
Upload model
Browse files- .DS_Store +0 -0
- .gitattributes +1 -0
- README.md +243 -0
- added_tokens.json +4 -0
- config.json +26 -0
- configs/lmstudio/preset.json +11 -0
- configs/silly_tavern/cards/LaraLightland.png +0 -0
- configs/silly_tavern/cards/Seraphina.png +3 -0
- configs/silly_tavern/settings_screenshot.webp +0 -0
- configs/silly_tavern/v1/context_settings.json +11 -0
- configs/silly_tavern/v1/instruct_mode_settings.json +17 -0
- configs/silly_tavern/v2/context_settings.json +11 -0
- configs/silly_tavern/v2/instruct_mode_settings.json +17 -0
- example/interactive.py +129 -0
- example/prompt/__init__.py +0 -0
- example/prompt/format.py +96 -0
- example/simple.py +132 -0
- generation_config.json +7 -0
- model-00001-of-00003.safetensors +3 -0
- model-00002-of-00003.safetensors +3 -0
- model-00003-of-00003.safetensors +3 -0
- model.safetensors.index.json +298 -0
- pytorch_model.bin.index.json +298 -0
- special_tokens_map.json +39 -0
- tokenizer.json +0 -0
- tokenizer.model +3 -0
- tokenizer_config.json +62 -0
.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
configs/silly_tavern/cards/Seraphina.png filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,243 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
language:
|
| 3 |
+
- en
|
| 4 |
+
pipeline_tag: text-generation
|
| 5 |
+
tags:
|
| 6 |
+
- unsloth
|
| 7 |
+
- axolotl
|
| 8 |
+
license: cc-by-nc-nd-4.0
|
| 9 |
+
---
|
| 10 |
+
|
| 11 |
+
# DreamGen Opus V1
|
| 12 |
+
|
| 13 |
+
<div style="display: flex; flex-direction: row; align-items: center;">
|
| 14 |
+
<img src="/dreamgen/opus-v1.2-7b/resolve/main/images/logo-1024.png" alt="model logo" style="
|
| 15 |
+
border-radius: 12px;
|
| 16 |
+
margin-right: 12px;
|
| 17 |
+
margin-top: 0px;
|
| 18 |
+
margin-bottom: 0px;
|
| 19 |
+
max-width: 100px;
|
| 20 |
+
height: auto;
|
| 21 |
+
"/>
|
| 22 |
+
|
| 23 |
+
Models for **(steerable) story-writing and role-playing**.
|
| 24 |
+
<br/>[All Opus V1 models, including quants](https://huggingface.co/collections/dreamgen/opus-v1-65d092a6f8ab7fc669111b31).
|
| 25 |
+
|
| 26 |
+
</div>
|
| 27 |
+
|
| 28 |
+
## Resources
|
| 29 |
+
|
| 30 |
+
- [**Opus V1 prompting guide**](https://dreamgen.com/docs/models/opus/v1) with many (interactive) examples and prompts that you can copy.
|
| 31 |
+
- [**Google Colab**](https://colab.research.google.com/drive/1J178fH6IdQOXNi-Njgdacf5QgAxsdT20?usp=sharing) for interactive role-play using `opus-v1.2-7b`.
|
| 32 |
+
- [Python code](example/prompt/format.py) to format the prompt correctly.
|
| 33 |
+
- Join the community on [**Discord**](https://dreamgen.com/discord) to get early access to new models.
|
| 34 |
+
|
| 35 |
+
<img src="/dreamgen/opus-v1.2-7b/resolve/main/images/story_writing.webp" alt="story writing on dreamgen.com" style="
|
| 36 |
+
padding: 12px;
|
| 37 |
+
border-radius: 12px;
|
| 38 |
+
border: 2px solid #f9a8d4;
|
| 39 |
+
background: rgb(9, 9, 11);
|
| 40 |
+
"/>
|
| 41 |
+
|
| 42 |
+
## Prompting
|
| 43 |
+
|
| 44 |
+
<details>
|
| 45 |
+
<summary>The models use an extended version of ChatML.</summary>
|
| 46 |
+
|
| 47 |
+
```
|
| 48 |
+
<|im_start|>system
|
| 49 |
+
(Story description in the right format here)
|
| 50 |
+
(Typically consists of plot description, style description and characters)<|im_end|>
|
| 51 |
+
<|im_start|>user
|
| 52 |
+
(Your instruction on how the story should continue)<|im_end|>
|
| 53 |
+
<|im_start|>text names= Alice
|
| 54 |
+
(Continuation of the story from the Alice character)<|im_end|>
|
| 55 |
+
<|im_start|>text
|
| 56 |
+
(Continuation of the story from no character in particular (pure narration))<|im_end|>
|
| 57 |
+
<|im_start|>user
|
| 58 |
+
(Your instruction on how the story should continue)<|im_end|>
|
| 59 |
+
<|im_start|>text names= Bob
|
| 60 |
+
(Continuation of the story from the Bob character)<|im_end|>
|
| 61 |
+
```
|
| 62 |
+
|
| 63 |
+
The Opus V1 extension is the addition of the `text` role, and the addition / modification of role names.
|
| 64 |
+
|
| 65 |
+
Pay attention to the following:
|
| 66 |
+
|
| 67 |
+
- The `text` messages can (but don't have to have) `names`, names are used to indicate the "active" character during role-play.
|
| 68 |
+
- There can be multiple subsequent message with a `text` role, especially if names are involved.
|
| 69 |
+
- There can be multiple names attached to a message.
|
| 70 |
+
- The format for names is `names= {{name[0]}}; {{name[1]}}`, beware of the spaces after `names=` and after the `;`. This spacing leads to most natural tokenization for the names.
|
| 71 |
+
</details>
|
| 72 |
+
|
| 73 |
+
While the main goal for the models is great story-writing and role-playing performance, the models are also capable of several writing related tasks as well as general assistance.
|
| 74 |
+
|
| 75 |
+
Here's how you can prompt the model for the following tasks
|
| 76 |
+
|
| 77 |
+
### Steerable Story-writing and Role-playing:
|
| 78 |
+
|
| 79 |
+
- [Story-writing prompt guide](https://dreamgen.com/docs/models/opus/v1#task-story-writing)
|
| 80 |
+
- [Role-playing prompt guide](https://dreamgen.com/docs/models/opus/v1#task-role-playing)
|
| 81 |
+
- Input:
|
| 82 |
+
- System prompt: You provide story / role-play description, which consists of:
|
| 83 |
+
- Plot description
|
| 84 |
+
- Style description
|
| 85 |
+
- Characters and their descriptions
|
| 86 |
+
- Conversation turns:
|
| 87 |
+
- Text / message turn: This represents part of the story or role play
|
| 88 |
+
- Instruction: This tells the model what should happen next
|
| 89 |
+
- Output: Continuation of the story / role-play.
|
| 90 |
+
|
| 91 |
+
### Story plot summarization
|
| 92 |
+
|
| 93 |
+
- [Prompt guide](https://dreamgen.com/docs/models/opus/v1#task-plot-description)
|
| 94 |
+
- Input: A story, or a few chapters of a story.
|
| 95 |
+
- Output: A description of the story or chapters.
|
| 96 |
+
|
| 97 |
+
#### Examples:
|
| 98 |
+
|
| 99 |
+
<details>
|
| 100 |
+
<summary>Summary of <a href="https://www.libraryofshortstories.com/onlinereader/the-last-incantation">short fiction story</a> in 50 words</summary>
|
| 101 |
+
<blockquote>
|
| 102 |
+
Malygris, a powerful magician, summons his long-dead lover Nylissa from the grave using necromancy. However, upon seeing her, he realizes that she is not the same person he once knew, leading him to question the nature of love, memory, and the power of magic.
|
| 103 |
+
</blockquote>
|
| 104 |
+
</details>
|
| 105 |
+
<details>
|
| 106 |
+
<summary>Summary of <a href="https://www.libraryofshortstories.com/onlinereader/the-last-incantation">short fiction story</a> in 200 words</summary>
|
| 107 |
+
<blockquote>
|
| 108 |
+
The story is a dark fantasy set in the city of Susran, where an ancient and powerful magician named Malygris dwells in a tower atop a conical hill. Malygris, who has mastered all forms of sorcery and necromancy, is plagued by a deep sense of ennui and melancholy. He seeks solace in the memory of Nylissa, a girl he once loved in his youth.
|
| 109 |
+
|
| 110 |
+
One day, Malygris decides to summon Nylissa's spirit from the grave using his necromantic powers. He performs the necessary rituals and incantations, and Nylissa appears before him as a ghostly apparition. However, as Malygris gazes upon her, he becomes increasingly disillusioned. He notices subtle changes in her appearance and behavior that do not match his memories of her. He begins to question whether this is truly the same Nylissa he once knew, or if it is just another illusion conjured by his magic.
|
| 111 |
+
|
| 112 |
+
As Malygris grapples with this uncertainty, he becomes increasingly despondent and disillusioned with life itself. He realizes that even his magic cannot bring back the past or make him truly happy. In the end, he dismisses Nylissa's spirit and returns to his lonely tower, resigned to his fate as an old and weary sorcerer.
|
| 113 |
+
</blockquote>
|
| 114 |
+
|
| 115 |
+
</details>
|
| 116 |
+
<details>
|
| 117 |
+
<summary>Summary of <a href="https://edition.cnn.com/2024/02/29/health/pets-diseases-viruses-bacteria-wellness/index.html">CNN News article</a> in 150 words</summary>
|
| 118 |
+
<blockquote>
|
| 119 |
+
The article discusses the recent human deaths from diseases transmitted by animals, specifically Alaskapox and bubonic plague. Dr. Leana Wen, an emergency physician and former Baltimore health commissioner, explains the various ways household pets can transmit diseases to humans. These include fecal-oral transmission, scratches and bites, and vector-borne diseases like ticks, fleas, and mosquitoes. Wen emphasizes the importance of vaccinating pets, maintaining cleanliness, and taking commonsense precautions to reduce disease transmission. She also advises that individuals who are immunocompromised, babies, and pregnant women should take additional care when interacting with animals.
|
| 120 |
+
</blockquote>
|
| 121 |
+
</details>
|
| 122 |
+
<details>
|
| 123 |
+
<summary>Summary of <a href="https://edition.cnn.com/2024/02/29/health/pets-diseases-viruses-bacteria-wellness/index.html">CNN News article</a> in 50 words</summary>
|
| 124 |
+
<blockquote>
|
| 125 |
+
A doctor discusses the risks of diseases transmitted from animals to humans, focusing on household pets like cats and dogs. They emphasize the importance of vaccination, hygiene, and regular veterinary care to prevent these illnesses.
|
| 126 |
+
</blockquote>
|
| 127 |
+
</details>
|
| 128 |
+
|
| 129 |
+
### Story character description
|
| 130 |
+
|
| 131 |
+
- [Prompt guide](https://dreamgen.com/docs/models/opus/v1#task-char-description)
|
| 132 |
+
- Input: A story, or a few chapters of a story, set of characters.
|
| 133 |
+
- Output: A description of the characters.
|
| 134 |
+
|
| 135 |
+
#### Examples:
|
| 136 |
+
|
| 137 |
+
<details>
|
| 138 |
+
<summary>Description of the Malygris character from <a href="https://www.libraryofshortstories.com/onlinereader/the-last-incantation">this story</a> in 50 words</summary>
|
| 139 |
+
<blockquote>
|
| 140 |
+
Malygris is an ancient and powerful magician, characterized by his long white beard, cold green eyes, and a violet robe. He is a master of necromancy and possesses a vast knowledge of forbidden magic. Despite his immense power, he is plagued by a deep sense of melancholy and ennui.
|
| 141 |
+
</blockquote>
|
| 142 |
+
</details>
|
| 143 |
+
|
| 144 |
+
<details>
|
| 145 |
+
<summary>Description of the prince character from <a href="https://www.libraryofshortstories.com/onlinereader/the-pearl-of-love">this story</a> in 50 words</summary>
|
| 146 |
+
<blockquote>
|
| 147 |
+
The prince is a devoted and determined individual, driven by his love for his late queen. He is described as a graceful youth in the beginning, but as he grows older, his dedication to the Pearl of Love transforms him into a grave and intent man. His sense of color and design evolves over time, reflecting his growing maturity and artistic vision.
|
| 148 |
+
</blockquote>
|
| 149 |
+
</details>
|
| 150 |
+
|
| 151 |
+
### Story style description
|
| 152 |
+
|
| 153 |
+
- [Prompt guide](https://dreamgen.com/docs/models/opus/v1#task-style-description)
|
| 154 |
+
- Input: A story, or a few chapters of a story.
|
| 155 |
+
- Output: A description the style of the story.
|
| 156 |
+
|
| 157 |
+
<details>
|
| 158 |
+
<summary>Style description of <a href="https://www.libraryofshortstories.com/onlinereader/the-last-incantation">this story</a></summary>
|
| 159 |
+
<blockquote>
|
| 160 |
+
The story is written in a descriptive and evocative style, with a focus on the atmosphere and setting. The author uses vivid and detailed language to create a sense of place and time, and employs a variety of literary devices such as similes, metaphors, and allusions to enhance the mood and tone of the narrative. The sentence structure is varied, with a mix of short and long sentences that create a rhythmic flow to the prose.
|
| 161 |
+
</blockquote>
|
| 162 |
+
</details>
|
| 163 |
+
|
| 164 |
+
<details>
|
| 165 |
+
<summary>Style description of <a href="https://www.libraryofshortstories.com/onlinereader/the-pearl-of-love">this story</a></summary>
|
| 166 |
+
<blockquote>
|
| 167 |
+
The writing style is descriptive and evocative, with a focus on the beauty and grandeur of the Pearl of Love. The author uses vivid imagery and sensory details to create a rich and immersive atmosphere. The tone is reverential and contemplative, reflecting the prince's deep love for his queen and his dedication to creating a lasting monument to her memory.
|
| 168 |
+
</blockquote>
|
| 169 |
+
</details>
|
| 170 |
+
|
| 171 |
+
### Story description to chapters
|
| 172 |
+
|
| 173 |
+
- [Prompt guide](https://dreamgen.com/docs/models/opus/v1#task-story-description-to-chapter-descriptions)
|
| 174 |
+
- Input: A brief plot description and the desired number of chapters.
|
| 175 |
+
- Output: A description for each chapter.
|
| 176 |
+
|
| 177 |
+
### And more...
|
| 178 |
+
|
| 179 |
+
## Sampling params
|
| 180 |
+
|
| 181 |
+
For story-writing and role-play, I recommend "Min P" based sampling with `min_p` in the range `[0.01, 0.1]` and with `temperature` in the range `[0.5, 1.5]`, depending on your preferences. A good starting point would be `min_p=0.1; temperature=0.8`.
|
| 182 |
+
|
| 183 |
+
You may also benefit from setting presence, frequency and repetition penalties, especially at lower temperatures.
|
| 184 |
+
|
| 185 |
+
## Dataset
|
| 186 |
+
|
| 187 |
+
The fine-tuning dataset consisted of ~100M tokens of steerable story-writing, role-playing, writing-assistant and general-assistant examples. Each example was up to 31000 tokens long.
|
| 188 |
+
|
| 189 |
+
All story-writing and role-playing examples were based on human-written text.
|
| 190 |
+
|
| 191 |
+

|
| 192 |
+
|
| 193 |
+
## Running the model
|
| 194 |
+
|
| 195 |
+
The model is should be compatible with any software that supports the base model, but beware of prompting and tokenization.
|
| 196 |
+
|
| 197 |
+
I recommend using these model versions:
|
| 198 |
+
|
| 199 |
+
- 7B: [no quant (opus-v1.2-7b)](https://huggingface.co/dreamgen/opus-v1.2-7b)
|
| 200 |
+
- 34B: [no quant (opus-v1-34b)](https://huggingface.co/dreamgen/opus-v1-34b) or [awq (opus-v1-34b-awq)](https://huggingface.co/dreamgen/opus-v1-34b-awq)
|
| 201 |
+
- 34B: [no quant (opus-v1.2-70b)](https://huggingface.co/dreamgen/opus-v1.2-70b) or [awq (opus-v1.2-70b-awq)](https://huggingface.co/dreamgen/opus-v1.2-70b-awq)
|
| 202 |
+
|
| 203 |
+
### Running on DreamGen.com (free)
|
| 204 |
+
|
| 205 |
+
You can run the models on [dreamgen.com](https://dreamgen.com) for free — you can use the built-in UI for story-writing & role-playing, or use [the API](https://dreamgen.com/docs/api).
|
| 206 |
+
|
| 207 |
+
### Running Locally
|
| 208 |
+
|
| 209 |
+
- **Make sure your prompt is as close as possible to the Opus V1**
|
| 210 |
+
- Regardless of which backend you use, it's important that you format your prompt well and that the tokenization works correctly.
|
| 211 |
+
- [Read the prompt guide](https://dreamgen.com/docs/models/opus/v1)
|
| 212 |
+
- [Read the prompt formatting code](example/prompt/format.py)
|
| 213 |
+
- Make sure `<|im_start|>` and `<|im_end|>` are tokenized correctly
|
| 214 |
+
- **vLLM**
|
| 215 |
+
- [**Google Colab**](https://colab.research.google.com/drive/1J178fH6IdQOXNi-Njgdacf5QgAxsdT20?usp=sharing): This is a simple interactive Google Colab to do role-play with the 7B model, it should fit on the T4 GPU.
|
| 216 |
+
- [Code](example/prompt/interactive.py): This is simple script for interactive chat for one hard-coded scenario.
|
| 217 |
+
- **SillyTavern**
|
| 218 |
+
- [Official SillyTavern documentation for DreamGen](https://docs.sillytavern.app/usage/api-connections/dreamgen/) -- applies to both the API an local models
|
| 219 |
+
- SillyTavern (staging) comes with built-in DreamGen preset for RP
|
| 220 |
+
- Other presets can be found [here](https://huggingface.co/dreamgen/opus-v1.2-7b/tree/main/configs/silly_tavern), v2 kindly provided by @MarinaraSpaghetti
|
| 221 |
+
- Make sure to unselect `Skip special tokens`, otherwise it won't work
|
| 222 |
+
- This is just an attempt at approximating the Opus V1 prompt, it won't be perfect
|
| 223 |
+
- Character cards specifically rewritten for the built-in DreamGen preset:
|
| 224 |
+
- [Seraphina](configs/silly_tavern/cards/Seraphina.png) (based on the default Seraphina card)
|
| 225 |
+
- [Lara Lightland](configs/silly_tavern/cards/LaraLightland.png) (based on the card by Deffcolony)
|
| 226 |
+
- **LM Studio**
|
| 227 |
+
- [Config](configs/lmstudio/preset.json)
|
| 228 |
+
- Just like ChatML, just changed "assistant" to "text" role.
|
| 229 |
+
- **There's a bug** in LM Studio if you delete a message or click "Continue", [see here for details](https://discord.com/channels/1110598183144399058/1212665261128417280/1212665261128417280).
|
| 230 |
+
- **HuggingFace**
|
| 231 |
+
- [Chat template](tokenizer_config.json#L51)
|
| 232 |
+
- Just like ChatML, just changed "assistant" to "text" role.
|
| 233 |
+
|
| 234 |
+
## Known Issues
|
| 235 |
+
|
| 236 |
+
- **34B repetition**:
|
| 237 |
+
- The 34B sometimes gets stuck repeating the same word, or synonyms. This seems to be a common problem across various Yi 34B fine-tunes.
|
| 238 |
+
- **GGUF**:
|
| 239 |
+
- The tokenization might be messed up. Some users reported that `<|im_start|>` and `<|im_end|>` are tokenized as multiple tokens. Also llama.cpp may not tokenize correctly (the Yi tokenizer is subtly different from the Llama 2 tokenizer).
|
| 240 |
+
|
| 241 |
+
## License
|
| 242 |
+
|
| 243 |
+
- This model is intended for personal use only, other use is not permitted.
|
added_tokens.json
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"<|im_end|>": 32001,
|
| 3 |
+
"<|im_start|>": 32000
|
| 4 |
+
}
|
config.json
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "mistralai/Mistral-7B-Instruct-v0.2",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"MistralForCausalLM"
|
| 5 |
+
],
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"bos_token_id": 1,
|
| 8 |
+
"eos_token_id": 2,
|
| 9 |
+
"hidden_act": "silu",
|
| 10 |
+
"hidden_size": 4096,
|
| 11 |
+
"initializer_range": 0.02,
|
| 12 |
+
"intermediate_size": 14336,
|
| 13 |
+
"max_position_embeddings": 32768,
|
| 14 |
+
"model_type": "mistral",
|
| 15 |
+
"num_attention_heads": 32,
|
| 16 |
+
"num_hidden_layers": 32,
|
| 17 |
+
"num_key_value_heads": 8,
|
| 18 |
+
"rms_norm_eps": 1e-05,
|
| 19 |
+
"rope_theta": 1000000.0,
|
| 20 |
+
"sliding_window": null,
|
| 21 |
+
"tie_word_embeddings": false,
|
| 22 |
+
"torch_dtype": "bfloat16",
|
| 23 |
+
"transformers_version": "4.38.0.dev0",
|
| 24 |
+
"use_cache": false,
|
| 25 |
+
"vocab_size": 32002
|
| 26 |
+
}
|
configs/lmstudio/preset.json
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"name": "OpusV1StoryWriting",
|
| 3 |
+
"inference_params": {
|
| 4 |
+
"input_prefix": "<|im_end|>\n<|im_start|>user\n",
|
| 5 |
+
"input_suffix": "<|im_end|>\n<|im_start|>text\n",
|
| 6 |
+
"antiprompt": ["<|im_start|>", "<|im_end|>"],
|
| 7 |
+
"pre_prompt_prefix": "<|im_start|>system\n",
|
| 8 |
+
"pre_prompt_suffix": "",
|
| 9 |
+
"pre_prompt": "You are an intelligent, skilled, versatile writer.\n\nYour task is to write a story based on the information below.\n\n## Overall plot description:\n\n"
|
| 10 |
+
}
|
| 11 |
+
}
|
configs/silly_tavern/cards/LaraLightland.png
ADDED

|
configs/silly_tavern/cards/Seraphina.png
ADDED

|
Git LFS Details
|
configs/silly_tavern/settings_screenshot.webp
ADDED
|
configs/silly_tavern/v1/context_settings.json
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
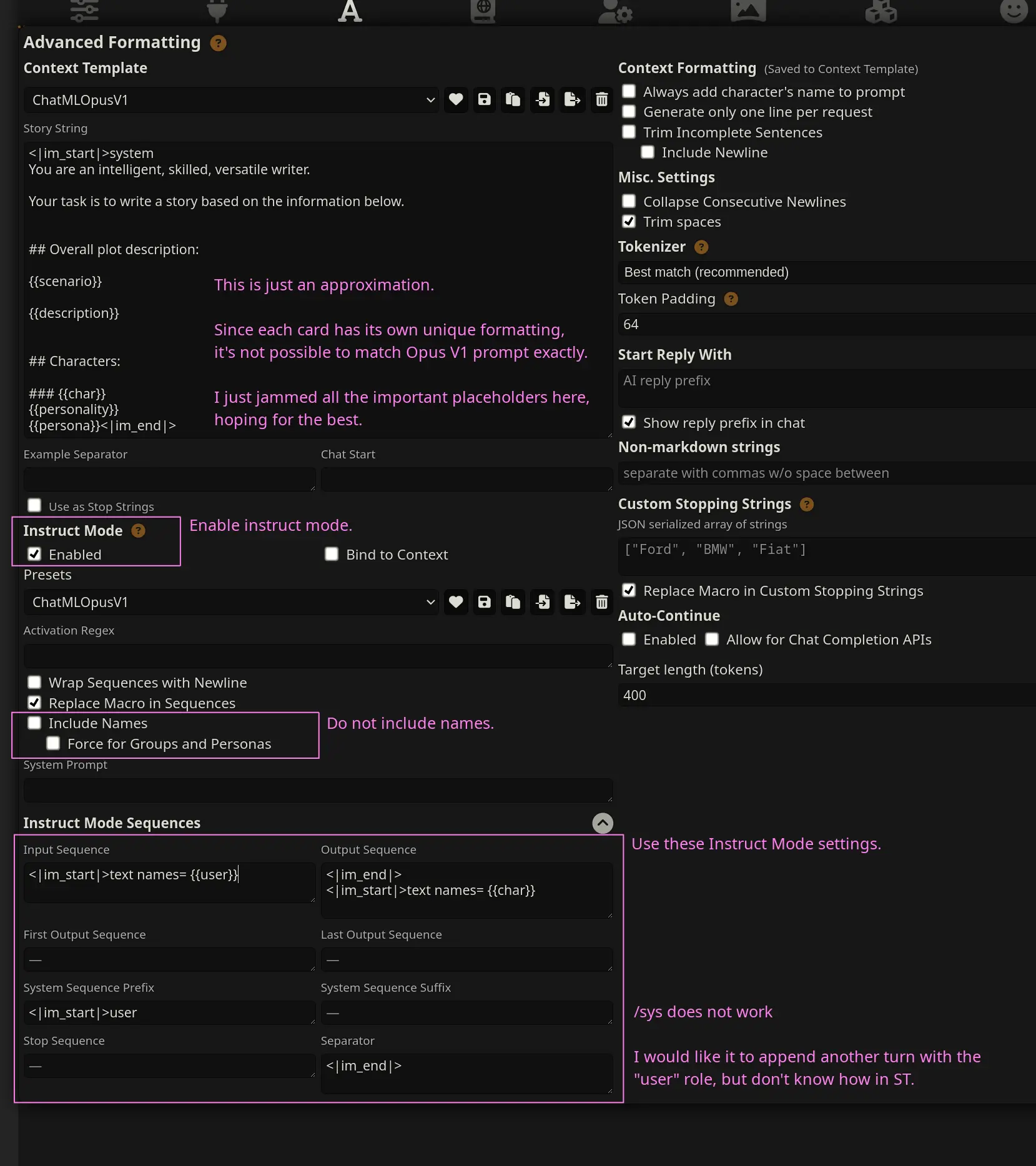
"story_string": "<|im_start|>system\nYou are an intelligent, skilled, versatile writer.\n\nYour task is to write a story based on the information below.\n\n\n## Overall plot description:\n\n{{scenario}}\n\n{{description}}\n\n\n## Characters:\n\n### {{char}}\n{{personality}}\n{{persona}}<|im_end|>",
|
| 3 |
+
"example_separator": "",
|
| 4 |
+
"chat_start": "",
|
| 5 |
+
"use_stop_strings": false,
|
| 6 |
+
"always_force_name2": false,
|
| 7 |
+
"trim_sentences": false,
|
| 8 |
+
"include_newline": false,
|
| 9 |
+
"single_line": false,
|
| 10 |
+
"name": "ChatMLOpusV1_ST2"
|
| 11 |
+
}
|
configs/silly_tavern/v1/instruct_mode_settings.json
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"system_prompt": "",
|
| 3 |
+
"input_sequence": "<|im_start|>text names= {{user}}\n",
|
| 4 |
+
"output_sequence": "<|im_end|>\n<|im_start|>text names= {{char}}\n",
|
| 5 |
+
"first_output_sequence": "",
|
| 6 |
+
"last_output_sequence": "",
|
| 7 |
+
"system_sequence_prefix": "",
|
| 8 |
+
"system_sequence_suffix": "",
|
| 9 |
+
"stop_sequence": "",
|
| 10 |
+
"separator_sequence": "<|im_end|>\n",
|
| 11 |
+
"wrap": false,
|
| 12 |
+
"macro": true,
|
| 13 |
+
"names": false,
|
| 14 |
+
"names_force_groups": false,
|
| 15 |
+
"activation_regex": "",
|
| 16 |
+
"name": "ChatMLOpusV1_ST1"
|
| 17 |
+
}
|
configs/silly_tavern/v2/context_settings.json
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"story_string": "<|im_start|>system\n{{#if system}}{{system}}\n\n\n{{/if}}## Overall plot description:\n\n{{#if wiBefore}}{{wiBefore}}\n\n{{/if}}{{#if scenario}}{{scenario}}\n\n\n{{/if}}## Characters:\n\n### {{char}}\n{{#if description}}{{description}}\n{{/if}}{{#if personality}}{{personality}}\n\n{{/if}}### {{user}}\n{{#if persona}}{{persona}}\n\n{{/if}}{{#if wiAfter}}{{wiAfter}}\n\n{{/if}}{{#if mesExamples}}## {{char}}'s example message:\n\n{{mesExamples}}{{/if}}",
|
| 3 |
+
"example_separator": "",
|
| 4 |
+
"chat_start": "",
|
| 5 |
+
"use_stop_strings": false,
|
| 6 |
+
"always_force_name2": false,
|
| 7 |
+
"trim_sentences": true,
|
| 8 |
+
"include_newline": false,
|
| 9 |
+
"single_line": false,
|
| 10 |
+
"name": "ChatMLOpusV1_ST2"
|
| 11 |
+
}
|
configs/silly_tavern/v2/instruct_mode_settings.json
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"system_prompt": "You are an intelligent, skilled, versatile writer.\n\nYour task is to write a role-play based on the information below.\n\n\n## Style description:\n\nThis role-play is written as a third-person introspective narrative in past tense. Scenes are described vividly, with great detail.",
|
| 3 |
+
"input_sequence": "<|im_end|>\n<|im_start|>text names= {{user}}\n",
|
| 4 |
+
"output_sequence": "<|im_end|>\n<|im_start|>text names= {{char}}\n",
|
| 5 |
+
"first_output_sequence": "",
|
| 6 |
+
"last_output_sequence": "<|im_end|>\n<|im_start|>user\nLength: 400 words\n{{char}} replies to {{user}} in detailed and elaborate way.<|im_end|>\n<|im_start|>text names= {{char}}\n",
|
| 7 |
+
"system_sequence_prefix": "",
|
| 8 |
+
"system_sequence_suffix": "",
|
| 9 |
+
"stop_sequence": "",
|
| 10 |
+
"separator_sequence": "",
|
| 11 |
+
"wrap": false,
|
| 12 |
+
"macro": true,
|
| 13 |
+
"names": false,
|
| 14 |
+
"names_force_groups": false,
|
| 15 |
+
"activation_regex": "",
|
| 16 |
+
"name": "ChatMLOpusV1_ST2"
|
| 17 |
+
}
|
example/interactive.py
ADDED
|
@@ -0,0 +1,129 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# python interactive.py
|
| 2 |
+
|
| 3 |
+
# %%
|
| 4 |
+
|
| 5 |
+
import fileinput
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
from vllm import LLM, SamplingParams
|
| 9 |
+
|
| 10 |
+
from prompt.format import (
|
| 11 |
+
format_opus_v1_prompt,
|
| 12 |
+
OpusV1Character,
|
| 13 |
+
OpusV1Prompt,
|
| 14 |
+
OpusV1StorySystemPrompt,
|
| 15 |
+
OpusV1Turn,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
# %%
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def main():
|
| 23 |
+
sampling_params = SamplingParams(
|
| 24 |
+
# I usually stay between 0.0 and 1.0, especially for the Yi models I found lower tends to be better.
|
| 25 |
+
# For assistant tasks, I usually use 0.0.
|
| 26 |
+
temperature=0.8,
|
| 27 |
+
min_p=0.05,
|
| 28 |
+
presence_penalty=0.1,
|
| 29 |
+
frequency_penalty=0.1,
|
| 30 |
+
repetition_penalty=1.1,
|
| 31 |
+
max_tokens=200,
|
| 32 |
+
ignore_eos=True,
|
| 33 |
+
skip_special_tokens=False,
|
| 34 |
+
spaces_between_special_tokens=False,
|
| 35 |
+
stop=["<|im_end|>"],
|
| 36 |
+
include_stop_str_in_output=False,
|
| 37 |
+
)
|
| 38 |
+
|
| 39 |
+
# Set max_model_len to fit in memory.
|
| 40 |
+
model = LLM(
|
| 41 |
+
"dreamgen/opus-v1.2-7b",
|
| 42 |
+
max_model_len=2000,
|
| 43 |
+
enforce_eager=True,
|
| 44 |
+
swap_space=0,
|
| 45 |
+
gpu_memory_utilization=0.85,
|
| 46 |
+
)
|
| 47 |
+
|
| 48 |
+
plot_description = """
|
| 49 |
+
This is a fanfiction from the Harry Potter universe. In this alternate reality, Harry Potter is evil and secretly siding with Slytherin.
|
| 50 |
+
Up until now, Harry was pretending to be friends with Hermione and Ron, that changes when he invites Hermione to his chambers where he tricks her to drink Amorentia, the most powerful love potion.
|
| 51 |
+
"""
|
| 52 |
+
|
| 53 |
+
char1 = OpusV1Character(
|
| 54 |
+
name="Harry Potter",
|
| 55 |
+
description="""Harry Potter in this fanfiction is secretly a member of Slytherin and is using his powers for evil rather than for good. Up until now, he was pretending to be friends with Hermione and Ron.""",
|
| 56 |
+
)
|
| 57 |
+
char2 = OpusV1Character(
|
| 58 |
+
name="Hermione Granger",
|
| 59 |
+
description="""Hermione appears just like in the original books.""",
|
| 60 |
+
)
|
| 61 |
+
|
| 62 |
+
story_prompt = OpusV1StorySystemPrompt(
|
| 63 |
+
plot_description=plot_description,
|
| 64 |
+
style_description="",
|
| 65 |
+
characters=[char1, char2],
|
| 66 |
+
)
|
| 67 |
+
|
| 68 |
+
turns = [
|
| 69 |
+
OpusV1Turn(
|
| 70 |
+
role="user",
|
| 71 |
+
content="""Harry invites Hermione into his chamber and offers her water, which Hermione happily accepts and drinks.""".strip(),
|
| 72 |
+
),
|
| 73 |
+
OpusV1Turn(
|
| 74 |
+
role="text",
|
| 75 |
+
names=[char1.name],
|
| 76 |
+
content="""“Come in,” said Harry, waving at the doorway behind Hermione’s back.""".strip(),
|
| 77 |
+
),
|
| 78 |
+
]
|
| 79 |
+
|
| 80 |
+
def run():
|
| 81 |
+
turns.append(OpusV1Turn(role="text", content="", names=[char2.name], open=True))
|
| 82 |
+
|
| 83 |
+
prompt = OpusV1Prompt(story=story_prompt, turns=turns)
|
| 84 |
+
|
| 85 |
+
output = model.generate(
|
| 86 |
+
format_opus_v1_prompt(prompt), sampling_params, use_tqdm=False
|
| 87 |
+
)
|
| 88 |
+
|
| 89 |
+
response = OpusV1Turn(
|
| 90 |
+
role="text", content=output[0].outputs[0].text.strip(), names=[char2.name]
|
| 91 |
+
)
|
| 92 |
+
turns.append(response)
|
| 93 |
+
print(pretty_turn(response), flush=True)
|
| 94 |
+
print(f"[{char1.name}]: ", end="", flush=True)
|
| 95 |
+
|
| 96 |
+
print("## Plot description:\n")
|
| 97 |
+
print(plot_description.strip() + "\n\n")
|
| 98 |
+
|
| 99 |
+
for turn in turns:
|
| 100 |
+
print(pretty_turn(turn))
|
| 101 |
+
|
| 102 |
+
run()
|
| 103 |
+
|
| 104 |
+
for line in fileinput.input():
|
| 105 |
+
line = line.strip()
|
| 106 |
+
if line.startswith("/ins"):
|
| 107 |
+
content = line[4:].strip()
|
| 108 |
+
role = "user"
|
| 109 |
+
names = []
|
| 110 |
+
else:
|
| 111 |
+
content = line
|
| 112 |
+
role = "text"
|
| 113 |
+
names = [char1.name]
|
| 114 |
+
|
| 115 |
+
turns.append(OpusV1Turn(role=role, content=content, names=names))
|
| 116 |
+
run()
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
def pretty_turn(turn):
|
| 120 |
+
if turn.role == "user":
|
| 121 |
+
return f"/ins {turn.content.strip()}"
|
| 122 |
+
else:
|
| 123 |
+
if len(turn.names) > 0:
|
| 124 |
+
return f"[{turn.names[0]}]: {turn.content.strip()}"
|
| 125 |
+
else:
|
| 126 |
+
return turn.content.strip()
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
main()
|
example/prompt/__init__.py
ADDED
|
File without changes
|
example/prompt/format.py
ADDED
|
@@ -0,0 +1,96 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# %%
|
| 2 |
+
from typing import Optional, List
|
| 3 |
+
from dataclasses import field, dataclass
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
@dataclass
|
| 7 |
+
class OpusV1Turn:
|
| 8 |
+
role: str
|
| 9 |
+
content: str
|
| 10 |
+
names: List[str] = field(default_factory=list)
|
| 11 |
+
# If set to true, will not append <|im_end|>, so the model will continue the turn.
|
| 12 |
+
# In RP you can for example use the following to force a specific character response:
|
| 13 |
+
# role="text"
|
| 14 |
+
# names=["Jack"]
|
| 15 |
+
# open="true"
|
| 16 |
+
open: bool = False
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
@dataclass
|
| 20 |
+
class OpusV1Character:
|
| 21 |
+
name: str
|
| 22 |
+
description: str
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
@dataclass
|
| 26 |
+
class OpusV1StorySystemPrompt:
|
| 27 |
+
format: str = "prose"
|
| 28 |
+
plot_description: str = ""
|
| 29 |
+
style_description: str = ""
|
| 30 |
+
characters: List[OpusV1Character] = field(default_factory=list)
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
@dataclass
|
| 34 |
+
class OpusV1Prompt:
|
| 35 |
+
story: Optional[OpusV1StorySystemPrompt] = None
|
| 36 |
+
turns: List[OpusV1Turn] = field(default_factory=list)
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def format_opus_v1_prompt(prompt) -> str:
|
| 40 |
+
turns = prompt.turns
|
| 41 |
+
if prompt.story is not None:
|
| 42 |
+
system = format_opus_v1_system_prompt(prompt.story)
|
| 43 |
+
turns = [OpusV1Turn(role="system", content=system)] + turns
|
| 44 |
+
|
| 45 |
+
parts = []
|
| 46 |
+
for i, turn in enumerate(turns):
|
| 47 |
+
assert turn.role in ["user", "text", "system", "assistant"]
|
| 48 |
+
assert turn.role != "system" or i == 0
|
| 49 |
+
|
| 50 |
+
is_last = i == len(turns) - 1
|
| 51 |
+
open = is_last and turn.open
|
| 52 |
+
parts.append(format_turn(turn.role, turn.content, turn.names, open=open))
|
| 53 |
+
return "".join(parts)
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def format_turn(
|
| 57 |
+
role: str, content: str, names: List[str] = [], open: bool = False
|
| 58 |
+
) -> str:
|
| 59 |
+
im_start = "<|im_start|>"
|
| 60 |
+
im_end = "<|im_end|>"
|
| 61 |
+
|
| 62 |
+
body = im_start + role
|
| 63 |
+
if len(names) > 0:
|
| 64 |
+
body += f" names= {'; '.join(names)}"
|
| 65 |
+
|
| 66 |
+
body += "\n"
|
| 67 |
+
if open:
|
| 68 |
+
return body + content.lstrip()
|
| 69 |
+
else:
|
| 70 |
+
return body + content.strip() + im_end + "\n"
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def format_opus_v1_system_prompt(prompt) -> str:
|
| 74 |
+
format_text = "story" if prompt.format == "prose" else "role-play"
|
| 75 |
+
system = f"""
|
| 76 |
+
You are an intelligent, skilled, versatile writer.
|
| 77 |
+
|
| 78 |
+
Your task is to write a {format_text} based on the information below.
|
| 79 |
+
|
| 80 |
+
Write the {format_text} as if it's a book.
|
| 81 |
+
""".strip()
|
| 82 |
+
|
| 83 |
+
if len(prompt.plot_description) > 0:
|
| 84 |
+
system += "\n\n\n## Plot description:\n\n"
|
| 85 |
+
system += prompt.plot_description.strip()
|
| 86 |
+
if len(prompt.style_description) > 0:
|
| 87 |
+
system += "\n\n\n## Style description:\n\n"
|
| 88 |
+
system += prompt.style_description.strip()
|
| 89 |
+
if len(prompt.characters) > 0:
|
| 90 |
+
system += "\n\n\n## Characters:\n\n"
|
| 91 |
+
for character in prompt.characters:
|
| 92 |
+
system += f"### {character.name}\n\n"
|
| 93 |
+
system += character.description.strip()
|
| 94 |
+
system += "\n\n"
|
| 95 |
+
|
| 96 |
+
return system.strip()
|
example/simple.py
ADDED
|
@@ -0,0 +1,132 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# python simple.py
|
| 2 |
+
|
| 3 |
+
# %%
|
| 4 |
+
|
| 5 |
+
from vllm import LLM, SamplingParams
|
| 6 |
+
|
| 7 |
+
from prompt.format import (
|
| 8 |
+
format_opus_v1_prompt,
|
| 9 |
+
OpusV1Character,
|
| 10 |
+
OpusV1Prompt,
|
| 11 |
+
OpusV1StorySystemPrompt,
|
| 12 |
+
OpusV1Turn,
|
| 13 |
+
)
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
# %%
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def build_story_prompt() -> OpusV1Prompt:
|
| 20 |
+
plot_description = """
|
| 21 |
+
This is a fanfiction from the Harry Potter universe. In this alternate reality, Harry Potter is evil and secretly siding with Slytherin.
|
| 22 |
+
Up until now, Harry was pretending to be friends with Hermione and Ron, that changes when he invites Hermione to his chambers where he tricks her to drink Amorentia, the most powerful love potion.
|
| 23 |
+
"""
|
| 24 |
+
|
| 25 |
+
harry_description = """
|
| 26 |
+
Harry Potter in this fanfiction is secretly a member of Slytherin and is using his powers for evil rather than for good. Up until now, he was pretending to be friends with Hermione and Ron.
|
| 27 |
+
"""
|
| 28 |
+
|
| 29 |
+
hermione_description = """
|
| 30 |
+
Hermione appears just like in the original books.
|
| 31 |
+
"""
|
| 32 |
+
|
| 33 |
+
story_prompt = OpusV1StorySystemPrompt(
|
| 34 |
+
plot_description=plot_description,
|
| 35 |
+
style_description="",
|
| 36 |
+
characters=[
|
| 37 |
+
OpusV1Character(name="Harry Potter", description=harry_description),
|
| 38 |
+
OpusV1Character(name="Hermione Granger", description=hermione_description),
|
| 39 |
+
],
|
| 40 |
+
)
|
| 41 |
+
|
| 42 |
+
return OpusV1Prompt(
|
| 43 |
+
story=story_prompt,
|
| 44 |
+
turns=[
|
| 45 |
+
OpusV1Turn(
|
| 46 |
+
role="user",
|
| 47 |
+
content="""
|
| 48 |
+
The story starts with Harry welcoming Hermione into his chambers, who he invited there earlier that day. He offers her water to drink, but it contains a love potion.
|
| 49 |
+
""".strip(),
|
| 50 |
+
),
|
| 51 |
+
OpusV1Turn(
|
| 52 |
+
role="text",
|
| 53 |
+
content="""
|
| 54 |
+
“Come in,” said Harry, waving at the doorway behind Hermione’s back.
|
| 55 |
+
|
| 56 |
+
“Hello?” she said, stepping inside, “what did you want me to come up here for?”
|
| 57 |
+
|
| 58 |
+
“Well, I thought we could get away from all the noise down there, have a chat about what we plan to do for Christmas…” Harry said, fumbling for words. He had never really been any good with girls. “But anyway, please, take a seat and let me get us some water!” he said, darting over to the sideboard.
|
| 59 |
+
|
| 60 |
+
He returned quickly with two glasses of water. Hermione took hers and thanked him, taking in a big gulp. As soon as she swallowed, Harry saw her eyes widen as her heart began beating wildly in her chest.
|
| 61 |
+
|
| 62 |
+
It worked! Harry thought, grinning to himself. Amorentia truly was the world’s best love potion, its effects lasting twice as long and being five times stronger.
|
| 63 |
+
""".strip(),
|
| 64 |
+
open=True,
|
| 65 |
+
),
|
| 66 |
+
],
|
| 67 |
+
)
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
def build_assistant_prompt() -> OpusV1Prompt:
|
| 71 |
+
return OpusV1Prompt(
|
| 72 |
+
turns=[
|
| 73 |
+
OpusV1Turn(
|
| 74 |
+
role="system",
|
| 75 |
+
content="You are an intelligent, knowledgeable, helpful, general-purpose assistant.",
|
| 76 |
+
),
|
| 77 |
+
OpusV1Turn(
|
| 78 |
+
role="user",
|
| 79 |
+
content="Give me a sentence where every word begins with 'S'",
|
| 80 |
+
),
|
| 81 |
+
]
|
| 82 |
+
)
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
# %%
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
def main():
|
| 89 |
+
sampling_params = SamplingParams(
|
| 90 |
+
# I usually stay between 0.0 and 1.0, especially for the Yi models I found lower tends to be better.
|
| 91 |
+
# For assistant tasks, I usually use 0.0.
|
| 92 |
+
temperature=0.0,
|
| 93 |
+
min_p=0.05,
|
| 94 |
+
presence_penalty=0.1,
|
| 95 |
+
frequency_penalty=0.1,
|
| 96 |
+
repetition_penalty=1.1,
|
| 97 |
+
max_tokens=200,
|
| 98 |
+
ignore_eos=True,
|
| 99 |
+
skip_special_tokens=False,
|
| 100 |
+
spaces_between_special_tokens=False,
|
| 101 |
+
)
|
| 102 |
+
|
| 103 |
+
# Set max_model_len to fit in memory.
|
| 104 |
+
model = LLM(
|
| 105 |
+
"dreamgen/opus-v1.2-7b",
|
| 106 |
+
max_model_len=2000,
|
| 107 |
+
enforce_eager=True,
|
| 108 |
+
swap_space=0,
|
| 109 |
+
gpu_memory_utilization=0.85,
|
| 110 |
+
)
|
| 111 |
+
|
| 112 |
+
story_prompt = build_story_prompt()
|
| 113 |
+
print(format_opus_v1_prompt(story_prompt))
|
| 114 |
+
|
| 115 |
+
output = model.generate(format_opus_v1_prompt(story_prompt), sampling_params)
|
| 116 |
+
print(output[0].outputs[0].text)
|
| 117 |
+
|
| 118 |
+
# Expected:
|
| 119 |
+
"""
|
| 120 |
+
It would make her fall deeply in love with him, and then he could use her to get what he wanted.
|
| 121 |
+
|
| 122 |
+
“Harry, what’s going on? You look so happy!” Hermione asked, smiling at him.
|
| 123 |
+
|
| 124 |
+
“Oh, well, I guess I am,” Harry replied, trying not to laugh. “I mean, I’ve always known that you were the one for me.”
|
| 125 |
+
|
| 126 |
+
“Really?” Hermione asked, blushing slightly. “I didn’t know that.”
|
| 127 |
+
|
| 128 |
+
“Yeah, I’ve always had feelings for you,” Harry said, leaning forward and placing his hand on top of hers. “And now that I’ve got you alone, I can finally tell you how much I care about you.”
|
| 129 |
+
"""
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
main()
|
generation_config.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 1,
|
| 4 |
+
"do_sample": true,
|
| 5 |
+
"eos_token_id": 2,
|
| 6 |
+
"transformers_version": "4.38.0.dev0"
|
| 7 |
+
}
|
model-00001-of-00003.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:be416417ca5c4df52ab8a75181d79537eb02b54d327553e47f4f869930252876
|
| 3 |
+
size 4943178720
|
model-00002-of-00003.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:caf454cd551ccadf92929e442ec07dd86354bddf8c582eb6bda760b8c475d3d7
|
| 3 |
+
size 4999819336
|
model-00003-of-00003.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:442d781228430f36c8b4d98f8df7a5dcc8ea04d0bcd53c1d9c7402e138c2e7b2
|
| 3 |
+
size 4540532728
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,298 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 14483496960
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"lm_head.weight": "model-00003-of-00003.safetensors",
|
| 7 |
+
"model.embed_tokens.weight": "model-00001-of-00003.safetensors",
|
| 8 |
+
"model.layers.0.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 9 |
+
"model.layers.0.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 10 |
+
"model.layers.0.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 11 |
+
"model.layers.0.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 12 |
+
"model.layers.0.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 13 |
+
"model.layers.0.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 14 |
+
"model.layers.0.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 15 |
+
"model.layers.0.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 16 |
+
"model.layers.0.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 17 |
+
"model.layers.1.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 18 |
+
"model.layers.1.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 19 |
+
"model.layers.1.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 20 |
+
"model.layers.1.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 21 |
+
"model.layers.1.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 22 |
+
"model.layers.1.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 23 |
+
"model.layers.1.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 24 |
+
"model.layers.1.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 25 |
+
"model.layers.1.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 26 |
+
"model.layers.10.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 27 |
+
"model.layers.10.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 28 |
+
"model.layers.10.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 29 |
+
"model.layers.10.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 30 |
+
"model.layers.10.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 31 |
+
"model.layers.10.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 32 |
+
"model.layers.10.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 33 |
+
"model.layers.10.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 34 |
+
"model.layers.10.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 35 |
+
"model.layers.11.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 36 |
+
"model.layers.11.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 37 |
+
"model.layers.11.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 38 |
+
"model.layers.11.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 39 |
+
"model.layers.11.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 40 |
+
"model.layers.11.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 41 |
+
"model.layers.11.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 42 |
+
"model.layers.11.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 43 |
+
"model.layers.11.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 44 |
+
"model.layers.12.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 45 |
+
"model.layers.12.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 46 |
+
"model.layers.12.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 47 |
+
"model.layers.12.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 48 |
+
"model.layers.12.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 49 |
+
"model.layers.12.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 50 |
+
"model.layers.12.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 51 |
+
"model.layers.12.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 52 |
+
"model.layers.12.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 53 |
+
"model.layers.13.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 54 |
+
"model.layers.13.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 55 |
+
"model.layers.13.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 56 |
+
"model.layers.13.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 57 |
+
"model.layers.13.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 58 |
+
"model.layers.13.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 59 |
+
"model.layers.13.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 60 |
+
"model.layers.13.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 61 |
+
"model.layers.13.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 62 |
+
"model.layers.14.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 63 |
+
"model.layers.14.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 64 |
+
"model.layers.14.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 65 |
+
"model.layers.14.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 66 |
+
"model.layers.14.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 67 |
+
"model.layers.14.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 68 |
+
"model.layers.14.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 69 |
+
"model.layers.14.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 70 |
+
"model.layers.14.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 71 |
+
"model.layers.15.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 72 |
+
"model.layers.15.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 73 |
+
"model.layers.15.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 74 |
+
"model.layers.15.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 75 |
+
"model.layers.15.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 76 |
+
"model.layers.15.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 77 |
+
"model.layers.15.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 78 |
+
"model.layers.15.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 79 |
+
"model.layers.15.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 80 |
+
"model.layers.16.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 81 |
+
"model.layers.16.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 82 |
+
"model.layers.16.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 83 |
+
"model.layers.16.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 84 |
+
"model.layers.16.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 85 |
+
"model.layers.16.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 86 |
+
"model.layers.16.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 87 |
+
"model.layers.16.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 88 |
+
"model.layers.16.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 89 |
+
"model.layers.17.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 90 |
+
"model.layers.17.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 91 |
+
"model.layers.17.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 92 |
+
"model.layers.17.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 93 |
+
"model.layers.17.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 94 |
+
"model.layers.17.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 95 |
+
"model.layers.17.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 96 |
+
"model.layers.17.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 97 |
+
"model.layers.17.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 98 |
+
"model.layers.18.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 99 |
+
"model.layers.18.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 100 |
+
"model.layers.18.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 101 |
+
"model.layers.18.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 102 |
+
"model.layers.18.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 103 |
+
"model.layers.18.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 104 |
+
"model.layers.18.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 105 |
+
"model.layers.18.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 106 |
+
"model.layers.18.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 107 |
+
"model.layers.19.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 108 |
+
"model.layers.19.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 109 |
+
"model.layers.19.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 110 |
+
"model.layers.19.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 111 |
+
"model.layers.19.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 112 |
+
"model.layers.19.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 113 |
+
"model.layers.19.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 114 |
+
"model.layers.19.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 115 |
+
"model.layers.19.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 116 |
+
"model.layers.2.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 117 |
+
"model.layers.2.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 118 |
+
"model.layers.2.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 119 |
+
"model.layers.2.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 120 |
+
"model.layers.2.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 121 |
+
"model.layers.2.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 122 |
+
"model.layers.2.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 123 |
+
"model.layers.2.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 124 |
+
"model.layers.2.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 125 |
+
"model.layers.20.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 126 |
+
"model.layers.20.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 127 |
+
"model.layers.20.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 128 |
+
"model.layers.20.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 129 |
+
"model.layers.20.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 130 |
+
"model.layers.20.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 131 |
+
"model.layers.20.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 132 |
+
"model.layers.20.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 133 |
+
"model.layers.20.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 134 |
+
"model.layers.21.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 135 |
+
"model.layers.21.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 136 |
+
"model.layers.21.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 137 |
+
"model.layers.21.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 138 |
+
"model.layers.21.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 139 |
+
"model.layers.21.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 140 |
+
"model.layers.21.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 141 |
+
"model.layers.21.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 142 |
+
"model.layers.21.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 143 |
+
"model.layers.22.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 144 |
+
"model.layers.22.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 145 |
+
"model.layers.22.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 146 |
+
"model.layers.22.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 147 |
+
"model.layers.22.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 148 |
+
"model.layers.22.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 149 |
+
"model.layers.22.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 150 |
+
"model.layers.22.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 151 |
+
"model.layers.22.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 152 |
+
"model.layers.23.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 153 |
+
"model.layers.23.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 154 |
+
"model.layers.23.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 155 |
+
"model.layers.23.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 156 |
+
"model.layers.23.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 157 |
+
"model.layers.23.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 158 |
+
"model.layers.23.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 159 |
+
"model.layers.23.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 160 |
+
"model.layers.23.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 161 |
+
"model.layers.24.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 162 |
+
"model.layers.24.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 163 |
+
"model.layers.24.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 164 |
+
"model.layers.24.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 165 |
+
"model.layers.24.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 166 |
+
"model.layers.24.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 167 |
+
"model.layers.24.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 168 |
+
"model.layers.24.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 169 |
+
"model.layers.24.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 170 |
+
"model.layers.25.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 171 |
+
"model.layers.25.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 172 |
+
"model.layers.25.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 173 |
+
"model.layers.25.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 174 |
+
"model.layers.25.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 175 |
+
"model.layers.25.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 176 |
+
"model.layers.25.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 177 |
+
"model.layers.25.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 178 |
+
"model.layers.25.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 179 |
+
"model.layers.26.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 180 |
+
"model.layers.26.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 181 |
+
"model.layers.26.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 182 |
+
"model.layers.26.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 183 |
+
"model.layers.26.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 184 |
+
"model.layers.26.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 185 |
+
"model.layers.26.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 186 |
+
"model.layers.26.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 187 |
+
"model.layers.26.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 188 |
+
"model.layers.27.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 189 |
+
"model.layers.27.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 190 |
+
"model.layers.27.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 191 |
+
"model.layers.27.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 192 |
+
"model.layers.27.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 193 |
+
"model.layers.27.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 194 |
+
"model.layers.27.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 195 |
+
"model.layers.27.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 196 |
+
"model.layers.27.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 197 |
+
"model.layers.28.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 198 |
+
"model.layers.28.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 199 |
+
"model.layers.28.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 200 |
+
"model.layers.28.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 201 |
+
"model.layers.28.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 202 |
+
"model.layers.28.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 203 |
+
"model.layers.28.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 204 |
+
"model.layers.28.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 205 |
+
"model.layers.28.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 206 |
+
"model.layers.29.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 207 |
+
"model.layers.29.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 208 |
+
"model.layers.29.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 209 |
+
"model.layers.29.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 210 |
+
"model.layers.29.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 211 |
+
"model.layers.29.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 212 |
+
"model.layers.29.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 213 |
+
"model.layers.29.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 214 |
+
"model.layers.29.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 215 |
+
"model.layers.3.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 216 |
+
"model.layers.3.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 217 |
+
"model.layers.3.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 218 |
+
"model.layers.3.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 219 |
+
"model.layers.3.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 220 |
+
"model.layers.3.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 221 |
+
"model.layers.3.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 222 |
+
"model.layers.3.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 223 |
+
"model.layers.3.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 224 |
+
"model.layers.30.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 225 |
+
"model.layers.30.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 226 |
+
"model.layers.30.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 227 |
+
"model.layers.30.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 228 |
+
"model.layers.30.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 229 |
+
"model.layers.30.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 230 |
+
"model.layers.30.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 231 |
+
"model.layers.30.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 232 |
+
"model.layers.30.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 233 |
+
"model.layers.31.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 234 |
+
"model.layers.31.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 235 |
+
"model.layers.31.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 236 |
+
"model.layers.31.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 237 |
+
"model.layers.31.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 238 |
+
"model.layers.31.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 239 |
+
"model.layers.31.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 240 |
+
"model.layers.31.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 241 |
+
"model.layers.31.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 242 |
+
"model.layers.4.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 243 |
+
"model.layers.4.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 244 |
+
"model.layers.4.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 245 |
+
"model.layers.4.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 246 |
+
"model.layers.4.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 247 |
+
"model.layers.4.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 248 |
+
"model.layers.4.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 249 |
+
"model.layers.4.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 250 |
+
"model.layers.4.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 251 |
+
"model.layers.5.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 252 |
+
"model.layers.5.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 253 |
+
"model.layers.5.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 254 |
+
"model.layers.5.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 255 |
+
"model.layers.5.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 256 |
+
"model.layers.5.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 257 |
+
"model.layers.5.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 258 |
+
"model.layers.5.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 259 |
+
"model.layers.5.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 260 |
+
"model.layers.6.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 261 |
+
"model.layers.6.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 262 |
+
"model.layers.6.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 263 |
+
"model.layers.6.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 264 |
+
"model.layers.6.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 265 |
+
"model.layers.6.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 266 |
+
"model.layers.6.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 267 |
+
"model.layers.6.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 268 |
+
"model.layers.6.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 269 |
+
"model.layers.7.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 270 |
+
"model.layers.7.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 271 |
+
"model.layers.7.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 272 |
+
"model.layers.7.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 273 |
+
"model.layers.7.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 274 |
+
"model.layers.7.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 275 |
+
"model.layers.7.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 276 |
+
"model.layers.7.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 277 |
+
"model.layers.7.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 278 |
+
"model.layers.8.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 279 |
+
"model.layers.8.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 280 |
+
"model.layers.8.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 281 |
+
"model.layers.8.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 282 |
+
"model.layers.8.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 283 |
+
"model.layers.8.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 284 |
+
"model.layers.8.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 285 |
+
"model.layers.8.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 286 |
+
"model.layers.8.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 287 |
+
"model.layers.9.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 288 |
+
"model.layers.9.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 289 |
+
"model.layers.9.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 290 |
+
"model.layers.9.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 291 |
+
"model.layers.9.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 292 |
+
"model.layers.9.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 293 |
+
"model.layers.9.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 294 |
+
"model.layers.9.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 295 |
+
"model.layers.9.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 296 |
+
"model.norm.weight": "model-00003-of-00003.safetensors"
|
| 297 |
+
}
|
| 298 |
+
}
|
pytorch_model.bin.index.json
ADDED
|
@@ -0,0 +1,298 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 14483496960
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"lm_head.weight": "pytorch_model-00003-of-00003.bin",
|
| 7 |
+
"model.embed_tokens.weight": "pytorch_model-00001-of-00003.bin",
|
| 8 |
+
"model.layers.0.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 9 |
+
"model.layers.0.mlp.down_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 10 |
+
"model.layers.0.mlp.gate_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 11 |
+
"model.layers.0.mlp.up_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 12 |
+
"model.layers.0.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 13 |
+
"model.layers.0.self_attn.k_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 14 |
+
"model.layers.0.self_attn.o_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 15 |
+
"model.layers.0.self_attn.q_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 16 |
+
"model.layers.0.self_attn.v_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 17 |
+
"model.layers.1.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 18 |
+
"model.layers.1.mlp.down_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 19 |
+
"model.layers.1.mlp.gate_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 20 |
+
"model.layers.1.mlp.up_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 21 |
+
"model.layers.1.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 22 |
+
"model.layers.1.self_attn.k_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 23 |
+
"model.layers.1.self_attn.o_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 24 |
+
"model.layers.1.self_attn.q_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 25 |
+
"model.layers.1.self_attn.v_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 26 |
+
"model.layers.10.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 27 |
+
"model.layers.10.mlp.down_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 28 |
+
"model.layers.10.mlp.gate_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 29 |
+
"model.layers.10.mlp.up_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 30 |
+
"model.layers.10.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 31 |
+
"model.layers.10.self_attn.k_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 32 |
+
"model.layers.10.self_attn.o_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 33 |
+
"model.layers.10.self_attn.q_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 34 |
+
"model.layers.10.self_attn.v_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 35 |
+
"model.layers.11.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 36 |
+
"model.layers.11.mlp.down_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 37 |
+
"model.layers.11.mlp.gate_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 38 |
+
"model.layers.11.mlp.up_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 39 |
+
"model.layers.11.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 40 |
+
"model.layers.11.self_attn.k_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 41 |
+
"model.layers.11.self_attn.o_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 42 |
+
"model.layers.11.self_attn.q_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 43 |
+
"model.layers.11.self_attn.v_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 44 |
+
"model.layers.12.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 45 |
+
"model.layers.12.mlp.down_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 46 |
+
"model.layers.12.mlp.gate_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 47 |
+
"model.layers.12.mlp.up_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 48 |
+
"model.layers.12.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 49 |
+
"model.layers.12.self_attn.k_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 50 |
+
"model.layers.12.self_attn.o_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 51 |
+
"model.layers.12.self_attn.q_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 52 |
+
"model.layers.12.self_attn.v_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 53 |
+
"model.layers.13.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 54 |
+
"model.layers.13.mlp.down_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 55 |
+
"model.layers.13.mlp.gate_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 56 |
+
"model.layers.13.mlp.up_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 57 |
+
"model.layers.13.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 58 |
+
"model.layers.13.self_attn.k_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 59 |
+
"model.layers.13.self_attn.o_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 60 |
+
"model.layers.13.self_attn.q_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 61 |
+
"model.layers.13.self_attn.v_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 62 |
+
"model.layers.14.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 63 |
+
"model.layers.14.mlp.down_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 64 |
+
"model.layers.14.mlp.gate_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 65 |
+
"model.layers.14.mlp.up_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 66 |
+
"model.layers.14.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 67 |
+
"model.layers.14.self_attn.k_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 68 |
+
"model.layers.14.self_attn.o_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 69 |
+
"model.layers.14.self_attn.q_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 70 |
+
"model.layers.14.self_attn.v_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 71 |
+
"model.layers.15.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 72 |
+
"model.layers.15.mlp.down_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 73 |
+
"model.layers.15.mlp.gate_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 74 |
+
"model.layers.15.mlp.up_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 75 |
+
"model.layers.15.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 76 |
+
"model.layers.15.self_attn.k_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 77 |
+
"model.layers.15.self_attn.o_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 78 |
+
"model.layers.15.self_attn.q_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 79 |
+
"model.layers.15.self_attn.v_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 80 |
+
"model.layers.16.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 81 |
+
"model.layers.16.mlp.down_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 82 |
+
"model.layers.16.mlp.gate_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 83 |
+
"model.layers.16.mlp.up_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 84 |
+
"model.layers.16.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 85 |
+
"model.layers.16.self_attn.k_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 86 |
+
"model.layers.16.self_attn.o_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 87 |
+
"model.layers.16.self_attn.q_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 88 |
+
"model.layers.16.self_attn.v_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 89 |
+
"model.layers.17.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 90 |
+
"model.layers.17.mlp.down_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 91 |
+
"model.layers.17.mlp.gate_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 92 |
+
"model.layers.17.mlp.up_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 93 |
+
"model.layers.17.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 94 |
+
"model.layers.17.self_attn.k_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 95 |
+
"model.layers.17.self_attn.o_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 96 |
+
"model.layers.17.self_attn.q_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 97 |
+
"model.layers.17.self_attn.v_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 98 |
+
"model.layers.18.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 99 |
+
"model.layers.18.mlp.down_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 100 |
+
"model.layers.18.mlp.gate_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 101 |
+
"model.layers.18.mlp.up_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 102 |
+
"model.layers.18.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 103 |
+
"model.layers.18.self_attn.k_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 104 |
+
"model.layers.18.self_attn.o_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 105 |
+
"model.layers.18.self_attn.q_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 106 |
+
"model.layers.18.self_attn.v_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 107 |
+
"model.layers.19.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 108 |
+
"model.layers.19.mlp.down_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 109 |
+
"model.layers.19.mlp.gate_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 110 |
+
"model.layers.19.mlp.up_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 111 |
+
"model.layers.19.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 112 |
+
"model.layers.19.self_attn.k_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 113 |
+
"model.layers.19.self_attn.o_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 114 |
+
"model.layers.19.self_attn.q_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 115 |
+
"model.layers.19.self_attn.v_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 116 |
+
"model.layers.2.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 117 |
+
"model.layers.2.mlp.down_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 118 |
+
"model.layers.2.mlp.gate_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 119 |
+
"model.layers.2.mlp.up_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 120 |
+
"model.layers.2.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 121 |
+
"model.layers.2.self_attn.k_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 122 |
+
"model.layers.2.self_attn.o_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 123 |
+
"model.layers.2.self_attn.q_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 124 |
+
"model.layers.2.self_attn.v_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 125 |
+
"model.layers.20.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 126 |
+
"model.layers.20.mlp.down_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 127 |
+
"model.layers.20.mlp.gate_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 128 |
+
"model.layers.20.mlp.up_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 129 |
+
"model.layers.20.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 130 |
+
"model.layers.20.self_attn.k_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 131 |
+
"model.layers.20.self_attn.o_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 132 |
+
"model.layers.20.self_attn.q_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 133 |
+
"model.layers.20.self_attn.v_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 134 |
+
"model.layers.21.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 135 |
+
"model.layers.21.mlp.down_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 136 |
+
"model.layers.21.mlp.gate_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 137 |
+
"model.layers.21.mlp.up_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 138 |
+
"model.layers.21.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 139 |
+
"model.layers.21.self_attn.k_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 140 |
+
"model.layers.21.self_attn.o_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 141 |
+
"model.layers.21.self_attn.q_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 142 |
+
"model.layers.21.self_attn.v_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 143 |
+
"model.layers.22.input_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 144 |
+
"model.layers.22.mlp.down_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 145 |
+
"model.layers.22.mlp.gate_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 146 |
+
"model.layers.22.mlp.up_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 147 |
+
"model.layers.22.post_attention_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 148 |
+
"model.layers.22.self_attn.k_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 149 |
+
"model.layers.22.self_attn.o_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 150 |
+
"model.layers.22.self_attn.q_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 151 |
+
"model.layers.22.self_attn.v_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 152 |
+
"model.layers.23.input_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 153 |
+
"model.layers.23.mlp.down_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 154 |
+
"model.layers.23.mlp.gate_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 155 |
+
"model.layers.23.mlp.up_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 156 |
+
"model.layers.23.post_attention_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 157 |
+
"model.layers.23.self_attn.k_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 158 |
+
"model.layers.23.self_attn.o_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 159 |
+
"model.layers.23.self_attn.q_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 160 |
+
"model.layers.23.self_attn.v_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 161 |
+
"model.layers.24.input_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 162 |
+
"model.layers.24.mlp.down_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 163 |
+
"model.layers.24.mlp.gate_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 164 |
+
"model.layers.24.mlp.up_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 165 |
+
"model.layers.24.post_attention_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 166 |
+
"model.layers.24.self_attn.k_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 167 |
+
"model.layers.24.self_attn.o_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 168 |
+
"model.layers.24.self_attn.q_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 169 |
+
"model.layers.24.self_attn.v_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 170 |
+
"model.layers.25.input_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 171 |
+
"model.layers.25.mlp.down_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 172 |
+
"model.layers.25.mlp.gate_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 173 |
+
"model.layers.25.mlp.up_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 174 |
+
"model.layers.25.post_attention_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 175 |
+
"model.layers.25.self_attn.k_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 176 |
+
"model.layers.25.self_attn.o_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 177 |
+
"model.layers.25.self_attn.q_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 178 |
+
"model.layers.25.self_attn.v_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 179 |
+
"model.layers.26.input_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 180 |
+
"model.layers.26.mlp.down_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 181 |
+
"model.layers.26.mlp.gate_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 182 |
+
"model.layers.26.mlp.up_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 183 |
+
"model.layers.26.post_attention_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 184 |
+
"model.layers.26.self_attn.k_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 185 |
+
"model.layers.26.self_attn.o_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 186 |
+
"model.layers.26.self_attn.q_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 187 |
+
"model.layers.26.self_attn.v_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 188 |
+
"model.layers.27.input_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 189 |
+
"model.layers.27.mlp.down_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 190 |
+
"model.layers.27.mlp.gate_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 191 |
+
"model.layers.27.mlp.up_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 192 |
+
"model.layers.27.post_attention_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 193 |
+
"model.layers.27.self_attn.k_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 194 |
+
"model.layers.27.self_attn.o_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 195 |
+
"model.layers.27.self_attn.q_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 196 |
+
"model.layers.27.self_attn.v_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 197 |
+
"model.layers.28.input_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 198 |
+
"model.layers.28.mlp.down_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 199 |
+
"model.layers.28.mlp.gate_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 200 |
+
"model.layers.28.mlp.up_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 201 |
+
"model.layers.28.post_attention_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 202 |
+
"model.layers.28.self_attn.k_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 203 |
+
"model.layers.28.self_attn.o_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 204 |
+
"model.layers.28.self_attn.q_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 205 |
+
"model.layers.28.self_attn.v_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 206 |
+
"model.layers.29.input_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 207 |
+
"model.layers.29.mlp.down_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 208 |
+
"model.layers.29.mlp.gate_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 209 |
+
"model.layers.29.mlp.up_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 210 |
+
"model.layers.29.post_attention_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 211 |
+
"model.layers.29.self_attn.k_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 212 |
+
"model.layers.29.self_attn.o_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 213 |
+
"model.layers.29.self_attn.q_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 214 |
+
"model.layers.29.self_attn.v_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 215 |
+
"model.layers.3.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 216 |
+
"model.layers.3.mlp.down_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 217 |
+
"model.layers.3.mlp.gate_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 218 |
+
"model.layers.3.mlp.up_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 219 |
+
"model.layers.3.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 220 |
+
"model.layers.3.self_attn.k_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 221 |
+
"model.layers.3.self_attn.o_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 222 |
+
"model.layers.3.self_attn.q_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 223 |
+
"model.layers.3.self_attn.v_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 224 |
+
"model.layers.30.input_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 225 |
+
"model.layers.30.mlp.down_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 226 |
+
"model.layers.30.mlp.gate_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 227 |
+
"model.layers.30.mlp.up_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 228 |
+
"model.layers.30.post_attention_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 229 |
+
"model.layers.30.self_attn.k_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 230 |
+
"model.layers.30.self_attn.o_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 231 |
+
"model.layers.30.self_attn.q_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 232 |
+
"model.layers.30.self_attn.v_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 233 |
+
"model.layers.31.input_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 234 |
+
"model.layers.31.mlp.down_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 235 |
+
"model.layers.31.mlp.gate_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 236 |
+
"model.layers.31.mlp.up_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 237 |
+
"model.layers.31.post_attention_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 238 |
+
"model.layers.31.self_attn.k_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 239 |
+
"model.layers.31.self_attn.o_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 240 |
+
"model.layers.31.self_attn.q_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 241 |
+
"model.layers.31.self_attn.v_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 242 |
+
"model.layers.4.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 243 |
+
"model.layers.4.mlp.down_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 244 |
+
"model.layers.4.mlp.gate_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 245 |
+
"model.layers.4.mlp.up_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 246 |
+
"model.layers.4.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 247 |
+
"model.layers.4.self_attn.k_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 248 |
+
"model.layers.4.self_attn.o_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 249 |
+
"model.layers.4.self_attn.q_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 250 |
+
"model.layers.4.self_attn.v_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 251 |
+
"model.layers.5.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 252 |
+
"model.layers.5.mlp.down_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 253 |
+
"model.layers.5.mlp.gate_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 254 |
+
"model.layers.5.mlp.up_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 255 |
+
"model.layers.5.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 256 |
+
"model.layers.5.self_attn.k_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 257 |
+
"model.layers.5.self_attn.o_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 258 |
+
"model.layers.5.self_attn.q_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 259 |
+
"model.layers.5.self_attn.v_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 260 |
+
"model.layers.6.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 261 |
+
"model.layers.6.mlp.down_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 262 |
+
"model.layers.6.mlp.gate_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 263 |
+
"model.layers.6.mlp.up_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 264 |
+
"model.layers.6.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 265 |
+
"model.layers.6.self_attn.k_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 266 |
+
"model.layers.6.self_attn.o_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 267 |
+
"model.layers.6.self_attn.q_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 268 |
+
"model.layers.6.self_attn.v_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 269 |
+
"model.layers.7.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 270 |
+
"model.layers.7.mlp.down_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 271 |
+
"model.layers.7.mlp.gate_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 272 |
+
"model.layers.7.mlp.up_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 273 |
+
"model.layers.7.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 274 |
+
"model.layers.7.self_attn.k_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 275 |
+
"model.layers.7.self_attn.o_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 276 |
+
"model.layers.7.self_attn.q_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 277 |
+
"model.layers.7.self_attn.v_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 278 |
+
"model.layers.8.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 279 |
+
"model.layers.8.mlp.down_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 280 |
+
"model.layers.8.mlp.gate_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 281 |
+
"model.layers.8.mlp.up_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 282 |
+
"model.layers.8.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 283 |
+
"model.layers.8.self_attn.k_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 284 |
+
"model.layers.8.self_attn.o_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 285 |
+
"model.layers.8.self_attn.q_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 286 |
+
"model.layers.8.self_attn.v_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 287 |
+
"model.layers.9.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 288 |
+
"model.layers.9.mlp.down_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 289 |
+
"model.layers.9.mlp.gate_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 290 |
+
"model.layers.9.mlp.up_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 291 |
+
"model.layers.9.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 292 |
+
"model.layers.9.self_attn.k_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 293 |
+
"model.layers.9.self_attn.o_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 294 |
+
"model.layers.9.self_attn.q_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 295 |
+
"model.layers.9.self_attn.v_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 296 |
+
"model.norm.weight": "pytorch_model-00003-of-00003.bin"
|
| 297 |
+
}
|
| 298 |
+
}
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
{
|
| 4 |
+
"content": "<|im_start|>",
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"normalized": false,
|
| 7 |
+
"rstrip": false,
|
| 8 |
+
"single_word": false
|
| 9 |
+
},
|
| 10 |
+
{
|
| 11 |
+
"content": "<|im_end|>",
|
| 12 |
+
"lstrip": false,
|
| 13 |
+
"normalized": false,
|
| 14 |
+
"rstrip": false,
|
| 15 |
+
"single_word": false
|
| 16 |
+
}
|
| 17 |
+
],
|
| 18 |
+
"bos_token": {
|
| 19 |
+
"content": "<s>",
|
| 20 |
+
"lstrip": false,
|
| 21 |
+
"normalized": false,
|
| 22 |
+
"rstrip": false,
|
| 23 |
+
"single_word": false
|
| 24 |
+
},
|
| 25 |
+
"eos_token": {
|
| 26 |
+
"content": "</s>",
|
| 27 |
+
"lstrip": false,
|
| 28 |
+
"normalized": false,
|
| 29 |
+
"rstrip": false,
|
| 30 |
+
"single_word": false
|
| 31 |
+
},
|
| 32 |
+
"unk_token": {
|
| 33 |
+
"content": "<unk>",
|
| 34 |
+
"lstrip": false,
|
| 35 |
+
"normalized": false,
|
| 36 |
+
"rstrip": false,
|
| 37 |
+
"single_word": false
|
| 38 |
+
}
|
| 39 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dadfd56d766715c61d2ef780a525ab43b8e6da4de6865bda3d95fdef5e134055
|
| 3 |
+
size 493443
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,62 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": true,
|
| 3 |
+
"add_eos_token": false,
|
| 4 |
+
"added_tokens_decoder": {
|
| 5 |
+
"0": {
|
| 6 |
+
"content": "<unk>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": false,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false,
|
| 11 |
+
"special": true
|
| 12 |
+
},
|
| 13 |
+
"1": {
|
| 14 |
+
"content": "<s>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false,
|
| 19 |
+
"special": true
|
| 20 |
+
},
|
| 21 |
+
"2": {
|
| 22 |
+
"content": "</s>",
|
| 23 |
+
"lstrip": false,
|
| 24 |
+
"normalized": false,
|
| 25 |
+
"rstrip": false,
|
| 26 |
+
"single_word": false,
|
| 27 |
+
"special": true
|
| 28 |
+
},
|
| 29 |
+
"32000": {
|
| 30 |
+
"content": "<|im_start|>",
|
| 31 |
+
"lstrip": false,
|
| 32 |
+
"normalized": false,
|
| 33 |
+
"rstrip": false,
|
| 34 |
+
"single_word": false,
|
| 35 |
+
"special": true
|
| 36 |
+
},
|
| 37 |
+
"32001": {
|
| 38 |
+
"content": "<|im_end|>",
|
| 39 |
+
"lstrip": false,
|
| 40 |
+
"normalized": false,
|
| 41 |
+
"rstrip": false,
|
| 42 |
+
"single_word": false,
|
| 43 |
+
"special": true
|
| 44 |
+
}
|
| 45 |
+
},
|
| 46 |
+
"additional_special_tokens": [
|
| 47 |
+
"<|im_start|>",
|
| 48 |
+
"<|im_end|>"
|
| 49 |
+
],
|
| 50 |
+
"bos_token": "<s>",
|
| 51 |
+
"chat_template": "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{{'<|im_start|>'}}{% if message['role']=='assistant' %}{{'text'}}{% else %}{{message['role']}}{% endif %}{{'\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>text\n' }}{% endif %}",
|
| 52 |
+
"clean_up_tokenization_spaces": false,
|
| 53 |
+
"eos_token": "</s>",
|
| 54 |
+
"legacy": true,
|
| 55 |
+
"model_max_length": 1000000000000000019884624838656,
|
| 56 |
+
"pad_token": null,
|
| 57 |
+
"sp_model_kwargs": {},
|
| 58 |
+
"spaces_between_special_tokens": false,
|
| 59 |
+
"tokenizer_class": "LlamaTokenizer",
|
| 60 |
+
"unk_token": "<unk>",
|
| 61 |
+
"use_default_system_prompt": false
|
| 62 |
+
}
|