
Commit
•
b0011e7
1
Parent(s):
b44d453
Update README.md
Browse files
README.md
CHANGED
|
@@ -1,71 +1,173 @@
|
|
| 1 |
---
|
| 2 |
-
|
|
|
|
| 3 |
tags:
|
| 4 |
-
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
|
|
|
| 11 |
---
|
| 12 |
|
| 13 |
-
|
| 14 |
-
|
| 15 |
-
|
| 16 |
-
|
| 17 |
-
|
| 18 |
-
|
| 19 |
-
|
| 20 |
-
|
| 21 |
-
|
| 22 |
-
|
| 23 |
-
|
| 24 |
-
|
| 25 |
-
|
| 26 |
-
- Recall Macro: 0.5577
|
| 27 |
-
- Precision Micro: 0.5294
|
| 28 |
-
- Recall Micro: 0.5294
|
| 29 |
-
|
| 30 |
-
## Model description
|
| 31 |
-
|
| 32 |
-
More information needed
|
| 33 |
-
|
| 34 |
-
## Intended uses & limitations
|
| 35 |
-
|
| 36 |
-
More information needed
|
| 37 |
-
|
| 38 |
-
## Training and evaluation data
|
| 39 |
-
|
| 40 |
-
More information needed
|
| 41 |
-
|
| 42 |
-
## Training procedure
|
| 43 |
-
|
| 44 |
-
### Training hyperparameters
|
| 45 |
-
|
| 46 |
-
The following hyperparameters were used during training:
|
| 47 |
-
- learning_rate: 9e-06
|
| 48 |
-
- train_batch_size: 4
|
| 49 |
-
- eval_batch_size: 32
|
| 50 |
-
- seed: 42
|
| 51 |
-
- gradient_accumulation_steps: 8
|
| 52 |
-
- total_train_batch_size: 32
|
| 53 |
-
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 54 |
-
- lr_scheduler_type: linear
|
| 55 |
-
- lr_scheduler_warmup_ratio: 0.06
|
| 56 |
-
- num_epochs: 2
|
| 57 |
|
| 58 |
-
### Training results
|
| 59 |
|
| 60 |
-
|
| 61 |
-
|
| 62 |
-
|
| 63 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 64 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 65 |
|
| 66 |
-
### Framework versions
|
| 67 |
|
| 68 |
-
|
| 69 |
-
|
| 70 |
-
|
| 71 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
language:
|
| 3 |
+
- en
|
| 4 |
tags:
|
| 5 |
+
- text-classification
|
| 6 |
+
- zero-shot-classification
|
| 7 |
+
pipeline_tag: zero-shot-classification
|
| 8 |
+
library_name: transformers
|
| 9 |
+
license: mit
|
| 10 |
+
datasets:
|
| 11 |
+
- nyu-mll/multi_nli
|
| 12 |
+
- fever
|
| 13 |
---
|
| 14 |
|
| 15 |
+
# Model description: roberta-large-zeroshot-v2.0
|
| 16 |
+
The model is designed for zero-shot classification with the Hugging Face pipeline.
|
| 17 |
+
|
| 18 |
+
The main advantage of this `zeroshot-v2.0` series of models is that they are trained on commercially-friendly data
|
| 19 |
+
and are fully commercially usable, while my older `zeroshot-v1.1` models included training data with non-commercially licenses data.
|
| 20 |
+
An overview of the latest zeroshot classifiers with different sizes and licenses is available in my [Zeroshot Classifier Collection](https://huggingface.co/collections/MoritzLaurer/zeroshot-classifiers-6548b4ff407bb19ff5c3ad6f).
|
| 21 |
+
|
| 22 |
+
The model can do one universal classification task: determine whether a hypothesis is "true" or "not true" given a text
|
| 23 |
+
(`entailment` vs. `not_entailment`).
|
| 24 |
+
This task format is based on the Natural Language Inference task (NLI).
|
| 25 |
+
The task is so universal that any classification task can be reformulated into this task.
|
| 26 |
+
Note that compared to other NLI models, this model predicts two classes (`entailment` vs. `not_entailment`)
|
| 27 |
+
as opposed to three classes (entailment/neutral/contradiction).
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 28 |
|
|
|
|
| 29 |
|
| 30 |
+
## Training data
|
| 31 |
+
The model is trained on two types of fully commercially-friendly data:
|
| 32 |
+
1. Synthetic data generated with [Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1).
|
| 33 |
+
I first created a list of 500+ diverse text classification tasks for 25 professions in conversations with Mistral-large. The data was manually curated.
|
| 34 |
+
I then used this as seed data to generate several hundred thousand texts for the different tasks with Mixtral-8x7B-Instruct-v0.1.
|
| 35 |
+
The final dataset used is available in the [synthetic_zeroshot_mixtral_v0.1](https://huggingface.co/datasets/MoritzLaurer/synthetic_zeroshot_mixtral_v0.1) dataset
|
| 36 |
+
in the subset `mixtral_written_text_for_tasks_v4`. Data curation was done in multiple iterations and I will release more information on this process soon.
|
| 37 |
+
2. Two commercially-friendly NLI datasets: ([MNLI](https://huggingface.co/datasets/nyu-mll/multi_nli), [FEVER-NLI](https://huggingface.co/datasets/fever)).
|
| 38 |
+
These datasets were added to increase generalization. Datasets like ANLI were excluded due to their non-commercial license.
|
| 39 |
|
| 40 |
+
The model was only trained on English data. I will release a multilingual version of this model soon.
|
| 41 |
+
For __multilingual use-cases__,
|
| 42 |
+
I alternatively recommend machine translating texts to English with libraries like [EasyNMT](https://github.com/UKPLab/EasyNMT).
|
| 43 |
+
English-only models tend to perform better than multilingual models and
|
| 44 |
+
validation with English data can be easier if you don't speak all languages in your corpus.
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
## How to use the model
|
| 49 |
+
```python
|
| 50 |
+
#!pip install transformers[sentencepiece]
|
| 51 |
+
from transformers import pipeline
|
| 52 |
+
text = "Angela Merkel is a politician in Germany and leader of the CDU"
|
| 53 |
+
hypothesis_template = "This example is about {}"
|
| 54 |
+
classes_verbalized = ["politics", "economy", "entertainment", "environment"]
|
| 55 |
+
zeroshot_classifier = pipeline("zero-shot-classification", model="MoritzLaurer/roberta-large-zeroshot-v2.0")
|
| 56 |
+
output = zeroshot_classifier(text, classes_verbalised, hypothesis_template=hypothesis_template, multi_label=False)
|
| 57 |
+
print(output)
|
| 58 |
+
```
|
| 59 |
+
|
| 60 |
+
`multi_label=False` forces the model to decide on only one class. `multi_label=True` enables the model to choose multiple classes.
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
## Metrics
|
| 64 |
+
|
| 65 |
+
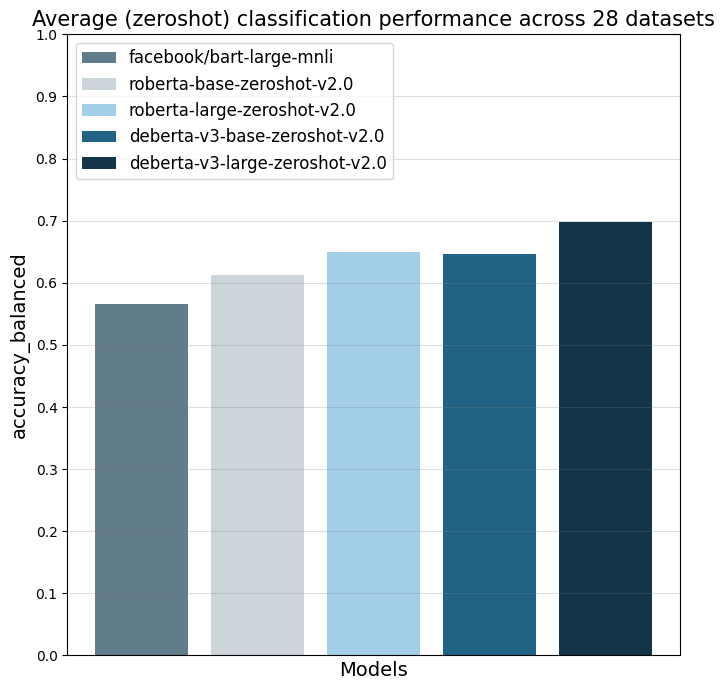
The model was evaluated on 28 different text classification tasks with the [balanced_accuracy](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.balanced_accuracy_score.html) metric.
|
| 66 |
+
The main reference point is `facebook/bart-large-mnli` which is at the time of writing (27.03.24) the most used commercially-friendly 0-shot classifier.
|
| 67 |
+
The different `zeroshot-v2.0` models were all trained with the same data and the only difference is the underlying foundation model.
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
| | facebook/bart-large-mnli | roberta-base-zeroshot-v2.0 | roberta-large-zeroshot-v2.0 | deberta-v3-base-zeroshot-v2.0 | deberta-v3-large-zeroshot-v2.0 |
|
| 72 |
+
|:---------------------------|---------------------------:|-----------------------------:|------------------------------:|--------------------------------:|---------------------------------:|
|
| 73 |
+
| all datasets mean | 0.566 | 0.612 | 0.65 | 0.647 | 0.697 |
|
| 74 |
+
| amazonpolarity (2) | 0.937 | 0.924 | 0.951 | 0.937 | 0.952 |
|
| 75 |
+
| imdb (2) | 0.892 | 0.871 | 0.904 | 0.893 | 0.923 |
|
| 76 |
+
| appreviews (2) | 0.934 | 0.913 | 0.937 | 0.938 | 0.943 |
|
| 77 |
+
| yelpreviews (2) | 0.948 | 0.953 | 0.977 | 0.979 | 0.988 |
|
| 78 |
+
| rottentomatoes (2) | 0.831 | 0.803 | 0.841 | 0.841 | 0.87 |
|
| 79 |
+
| emotiondair (6) | 0.495 | 0.523 | 0.514 | 0.487 | 0.495 |
|
| 80 |
+
| emocontext (4) | 0.605 | 0.535 | 0.609 | 0.566 | 0.687 |
|
| 81 |
+
| empathetic (32) | 0.366 | 0.386 | 0.417 | 0.388 | 0.455 |
|
| 82 |
+
| financialphrasebank (3) | 0.673 | 0.521 | 0.445 | 0.678 | 0.656 |
|
| 83 |
+
| banking77 (72) | 0.327 | 0.138 | 0.297 | 0.433 | 0.542 |
|
| 84 |
+
| massive (59) | 0.454 | 0.481 | 0.599 | 0.533 | 0.599 |
|
| 85 |
+
| wikitoxic_toxicaggreg (2) | 0.609 | 0.752 | 0.768 | 0.752 | 0.751 |
|
| 86 |
+
| wikitoxic_obscene (2) | 0.728 | 0.818 | 0.854 | 0.853 | 0.884 |
|
| 87 |
+
| wikitoxic_threat (2) | 0.531 | 0.796 | 0.874 | 0.861 | 0.876 |
|
| 88 |
+
| wikitoxic_insult (2) | 0.514 | 0.738 | 0.802 | 0.768 | 0.778 |
|
| 89 |
+
| wikitoxic_identityhate (2) | 0.567 | 0.776 | 0.801 | 0.774 | 0.801 |
|
| 90 |
+
| hateoffensive (3) | 0.41 | 0.497 | 0.484 | 0.539 | 0.634 |
|
| 91 |
+
| hatexplain (3) | 0.373 | 0.423 | 0.385 | 0.441 | 0.446 |
|
| 92 |
+
| biasframes_offensive (2) | 0.499 | 0.571 | 0.587 | 0.546 | 0.648 |
|
| 93 |
+
| biasframes_sex (2) | 0.503 | 0.703 | 0.845 | 0.794 | 0.877 |
|
| 94 |
+
| biasframes_intent (2) | 0.635 | 0.541 | 0.635 | 0.562 | 0.696 |
|
| 95 |
+
| agnews (4) | 0.722 | 0.765 | 0.764 | 0.694 | 0.824 |
|
| 96 |
+
| yahootopics (10) | 0.303 | 0.55 | 0.621 | 0.575 | 0.605 |
|
| 97 |
+
| trueteacher (2) | 0.492 | 0.488 | 0.501 | 0.505 | 0.515 |
|
| 98 |
+
| spam (2) | 0.523 | 0.537 | 0.528 | 0.531 | 0.698 |
|
| 99 |
+
| wellformedquery (2) | 0.528 | 0.5 | 0.5 | 0.5 | 0.476 |
|
| 100 |
+
| manifesto (56) | 0.088 | 0.111 | 0.206 | 0.198 | 0.277 |
|
| 101 |
+
| capsotu (21) | 0.375 | 0.525 | 0.558 | 0.543 | 0.631 |
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
## When to use which model
|
| 106 |
+
|
| 107 |
+
- deberta-v3-zeroshot vs. roberta-zeroshot: deberta-v3 performs clearly better than roberta, but it is slower.
|
| 108 |
+
roberta is directly compatible with Hugging Face's production inference TEI containers and flash attention.
|
| 109 |
+
These containers are a good choice for production use-cases. tl;dr: For accuracy, use a deberta-v3 model.
|
| 110 |
+
If production inference speed is a concern, you can consider a roberta model (e.g. in a TEI container and [HF Inference Endpoints](https://ui.endpoints.huggingface.co/catalog)).
|
| 111 |
+
- `zeroshot-v1.1` vs. `zeroshot-v2.0` models: My `zeroshot-v1.1` models (see [Zeroshot Classifier Collection](https://huggingface.co/collections/MoritzLaurer/zeroshot-classifiers-6548b4ff407bb19ff5c3ad6f)))
|
| 112 |
+
perform better on these 28 datasets, but they are trained on several datasets with non-commercial licenses.
|
| 113 |
+
For commercial users, I therefore recommend using a v2.0 model and non-commercial users might get better performance with a v1.1 model.
|
| 114 |
+
- The latest updates on new models are always available in the [Zeroshot Classifier Collection](https://huggingface.co/collections/MoritzLaurer/zeroshot-classifiers-6548b4ff407bb19ff5c3ad6f).
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
## Reproduction
|
| 118 |
+
|
| 119 |
+
Reproduction code is available in the `v2_synthetic_data` directory here: https://github.com/MoritzLaurer/zeroshot-classifier/tree/main
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
## Limitations and bias
|
| 124 |
+
The model can only do text classification tasks.
|
| 125 |
+
|
| 126 |
+
Biases can come from the underlying foundation model, the human NLI training data and the synthetic data generated by Mixtral.
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
## License
|
| 131 |
+
The foundation model (DeBERTa-v3) is published under the MIT license.
|
| 132 |
+
The training data is released under different, permissive, commercially-friendly licenses
|
| 133 |
+
([MNLI](https://huggingface.co/datasets/nyu-mll/multi_nli), [FEVER-NLI](https://huggingface.co/datasets/fever), [synthetic_zeroshot_mixtral_v0.1](https://huggingface.co/datasets/MoritzLaurer/synthetic_zeroshot_mixtral_v0.1))
|
| 134 |
+
|
| 135 |
+
## Citation
|
| 136 |
+
|
| 137 |
+
This model is an extension of the research described in this [paper](https://arxiv.org/pdf/2312.17543.pdf).
|
| 138 |
+
|
| 139 |
+
If you use this model academically, please cite:
|
| 140 |
+
```
|
| 141 |
+
@misc{laurer_building_2023,
|
| 142 |
+
title = {Building {Efficient} {Universal} {Classifiers} with {Natural} {Language} {Inference}},
|
| 143 |
+
url = {http://arxiv.org/abs/2312.17543},
|
| 144 |
+
doi = {10.48550/arXiv.2312.17543},
|
| 145 |
+
abstract = {Generative Large Language Models (LLMs) have become the mainstream choice for fewshot and zeroshot learning thanks to the universality of text generation. Many users, however, do not need the broad capabilities of generative LLMs when they only want to automate a classification task. Smaller BERT-like models can also learn universal tasks, which allow them to do any text classification task without requiring fine-tuning (zeroshot classification) or to learn new tasks with only a few examples (fewshot), while being significantly more efficient than generative LLMs. This paper (1) explains how Natural Language Inference (NLI) can be used as a universal classification task that follows similar principles as instruction fine-tuning of generative LLMs, (2) provides a step-by-step guide with reusable Jupyter notebooks for building a universal classifier, and (3) shares the resulting universal classifier that is trained on 33 datasets with 389 diverse classes. Parts of the code we share has been used to train our older zeroshot classifiers that have been downloaded more than 55 million times via the Hugging Face Hub as of December 2023. Our new classifier improves zeroshot performance by 9.4\%.},
|
| 146 |
+
urldate = {2024-01-05},
|
| 147 |
+
publisher = {arXiv},
|
| 148 |
+
author = {Laurer, Moritz and van Atteveldt, Wouter and Casas, Andreu and Welbers, Kasper},
|
| 149 |
+
month = dec,
|
| 150 |
+
year = {2023},
|
| 151 |
+
note = {arXiv:2312.17543 [cs]},
|
| 152 |
+
keywords = {Computer Science - Artificial Intelligence, Computer Science - Computation and Language},
|
| 153 |
+
}
|
| 154 |
+
```
|
| 155 |
+
|
| 156 |
+
### Ideas for cooperation or questions?
|
| 157 |
+
If you have questions or ideas for cooperation, contact me at moritz{at}huggingface{dot}co or [LinkedIn](https://www.linkedin.com/in/moritz-laurer/)
|
| 158 |
|
|
|
|
| 159 |
|
| 160 |
+
|
| 161 |
+
### Flexible usage and "prompting"
|
| 162 |
+
You can formulate your own hypotheses by changing the `hypothesis_template` of the zeroshot pipeline.
|
| 163 |
+
Similar to "prompt engineering" for LLMs, you can test different formulations of your `hypothesis_template` and verbalized classes to improve performance.
|
| 164 |
+
|
| 165 |
+
```python
|
| 166 |
+
from transformers import pipeline
|
| 167 |
+
text = "Angela Merkel is a politician in Germany and leader of the CDU"
|
| 168 |
+
hypothesis_template = "Merkel is the leader of the party: {}"
|
| 169 |
+
classes_verbalized = ["CDU", "SPD", "Greens"]
|
| 170 |
+
zeroshot_classifier = pipeline("zero-shot-classification", model="MoritzLaurer/roberta-large-zeroshot-v2.0")
|
| 171 |
+
output = zeroshot_classifier(text, classes_verbalized, hypothesis_template=hypothesis_template, multi_label=False)
|
| 172 |
+
print(output)
|
| 173 |
+
```
|