

Upload 22 files
Browse files- .github/FUNDING.yml +1 -0
- .gitignore +3 -0
- EXAMPLES.md +37 -0
- LICENSE +27 -0
- MANIFEST.in +4 -0
- README.md +302 -5
- figures/pipeline.png +0 -0
- requirements.txt +7 -0
- setup.py +30 -0
- whisperx/SubtitlesProcessor.py +227 -0
- whisperx/__init__.py +4 -0
- whisperx/__main__.py +4 -0
- whisperx/alignment.py +467 -0
- whisperx/asr.py +357 -0
- whisperx/assets/mel_filters.npz +3 -0
- whisperx/audio.py +159 -0
- whisperx/conjunctions.py +43 -0
- whisperx/diarize.py +74 -0
- whisperx/transcribe.py +230 -0
- whisperx/types.py +58 -0
- whisperx/utils.py +437 -0
- whisperx/vad.py +311 -0
.github/FUNDING.yml
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
custom: https://www.buymeacoffee.com/maxhbain
|
.gitignore
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
whisperx.egg-info/
|
| 2 |
+
**/__pycache__/
|
| 3 |
+
.ipynb_checkpoints
|
EXAMPLES.md
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# More Examples
|
| 2 |
+
|
| 3 |
+
## Other Languages
|
| 4 |
+
|
| 5 |
+
For non-english ASR, it is best to use the `large` whisper model. Alignment models are automatically picked by the chosen language from the default [lists](https://github.com/m-bain/whisperX/blob/main/whisperx/alignment.py#L18).
|
| 6 |
+
|
| 7 |
+
Currently support default models tested for {en, fr, de, es, it, ja, zh, nl}
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
If the detected language is not in this list, you need to find a phoneme-based ASR model from [huggingface model hub](https://huggingface.co/models) and test it on your data.
|
| 11 |
+
|
| 12 |
+
### French
|
| 13 |
+
whisperx --model large --language fr examples/sample_fr_01.wav
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
https://user-images.githubusercontent.com/36994049/208298804-31c49d6f-6787-444e-a53f-e93c52706752.mov
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
### German
|
| 20 |
+
whisperx --model large --language de examples/sample_de_01.wav
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
https://user-images.githubusercontent.com/36994049/208298811-e36002ba-3698-4731-97d4-0aebd07e0eb3.mov
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
### Italian
|
| 27 |
+
whisperx --model large --language de examples/sample_it_01.wav
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
https://user-images.githubusercontent.com/36994049/208298819-6f462b2c-8cae-4c54-b8e1-90855794efc7.mov
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
### Japanese
|
| 34 |
+
whisperx --model large --language ja examples/sample_ja_01.wav
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
https://user-images.githubusercontent.com/19920981/208731743-311f2360-b73b-4c60-809d-aaf3cd7e06f4.mov
|
LICENSE
CHANGED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Copyright (c) 2022, Max Bain
|
| 2 |
+
All rights reserved.
|
| 3 |
+
|
| 4 |
+
Redistribution and use in source and binary forms, with or without
|
| 5 |
+
modification, are permitted provided that the following conditions are met:
|
| 6 |
+
1. Redistributions of source code must retain the above copyright
|
| 7 |
+
notice, this list of conditions and the following disclaimer.
|
| 8 |
+
2. Redistributions in binary form must reproduce the above copyright
|
| 9 |
+
notice, this list of conditions and the following disclaimer in the
|
| 10 |
+
documentation and/or other materials provided with the distribution.
|
| 11 |
+
3. All advertising materials mentioning features or use of this software
|
| 12 |
+
must display the following acknowledgement:
|
| 13 |
+
This product includes software developed by Max Bain.
|
| 14 |
+
4. Neither the name of Max Bain nor the
|
| 15 |
+
names of its contributors may be used to endorse or promote products
|
| 16 |
+
derived from this software without specific prior written permission.
|
| 17 |
+
|
| 18 |
+
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDER ''AS IS'' AND ANY
|
| 19 |
+
EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
|
| 20 |
+
WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
|
| 21 |
+
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
|
| 22 |
+
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
|
| 23 |
+
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
|
| 24 |
+
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
|
| 25 |
+
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
|
| 26 |
+
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
|
| 27 |
+
USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
MANIFEST.in
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
include whisperx/assets/*
|
| 2 |
+
include whisperx/assets/gpt2/*
|
| 3 |
+
include whisperx/assets/multilingual/*
|
| 4 |
+
include whisperx/normalizers/english.json
|
README.md
CHANGED
|
@@ -1,5 +1,302 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
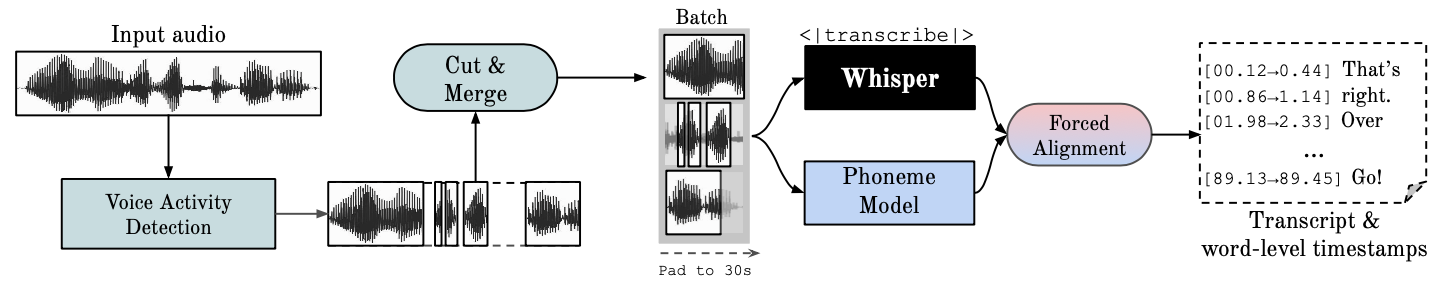
<h1 align="center">WhisperX</h1>
|
| 2 |
+
|
| 3 |
+
<p align="center">
|
| 4 |
+
<a href="https://github.com/m-bain/whisperX/stargazers">
|
| 5 |
+
<img src="https://img.shields.io/github/stars/m-bain/whisperX.svg?colorA=orange&colorB=orange&logo=github"
|
| 6 |
+
alt="GitHub stars">
|
| 7 |
+
</a>
|
| 8 |
+
<a href="https://github.com/m-bain/whisperX/issues">
|
| 9 |
+
<img src="https://img.shields.io/github/issues/m-bain/whisperx.svg"
|
| 10 |
+
alt="GitHub issues">
|
| 11 |
+
</a>
|
| 12 |
+
<a href="https://github.com/m-bain/whisperX/blob/master/LICENSE">
|
| 13 |
+
<img src="https://img.shields.io/github/license/m-bain/whisperX.svg"
|
| 14 |
+
alt="GitHub license">
|
| 15 |
+
</a>
|
| 16 |
+
<a href="https://arxiv.org/abs/2303.00747">
|
| 17 |
+
<img src="http://img.shields.io/badge/Arxiv-2303.00747-B31B1B.svg"
|
| 18 |
+
alt="ArXiv paper">
|
| 19 |
+
</a>
|
| 20 |
+
<a href="https://twitter.com/intent/tweet?text=&url=https%3A%2F%2Fgithub.com%2Fm-bain%2FwhisperX">
|
| 21 |
+
<img src="https://img.shields.io/twitter/url/https/github.com/m-bain/whisperX.svg?style=social" alt="Twitter">
|
| 22 |
+
</a>
|
| 23 |
+
</p>
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
<img width="1216" align="center" alt="whisperx-arch" src="figures/pipeline.png">
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
<!-- <p align="left">Whisper-Based Automatic Speech Recognition (ASR) with improved timestamp accuracy + quality via forced phoneme alignment and voice-activity based batching for fast inference.</p> -->
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
<!-- <h2 align="left", id="what-is-it">What is it 🔎</h2> -->
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
This repository provides fast automatic speech recognition (70x realtime with large-v2) with word-level timestamps and speaker diarization.
|
| 36 |
+
|
| 37 |
+
- ⚡️ Batched inference for 70x realtime transcription using whisper large-v2
|
| 38 |
+
- 🪶 [faster-whisper](https://github.com/guillaumekln/faster-whisper) backend, requires <8GB gpu memory for large-v2 with beam_size=5
|
| 39 |
+
- 🎯 Accurate word-level timestamps using wav2vec2 alignment
|
| 40 |
+
- 👯♂️ Multispeaker ASR using speaker diarization from [pyannote-audio](https://github.com/pyannote/pyannote-audio) (speaker ID labels)
|
| 41 |
+
- 🗣️ VAD preprocessing, reduces hallucination & batching with no WER degradation
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
**Whisper** is an ASR model [developed by OpenAI](https://github.com/openai/whisper), trained on a large dataset of diverse audio. Whilst it does produces highly accurate transcriptions, the corresponding timestamps are at the utterance-level, not per word, and can be inaccurate by several seconds. OpenAI's whisper does not natively support batching.
|
| 46 |
+
|
| 47 |
+
**Phoneme-Based ASR** A suite of models finetuned to recognise the smallest unit of speech distinguishing one word from another, e.g. the element p in "tap". A popular example model is [wav2vec2.0](https://huggingface.co/facebook/wav2vec2-large-960h-lv60-self).
|
| 48 |
+
|
| 49 |
+
**Forced Alignment** refers to the process by which orthographic transcriptions are aligned to audio recordings to automatically generate phone level segmentation.
|
| 50 |
+
|
| 51 |
+
**Voice Activity Detection (VAD)** is the detection of the presence or absence of human speech.
|
| 52 |
+
|
| 53 |
+
**Speaker Diarization** is the process of partitioning an audio stream containing human speech into homogeneous segments according to the identity of each speaker.
|
| 54 |
+
|
| 55 |
+
<h2 align="left", id="highlights">New🚨</h2>
|
| 56 |
+
|
| 57 |
+
- 1st place at [Ego4d transcription challenge](https://eval.ai/web/challenges/challenge-page/1637/leaderboard/3931/WER) 🏆
|
| 58 |
+
- _WhisperX_ accepted at INTERSPEECH 2023
|
| 59 |
+
- v3 transcript segment-per-sentence: using nltk sent_tokenize for better subtitlting & better diarization
|
| 60 |
+
- v3 released, 70x speed-up open-sourced. Using batched whisper with [faster-whisper](https://github.com/guillaumekln/faster-whisper) backend!
|
| 61 |
+
- v2 released, code cleanup, imports whisper library VAD filtering is now turned on by default, as in the paper.
|
| 62 |
+
- Paper drop🎓👨🏫! Please see our [ArxiV preprint](https://arxiv.org/abs/2303.00747) for benchmarking and details of WhisperX. We also introduce more efficient batch inference resulting in large-v2 with *60-70x REAL TIME speed.
|
| 63 |
+
|
| 64 |
+
<h2 align="left" id="setup">Setup ⚙️</h2>
|
| 65 |
+
Tested for PyTorch 2.0, Python 3.10 (use other versions at your own risk!)
|
| 66 |
+
|
| 67 |
+
GPU execution requires the NVIDIA libraries cuBLAS 11.x and cuDNN 8.x to be installed on the system. Please refer to the [CTranslate2 documentation](https://opennmt.net/CTranslate2/installation.html).
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
### 1. Create Python3.10 environment
|
| 71 |
+
|
| 72 |
+
`conda create --name whisperx python=3.10`
|
| 73 |
+
|
| 74 |
+
`conda activate whisperx`
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
### 2. Install PyTorch, e.g. for Linux and Windows CUDA11.8:
|
| 78 |
+
|
| 79 |
+
`conda install pytorch==2.0.0 torchaudio==2.0.0 pytorch-cuda=11.8 -c pytorch -c nvidia`
|
| 80 |
+
|
| 81 |
+
See other methods [here.](https://pytorch.org/get-started/previous-versions/#v200)
|
| 82 |
+
|
| 83 |
+
### 3. Install this repo
|
| 84 |
+
|
| 85 |
+
`pip install git+https://github.com/m-bain/whisperx.git`
|
| 86 |
+
|
| 87 |
+
If already installed, update package to most recent commit
|
| 88 |
+
|
| 89 |
+
`pip install git+https://github.com/m-bain/whisperx.git --upgrade`
|
| 90 |
+
|
| 91 |
+
If wishing to modify this package, clone and install in editable mode:
|
| 92 |
+
```
|
| 93 |
+
$ git clone https://github.com/m-bain/whisperX.git
|
| 94 |
+
$ cd whisperX
|
| 95 |
+
$ pip install -e .
|
| 96 |
+
```
|
| 97 |
+
|
| 98 |
+
You may also need to install ffmpeg, rust etc. Follow openAI instructions here https://github.com/openai/whisper#setup.
|
| 99 |
+
|
| 100 |
+
### Speaker Diarization
|
| 101 |
+
To **enable Speaker Diarization**, include your Hugging Face access token (read) that you can generate from [Here](https://huggingface.co/settings/tokens) after the `--hf_token` argument and accept the user agreement for the following models: [Segmentation](https://huggingface.co/pyannote/segmentation-3.0) and [Speaker-Diarization-3.1](https://huggingface.co/pyannote/speaker-diarization-3.1) (if you choose to use Speaker-Diarization 2.x, follow requirements [here](https://huggingface.co/pyannote/speaker-diarization) instead.)
|
| 102 |
+
|
| 103 |
+
> **Note**<br>
|
| 104 |
+
> As of Oct 11, 2023, there is a known issue regarding slow performance with pyannote/Speaker-Diarization-3.0 in whisperX. It is due to dependency conflicts between faster-whisper and pyannote-audio 3.0.0. Please see [this issue](https://github.com/m-bain/whisperX/issues/499) for more details and potential workarounds.
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
<h2 align="left" id="example">Usage 💬 (command line)</h2>
|
| 108 |
+
|
| 109 |
+
### English
|
| 110 |
+
|
| 111 |
+
Run whisper on example segment (using default params, whisper small) add `--highlight_words True` to visualise word timings in the .srt file.
|
| 112 |
+
|
| 113 |
+
whisperx examples/sample01.wav
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
Result using *WhisperX* with forced alignment to wav2vec2.0 large:
|
| 117 |
+
|
| 118 |
+
https://user-images.githubusercontent.com/36994049/208253969-7e35fe2a-7541-434a-ae91-8e919540555d.mp4
|
| 119 |
+
|
| 120 |
+
Compare this to original whisper out the box, where many transcriptions are out of sync:
|
| 121 |
+
|
| 122 |
+
https://user-images.githubusercontent.com/36994049/207743923-b4f0d537-29ae-4be2-b404-bb941db73652.mov
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
For increased timestamp accuracy, at the cost of higher gpu mem, use bigger models (bigger alignment model not found to be that helpful, see paper) e.g.
|
| 126 |
+
|
| 127 |
+
whisperx examples/sample01.wav --model large-v2 --align_model WAV2VEC2_ASR_LARGE_LV60K_960H --batch_size 4
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
To label the transcript with speaker ID's (set number of speakers if known e.g. `--min_speakers 2` `--max_speakers 2`):
|
| 131 |
+
|
| 132 |
+
whisperx examples/sample01.wav --model large-v2 --diarize --highlight_words True
|
| 133 |
+
|
| 134 |
+
To run on CPU instead of GPU (and for running on Mac OS X):
|
| 135 |
+
|
| 136 |
+
whisperx examples/sample01.wav --compute_type int8
|
| 137 |
+
|
| 138 |
+
### Other languages
|
| 139 |
+
|
| 140 |
+
The phoneme ASR alignment model is *language-specific*, for tested languages these models are [automatically picked from torchaudio pipelines or huggingface](https://github.com/m-bain/whisperX/blob/e909f2f766b23b2000f2d95df41f9b844ac53e49/whisperx/transcribe.py#L22).
|
| 141 |
+
Just pass in the `--language` code, and use the whisper `--model large`.
|
| 142 |
+
|
| 143 |
+
Currently default models provided for `{en, fr, de, es, it, ja, zh, nl, uk, pt}`. If the detected language is not in this list, you need to find a phoneme-based ASR model from [huggingface model hub](https://huggingface.co/models) and test it on your data.
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
#### E.g. German
|
| 147 |
+
whisperx --model large-v2 --language de examples/sample_de_01.wav
|
| 148 |
+
|
| 149 |
+
https://user-images.githubusercontent.com/36994049/208298811-e36002ba-3698-4731-97d4-0aebd07e0eb3.mov
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
See more examples in other languages [here](EXAMPLES.md).
|
| 153 |
+
|
| 154 |
+
## Python usage 🐍
|
| 155 |
+
|
| 156 |
+
```python
|
| 157 |
+
import whisperx
|
| 158 |
+
import gc
|
| 159 |
+
|
| 160 |
+
device = "cuda"
|
| 161 |
+
audio_file = "audio.mp3"
|
| 162 |
+
batch_size = 16 # reduce if low on GPU mem
|
| 163 |
+
compute_type = "float16" # change to "int8" if low on GPU mem (may reduce accuracy)
|
| 164 |
+
|
| 165 |
+
# 1. Transcribe with original whisper (batched)
|
| 166 |
+
model = whisperx.load_model("large-v2", device, compute_type=compute_type)
|
| 167 |
+
|
| 168 |
+
# save model to local path (optional)
|
| 169 |
+
# model_dir = "/path/"
|
| 170 |
+
# model = whisperx.load_model("large-v2", device, compute_type=compute_type, download_root=model_dir)
|
| 171 |
+
|
| 172 |
+
audio = whisperx.load_audio(audio_file)
|
| 173 |
+
result = model.transcribe(audio, batch_size=batch_size)
|
| 174 |
+
print(result["segments"]) # before alignment
|
| 175 |
+
|
| 176 |
+
# delete model if low on GPU resources
|
| 177 |
+
# import gc; gc.collect(); torch.cuda.empty_cache(); del model
|
| 178 |
+
|
| 179 |
+
# 2. Align whisper output
|
| 180 |
+
model_a, metadata = whisperx.load_align_model(language_code=result["language"], device=device)
|
| 181 |
+
result = whisperx.align(result["segments"], model_a, metadata, audio, device, return_char_alignments=False)
|
| 182 |
+
|
| 183 |
+
print(result["segments"]) # after alignment
|
| 184 |
+
|
| 185 |
+
# delete model if low on GPU resources
|
| 186 |
+
# import gc; gc.collect(); torch.cuda.empty_cache(); del model_a
|
| 187 |
+
|
| 188 |
+
# 3. Assign speaker labels
|
| 189 |
+
diarize_model = whisperx.DiarizationPipeline(use_auth_token=YOUR_HF_TOKEN, device=device)
|
| 190 |
+
|
| 191 |
+
# add min/max number of speakers if known
|
| 192 |
+
diarize_segments = diarize_model(audio)
|
| 193 |
+
# diarize_model(audio, min_speakers=min_speakers, max_speakers=max_speakers)
|
| 194 |
+
|
| 195 |
+
result = whisperx.assign_word_speakers(diarize_segments, result)
|
| 196 |
+
print(diarize_segments)
|
| 197 |
+
print(result["segments"]) # segments are now assigned speaker IDs
|
| 198 |
+
```
|
| 199 |
+
|
| 200 |
+
## Demos 🚀
|
| 201 |
+
|
| 202 |
+
[](https://replicate.com/victor-upmeet/whisperx)
|
| 203 |
+
[](https://replicate.com/daanelson/whisperx)
|
| 204 |
+
[](https://replicate.com/carnifexer/whisperx)
|
| 205 |
+
|
| 206 |
+
If you don't have access to your own GPUs, use the links above to try out WhisperX.
|
| 207 |
+
|
| 208 |
+
<h2 align="left" id="whisper-mod">Technical Details 👷♂️</h2>
|
| 209 |
+
|
| 210 |
+
For specific details on the batching and alignment, the effect of VAD, as well as the chosen alignment model, see the preprint [paper](https://www.robots.ox.ac.uk/~vgg/publications/2023/Bain23/bain23.pdf).
|
| 211 |
+
|
| 212 |
+
To reduce GPU memory requirements, try any of the following (2. & 3. can affect quality):
|
| 213 |
+
1. reduce batch size, e.g. `--batch_size 4`
|
| 214 |
+
2. use a smaller ASR model `--model base`
|
| 215 |
+
3. Use lighter compute type `--compute_type int8`
|
| 216 |
+
|
| 217 |
+
Transcription differences from openai's whisper:
|
| 218 |
+
1. Transcription without timestamps. To enable single pass batching, whisper inference is performed `--without_timestamps True`, this ensures 1 forward pass per sample in the batch. However, this can cause discrepancies the default whisper output.
|
| 219 |
+
2. VAD-based segment transcription, unlike the buffered transcription of openai's. In Wthe WhisperX paper we show this reduces WER, and enables accurate batched inference
|
| 220 |
+
3. `--condition_on_prev_text` is set to `False` by default (reduces hallucination)
|
| 221 |
+
|
| 222 |
+
<h2 align="left" id="limitations">Limitations ⚠️</h2>
|
| 223 |
+
|
| 224 |
+
- Transcript words which do not contain characters in the alignment models dictionary e.g. "2014." or "£13.60" cannot be aligned and therefore are not given a timing.
|
| 225 |
+
- Overlapping speech is not handled particularly well by whisper nor whisperx
|
| 226 |
+
- Diarization is far from perfect
|
| 227 |
+
- Language specific wav2vec2 model is needed
|
| 228 |
+
|
| 229 |
+
|
| 230 |
+
<h2 align="left" id="contribute">Contribute 🧑🏫</h2>
|
| 231 |
+
|
| 232 |
+
If you are multilingual, a major way you can contribute to this project is to find phoneme models on huggingface (or train your own) and test them on speech for the target language. If the results look good send a pull request and some examples showing its success.
|
| 233 |
+
|
| 234 |
+
Bug finding and pull requests are also highly appreciated to keep this project going, since it's already diverging from the original research scope.
|
| 235 |
+
|
| 236 |
+
<h2 align="left" id="coming-soon">TODO 🗓</h2>
|
| 237 |
+
|
| 238 |
+
* [x] Multilingual init
|
| 239 |
+
|
| 240 |
+
* [x] Automatic align model selection based on language detection
|
| 241 |
+
|
| 242 |
+
* [x] Python usage
|
| 243 |
+
|
| 244 |
+
* [x] Incorporating speaker diarization
|
| 245 |
+
|
| 246 |
+
* [x] Model flush, for low gpu mem resources
|
| 247 |
+
|
| 248 |
+
* [x] Faster-whisper backend
|
| 249 |
+
|
| 250 |
+
* [x] Add max-line etc. see (openai's whisper utils.py)
|
| 251 |
+
|
| 252 |
+
* [x] Sentence-level segments (nltk toolbox)
|
| 253 |
+
|
| 254 |
+
* [x] Improve alignment logic
|
| 255 |
+
|
| 256 |
+
* [ ] update examples with diarization and word highlighting
|
| 257 |
+
|
| 258 |
+
* [ ] Subtitle .ass output <- bring this back (removed in v3)
|
| 259 |
+
|
| 260 |
+
* [ ] Add benchmarking code (TEDLIUM for spd/WER & word segmentation)
|
| 261 |
+
|
| 262 |
+
* [ ] Allow silero-vad as alternative VAD option
|
| 263 |
+
|
| 264 |
+
* [ ] Improve diarization (word level). *Harder than first thought...*
|
| 265 |
+
|
| 266 |
+
|
| 267 |
+
<h2 align="left" id="contact">Contact/Support 📇</h2>
|
| 268 |
+
|
| 269 |
+
|
| 270 |
+
Contact maxhbain@gmail.com for queries.
|
| 271 |
+
|
| 272 |
+
<a href="https://www.buymeacoffee.com/maxhbain" target="_blank"><img src="https://cdn.buymeacoffee.com/buttons/default-orange.png" alt="Buy Me A Coffee" height="41" width="174"></a>
|
| 273 |
+
|
| 274 |
+
|
| 275 |
+
<h2 align="left" id="acks">Acknowledgements 🙏</h2>
|
| 276 |
+
|
| 277 |
+
This work, and my PhD, is supported by the [VGG (Visual Geometry Group)](https://www.robots.ox.ac.uk/~vgg/) and the University of Oxford.
|
| 278 |
+
|
| 279 |
+
Of course, this is builds on [openAI's whisper](https://github.com/openai/whisper).
|
| 280 |
+
Borrows important alignment code from [PyTorch tutorial on forced alignment](https://pytorch.org/tutorials/intermediate/forced_alignment_with_torchaudio_tutorial.html)
|
| 281 |
+
And uses the wonderful pyannote VAD / Diarization https://github.com/pyannote/pyannote-audio
|
| 282 |
+
|
| 283 |
+
|
| 284 |
+
Valuable VAD & Diarization Models from [pyannote audio][https://github.com/pyannote/pyannote-audio]
|
| 285 |
+
|
| 286 |
+
Great backend from [faster-whisper](https://github.com/guillaumekln/faster-whisper) and [CTranslate2](https://github.com/OpenNMT/CTranslate2)
|
| 287 |
+
|
| 288 |
+
Those who have [supported this work financially](https://www.buymeacoffee.com/maxhbain) 🙏
|
| 289 |
+
|
| 290 |
+
Finally, thanks to the OS [contributors](https://github.com/m-bain/whisperX/graphs/contributors) of this project, keeping it going and identifying bugs.
|
| 291 |
+
|
| 292 |
+
<h2 align="left" id="cite">Citation</h2>
|
| 293 |
+
If you use this in your research, please cite the paper:
|
| 294 |
+
|
| 295 |
+
```bibtex
|
| 296 |
+
@article{bain2022whisperx,
|
| 297 |
+
title={WhisperX: Time-Accurate Speech Transcription of Long-Form Audio},
|
| 298 |
+
author={Bain, Max and Huh, Jaesung and Han, Tengda and Zisserman, Andrew},
|
| 299 |
+
journal={INTERSPEECH 2023},
|
| 300 |
+
year={2023}
|
| 301 |
+
}
|
| 302 |
+
```
|
figures/pipeline.png
ADDED
|
requirements.txt
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
torch>=2
|
| 2 |
+
torchaudio>=2
|
| 3 |
+
faster-whisper==1.0.0
|
| 4 |
+
transformers
|
| 5 |
+
pandas
|
| 6 |
+
setuptools>=65
|
| 7 |
+
nltk
|
setup.py
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import platform
|
| 3 |
+
|
| 4 |
+
import pkg_resources
|
| 5 |
+
from setuptools import find_packages, setup
|
| 6 |
+
|
| 7 |
+
setup(
|
| 8 |
+
name="whisperx",
|
| 9 |
+
py_modules=["whisperx"],
|
| 10 |
+
version="3.1.1",
|
| 11 |
+
description="Time-Accurate Automatic Speech Recognition using Whisper.",
|
| 12 |
+
readme="README.md",
|
| 13 |
+
python_requires=">=3.8",
|
| 14 |
+
author="Max Bain",
|
| 15 |
+
url="https://github.com/m-bain/whisperx",
|
| 16 |
+
license="MIT",
|
| 17 |
+
packages=find_packages(exclude=["tests*"]),
|
| 18 |
+
install_requires=[
|
| 19 |
+
str(r)
|
| 20 |
+
for r in pkg_resources.parse_requirements(
|
| 21 |
+
open(os.path.join(os.path.dirname(__file__), "requirements.txt"))
|
| 22 |
+
)
|
| 23 |
+
]
|
| 24 |
+
+ [f"pyannote.audio==3.1.1"],
|
| 25 |
+
entry_points={
|
| 26 |
+
"console_scripts": ["whisperx=whisperx.transcribe:cli"],
|
| 27 |
+
},
|
| 28 |
+
include_package_data=True,
|
| 29 |
+
extras_require={"dev": ["pytest"]},
|
| 30 |
+
)
|
whisperx/SubtitlesProcessor.py
ADDED
|
@@ -0,0 +1,227 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
from conjunctions import get_conjunctions, get_comma
|
| 3 |
+
from typing import TextIO
|
| 4 |
+
|
| 5 |
+
def normal_round(n):
|
| 6 |
+
if n - math.floor(n) < 0.5:
|
| 7 |
+
return math.floor(n)
|
| 8 |
+
return math.ceil(n)
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def format_timestamp(seconds: float, is_vtt: bool = False):
|
| 12 |
+
|
| 13 |
+
assert seconds >= 0, "non-negative timestamp expected"
|
| 14 |
+
milliseconds = round(seconds * 1000.0)
|
| 15 |
+
|
| 16 |
+
hours = milliseconds // 3_600_000
|
| 17 |
+
milliseconds -= hours * 3_600_000
|
| 18 |
+
|
| 19 |
+
minutes = milliseconds // 60_000
|
| 20 |
+
milliseconds -= minutes * 60_000
|
| 21 |
+
|
| 22 |
+
seconds = milliseconds // 1_000
|
| 23 |
+
milliseconds -= seconds * 1_000
|
| 24 |
+
|
| 25 |
+
separator = '.' if is_vtt else ','
|
| 26 |
+
|
| 27 |
+
hours_marker = f"{hours:02d}:"
|
| 28 |
+
return (
|
| 29 |
+
f"{hours_marker}{minutes:02d}:{seconds:02d}{separator}{milliseconds:03d}"
|
| 30 |
+
)
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
class SubtitlesProcessor:
|
| 35 |
+
def __init__(self, segments, lang, max_line_length = 45, min_char_length_splitter = 30, is_vtt = False):
|
| 36 |
+
self.comma = get_comma(lang)
|
| 37 |
+
self.conjunctions = set(get_conjunctions(lang))
|
| 38 |
+
self.segments = segments
|
| 39 |
+
self.lang = lang
|
| 40 |
+
self.max_line_length = max_line_length
|
| 41 |
+
self.min_char_length_splitter = min_char_length_splitter
|
| 42 |
+
self.is_vtt = is_vtt
|
| 43 |
+
complex_script_languages = ['th', 'lo', 'my', 'km', 'am', 'ko', 'ja', 'zh', 'ti', 'ta', 'te', 'kn', 'ml', 'hi', 'ne', 'mr', 'ar', 'fa', 'ur', 'ka']
|
| 44 |
+
if self.lang in complex_script_languages:
|
| 45 |
+
self.max_line_length = 30
|
| 46 |
+
self.min_char_length_splitter = 20
|
| 47 |
+
|
| 48 |
+
def estimate_timestamp_for_word(self, words, i, next_segment_start_time=None):
|
| 49 |
+
k = 0.25
|
| 50 |
+
has_prev_end = i > 0 and 'end' in words[i - 1]
|
| 51 |
+
has_next_start = i < len(words) - 1 and 'start' in words[i + 1]
|
| 52 |
+
|
| 53 |
+
if has_prev_end:
|
| 54 |
+
words[i]['start'] = words[i - 1]['end']
|
| 55 |
+
if has_next_start:
|
| 56 |
+
words[i]['end'] = words[i + 1]['start']
|
| 57 |
+
else:
|
| 58 |
+
if next_segment_start_time:
|
| 59 |
+
words[i]['end'] = next_segment_start_time if next_segment_start_time - words[i - 1]['end'] <= 1 else next_segment_start_time - 0.5
|
| 60 |
+
else:
|
| 61 |
+
words[i]['end'] = words[i]['start'] + len(words[i]['word']) * k
|
| 62 |
+
|
| 63 |
+
elif has_next_start:
|
| 64 |
+
words[i]['start'] = words[i + 1]['start'] - len(words[i]['word']) * k
|
| 65 |
+
words[i]['end'] = words[i + 1]['start']
|
| 66 |
+
|
| 67 |
+
else:
|
| 68 |
+
if next_segment_start_time:
|
| 69 |
+
words[i]['start'] = next_segment_start_time - 1
|
| 70 |
+
words[i]['end'] = next_segment_start_time - 0.5
|
| 71 |
+
else:
|
| 72 |
+
words[i]['start'] = 0
|
| 73 |
+
words[i]['end'] = 0
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def process_segments(self, advanced_splitting=True):
|
| 78 |
+
subtitles = []
|
| 79 |
+
for i, segment in enumerate(self.segments):
|
| 80 |
+
next_segment_start_time = self.segments[i + 1]['start'] if i + 1 < len(self.segments) else None
|
| 81 |
+
|
| 82 |
+
if advanced_splitting:
|
| 83 |
+
|
| 84 |
+
split_points = self.determine_advanced_split_points(segment, next_segment_start_time)
|
| 85 |
+
subtitles.extend(self.generate_subtitles_from_split_points(segment, split_points, next_segment_start_time))
|
| 86 |
+
else:
|
| 87 |
+
words = segment['words']
|
| 88 |
+
for i, word in enumerate(words):
|
| 89 |
+
if 'start' not in word or 'end' not in word:
|
| 90 |
+
self.estimate_timestamp_for_word(words, i, next_segment_start_time)
|
| 91 |
+
|
| 92 |
+
subtitles.append({
|
| 93 |
+
'start': segment['start'],
|
| 94 |
+
'end': segment['end'],
|
| 95 |
+
'text': segment['text']
|
| 96 |
+
})
|
| 97 |
+
|
| 98 |
+
return subtitles
|
| 99 |
+
|
| 100 |
+
def determine_advanced_split_points(self, segment, next_segment_start_time=None):
|
| 101 |
+
split_points = []
|
| 102 |
+
last_split_point = 0
|
| 103 |
+
char_count = 0
|
| 104 |
+
|
| 105 |
+
words = segment.get('words', segment['text'].split())
|
| 106 |
+
add_space = 0 if self.lang in ['zh', 'ja'] else 1
|
| 107 |
+
|
| 108 |
+
total_char_count = sum(len(word['word']) if isinstance(word, dict) else len(word) + add_space for word in words)
|
| 109 |
+
char_count_after = total_char_count
|
| 110 |
+
|
| 111 |
+
for i, word in enumerate(words):
|
| 112 |
+
word_text = word['word'] if isinstance(word, dict) else word
|
| 113 |
+
word_length = len(word_text) + add_space
|
| 114 |
+
char_count += word_length
|
| 115 |
+
char_count_after -= word_length
|
| 116 |
+
|
| 117 |
+
char_count_before = char_count - word_length
|
| 118 |
+
|
| 119 |
+
if isinstance(word, dict) and ('start' not in word or 'end' not in word):
|
| 120 |
+
self.estimate_timestamp_for_word(words, i, next_segment_start_time)
|
| 121 |
+
|
| 122 |
+
if char_count >= self.max_line_length:
|
| 123 |
+
midpoint = normal_round((last_split_point + i) / 2)
|
| 124 |
+
if char_count_before >= self.min_char_length_splitter:
|
| 125 |
+
split_points.append(midpoint)
|
| 126 |
+
last_split_point = midpoint + 1
|
| 127 |
+
char_count = sum(len(words[j]['word']) if isinstance(words[j], dict) else len(words[j]) + add_space for j in range(last_split_point, i + 1))
|
| 128 |
+
|
| 129 |
+
elif word_text.endswith(self.comma) and char_count_before >= self.min_char_length_splitter and char_count_after >= self.min_char_length_splitter:
|
| 130 |
+
split_points.append(i)
|
| 131 |
+
last_split_point = i + 1
|
| 132 |
+
char_count = 0
|
| 133 |
+
|
| 134 |
+
elif word_text.lower() in self.conjunctions and char_count_before >= self.min_char_length_splitter and char_count_after >= self.min_char_length_splitter:
|
| 135 |
+
split_points.append(i - 1)
|
| 136 |
+
last_split_point = i
|
| 137 |
+
char_count = word_length
|
| 138 |
+
|
| 139 |
+
return split_points
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
def generate_subtitles_from_split_points(self, segment, split_points, next_start_time=None):
|
| 143 |
+
subtitles = []
|
| 144 |
+
|
| 145 |
+
words = segment.get('words', segment['text'].split())
|
| 146 |
+
total_word_count = len(words)
|
| 147 |
+
total_time = segment['end'] - segment['start']
|
| 148 |
+
elapsed_time = segment['start']
|
| 149 |
+
prefix = ' ' if self.lang not in ['zh', 'ja'] else ''
|
| 150 |
+
start_idx = 0
|
| 151 |
+
for split_point in split_points:
|
| 152 |
+
|
| 153 |
+
fragment_words = words[start_idx:split_point + 1]
|
| 154 |
+
current_word_count = len(fragment_words)
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
if isinstance(fragment_words[0], dict):
|
| 158 |
+
start_time = fragment_words[0]['start']
|
| 159 |
+
end_time = fragment_words[-1]['end']
|
| 160 |
+
next_start_time_for_word = words[split_point + 1]['start'] if split_point + 1 < len(words) else None
|
| 161 |
+
if next_start_time_for_word and (next_start_time_for_word - end_time) <= 0.8:
|
| 162 |
+
end_time = next_start_time_for_word
|
| 163 |
+
else:
|
| 164 |
+
fragment = prefix.join(fragment_words).strip()
|
| 165 |
+
current_duration = (current_word_count / total_word_count) * total_time
|
| 166 |
+
start_time = elapsed_time
|
| 167 |
+
end_time = elapsed_time + current_duration
|
| 168 |
+
elapsed_time += current_duration
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
subtitles.append({
|
| 172 |
+
'start': start_time,
|
| 173 |
+
'end': end_time,
|
| 174 |
+
'text': fragment if not isinstance(fragment_words[0], dict) else prefix.join(word['word'] for word in fragment_words)
|
| 175 |
+
})
|
| 176 |
+
|
| 177 |
+
start_idx = split_point + 1
|
| 178 |
+
|
| 179 |
+
# Handle the last fragment
|
| 180 |
+
if start_idx < len(words):
|
| 181 |
+
fragment_words = words[start_idx:]
|
| 182 |
+
current_word_count = len(fragment_words)
|
| 183 |
+
|
| 184 |
+
if isinstance(fragment_words[0], dict):
|
| 185 |
+
start_time = fragment_words[0]['start']
|
| 186 |
+
end_time = fragment_words[-1]['end']
|
| 187 |
+
else:
|
| 188 |
+
fragment = prefix.join(fragment_words).strip()
|
| 189 |
+
current_duration = (current_word_count / total_word_count) * total_time
|
| 190 |
+
start_time = elapsed_time
|
| 191 |
+
end_time = elapsed_time + current_duration
|
| 192 |
+
|
| 193 |
+
if next_start_time and (next_start_time - end_time) <= 0.8:
|
| 194 |
+
end_time = next_start_time
|
| 195 |
+
|
| 196 |
+
subtitles.append({
|
| 197 |
+
'start': start_time,
|
| 198 |
+
'end': end_time if end_time is not None else segment['end'],
|
| 199 |
+
'text': fragment if not isinstance(fragment_words[0], dict) else prefix.join(word['word'] for word in fragment_words)
|
| 200 |
+
})
|
| 201 |
+
|
| 202 |
+
return subtitles
|
| 203 |
+
|
| 204 |
+
|
| 205 |
+
|
| 206 |
+
def save(self, filename="subtitles.srt", advanced_splitting=True):
|
| 207 |
+
|
| 208 |
+
subtitles = self.process_segments(advanced_splitting)
|
| 209 |
+
|
| 210 |
+
def write_subtitle(file, idx, start_time, end_time, text):
|
| 211 |
+
|
| 212 |
+
file.write(f"{idx}\n")
|
| 213 |
+
file.write(f"{start_time} --> {end_time}\n")
|
| 214 |
+
file.write(text + "\n\n")
|
| 215 |
+
|
| 216 |
+
with open(filename, 'w', encoding='utf-8') as file:
|
| 217 |
+
if self.is_vtt:
|
| 218 |
+
file.write("WEBVTT\n\n")
|
| 219 |
+
|
| 220 |
+
if advanced_splitting:
|
| 221 |
+
for idx, subtitle in enumerate(subtitles, 1):
|
| 222 |
+
start_time = format_timestamp(subtitle['start'], self.is_vtt)
|
| 223 |
+
end_time = format_timestamp(subtitle['end'], self.is_vtt)
|
| 224 |
+
text = subtitle['text'].strip()
|
| 225 |
+
write_subtitle(file, idx, start_time, end_time, text)
|
| 226 |
+
|
| 227 |
+
return len(subtitles)
|
whisperx/__init__.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .transcribe import load_model
|
| 2 |
+
from .alignment import load_align_model, align
|
| 3 |
+
from .audio import load_audio
|
| 4 |
+
from .diarize import assign_word_speakers, DiarizationPipeline
|
whisperx/__main__.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .transcribe import cli
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
cli()
|
whisperx/alignment.py
ADDED
|
@@ -0,0 +1,467 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
""""
|
| 2 |
+
Forced Alignment with Whisper
|
| 3 |
+
C. Max Bain
|
| 4 |
+
"""
|
| 5 |
+
from dataclasses import dataclass
|
| 6 |
+
from typing import Iterable, Union, List
|
| 7 |
+
|
| 8 |
+
import numpy as np
|
| 9 |
+
import pandas as pd
|
| 10 |
+
import torch
|
| 11 |
+
import torchaudio
|
| 12 |
+
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
|
| 13 |
+
|
| 14 |
+
from .audio import SAMPLE_RATE, load_audio
|
| 15 |
+
from .utils import interpolate_nans
|
| 16 |
+
from .types import AlignedTranscriptionResult, SingleSegment, SingleAlignedSegment, SingleWordSegment
|
| 17 |
+
import nltk
|
| 18 |
+
from nltk.tokenize.punkt import PunktSentenceTokenizer, PunktParameters
|
| 19 |
+
|
| 20 |
+
PUNKT_ABBREVIATIONS = ['dr', 'vs', 'mr', 'mrs', 'prof']
|
| 21 |
+
|
| 22 |
+
LANGUAGES_WITHOUT_SPACES = ["ja", "zh"]
|
| 23 |
+
|
| 24 |
+
DEFAULT_ALIGN_MODELS_TORCH = {
|
| 25 |
+
"en": "WAV2VEC2_ASR_BASE_960H",
|
| 26 |
+
"fr": "VOXPOPULI_ASR_BASE_10K_FR",
|
| 27 |
+
"de": "VOXPOPULI_ASR_BASE_10K_DE",
|
| 28 |
+
"es": "VOXPOPULI_ASR_BASE_10K_ES",
|
| 29 |
+
"it": "VOXPOPULI_ASR_BASE_10K_IT",
|
| 30 |
+
}
|
| 31 |
+
|
| 32 |
+
DEFAULT_ALIGN_MODELS_HF = {
|
| 33 |
+
"ja": "jonatasgrosman/wav2vec2-large-xlsr-53-japanese",
|
| 34 |
+
"zh": "jonatasgrosman/wav2vec2-large-xlsr-53-chinese-zh-cn",
|
| 35 |
+
"nl": "jonatasgrosman/wav2vec2-large-xlsr-53-dutch",
|
| 36 |
+
"uk": "Yehor/wav2vec2-xls-r-300m-uk-with-small-lm",
|
| 37 |
+
"pt": "jonatasgrosman/wav2vec2-large-xlsr-53-portuguese",
|
| 38 |
+
"ar": "jonatasgrosman/wav2vec2-large-xlsr-53-arabic",
|
| 39 |
+
"cs": "comodoro/wav2vec2-xls-r-300m-cs-250",
|
| 40 |
+
"ru": "jonatasgrosman/wav2vec2-large-xlsr-53-russian",
|
| 41 |
+
"pl": "jonatasgrosman/wav2vec2-large-xlsr-53-polish",
|
| 42 |
+
"hu": "jonatasgrosman/wav2vec2-large-xlsr-53-hungarian",
|
| 43 |
+
"fi": "jonatasgrosman/wav2vec2-large-xlsr-53-finnish",
|
| 44 |
+
"fa": "jonatasgrosman/wav2vec2-large-xlsr-53-persian",
|
| 45 |
+
"el": "jonatasgrosman/wav2vec2-large-xlsr-53-greek",
|
| 46 |
+
"tr": "mpoyraz/wav2vec2-xls-r-300m-cv7-turkish",
|
| 47 |
+
"da": "saattrupdan/wav2vec2-xls-r-300m-ftspeech",
|
| 48 |
+
"he": "imvladikon/wav2vec2-xls-r-300m-hebrew",
|
| 49 |
+
"vi": 'nguyenvulebinh/wav2vec2-base-vi',
|
| 50 |
+
"ko": "kresnik/wav2vec2-large-xlsr-korean",
|
| 51 |
+
"ur": "kingabzpro/wav2vec2-large-xls-r-300m-Urdu",
|
| 52 |
+
"te": "anuragshas/wav2vec2-large-xlsr-53-telugu",
|
| 53 |
+
"hi": "theainerd/Wav2Vec2-large-xlsr-hindi",
|
| 54 |
+
"ca": "softcatala/wav2vec2-large-xlsr-catala",
|
| 55 |
+
"ml": "gvs/wav2vec2-large-xlsr-malayalam",
|
| 56 |
+
"no": "NbAiLab/nb-wav2vec2-1b-bokmaal",
|
| 57 |
+
"nn": "NbAiLab/nb-wav2vec2-300m-nynorsk",
|
| 58 |
+
}
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def load_align_model(language_code, device, model_name=None, model_dir=None):
|
| 62 |
+
if model_name is None:
|
| 63 |
+
# use default model
|
| 64 |
+
if language_code in DEFAULT_ALIGN_MODELS_TORCH:
|
| 65 |
+
model_name = DEFAULT_ALIGN_MODELS_TORCH[language_code]
|
| 66 |
+
elif language_code in DEFAULT_ALIGN_MODELS_HF:
|
| 67 |
+
model_name = DEFAULT_ALIGN_MODELS_HF[language_code]
|
| 68 |
+
else:
|
| 69 |
+
print(f"There is no default alignment model set for this language ({language_code}).\
|
| 70 |
+
Please find a wav2vec2.0 model finetuned on this language in https://huggingface.co/models, then pass the model name in --align_model [MODEL_NAME]")
|
| 71 |
+
raise ValueError(f"No default align-model for language: {language_code}")
|
| 72 |
+
|
| 73 |
+
if model_name in torchaudio.pipelines.__all__:
|
| 74 |
+
pipeline_type = "torchaudio"
|
| 75 |
+
bundle = torchaudio.pipelines.__dict__[model_name]
|
| 76 |
+
align_model = bundle.get_model(dl_kwargs={"model_dir": model_dir}).to(device)
|
| 77 |
+
labels = bundle.get_labels()
|
| 78 |
+
align_dictionary = {c.lower(): i for i, c in enumerate(labels)}
|
| 79 |
+
else:
|
| 80 |
+
try:
|
| 81 |
+
processor = Wav2Vec2Processor.from_pretrained(model_name)
|
| 82 |
+
align_model = Wav2Vec2ForCTC.from_pretrained(model_name)
|
| 83 |
+
except Exception as e:
|
| 84 |
+
print(e)
|
| 85 |
+
print(f"Error loading model from huggingface, check https://huggingface.co/models for finetuned wav2vec2.0 models")
|
| 86 |
+
raise ValueError(f'The chosen align_model "{model_name}" could not be found in huggingface (https://huggingface.co/models) or torchaudio (https://pytorch.org/audio/stable/pipelines.html#id14)')
|
| 87 |
+
pipeline_type = "huggingface"
|
| 88 |
+
align_model = align_model.to(device)
|
| 89 |
+
labels = processor.tokenizer.get_vocab()
|
| 90 |
+
align_dictionary = {char.lower(): code for char,code in processor.tokenizer.get_vocab().items()}
|
| 91 |
+
|
| 92 |
+
align_metadata = {"language": language_code, "dictionary": align_dictionary, "type": pipeline_type}
|
| 93 |
+
|
| 94 |
+
return align_model, align_metadata
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
def align(
|
| 98 |
+
transcript: Iterable[SingleSegment],
|
| 99 |
+
model: torch.nn.Module,
|
| 100 |
+
align_model_metadata: dict,
|
| 101 |
+
audio: Union[str, np.ndarray, torch.Tensor],
|
| 102 |
+
device: str,
|
| 103 |
+
interpolate_method: str = "nearest",
|
| 104 |
+
return_char_alignments: bool = False,
|
| 105 |
+
print_progress: bool = False,
|
| 106 |
+
combined_progress: bool = False,
|
| 107 |
+
) -> AlignedTranscriptionResult:
|
| 108 |
+
"""
|
| 109 |
+
Align phoneme recognition predictions to known transcription.
|
| 110 |
+
"""
|
| 111 |
+
|
| 112 |
+
if not torch.is_tensor(audio):
|
| 113 |
+
if isinstance(audio, str):
|
| 114 |
+
audio = load_audio(audio)
|
| 115 |
+
audio = torch.from_numpy(audio)
|
| 116 |
+
if len(audio.shape) == 1:
|
| 117 |
+
audio = audio.unsqueeze(0)
|
| 118 |
+
|
| 119 |
+
MAX_DURATION = audio.shape[1] / SAMPLE_RATE
|
| 120 |
+
|
| 121 |
+
model_dictionary = align_model_metadata["dictionary"]
|
| 122 |
+
model_lang = align_model_metadata["language"]
|
| 123 |
+
model_type = align_model_metadata["type"]
|
| 124 |
+
|
| 125 |
+
# 1. Preprocess to keep only characters in dictionary
|
| 126 |
+
total_segments = len(transcript)
|
| 127 |
+
for sdx, segment in enumerate(transcript):
|
| 128 |
+
# strip spaces at beginning / end, but keep track of the amount.
|
| 129 |
+
if print_progress:
|
| 130 |
+
base_progress = ((sdx + 1) / total_segments) * 100
|
| 131 |
+
percent_complete = (50 + base_progress / 2) if combined_progress else base_progress
|
| 132 |
+
print(f"Progress: {percent_complete:.2f}%...")
|
| 133 |
+
|
| 134 |
+
num_leading = len(segment["text"]) - len(segment["text"].lstrip())
|
| 135 |
+
num_trailing = len(segment["text"]) - len(segment["text"].rstrip())
|
| 136 |
+
text = segment["text"]
|
| 137 |
+
|
| 138 |
+
# split into words
|
| 139 |
+
if model_lang not in LANGUAGES_WITHOUT_SPACES:
|
| 140 |
+
per_word = text.split(" ")
|
| 141 |
+
else:
|
| 142 |
+
per_word = text
|
| 143 |
+
|
| 144 |
+
clean_char, clean_cdx = [], []
|
| 145 |
+
for cdx, char in enumerate(text):
|
| 146 |
+
char_ = char.lower()
|
| 147 |
+
# wav2vec2 models use "|" character to represent spaces
|
| 148 |
+
if model_lang not in LANGUAGES_WITHOUT_SPACES:
|
| 149 |
+
char_ = char_.replace(" ", "|")
|
| 150 |
+
|
| 151 |
+
# ignore whitespace at beginning and end of transcript
|
| 152 |
+
if cdx < num_leading:
|
| 153 |
+
pass
|
| 154 |
+
elif cdx > len(text) - num_trailing - 1:
|
| 155 |
+
pass
|
| 156 |
+
elif char_ in model_dictionary.keys():
|
| 157 |
+
clean_char.append(char_)
|
| 158 |
+
clean_cdx.append(cdx)
|
| 159 |
+
|
| 160 |
+
clean_wdx = []
|
| 161 |
+
for wdx, wrd in enumerate(per_word):
|
| 162 |
+
if any([c in model_dictionary.keys() for c in wrd]):
|
| 163 |
+
clean_wdx.append(wdx)
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
punkt_param = PunktParameters()
|
| 167 |
+
punkt_param.abbrev_types = set(PUNKT_ABBREVIATIONS)
|
| 168 |
+
sentence_splitter = PunktSentenceTokenizer(punkt_param)
|
| 169 |
+
sentence_spans = list(sentence_splitter.span_tokenize(text))
|
| 170 |
+
|
| 171 |
+
segment["clean_char"] = clean_char
|
| 172 |
+
segment["clean_cdx"] = clean_cdx
|
| 173 |
+
segment["clean_wdx"] = clean_wdx
|
| 174 |
+
segment["sentence_spans"] = sentence_spans
|
| 175 |
+
|
| 176 |
+
aligned_segments: List[SingleAlignedSegment] = []
|
| 177 |
+
|
| 178 |
+
# 2. Get prediction matrix from alignment model & align
|
| 179 |
+
for sdx, segment in enumerate(transcript):
|
| 180 |
+
|
| 181 |
+
t1 = segment["start"]
|
| 182 |
+
t2 = segment["end"]
|
| 183 |
+
text = segment["text"]
|
| 184 |
+
|
| 185 |
+
aligned_seg: SingleAlignedSegment = {
|
| 186 |
+
"start": t1,
|
| 187 |
+
"end": t2,
|
| 188 |
+
"text": text,
|
| 189 |
+
"words": [],
|
| 190 |
+
}
|
| 191 |
+
|
| 192 |
+
if return_char_alignments:
|
| 193 |
+
aligned_seg["chars"] = []
|
| 194 |
+
|
| 195 |
+
# check we can align
|
| 196 |
+
if len(segment["clean_char"]) == 0:
|
| 197 |
+
print(f'Failed to align segment ("{segment["text"]}"): no characters in this segment found in model dictionary, resorting to original...')
|
| 198 |
+
aligned_segments.append(aligned_seg)
|
| 199 |
+
continue
|
| 200 |
+
|
| 201 |
+
if t1 >= MAX_DURATION:
|
| 202 |
+
print(f'Failed to align segment ("{segment["text"]}"): original start time longer than audio duration, skipping...')
|
| 203 |
+
aligned_segments.append(aligned_seg)
|
| 204 |
+
continue
|
| 205 |
+
|
| 206 |
+
text_clean = "".join(segment["clean_char"])
|
| 207 |
+
tokens = [model_dictionary[c] for c in text_clean]
|
| 208 |
+
|
| 209 |
+
f1 = int(t1 * SAMPLE_RATE)
|
| 210 |
+
f2 = int(t2 * SAMPLE_RATE)
|
| 211 |
+
|
| 212 |
+
# TODO: Probably can get some speedup gain with batched inference here
|
| 213 |
+
waveform_segment = audio[:, f1:f2]
|
| 214 |
+
# Handle the minimum input length for wav2vec2 models
|
| 215 |
+
if waveform_segment.shape[-1] < 400:
|
| 216 |
+
lengths = torch.as_tensor([waveform_segment.shape[-1]]).to(device)
|
| 217 |
+
waveform_segment = torch.nn.functional.pad(
|
| 218 |
+
waveform_segment, (0, 400 - waveform_segment.shape[-1])
|
| 219 |
+
)
|
| 220 |
+
else:
|
| 221 |
+
lengths = None
|
| 222 |
+
|
| 223 |
+
with torch.inference_mode():
|
| 224 |
+
if model_type == "torchaudio":
|
| 225 |
+
emissions, _ = model(waveform_segment.to(device), lengths=lengths)
|
| 226 |
+
elif model_type == "huggingface":
|
| 227 |
+
emissions = model(waveform_segment.to(device)).logits
|
| 228 |
+
else:
|
| 229 |
+
raise NotImplementedError(f"Align model of type {model_type} not supported.")
|
| 230 |
+
emissions = torch.log_softmax(emissions, dim=-1)
|
| 231 |
+
|
| 232 |
+
emission = emissions[0].cpu().detach()
|
| 233 |
+
|
| 234 |
+
blank_id = 0
|
| 235 |
+
for char, code in model_dictionary.items():
|
| 236 |
+
if char == '[pad]' or char == '<pad>':
|
| 237 |
+
blank_id = code
|
| 238 |
+
|
| 239 |
+
trellis = get_trellis(emission, tokens, blank_id)
|
| 240 |
+
path = backtrack(trellis, emission, tokens, blank_id)
|
| 241 |
+
|
| 242 |
+
if path is None:
|
| 243 |
+
print(f'Failed to align segment ("{segment["text"]}"): backtrack failed, resorting to original...')
|
| 244 |
+
aligned_segments.append(aligned_seg)
|
| 245 |
+
continue
|
| 246 |
+
|
| 247 |
+
char_segments = merge_repeats(path, text_clean)
|
| 248 |
+
|
| 249 |
+
duration = t2 -t1
|
| 250 |
+
ratio = duration * waveform_segment.size(0) / (trellis.size(0) - 1)
|
| 251 |
+
|
| 252 |
+
# assign timestamps to aligned characters
|
| 253 |
+
char_segments_arr = []
|
| 254 |
+
word_idx = 0
|
| 255 |
+
for cdx, char in enumerate(text):
|
| 256 |
+
start, end, score = None, None, None
|
| 257 |
+
if cdx in segment["clean_cdx"]:
|
| 258 |
+
char_seg = char_segments[segment["clean_cdx"].index(cdx)]
|
| 259 |
+
start = round(char_seg.start * ratio + t1, 3)
|
| 260 |
+
end = round(char_seg.end * ratio + t1, 3)
|
| 261 |
+
score = round(char_seg.score, 3)
|
| 262 |
+
|
| 263 |
+
char_segments_arr.append(
|
| 264 |
+
{
|
| 265 |
+
"char": char,
|
| 266 |
+
"start": start,
|
| 267 |
+
"end": end,
|
| 268 |
+
"score": score,
|
| 269 |
+
"word-idx": word_idx,
|
| 270 |
+
}
|
| 271 |
+
)
|
| 272 |
+
|
| 273 |
+
# increment word_idx, nltk word tokenization would probably be more robust here, but us space for now...
|
| 274 |
+
if model_lang in LANGUAGES_WITHOUT_SPACES:
|
| 275 |
+
word_idx += 1
|
| 276 |
+
elif cdx == len(text) - 1 or text[cdx+1] == " ":
|
| 277 |
+
word_idx += 1
|
| 278 |
+
|
| 279 |
+
char_segments_arr = pd.DataFrame(char_segments_arr)
|
| 280 |
+
|
| 281 |
+
aligned_subsegments = []
|
| 282 |
+
# assign sentence_idx to each character index
|
| 283 |
+
char_segments_arr["sentence-idx"] = None
|
| 284 |
+
for sdx, (sstart, send) in enumerate(segment["sentence_spans"]):
|
| 285 |
+
curr_chars = char_segments_arr.loc[(char_segments_arr.index >= sstart) & (char_segments_arr.index <= send)]
|
| 286 |
+
char_segments_arr.loc[(char_segments_arr.index >= sstart) & (char_segments_arr.index <= send), "sentence-idx"] = sdx
|
| 287 |
+
|
| 288 |
+
sentence_text = text[sstart:send]
|
| 289 |
+
sentence_start = curr_chars["start"].min()
|
| 290 |
+
end_chars = curr_chars[curr_chars["char"] != ' ']
|
| 291 |
+
sentence_end = end_chars["end"].max()
|
| 292 |
+
sentence_words = []
|
| 293 |
+
|
| 294 |
+
for word_idx in curr_chars["word-idx"].unique():
|
| 295 |
+
word_chars = curr_chars.loc[curr_chars["word-idx"] == word_idx]
|
| 296 |
+
word_text = "".join(word_chars["char"].tolist()).strip()
|
| 297 |
+
if len(word_text) == 0:
|
| 298 |
+
continue
|
| 299 |
+
|
| 300 |
+
# dont use space character for alignment
|
| 301 |
+
word_chars = word_chars[word_chars["char"] != " "]
|
| 302 |
+
|
| 303 |
+
word_start = word_chars["start"].min()
|
| 304 |
+
word_end = word_chars["end"].max()
|
| 305 |
+
word_score = round(word_chars["score"].mean(), 3)
|
| 306 |
+
|
| 307 |
+
# -1 indicates unalignable
|
| 308 |
+
word_segment = {"word": word_text}
|
| 309 |
+
|
| 310 |
+
if not np.isnan(word_start):
|
| 311 |
+
word_segment["start"] = word_start
|
| 312 |
+
if not np.isnan(word_end):
|
| 313 |
+
word_segment["end"] = word_end
|
| 314 |
+
if not np.isnan(word_score):
|
| 315 |
+
word_segment["score"] = word_score
|
| 316 |
+
|
| 317 |
+
sentence_words.append(word_segment)
|
| 318 |
+
|
| 319 |
+
aligned_subsegments.append({
|
| 320 |
+
"text": sentence_text,
|
| 321 |
+
"start": sentence_start,
|
| 322 |
+
"end": sentence_end,
|
| 323 |
+
"words": sentence_words,
|
| 324 |
+
})
|
| 325 |
+
|
| 326 |
+
if return_char_alignments:
|
| 327 |
+
curr_chars = curr_chars[["char", "start", "end", "score"]]
|
| 328 |
+
curr_chars.fillna(-1, inplace=True)
|
| 329 |
+
curr_chars = curr_chars.to_dict("records")
|
| 330 |
+
curr_chars = [{key: val for key, val in char.items() if val != -1} for char in curr_chars]
|
| 331 |
+
aligned_subsegments[-1]["chars"] = curr_chars
|
| 332 |
+
|
| 333 |
+
aligned_subsegments = pd.DataFrame(aligned_subsegments)
|
| 334 |
+
aligned_subsegments["start"] = interpolate_nans(aligned_subsegments["start"], method=interpolate_method)
|
| 335 |
+
aligned_subsegments["end"] = interpolate_nans(aligned_subsegments["end"], method=interpolate_method)
|
| 336 |
+
# concatenate sentences with same timestamps
|
| 337 |
+
agg_dict = {"text": " ".join, "words": "sum"}
|
| 338 |
+
if model_lang in LANGUAGES_WITHOUT_SPACES:
|
| 339 |
+
agg_dict["text"] = "".join
|
| 340 |
+
if return_char_alignments:
|
| 341 |
+
agg_dict["chars"] = "sum"
|
| 342 |
+
aligned_subsegments= aligned_subsegments.groupby(["start", "end"], as_index=False).agg(agg_dict)
|
| 343 |
+
aligned_subsegments = aligned_subsegments.to_dict('records')
|
| 344 |
+
aligned_segments += aligned_subsegments
|
| 345 |
+
|
| 346 |
+
# create word_segments list
|
| 347 |
+
word_segments: List[SingleWordSegment] = []
|
| 348 |
+
for segment in aligned_segments:
|
| 349 |
+
word_segments += segment["words"]
|
| 350 |
+
|
| 351 |
+
return {"segments": aligned_segments, "word_segments": word_segments}
|
| 352 |
+
|
| 353 |
+
"""
|
| 354 |
+
source: https://pytorch.org/tutorials/intermediate/forced_alignment_with_torchaudio_tutorial.html
|
| 355 |
+
"""
|
| 356 |
+
def get_trellis(emission, tokens, blank_id=0):
|
| 357 |
+
num_frame = emission.size(0)
|
| 358 |
+
num_tokens = len(tokens)
|
| 359 |
+
|
| 360 |
+
# Trellis has extra diemsions for both time axis and tokens.
|
| 361 |
+
# The extra dim for tokens represents <SoS> (start-of-sentence)
|
| 362 |
+
# The extra dim for time axis is for simplification of the code.
|
| 363 |
+
trellis = torch.empty((num_frame + 1, num_tokens + 1))
|
| 364 |
+
trellis[0, 0] = 0
|
| 365 |
+
trellis[1:, 0] = torch.cumsum(emission[:, 0], 0)
|
| 366 |
+
trellis[0, -num_tokens:] = -float("inf")
|
| 367 |
+
trellis[-num_tokens:, 0] = float("inf")
|
| 368 |
+
|
| 369 |
+
for t in range(num_frame):
|
| 370 |
+
trellis[t + 1, 1:] = torch.maximum(
|
| 371 |
+
# Score for staying at the same token
|
| 372 |
+
trellis[t, 1:] + emission[t, blank_id],
|
| 373 |
+
# Score for changing to the next token
|
| 374 |
+
trellis[t, :-1] + emission[t, tokens],
|
| 375 |
+
)
|
| 376 |
+
return trellis
|
| 377 |
+
|
| 378 |
+
@dataclass
|
| 379 |
+
class Point:
|
| 380 |
+
token_index: int
|
| 381 |
+
time_index: int
|
| 382 |
+
score: float
|
| 383 |
+
|
| 384 |
+
def backtrack(trellis, emission, tokens, blank_id=0):
|
| 385 |
+
# Note:
|
| 386 |
+
# j and t are indices for trellis, which has extra dimensions
|
| 387 |
+
# for time and tokens at the beginning.
|
| 388 |
+
# When referring to time frame index `T` in trellis,
|
| 389 |
+
# the corresponding index in emission is `T-1`.
|
| 390 |
+
# Similarly, when referring to token index `J` in trellis,
|
| 391 |
+
# the corresponding index in transcript is `J-1`.
|
| 392 |
+
j = trellis.size(1) - 1
|
| 393 |
+
t_start = torch.argmax(trellis[:, j]).item()
|
| 394 |
+
|
| 395 |
+
path = []
|
| 396 |
+
for t in range(t_start, 0, -1):
|
| 397 |
+
# 1. Figure out if the current position was stay or change
|
| 398 |
+
# Note (again):
|
| 399 |
+
# `emission[J-1]` is the emission at time frame `J` of trellis dimension.
|
| 400 |
+
# Score for token staying the same from time frame J-1 to T.
|
| 401 |
+
stayed = trellis[t - 1, j] + emission[t - 1, blank_id]
|
| 402 |
+
# Score for token changing from C-1 at T-1 to J at T.
|
| 403 |
+
changed = trellis[t - 1, j - 1] + emission[t - 1, tokens[j - 1]]
|
| 404 |
+
|
| 405 |
+
# 2. Store the path with frame-wise probability.
|
| 406 |
+
prob = emission[t - 1, tokens[j - 1] if changed > stayed else 0].exp().item()
|
| 407 |
+
# Return token index and time index in non-trellis coordinate.
|
| 408 |
+
path.append(Point(j - 1, t - 1, prob))
|
| 409 |
+
|
| 410 |
+
# 3. Update the token
|
| 411 |
+
if changed > stayed:
|
| 412 |
+
j -= 1
|
| 413 |
+
if j == 0:
|
| 414 |
+
break
|
| 415 |
+
else:
|
| 416 |
+
# failed
|
| 417 |
+
return None
|
| 418 |
+
return path[::-1]
|
| 419 |
+
|
| 420 |
+
# Merge the labels
|
| 421 |
+
@dataclass
|
| 422 |
+
class Segment:
|
| 423 |
+
label: str
|
| 424 |
+
start: int
|
| 425 |
+
end: int
|
| 426 |
+
score: float
|
| 427 |
+
|
| 428 |
+
def __repr__(self):
|
| 429 |
+
return f"{self.label}\t({self.score:4.2f}): [{self.start:5d}, {self.end:5d})"
|
| 430 |
+
|
| 431 |
+
@property
|
| 432 |
+
def length(self):
|
| 433 |
+
return self.end - self.start
|
| 434 |
+
|
| 435 |
+
def merge_repeats(path, transcript):
|
| 436 |
+
i1, i2 = 0, 0
|
| 437 |
+
segments = []
|
| 438 |
+
while i1 < len(path):
|
| 439 |
+
while i2 < len(path) and path[i1].token_index == path[i2].token_index:
|
| 440 |
+
i2 += 1
|
| 441 |
+
score = sum(path[k].score for k in range(i1, i2)) / (i2 - i1)
|
| 442 |
+
segments.append(
|
| 443 |
+
Segment(
|
| 444 |
+
transcript[path[i1].token_index],
|
| 445 |
+
path[i1].time_index,
|
| 446 |
+
path[i2 - 1].time_index + 1,
|
| 447 |
+
score,
|
| 448 |
+
)
|
| 449 |
+
)
|
| 450 |
+
i1 = i2
|
| 451 |
+
return segments
|
| 452 |
+
|
| 453 |
+
def merge_words(segments, separator="|"):
|
| 454 |
+
words = []
|
| 455 |
+
i1, i2 = 0, 0
|
| 456 |
+
while i1 < len(segments):
|
| 457 |
+
if i2 >= len(segments) or segments[i2].label == separator:
|
| 458 |
+
if i1 != i2:
|
| 459 |
+
segs = segments[i1:i2]
|
| 460 |
+
word = "".join([seg.label for seg in segs])
|
| 461 |
+
score = sum(seg.score * seg.length for seg in segs) / sum(seg.length for seg in segs)
|
| 462 |
+
words.append(Segment(word, segments[i1].start, segments[i2 - 1].end, score))
|
| 463 |
+
i1 = i2 + 1
|
| 464 |
+
i2 = i1
|
| 465 |
+
else:
|
| 466 |
+
i2 += 1
|
| 467 |
+
return words
|
whisperx/asr.py
ADDED
|
@@ -0,0 +1,357 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import warnings
|
| 3 |
+
from typing import List, Union, Optional, NamedTuple
|
| 4 |
+
|
| 5 |
+
import ctranslate2
|
| 6 |
+
import faster_whisper
|
| 7 |
+
import numpy as np
|
| 8 |
+
import torch
|
| 9 |
+
from transformers import Pipeline
|
| 10 |
+
from transformers.pipelines.pt_utils import PipelineIterator
|
| 11 |
+
|
| 12 |
+
from .audio import N_SAMPLES, SAMPLE_RATE, load_audio, log_mel_spectrogram
|
| 13 |
+
from .vad import load_vad_model, merge_chunks
|
| 14 |
+
from .types import TranscriptionResult, SingleSegment
|
| 15 |
+
|
| 16 |
+
def find_numeral_symbol_tokens(tokenizer):
|
| 17 |
+
numeral_symbol_tokens = []
|
| 18 |
+
for i in range(tokenizer.eot):
|
| 19 |
+
token = tokenizer.decode([i]).removeprefix(" ")
|
| 20 |
+
has_numeral_symbol = any(c in "0123456789%$£" for c in token)
|
| 21 |
+
if has_numeral_symbol:
|
| 22 |
+
numeral_symbol_tokens.append(i)
|
| 23 |
+
return numeral_symbol_tokens
|
| 24 |
+
|
| 25 |
+
class WhisperModel(faster_whisper.WhisperModel):
|
| 26 |
+
'''
|
| 27 |
+
FasterWhisperModel provides batched inference for faster-whisper.
|
| 28 |
+
Currently only works in non-timestamp mode and fixed prompt for all samples in batch.
|
| 29 |
+
'''
|
| 30 |
+
|
| 31 |
+
def generate_segment_batched(self, features: np.ndarray, tokenizer: faster_whisper.tokenizer.Tokenizer, options: faster_whisper.transcribe.TranscriptionOptions, encoder_output = None):
|
| 32 |
+
batch_size = features.shape[0]
|
| 33 |
+
all_tokens = []
|
| 34 |
+
prompt_reset_since = 0
|
| 35 |
+
if options.initial_prompt is not None:
|
| 36 |
+
initial_prompt = " " + options.initial_prompt.strip()
|
| 37 |
+
initial_prompt_tokens = tokenizer.encode(initial_prompt)
|
| 38 |
+
all_tokens.extend(initial_prompt_tokens)
|
| 39 |
+
previous_tokens = all_tokens[prompt_reset_since:]
|
| 40 |
+
prompt = self.get_prompt(
|
| 41 |
+
tokenizer,
|
| 42 |
+
previous_tokens,
|
| 43 |
+
without_timestamps=options.without_timestamps,
|
| 44 |
+
prefix=options.prefix,
|
| 45 |
+
)
|
| 46 |
+
|
| 47 |
+
encoder_output = self.encode(features)
|
| 48 |
+
|
| 49 |
+
max_initial_timestamp_index = int(
|
| 50 |
+
round(options.max_initial_timestamp / self.time_precision)
|
| 51 |
+
)
|
| 52 |
+
|
| 53 |
+
result = self.model.generate(
|
| 54 |
+
encoder_output,
|
| 55 |
+
[prompt] * batch_size,
|
| 56 |
+
beam_size=options.beam_size,
|
| 57 |
+
patience=options.patience,
|
| 58 |
+
length_penalty=options.length_penalty,
|
| 59 |
+
max_length=self.max_length,
|
| 60 |
+
suppress_blank=options.suppress_blank,
|
| 61 |
+
suppress_tokens=options.suppress_tokens,
|
| 62 |
+
)
|
| 63 |
+
|
| 64 |
+
tokens_batch = [x.sequences_ids[0] for x in result]
|
| 65 |
+
|
| 66 |
+
def decode_batch(tokens: List[List[int]]) -> str:
|
| 67 |
+
res = []
|
| 68 |
+
for tk in tokens:
|
| 69 |
+
res.append([token for token in tk if token < tokenizer.eot])
|
| 70 |
+
# text_tokens = [token for token in tokens if token < self.eot]
|
| 71 |
+
return tokenizer.tokenizer.decode_batch(res)
|
| 72 |
+
|
| 73 |
+
text = decode_batch(tokens_batch)
|
| 74 |
+
|
| 75 |
+
return text
|
| 76 |
+
|
| 77 |
+
def encode(self, features: np.ndarray) -> ctranslate2.StorageView:
|
| 78 |
+
# When the model is running on multiple GPUs, the encoder output should be moved
|
| 79 |
+
# to the CPU since we don't know which GPU will handle the next job.
|
| 80 |
+
to_cpu = self.model.device == "cuda" and len(self.model.device_index) > 1
|
| 81 |
+
# unsqueeze if batch size = 1
|
| 82 |
+
if len(features.shape) == 2:
|
| 83 |
+
features = np.expand_dims(features, 0)
|
| 84 |
+
features = faster_whisper.transcribe.get_ctranslate2_storage(features)
|
| 85 |
+
|
| 86 |
+
return self.model.encode(features, to_cpu=to_cpu)
|
| 87 |
+
|
| 88 |
+
class FasterWhisperPipeline(Pipeline):
|
| 89 |
+
"""
|
| 90 |
+
Huggingface Pipeline wrapper for FasterWhisperModel.
|
| 91 |
+
"""
|
| 92 |
+
# TODO:
|
| 93 |
+
# - add support for timestamp mode
|
| 94 |
+
# - add support for custom inference kwargs
|
| 95 |
+
|
| 96 |
+
def __init__(
|
| 97 |
+
self,
|
| 98 |
+
model,
|
| 99 |
+
vad,
|
| 100 |
+
vad_params: dict,
|
| 101 |
+
options : NamedTuple,
|
| 102 |
+
tokenizer=None,
|
| 103 |
+
device: Union[int, str, "torch.device"] = -1,
|
| 104 |
+
framework = "pt",
|
| 105 |
+
language : Optional[str] = None,
|
| 106 |
+
suppress_numerals: bool = False,
|
| 107 |
+
**kwargs
|
| 108 |
+
):
|
| 109 |
+
self.model = model
|
| 110 |
+
self.tokenizer = tokenizer
|
| 111 |
+
self.options = options
|
| 112 |
+
self.preset_language = language
|
| 113 |
+
self.suppress_numerals = suppress_numerals
|
| 114 |
+
self._batch_size = kwargs.pop("batch_size", None)
|
| 115 |
+
self._num_workers = 1
|
| 116 |
+
self._preprocess_params, self._forward_params, self._postprocess_params = self._sanitize_parameters(**kwargs)
|
| 117 |
+
self.call_count = 0
|
| 118 |
+
self.framework = framework
|
| 119 |
+
if self.framework == "pt":
|
| 120 |
+
if isinstance(device, torch.device):
|
| 121 |
+
self.device = device
|
| 122 |
+
elif isinstance(device, str):
|
| 123 |
+
self.device = torch.device(device)
|
| 124 |
+
elif device < 0:
|
| 125 |
+
self.device = torch.device("cpu")
|
| 126 |
+
else:
|
| 127 |
+
self.device = torch.device(f"cuda:{device}")
|
| 128 |
+
else:
|
| 129 |
+
self.device = device
|
| 130 |
+
|
| 131 |
+
super(Pipeline, self).__init__()
|
| 132 |
+
self.vad_model = vad
|
| 133 |
+
self._vad_params = vad_params
|
| 134 |
+
|
| 135 |
+
def _sanitize_parameters(self, **kwargs):
|
| 136 |
+
preprocess_kwargs = {}
|
| 137 |
+
if "tokenizer" in kwargs:
|
| 138 |
+
preprocess_kwargs["maybe_arg"] = kwargs["maybe_arg"]
|
| 139 |
+
return preprocess_kwargs, {}, {}
|
| 140 |
+
|
| 141 |
+
def preprocess(self, audio):
|
| 142 |
+
audio = audio['inputs']
|
| 143 |
+
model_n_mels = self.model.feat_kwargs.get("feature_size")
|
| 144 |
+
features = log_mel_spectrogram(
|
| 145 |
+
audio,
|
| 146 |
+
n_mels=model_n_mels if model_n_mels is not None else 80,
|
| 147 |
+
padding=N_SAMPLES - audio.shape[0],
|
| 148 |
+
)
|
| 149 |
+
return {'inputs': features}
|
| 150 |
+
|
| 151 |
+
def _forward(self, model_inputs):
|
| 152 |
+
outputs = self.model.generate_segment_batched(model_inputs['inputs'], self.tokenizer, self.options)
|
| 153 |
+
return {'text': outputs}
|
| 154 |
+
|
| 155 |
+
def postprocess(self, model_outputs):
|
| 156 |
+
return model_outputs
|
| 157 |
+
|
| 158 |
+
def get_iterator(
|
| 159 |
+
self, inputs, num_workers: int, batch_size: int, preprocess_params, forward_params, postprocess_params
|
| 160 |
+
):
|
| 161 |
+
dataset = PipelineIterator(inputs, self.preprocess, preprocess_params)
|
| 162 |
+
if "TOKENIZERS_PARALLELISM" not in os.environ:
|
| 163 |
+
os.environ["TOKENIZERS_PARALLELISM"] = "false"
|
| 164 |
+
# TODO hack by collating feature_extractor and image_processor
|
| 165 |
+
|
| 166 |
+
def stack(items):
|
| 167 |
+
return {'inputs': torch.stack([x['inputs'] for x in items])}
|
| 168 |
+
dataloader = torch.utils.data.DataLoader(dataset, num_workers=num_workers, batch_size=batch_size, collate_fn=stack)
|
| 169 |
+
model_iterator = PipelineIterator(dataloader, self.forward, forward_params, loader_batch_size=batch_size)
|
| 170 |
+
final_iterator = PipelineIterator(model_iterator, self.postprocess, postprocess_params)
|
| 171 |
+
return final_iterator
|
| 172 |
+
|
| 173 |
+
def transcribe(
|
| 174 |
+
self, audio: Union[str, np.ndarray], batch_size=None, num_workers=0, language=None, task=None, chunk_size=30, print_progress = False, combined_progress=False
|
| 175 |
+
) -> TranscriptionResult:
|
| 176 |
+
if isinstance(audio, str):
|
| 177 |
+
audio = load_audio(audio)
|
| 178 |
+
|
| 179 |
+
def data(audio, segments):
|
| 180 |
+
for seg in segments:
|
| 181 |
+
f1 = int(seg['start'] * SAMPLE_RATE)
|
| 182 |
+
f2 = int(seg['end'] * SAMPLE_RATE)
|
| 183 |
+
# print(f2-f1)
|
| 184 |
+
yield {'inputs': audio[f1:f2]}
|
| 185 |
+
|
| 186 |
+
vad_segments = self.vad_model({"waveform": torch.from_numpy(audio).unsqueeze(0), "sample_rate": SAMPLE_RATE})
|
| 187 |
+
vad_segments = merge_chunks(
|
| 188 |
+
vad_segments,
|
| 189 |
+
chunk_size,
|
| 190 |
+
onset=self._vad_params["vad_onset"],
|
| 191 |
+
offset=self._vad_params["vad_offset"],
|
| 192 |
+
)
|
| 193 |
+
if self.tokenizer is None:
|
| 194 |
+
language = language or self.detect_language(audio)
|
| 195 |
+
task = task or "transcribe"
|
| 196 |
+
self.tokenizer = faster_whisper.tokenizer.Tokenizer(self.model.hf_tokenizer,
|
| 197 |
+
self.model.model.is_multilingual, task=task,
|
| 198 |
+
language=language)
|
| 199 |
+
else:
|
| 200 |
+
language = language or self.tokenizer.language_code
|
| 201 |
+
task = task or self.tokenizer.task
|
| 202 |
+
if task != self.tokenizer.task or language != self.tokenizer.language_code:
|
| 203 |
+
self.tokenizer = faster_whisper.tokenizer.Tokenizer(self.model.hf_tokenizer,
|
| 204 |
+
self.model.model.is_multilingual, task=task,
|
| 205 |
+
language=language)
|
| 206 |
+
|
| 207 |
+
if self.suppress_numerals:
|
| 208 |
+
previous_suppress_tokens = self.options.suppress_tokens
|
| 209 |
+
numeral_symbol_tokens = find_numeral_symbol_tokens(self.tokenizer)
|
| 210 |
+
print(f"Suppressing numeral and symbol tokens")
|
| 211 |
+
new_suppressed_tokens = numeral_symbol_tokens + self.options.suppress_tokens
|
| 212 |
+
new_suppressed_tokens = list(set(new_suppressed_tokens))
|
| 213 |
+
self.options = self.options._replace(suppress_tokens=new_suppressed_tokens)
|
| 214 |
+
|
| 215 |
+
segments: List[SingleSegment] = []
|
| 216 |
+
batch_size = batch_size or self._batch_size
|
| 217 |
+
total_segments = len(vad_segments)
|
| 218 |
+
for idx, out in enumerate(self.__call__(data(audio, vad_segments), batch_size=batch_size, num_workers=num_workers)):
|
| 219 |
+
if print_progress:
|
| 220 |
+
base_progress = ((idx + 1) / total_segments) * 100
|
| 221 |
+
percent_complete = base_progress / 2 if combined_progress else base_progress
|
| 222 |
+
print(f"Progress: {percent_complete:.2f}%...")
|
| 223 |
+
text = out['text']
|
| 224 |
+
if batch_size in [0, 1, None]:
|
| 225 |
+
text = text[0]
|
| 226 |
+
segments.append(
|
| 227 |
+
{
|
| 228 |
+
"text": text,
|
| 229 |
+
"start": round(vad_segments[idx]['start'], 3),
|
| 230 |
+
"end": round(vad_segments[idx]['end'], 3)
|
| 231 |
+
}
|
| 232 |
+
)
|
| 233 |
+
|
| 234 |
+
# revert the tokenizer if multilingual inference is enabled
|
| 235 |
+
if self.preset_language is None:
|
| 236 |
+
self.tokenizer = None
|
| 237 |
+
|
| 238 |
+
# revert suppressed tokens if suppress_numerals is enabled
|
| 239 |
+
if self.suppress_numerals:
|
| 240 |
+
self.options = self.options._replace(suppress_tokens=previous_suppress_tokens)
|
| 241 |
+
|
| 242 |
+
return {"segments": segments, "language": language}
|
| 243 |
+
|
| 244 |
+
|
| 245 |
+
def detect_language(self, audio: np.ndarray):
|
| 246 |
+
if audio.shape[0] < N_SAMPLES:
|
| 247 |
+
print("Warning: audio is shorter than 30s, language detection may be inaccurate.")
|
| 248 |
+
model_n_mels = self.model.feat_kwargs.get("feature_size")
|
| 249 |
+
segment = log_mel_spectrogram(audio[: N_SAMPLES],
|
| 250 |
+
n_mels=model_n_mels if model_n_mels is not None else 80,
|
| 251 |
+
padding=0 if audio.shape[0] >= N_SAMPLES else N_SAMPLES - audio.shape[0])
|
| 252 |
+
encoder_output = self.model.encode(segment)
|
| 253 |
+
results = self.model.model.detect_language(encoder_output)
|
| 254 |
+
language_token, language_probability = results[0][0]
|
| 255 |
+
language = language_token[2:-2]
|
| 256 |
+
print(f"Detected language: {language} ({language_probability:.2f}) in first 30s of audio...")
|
| 257 |
+
return language
|
| 258 |
+
|
| 259 |
+
def load_model(whisper_arch,
|
| 260 |
+
device,
|
| 261 |
+
device_index=0,
|
| 262 |
+
compute_type="float16",
|
| 263 |
+
asr_options=None,
|
| 264 |
+
language : Optional[str] = None,
|
| 265 |
+
vad_model=None,
|
| 266 |
+
vad_options=None,
|
| 267 |
+
model : Optional[WhisperModel] = None,
|
| 268 |
+
task="transcribe",
|
| 269 |
+
download_root=None,
|
| 270 |
+
threads=4):
|
| 271 |
+
'''Load a Whisper model for inference.
|
| 272 |
+
Args:
|
| 273 |
+
whisper_arch: str - The name of the Whisper model to load.
|
| 274 |
+
device: str - The device to load the model on.
|
| 275 |
+
compute_type: str - The compute type to use for the model.
|
| 276 |
+
options: dict - A dictionary of options to use for the model.
|
| 277 |
+
language: str - The language of the model. (use English for now)
|
| 278 |
+
model: Optional[WhisperModel] - The WhisperModel instance to use.
|
| 279 |
+
download_root: Optional[str] - The root directory to download the model to.
|
| 280 |
+
threads: int - The number of cpu threads to use per worker, e.g. will be multiplied by num workers.
|
| 281 |
+
Returns:
|
| 282 |
+
A Whisper pipeline.
|
| 283 |
+
'''
|
| 284 |
+
|
| 285 |
+
if whisper_arch.endswith(".en"):
|
| 286 |
+
language = "en"
|
| 287 |
+
|
| 288 |
+
model = model or WhisperModel(whisper_arch,
|
| 289 |
+
device=device,
|
| 290 |
+
device_index=device_index,
|
| 291 |
+
compute_type=compute_type,
|
| 292 |
+
download_root=download_root,
|
| 293 |
+
cpu_threads=threads)
|
| 294 |
+
if language is not None:
|
| 295 |
+
tokenizer = faster_whisper.tokenizer.Tokenizer(model.hf_tokenizer, model.model.is_multilingual, task=task, language=language)
|
| 296 |
+
else:
|
| 297 |
+
print("No language specified, language will be first be detected for each audio file (increases inference time).")
|
| 298 |
+
tokenizer = None
|
| 299 |
+
|
| 300 |
+
default_asr_options = {
|
| 301 |
+
"beam_size": 5,
|
| 302 |
+
"best_of": 5,
|
| 303 |
+
"patience": 1,
|
| 304 |
+
"length_penalty": 1,
|
| 305 |
+
"repetition_penalty": 1,
|
| 306 |
+
"no_repeat_ngram_size": 0,
|
| 307 |
+
"temperatures": [0.0, 0.2, 0.4, 0.6, 0.8, 1.0],
|
| 308 |
+
"compression_ratio_threshold": 2.4,
|
| 309 |
+
"log_prob_threshold": -1.0,
|
| 310 |
+
"no_speech_threshold": 0.6,
|
| 311 |
+
"condition_on_previous_text": False,
|
| 312 |
+
"prompt_reset_on_temperature": 0.5,
|
| 313 |
+
"initial_prompt": None,
|
| 314 |
+
"prefix": None,
|
| 315 |
+
"suppress_blank": True,
|
| 316 |
+
"suppress_tokens": [-1],
|
| 317 |
+
"without_timestamps": True,
|
| 318 |
+
"max_initial_timestamp": 0.0,
|
| 319 |
+
"word_timestamps": False,
|
| 320 |
+
"prepend_punctuations": "\"'“¿([{-",
|
| 321 |
+
"append_punctuations": "\"'.。,,!!??::”)]}、",
|
| 322 |
+
"suppress_numerals": False,
|
| 323 |
+
"max_new_tokens": None,
|
| 324 |
+
"clip_timestamps": None,
|
| 325 |
+
"hallucination_silence_threshold": None,
|
| 326 |
+
}
|
| 327 |
+
|
| 328 |
+
if asr_options is not None:
|
| 329 |
+
default_asr_options.update(asr_options)
|
| 330 |
+
|
| 331 |
+
suppress_numerals = default_asr_options["suppress_numerals"]
|
| 332 |
+
del default_asr_options["suppress_numerals"]
|
| 333 |
+
|
| 334 |
+
default_asr_options = faster_whisper.transcribe.TranscriptionOptions(**default_asr_options)
|
| 335 |
+
|
| 336 |
+
default_vad_options = {
|
| 337 |
+
"vad_onset": 0.500,
|
| 338 |
+
"vad_offset": 0.363
|
| 339 |
+
}
|
| 340 |
+
|
| 341 |
+
if vad_options is not None:
|
| 342 |
+
default_vad_options.update(vad_options)
|
| 343 |
+
|
| 344 |
+
if vad_model is not None:
|
| 345 |
+
vad_model = vad_model
|
| 346 |
+
else:
|
| 347 |
+
vad_model = load_vad_model(torch.device(device), use_auth_token=None, **default_vad_options)
|
| 348 |
+
|
| 349 |
+
return FasterWhisperPipeline(
|
| 350 |
+
model=model,
|
| 351 |
+
vad=vad_model,
|
| 352 |
+
options=default_asr_options,
|
| 353 |
+
tokenizer=tokenizer,
|
| 354 |
+
language=language,
|
| 355 |
+
suppress_numerals=suppress_numerals,
|
| 356 |
+
vad_params=default_vad_options,
|
| 357 |
+
)
|
whisperx/assets/mel_filters.npz
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7450ae70723a5ef9d341e3cee628c7cb0177f36ce42c44b7ed2bf3325f0f6d4c
|
| 3 |
+
size 4271
|
whisperx/audio.py
ADDED
|
@@ -0,0 +1,159 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import subprocess
|
| 3 |
+
from functools import lru_cache
|
| 4 |
+
from typing import Optional, Union
|
| 5 |
+
|
| 6 |
+
import numpy as np
|
| 7 |
+
import torch
|
| 8 |
+
import torch.nn.functional as F
|
| 9 |
+
|
| 10 |
+
from .utils import exact_div
|
| 11 |
+
|
| 12 |
+
# hard-coded audio hyperparameters
|
| 13 |
+
SAMPLE_RATE = 16000
|
| 14 |
+
N_FFT = 400
|
| 15 |
+
HOP_LENGTH = 160
|
| 16 |
+
CHUNK_LENGTH = 30
|
| 17 |
+
N_SAMPLES = CHUNK_LENGTH * SAMPLE_RATE # 480000 samples in a 30-second chunk
|
| 18 |
+
N_FRAMES = exact_div(N_SAMPLES, HOP_LENGTH) # 3000 frames in a mel spectrogram input
|
| 19 |
+
|
| 20 |
+
N_SAMPLES_PER_TOKEN = HOP_LENGTH * 2 # the initial convolutions has stride 2
|
| 21 |
+
FRAMES_PER_SECOND = exact_div(SAMPLE_RATE, HOP_LENGTH) # 10ms per audio frame
|
| 22 |
+
TOKENS_PER_SECOND = exact_div(SAMPLE_RATE, N_SAMPLES_PER_TOKEN) # 20ms per audio token
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def load_audio(file: str, sr: int = SAMPLE_RATE):
|
| 26 |
+
"""
|
| 27 |
+
Open an audio file and read as mono waveform, resampling as necessary
|
| 28 |
+
|
| 29 |
+
Parameters
|
| 30 |
+
----------
|
| 31 |
+
file: str
|
| 32 |
+
The audio file to open
|
| 33 |
+
|
| 34 |
+
sr: int
|
| 35 |
+
The sample rate to resample the audio if necessary
|
| 36 |
+
|
| 37 |
+
Returns
|
| 38 |
+
-------
|
| 39 |
+
A NumPy array containing the audio waveform, in float32 dtype.
|
| 40 |
+
"""
|
| 41 |
+
try:
|
| 42 |
+
# Launches a subprocess to decode audio while down-mixing and resampling as necessary.
|
| 43 |
+
# Requires the ffmpeg CLI to be installed.
|
| 44 |
+
cmd = [
|
| 45 |
+
"ffmpeg",
|
| 46 |
+
"-nostdin",
|
| 47 |
+
"-threads",
|
| 48 |
+
"0",
|
| 49 |
+
"-i",
|
| 50 |
+
file,
|
| 51 |
+
"-f",
|
| 52 |
+
"s16le",
|
| 53 |
+
"-ac",
|
| 54 |
+
"1",
|
| 55 |
+
"-acodec",
|
| 56 |
+
"pcm_s16le",
|
| 57 |
+
"-ar",
|
| 58 |
+
str(sr),
|
| 59 |
+
"-",
|
| 60 |
+
]
|
| 61 |
+
out = subprocess.run(cmd, capture_output=True, check=True).stdout
|
| 62 |
+
except subprocess.CalledProcessError as e:
|
| 63 |
+
raise RuntimeError(f"Failed to load audio: {e.stderr.decode()}") from e
|
| 64 |
+
|
| 65 |
+
return np.frombuffer(out, np.int16).flatten().astype(np.float32) / 32768.0
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def pad_or_trim(array, length: int = N_SAMPLES, *, axis: int = -1):
|
| 69 |
+
"""
|
| 70 |
+
Pad or trim the audio array to N_SAMPLES, as expected by the encoder.
|
| 71 |
+
"""
|
| 72 |
+
if torch.is_tensor(array):
|
| 73 |
+
if array.shape[axis] > length:
|
| 74 |
+
array = array.index_select(
|
| 75 |
+
dim=axis, index=torch.arange(length, device=array.device)
|
| 76 |
+
)
|
| 77 |
+
|
| 78 |
+
if array.shape[axis] < length:
|
| 79 |
+
pad_widths = [(0, 0)] * array.ndim
|
| 80 |
+
pad_widths[axis] = (0, length - array.shape[axis])
|
| 81 |
+
array = F.pad(array, [pad for sizes in pad_widths[::-1] for pad in sizes])
|
| 82 |
+
else:
|
| 83 |
+
if array.shape[axis] > length:
|
| 84 |
+
array = array.take(indices=range(length), axis=axis)
|
| 85 |
+
|
| 86 |
+
if array.shape[axis] < length:
|
| 87 |
+
pad_widths = [(0, 0)] * array.ndim
|
| 88 |
+
pad_widths[axis] = (0, length - array.shape[axis])
|
| 89 |
+
array = np.pad(array, pad_widths)
|
| 90 |
+
|
| 91 |
+
return array
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
@lru_cache(maxsize=None)
|
| 95 |
+
def mel_filters(device, n_mels: int) -> torch.Tensor:
|
| 96 |
+
"""
|
| 97 |
+
load the mel filterbank matrix for projecting STFT into a Mel spectrogram.
|
| 98 |
+
Allows decoupling librosa dependency; saved using:
|
| 99 |
+
|
| 100 |
+
np.savez_compressed(
|
| 101 |
+
"mel_filters.npz",
|
| 102 |
+
mel_80=librosa.filters.mel(sr=16000, n_fft=400, n_mels=80),
|
| 103 |
+
)
|
| 104 |
+
"""
|
| 105 |
+
assert n_mels in [80, 128], f"Unsupported n_mels: {n_mels}"
|
| 106 |
+
with np.load(
|
| 107 |
+
os.path.join(os.path.dirname(__file__), "assets", "mel_filters.npz")
|
| 108 |
+
) as f:
|
| 109 |
+
return torch.from_numpy(f[f"mel_{n_mels}"]).to(device)
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
def log_mel_spectrogram(
|
| 113 |
+
audio: Union[str, np.ndarray, torch.Tensor],
|
| 114 |
+
n_mels: int,
|
| 115 |
+
padding: int = 0,
|
| 116 |
+
device: Optional[Union[str, torch.device]] = None,
|
| 117 |
+
):
|
| 118 |
+
"""
|
| 119 |
+
Compute the log-Mel spectrogram of
|
| 120 |
+
|
| 121 |
+
Parameters
|
| 122 |
+
----------
|
| 123 |
+
audio: Union[str, np.ndarray, torch.Tensor], shape = (*)
|
| 124 |
+
The path to audio or either a NumPy array or Tensor containing the audio waveform in 16 kHz
|
| 125 |
+
|
| 126 |
+
n_mels: int
|
| 127 |
+
The number of Mel-frequency filters, only 80 is supported
|
| 128 |
+
|
| 129 |
+
padding: int
|
| 130 |
+
Number of zero samples to pad to the right
|
| 131 |
+
|
| 132 |
+
device: Optional[Union[str, torch.device]]
|
| 133 |
+
If given, the audio tensor is moved to this device before STFT
|
| 134 |
+
|
| 135 |
+
Returns
|
| 136 |
+
-------
|
| 137 |
+
torch.Tensor, shape = (80, n_frames)
|
| 138 |
+
A Tensor that contains the Mel spectrogram
|
| 139 |
+
"""
|
| 140 |
+
if not torch.is_tensor(audio):
|
| 141 |
+
if isinstance(audio, str):
|
| 142 |
+
audio = load_audio(audio)
|
| 143 |
+
audio = torch.from_numpy(audio)
|
| 144 |
+
|
| 145 |
+
if device is not None:
|
| 146 |
+
audio = audio.to(device)
|
| 147 |
+
if padding > 0:
|
| 148 |
+
audio = F.pad(audio, (0, padding))
|
| 149 |
+
window = torch.hann_window(N_FFT).to(audio.device)
|
| 150 |
+
stft = torch.stft(audio, N_FFT, HOP_LENGTH, window=window, return_complex=True)
|
| 151 |
+
magnitudes = stft[..., :-1].abs() ** 2
|
| 152 |
+
|
| 153 |
+
filters = mel_filters(audio.device, n_mels)
|
| 154 |
+
mel_spec = filters @ magnitudes
|
| 155 |
+
|
| 156 |
+
log_spec = torch.clamp(mel_spec, min=1e-10).log10()
|
| 157 |
+
log_spec = torch.maximum(log_spec, log_spec.max() - 8.0)
|
| 158 |
+
log_spec = (log_spec + 4.0) / 4.0
|
| 159 |
+
return log_spec
|
whisperx/conjunctions.py
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# conjunctions.py
|
| 2 |
+
|
| 3 |
+
conjunctions_by_language = {
|
| 4 |
+
'en': {'and', 'whether', 'or', 'as', 'but', 'so', 'for', 'nor', 'which', 'yet', 'although', 'since', 'unless', 'when', 'while', 'because', 'if', 'how', 'that', 'than', 'who', 'where', 'what', 'near', 'before', 'after', 'across', 'through', 'until', 'once', 'whereas', 'even', 'both', 'either', 'neither', 'though'},
|
| 5 |
+
'fr': {'et', 'ou', 'mais', 'parce', 'bien', 'pendant', 'quand', 'où', 'comme', 'si', 'que', 'avant', 'après', 'aussitôt', 'jusqu’à', 'à', 'malgré', 'donc', 'tant', 'puisque', 'ni', 'soit', 'bien', 'encore', 'dès', 'lorsque'},
|
| 6 |
+
'de': {'und', 'oder', 'aber', 'weil', 'obwohl', 'während', 'wenn', 'wo', 'wie', 'dass', 'bevor', 'nachdem', 'sobald', 'bis', 'außer', 'trotzdem', 'also', 'sowie', 'indem', 'weder', 'sowohl', 'zwar', 'jedoch'},
|
| 7 |
+
'es': {'y', 'o', 'pero', 'porque', 'aunque', 'sin', 'mientras', 'cuando', 'donde', 'como', 'si', 'que', 'antes', 'después', 'tan', 'hasta', 'a', 'a', 'por', 'ya', 'ni', 'sino'},
|
| 8 |
+
'it': {'e', 'o', 'ma', 'perché', 'anche', 'mentre', 'quando', 'dove', 'come', 'se', 'che', 'prima', 'dopo', 'appena', 'fino', 'a', 'nonostante', 'quindi', 'poiché', 'né', 'ossia', 'cioè'},
|
| 9 |
+
'ja': {'そして', 'または', 'しかし', 'なぜなら', 'もし', 'それとも', 'だから', 'それに', 'なのに', 'そのため', 'かつ', 'それゆえに', 'ならば', 'もしくは', 'ため'},
|
| 10 |
+
'zh': {'和', '或', '但是', '因为', '任何', '也', '虽然', '而且', '所以', '如果', '除非', '尽管', '既然', '即使', '只要', '直到', '然后', '因此', '不但', '而是', '不过'},
|
| 11 |
+
'nl': {'en', 'of', 'maar', 'omdat', 'hoewel', 'terwijl', 'wanneer', 'waar', 'zoals', 'als', 'dat', 'voordat', 'nadat', 'zodra', 'totdat', 'tenzij', 'ondanks', 'dus', 'zowel', 'noch', 'echter', 'toch'},
|
| 12 |
+
'uk': {'та', 'або', 'але', 'тому', 'хоча', 'поки', 'бо', 'коли', 'де', 'як', 'якщо', 'що', 'перш', 'після', 'доки', 'незважаючи', 'тому', 'ані'},
|
| 13 |
+
'pt': {'e', 'ou', 'mas', 'porque', 'embora', 'enquanto', 'quando', 'onde', 'como', 'se', 'que', 'antes', 'depois', 'assim', 'até', 'a', 'apesar', 'portanto', 'já', 'pois', 'nem', 'senão'},
|
| 14 |
+
'ar': {'و', 'أو', 'لكن', 'لأن', 'مع', 'بينما', 'عندما', 'حيث', 'كما', 'إذا', 'الذي', 'قبل', 'بعد', 'فور', 'حتى', 'إلا', 'رغم', 'لذلك', 'بما'},
|
| 15 |
+
'cs': {'a', 'nebo', 'ale', 'protože', 'ačkoli', 'zatímco', 'když', 'kde', 'jako', 'pokud', 'že', 'než', 'poté', 'jakmile', 'dokud', 'pokud ne', 'navzdory', 'tak', 'stejně', 'ani', 'tudíž'},
|
| 16 |
+
'ru': {'и', 'или', 'но', 'потому', 'хотя', 'пока', 'когда', 'где', 'как', 'если', 'что', 'перед', 'после', 'несмотря', 'таким', 'также', 'ни', 'зато'},
|
| 17 |
+
'pl': {'i', 'lub', 'ale', 'ponieważ', 'chociaż', 'podczas', 'kiedy', 'gdzie', 'jak', 'jeśli', 'że', 'zanim', 'po', 'jak tylko', 'dopóki', 'chyba', 'pomimo', 'więc', 'tak', 'ani', 'czyli'},
|
| 18 |
+
'hu': {'és', 'vagy', 'de', 'mert', 'habár', 'míg', 'amikor', 'ahol', 'ahogy', 'ha', 'hogy', 'mielőtt', 'miután', 'amint', 'amíg', 'hacsak', 'ellenére', 'tehát', 'úgy', 'sem', 'vagyis'},
|
| 19 |
+
'fi': {'ja', 'tai', 'mutta', 'koska', 'vaikka', 'kun', 'missä', 'kuten', 'jos', 'että', 'ennen', 'sen jälkeen', 'heti', 'kunnes', 'ellei', 'huolimatta', 'siis', 'sekä', 'eikä', 'vaan'},
|
| 20 |
+
'fa': {'و', 'یا', 'اما', 'چون', 'اگرچه', 'در حالی', 'وقتی', 'کجا', 'چگونه', 'اگر', 'که', 'قبل', 'پس', 'به محض', 'تا زمانی', 'مگر', 'با وجود', 'پس', 'همچنین', 'نه'},
|
| 21 |
+
'el': {'και', 'ή', 'αλλά', 'επειδή', 'αν', 'ενώ', 'όταν', 'όπου', 'όπως', 'αν', 'που', 'προτού', 'αφού', 'μόλις', 'μέχρι', 'εκτός', 'παρά', 'έτσι', 'όπως', 'ούτε', 'δηλαδή'},
|
| 22 |
+
'tr': {'ve', 'veya', 'ama', 'çünkü', 'her ne', 'iken', 'nerede', 'nasıl', 'eğer', 'ki', 'önce', 'sonra', 'hemen', 'kadar', 'rağmen', 'hem', 'ne', 'yani'},
|
| 23 |
+
'da': {'og', 'eller', 'men', 'fordi', 'selvom', 'mens', 'når', 'hvor', 'som', 'hvis', 'at', 'før', 'efter', 'indtil', 'medmindre', 'således', 'ligesom', 'hverken', 'altså'},
|
| 24 |
+
'he': {'ו', 'או', 'אבל', 'כי', 'אף', 'בזמן', 'כאשר', 'היכן', 'כיצד', 'אם', 'ש', 'לפני', 'אחרי', 'ברגע', 'עד', 'אלא', 'למרות', 'לכן', 'כמו', 'לא', 'אז'},
|
| 25 |
+
'vi': {'và', 'hoặc', 'nhưng', 'bởi', 'mặc', 'trong', 'khi', 'ở', 'như', 'nếu', 'rằng', 'trước', 'sau', 'ngay', 'cho', 'trừ', 'mặc', 'vì', 'giống', 'cũng', 'tức'},
|
| 26 |
+
'ko': {'그리고', '또는','그런데','그래도', '이나', '결국', '마지막으로', '마찬가지로', '반면에', '아니면', '거나', '또는', '그럼에도', '그렇기', '때문에', '덧붙이자면', '게다가', '그러나', '고', '그래서', '랑', '한다면', '하지만', '��엇', '왜냐하면', '비록', '동안', '언제', '어디서', '어떻게', '만약', '그', '전에', '후에', '즉시', '까지', '아니라면', '불구하고', '따라서', '같은', '도'},
|
| 27 |
+
'ur': {'اور', 'یا', 'مگر', 'کیونکہ', 'اگرچہ', 'جبکہ', 'جب', 'کہاں', 'کس طرح', 'اگر', 'کہ', 'سے پہلے', 'کے بعد', 'جیسے ہی', 'تک', 'اگر نہیں تو', 'کے باوجود', 'اس لئے', 'جیسے', 'نہ'},
|
| 28 |
+
'hi': {'और', 'या', 'पर', 'तो', 'न', 'फिर', 'हालांकि', 'चूंकि', 'अगर', 'कैसे', 'वह', 'से', 'जो', 'जहां', 'क्या', 'नजदीक', 'पहले', 'बाद', 'के', 'पार', 'माध्यम', 'तक', 'एक', 'जबकि', 'यहां', 'तक', 'दोनों', 'या', 'न', 'हालांकि'}
|
| 29 |
+
|
| 30 |
+
}
|
| 31 |
+
|
| 32 |
+
commas_by_language = {
|
| 33 |
+
'ja': '、',
|
| 34 |
+
'zh': ',',
|
| 35 |
+
'fa': '،',
|
| 36 |
+
'ur': '،'
|
| 37 |
+
}
|
| 38 |
+
|
| 39 |
+
def get_conjunctions(lang_code):
|
| 40 |
+
return conjunctions_by_language.get(lang_code, set())
|
| 41 |
+
|
| 42 |
+
def get_comma(lang_code):
|
| 43 |
+
return commas_by_language.get(lang_code, ',')
|
whisperx/diarize.py
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import pandas as pd
|
| 3 |
+
from pyannote.audio import Pipeline
|
| 4 |
+
from typing import Optional, Union
|
| 5 |
+
import torch
|
| 6 |
+
|
| 7 |
+
from .audio import load_audio, SAMPLE_RATE
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
class DiarizationPipeline:
|
| 11 |
+
def __init__(
|
| 12 |
+
self,
|
| 13 |
+
model_name="pyannote/speaker-diarization-3.1",
|
| 14 |
+
use_auth_token=None,
|
| 15 |
+
device: Optional[Union[str, torch.device]] = "cpu",
|
| 16 |
+
):
|
| 17 |
+
if isinstance(device, str):
|
| 18 |
+
device = torch.device(device)
|
| 19 |
+
self.model = Pipeline.from_pretrained(model_name, use_auth_token=use_auth_token).to(device)
|
| 20 |
+
|
| 21 |
+
def __call__(self, audio: Union[str, np.ndarray], num_speakers=None, min_speakers=None, max_speakers=None):
|
| 22 |
+
if isinstance(audio, str):
|
| 23 |
+
audio = load_audio(audio)
|
| 24 |
+
audio_data = {
|
| 25 |
+
'waveform': torch.from_numpy(audio[None, :]),
|
| 26 |
+
'sample_rate': SAMPLE_RATE
|
| 27 |
+
}
|
| 28 |
+
segments = self.model(audio_data, num_speakers = num_speakers, min_speakers=min_speakers, max_speakers=max_speakers)
|
| 29 |
+
diarize_df = pd.DataFrame(segments.itertracks(yield_label=True), columns=['segment', 'label', 'speaker'])
|
| 30 |
+
diarize_df['start'] = diarize_df['segment'].apply(lambda x: x.start)
|
| 31 |
+
diarize_df['end'] = diarize_df['segment'].apply(lambda x: x.end)
|
| 32 |
+
return diarize_df
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def assign_word_speakers(diarize_df, transcript_result, fill_nearest=False):
|
| 36 |
+
transcript_segments = transcript_result["segments"]
|
| 37 |
+
for seg in transcript_segments:
|
| 38 |
+
# assign speaker to segment (if any)
|
| 39 |
+
diarize_df['intersection'] = np.minimum(diarize_df['end'], seg['end']) - np.maximum(diarize_df['start'], seg['start'])
|
| 40 |
+
diarize_df['union'] = np.maximum(diarize_df['end'], seg['end']) - np.minimum(diarize_df['start'], seg['start'])
|
| 41 |
+
# remove no hit, otherwise we look for closest (even negative intersection...)
|
| 42 |
+
if not fill_nearest:
|
| 43 |
+
dia_tmp = diarize_df[diarize_df['intersection'] > 0]
|
| 44 |
+
else:
|
| 45 |
+
dia_tmp = diarize_df
|
| 46 |
+
if len(dia_tmp) > 0:
|
| 47 |
+
# sum over speakers
|
| 48 |
+
speaker = dia_tmp.groupby("speaker")["intersection"].sum().sort_values(ascending=False).index[0]
|
| 49 |
+
seg["speaker"] = speaker
|
| 50 |
+
|
| 51 |
+
# assign speaker to words
|
| 52 |
+
if 'words' in seg:
|
| 53 |
+
for word in seg['words']:
|
| 54 |
+
if 'start' in word:
|
| 55 |
+
diarize_df['intersection'] = np.minimum(diarize_df['end'], word['end']) - np.maximum(diarize_df['start'], word['start'])
|
| 56 |
+
diarize_df['union'] = np.maximum(diarize_df['end'], word['end']) - np.minimum(diarize_df['start'], word['start'])
|
| 57 |
+
# remove no hit
|
| 58 |
+
if not fill_nearest:
|
| 59 |
+
dia_tmp = diarize_df[diarize_df['intersection'] > 0]
|
| 60 |
+
else:
|
| 61 |
+
dia_tmp = diarize_df
|
| 62 |
+
if len(dia_tmp) > 0:
|
| 63 |
+
# sum over speakers
|
| 64 |
+
speaker = dia_tmp.groupby("speaker")["intersection"].sum().sort_values(ascending=False).index[0]
|
| 65 |
+
word["speaker"] = speaker
|
| 66 |
+
|
| 67 |
+
return transcript_result
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
class Segment:
|
| 71 |
+
def __init__(self, start, end, speaker=None):
|
| 72 |
+
self.start = start
|
| 73 |
+
self.end = end
|
| 74 |
+
self.speaker = speaker
|
whisperx/transcribe.py
ADDED
|
@@ -0,0 +1,230 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import gc
|
| 3 |
+
import os
|
| 4 |
+
import warnings
|
| 5 |
+
|
| 6 |
+
import numpy as np
|
| 7 |
+
import torch
|
| 8 |
+
|
| 9 |
+
from .alignment import align, load_align_model
|
| 10 |
+
from .asr import load_model
|
| 11 |
+
from .audio import load_audio
|
| 12 |
+
from .diarize import DiarizationPipeline, assign_word_speakers
|
| 13 |
+
from .utils import (LANGUAGES, TO_LANGUAGE_CODE, get_writer, optional_float,
|
| 14 |
+
optional_int, str2bool)
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def cli():
|
| 18 |
+
# fmt: off
|
| 19 |
+
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
|
| 20 |
+
parser.add_argument("audio", nargs="+", type=str, help="audio file(s) to transcribe")
|
| 21 |
+
parser.add_argument("--model", default="small", help="name of the Whisper model to use")
|
| 22 |
+
parser.add_argument("--model_dir", type=str, default=None, help="the path to save model files; uses ~/.cache/whisper by default")
|
| 23 |
+
parser.add_argument("--device", default="cuda" if torch.cuda.is_available() else "cpu", help="device to use for PyTorch inference")
|
| 24 |
+
parser.add_argument("--device_index", default=0, type=int, help="device index to use for FasterWhisper inference")
|
| 25 |
+
parser.add_argument("--batch_size", default=8, type=int, help="the preferred batch size for inference")
|
| 26 |
+
parser.add_argument("--compute_type", default="float16", type=str, choices=["float16", "float32", "int8"], help="compute type for computation")
|
| 27 |
+
|
| 28 |
+
parser.add_argument("--output_dir", "-o", type=str, default=".", help="directory to save the outputs")
|
| 29 |
+
parser.add_argument("--output_format", "-f", type=str, default="all", choices=["all", "srt", "vtt", "txt", "tsv", "json", "aud"], help="format of the output file; if not specified, all available formats will be produced")
|
| 30 |
+
parser.add_argument("--verbose", type=str2bool, default=True, help="whether to print out the progress and debug messages")
|
| 31 |
+
|
| 32 |
+
parser.add_argument("--task", type=str, default="transcribe", choices=["transcribe", "translate"], help="whether to perform X->X speech recognition ('transcribe') or X->English translation ('translate')")
|
| 33 |
+
parser.add_argument("--language", type=str, default=None, choices=sorted(LANGUAGES.keys()) + sorted([k.title() for k in TO_LANGUAGE_CODE.keys()]), help="language spoken in the audio, specify None to perform language detection")
|
| 34 |
+
|
| 35 |
+
# alignment params
|
| 36 |
+
parser.add_argument("--align_model", default=None, help="Name of phoneme-level ASR model to do alignment")
|
| 37 |
+
parser.add_argument("--interpolate_method", default="nearest", choices=["nearest", "linear", "ignore"], help="For word .srt, method to assign timestamps to non-aligned words, or merge them into neighbouring.")
|
| 38 |
+
parser.add_argument("--no_align", action='store_true', help="Do not perform phoneme alignment")
|
| 39 |
+
parser.add_argument("--return_char_alignments", action='store_true', help="Return character-level alignments in the output json file")
|
| 40 |
+
|
| 41 |
+
# vad params
|
| 42 |
+
parser.add_argument("--vad_onset", type=float, default=0.500, help="Onset threshold for VAD (see pyannote.audio), reduce this if speech is not being detected")
|
| 43 |
+
parser.add_argument("--vad_offset", type=float, default=0.363, help="Offset threshold for VAD (see pyannote.audio), reduce this if speech is not being detected.")
|
| 44 |
+
parser.add_argument("--chunk_size", type=int, default=30, help="Chunk size for merging VAD segments. Default is 30, reduce this if the chunk is too long.")
|
| 45 |
+
|
| 46 |
+
# diarization params
|
| 47 |
+
parser.add_argument("--diarize", action="store_true", help="Apply diarization to assign speaker labels to each segment/word")
|
| 48 |
+
parser.add_argument("--min_speakers", default=None, type=int, help="Minimum number of speakers to in audio file")
|
| 49 |
+
parser.add_argument("--max_speakers", default=None, type=int, help="Maximum number of speakers to in audio file")
|
| 50 |
+
|
| 51 |
+
parser.add_argument("--temperature", type=float, default=0, help="temperature to use for sampling")
|
| 52 |
+
parser.add_argument("--best_of", type=optional_int, default=5, help="number of candidates when sampling with non-zero temperature")
|
| 53 |
+
parser.add_argument("--beam_size", type=optional_int, default=5, help="number of beams in beam search, only applicable when temperature is zero")
|
| 54 |
+
parser.add_argument("--patience", type=float, default=1.0, help="optional patience value to use in beam decoding, as in https://arxiv.org/abs/2204.05424, the default (1.0) is equivalent to conventional beam search")
|
| 55 |
+
parser.add_argument("--length_penalty", type=float, default=1.0, help="optional token length penalty coefficient (alpha) as in https://arxiv.org/abs/1609.08144, uses simple length normalization by default")
|
| 56 |
+
|
| 57 |
+
parser.add_argument("--suppress_tokens", type=str, default="-1", help="comma-separated list of token ids to suppress during sampling; '-1' will suppress most special characters except common punctuations")
|
| 58 |
+
parser.add_argument("--suppress_numerals", action="store_true", help="whether to suppress numeric symbols and currency symbols during sampling, since wav2vec2 cannot align them correctly")
|
| 59 |
+
|
| 60 |
+
parser.add_argument("--initial_prompt", type=str, default=None, help="optional text to provide as a prompt for the first window.")
|
| 61 |
+
parser.add_argument("--condition_on_previous_text", type=str2bool, default=False, help="if True, provide the previous output of the model as a prompt for the next window; disabling may make the text inconsistent across windows, but the model becomes less prone to getting stuck in a failure loop")
|
| 62 |
+
parser.add_argument("--fp16", type=str2bool, default=True, help="whether to perform inference in fp16; True by default")
|
| 63 |
+
|
| 64 |
+
parser.add_argument("--temperature_increment_on_fallback", type=optional_float, default=0.2, help="temperature to increase when falling back when the decoding fails to meet either of the thresholds below")
|
| 65 |
+
parser.add_argument("--compression_ratio_threshold", type=optional_float, default=2.4, help="if the gzip compression ratio is higher than this value, treat the decoding as failed")
|
| 66 |
+
parser.add_argument("--logprob_threshold", type=optional_float, default=-1.0, help="if the average log probability is lower than this value, treat the decoding as failed")
|
| 67 |
+
parser.add_argument("--no_speech_threshold", type=optional_float, default=0.6, help="if the probability of the <|nospeech|> token is higher than this value AND the decoding has failed due to `logprob_threshold`, consider the segment as silence")
|
| 68 |
+
|
| 69 |
+
parser.add_argument("--max_line_width", type=optional_int, default=None, help="(not possible with --no_align) the maximum number of characters in a line before breaking the line")
|
| 70 |
+
parser.add_argument("--max_line_count", type=optional_int, default=None, help="(not possible with --no_align) the maximum number of lines in a segment")
|
| 71 |
+
parser.add_argument("--highlight_words", type=str2bool, default=False, help="(not possible with --no_align) underline each word as it is spoken in srt and vtt")
|
| 72 |
+
parser.add_argument("--segment_resolution", type=str, default="sentence", choices=["sentence", "chunk"], help="(not possible with --no_align) the maximum number of characters in a line before breaking the line")
|
| 73 |
+
|
| 74 |
+
parser.add_argument("--threads", type=optional_int, default=0, help="number of threads used by torch for CPU inference; supercedes MKL_NUM_THREADS/OMP_NUM_THREADS")
|
| 75 |
+
|
| 76 |
+
parser.add_argument("--hf_token", type=str, default=None, help="Hugging Face Access Token to access PyAnnote gated models")
|
| 77 |
+
|
| 78 |
+
parser.add_argument("--print_progress", type=str2bool, default = False, help = "if True, progress will be printed in transcribe() and align() methods.")
|
| 79 |
+
# fmt: on
|
| 80 |
+
|
| 81 |
+
args = parser.parse_args().__dict__
|
| 82 |
+
model_name: str = args.pop("model")
|
| 83 |
+
batch_size: int = args.pop("batch_size")
|
| 84 |
+
model_dir: str = args.pop("model_dir")
|
| 85 |
+
output_dir: str = args.pop("output_dir")
|
| 86 |
+
output_format: str = args.pop("output_format")
|
| 87 |
+
device: str = args.pop("device")
|
| 88 |
+
device_index: int = args.pop("device_index")
|
| 89 |
+
compute_type: str = args.pop("compute_type")
|
| 90 |
+
|
| 91 |
+
# model_flush: bool = args.pop("model_flush")
|
| 92 |
+
os.makedirs(output_dir, exist_ok=True)
|
| 93 |
+
|
| 94 |
+
align_model: str = args.pop("align_model")
|
| 95 |
+
interpolate_method: str = args.pop("interpolate_method")
|
| 96 |
+
no_align: bool = args.pop("no_align")
|
| 97 |
+
task : str = args.pop("task")
|
| 98 |
+
if task == "translate":
|
| 99 |
+
# translation cannot be aligned
|
| 100 |
+
no_align = True
|
| 101 |
+
|
| 102 |
+
return_char_alignments: bool = args.pop("return_char_alignments")
|
| 103 |
+
|
| 104 |
+
hf_token: str = args.pop("hf_token")
|
| 105 |
+
vad_onset: float = args.pop("vad_onset")
|
| 106 |
+
vad_offset: float = args.pop("vad_offset")
|
| 107 |
+
|
| 108 |
+
chunk_size: int = args.pop("chunk_size")
|
| 109 |
+
|
| 110 |
+
diarize: bool = args.pop("diarize")
|
| 111 |
+
min_speakers: int = args.pop("min_speakers")
|
| 112 |
+
max_speakers: int = args.pop("max_speakers")
|
| 113 |
+
print_progress: bool = args.pop("print_progress")
|
| 114 |
+
|
| 115 |
+
if args["language"] is not None:
|
| 116 |
+
args["language"] = args["language"].lower()
|
| 117 |
+
if args["language"] not in LANGUAGES:
|
| 118 |
+
if args["language"] in TO_LANGUAGE_CODE:
|
| 119 |
+
args["language"] = TO_LANGUAGE_CODE[args["language"]]
|
| 120 |
+
else:
|
| 121 |
+
raise ValueError(f"Unsupported language: {args['language']}")
|
| 122 |
+
|
| 123 |
+
if model_name.endswith(".en") and args["language"] != "en":
|
| 124 |
+
if args["language"] is not None:
|
| 125 |
+
warnings.warn(
|
| 126 |
+
f"{model_name} is an English-only model but received '{args['language']}'; using English instead."
|
| 127 |
+
)
|
| 128 |
+
args["language"] = "en"
|
| 129 |
+
align_language = args["language"] if args["language"] is not None else "en" # default to loading english if not specified
|
| 130 |
+
|
| 131 |
+
temperature = args.pop("temperature")
|
| 132 |
+
if (increment := args.pop("temperature_increment_on_fallback")) is not None:
|
| 133 |
+
temperature = tuple(np.arange(temperature, 1.0 + 1e-6, increment))
|
| 134 |
+
else:
|
| 135 |
+
temperature = [temperature]
|
| 136 |
+
|
| 137 |
+
faster_whisper_threads = 4
|
| 138 |
+
if (threads := args.pop("threads")) > 0:
|
| 139 |
+
torch.set_num_threads(threads)
|
| 140 |
+
faster_whisper_threads = threads
|
| 141 |
+
|
| 142 |
+
asr_options = {
|
| 143 |
+
"beam_size": args.pop("beam_size"),
|
| 144 |
+
"patience": args.pop("patience"),
|
| 145 |
+
"length_penalty": args.pop("length_penalty"),
|
| 146 |
+
"temperatures": temperature,
|
| 147 |
+
"compression_ratio_threshold": args.pop("compression_ratio_threshold"),
|
| 148 |
+
"log_prob_threshold": args.pop("logprob_threshold"),
|
| 149 |
+
"no_speech_threshold": args.pop("no_speech_threshold"),
|
| 150 |
+
"condition_on_previous_text": False,
|
| 151 |
+
"initial_prompt": args.pop("initial_prompt"),
|
| 152 |
+
"suppress_tokens": [int(x) for x in args.pop("suppress_tokens").split(",")],
|
| 153 |
+
"suppress_numerals": args.pop("suppress_numerals"),
|
| 154 |
+
}
|
| 155 |
+
|
| 156 |
+
writer = get_writer(output_format, output_dir)
|
| 157 |
+
word_options = ["highlight_words", "max_line_count", "max_line_width"]
|
| 158 |
+
if no_align:
|
| 159 |
+
for option in word_options:
|
| 160 |
+
if args[option]:
|
| 161 |
+
parser.error(f"--{option} not possible with --no_align")
|
| 162 |
+
if args["max_line_count"] and not args["max_line_width"]:
|
| 163 |
+
warnings.warn("--max_line_count has no effect without --max_line_width")
|
| 164 |
+
writer_args = {arg: args.pop(arg) for arg in word_options}
|
| 165 |
+
|
| 166 |
+
# Part 1: VAD & ASR Loop
|
| 167 |
+
results = []
|
| 168 |
+
tmp_results = []
|
| 169 |
+
# model = load_model(model_name, device=device, download_root=model_dir)
|
| 170 |
+
model = load_model(model_name, device=device, device_index=device_index, download_root=model_dir, compute_type=compute_type, language=args['language'], asr_options=asr_options, vad_options={"vad_onset": vad_onset, "vad_offset": vad_offset}, task=task, threads=faster_whisper_threads)
|
| 171 |
+
|
| 172 |
+
for audio_path in args.pop("audio"):
|
| 173 |
+
audio = load_audio(audio_path)
|
| 174 |
+
# >> VAD & ASR
|
| 175 |
+
print(">>Performing transcription...")
|
| 176 |
+
result = model.transcribe(audio, batch_size=batch_size, chunk_size=chunk_size, print_progress=print_progress)
|
| 177 |
+
results.append((result, audio_path))
|
| 178 |
+
|
| 179 |
+
# Unload Whisper and VAD
|
| 180 |
+
del model
|
| 181 |
+
gc.collect()
|
| 182 |
+
torch.cuda.empty_cache()
|
| 183 |
+
|
| 184 |
+
# Part 2: Align Loop
|
| 185 |
+
if not no_align:
|
| 186 |
+
tmp_results = results
|
| 187 |
+
results = []
|
| 188 |
+
align_model, align_metadata = load_align_model(align_language, device, model_name=align_model)
|
| 189 |
+
for result, audio_path in tmp_results:
|
| 190 |
+
# >> Align
|
| 191 |
+
if len(tmp_results) > 1:
|
| 192 |
+
input_audio = audio_path
|
| 193 |
+
else:
|
| 194 |
+
# lazily load audio from part 1
|
| 195 |
+
input_audio = audio
|
| 196 |
+
|
| 197 |
+
if align_model is not None and len(result["segments"]) > 0:
|
| 198 |
+
if result.get("language", "en") != align_metadata["language"]:
|
| 199 |
+
# load new language
|
| 200 |
+
print(f"New language found ({result['language']})! Previous was ({align_metadata['language']}), loading new alignment model for new language...")
|
| 201 |
+
align_model, align_metadata = load_align_model(result["language"], device)
|
| 202 |
+
print(">>Performing alignment...")
|
| 203 |
+
result = align(result["segments"], align_model, align_metadata, input_audio, device, interpolate_method=interpolate_method, return_char_alignments=return_char_alignments, print_progress=print_progress)
|
| 204 |
+
|
| 205 |
+
results.append((result, audio_path))
|
| 206 |
+
|
| 207 |
+
# Unload align model
|
| 208 |
+
del align_model
|
| 209 |
+
gc.collect()
|
| 210 |
+
torch.cuda.empty_cache()
|
| 211 |
+
|
| 212 |
+
# >> Diarize
|
| 213 |
+
if diarize:
|
| 214 |
+
if hf_token is None:
|
| 215 |
+
print("Warning, no --hf_token used, needs to be saved in environment variable, otherwise will throw error loading diarization model...")
|
| 216 |
+
tmp_results = results
|
| 217 |
+
print(">>Performing diarization...")
|
| 218 |
+
results = []
|
| 219 |
+
diarize_model = DiarizationPipeline(use_auth_token=hf_token, device=device)
|
| 220 |
+
for result, input_audio_path in tmp_results:
|
| 221 |
+
diarize_segments = diarize_model(input_audio_path, min_speakers=min_speakers, max_speakers=max_speakers)
|
| 222 |
+
result = assign_word_speakers(diarize_segments, result)
|
| 223 |
+
results.append((result, input_audio_path))
|
| 224 |
+
# >> Write
|
| 225 |
+
for result, audio_path in results:
|
| 226 |
+
result["language"] = align_language
|
| 227 |
+
writer(result, audio_path, writer_args)
|
| 228 |
+
|
| 229 |
+
if __name__ == "__main__":
|
| 230 |
+
cli()
|
whisperx/types.py
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import TypedDict, Optional, List
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
class SingleWordSegment(TypedDict):
|
| 5 |
+
"""
|
| 6 |
+
A single word of a speech.
|
| 7 |
+
"""
|
| 8 |
+
word: str
|
| 9 |
+
start: float
|
| 10 |
+
end: float
|
| 11 |
+
score: float
|
| 12 |
+
|
| 13 |
+
class SingleCharSegment(TypedDict):
|
| 14 |
+
"""
|
| 15 |
+
A single char of a speech.
|
| 16 |
+
"""
|
| 17 |
+
char: str
|
| 18 |
+
start: float
|
| 19 |
+
end: float
|
| 20 |
+
score: float
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
class SingleSegment(TypedDict):
|
| 24 |
+
"""
|
| 25 |
+
A single segment (up to multiple sentences) of a speech.
|
| 26 |
+
"""
|
| 27 |
+
|
| 28 |
+
start: float
|
| 29 |
+
end: float
|
| 30 |
+
text: str
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
class SingleAlignedSegment(TypedDict):
|
| 34 |
+
"""
|
| 35 |
+
A single segment (up to multiple sentences) of a speech with word alignment.
|
| 36 |
+
"""
|
| 37 |
+
|
| 38 |
+
start: float
|
| 39 |
+
end: float
|
| 40 |
+
text: str
|
| 41 |
+
words: List[SingleWordSegment]
|
| 42 |
+
chars: Optional[List[SingleCharSegment]]
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
class TranscriptionResult(TypedDict):
|
| 46 |
+
"""
|
| 47 |
+
A list of segments and word segments of a speech.
|
| 48 |
+
"""
|
| 49 |
+
segments: List[SingleSegment]
|
| 50 |
+
language: str
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
class AlignedTranscriptionResult(TypedDict):
|
| 54 |
+
"""
|
| 55 |
+
A list of segments and word segments of a speech.
|
| 56 |
+
"""
|
| 57 |
+
segments: List[SingleAlignedSegment]
|
| 58 |
+
word_segments: List[SingleWordSegment]
|
whisperx/utils.py
ADDED
|
@@ -0,0 +1,437 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import os
|
| 3 |
+
import re
|
| 4 |
+
import sys
|
| 5 |
+
import zlib
|
| 6 |
+
from typing import Callable, Optional, TextIO
|
| 7 |
+
|
| 8 |
+
LANGUAGES = {
|
| 9 |
+
"en": "english",
|
| 10 |
+
"zh": "chinese",
|
| 11 |
+
"de": "german",
|
| 12 |
+
"es": "spanish",
|
| 13 |
+
"ru": "russian",
|
| 14 |
+
"ko": "korean",
|
| 15 |
+
"fr": "french",
|
| 16 |
+
"ja": "japanese",
|
| 17 |
+
"pt": "portuguese",
|
| 18 |
+
"tr": "turkish",
|
| 19 |
+
"pl": "polish",
|
| 20 |
+
"ca": "catalan",
|
| 21 |
+
"nl": "dutch",
|
| 22 |
+
"ar": "arabic",
|
| 23 |
+
"sv": "swedish",
|
| 24 |
+
"it": "italian",
|
| 25 |
+
"id": "indonesian",
|
| 26 |
+
"hi": "hindi",
|
| 27 |
+
"fi": "finnish",
|
| 28 |
+
"vi": "vietnamese",
|
| 29 |
+
"he": "hebrew",
|
| 30 |
+
"uk": "ukrainian",
|
| 31 |
+
"el": "greek",
|
| 32 |
+
"ms": "malay",
|
| 33 |
+
"cs": "czech",
|
| 34 |
+
"ro": "romanian",
|
| 35 |
+
"da": "danish",
|
| 36 |
+
"hu": "hungarian",
|
| 37 |
+
"ta": "tamil",
|
| 38 |
+
"no": "norwegian",
|
| 39 |
+
"th": "thai",
|
| 40 |
+
"ur": "urdu",
|
| 41 |
+
"hr": "croatian",
|
| 42 |
+
"bg": "bulgarian",
|
| 43 |
+
"lt": "lithuanian",
|
| 44 |
+
"la": "latin",
|
| 45 |
+
"mi": "maori",
|
| 46 |
+
"ml": "malayalam",
|
| 47 |
+
"cy": "welsh",
|
| 48 |
+
"sk": "slovak",
|
| 49 |
+
"te": "telugu",
|
| 50 |
+
"fa": "persian",
|
| 51 |
+
"lv": "latvian",
|
| 52 |
+
"bn": "bengali",
|
| 53 |
+
"sr": "serbian",
|
| 54 |
+
"az": "azerbaijani",
|
| 55 |
+
"sl": "slovenian",
|
| 56 |
+
"kn": "kannada",
|
| 57 |
+
"et": "estonian",
|
| 58 |
+
"mk": "macedonian",
|
| 59 |
+
"br": "breton",
|
| 60 |
+
"eu": "basque",
|
| 61 |
+
"is": "icelandic",
|
| 62 |
+
"hy": "armenian",
|
| 63 |
+
"ne": "nepali",
|
| 64 |
+
"mn": "mongolian",
|
| 65 |
+
"bs": "bosnian",
|
| 66 |
+
"kk": "kazakh",
|
| 67 |
+
"sq": "albanian",
|
| 68 |
+
"sw": "swahili",
|
| 69 |
+
"gl": "galician",
|
| 70 |
+
"mr": "marathi",
|
| 71 |
+
"pa": "punjabi",
|
| 72 |
+
"si": "sinhala",
|
| 73 |
+
"km": "khmer",
|
| 74 |
+
"sn": "shona",
|
| 75 |
+
"yo": "yoruba",
|
| 76 |
+
"so": "somali",
|
| 77 |
+
"af": "afrikaans",
|
| 78 |
+
"oc": "occitan",
|
| 79 |
+
"ka": "georgian",
|
| 80 |
+
"be": "belarusian",
|
| 81 |
+
"tg": "tajik",
|
| 82 |
+
"sd": "sindhi",
|
| 83 |
+
"gu": "gujarati",
|
| 84 |
+
"am": "amharic",
|
| 85 |
+
"yi": "yiddish",
|
| 86 |
+
"lo": "lao",
|
| 87 |
+
"uz": "uzbek",
|
| 88 |
+
"fo": "faroese",
|
| 89 |
+
"ht": "haitian creole",
|
| 90 |
+
"ps": "pashto",
|
| 91 |
+
"tk": "turkmen",
|
| 92 |
+
"nn": "nynorsk",
|
| 93 |
+
"mt": "maltese",
|
| 94 |
+
"sa": "sanskrit",
|
| 95 |
+
"lb": "luxembourgish",
|
| 96 |
+
"my": "myanmar",
|
| 97 |
+
"bo": "tibetan",
|
| 98 |
+
"tl": "tagalog",
|
| 99 |
+
"mg": "malagasy",
|
| 100 |
+
"as": "assamese",
|
| 101 |
+
"tt": "tatar",
|
| 102 |
+
"haw": "hawaiian",
|
| 103 |
+
"ln": "lingala",
|
| 104 |
+
"ha": "hausa",
|
| 105 |
+
"ba": "bashkir",
|
| 106 |
+
"jw": "javanese",
|
| 107 |
+
"su": "sundanese",
|
| 108 |
+
"yue": "cantonese",
|
| 109 |
+
}
|
| 110 |
+
|
| 111 |
+
# language code lookup by name, with a few language aliases
|
| 112 |
+
TO_LANGUAGE_CODE = {
|
| 113 |
+
**{language: code for code, language in LANGUAGES.items()},
|
| 114 |
+
"burmese": "my",
|
| 115 |
+
"valencian": "ca",
|
| 116 |
+
"flemish": "nl",
|
| 117 |
+
"haitian": "ht",
|
| 118 |
+
"letzeburgesch": "lb",
|
| 119 |
+
"pushto": "ps",
|
| 120 |
+
"panjabi": "pa",
|
| 121 |
+
"moldavian": "ro",
|
| 122 |
+
"moldovan": "ro",
|
| 123 |
+
"sinhalese": "si",
|
| 124 |
+
"castilian": "es",
|
| 125 |
+
}
|
| 126 |
+
|
| 127 |
+
LANGUAGES_WITHOUT_SPACES = ["ja", "zh"]
|
| 128 |
+
|
| 129 |
+
system_encoding = sys.getdefaultencoding()
|
| 130 |
+
|
| 131 |
+
if system_encoding != "utf-8":
|
| 132 |
+
|
| 133 |
+
def make_safe(string):
|
| 134 |
+
# replaces any character not representable using the system default encoding with an '?',
|
| 135 |
+
# avoiding UnicodeEncodeError (https://github.com/openai/whisper/discussions/729).
|
| 136 |
+
return string.encode(system_encoding, errors="replace").decode(system_encoding)
|
| 137 |
+
|
| 138 |
+
else:
|
| 139 |
+
|
| 140 |
+
def make_safe(string):
|
| 141 |
+
# utf-8 can encode any Unicode code point, so no need to do the round-trip encoding
|
| 142 |
+
return string
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
def exact_div(x, y):
|
| 146 |
+
assert x % y == 0
|
| 147 |
+
return x // y
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
def str2bool(string):
|
| 151 |
+
str2val = {"True": True, "False": False}
|
| 152 |
+
if string in str2val:
|
| 153 |
+
return str2val[string]
|
| 154 |
+
else:
|
| 155 |
+
raise ValueError(f"Expected one of {set(str2val.keys())}, got {string}")
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
def optional_int(string):
|
| 159 |
+
return None if string == "None" else int(string)
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
def optional_float(string):
|
| 163 |
+
return None if string == "None" else float(string)
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
def compression_ratio(text) -> float:
|
| 167 |
+
text_bytes = text.encode("utf-8")
|
| 168 |
+
return len(text_bytes) / len(zlib.compress(text_bytes))
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
def format_timestamp(
|
| 172 |
+
seconds: float, always_include_hours: bool = False, decimal_marker: str = "."
|
| 173 |
+
):
|
| 174 |
+
assert seconds >= 0, "non-negative timestamp expected"
|
| 175 |
+
milliseconds = round(seconds * 1000.0)
|
| 176 |
+
|
| 177 |
+
hours = milliseconds // 3_600_000
|
| 178 |
+
milliseconds -= hours * 3_600_000
|
| 179 |
+
|
| 180 |
+
minutes = milliseconds // 60_000
|
| 181 |
+
milliseconds -= minutes * 60_000
|
| 182 |
+
|
| 183 |
+
seconds = milliseconds // 1_000
|
| 184 |
+
milliseconds -= seconds * 1_000
|
| 185 |
+
|
| 186 |
+
hours_marker = f"{hours:02d}:" if always_include_hours or hours > 0 else ""
|
| 187 |
+
return (
|
| 188 |
+
f"{hours_marker}{minutes:02d}:{seconds:02d}{decimal_marker}{milliseconds:03d}"
|
| 189 |
+
)
|
| 190 |
+
|
| 191 |
+
|
| 192 |
+
class ResultWriter:
|
| 193 |
+
extension: str
|
| 194 |
+
|
| 195 |
+
def __init__(self, output_dir: str):
|
| 196 |
+
self.output_dir = output_dir
|
| 197 |
+
|
| 198 |
+
def __call__(self, result: dict, audio_path: str, options: dict):
|
| 199 |
+
audio_basename = os.path.basename(audio_path)
|
| 200 |
+
audio_basename = os.path.splitext(audio_basename)[0]
|
| 201 |
+
output_path = os.path.join(
|
| 202 |
+
self.output_dir, audio_basename + "." + self.extension
|
| 203 |
+
)
|
| 204 |
+
|
| 205 |
+
with open(output_path, "w", encoding="utf-8") as f:
|
| 206 |
+
self.write_result(result, file=f, options=options)
|
| 207 |
+
|
| 208 |
+
def write_result(self, result: dict, file: TextIO, options: dict):
|
| 209 |
+
raise NotImplementedError
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
class WriteTXT(ResultWriter):
|
| 213 |
+
extension: str = "txt"
|
| 214 |
+
|
| 215 |
+
def write_result(self, result: dict, file: TextIO, options: dict):
|
| 216 |
+
for segment in result["segments"]:
|
| 217 |
+
print(segment["text"].strip(), file=file, flush=True)
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
class SubtitlesWriter(ResultWriter):
|
| 221 |
+
always_include_hours: bool
|
| 222 |
+
decimal_marker: str
|
| 223 |
+
|
| 224 |
+
def iterate_result(self, result: dict, options: dict):
|
| 225 |
+
raw_max_line_width: Optional[int] = options["max_line_width"]
|
| 226 |
+
max_line_count: Optional[int] = options["max_line_count"]
|
| 227 |
+
highlight_words: bool = options["highlight_words"]
|
| 228 |
+
max_line_width = 1000 if raw_max_line_width is None else raw_max_line_width
|
| 229 |
+
preserve_segments = max_line_count is None or raw_max_line_width is None
|
| 230 |
+
|
| 231 |
+
if len(result["segments"]) == 0:
|
| 232 |
+
return
|
| 233 |
+
|
| 234 |
+
def iterate_subtitles():
|
| 235 |
+
line_len = 0
|
| 236 |
+
line_count = 1
|
| 237 |
+
# the next subtitle to yield (a list of word timings with whitespace)
|
| 238 |
+
subtitle: list[dict] = []
|
| 239 |
+
times = []
|
| 240 |
+
last = result["segments"][0]["start"]
|
| 241 |
+
for segment in result["segments"]:
|
| 242 |
+
for i, original_timing in enumerate(segment["words"]):
|
| 243 |
+
timing = original_timing.copy()
|
| 244 |
+
long_pause = not preserve_segments
|
| 245 |
+
if "start" in timing:
|
| 246 |
+
long_pause = long_pause and timing["start"] - last > 3.0
|
| 247 |
+
else:
|
| 248 |
+
long_pause = False
|
| 249 |
+
has_room = line_len + len(timing["word"]) <= max_line_width
|
| 250 |
+
seg_break = i == 0 and len(subtitle) > 0 and preserve_segments
|
| 251 |
+
if line_len > 0 and has_room and not long_pause and not seg_break:
|
| 252 |
+
# line continuation
|
| 253 |
+
line_len += len(timing["word"])
|
| 254 |
+
else:
|
| 255 |
+
# new line
|
| 256 |
+
timing["word"] = timing["word"].strip()
|
| 257 |
+
if (
|
| 258 |
+
len(subtitle) > 0
|
| 259 |
+
and max_line_count is not None
|
| 260 |
+
and (long_pause or line_count >= max_line_count)
|
| 261 |
+
or seg_break
|
| 262 |
+
):
|
| 263 |
+
# subtitle break
|
| 264 |
+
yield subtitle, times
|
| 265 |
+
subtitle = []
|
| 266 |
+
times = []
|
| 267 |
+
line_count = 1
|
| 268 |
+
elif line_len > 0:
|
| 269 |
+
# line break
|
| 270 |
+
line_count += 1
|
| 271 |
+
timing["word"] = "\n" + timing["word"]
|
| 272 |
+
line_len = len(timing["word"].strip())
|
| 273 |
+
subtitle.append(timing)
|
| 274 |
+
times.append((segment["start"], segment["end"], segment.get("speaker")))
|
| 275 |
+
if "start" in timing:
|
| 276 |
+
last = timing["start"]
|
| 277 |
+
if len(subtitle) > 0:
|
| 278 |
+
yield subtitle, times
|
| 279 |
+
|
| 280 |
+
if "words" in result["segments"][0]:
|
| 281 |
+
for subtitle, _ in iterate_subtitles():
|
| 282 |
+
sstart, ssend, speaker = _[0]
|
| 283 |
+
subtitle_start = self.format_timestamp(sstart)
|
| 284 |
+
subtitle_end = self.format_timestamp(ssend)
|
| 285 |
+
if result["language"] in LANGUAGES_WITHOUT_SPACES:
|
| 286 |
+
subtitle_text = "".join([word["word"] for word in subtitle])
|
| 287 |
+
else:
|
| 288 |
+
subtitle_text = " ".join([word["word"] for word in subtitle])
|
| 289 |
+
has_timing = any(["start" in word for word in subtitle])
|
| 290 |
+
|
| 291 |
+
# add [$SPEAKER_ID]: to each subtitle if speaker is available
|
| 292 |
+
prefix = ""
|
| 293 |
+
if speaker is not None:
|
| 294 |
+
prefix = f"[{speaker}]: "
|
| 295 |
+
|
| 296 |
+
if highlight_words and has_timing:
|
| 297 |
+
last = subtitle_start
|
| 298 |
+
all_words = [timing["word"] for timing in subtitle]
|
| 299 |
+
for i, this_word in enumerate(subtitle):
|
| 300 |
+
if "start" in this_word:
|
| 301 |
+
start = self.format_timestamp(this_word["start"])
|
| 302 |
+
end = self.format_timestamp(this_word["end"])
|
| 303 |
+
if last != start:
|
| 304 |
+
yield last, start, prefix + subtitle_text
|
| 305 |
+
|
| 306 |
+
yield start, end, prefix + " ".join(
|
| 307 |
+
[
|
| 308 |
+
re.sub(r"^(\s*)(.*)$", r"\1<u>\2</u>", word)
|
| 309 |
+
if j == i
|
| 310 |
+
else word
|
| 311 |
+
for j, word in enumerate(all_words)
|
| 312 |
+
]
|
| 313 |
+
)
|
| 314 |
+
last = end
|
| 315 |
+
else:
|
| 316 |
+
yield subtitle_start, subtitle_end, prefix + subtitle_text
|
| 317 |
+
else:
|
| 318 |
+
for segment in result["segments"]:
|
| 319 |
+
segment_start = self.format_timestamp(segment["start"])
|
| 320 |
+
segment_end = self.format_timestamp(segment["end"])
|
| 321 |
+
segment_text = segment["text"].strip().replace("-->", "->")
|
| 322 |
+
if "speaker" in segment:
|
| 323 |
+
segment_text = f"[{segment['speaker']}]: {segment_text}"
|
| 324 |
+
yield segment_start, segment_end, segment_text
|
| 325 |
+
|
| 326 |
+
def format_timestamp(self, seconds: float):
|
| 327 |
+
return format_timestamp(
|
| 328 |
+
seconds=seconds,
|
| 329 |
+
always_include_hours=self.always_include_hours,
|
| 330 |
+
decimal_marker=self.decimal_marker,
|
| 331 |
+
)
|
| 332 |
+
|
| 333 |
+
|
| 334 |
+
class WriteVTT(SubtitlesWriter):
|
| 335 |
+
extension: str = "vtt"
|
| 336 |
+
always_include_hours: bool = False
|
| 337 |
+
decimal_marker: str = "."
|
| 338 |
+
|
| 339 |
+
def write_result(self, result: dict, file: TextIO, options: dict):
|
| 340 |
+
print("WEBVTT\n", file=file)
|
| 341 |
+
for start, end, text in self.iterate_result(result, options):
|
| 342 |
+
print(f"{start} --> {end}\n{text}\n", file=file, flush=True)
|
| 343 |
+
|
| 344 |
+
|
| 345 |
+
class WriteSRT(SubtitlesWriter):
|
| 346 |
+
extension: str = "srt"
|
| 347 |
+
always_include_hours: bool = True
|
| 348 |
+
decimal_marker: str = ","
|
| 349 |
+
|
| 350 |
+
def write_result(self, result: dict, file: TextIO, options: dict):
|
| 351 |
+
for i, (start, end, text) in enumerate(
|
| 352 |
+
self.iterate_result(result, options), start=1
|
| 353 |
+
):
|
| 354 |
+
print(f"{i}\n{start} --> {end}\n{text}\n", file=file, flush=True)
|
| 355 |
+
|
| 356 |
+
|
| 357 |
+
class WriteTSV(ResultWriter):
|
| 358 |
+
"""
|
| 359 |
+
Write a transcript to a file in TSV (tab-separated values) format containing lines like:
|
| 360 |
+
<start time in integer milliseconds>\t<end time in integer milliseconds>\t<transcript text>
|
| 361 |
+
|
| 362 |
+
Using integer milliseconds as start and end times means there's no chance of interference from
|
| 363 |
+
an environment setting a language encoding that causes the decimal in a floating point number
|
| 364 |
+
to appear as a comma; also is faster and more efficient to parse & store, e.g., in C++.
|
| 365 |
+
"""
|
| 366 |
+
|
| 367 |
+
extension: str = "tsv"
|
| 368 |
+
|
| 369 |
+
def write_result(self, result: dict, file: TextIO, options: dict):
|
| 370 |
+
print("start", "end", "text", sep="\t", file=file)
|
| 371 |
+
for segment in result["segments"]:
|
| 372 |
+
print(round(1000 * segment["start"]), file=file, end="\t")
|
| 373 |
+
print(round(1000 * segment["end"]), file=file, end="\t")
|
| 374 |
+
print(segment["text"].strip().replace("\t", " "), file=file, flush=True)
|
| 375 |
+
|
| 376 |
+
class WriteAudacity(ResultWriter):
|
| 377 |
+
"""
|
| 378 |
+
Write a transcript to a text file that audacity can import as labels.
|
| 379 |
+
The extension used is "aud" to distinguish it from the txt file produced by WriteTXT.
|
| 380 |
+
Yet this is not an audacity project but only a label file!
|
| 381 |
+
|
| 382 |
+
Please note : Audacity uses seconds in timestamps not ms!
|
| 383 |
+
Also there is no header expected.
|
| 384 |
+
|
| 385 |
+
If speaker is provided it is prepended to the text between double square brackets [[]].
|
| 386 |
+
"""
|
| 387 |
+
|
| 388 |
+
extension: str = "aud"
|
| 389 |
+
|
| 390 |
+
def write_result(self, result: dict, file: TextIO, options: dict):
|
| 391 |
+
ARROW = " "
|
| 392 |
+
for segment in result["segments"]:
|
| 393 |
+
print(segment["start"], file=file, end=ARROW)
|
| 394 |
+
print(segment["end"], file=file, end=ARROW)
|
| 395 |
+
print( ( ("[[" + segment["speaker"] + "]]") if "speaker" in segment else "") + segment["text"].strip().replace("\t", " "), file=file, flush=True)
|
| 396 |
+
|
| 397 |
+
|
| 398 |
+
|
| 399 |
+
class WriteJSON(ResultWriter):
|
| 400 |
+
extension: str = "json"
|
| 401 |
+
|
| 402 |
+
def write_result(self, result: dict, file: TextIO, options: dict):
|
| 403 |
+
json.dump(result, file, ensure_ascii=False)
|
| 404 |
+
|
| 405 |
+
|
| 406 |
+
def get_writer(
|
| 407 |
+
output_format: str, output_dir: str
|
| 408 |
+
) -> Callable[[dict, TextIO, dict], None]:
|
| 409 |
+
writers = {
|
| 410 |
+
"txt": WriteTXT,
|
| 411 |
+
"vtt": WriteVTT,
|
| 412 |
+
"srt": WriteSRT,
|
| 413 |
+
"tsv": WriteTSV,
|
| 414 |
+
"json": WriteJSON,
|
| 415 |
+
}
|
| 416 |
+
optional_writers = {
|
| 417 |
+
"aud": WriteAudacity,
|
| 418 |
+
}
|
| 419 |
+
|
| 420 |
+
if output_format == "all":
|
| 421 |
+
all_writers = [writer(output_dir) for writer in writers.values()]
|
| 422 |
+
|
| 423 |
+
def write_all(result: dict, file: TextIO, options: dict):
|
| 424 |
+
for writer in all_writers:
|
| 425 |
+
writer(result, file, options)
|
| 426 |
+
|
| 427 |
+
return write_all
|
| 428 |
+
|
| 429 |
+
if output_format in optional_writers:
|
| 430 |
+
return optional_writers[output_format](output_dir)
|
| 431 |
+
return writers[output_format](output_dir)
|
| 432 |
+
|
| 433 |
+
def interpolate_nans(x, method='nearest'):
|
| 434 |
+
if x.notnull().sum() > 1:
|
| 435 |
+
return x.interpolate(method=method).ffill().bfill()
|
| 436 |
+
else:
|
| 437 |
+
return x.ffill().bfill()
|
whisperx/vad.py
ADDED
|
@@ -0,0 +1,311 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import hashlib
|
| 2 |
+
import os
|
| 3 |
+
import urllib
|
| 4 |
+
from typing import Callable, Optional, Text, Union
|
| 5 |
+
|
| 6 |
+
import numpy as np
|
| 7 |
+
import pandas as pd
|
| 8 |
+
import torch
|
| 9 |
+
from pyannote.audio import Model
|
| 10 |
+
from pyannote.audio.core.io import AudioFile
|
| 11 |
+
from pyannote.audio.pipelines import VoiceActivityDetection
|
| 12 |
+
from pyannote.audio.pipelines.utils import PipelineModel
|
| 13 |
+
from pyannote.core import Annotation, Segment, SlidingWindowFeature
|
| 14 |
+
from tqdm import tqdm
|
| 15 |
+
|
| 16 |
+
from .diarize import Segment as SegmentX
|
| 17 |
+
|
| 18 |
+
VAD_SEGMENTATION_URL = "https://whisperx.s3.eu-west-2.amazonaws.com/model_weights/segmentation/0b5b3216d60a2d32fc086b47ea8c67589aaeb26b7e07fcbe620d6d0b83e209ea/pytorch_model.bin"
|
| 19 |
+
|
| 20 |
+
def load_vad_model(device, vad_onset=0.500, vad_offset=0.363, use_auth_token=None, model_fp=None):
|
| 21 |
+
model_dir = torch.hub._get_torch_home()
|
| 22 |
+
os.makedirs(model_dir, exist_ok = True)
|
| 23 |
+
if model_fp is None:
|
| 24 |
+
model_fp = os.path.join(model_dir, "whisperx-vad-segmentation.bin")
|
| 25 |
+
if os.path.exists(model_fp) and not os.path.isfile(model_fp):
|
| 26 |
+
raise RuntimeError(f"{model_fp} exists and is not a regular file")
|
| 27 |
+
|
| 28 |
+
if not os.path.isfile(model_fp):
|
| 29 |
+
with urllib.request.urlopen(VAD_SEGMENTATION_URL) as source, open(model_fp, "wb") as output:
|
| 30 |
+
with tqdm(
|
| 31 |
+
total=int(source.info().get("Content-Length")),
|
| 32 |
+
ncols=80,
|
| 33 |
+
unit="iB",
|
| 34 |
+
unit_scale=True,
|
| 35 |
+
unit_divisor=1024,
|
| 36 |
+
) as loop:
|
| 37 |
+
while True:
|
| 38 |
+
buffer = source.read(8192)
|
| 39 |
+
if not buffer:
|
| 40 |
+
break
|
| 41 |
+
|
| 42 |
+
output.write(buffer)
|
| 43 |
+
loop.update(len(buffer))
|
| 44 |
+
|
| 45 |
+
model_bytes = open(model_fp, "rb").read()
|
| 46 |
+
if hashlib.sha256(model_bytes).hexdigest() != VAD_SEGMENTATION_URL.split('/')[-2]:
|
| 47 |
+
raise RuntimeError(
|
| 48 |
+
"Model has been downloaded but the SHA256 checksum does not not match. Please retry loading the model."
|
| 49 |
+
)
|
| 50 |
+
|
| 51 |
+
vad_model = Model.from_pretrained(model_fp, use_auth_token=use_auth_token)
|
| 52 |
+
hyperparameters = {"onset": vad_onset,
|
| 53 |
+
"offset": vad_offset,
|
| 54 |
+
"min_duration_on": 0.1,
|
| 55 |
+
"min_duration_off": 0.1}
|
| 56 |
+
vad_pipeline = VoiceActivitySegmentation(segmentation=vad_model, device=torch.device(device))
|
| 57 |
+
vad_pipeline.instantiate(hyperparameters)
|
| 58 |
+
|
| 59 |
+
return vad_pipeline
|
| 60 |
+
|
| 61 |
+
class Binarize:
|
| 62 |
+
"""Binarize detection scores using hysteresis thresholding, with min-cut operation
|
| 63 |
+
to ensure not segments are longer than max_duration.
|
| 64 |
+
|
| 65 |
+
Parameters
|
| 66 |
+
----------
|
| 67 |
+
onset : float, optional
|
| 68 |
+
Onset threshold. Defaults to 0.5.
|
| 69 |
+
offset : float, optional
|
| 70 |
+
Offset threshold. Defaults to `onset`.
|
| 71 |
+
min_duration_on : float, optional
|
| 72 |
+
Remove active regions shorter than that many seconds. Defaults to 0s.
|
| 73 |
+
min_duration_off : float, optional
|
| 74 |
+
Fill inactive regions shorter than that many seconds. Defaults to 0s.
|
| 75 |
+
pad_onset : float, optional
|
| 76 |
+
Extend active regions by moving their start time by that many seconds.
|
| 77 |
+
Defaults to 0s.
|
| 78 |
+
pad_offset : float, optional
|
| 79 |
+
Extend active regions by moving their end time by that many seconds.
|
| 80 |
+
Defaults to 0s.
|
| 81 |
+
max_duration: float
|
| 82 |
+
The maximum length of an active segment, divides segment at timestamp with lowest score.
|
| 83 |
+
Reference
|
| 84 |
+
---------
|
| 85 |
+
Gregory Gelly and Jean-Luc Gauvain. "Minimum Word Error Training of
|
| 86 |
+
RNN-based Voice Activity Detection", InterSpeech 2015.
|
| 87 |
+
|
| 88 |
+
Modified by Max Bain to include WhisperX's min-cut operation
|
| 89 |
+
https://arxiv.org/abs/2303.00747
|
| 90 |
+
|
| 91 |
+
Pyannote-audio
|
| 92 |
+
"""
|
| 93 |
+
|
| 94 |
+
def __init__(
|
| 95 |
+
self,
|
| 96 |
+
onset: float = 0.5,
|
| 97 |
+
offset: Optional[float] = None,
|
| 98 |
+
min_duration_on: float = 0.0,
|
| 99 |
+
min_duration_off: float = 0.0,
|
| 100 |
+
pad_onset: float = 0.0,
|
| 101 |
+
pad_offset: float = 0.0,
|
| 102 |
+
max_duration: float = float('inf')
|
| 103 |
+
):
|
| 104 |
+
|
| 105 |
+
super().__init__()
|
| 106 |
+
|
| 107 |
+
self.onset = onset
|
| 108 |
+
self.offset = offset or onset
|
| 109 |
+
|
| 110 |
+
self.pad_onset = pad_onset
|
| 111 |
+
self.pad_offset = pad_offset
|
| 112 |
+
|
| 113 |
+
self.min_duration_on = min_duration_on
|
| 114 |
+
self.min_duration_off = min_duration_off
|
| 115 |
+
|
| 116 |
+
self.max_duration = max_duration
|
| 117 |
+
|
| 118 |
+
def __call__(self, scores: SlidingWindowFeature) -> Annotation:
|
| 119 |
+
"""Binarize detection scores
|
| 120 |
+
Parameters
|
| 121 |
+
----------
|
| 122 |
+
scores : SlidingWindowFeature
|
| 123 |
+
Detection scores.
|
| 124 |
+
Returns
|
| 125 |
+
-------
|
| 126 |
+
active : Annotation
|
| 127 |
+
Binarized scores.
|
| 128 |
+
"""
|
| 129 |
+
|
| 130 |
+
num_frames, num_classes = scores.data.shape
|
| 131 |
+
frames = scores.sliding_window
|
| 132 |
+
timestamps = [frames[i].middle for i in range(num_frames)]
|
| 133 |
+
|
| 134 |
+
# annotation meant to store 'active' regions
|
| 135 |
+
active = Annotation()
|
| 136 |
+
for k, k_scores in enumerate(scores.data.T):
|
| 137 |
+
|
| 138 |
+
label = k if scores.labels is None else scores.labels[k]
|
| 139 |
+
|
| 140 |
+
# initial state
|
| 141 |
+
start = timestamps[0]
|
| 142 |
+
is_active = k_scores[0] > self.onset
|
| 143 |
+
curr_scores = [k_scores[0]]
|
| 144 |
+
curr_timestamps = [start]
|
| 145 |
+
t = start
|
| 146 |
+
for t, y in zip(timestamps[1:], k_scores[1:]):
|
| 147 |
+
# currently active
|
| 148 |
+
if is_active:
|
| 149 |
+
curr_duration = t - start
|
| 150 |
+
if curr_duration > self.max_duration:
|
| 151 |
+
search_after = len(curr_scores) // 2
|
| 152 |
+
# divide segment
|
| 153 |
+
min_score_div_idx = search_after + np.argmin(curr_scores[search_after:])
|
| 154 |
+
min_score_t = curr_timestamps[min_score_div_idx]
|
| 155 |
+
region = Segment(start - self.pad_onset, min_score_t + self.pad_offset)
|
| 156 |
+
active[region, k] = label
|
| 157 |
+
start = curr_timestamps[min_score_div_idx]
|
| 158 |
+
curr_scores = curr_scores[min_score_div_idx+1:]
|
| 159 |
+
curr_timestamps = curr_timestamps[min_score_div_idx+1:]
|
| 160 |
+
# switching from active to inactive
|
| 161 |
+
elif y < self.offset:
|
| 162 |
+
region = Segment(start - self.pad_onset, t + self.pad_offset)
|
| 163 |
+
active[region, k] = label
|
| 164 |
+
start = t
|
| 165 |
+
is_active = False
|
| 166 |
+
curr_scores = []
|
| 167 |
+
curr_timestamps = []
|
| 168 |
+
curr_scores.append(y)
|
| 169 |
+
curr_timestamps.append(t)
|
| 170 |
+
# currently inactive
|
| 171 |
+
else:
|
| 172 |
+
# switching from inactive to active
|
| 173 |
+
if y > self.onset:
|
| 174 |
+
start = t
|
| 175 |
+
is_active = True
|
| 176 |
+
|
| 177 |
+
# if active at the end, add final region
|
| 178 |
+
if is_active:
|
| 179 |
+
region = Segment(start - self.pad_onset, t + self.pad_offset)
|
| 180 |
+
active[region, k] = label
|
| 181 |
+
|
| 182 |
+
# because of padding, some active regions might be overlapping: merge them.
|
| 183 |
+
# also: fill same speaker gaps shorter than min_duration_off
|
| 184 |
+
if self.pad_offset > 0.0 or self.pad_onset > 0.0 or self.min_duration_off > 0.0:
|
| 185 |
+
if self.max_duration < float("inf"):
|
| 186 |
+
raise NotImplementedError(f"This would break current max_duration param")
|
| 187 |
+
active = active.support(collar=self.min_duration_off)
|
| 188 |
+
|
| 189 |
+
# remove tracks shorter than min_duration_on
|
| 190 |
+
if self.min_duration_on > 0:
|
| 191 |
+
for segment, track in list(active.itertracks()):
|
| 192 |
+
if segment.duration < self.min_duration_on:
|
| 193 |
+
del active[segment, track]
|
| 194 |
+
|
| 195 |
+
return active
|
| 196 |
+
|
| 197 |
+
|
| 198 |
+
class VoiceActivitySegmentation(VoiceActivityDetection):
|
| 199 |
+
def __init__(
|
| 200 |
+
self,
|
| 201 |
+
segmentation: PipelineModel = "pyannote/segmentation",
|
| 202 |
+
fscore: bool = False,
|
| 203 |
+
use_auth_token: Union[Text, None] = None,
|
| 204 |
+
**inference_kwargs,
|
| 205 |
+
):
|
| 206 |
+
|
| 207 |
+
super().__init__(segmentation=segmentation, fscore=fscore, use_auth_token=use_auth_token, **inference_kwargs)
|
| 208 |
+
|
| 209 |
+
def apply(self, file: AudioFile, hook: Optional[Callable] = None) -> Annotation:
|
| 210 |
+
"""Apply voice activity detection
|
| 211 |
+
|
| 212 |
+
Parameters
|
| 213 |
+
----------
|
| 214 |
+
file : AudioFile
|
| 215 |
+
Processed file.
|
| 216 |
+
hook : callable, optional
|
| 217 |
+
Hook called after each major step of the pipeline with the following
|
| 218 |
+
signature: hook("step_name", step_artefact, file=file)
|
| 219 |
+
|
| 220 |
+
Returns
|
| 221 |
+
-------
|
| 222 |
+
speech : Annotation
|
| 223 |
+
Speech regions.
|
| 224 |
+
"""
|
| 225 |
+
|
| 226 |
+
# setup hook (e.g. for debugging purposes)
|
| 227 |
+
hook = self.setup_hook(file, hook=hook)
|
| 228 |
+
|
| 229 |
+
# apply segmentation model (only if needed)
|
| 230 |
+
# output shape is (num_chunks, num_frames, 1)
|
| 231 |
+
if self.training:
|
| 232 |
+
if self.CACHED_SEGMENTATION in file:
|
| 233 |
+
segmentations = file[self.CACHED_SEGMENTATION]
|
| 234 |
+
else:
|
| 235 |
+
segmentations = self._segmentation(file)
|
| 236 |
+
file[self.CACHED_SEGMENTATION] = segmentations
|
| 237 |
+
else:
|
| 238 |
+
segmentations: SlidingWindowFeature = self._segmentation(file)
|
| 239 |
+
|
| 240 |
+
return segmentations
|
| 241 |
+
|
| 242 |
+
|
| 243 |
+
def merge_vad(vad_arr, pad_onset=0.0, pad_offset=0.0, min_duration_off=0.0, min_duration_on=0.0):
|
| 244 |
+
|
| 245 |
+
active = Annotation()
|
| 246 |
+
for k, vad_t in enumerate(vad_arr):
|
| 247 |
+
region = Segment(vad_t[0] - pad_onset, vad_t[1] + pad_offset)
|
| 248 |
+
active[region, k] = 1
|
| 249 |
+
|
| 250 |
+
|
| 251 |
+
if pad_offset > 0.0 or pad_onset > 0.0 or min_duration_off > 0.0:
|
| 252 |
+
active = active.support(collar=min_duration_off)
|
| 253 |
+
|
| 254 |
+
# remove tracks shorter than min_duration_on
|
| 255 |
+
if min_duration_on > 0:
|
| 256 |
+
for segment, track in list(active.itertracks()):
|
| 257 |
+
if segment.duration < min_duration_on:
|
| 258 |
+
del active[segment, track]
|
| 259 |
+
|
| 260 |
+
active = active.for_json()
|
| 261 |
+
active_segs = pd.DataFrame([x['segment'] for x in active['content']])
|
| 262 |
+
return active_segs
|
| 263 |
+
|
| 264 |
+
def merge_chunks(
|
| 265 |
+
segments,
|
| 266 |
+
chunk_size,
|
| 267 |
+
onset: float = 0.5,
|
| 268 |
+
offset: Optional[float] = None,
|
| 269 |
+
):
|
| 270 |
+
"""
|
| 271 |
+
Merge operation described in paper
|
| 272 |
+
"""
|
| 273 |
+
curr_end = 0
|
| 274 |
+
merged_segments = []
|
| 275 |
+
seg_idxs = []
|
| 276 |
+
speaker_idxs = []
|
| 277 |
+
|
| 278 |
+
assert chunk_size > 0
|
| 279 |
+
binarize = Binarize(max_duration=chunk_size, onset=onset, offset=offset)
|
| 280 |
+
segments = binarize(segments)
|
| 281 |
+
segments_list = []
|
| 282 |
+
for speech_turn in segments.get_timeline():
|
| 283 |
+
segments_list.append(SegmentX(speech_turn.start, speech_turn.end, "UNKNOWN"))
|
| 284 |
+
|
| 285 |
+
if len(segments_list) == 0:
|
| 286 |
+
print("No active speech found in audio")
|
| 287 |
+
return []
|
| 288 |
+
# assert segments_list, "segments_list is empty."
|
| 289 |
+
# Make sur the starting point is the start of the segment.
|
| 290 |
+
curr_start = segments_list[0].start
|
| 291 |
+
|
| 292 |
+
for seg in segments_list:
|
| 293 |
+
if seg.end - curr_start > chunk_size and curr_end-curr_start > 0:
|
| 294 |
+
merged_segments.append({
|
| 295 |
+
"start": curr_start,
|
| 296 |
+
"end": curr_end,
|
| 297 |
+
"segments": seg_idxs,
|
| 298 |
+
})
|
| 299 |
+
curr_start = seg.start
|
| 300 |
+
seg_idxs = []
|
| 301 |
+
speaker_idxs = []
|
| 302 |
+
curr_end = seg.end
|
| 303 |
+
seg_idxs.append((seg.start, seg.end))
|
| 304 |
+
speaker_idxs.append(seg.speaker)
|
| 305 |
+
# add final
|
| 306 |
+
merged_segments.append({
|
| 307 |
+
"start": curr_start,
|
| 308 |
+
"end": curr_end,
|
| 309 |
+
"segments": seg_idxs,
|
| 310 |
+
})
|
| 311 |
+
return merged_segments
|