---
license: apache-2.0
library_name: pruna-engine
thumbnail: "https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"
metrics:
- memory_disk
- memory_inference
- inference_latency
- inference_throughput
- inference_CO2_emissions
- inference_energy_consumption
---
Deprecation Notice: This model is deprecated and will no longer receive updates.
# Simply make AI models cheaper, smaller, faster, and greener!
[](https://twitter.com/PrunaAI)
[](https://github.com/PrunaAI)
[](https://www.linkedin.com/company/93832878/admin/feed/posts/?feedType=following)
- Give a thumbs up if you like this model!
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
- Request access to easily compress your *own* AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
- Read the documentations to know more [here](https://pruna-ai-pruna.readthedocs-hosted.com/en/latest/)
- Share feedback and suggestions on the Slack of Pruna AI (Coming soon!).
## Results
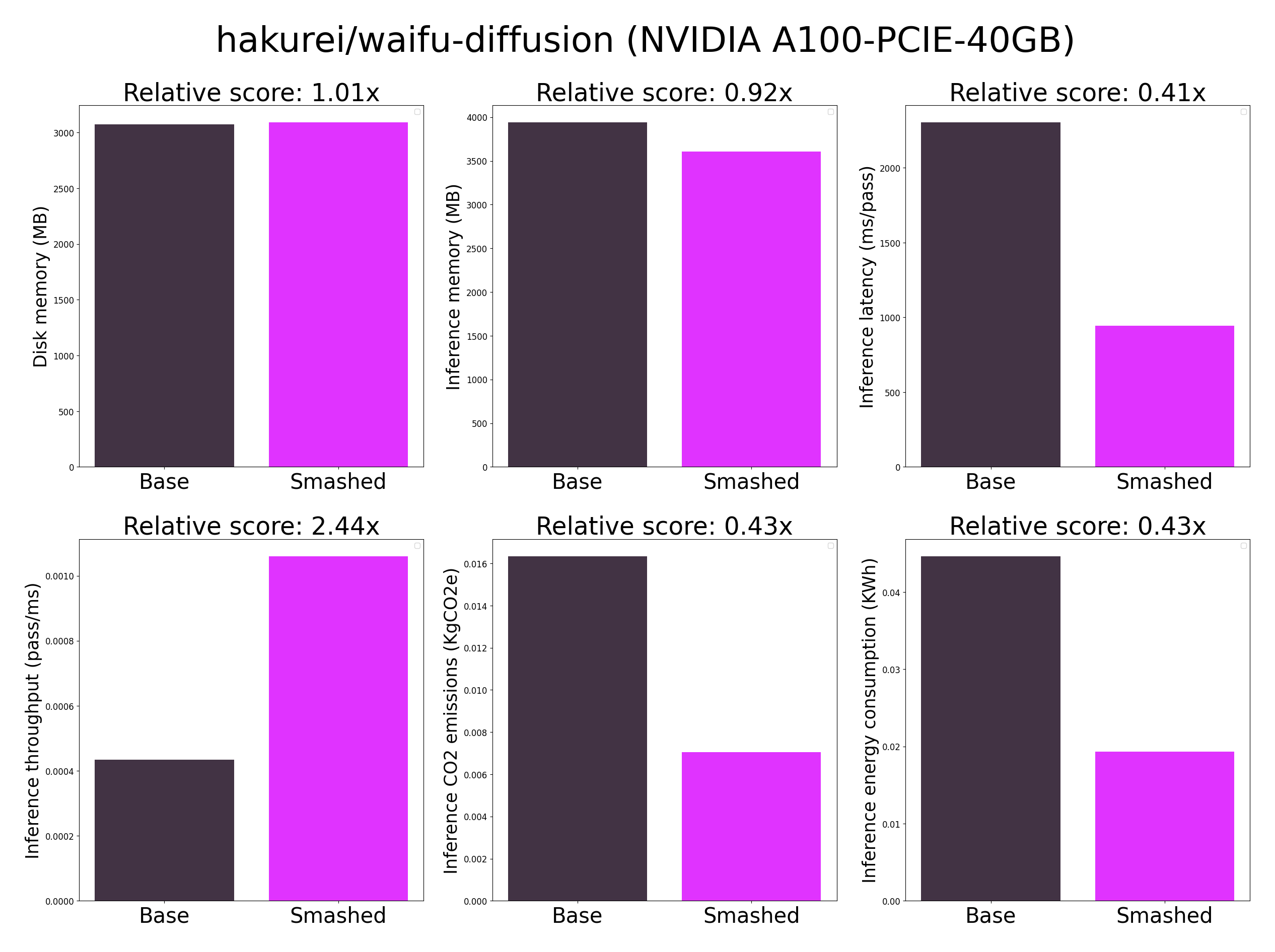
**Important remarks:**
- The quality of the model output might slightly vary compared to the base model. There might be minimal quality loss.
- These results were obtained on NVIDIA A100-PCIE-40GB with configuration described in config.json and are obtained after a hardware warmup. Efficiency results may vary in other settings (e.g. other hardware, image size, batch size, ...).
- You can request premium access to more compression methods and tech support for your specific use-cases [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
## Setup
You can run the smashed model with these steps:
0. Check cuda, torch, packaging requirements are installed. For cuda, check with `nvcc --version` and install with `conda install nvidia/label/cuda-12.1.0::cuda`. For packaging and torch, run `pip install packaging torch`.
1. Install the `pruna-engine` available [here](https://pypi.org/project/pruna-engine/) on Pypi. It might take 15 minutes to install.
```bash
pip install pruna-engine[gpu] --extra-index-url https://pypi.nvidia.com --extra-index-url https://pypi.ngc.nvidia.com --extra-index-url https://prunaai.pythonanywhere.com/
```
3. Download the model files using one of these three options.
- Option 1 - Use command line interface (CLI):
```bash
mkdir hakurei-waifu-diffusion-turbo-green-smashed
huggingface-cli download PrunaAI/hakurei-waifu-diffusion-turbo-green-smashed --local-dir hakurei-waifu-diffusion-turbo-green-smashed --local-dir-use-symlinks False
```
- Option 2 - Use Python:
```python
import subprocess
repo_name = "hakurei-waifu-diffusion-turbo-green-smashed"
subprocess.run(["mkdir", repo_name])
subprocess.run(["huggingface-cli", "download", 'PrunaAI/'+ repo_name, "--local-dir", repo_name, "--local-dir-use-symlinks", "False"])
```
- Option 3 - Download them manually on the HuggingFace model page.
3. Load & run the model.
```python
from pruna_engine.PrunaModel import PrunaModel
model_path = "hakurei-waifu-diffusion-turbo-green-smashed/model" # Specify the downloaded model path.
smashed_model = PrunaModel.load_model(model_path) # Load the model.
smashed_model(prompt='Beautiful fruits in trees', height=512, width=512)[0][0] # Run the model where x is the expected input of.
```
## Configurations
The configuration info are in `config.json`.
## License
We follow the same license as the original model. Please check the license of the original model hakurei/waifu-diffusion before using this model.
## Want to compress other models?
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
- Request access to easily compress your own AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai). 