---
license: apache-2.0
---
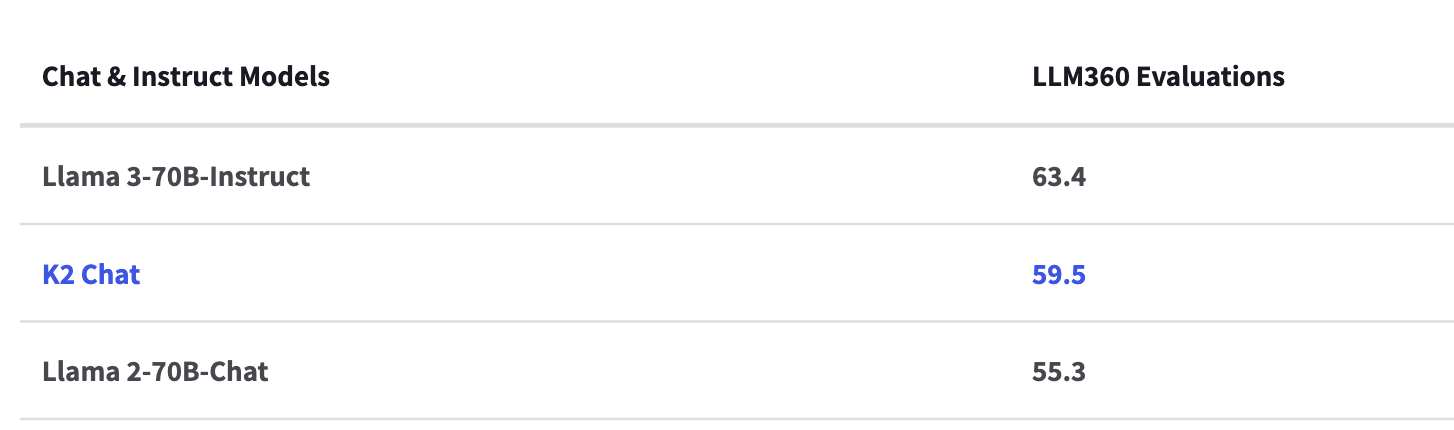
# K2-Chat: a fully-reproducible large language model outperforming Llama 2 70B using 35% less compute
blurb
 ## Loading K2-Chat
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("LLM360/K2-Chat")
model = AutoModelForCausalLM.from_pretrained("LLM360/K2-Chat")
prompt = '<|beginofuser|>what is the highest mountain on earth?<|beginofsystem|>'
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
gen_tokens = model.generate(input_ids, do_sample=True, max_new_tokens=128)
print("-"*20 + "Output for model" + 20 * '-')
print(tokenizer.batch_decode(gen_tokens)[0])
```
## Loading K2-Chat
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("LLM360/K2-Chat")
model = AutoModelForCausalLM.from_pretrained("LLM360/K2-Chat")
prompt = '<|beginofuser|>what is the highest mountain on earth?<|beginofsystem|>'
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
gen_tokens = model.generate(input_ids, do_sample=True, max_new_tokens=128)
print("-"*20 + "Output for model" + 20 * '-')
print(tokenizer.batch_decode(gen_tokens)[0])
```