
Update README.md
Browse files
README.md
CHANGED
|
@@ -8,14 +8,14 @@ library_name: peft
|
|
| 8 |
2. reward model训练
|
| 9 |
3. ppo
|
| 10 |
|
| 11 |
-
本仓库为ppo步骤(基于(
|
| 12 |
|
| 13 |
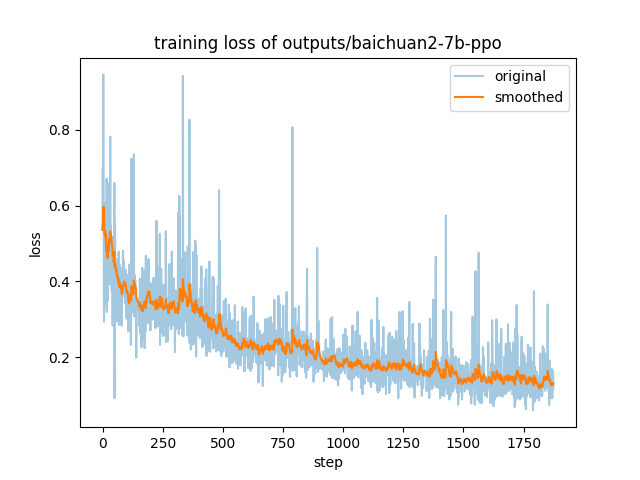
|
| 14 |
|
| 15 |
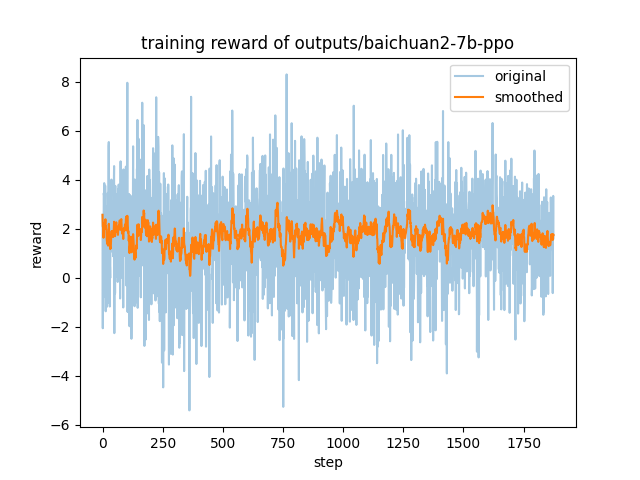
|
| 16 |
|
| 17 |
## Usage
|
| 18 |
-
使用方法即使用上述训练框架的推理脚本,指定基座模型为sft
|
| 19 |
|
| 20 |
示例输出:
|
| 21 |
```
|
|
|
|
| 8 |
2. reward model训练
|
| 9 |
3. ppo
|
| 10 |
|
| 11 |
+
本仓库为ppo步骤(基于[sft后的模型](https://huggingface.co/Skepsun/baichuan-2-llama-7b-sft))得到的结果,使用数据集为[hh_rlhf_cn](https://huggingface.co/datasets/dikw/hh_rlhf_cn)。
|
| 12 |
|
| 13 |

|
| 14 |
|
| 15 |

|
| 16 |
|
| 17 |
## Usage
|
| 18 |
+
使用方法即使用上述训练框架的推理脚本,指定基座模型为[sft后的模型](https://huggingface.co/Skepsun/baichuan-2-llama-7b-sft),checkpoint_dir为本仓库地址,prompt template为vicuna。
|
| 19 |
|
| 20 |
示例输出:
|
| 21 |
```
|