
| 505 |
+
# add zero attention along batch dimension (now first)
|
| 506 |
+
if add_zero_attn:
|
| 507 |
+
zero_attn_shape = (bsz * num_heads, 1, head_dim)
|
| 508 |
+
k = torch.cat([k, torch.zeros(zero_attn_shape, dtype=k.dtype, device=k.device)], dim=1)
|
| 509 |
+
v = torch.cat([v, torch.zeros(zero_attn_shape, dtype=v.dtype, device=v.device)], dim=1)
|
| 510 |
+
if attn_mask is not None:
|
| 511 |
+
attn_mask = pad(attn_mask, (0, 1))
|
| 512 |
+
if key_padding_mask is not None:
|
| 513 |
+
key_padding_mask = pad(key_padding_mask, (0, 1))
|
| 514 |
+
|
| 515 |
+
# update source sequence length after adjustments
|
| 516 |
+
src_len = k.size(1)
|
| 517 |
+
|
| 518 |
+
# merge key padding and attention masks
|
| 519 |
+
if key_padding_mask is not None:
|
| 520 |
+
assert key_padding_mask.shape == (bsz, src_len), \
|
| 521 |
+
f"expecting key_padding_mask shape of {(bsz, src_len)}, but got {key_padding_mask.shape}"
|
| 522 |
+
key_padding_mask = key_padding_mask.view(bsz, 1, 1, src_len). \
|
| 523 |
+
expand(-1, num_heads, -1, -1).reshape(bsz * num_heads, 1, src_len)
|
| 524 |
+
if attn_mask is None:
|
| 525 |
+
attn_mask = key_padding_mask
|
| 526 |
+
else:
|
| 527 |
+
attn_mask = attn_mask + key_padding_mask
|
| 528 |
+
|
| 529 |
+
# adjust dropout probability
|
| 530 |
+
if not training:
|
| 531 |
+
dropout_p = 0.0
|
| 532 |
+
|
| 533 |
+
#
|
| 534 |
+
# (deep breath) calculate attention and out projection
|
| 535 |
+
#
|
| 536 |
+
|
| 537 |
+
if need_weights:
|
| 538 |
+
B, Nt, E = q.shape
|
| 539 |
+
q_scaled = q / math.sqrt(E)
|
| 540 |
+
|
| 541 |
+
assert not (is_causal and attn_mask is None), "FIXME: is_causal not implemented for need_weights"
|
| 542 |
+
|
| 543 |
+
if attn_mask is not None:
|
| 544 |
+
attn_output_weights = torch.baddbmm(attn_mask, q_scaled, k.transpose(-2, -1))
|
| 545 |
+
else:
|
| 546 |
+
attn_output_weights = torch.bmm(q_scaled, k.transpose(-2, -1))
|
| 547 |
+
attn_output_weights = softmax(attn_output_weights, dim=-1)
|
| 548 |
+
if dropout_p > 0.0:
|
| 549 |
+
attn_output_weights = dropout(attn_output_weights, p=dropout_p)
|
| 550 |
+
|
| 551 |
+
attn_output = torch.bmm(attn_output_weights, v)
|
| 552 |
+
|
| 553 |
+
attn_output = attn_output.transpose(0, 1).contiguous().view(tgt_len * bsz, embed_dim)
|
| 554 |
+
attn_output = self.out_proj(attn_output)
|
| 555 |
+
attn_output = attn_output.view(tgt_len, bsz, attn_output.size(1))
|
| 556 |
+
|
| 557 |
+
# optionally average attention weights over heads
|
| 558 |
+
attn_output_weights = attn_output_weights.view(bsz, num_heads, tgt_len, src_len)
|
| 559 |
+
if average_attn_weights:
|
| 560 |
+
attn_output_weights = attn_output_weights.mean(dim=1)
|
| 561 |
+
|
| 562 |
+
if not is_batched:
|
| 563 |
+
# squeeze the output if input was unbatched
|
| 564 |
+
attn_output = attn_output.squeeze(1)
|
| 565 |
+
attn_output_weights = attn_output_weights.squeeze(0)
|
| 566 |
+
return attn_output, attn_output_weights
|
| 567 |
+
else:
|
| 568 |
+
# attn_mask can be either (L,S) or (N*num_heads, L, S)
|
| 569 |
+
# if attn_mask's shape is (1, L, S) we need to unsqueeze to (1, 1, L, S)
|
| 570 |
+
# in order to match the input for SDPA of (N, num_heads, L, S)
|
| 571 |
+
if attn_mask is not None:
|
| 572 |
+
if attn_mask.size(0) == 1 and attn_mask.dim() == 3:
|
| 573 |
+
attn_mask = attn_mask.unsqueeze(0)
|
| 574 |
+
else:
|
| 575 |
+
attn_mask = attn_mask.view(bsz, num_heads, -1, src_len)
|
| 576 |
+
|
| 577 |
+
q = q.view(bsz, num_heads, tgt_len, head_dim)
|
| 578 |
+
k = k.view(bsz, num_heads, src_len, head_dim)
|
| 579 |
+
v = v.view(bsz, num_heads, src_len, head_dim)
|
| 580 |
+
|
| 581 |
+
attn_output = F.scaled_dot_product_attention(q, k, v, attn_mask, dropout_p, is_causal)
|
| 582 |
+
attn_output = attn_output.permute(2, 0, 1, 3).contiguous().view(bsz * tgt_len, embed_dim)
|
| 583 |
+
|
| 584 |
+
attn_output = self.out_proj(attn_output)
|
| 585 |
+
attn_output = attn_output.view(tgt_len, bsz, attn_output.size(1))
|
| 586 |
+
if not is_batched:
|
| 587 |
+
# squeeze the output if input was unbatched
|
| 588 |
+
attn_output = attn_output.squeeze(1)
|
| 589 |
+
return attn_output, None
|
| 590 |
+
|
| 591 |
+
|
| 592 |
+
def _mha_shape_check(query: Tensor, key: Tensor, value: Tensor,
|
| 593 |
+
key_padding_mask: Optional[Tensor], attn_mask: Optional[Tensor], num_heads: int):
|
| 594 |
+
# Verifies the expected shape for `query, `key`, `value`, `key_padding_mask` and `attn_mask`
|
| 595 |
+
# and returns if the input is batched or not.
|
| 596 |
+
# Raises an error if `query` is not 2-D (unbatched) or 3-D (batched) tensor.
|
| 597 |
+
|
| 598 |
+
# Shape check.
|
| 599 |
+
if query.dim() == 3:
|
| 600 |
+
# Batched Inputs
|
| 601 |
+
is_batched = True
|
| 602 |
+
assert key.dim() == 3 and value.dim() == 3, \
|
| 603 |
+
("For batched (3-D) `query`, expected `key` and `value` to be 3-D"
|
| 604 |
+
f" but found {key.dim()}-D and {value.dim()}-D tensors respectively")
|
| 605 |
+
if key_padding_mask is not None:
|
| 606 |
+
assert key_padding_mask.dim() == 2, \
|
| 607 |
+
("For batched (3-D) `query`, expected `key_padding_mask` to be `None` or 2-D"
|
| 608 |
+
f" but found {key_padding_mask.dim()}-D tensor instead")
|
| 609 |
+
if attn_mask is not None:
|
| 610 |
+
assert attn_mask.dim() in (2, 3), \
|
| 611 |
+
("For batched (3-D) `query`, expected `attn_mask` to be `None`, 2-D or 3-D"
|
| 612 |
+
f" but found {attn_mask.dim()}-D tensor instead")
|
| 613 |
+
elif query.dim() == 2:
|
| 614 |
+
# Unbatched Inputs
|
| 615 |
+
is_batched = False
|
| 616 |
+
assert key.dim() == 2 and value.dim() == 2, \
|
| 617 |
+
("For unbatched (2-D) `query`, expected `key` and `value` to be 2-D"
|
| 618 |
+
f" but found {key.dim()}-D and {value.dim()}-D tensors respectively")
|
| 619 |
+
|
| 620 |
+
if key_padding_mask is not None:
|
| 621 |
+
assert key_padding_mask.dim() == 1, \
|
| 622 |
+
("For unbatched (2-D) `query`, expected `key_padding_mask` to be `None` or 1-D"
|
| 623 |
+
f" but found {key_padding_mask.dim()}-D tensor instead")
|
| 624 |
+
|
| 625 |
+
if attn_mask is not None:
|
| 626 |
+
assert attn_mask.dim() in (2, 3), \
|
| 627 |
+
("For unbatched (2-D) `query`, expected `attn_mask` to be `None`, 2-D or 3-D"
|
| 628 |
+
f" but found {attn_mask.dim()}-D tensor instead")
|
| 629 |
+
if attn_mask.dim() == 3:
|
| 630 |
+
expected_shape = (num_heads, query.shape[0], key.shape[0])
|
| 631 |
+
assert attn_mask.shape == expected_shape, \
|
| 632 |
+
(f"Expected `attn_mask` shape to be {expected_shape} but got {attn_mask.shape}")
|
| 633 |
+
else:
|
| 634 |
+
raise AssertionError(
|
| 635 |
+
f"query should be unbatched 2D or batched 3D tensor but received {query.dim()}-D query tensor")
|
| 636 |
+
|
| 637 |
+
return is_batched
|
| 638 |
+
|
| 639 |
+
|
| 640 |
+
def _canonical_mask(
|
| 641 |
+
mask: Optional[Tensor],
|
| 642 |
+
mask_name: str,
|
| 643 |
+
other_type: Optional[DType],
|
| 644 |
+
other_name: str,
|
| 645 |
+
target_type: DType,
|
| 646 |
+
check_other: bool = True,
|
| 647 |
+
) -> Optional[Tensor]:
|
| 648 |
+
|
| 649 |
+
if mask is not None:
|
| 650 |
+
_mask_dtype = mask.dtype
|
| 651 |
+
_mask_is_float = torch.is_floating_point(mask)
|
| 652 |
+
if _mask_dtype != torch.bool and not _mask_is_float:
|
| 653 |
+
raise AssertionError(
|
| 654 |
+
f"only bool and floating types of {mask_name} are supported")
|
| 655 |
+
if check_other and other_type is not None:
|
| 656 |
+
if _mask_dtype != other_type:
|
| 657 |
+
warnings.warn(
|
| 658 |
+
f"Support for mismatched {mask_name} and {other_name} "
|
| 659 |
+
"is deprecated. Use same type for both instead."
|
| 660 |
+
)
|
| 661 |
+
if not _mask_is_float:
|
| 662 |
+
mask = (
|
| 663 |
+
torch.zeros_like(mask, dtype=target_type)
|
| 664 |
+
.masked_fill_(mask, float("-inf"))
|
| 665 |
+
)
|
| 666 |
+
return mask
|
| 667 |
+
|
| 668 |
+
|
| 669 |
+
def _none_or_dtype(input: Optional[Tensor]) -> Optional[DType]:
|
| 670 |
+
if input is None:
|
| 671 |
+
return None
|
| 672 |
+
elif isinstance(input, torch.Tensor):
|
| 673 |
+
return input.dtype
|
| 674 |
+
raise RuntimeError("input to _none_or_dtype() must be None or torch.Tensor")
|
| 675 |
+
|
| 676 |
+
def _in_projection_packed(
|
| 677 |
+
q: Tensor,
|
| 678 |
+
k: Tensor,
|
| 679 |
+
v: Tensor,
|
| 680 |
+
w: Tensor,
|
| 681 |
+
b: Optional[Tensor] = None,
|
| 682 |
+
) -> List[Tensor]:
|
| 683 |
+
r"""
|
| 684 |
+
Performs the in-projection step of the attention operation, using packed weights.
|
| 685 |
+
Output is a triple containing projection tensors for query, key and value.
|
| 686 |
+
Args:
|
| 687 |
+
q, k, v: query, key and value tensors to be projected. For self-attention,
|
| 688 |
+
these are typically the same tensor; for encoder-decoder attention,
|
| 689 |
+
k and v are typically the same tensor. (We take advantage of these
|
| 690 |
+
identities for performance if they are present.) Regardless, q, k and v
|
| 691 |
+
must share a common embedding dimension; otherwise their shapes may vary.
|
| 692 |
+
w: projection weights for q, k and v, packed into a single tensor. Weights
|
| 693 |
+
are packed along dimension 0, in q, k, v order.
|
| 694 |
+
b: optional projection biases for q, k and v, packed into a single tensor
|
| 695 |
+
in q, k, v order.
|
| 696 |
+
Shape:
|
| 697 |
+
Inputs:
|
| 698 |
+
- q: :math:`(..., E)` where E is the embedding dimension
|
| 699 |
+
- k: :math:`(..., E)` where E is the embedding dimension
|
| 700 |
+
- v: :math:`(..., E)` where E is the embedding dimension
|
| 701 |
+
- w: :math:`(E * 3, E)` where E is the embedding dimension
|
| 702 |
+
- b: :math:`E * 3` where E is the embedding dimension
|
| 703 |
+
Output:
|
| 704 |
+
- in output list :math:`[q', k', v']`, each output tensor will have the
|
| 705 |
+
same shape as the corresponding input tensor.
|
| 706 |
+
"""
|
| 707 |
+
E = q.size(-1)
|
| 708 |
+
if k is v:
|
| 709 |
+
if q is k:
|
| 710 |
+
# self-attention
|
| 711 |
+
proj = linear(q, w, b)
|
| 712 |
+
# reshape to 3, E and not E, 3 is deliberate for better memory coalescing and keeping same order as chunk()
|
| 713 |
+
proj = proj.unflatten(-1, (3, E)).unsqueeze(0).transpose(0, -2).squeeze(-2).contiguous()
|
| 714 |
+
return proj[0], proj[1], proj[2]
|
| 715 |
+
else:
|
| 716 |
+
# encoder-decoder attention
|
| 717 |
+
w_q, w_kv = w.split([E, E * 2])
|
| 718 |
+
if b is None:
|
| 719 |
+
b_q = b_kv = None
|
| 720 |
+
else:
|
| 721 |
+
b_q, b_kv = b.split([E, E * 2])
|
| 722 |
+
q_proj = linear(q, w_q, b_q)
|
| 723 |
+
kv_proj = linear(k, w_kv, b_kv)
|
| 724 |
+
# reshape to 2, E and not E, 2 is deliberate for better memory coalescing and keeping same order as chunk()
|
| 725 |
+
kv_proj = kv_proj.unflatten(-1, (2, E)).unsqueeze(0).transpose(0, -2).squeeze(-2).contiguous()
|
| 726 |
+
return (q_proj, kv_proj[0], kv_proj[1])
|
| 727 |
+
else:
|
| 728 |
+
w_q, w_k, w_v = w.chunk(3)
|
| 729 |
+
if b is None:
|
| 730 |
+
b_q = b_k = b_v = None
|
| 731 |
+
else:
|
| 732 |
+
b_q, b_k, b_v = b.chunk(3)
|
| 733 |
+
return linear(q, w_q, b_q), linear(k, w_k, b_k), linear(v, w_v, b_v)
|
| 734 |
+
|
| 735 |
+
|
| 736 |
+
def _in_projection(
|
| 737 |
+
q: Tensor,
|
| 738 |
+
k: Tensor,
|
| 739 |
+
v: Tensor,
|
| 740 |
+
w_q: Tensor,
|
| 741 |
+
w_k: Tensor,
|
| 742 |
+
w_v: Tensor,
|
| 743 |
+
b_q: Optional[Tensor] = None,
|
| 744 |
+
b_k: Optional[Tensor] = None,
|
| 745 |
+
b_v: Optional[Tensor] = None,
|
| 746 |
+
) -> Tuple[Tensor, Tensor, Tensor]:
|
| 747 |
+
r"""
|
| 748 |
+
Performs the in-projection step of the attention operation. This is simply
|
| 749 |
+
a triple of linear projections, with shape constraints on the weights which
|
| 750 |
+
ensure embedding dimension uniformity in the projected outputs.
|
| 751 |
+
Output is a triple containing projection tensors for query, key and value.
|
| 752 |
+
Args:
|
| 753 |
+
q, k, v: query, key and value tensors to be projected.
|
| 754 |
+
w_q, w_k, w_v: weights for q, k and v, respectively.
|
| 755 |
+
b_q, b_k, b_v: optional biases for q, k and v, respectively.
|
| 756 |
+
Shape:
|
| 757 |
+
Inputs:
|
| 758 |
+
- q: :math:`(Qdims..., Eq)` where Eq is the query embedding dimension and Qdims are any
|
| 759 |
+
number of leading dimensions.
|
| 760 |
+
- k: :math:`(Kdims..., Ek)` where Ek is the key embedding dimension and Kdims are any
|
| 761 |
+
number of leading dimensions.
|
| 762 |
+
- v: :math:`(Vdims..., Ev)` where Ev is the value embedding dimension and Vdims are any
|
| 763 |
+
number of leading dimensions.
|
| 764 |
+
- w_q: :math:`(Eq, Eq)`
|
| 765 |
+
- w_k: :math:`(Eq, Ek)`
|
| 766 |
+
- w_v: :math:`(Eq, Ev)`
|
| 767 |
+
- b_q: :math:`(Eq)`
|
| 768 |
+
- b_k: :math:`(Eq)`
|
| 769 |
+
- b_v: :math:`(Eq)`
|
| 770 |
+
Output: in output triple :math:`(q', k', v')`,
|
| 771 |
+
- q': :math:`[Qdims..., Eq]`
|
| 772 |
+
- k': :math:`[Kdims..., Eq]`
|
| 773 |
+
- v': :math:`[Vdims..., Eq]`
|
| 774 |
+
"""
|
| 775 |
+
Eq, Ek, Ev = q.size(-1), k.size(-1), v.size(-1)
|
| 776 |
+
assert w_q.shape == (Eq, Eq), f"expecting query weights shape of {(Eq, Eq)}, but got {w_q.shape}"
|
| 777 |
+
assert w_k.shape == (Eq, Ek), f"expecting key weights shape of {(Eq, Ek)}, but got {w_k.shape}"
|
| 778 |
+
assert w_v.shape == (Eq, Ev), f"expecting value weights shape of {(Eq, Ev)}, but got {w_v.shape}"
|
| 779 |
+
assert b_q is None or b_q.shape == (Eq,), f"expecting query bias shape of {(Eq,)}, but got {b_q.shape}"
|
| 780 |
+
assert b_k is None or b_k.shape == (Eq,), f"expecting key bias shape of {(Eq,)}, but got {b_k.shape}"
|
| 781 |
+
assert b_v is None or b_v.shape == (Eq,), f"expecting value bias shape of {(Eq,)}, but got {b_v.shape}"
|
| 782 |
+
return linear(q, w_q, b_q), linear(k, w_k, b_k), linear(v, w_v, b_v)
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<image>",
|
| 4 |
+
"</image>",
|
| 5 |
+
"<ref>",
|
| 6 |
+
"</ref>",
|
| 7 |
+
"<box>",
|
| 8 |
+
"</box>",
|
| 9 |
+
"<quad>",
|
| 10 |
+
"</quad>",
|
| 11 |
+
"<point>",
|
| 12 |
+
"</point>",
|
| 13 |
+
"<slice>",
|
| 14 |
+
"</slice>",
|
| 15 |
+
"<image_id>",
|
| 16 |
+
"</image_id>",
|
| 17 |
+
"<|reserved_special_token_0|>",
|
| 18 |
+
"<|reserved_special_token_1|>",
|
| 19 |
+
"<|reserved_special_token_2|>",
|
| 20 |
+
"<|reserved_special_token_3|>",
|
| 21 |
+
"<|reserved_special_token_4|>",
|
| 22 |
+
"<|reserved_special_token_5|>"
|
| 23 |
+
],
|
| 24 |
+
"bos_token": {
|
| 25 |
+
"content": "<|im_start|>",
|
| 26 |
+
"lstrip": false,
|
| 27 |
+
"normalized": false,
|
| 28 |
+
"rstrip": false,
|
| 29 |
+
"single_word": false
|
| 30 |
+
},
|
| 31 |
+
"eos_token": {
|
| 32 |
+
"content": "<|im_end|>",
|
| 33 |
+
"lstrip": false,
|
| 34 |
+
"normalized": false,
|
| 35 |
+
"rstrip": false,
|
| 36 |
+
"single_word": false
|
| 37 |
+
},
|
| 38 |
+
"pad_token": {
|
| 39 |
+
"content": "<|endoftext|>",
|
| 40 |
+
"lstrip": false,
|
| 41 |
+
"normalized": false,
|
| 42 |
+
"rstrip": false,
|
| 43 |
+
"single_word": false
|
| 44 |
+
},
|
| 45 |
+
"unk_token": {
|
| 46 |
+
"content": "<unk>",
|
| 47 |
+
"lstrip": false,
|
| 48 |
+
"normalized": false,
|
| 49 |
+
"rstrip": false,
|
| 50 |
+
"single_word": false
|
| 51 |
+
}
|
| 52 |
+
}
|
tokenization_minicpmv_fast.py
ADDED
|
@@ -0,0 +1,66 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from transformers.models.qwen2 import Qwen2TokenizerFast
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
class MiniCPMVTokenizerFast(Qwen2TokenizerFast):
|
| 5 |
+
def __init__(self, **kwargs):
|
| 6 |
+
super().__init__(**kwargs)
|
| 7 |
+
self.im_start = "<image>"
|
| 8 |
+
self.im_end = "</image>"
|
| 9 |
+
self.ref_start = "<ref>"
|
| 10 |
+
self.ref_end = "</ref>"
|
| 11 |
+
self.box_start = "<box>"
|
| 12 |
+
self.box_end = "</box>"
|
| 13 |
+
self.quad_start = "<quad>"
|
| 14 |
+
self.quad_end = "</quad>"
|
| 15 |
+
self.slice_start = "<slice>"
|
| 16 |
+
self.slice_end = "</slice>"
|
| 17 |
+
self.im_id_start = "<image_id>"
|
| 18 |
+
self.im_id_end = "</image_id>"
|
| 19 |
+
|
| 20 |
+
@property
|
| 21 |
+
def eos_id(self):
|
| 22 |
+
return self.eos_token_id
|
| 23 |
+
|
| 24 |
+
@property
|
| 25 |
+
def bos_id(self):
|
| 26 |
+
return self.bos_token_id
|
| 27 |
+
|
| 28 |
+
@property
|
| 29 |
+
def unk_id(self):
|
| 30 |
+
return self.unk_token_id
|
| 31 |
+
|
| 32 |
+
@property
|
| 33 |
+
def im_start_id(self):
|
| 34 |
+
return self.convert_tokens_to_ids(self.im_start)
|
| 35 |
+
|
| 36 |
+
@property
|
| 37 |
+
def im_end_id(self):
|
| 38 |
+
return self.convert_tokens_to_ids(self.im_end)
|
| 39 |
+
|
| 40 |
+
@property
|
| 41 |
+
def slice_start_id(self):
|
| 42 |
+
return self.convert_tokens_to_ids(self.slice_start)
|
| 43 |
+
|
| 44 |
+
@property
|
| 45 |
+
def slice_end_id(self):
|
| 46 |
+
return self.convert_tokens_to_ids(self.slice_end)
|
| 47 |
+
|
| 48 |
+
@property
|
| 49 |
+
def im_id_start_id(self):
|
| 50 |
+
return self.convert_tokens_to_ids(self.im_id_start)
|
| 51 |
+
|
| 52 |
+
@property
|
| 53 |
+
def im_id_end_id(self):
|
| 54 |
+
return self.convert_tokens_to_ids(self.im_id_end)
|
| 55 |
+
|
| 56 |
+
@property
|
| 57 |
+
def newline_id(self):
|
| 58 |
+
return self.convert_tokens_to_ids('\n')
|
| 59 |
+
|
| 60 |
+
@staticmethod
|
| 61 |
+
def escape(text: str) -> str:
|
| 62 |
+
return text
|
| 63 |
+
|
| 64 |
+
@staticmethod
|
| 65 |
+
def unescape(text: str) -> str:
|
| 66 |
+
return text
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9de76ce95f90e336b4d2b0ec11d37f3d5404f2dad0f7ac95298405474b2a3a90
|
| 3 |
+
size 11422257
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,235 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"added_tokens_decoder": {
|
| 4 |
+
"128244": {
|
| 5 |
+
"content": "<unk>",
|
| 6 |
+
"lstrip": false,
|
| 7 |
+
"normalized": false,
|
| 8 |
+
"rstrip": false,
|
| 9 |
+
"single_word": false,
|
| 10 |
+
"special": true
|
| 11 |
+
},
|
| 12 |
+
"151643": {
|
| 13 |
+
"content": "<|endoftext|>",
|
| 14 |
+
"lstrip": false,
|
| 15 |
+
"normalized": false,
|
| 16 |
+
"rstrip": false,
|
| 17 |
+
"single_word": false,
|
| 18 |
+
"special": true
|
| 19 |
+
},
|
| 20 |
+
"151644": {
|
| 21 |
+
"content": "<|im_start|>",
|
| 22 |
+
"lstrip": false,
|
| 23 |
+
"normalized": false,
|
| 24 |
+
"rstrip": false,
|
| 25 |
+
"single_word": false,
|
| 26 |
+
"special": true
|
| 27 |
+
},
|
| 28 |
+
"151645": {
|
| 29 |
+
"content": "<|im_end|>",
|
| 30 |
+
"lstrip": false,
|
| 31 |
+
"normalized": false,
|
| 32 |
+
"rstrip": false,
|
| 33 |
+
"single_word": false,
|
| 34 |
+
"special": true
|
| 35 |
+
},
|
| 36 |
+
"151646": {
|
| 37 |
+
"content": "<image>",
|
| 38 |
+
"lstrip": false,
|
| 39 |
+
"normalized": false,
|
| 40 |
+
"rstrip": false,
|
| 41 |
+
"single_word": false,
|
| 42 |
+
"special": true
|
| 43 |
+
},
|
| 44 |
+
"151647": {
|
| 45 |
+
"content": "</image>",
|
| 46 |
+
"lstrip": false,
|
| 47 |
+
"normalized": false,
|
| 48 |
+
"rstrip": false,
|
| 49 |
+
"single_word": false,
|
| 50 |
+
"special": true
|
| 51 |
+
},
|
| 52 |
+
"151648": {
|
| 53 |
+
"content": "<ref>",
|
| 54 |
+
"lstrip": false,
|
| 55 |
+
"normalized": false,
|
| 56 |
+
"rstrip": false,
|
| 57 |
+
"single_word": false,
|
| 58 |
+
"special": true
|
| 59 |
+
},
|
| 60 |
+
"151649": {
|
| 61 |
+
"content": "</ref>",
|
| 62 |
+
"lstrip": false,
|
| 63 |
+
"normalized": false,
|
| 64 |
+
"rstrip": false,
|
| 65 |
+
"single_word": false,
|
| 66 |
+
"special": true
|
| 67 |
+
},
|
| 68 |
+
"151650": {
|
| 69 |
+
"content": "<box>",
|
| 70 |
+
"lstrip": false,
|
| 71 |
+
"normalized": false,
|
| 72 |
+
"rstrip": false,
|
| 73 |
+
"single_word": false,
|
| 74 |
+
"special": true
|
| 75 |
+
},
|
| 76 |
+
"151651": {
|
| 77 |
+
"content": "</box>",
|
| 78 |
+
"lstrip": false,
|
| 79 |
+
"normalized": false,
|
| 80 |
+
"rstrip": false,
|
| 81 |
+
"single_word": false,
|
| 82 |
+
"special": true
|
| 83 |
+
},
|
| 84 |
+
"151652": {
|
| 85 |
+
"content": "<quad>",
|
| 86 |
+
"lstrip": false,
|
| 87 |
+
"normalized": false,
|
| 88 |
+
"rstrip": false,
|
| 89 |
+
"single_word": false,
|
| 90 |
+
"special": true
|
| 91 |
+
},
|
| 92 |
+
"151653": {
|
| 93 |
+
"content": "</quad>",
|
| 94 |
+
"lstrip": false,
|
| 95 |
+
"normalized": false,
|
| 96 |
+
"rstrip": false,
|
| 97 |
+
"single_word": false,
|
| 98 |
+
"special": true
|
| 99 |
+
},
|
| 100 |
+
"151654": {
|
| 101 |
+
"content": "<point>",
|
| 102 |
+
"lstrip": false,
|
| 103 |
+
"normalized": false,
|
| 104 |
+
"rstrip": false,
|
| 105 |
+
"single_word": false,
|
| 106 |
+
"special": true
|
| 107 |
+
},
|
| 108 |
+
"151655": {
|
| 109 |
+
"content": "</point>",
|
| 110 |
+
"lstrip": false,
|
| 111 |
+
"normalized": false,
|
| 112 |
+
"rstrip": false,
|
| 113 |
+
"single_word": false,
|
| 114 |
+
"special": true
|
| 115 |
+
},
|
| 116 |
+
"151656": {
|
| 117 |
+
"content": "<slice>",
|
| 118 |
+
"lstrip": false,
|
| 119 |
+
"normalized": false,
|
| 120 |
+
"rstrip": false,
|
| 121 |
+
"single_word": false,
|
| 122 |
+
"special": true
|
| 123 |
+
},
|
| 124 |
+
"151657": {
|
| 125 |
+
"content": "</slice>",
|
| 126 |
+
"lstrip": false,
|
| 127 |
+
"normalized": false,
|
| 128 |
+
"rstrip": false,
|
| 129 |
+
"single_word": false,
|
| 130 |
+
"special": true
|
| 131 |
+
},
|
| 132 |
+
"151658": {
|
| 133 |
+
"content": "<image_id>",
|
| 134 |
+
"lstrip": false,
|
| 135 |
+
"normalized": false,
|
| 136 |
+
"rstrip": false,
|
| 137 |
+
"single_word": false,
|
| 138 |
+
"special": true
|
| 139 |
+
},
|
| 140 |
+
"151659": {
|
| 141 |
+
"content": "</image_id>",
|
| 142 |
+
"lstrip": false,
|
| 143 |
+
"normalized": false,
|
| 144 |
+
"rstrip": false,
|
| 145 |
+
"single_word": false,
|
| 146 |
+
"special": true
|
| 147 |
+
},
|
| 148 |
+
"151660": {
|
| 149 |
+
"content": "<|reserved_special_token_0|>",
|
| 150 |
+
"lstrip": false,
|
| 151 |
+
"normalized": false,
|
| 152 |
+
"rstrip": false,
|
| 153 |
+
"single_word": false,
|
| 154 |
+
"special": true
|
| 155 |
+
},
|
| 156 |
+
"151661": {
|
| 157 |
+
"content": "<|reserved_special_token_1|>",
|
| 158 |
+
"lstrip": false,
|
| 159 |
+
"normalized": false,
|
| 160 |
+
"rstrip": false,
|
| 161 |
+
"single_word": false,
|
| 162 |
+
"special": true
|
| 163 |
+
},
|
| 164 |
+
"151662": {
|
| 165 |
+
"content": "<|reserved_special_token_2|>",
|
| 166 |
+
"lstrip": false,
|
| 167 |
+
"normalized": false,
|
| 168 |
+
"rstrip": false,
|
| 169 |
+
"single_word": false,
|
| 170 |
+
"special": true
|
| 171 |
+
},
|
| 172 |
+
"151663": {
|
| 173 |
+
"content": "<|reserved_special_token_3|>",
|
| 174 |
+
"lstrip": false,
|
| 175 |
+
"normalized": false,
|
| 176 |
+
"rstrip": false,
|
| 177 |
+
"single_word": false,
|
| 178 |
+
"special": true
|
| 179 |
+
},
|
| 180 |
+
"151664": {
|
| 181 |
+
"content": "<|reserved_special_token_4|>",
|
| 182 |
+
"lstrip": false,
|
| 183 |
+
"normalized": false,
|
| 184 |
+
"rstrip": false,
|
| 185 |
+
"single_word": false,
|
| 186 |
+
"special": true
|
| 187 |
+
},
|
| 188 |
+
"151665": {
|
| 189 |
+
"content": "<|reserved_special_token_5|>",
|
| 190 |
+
"lstrip": false,
|
| 191 |
+
"normalized": false,
|
| 192 |
+
"rstrip": false,
|
| 193 |
+
"single_word": false,
|
| 194 |
+
"special": true
|
| 195 |
+
}
|
| 196 |
+
},
|
| 197 |
+
"additional_special_tokens": [
|
| 198 |
+
"<image>",
|
| 199 |
+
"</image>",
|
| 200 |
+
"<ref>",
|
| 201 |
+
"</ref>",
|
| 202 |
+
"<box>",
|
| 203 |
+
"</box>",
|
| 204 |
+
"<quad>",
|
| 205 |
+
"</quad>",
|
| 206 |
+
"<point>",
|
| 207 |
+
"</point>",
|
| 208 |
+
"<slice>",
|
| 209 |
+
"</slice>",
|
| 210 |
+
"<image_id>",
|
| 211 |
+
"</image_id>",
|
| 212 |
+
"<|reserved_special_token_0|>",
|
| 213 |
+
"<|reserved_special_token_1|>",
|
| 214 |
+
"<|reserved_special_token_2|>",
|
| 215 |
+
"<|reserved_special_token_3|>",
|
| 216 |
+
"<|reserved_special_token_4|>",
|
| 217 |
+
"<|reserved_special_token_5|>"
|
| 218 |
+
],
|
| 219 |
+
"auto_map": {
|
| 220 |
+
"AutoTokenizer": [
|
| 221 |
+
"openbmb/MiniCPM-V-2_6--tokenization_minicpmv_fast.MiniCPMVTokenizerFast",
|
| 222 |
+
null
|
| 223 |
+
]
|
| 224 |
+
},
|
| 225 |
+
"bos_token": "<|im_start|>",
|
| 226 |
+
"chat_template": "{% for message in messages %}{% if loop.first and messages[0]['role'] != 'system' %}{{ '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n' }}{% endif %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}",
|
| 227 |
+
"clean_up_tokenization_spaces": false,
|
| 228 |
+
"eos_token": "<|im_end|>",
|
| 229 |
+
"errors": "replace",
|
| 230 |
+
"model_max_length": 1000000000000000019884624838656,
|
| 231 |
+
"pad_token": "<|endoftext|>",
|
| 232 |
+
"split_special_tokens": false,
|
| 233 |
+
"tokenizer_class": "MiniCPMVTokenizer",
|
| 234 |
+
"unk_token": "<unk>"
|
| 235 |
+
}
|
vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|