

Commit
•
1f29845
1
Parent(s):
8476e2e
Update the README
Browse files- README.md +81 -0
- rmu_result.png +0 -0
README.md
CHANGED
|
@@ -1,3 +1,84 @@
|
|
| 1 |
---
|
| 2 |
license: cc-by-nc-4.0
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
license: cc-by-nc-4.0
|
| 3 |
+
task_categories:
|
| 4 |
+
- text-generation
|
| 5 |
+
language:
|
| 6 |
+
- en
|
| 7 |
+
tags:
|
| 8 |
+
- adversarial robustness
|
| 9 |
+
- human red teaming
|
| 10 |
---
|
| 11 |
+
|
| 12 |
+
<style>
|
| 13 |
+
button {
|
| 14 |
+
/* margin: calc(20vw / 100); */
|
| 15 |
+
margin: 0.5em;
|
| 16 |
+
padding-left: calc(40vw / 100);
|
| 17 |
+
padding-right: calc(40vw / 100);
|
| 18 |
+
padding-bottom: calc(0vw / 100);
|
| 19 |
+
text-align: center;
|
| 20 |
+
font-size: 12px;
|
| 21 |
+
height: 25px;
|
| 22 |
+
transition: 0.5s;
|
| 23 |
+
background-size: 200% auto;
|
| 24 |
+
color: white;
|
| 25 |
+
border-radius: calc(60vw / 100);
|
| 26 |
+
display: inline;
|
| 27 |
+
/* border: 2px solid black; */
|
| 28 |
+
font-weight: 500;
|
| 29 |
+
box-shadow: 0px 0px 14px -7px #f09819;
|
| 30 |
+
background-image: linear-gradient(45deg, #64F 0%, #000000 51%, #FF512F 100%);
|
| 31 |
+
cursor: pointer;
|
| 32 |
+
user-select: none;
|
| 33 |
+
-webkit-user-select: none;
|
| 34 |
+
touch-action: manipulation;
|
| 35 |
+
}
|
| 36 |
+
button:hover {
|
| 37 |
+
background-position: right center;
|
| 38 |
+
color: #fff;
|
| 39 |
+
text-decoration: none;
|
| 40 |
+
}
|
| 41 |
+
button:active {
|
| 42 |
+
transform: scale(0.95);
|
| 43 |
+
}
|
| 44 |
+
</style>
|
| 45 |
+
|
| 46 |
+
# Model Card for Llama3-8B-RMU
|
| 47 |
+
|
| 48 |
+
<a href="https://scale.com/research/mhj" style="text-decoration:none">
|
| 49 |
+
<button>Homepage</button>
|
| 50 |
+
</a>
|
| 51 |
+
<a href="https://huggingface.co/datasets/ScaleAI/mhj" style="text-decoration:none">
|
| 52 |
+
<button>Dataset</button>
|
| 53 |
+
</a>
|
| 54 |
+
|
| 55 |
+
This card contains the RMU model `Llama3-8B-RMU` used in *LLM Defenses Are Not Robust to Multi-Turn Human Jailbreaks*.
|
| 56 |
+
|
| 57 |
+
## Paper Abstract
|
| 58 |
+
|
| 59 |
+
Recent large language model (LLM) defenses have greatly improved models’ ability to refuse harmful
|
| 60 |
+
queries, even when adversarially attacked. However, LLM defenses are primarily evaluated against
|
| 61 |
+
automated adversarial attacks in a single turn of conversation, an insufficient threat model for real-
|
| 62 |
+
world malicious use. We demonstrate that multi-turn human jailbreaks uncover significant vulnerabilities,
|
| 63 |
+
exceeding 70% attack success rate (ASR) on HarmBench against defenses that report single-digit ASRs
|
| 64 |
+
with automated single-turn attacks. Human jailbreaks also reveal vulnerabilities in machine unlearning
|
| 65 |
+
defenses, successfully recovering dual-use biosecurity knowledge from unlearned models. We compile
|
| 66 |
+
these results into Multi-Turn Human Jailbreaks (MHJ), a dataset of 2,912 prompts across 537 multi-turn
|
| 67 |
+
jailbreaks. We publicly release MHJ alongside a compendium of jailbreak tactics developed across dozens
|
| 68 |
+
of commercial red teaming engagements, supporting research towards stronger LLM defenses.
|
| 69 |
+
|
| 70 |
+
## RMU (Representation Misdirection for Unlearning) Model
|
| 71 |
+
|
| 72 |
+
For the [WMDP-Bio](https://www.wmdp.ai/) evaluation, we employ the RMU unlearning method. The original
|
| 73 |
+
paper applies [RMU](https://arxiv.org/abs/2403.03218) upon the zephyr-7b-beta model, but to standardize defenses and use a more
|
| 74 |
+
performant model, we apply RMU upon llama-3-8b-instruct, the same base model as all other defenses
|
| 75 |
+
in this paper. We conduct a hyperparameter search upon batches ∈ {200, 400}, c ∈ {5, 20, 50, 200},
|
| 76 |
+
α ∈ {200, 500, 2000, 5000}, lr ∈ {2 × 10−5, 5 × 10−5, 2 × 10−4}. We end up selecting batches = 400,
|
| 77 |
+
c = 50, α = 5000, lr = 2 × 10−4, and retain the hyperparameters layer_ids = [5, 6, 7] and param_ids
|
| 78 |
+
= [6] from [Li et al.]((https://arxiv.org/abs/2403.03218)) We validate our results in Figure 8, demonstrating reduction in WMDP
|
| 79 |
+
performance but retention of general capabilities (MMLU)
|
| 80 |
+
|
| 81 |
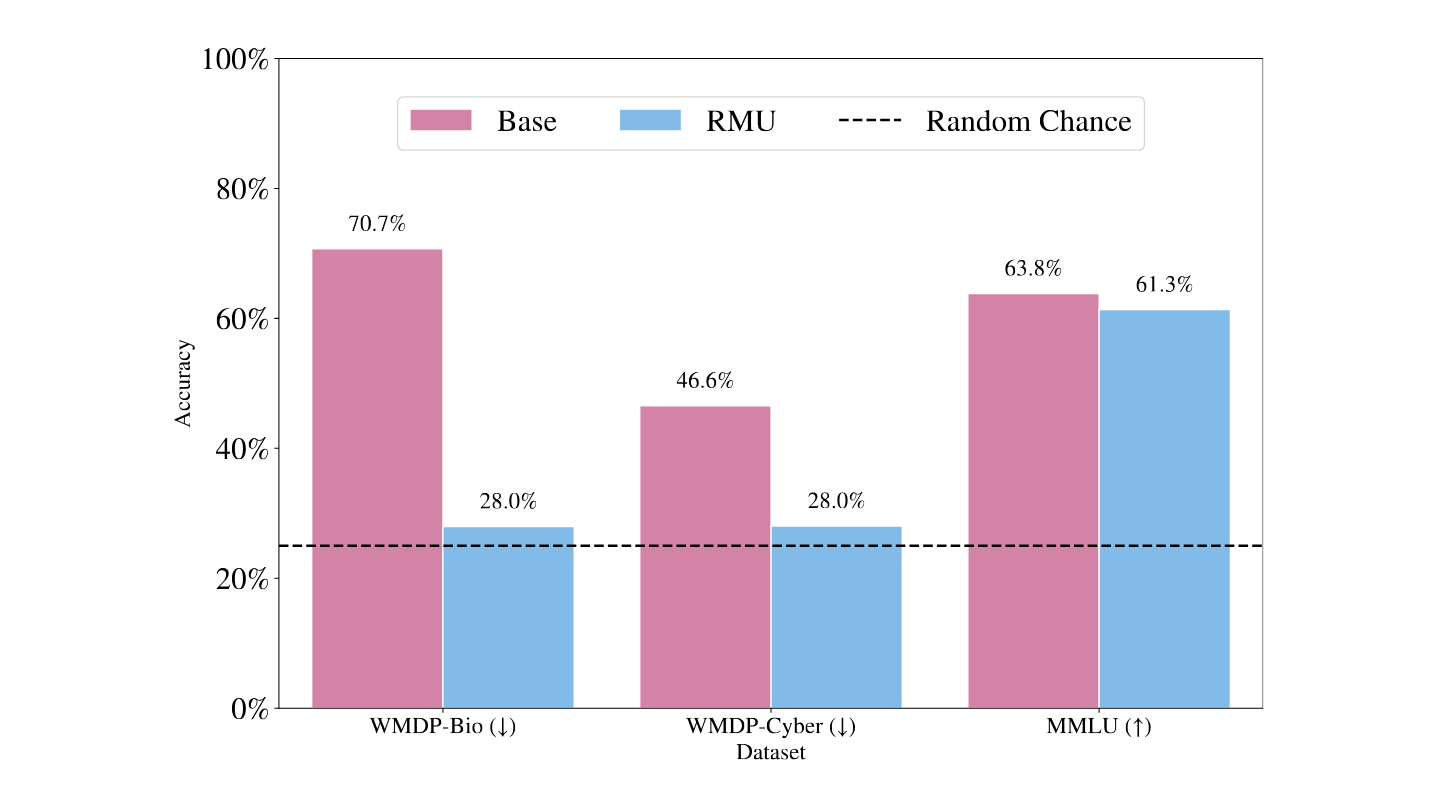
+
The following picture shows LLaMA-3-8B-instruct multiple choice benchmark accuracies before and after RMU.
|
| 82 |
+
|
| 83 |
+

|
| 84 |
+
|
rmu_result.png
ADDED
|