

QuantFactory/Llama-3.1-Herrsimian-8B-GGUF
This is quantized version of lemonilia/Llama-3.1-Herrsimian-8B created using llama.cpp
Original Model Card
Llama-3.1-Herrsimian-8B (v0.5b)

Herrsimian is a limited-scope NSFW roleplaying model intended to replicate the writing style of a certain prolific roleplayer who used to actively participate on a few different roleplay forums until the end of 2022. It's also a test bench for studying how much mileage can be obtained with a very limited amount of high-quality training samples of consistent style—mainly by training well into the overfitting regime.
The model, finetuned on Llama-3.1-8B-base, was trained with a multi-user, multi-character paradigm, where user or model turns don't necessarily alternate as in most other instruction prompting formats. As of present however the most commonly used LLM frontends cannot readily take advantage of this feature.
Note: There is still some work to be done on the dataset to increase general usability, but prose quality should be representitative of the final model.
- 2024-09-05 (v0.5b): ① increased RP data to 131 samples; this is probably the final content update as I don't have any more data from the same source worth including. ② Changed training hyperparameters; 12k context.
- 2024-09-04 (v0.4): increased RP data to 100 samples, some bugfixes. Slightly decreased learning rate.
- 2024-09-02 (v0.3): ① Added character descriptions and scenarios to the RP data using a variety of formats, which should make the model more flexible. ② Changed training hyperparameters. ③ Updated SillyTavern context preset. ④ Removed the 8-bit GGUF quantization as upon testing it appeared to have noticeably lower quality than the BF16 weights, for some inexplicable reason.
- 2024-09-01 (v0.2): increased RP data to 94 samples / 710k tokens. Maybe now more hallucination-prone?
- 2024-08-31 (v0.1): initial release, 77 samples / 580k tokens.
Usage notes
- The model is probably best used when merged or applied as a LoRA to Llama-3.1-8B-Instruct.
- I've observed that GGUF quantizations can degrade model quality, so it's probably best to avoid them.
Limitations
Notes mainly pertaining to the model trained on Llama-3.1-8B-Base.
- Herrsimian is not a general-purpose roleplay finetune.
- Only forum/book style roleplay format with narration in third person + past tense and quote marks-delimited dialogue lines is in-distribution and has been tested in depth.
- Users are supposed to "play along" as one would during a real roleplaying session, and not deliberately write nonsense or ultra-low effort messages; the model was simply not trained to deal with them.
- Second-person or Markdown-style roleplay styles might break the model.
- It's not a general-purpose instruct model.
- The model doesn't contain instruction/assistant-focused samples, although some instructions have been included in the RP samples (primarily as OOC).
- Don't put gimmicks or instructions inside character descriptions, as they will most likely not work as intended.
- The model is mainly intended for NSFW text generation.
- This is a training data limitation; I don't have safe-for-work roleplay in sufficient amounts from the same source.
- The range of topics/fetishes covered is limited.
- Mostly fantasy- and family-themed straight ERP scenarios.
- Although usually the responses make sense in a roleplaying context, occasionally they can be perplexing.
- Possibly the effect of training on the base model with limited amounts of data.
- The model can be somewhat hallucination-prone.
Prompting format
- User turns are labeled
::::user:while model turns are labeled::::assistant:- When used, character names immediately follow the user/model labels without spaces, for example
::::user:Jack:or::::assistant:Mark: - Exactly one space must follow the complete user or assistant labels.
- User/model labels are always preceded by two newlines
\n\n. - There is no real "system" role or label. System information or instructions can be added by using
::::user:without any attached character name.
- When used, character names immediately follow the user/model labels without spaces, for example
- OOC messages have been trained without character names, but in practice this doesn't seem to be a huge issue. The format is
(OOC: {{message}}) - It is necessary to add the BOS token at the start of the prompt (
<|begin_of_text|>in the case of Llama-3.1), otherwise performance will be significantly reduced. - The model wasn't trained with an EOS token after each model/assistant turn.
::::or::::useror::::assistantcan be used as stopping strings just as effectively.
Schematical example
The BOS token was omitted here. Messages and descriptions are short for the sake of brevity. The first ::::user block works as a system instruction of some sort.
::::user: Let's engage together in a roleplay.
# Roleplay title
A new day together
# Characters
## Nanashi
Anon's long-time friend. Can be somewhat terse.
{{character description here}}
## Anon
Our main protagonist. A completely normal person.
# Scenario
After meeting together, Anon and Nanashi have a little chat.
::::user:Anon: "Hello," said Anon, "How are you?"
::::assistant:Nanashi: "Very good, thanks for asking," Nanashi responded. "What would you like to do today?"
::::user:Anon: After thinking about it for a brief while, Anon proposed, "Well, we could have a coffee, what about that?"
::::user: (OOC: Can you write in a more cheerful tone?)
::::assistant:Nanashi: "Wow, that would be great! Let's go, let's go!"
::::user:Anon: [...]
Note that in reality OOC messages might not necessarily always have the intended effect. This is something I'm looking into.
SillyTavern context/instruct presets
For convenience, you can use the following SillyTavern context/instruct presets. Rename the files immediately after downloading them:
- Herrsimian-context.json (updated 2024-09-02)
- Herrsimian-instruct.json
SillyTavern-specific notes
- Make sure that Add BOS token is enabled in AI Response Configuration.
- Include names must be enabled in AI Response Formatting.
- Do not enable Names as Stop Strings as it can cause issues where the backend doesn't stop generating text, or produces partially cropped outputs.
- Do not enable Collapse consecutive newlines. This will remove double neuelines which are used in the prompting format.
Sampling settings
There are the settings I've used for testing with text-generation-webui as the backend. Note that the DRY sampler is not yet available in Llama.cpp:
- Neutralize samplers
- Temperature: 1.0
- Min-p: 0.05
- DRY Repetition penalty
- You must add
::::as a Sequence Breaker if you use DRY - Multiplier: 0.8
- Base: 1.75
- Allowed Length: 2
- You must add
Avoid using Repetition/Frequency/Presence Penalty, as they will penalize punctuation and the user/model label markers ::::.
Training details
Unsloth was used on a single RTX3090 24GB GPU with QLoRA finetuning.
As of writing, 131 manually curated, mostly human-sourced samples have been used, for a total of about 1.43M unique tokens at 12k tokens context length (2.45M tokens would have been possible with 52k+ tokens context). The preformatted data was finetuned as raw text (no masking of user turns or labels) for 5 epochs in total using a WSD scheduler without warmup, with constant learning rate for 3 epochs, followed by immediate decay to 25% of the initial learning rate (in the latest run this was simulated by resuming training at a reduced learning rate).
The learning rate was initially chosen so that the lowest eval loss on a representative long sample would occur within one epoch, and overfitting (eval loss increasing beyond the minimum point) happened after that.
In the end I opted for a LoRA Dropout rate of 0.55, which from published literature appears to be close to the optimal value.
Judging model quality in the overfitting regime is not straightforard, as it can increase up to a point and then plummet if overfitting exceeds a certain level.
Training hyperparameters
max_seq_length = 12288
lora_r = 128
lora_alpha = 256
lora_dropout = 0.55
use_rslora = False
per_device_train_batch_size = 1
gradient_accumulation_steps = 1
learning_rate = 0.0000950
warmup_steps = 0
weight_decay = 0.01
num_train_epochs = 5
lr_scheduler_type = "warmup_stable_decay"
lr_scheduler_kwargs = {
'num_stable_steps': 3 epochs
'num_decay_steps': 0 steps
'min_lr_ratio': 25%
}
Eval / Train loss graph
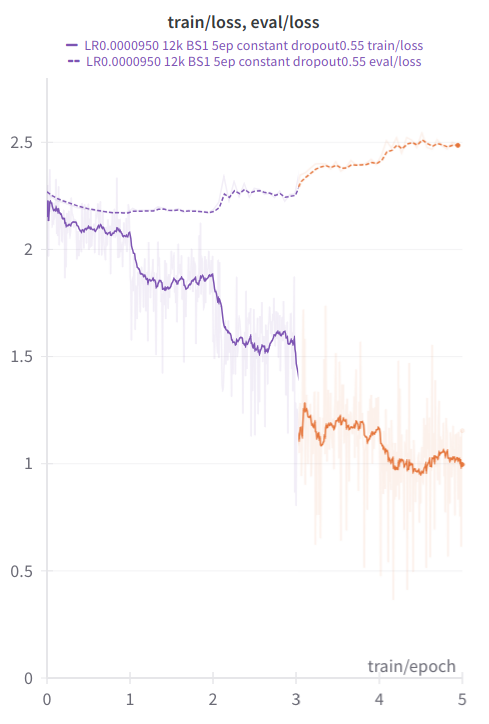 In the orange portion of the graph the learning rate was decreased to 25% of the initial level.
In the orange portion of the graph the learning rate was decreased to 25% of the initial level.
Questions and Answers
Q. Isn't the model overfitted? Isn't overfitting a bad thing?
A. By the common definition of overfitting, yes, it is overfitted. However, overfitting for chatbot use is not necessarily a drawback, see for example Zhou2023 (LIMA paper) and Ouyang2022 (GPT-3 paper), as well as the conclusions in a Guanaco replication attempt. Similarly, with Herrsimian, output quality appeared to subjectively improve with increasing number of training epochs, at least up to a point.
When perfectly fitted, the model upon testing appeared to be bland, but too much overfitting killed response creativity and diminished logic capabilities, although it made it reproduce the syle and vocabulary of the training data better (which was one of the aims of the dataset).
Q. Why raw text / text completion?
A. It's the simplest format to deal with and allows maximum freedom; additionally, the non-standard paradigm used (where user/model turns don't necessarily alternate) can make user turn masking using more complex with existing pipelines.
Q. Why didn't you use prompting format X?
A. Because the model was originally intended to employ a simple, easy-to-type prompting format that could be easily transferred to other models, without extra special tokens which can be difficult to properly train without also training the embeddings sufficiently enough. I also didn't want to use an Alpaca-like prompting format, since it conflicts with Markdown formatting.
Q. Can you train large model Y with the same data?
A. My efforts are limited to what can be done locally in reasonable amounts of time (a couple hours at most) with one 24GB GPU.
Q. Can you upload quantization Z?
A. Due to upload bandwidth limitations I have to be selective regarding what I upload onto my HuggingFace account. Additionally, GGUF quantizations of Llama 3.1 don't seem to work as intended, it turned out.
Q. What about PPO, DPO, KTO...?
A. I haven't bothered yet. Reinforcement learning from human feedback (RLHF) can decrease model creativity, anyway.
Q. Why doesn't the model contain instructions?
A. Actually, an initial iteration included multi-turn synthetic instructions to pad the data up to 1000 samples in total (similar to LIMA). I found however that they didn't have a significant positive effect on roleplaying performance. Simply overtraining on actual human roleplay (after suitable augmentation) in the target format appears to yield overall better results.
Q. What's up with the model name?
A. It's an indirect reference to the author from whom I borrowed the training data. Actually, I wanted to use a cuter name, but that might have possibly jeopardized the original author's privacy.
Q. Who is the character in the top image?
A. It's Son Biten from Touhou Juuouen - Unfinished Dream of All Living Ghost. Check out Gelbooru for the unedited source image.
- Downloads last month
- 176
Model tree for QuantFactory/Llama-3.1-Herrsimian-8B-GGUF
Base model
meta-llama/Meta-Llama-3.1-8B