# ControlNet
ControlNet is a type of model for controlling image diffusion models by conditioning the model with an additional input image. There are many types of conditioning inputs (canny edge, user sketching, human pose, depth, and more) you can use to control a diffusion model. This is hugely useful because it affords you greater control over image generation, making it easier to generate specific images without experimenting with different text prompts or denoising values as much.
Check out Section 3.5 of the [ControlNet](https://huggingface.co/papers/2302.05543) paper v1 for a list of ControlNet implementations on various conditioning inputs. You can find the official Stable Diffusion ControlNet conditioned models on [lllyasviel](https://huggingface.co/lllyasviel)'s Hub profile, and more [community-trained](https://huggingface.co/models?other=stable-diffusion&other=controlnet) ones on the Hub.
For Stable Diffusion XL (SDXL) ControlNet models, you can find them on the 🤗 [Diffusers](https://huggingface.co/diffusers) Hub organization, or you can browse [community-trained](https://huggingface.co/models?other=stable-diffusion-xl&other=controlnet) ones on the Hub.
A ControlNet model has two sets of weights (or blocks) connected by a zero-convolution layer:
- a *locked copy* keeps everything a large pretrained diffusion model has learned
- a *trainable copy* is trained on the additional conditioning input
Since the locked copy preserves the pretrained model, training and implementing a ControlNet on a new conditioning input is as fast as finetuning any other model because you aren't training the model from scratch.
This guide will show you how to use ControlNet for text-to-image, image-to-image, inpainting, and more! There are many types of ControlNet conditioning inputs to choose from, but in this guide we'll only focus on several of them. Feel free to experiment with other conditioning inputs!
Before you begin, make sure you have the following libraries installed:
```py
# uncomment to install the necessary libraries in Colab
#!pip install -q diffusers transformers accelerate opencv-python
```
## Text-to-image
For text-to-image, you normally pass a text prompt to the model. But with ControlNet, you can specify an additional conditioning input. Let's condition the model with a canny image, a white outline of an image on a black background. This way, the ControlNet can use the canny image as a control to guide the model to generate an image with the same outline.
Load an image and use the [opencv-python](https://github.com/opencv/opencv-python) library to extract the canny image:
```py
from diffusers.utils import load_image, make_image_grid
from PIL import Image
import cv2
import numpy as np
original_image = load_image(
"https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png"
)
image = np.array(original_image)
low_threshold = 100
high_threshold = 200
image = cv2.Canny(image, low_threshold, high_threshold)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image)
```
 original image
original image
 canny image
canny image
Next, load a ControlNet model conditioned on canny edge detection and pass it to the [`StableDiffusionControlNetPipeline`]. Use the faster [`UniPCMultistepScheduler`] and enable model offloading to speed up inference and reduce memory usage.
```py
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
import torch
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16, use_safetensors=True)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16, use_safetensors=True
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
```
Now pass your prompt and canny image to the pipeline:
```py
output = pipe(
"the mona lisa", image=canny_image
).images[0]
make_image_grid([original_image, canny_image, output], rows=1, cols=3)
```
## Image-to-image
For image-to-image, you'd typically pass an initial image and a prompt to the pipeline to generate a new image. With ControlNet, you can pass an additional conditioning input to guide the model. Let's condition the model with a depth map, an image which contains spatial information. This way, the ControlNet can use the depth map as a control to guide the model to generate an image that preserves spatial information.
You'll use the [`StableDiffusionControlNetImg2ImgPipeline`] for this task, which is different from the [`StableDiffusionControlNetPipeline`] because it allows you to pass an initial image as the starting point for the image generation process.
Load an image and use the `depth-estimation` [`~transformers.Pipeline`] from 🤗 Transformers to extract the depth map of an image:
```py
import torch
import numpy as np
from transformers import pipeline
from diffusers.utils import load_image, make_image_grid
image = load_image(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet-img2img.jpg"
)
def get_depth_map(image, depth_estimator):
image = depth_estimator(image)["depth"]
image = np.array(image)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
detected_map = torch.from_numpy(image).float() / 255.0
depth_map = detected_map.permute(2, 0, 1)
return depth_map
depth_estimator = pipeline("depth-estimation")
depth_map = get_depth_map(image, depth_estimator).unsqueeze(0).half().to("cuda")
```
Next, load a ControlNet model conditioned on depth maps and pass it to the [`StableDiffusionControlNetImg2ImgPipeline`]. Use the faster [`UniPCMultistepScheduler`] and enable model offloading to speed up inference and reduce memory usage.
```py
from diffusers import StableDiffusionControlNetImg2ImgPipeline, ControlNetModel, UniPCMultistepScheduler
import torch
controlnet = ControlNetModel.from_pretrained("lllyasviel/control_v11f1p_sd15_depth", torch_dtype=torch.float16, use_safetensors=True)
pipe = StableDiffusionControlNetImg2ImgPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16, use_safetensors=True
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
```
Now pass your prompt, initial image, and depth map to the pipeline:
```py
output = pipe(
"lego batman and robin", image=image, control_image=depth_map,
).images[0]
make_image_grid([image, output], rows=1, cols=2)
```
 original image
original image
 generated image
generated image
## Inpainting
For inpainting, you need an initial image, a mask image, and a prompt describing what to replace the mask with. ControlNet models allow you to add another control image to condition a model with. Let’s condition the model with an inpainting mask. This way, the ControlNet can use the inpainting mask as a control to guide the model to generate an image within the mask area.
Load an initial image and a mask image:
```py
from diffusers.utils import load_image, make_image_grid
init_image = load_image(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet-inpaint.jpg"
)
init_image = init_image.resize((512, 512))
mask_image = load_image(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet-inpaint-mask.jpg"
)
mask_image = mask_image.resize((512, 512))
make_image_grid([init_image, mask_image], rows=1, cols=2)
```
Create a function to prepare the control image from the initial and mask images. This'll create a tensor to mark the pixels in `init_image` as masked if the corresponding pixel in `mask_image` is over a certain threshold.
```py
import numpy as np
import torch
def make_inpaint_condition(image, image_mask):
image = np.array(image.convert("RGB")).astype(np.float32) / 255.0
image_mask = np.array(image_mask.convert("L")).astype(np.float32) / 255.0
assert image.shape[0:1] == image_mask.shape[0:1]
image[image_mask > 0.5] = -1.0 # set as masked pixel
image = np.expand_dims(image, 0).transpose(0, 3, 1, 2)
image = torch.from_numpy(image)
return image
control_image = make_inpaint_condition(init_image, mask_image)
```
 original image
original image
 mask image
mask image
Load a ControlNet model conditioned on inpainting and pass it to the [`StableDiffusionControlNetInpaintPipeline`]. Use the faster [`UniPCMultistepScheduler`] and enable model offloading to speed up inference and reduce memory usage.
```py
from diffusers import StableDiffusionControlNetInpaintPipeline, ControlNetModel, UniPCMultistepScheduler
controlnet = ControlNetModel.from_pretrained("lllyasviel/control_v11p_sd15_inpaint", torch_dtype=torch.float16, use_safetensors=True)
pipe = StableDiffusionControlNetInpaintPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16, use_safetensors=True
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
```
Now pass your prompt, initial image, mask image, and control image to the pipeline:
```py
output = pipe(
"corgi face with large ears, detailed, pixar, animated, disney",
num_inference_steps=20,
eta=1.0,
image=init_image,
mask_image=mask_image,
control_image=control_image,
).images[0]
make_image_grid([init_image, mask_image, output], rows=1, cols=3)
```
## Guess mode
[Guess mode](https://github.com/lllyasviel/ControlNet/discussions/188) does not require supplying a prompt to a ControlNet at all! This forces the ControlNet encoder to do its best to "guess" the contents of the input control map (depth map, pose estimation, canny edge, etc.).
Guess mode adjusts the scale of the output residuals from a ControlNet by a fixed ratio depending on the block depth. The shallowest `DownBlock` corresponds to 0.1, and as the blocks get deeper, the scale increases exponentially such that the scale of the `MidBlock` output becomes 1.0.
Guess mode does not have any impact on prompt conditioning and you can still provide a prompt if you want.
Set `guess_mode=True` in the pipeline, and it is [recommended](https://github.com/lllyasviel/ControlNet#guess-mode--non-prompt-mode) to set the `guidance_scale` value between 3.0 and 5.0.
```py
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel
from diffusers.utils import load_image, make_image_grid
import numpy as np
import torch
from PIL import Image
import cv2
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", use_safetensors=True)
pipe = StableDiffusionControlNetPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", controlnet=controlnet, use_safetensors=True).to("cuda")
original_image = load_image("https://huggingface.co/takuma104/controlnet_dev/resolve/main/bird_512x512.png")
image = np.array(original_image)
low_threshold = 100
high_threshold = 200
image = cv2.Canny(image, low_threshold, high_threshold)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image)
image = pipe("", image=canny_image, guess_mode=True, guidance_scale=3.0).images[0]
make_image_grid([original_image, canny_image, image], rows=1, cols=3)
```
 regular mode with prompt
regular mode with prompt
 guess mode without prompt
guess mode without prompt
## ControlNet with Stable Diffusion XL
There aren't too many ControlNet models compatible with Stable Diffusion XL (SDXL) at the moment, but we've trained two full-sized ControlNet models for SDXL conditioned on canny edge detection and depth maps. We're also experimenting with creating smaller versions of these SDXL-compatible ControlNet models so it is easier to run on resource-constrained hardware. You can find these checkpoints on the [🤗 Diffusers Hub organization](https://huggingface.co/diffusers)!
Let's use a SDXL ControlNet conditioned on canny images to generate an image. Start by loading an image and prepare the canny image:
```py
from diffusers import StableDiffusionXLControlNetPipeline, ControlNetModel, AutoencoderKL
from diffusers.utils import load_image, make_image_grid
from PIL import Image
import cv2
import numpy as np
import torch
original_image = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/hf-logo.png"
)
image = np.array(original_image)
low_threshold = 100
high_threshold = 200
image = cv2.Canny(image, low_threshold, high_threshold)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image)
make_image_grid([original_image, canny_image], rows=1, cols=2)
```
 original image
original image
 canny image
canny image
Load a SDXL ControlNet model conditioned on canny edge detection and pass it to the [`StableDiffusionXLControlNetPipeline`]. You can also enable model offloading to reduce memory usage.
```py
controlnet = ControlNetModel.from_pretrained(
"diffusers/controlnet-canny-sdxl-1.0",
torch_dtype=torch.float16,
use_safetensors=True
)
vae = AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16, use_safetensors=True)
pipe = StableDiffusionXLControlNetPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
controlnet=controlnet,
vae=vae,
torch_dtype=torch.float16,
use_safetensors=True
)
pipe.enable_model_cpu_offload()
```
Now pass your prompt (and optionally a negative prompt if you're using one) and canny image to the pipeline:
The [`controlnet_conditioning_scale`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/controlnet#diffusers.StableDiffusionControlNetPipeline.__call__.controlnet_conditioning_scale) parameter determines how much weight to assign to the conditioning inputs. A value of 0.5 is recommended for good generalization, but feel free to experiment with this number!
```py
prompt = "aerial view, a futuristic research complex in a bright foggy jungle, hard lighting"
negative_prompt = 'low quality, bad quality, sketches'
image = pipe(
prompt,
negative_prompt=negative_prompt,
image=canny_image,
controlnet_conditioning_scale=0.5,
).images[0]
make_image_grid([original_image, canny_image, image], rows=1, cols=3)
```

You can use [`StableDiffusionXLControlNetPipeline`] in guess mode as well by setting the parameter to `True`:
```py
from diffusers import StableDiffusionXLControlNetPipeline, ControlNetModel, AutoencoderKL
from diffusers.utils import load_image, make_image_grid
import numpy as np
import torch
import cv2
from PIL import Image
prompt = "aerial view, a futuristic research complex in a bright foggy jungle, hard lighting"
negative_prompt = "low quality, bad quality, sketches"
original_image = load_image(
"https://hf.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/hf-logo.png"
)
controlnet = ControlNetModel.from_pretrained(
"diffusers/controlnet-canny-sdxl-1.0", torch_dtype=torch.float16, use_safetensors=True
)
vae = AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16, use_safetensors=True)
pipe = StableDiffusionXLControlNetPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", controlnet=controlnet, vae=vae, torch_dtype=torch.float16, use_safetensors=True
)
pipe.enable_model_cpu_offload()
image = np.array(original_image)
image = cv2.Canny(image, 100, 200)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image)
image = pipe(
prompt, negative_prompt=negative_prompt, controlnet_conditioning_scale=0.5, image=canny_image, guess_mode=True,
).images[0]
make_image_grid([original_image, canny_image, image], rows=1, cols=3)
```
You can use a refiner model with `StableDiffusionXLControlNetPipeline` to improve image quality, just like you can with a regular `StableDiffusionXLPipeline`.
See the [Refine image quality](./sdxl#refine-image-quality) section to learn how to use the refiner model.
Make sure to use `StableDiffusionXLControlNetPipeline` and pass `image` and `controlnet_conditioning_scale`.
```py
base = StableDiffusionXLControlNetPipeline(...)
image = base(
prompt=prompt,
controlnet_conditioning_scale=0.5,
image=canny_image,
num_inference_steps=40,
denoising_end=0.8,
output_type="latent",
).images
# rest exactly as with StableDiffusionXLPipeline
```
## MultiControlNet
Replace the SDXL model with a model like [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) to use multiple conditioning inputs with Stable Diffusion models.
You can compose multiple ControlNet conditionings from different image inputs to create a *MultiControlNet*. To get better results, it is often helpful to:
1. mask conditionings such that they don't overlap (for example, mask the area of a canny image where the pose conditioning is located)
2. experiment with the [`controlnet_conditioning_scale`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/controlnet#diffusers.StableDiffusionControlNetPipeline.__call__.controlnet_conditioning_scale) parameter to determine how much weight to assign to each conditioning input
In this example, you'll combine a canny image and a human pose estimation image to generate a new image.
Prepare the canny image conditioning:
```py
from diffusers.utils import load_image, make_image_grid
from PIL import Image
import numpy as np
import cv2
original_image = load_image(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/landscape.png"
)
image = np.array(original_image)
low_threshold = 100
high_threshold = 200
image = cv2.Canny(image, low_threshold, high_threshold)
# zero out middle columns of image where pose will be overlaid
zero_start = image.shape[1] // 4
zero_end = zero_start + image.shape[1] // 2
image[:, zero_start:zero_end] = 0
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image)
make_image_grid([original_image, canny_image], rows=1, cols=2)
```
 original image
original image
 canny image
canny image
For human pose estimation, install [controlnet_aux](https://github.com/patrickvonplaten/controlnet_aux):
```py
# uncomment to install the necessary library in Colab
#!pip install -q controlnet-aux
```
Prepare the human pose estimation conditioning:
```py
from controlnet_aux import OpenposeDetector
openpose = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
original_image = load_image(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/person.png"
)
openpose_image = openpose(original_image)
make_image_grid([original_image, openpose_image], rows=1, cols=2)
```
 original image
original image
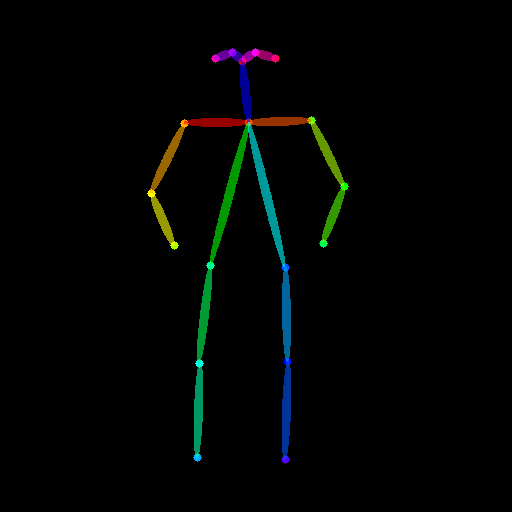 human pose image
human pose image
Load a list of ControlNet models that correspond to each conditioning, and pass them to the [`StableDiffusionXLControlNetPipeline`]. Use the faster [`UniPCMultistepScheduler`] and enable model offloading to reduce memory usage.
```py
from diffusers import StableDiffusionXLControlNetPipeline, ControlNetModel, AutoencoderKL, UniPCMultistepScheduler
import torch
controlnets = [
ControlNetModel.from_pretrained(
"thibaud/controlnet-openpose-sdxl-1.0", torch_dtype=torch.float16
),
ControlNetModel.from_pretrained(
"diffusers/controlnet-canny-sdxl-1.0", torch_dtype=torch.float16, use_safetensors=True
),
]
vae = AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16, use_safetensors=True)
pipe = StableDiffusionXLControlNetPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", controlnet=controlnets, vae=vae, torch_dtype=torch.float16, use_safetensors=True
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
```
Now you can pass your prompt (an optional negative prompt if you're using one), canny image, and pose image to the pipeline:
```py
prompt = "a giant standing in a fantasy landscape, best quality"
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
generator = torch.manual_seed(1)
images = [openpose_image.resize((1024, 1024)), canny_image.resize((1024, 1024))]
images = pipe(
prompt,
image=images,
num_inference_steps=25,
generator=generator,
negative_prompt=negative_prompt,
num_images_per_prompt=3,
controlnet_conditioning_scale=[1.0, 0.8],
).images
make_image_grid([original_image, canny_image, openpose_image,
images[0].resize((512, 512)), images[1].resize((512, 512)), images[2].resize((512, 512))], rows=2, cols=3)
```


