![]()
🔗 GitHub | 🏠 Infini-AI MaaS | 📖 WeChat Official | 💬 WeChat Groups
中文 | English
## 模型简介 Megrez-3B-Instruct是由无问芯穹([Infinigence AI](https://cloud.infini-ai.com/platform/ai))完全自主训练的大语言模型。Megrez-3B旨在通过软硬协同理念,打造一款极速推理、小巧精悍、极易上手的端侧智能解决方案。Megrez-3B具有以下优点: 1. 高精度:Megrez-3B虽然参数规模只有3B,但通过提升数据质量,成功弥合模型能力代差,将上一代14B模型的能力成功压缩进3B大小的模型,在主流榜单上取得了优秀的性能表现。 2. 高速度:模型小≠速度快。Megrez-3B通过软硬协同优化,确保了各结构参数与主流硬件高度适配,推理速度领先同精度模型最大300%。 3. 简单易用:模型设计之初我们进行了激烈的讨论:应该在结构设计上留出更多软硬协同的空间(如ReLU、稀疏化、更精简的结构等),还是使用经典结构便于开发者直接用起来?我们选择了后者,即采用最原始的LLaMA结构,开发者无需任何修改便可将模型部署于各种平台,最小化二次开发复杂度。 4. 丰富应用:我们提供了完整的WebSearch方案。我们对模型进行了针对性训练,使模型可以自动决策搜索调用时机,在搜索和对话中自动切换,并提供更好的总结效果。我们提供了完整的部署工程代码 [github](https://github.com/infinigence/InfiniWebSearch),用户可以基于该功能构建属于自己的Kimi或Perplexity,克服小模型常见的幻觉问题和知识储备不足的局限。 ## 基础信息 * Architecture: Llama-2 with GQA * Context length: 32K tokens * Params (Total): 2.92B * Params (Backbone only, w/o Emb or Softmax): 2.29B * Vocab Size: 122880 * Training data: 3T tokens * Supported languages: Chinese & English ## 性能 我们使用开源评测工具 [OpenCompass](https://github.com/open-compass/opencompass) 对 Megrez-3B-Instruct 进行了评测。部分评测结果如下表所示。 速度精度模型大小散点图如下,位置越靠近右上表明模型越好越快。 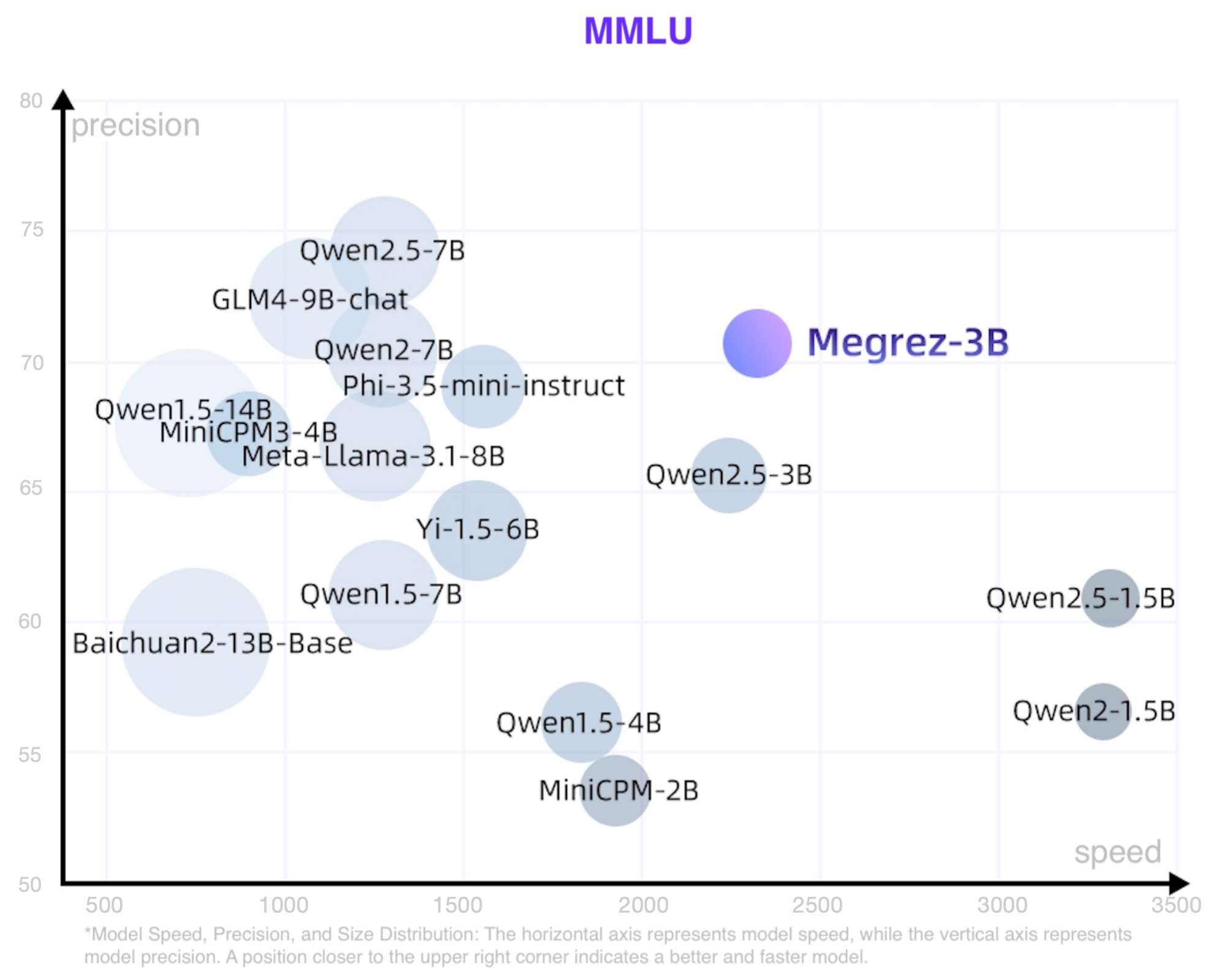 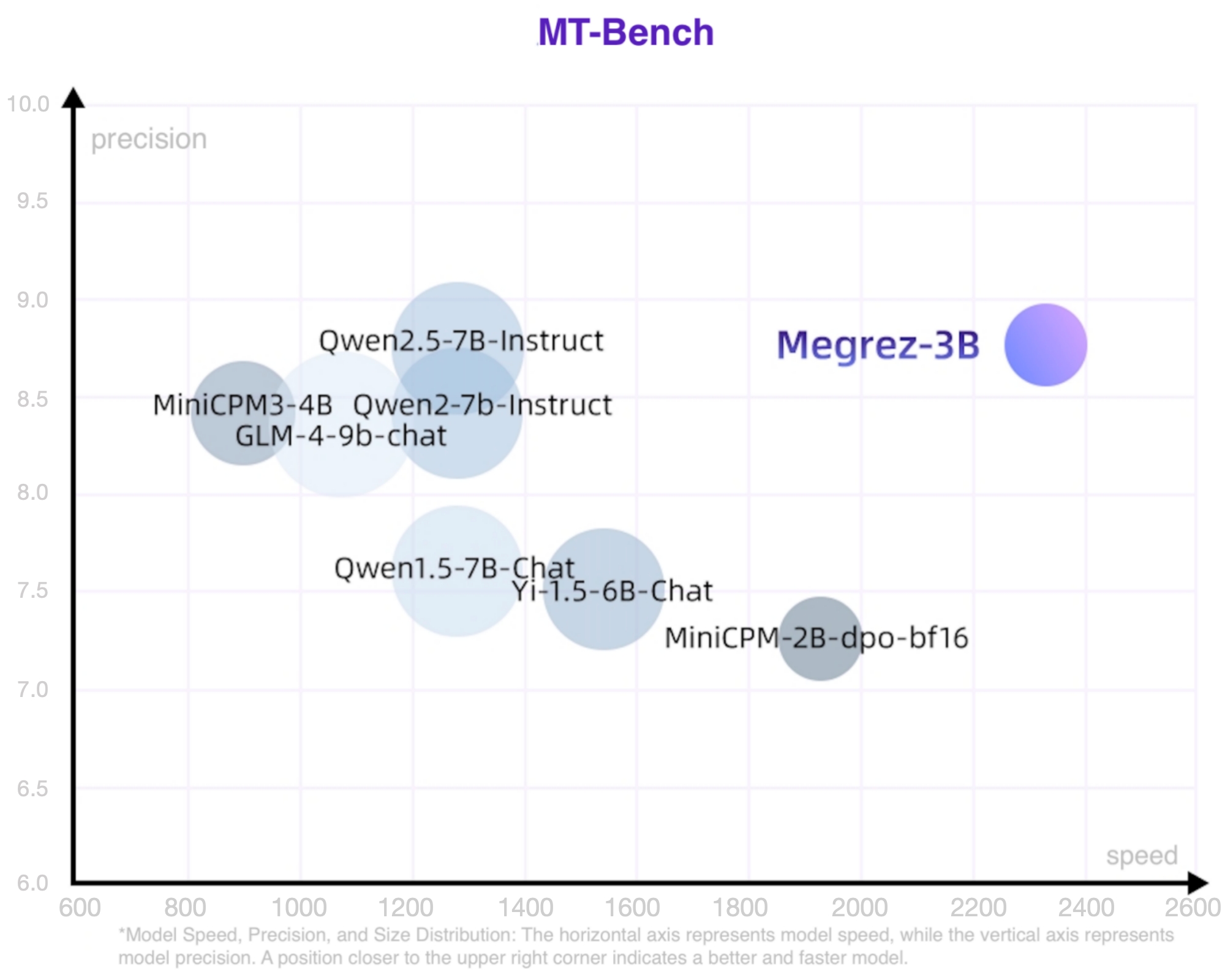 ### 综合能力 | 模型 | 指令模型 | # Non-Emb Params | 推理速度 (tokens/s) | C-EVAL | CMMLU | MMLU | MMLU-Pro | HumanEval | MBPP | GSM8K | MATH | |:---------------------:|:--------:|:---------------:|:-------------------:|:------:|:-----:|:-----:|:--------:|:---------:|:-----:|:-----:|:-----:| | Megrez-3B-Instruct | Y | 2.3 | 2329.4 | 84.8 | 74.7 | 72.8 | 46.1 | 78.7 | 71.0 | 65.5 | 28.3 | | Qwen2-1.5B | | 1.3 | 3299.5 | 70.6 | 70.3 | 56.5 | 21.8 | 31.1 | 37.4 | 58.5 | 21.7 | | Qwen2.5-1.5B | | 1.3 | 3318.8 | - | - | 60.9 | 28.5 | 37.2 | 60.2 | 68.5 | 35.0 | | MiniCPM-2B | | 2.4 | 1930.8 | 51.1 | 51.1 | 53.5 | - | 50.0 | 47.3 | 53.8 | 10.2 | | Qwen2.5-3B | | 2.8 | 2248.3 | - | - | 65.6 | 34.6 | 42.1 | 57.1 | 79.1 | 42.6 | | Qwen2.5-3B-Instruct | Y | 2.8 | 2248.3 | - | - | - | 43.7 | 74.4 | 72.7 | 86.7 | 65.9 | | Qwen1.5-4B | | 3.2 | 1837.9 | 67.6 | 66.7 | 56.1 | - | 25.6 | 29.2 | 57.0 | 10.0 | | Phi-3.5-mini-instruct | Y | 3.6 | 1559.1 | 46.1 | 46.9 | 69.0 | - | 62.8 | 69.6 | 86.2 | 48.5 | | MiniCPM3-4B | Y | 3.9 | 901.1 | 73.6 | 73.3 | 67.2 | - | 74.4 | 72.5 | 81.1 | 46.6 | | Yi-1.5-6B | | 5.5 | 1542.7 | - | 70.8 | 63.5 | - | 36.5 | 56.8 | 62.2 | 28.4 | | Qwen1.5-7B | | 6.5 | 1282.3 | 74.1 | 73.1 | 61.0 | 29.9 | 36.0 | 51.6 | 62.5 | 20.3 | | Qwen2-7B | | 6.5 | 1279.4 | 83.2 | 83.9 | 70.3 | 40.0 | 51.2 | 65.9 | 79.9 | 44.2 | | Qwen2.5-7B | | 6.5 | 1283.4 | - | - | 74.2 | 45.0 | 57.9 | 74.9 | 85.4 | 49.8 | | Meta-Llama-3.1-8B | | 7.0 | 1255.9 | - | - | 66.7 | 37.1 | - | - | - | - | | GLM-4-9B-chat | Y | 8.2 | 1076.1 | 75.6 | 71.5 | 72.4 | - | 71.8 | - | 79.6 | 50.6 | | Baichuan2-13B-Base | | 12.6 | 756.7 | 58.1 | 62.0 | 59.2 | - | 17.1 | 30.2 | 52.8 | 10.1 | | Qwen1.5-14B | | 12.6 | 735.6 | 78.7 | 77.6 | 67.6 | - | 37.8 | 44.0 | 70.1 | 29.2 | - Qwen2-1.5B模型的指标在其论文和Qwen2.5报告中点数不一致,当前采用原始论文中的精度 - 测速配置详见 README_SPEED.md ### 对话能力 本表只摘出有官方MT-Bench或AlignBench点数的模型 | 模型 | # Non-Emb Params | 推理速度 (tokens/s) | MT-Bench | AlignBench (ZH) | |---------------------|--------------------------------------|:--------------------------:|:--------:|:---------------:| | Megrez-3B-Instruct | 2.3 | 2329.4 | 8.64 | 7.06 | | MiniCPM-2B-sft-bf16 | 2.4 | 1930.8 | - | 4.64 | | MiniCPM-2B-dpo-bf16 | 2.4 | 1930.8 | 7.25 | - | | Qwen2.5-3B-Instruct | 2.8 | 2248.3 | - | - | | MiniCPM3-4B | 3.9 | 901.1 | 8.41 | 6.74 | | Yi-1.5-6B-Chat | 5.5 | 1542.7 | 7.50 | 6.20 | | Qwen1.5-7B-Chat | 6.5 | 1282.3 | 7.60 | 6.20 | | Qwen2-7b-Instruct | 6.5 | 1279.4 | 8.41 | 7.21 | | Qwen2.5-7B-Instruct | 6.5 | 1283.4 | 8.75 | - | | glm-4-9b-chat | 8.2 | 1076.1 | 8.35 | 7.01 | | Baichuan2-13B-Chat | 12.6 | 756.7 | - | 5.25 | ### LLM Leaderboard | 模型 | # Non-Emb Params | 推理速度 (tokens/s) | IFeval strict-prompt | BBH | ARC_C | HellaSwag | WinoGrande | TriviaQA | |-----------------------|--------------------------------------|:--------------------------:|:--------------------:|:----:|:-----:|:---------:|:----------:|:--------:| | Megrez-3B-Instruct | 2.3 | 2329.4 | 68.6 | 72.6 | 95.6 | 83.9 | 78.8 | 81.6 | | MiniCPM-2B | 2.4 | 1930.8 | - | 36.9 | 68.0 | 68.3 | - | 32.5 | | Qwen2.5-3B | 2.8 | 2248.3 | - | 56.3 | 56.5 | 74.6 | 71.1 | - | | Qwen2.5-3B-Instruct | 2.8 | 2248.3 | 58.2 | - | - | - | - | - | | Phi-3.5-mini-instruct | 3.6 | 1559.1 | - | 69.0 | 84.6 | 69.4 | 68.5 | - | | MiniCPM3-4B | 3.9 | 901.1 | 68.4 | 70.2 | - | - | - | - | | Qwen2-7B-Instruct | 6.5 | 1279.4 | - | 62.6 | 60.6 | 80.7 | 77.0 | - | | Meta-Llama-3.1-8B | 7.0 | 1255.9 | 71.5 | 28.9 | 83.4 | - | - | - | ### 长文本能力 #### Longbench | | 单文档问答 | 多文档问答 | 概要任务 | 少样本学习 | 人工合成任务 | 代码任务 | 平均 | |-----------------------|:------------------:|:-----------------:|:-------------:|:-----------------:|:---------------:|:----------------:|:-------:| | Megrez-3B-Instruct | 39.7 | 55.5 | 24.5 | 62.5 | 68.5 | 66.7 | 52.9 | | GPT-3.5-Turbo-16k | 50.5 | 33.7 | 21.25 | 48.15 | 54.1 | 54.1 | 43.63 | | ChatGLM3-6B-32k | 51.3 | 45.7 | 23.65 | 55.05 | 56.2 | 56.2 | 48.02 | | InternLM2-Chat-7B-SFT | 47.3 | 45.2 | 25.3 | 59.9 | 67.2 | 43.5 | 48.07 | #### 长文本对话能力 | | Longbench-Chat | |--------------------------|----------------| | Megrez-3B-Instruct | 4.98 | | Vicuna-7b-v1.5-16k | 3.51 | | Mistral-7B-Instruct-v0.2 | 5.84 | | ChatGLM3-6B-128k | 6.52 | | GLM-4-9B-Chat | 7.72 | #### 大海捞针实验 (Needle In A Haystack - Pressure Test) Megrez-3B-Instruct在32K文本下的大海捞针压力测试全部通过 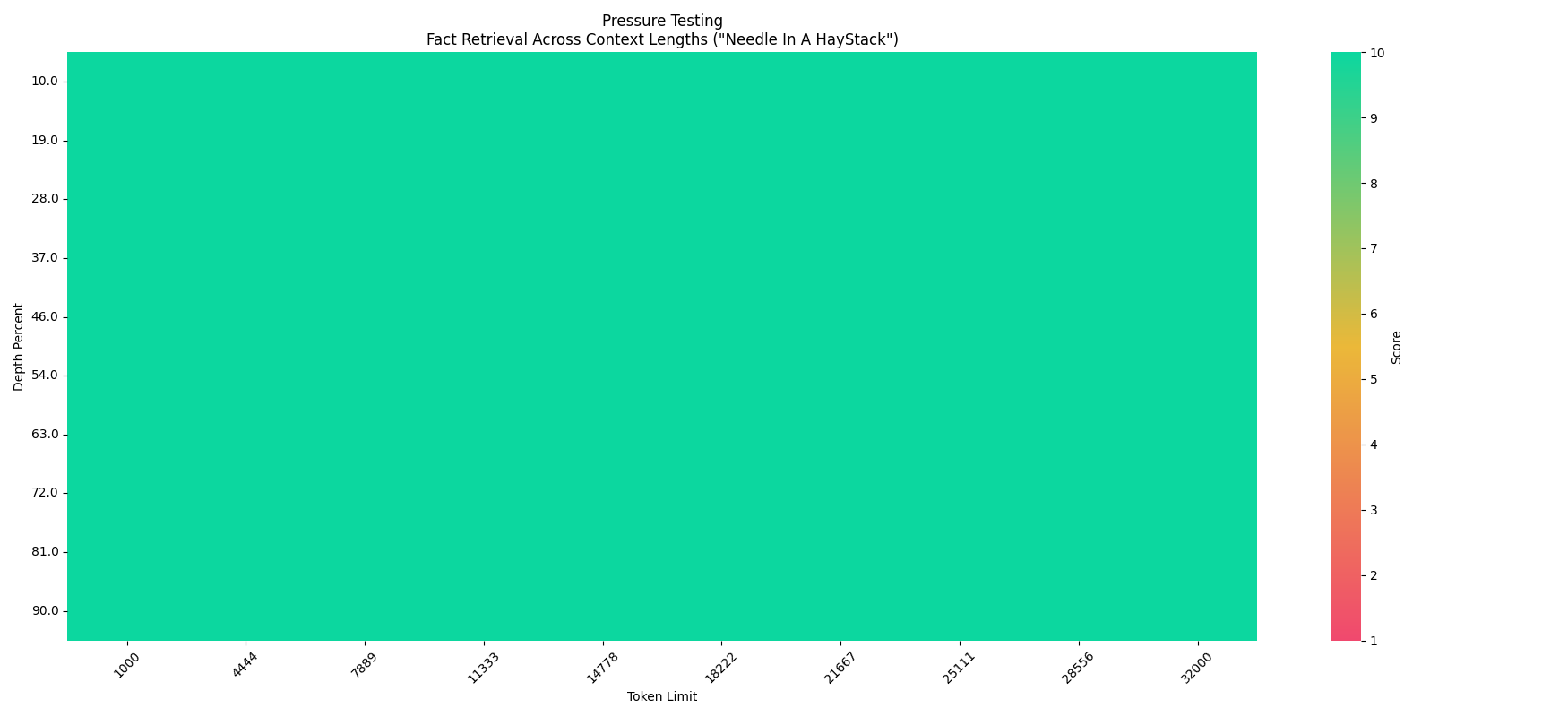 ## WebSearch 我们模型进行了针对性训练,并提供了完整的工程部署方案。[InfiniWebSearch](https://github.com/infinigence/InfiniWebSearch) 具有以下优势: 1. 自动决定调用时机:自动决策搜索调用时机,在搜索和对话中自动切换,避免一直调用或一直不调用 2. 上下文理解:根据多轮对话生成合理的搜索query或处理搜索结果,更好的理解用户意图 3. 带参考信息的结构化输出:每个结论注明出处,便于查验 4. 一个模型两种用法:通过sys prompt区分WebSearch功能开启与否,兼顾LLM的高精度与WebSearch的用户体验,两种能力不乱窜 我们对模型进行了针对性训练,使模型可以自动决策搜索调用时机,在搜索和对话中自动切换,并提供更好的总结效果。我们提供了完整的部署工程代码 ,用户可以基于该功能构建属于自己的Kimi或Perplexity,克服小模型常见的幻觉问题和知识储备不足的局限。  ## 快速上手 ### 在线体验 [MaaS (推荐)](https://cloud.infini-ai.com/genstudio/model/mo-c73owqiotql7lozr) ### 推理参数 - 对于对话、文章撰写等具有一定随机性或发散性的输出,可以采用 temperature=0.7等参数进行推理 - 对于数学、逻辑推理等确定性较高的输出,建议使用 **temperature=0.2** 的参数进行推理,以减少采样带来的幻觉影响,获得更好的推理能力 ### Huggingface 推理 安装transformers后,运行以下代码。 ``` python from transformers import AutoModelForCausalLM, AutoTokenizer import torch path = "Infinigence/Megrez-3B-Instruct" device = "cuda" tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True) model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch.bfloat16, device_map=device, trust_remote_code=True) messages = [ {"role": "user", "content": "讲讲黄焖鸡的做法。"}, ] model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt", add_generation_prompt=True).to(device) model_outputs = model.generate( model_inputs, do_sample=True, max_new_tokens=1024, top_p=0.9, temperature=0.2 ) output_token_ids = [ model_outputs[i][len(model_inputs[i]):] for i in range(len(model_inputs)) ] responses = tokenizer.batch_decode(output_token_ids, skip_special_tokens=True)[0] print(responses) ``` ### vLLM 推理 - 安装vLLM ```bash # Install vLLM with CUDA 12.1. pip install vllm ``` - 测试样例 ```python from transformers import AutoTokenizer from vllm import LLM, SamplingParams model_name = "Infinigence/Megrez-3B-Instruct" prompt = [{"role": "user", "content": "讲讲黄焖鸡的做法。"}] tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True) input_text = tokenizer.apply_chat_template(prompt, tokenize=False, add_generation_prompt=True) llm = LLM( model=model_name, trust_remote_code=True, tensor_parallel_size=1 ) sampling_params = SamplingParams(top_p=0.9, temperature=0.2, max_tokens=1024) outputs = llm.generate(prompts=input_text, sampling_params=sampling_params) print(outputs[0].outputs[0].text) ``` ## 开源协议及使用声明 - 协议:本仓库中代码依照 [Apache-2.0](https://www.apache.org/licenses/LICENSE-2.0) 协议开源 - 幻觉:大模型天然存在幻觉问题,用户使用过程中请勿完全相信模型生成的内容。若用户想获取更符合事实的生成内容,推荐利用我们的WebSearch功能,详见 [InfiniWebSearch](https://github.com/paxionfull/InfiniWebSearch)。 - 数学&推理:小模型在数学和推理任务上更容易出错误的计算过程或推理链条,从而导致最终结果错误。特别的,小模型的输出softmax分布相比大模型明显不够sharp,在较高temperature下更容易出现多次推理结果不一致的问题,在数学/推理等确定性问题上更为明显。我们推荐在这类问题上,调低temperature,或尝试多次推理验证。 - System Prompt:和绝大多数模型一样,我们推荐使用配置文件中chat_template默认的system prompt,以获得稳定和平衡的体验。本次模型发布弱化了角色扮演等涉及特定领域应用方面的能力,用户若有特定领域的应用需求,我们推荐在本模型基础上按需进行适当微调。 - 价值观及安全性:本模型已尽全力确保训练过程中使用的数据的合规性,但由于数据的大体量及复杂性,仍有可能存在一些无法预见的问题。如果出现使用本开源模型而导致的任何问题,包括但不限于数据安全问题、公共舆论风险,或模型被误导、滥用、传播或不当利用所带来的任何风险和问题,我们将不承担任何责任。
{kind=link}
{kind=link}