
PJMixers-Dev/LLaMa-3.2-Instruct-JankMix-v0.2-SFT-3B was further trained using KTO (with apo_zero_unpaired loss type) using a mix of instruct, RP, and storygen datasets. I created rejected samples by using the SFT with bad settings (including logit bias) for every model turn.
The model was only trained at max_length=6144, and is nowhere near a full epoch as it eventually crashed. So think of this like a test of a test.
W&B Training Logs
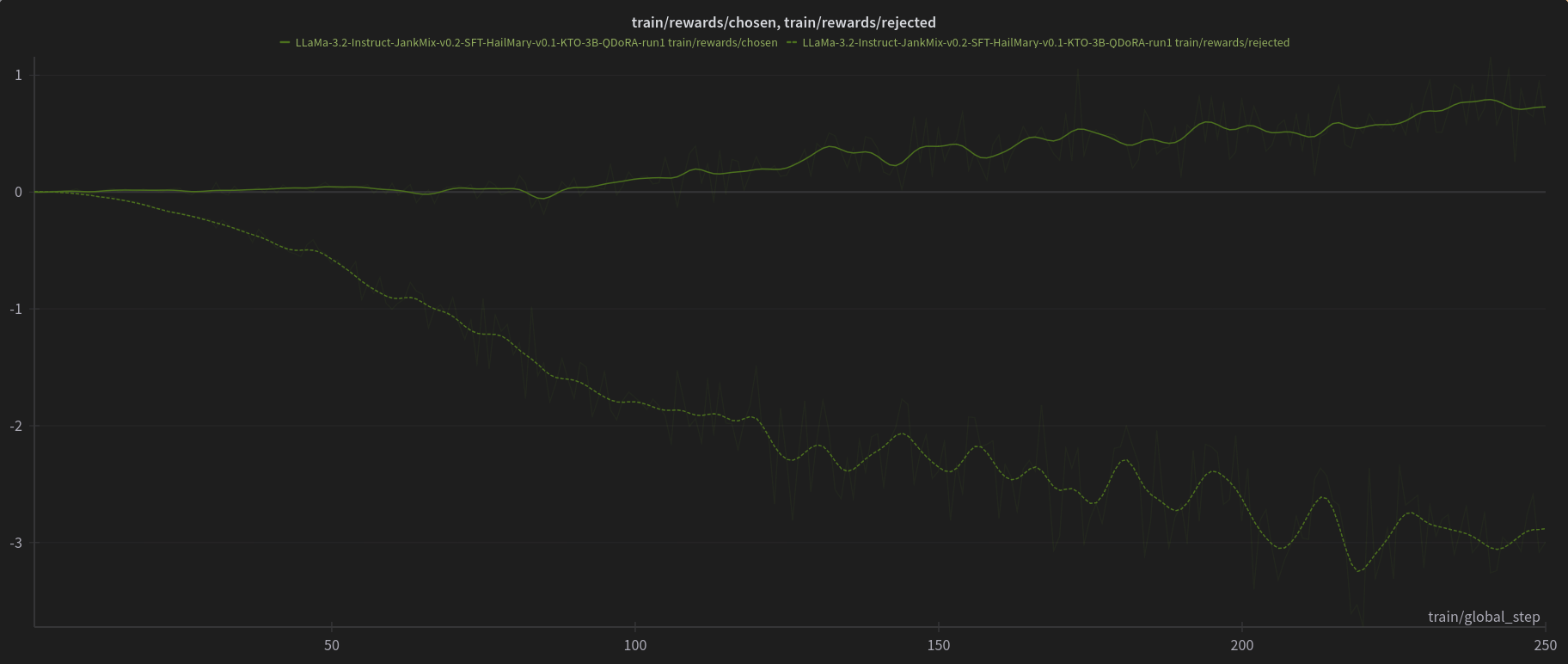
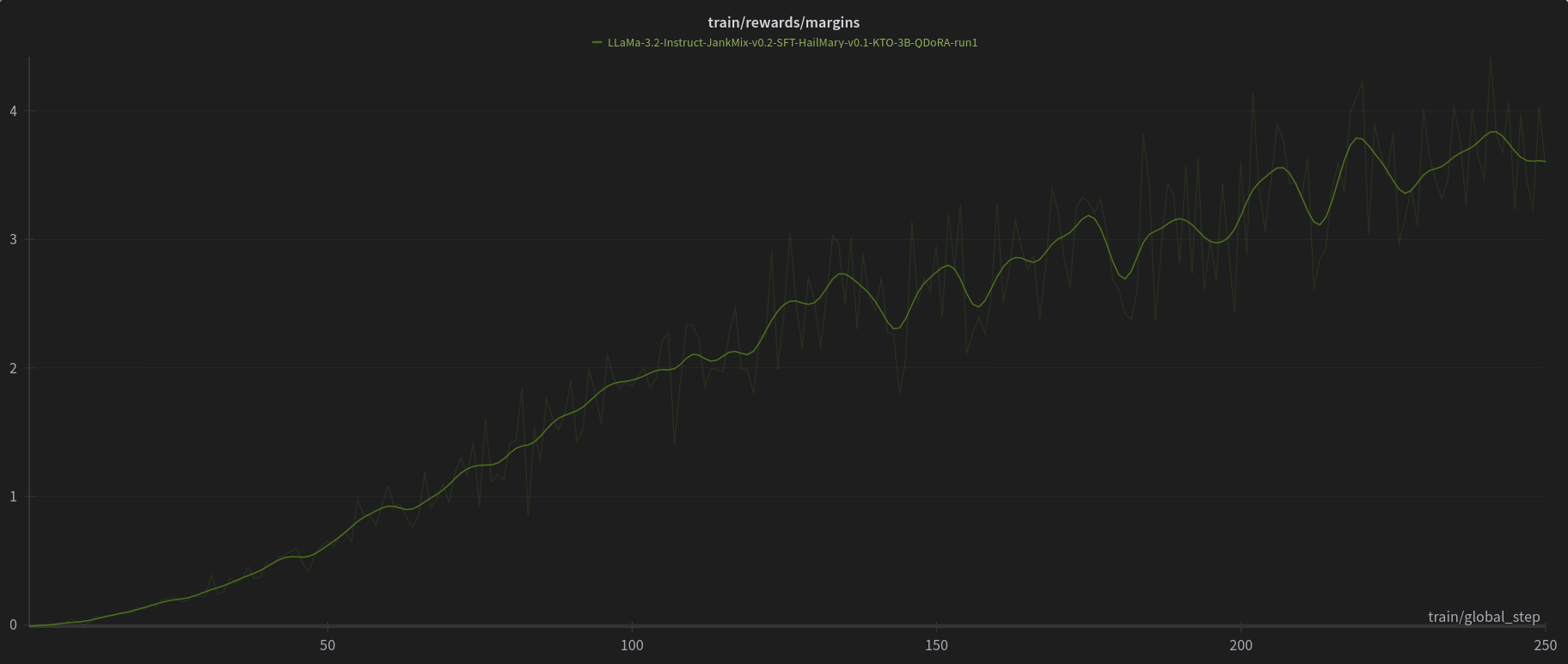
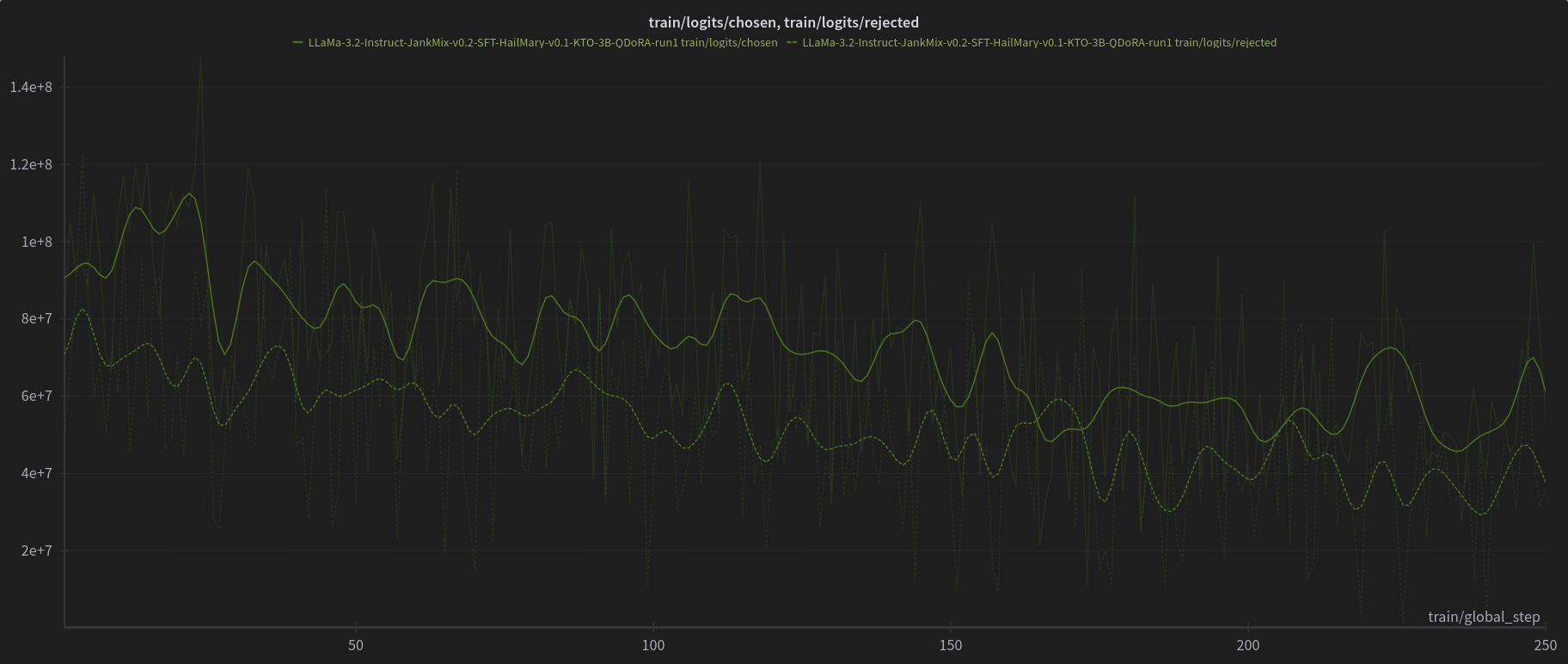
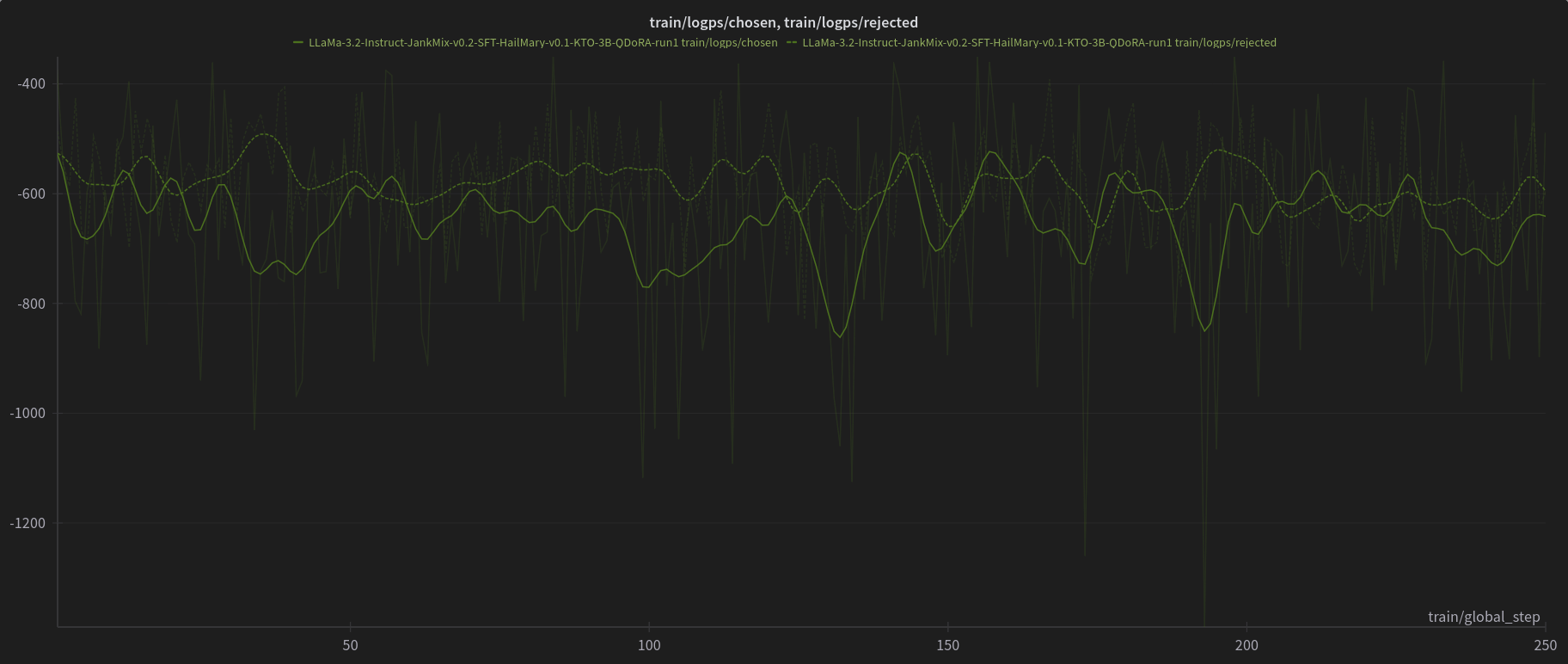
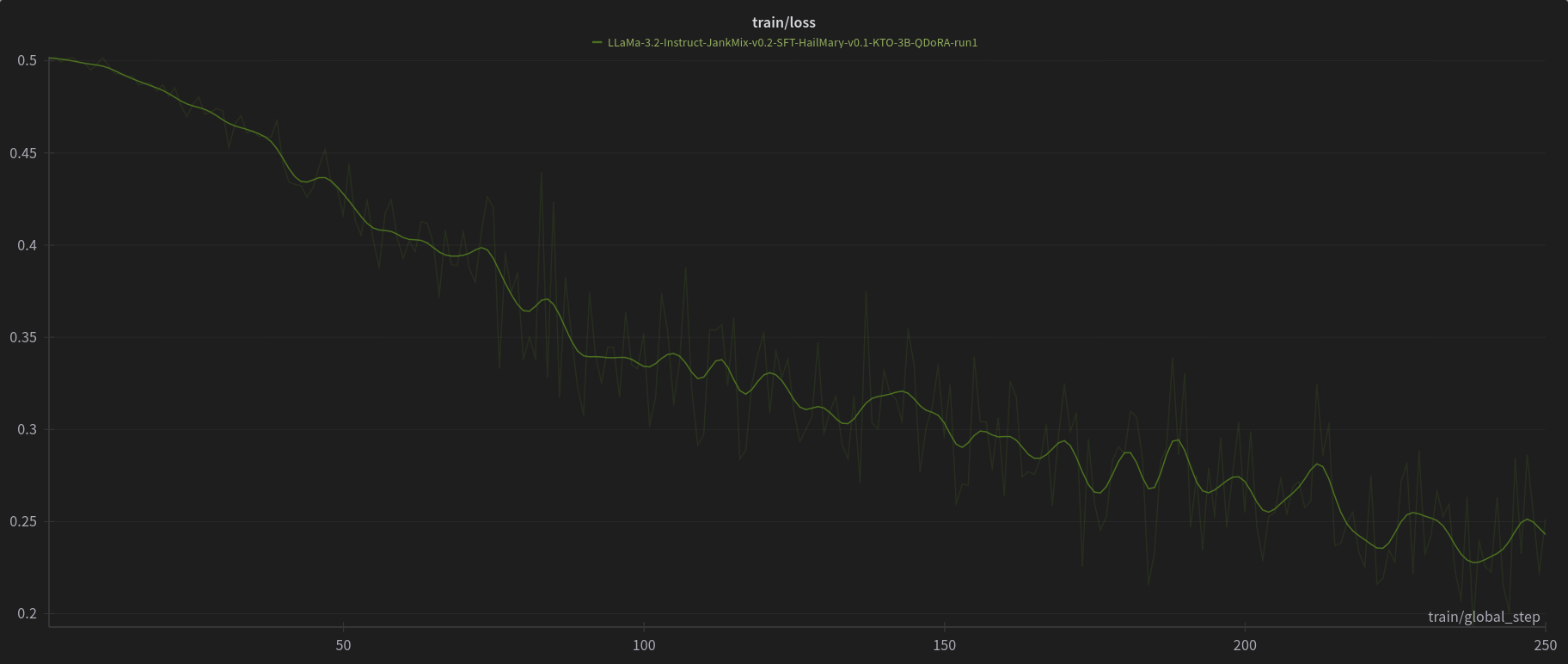
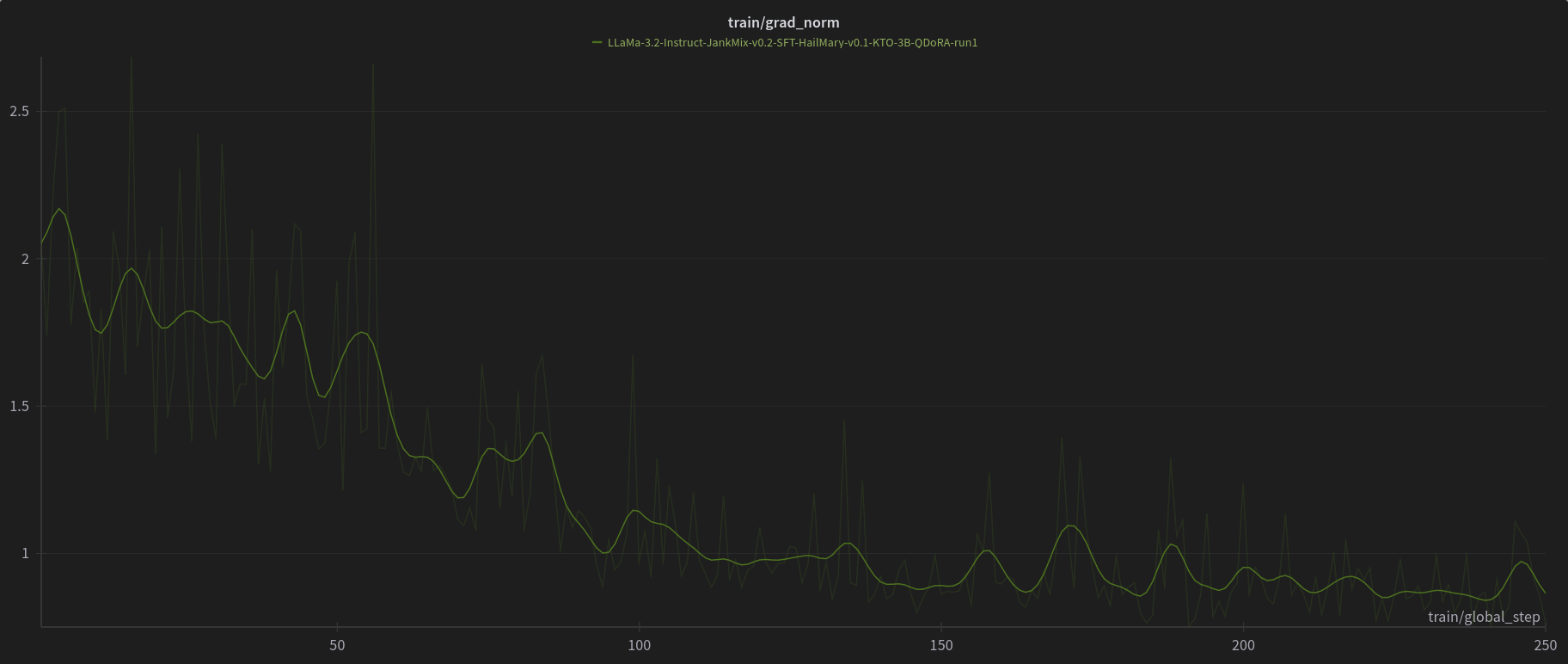
Open LLM Leaderboard Evaluation Results
Detailed results can be found here
| Metric | Value |
|---|---|
| Avg. | 21.69 |
| IFEval (0-Shot) | 65.04 |
| BBH (3-Shot) | 22.29 |
| MATH Lvl 5 (4-Shot) | 11.78 |
| GPQA (0-shot) | 2.91 |
| MuSR (0-shot) | 4.69 |
| MMLU-PRO (5-shot) | 23.42 |
- Downloads last month
- 328
Model tree for PJMixers-Dev/LLaMa-3.2-Instruct-JankMix-v0.2-SFT-HailMary-v0.1-KTO-3B-GGUF
Base model
meta-llama/Llama-3.2-3B-Instruct
Finetuned
unsloth/Llama-3.2-3B-Instruct
Evaluation results
- strict accuracy on IFEval (0-Shot)Open LLM Leaderboard65.040
- normalized accuracy on BBH (3-Shot)Open LLM Leaderboard22.290
- exact match on MATH Lvl 5 (4-Shot)Open LLM Leaderboard11.780
- acc_norm on GPQA (0-shot)Open LLM Leaderboard2.910
- acc_norm on MuSR (0-shot)Open LLM Leaderboard4.690
- accuracy on MMLU-PRO (5-shot)test set Open LLM Leaderboard23.420