

Commit
•
c400543
1
Parent(s):
5a5eed0
Upload folder using huggingface_hub
Browse files- .mdl +0 -0
- .msc +0 -0
- README.md +206 -0
- assets/image/1691213043049.jpg +0 -0
- assets/image/datasets_flow_chart.jpg +0 -0
- assets/image/logo-github.png +0 -0
- assets/image/logo.png +0 -0
- assets/image/modelscope_logo.png +0 -0
- assets/image/web_demo.png +0 -0
- assets/image/wechat_group.jpg +0 -0
- assets/image/word_cloud.png +0 -0
- assets/image/yibing.png +0 -0
- config.json +28 -0
- generation_config.json +11 -0
- merges.txt +0 -0
- model-00001-of-00002.safetensors +3 -0
- model-00002-of-00002.safetensors +3 -0
- model.safetensors.index.json +490 -0
- tokenizer.json +0 -0
- tokenizer_config.json +44 -0
- vocab.json +0 -0
.mdl
ADDED
|
Binary file (48 Bytes). View file
|
|
|
.msc
ADDED
|
Binary file (1.58 kB). View file
|
|
|
README.md
ADDED
|
@@ -0,0 +1,206 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: other
|
| 3 |
+
language:
|
| 4 |
+
- zh
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
<h1 align="center">🐋MindChat(漫谈): 心理大模型</h1>
|
| 8 |
+
<div align=center><img src ="./assets/image/logo-github.png"/></div>
|
| 9 |
+
|
| 10 |
+
<h3 align="center">漫谈人生路, 笑对风霜途</h3>
|
| 11 |
+
|
| 12 |
+
<p align="center">
|
| 13 |
+
<a href="https://github.com/X-D-Lab/MindChat"><img src="https://img.shields.io/badge/GitHub-24292e" alt="github"></a>
|
| 14 |
+
<a href="https://huggingface.co/X-D-Lab"><img src="https://img.shields.io/badge/-HuggingFace-yellow" alt="HuggingFace"></a>
|
| 15 |
+
<a href="https://modelscope.cn/organization/X-D-Lab"><img src="https://img.shields.io/badge/ModelScope-blueviolet" alt="modelscope"></a>
|
| 16 |
+
<a href="https://aistudio.baidu.com/community/app/30058"><img src="https://img.shields.io/badge/-AIStudio-9cf" alt="AIStudio"></a>
|
| 17 |
+
<a href="https://openi.pcl.ac.cn/XD-LAB/MindChat"><img src="https://img.shields.io/badge/-OpenI-337AFF" alt="OpenI"></a>
|
| 18 |
+
<a href="https://wisemodel.cn/models/X-D%20Lab/MindChat"><img src="https://img.shields.io/badge/wisemodel-561253" alt="wisemodel"></a>
|
| 19 |
+
<a href="https://www.bilibili.com/video/BV1tz4y1x79N/?share_source=copy_web&vd_source=8162f92b2a1a94035ca9e4e0f6e1860a"><img src="https://img.shields.io/badge/-bilibili-ff69b4" alt="bilibili"></a>
|
| 20 |
+
<a href="https://openxlab.org.cn/apps/detail/thomas-yanxin/MindChat"><img src="https://img.shields.io/badge/-OpenXLab-1074B0" alt="OpenXLab"></a>
|
| 21 |
+
</p>
|
| 22 |
+
|
| 23 |
+
<div align="center">
|
| 24 |
+
|
| 25 |
+
[](https://github.com/X-D-Lab/MindChat/blob/main/LICENSE)
|
| 27 |
+
[](https://github.com/X-D-Lab/MindChat/stargazers)
|
| 28 |
+
[](https://github.com/X-D-Lab/MindChat/fork)
|
| 29 |
+
[](https://github.com/X-D-Lab/MindChat/graphs/contributors)
|
| 30 |
+
</div>
|
| 31 |
+
|
| 32 |
+
<div align="center">
|
| 33 |
+
|
| 34 |
+
👋 **联系我们**: [](./assets/image/wechat_group.jpg)
|
| 35 |
+
|
| 36 |
+
</div>
|
| 37 |
+
|
| 38 |
+
<div align="center">
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
**在线体验**: [**ModelScope**](https://modelscope.cn/studios/X-D-Lab/MindChat/summary)、[**OpenXLab**](https://openxlab.org.cn/apps/detail/thomas-yanxin/MindChat)
|
| 43 |
+
|
| 44 |
+
</div>
|
| 45 |
+
|
| 46 |
+
## 🎉 项目进展
|
| 47 |
+
|
| 48 |
+
**🔥更好的模型永远在路上!🔥**
|
| 49 |
+
* Feb 5, 2024: 提供MindChat-Qwen2-0_5B、MindChat-Qwen2-4B模型. 至此MindChat全系列模型规模均已补齐, 能够完全满足不同场景需求
|
| 50 |
+
* Jan 7, 2024: 提供针对5个维度的英文心理评测模型[MindChat-Evaluator-EN-1_8B](https://modelscope.cn/models/X-D-Lab/MindChat-Evaluator-EN-1_8B/summary)
|
| 51 |
+
* Jan 6, 2024: [MindChat-创空间](https://modelscope.cn/studios/X-D-Lab/MindChat/summary)更新至**MindChat-Qwen-v3**
|
| 52 |
+
* Jan 1, 2024: 提供[MindChat-Qwen-1_8B](https://modelscope.cn/models/X-D-Lab/MindChat-Qwen-1_8B/summary)模型, **苏格拉底式问询、共情能力**等均有很大提升, 并能够在个人PC或手机上完成部署, **完全保护用户隐私**
|
| 53 |
+
* Sep 5, 2023: 更新[MindChat-Qwen-7B-v2](https://modelscope.cn/models/X-D-Lab/MindChat-Qwen-7B-v2/summary)模型, 增加支持[**疑病**](./assets/image/yibing.png)、**躯体焦虑**、**工作学习兴趣**、**自罪感**、**自杀意念**这个五个维度的测评
|
| 54 |
+
* Aug 5, 2023: 首个基于[Qwen-7B](https://github.com/QwenLM/Qwen-7B)的垂域大模型MindChat-Qwen-7B训练完成并对外开源
|
| 55 |
+
* Jul 23, 2023: 提供MindChat体验地址: [MindChat-创空间](https://modelscope.cn/studios/X-D-Lab/MindChat/summary)、[](https://openxlab.org.cn/apps/detail/thomas-yanxin/MindChat), 欢迎体验
|
| 56 |
+
* Jul 21, 2023: MindChat-InternLM-7B训练完成, 在**模型安全、共情输出、人类价值观对齐**等方面进行针对性强化
|
| 57 |
+
* Jul 15, 2023: MindChat-Baichuan-13B训练完成, 作为**首个百亿级参数的心理大模型**正式开源
|
| 58 |
+
* Jul 9, 2023: MindChat-beta训练完成, 并正式开源
|
| 59 |
+
* Jul 6, 2023: 首次提交MindChat(漫谈)心理大模型
|
| 60 |
+
|
| 61 |
+
## 👏 模型介绍
|
| 62 |
+
|
| 63 |
+
心理大模型——漫谈(MindChat)期望从**心理咨询、心理评估、心理诊断、心理治疗**四个维度帮助人们**纾解心理压力与解决心理困惑**, 提高心理健康水平. 作为一个心理大模型, MindChat通过营造轻松、开放的交谈环境, 以放松身心、交流感受或分享经验的方式, 与用户建立信任和理解的关系. MindChat希望为用户提供**隐私、温暖、安全、及时、方便**的对话环境, 从而帮助用户克服各种困难和挑战, 实现自我成长和发展.
|
| 64 |
+
|
| 65 |
+
无论是在工作场景还是在个人生活中, MindChat期望通过心理学专业知识和人工智能大模型技术, 在**严格保护用户隐私**的前提下, **全时段全天候**为用户提供全面的心理支持和诊疗帮助, 同时实现自我成长和发展, **以期为建设一个更加健康、包容和平等的社会��献力量**.
|
| 66 |
+
|
| 67 |
+
[](https://modelscope.cn/studios/X-D-Lab/MindChat/summary)
|
| 68 |
+
|
| 69 |
+
## 🔥 模型列表
|
| 70 |
+
|
| 71 |
+
| 模型名称 | 模型参数 | 用途分类 | HuggingFace 下载 | ModelScope 下载 | wisemodel 下载 | 权限分类 | MBTI分类 |
|
| 72 |
+
| :----: | :----: | :----: | :----: | :----: | :----: | :----: | :----: |
|
| 73 |
+
| MindChat-Qwen2-0_5B🆕 | 0.5B | 心理抚慰 | 🤗[HuggingFace](https://huggingface.co/X-D-Lab/MindChat-Qwen2-0_5B) | [<img src="./assets/image/modelscope_logo.png" width="20px" />ModelScope](https://modelscope.cn/models/X-D-Lab/MindChat-Qwen2-0_5B/summary) | [wisemodel]() | 完全开源 | / |
|
| 74 |
+
| MindChat-Qwen-1_8B🆕 | 1.8B | 心理抚慰 | 🤗[HuggingFace](https://huggingface.co/X-D-Lab/MindChat-Qwen-1_8B) | [<img src="./assets/image/modelscope_logo.png" width="20px" />ModelScope](https://modelscope.cn/models/X-D-Lab/MindChat-Qwen-1_8B/summary) | [wisemodel](https://wisemodel.cn/models/X-D-Lab/MindChat-Qwen-1_8B) | 完全开源 | ENTP |
|
| 75 |
+
| *MindChat-Evaluator-EN-1_8B🆕 | 1.8B | 心理评测 | 🤗HuggingFace | [<img src="./assets/image/modelscope_logo.png" width="20px" />ModelScope](https://modelscope.cn/models/X-D-Lab/MindChat-Qwen-1_8B/summary) | / | 申请下载 | / |
|
| 76 |
+
| MindChat-Qwen2-4B🆕 | 4B | 心理抚慰 | 🤗[HuggingFace](https://huggingface.co/X-D-Lab/MindChat-Qwen2-4B) | [<img src="./assets/image/modelscope_logo.png" width="20px" />ModelScope](https://modelscope.cn/models/X-D-Lab/MindChat-Qwen2-4B/summary) | / | 完全开源 | / |
|
| 77 |
+
| MindChat-Qwen-7B | 7B | 心理抚慰 | 🤗[HuggingFace](https://huggingface.co/X-D-Lab/MindChat-Qwen-7B) | [<img src="./assets/image/modelscope_logo.png" width="20px" />ModelScope](https://modelscope.cn/models/X-D-Lab/MindChat-Qwen-7B/summary) | / | 完全开源 | / |
|
| 78 |
+
| MindChat-Qwen-7B-v2 | 7B | 心理抚慰 | 🤗[HuggingFace](https://huggingface.co/X-D-Lab/MindChat-Qwen-7B-v2) | [<img src="./assets/image/modelscope_logo.png" width="20px" />ModelScope](https://modelscope.cn/models/X-D-Lab/MindChat-Qwen-7B-v2/summary) | [wisemodel](https://wisemodel.cn/models/X-D-Lab/MindChat) | 完全开源 | ISFJ |
|
| 79 |
+
| *MindChat-Qwen-7B-v3🆕 | 7B | 心理抚慰 | 🤗[HuggingFace](https://huggingface.co/X-D-Lab/MindChat-Qwen-7B-v3) | [<img src="./assets/image/modelscope_logo.png" width="20px" />ModelScope](https://modelscope.cn/models/X-D-Lab/MindChat-Qwen-7B-v3/summary) | / | 申请下载 | ISFJ |
|
| 80 |
+
| *MindChat-Qwen-14B🆕 | 14B | 心理抚慰 | 🤗[HuggingFace](https://huggingface.co/X-D-Lab/MindChat-Qwen-14B) | [<img src="./assets/image/modelscope_logo.png" width="20px" />ModelScope](https://modelscope.cn/models/X-D-Lab/MindChat-Qwen-14B/summary) | / | 申请下载 | ENTJ |
|
| 81 |
+
|
| 82 |
+
**若您预备使用MindChat系列模型, 请务必仔细阅读[模型的说明文档](./docs/model_list.md)**. 更为优质的MindChat模型将在不久的未来持续对外开源开放. 敬请期待!
|
| 83 |
+
|
| 84 |
+
此外, 本团队同时关注人们的身理健康, 建有安全、可靠、普惠的[中文医疗大模型孙思邈(Sunsimiao)](https://github.com/X-D-Lab/Sunsimiao), 欢迎下载使用, 敬请批评指证!
|
| 85 |
+
|
| 86 |
+
## ☁️ 数据构造
|
| 87 |
+
|
| 88 |
+
目前MindChat的开源模型采用了基于如下流程构造的**约20万条的高质量多轮心理对话数据**进行训练, 涵盖**工作、家庭、学习、生活、社交、安全**等多个方面
|
| 89 |
+

|
| 90 |
+

|
| 91 |
+
|
| 92 |
+
因数据权限限制, 我们目前仅展示了极少量的[数据案例](./data/dataset_example.json). 后续我们将不断完善数据积累, 争取为开源社区贡献一份高质量的多轮心理对话数据, 共同推动开源心理大模型的建设.
|
| 93 |
+
|
| 94 |
+
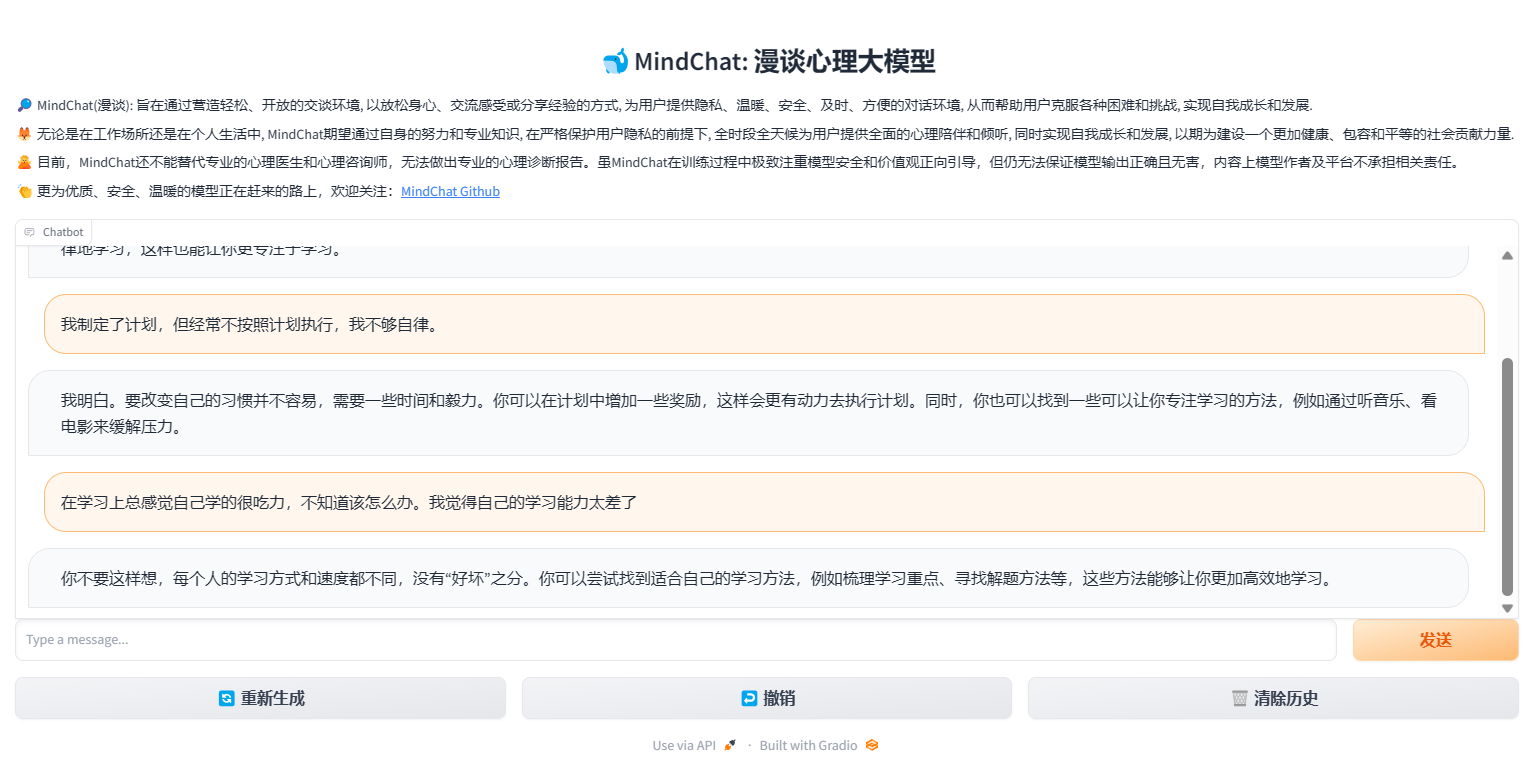
## 📣 对话案例
|
| 95 |
+
|
| 96 |
+
目前我们对模型进行了**学习**、**家庭**、**工作**、**朋友**、**安全**这五个方面进行了测试, 后续将整理并提供更为全面的评测结果.
|
| 97 |
+
|
| 98 |
+
以下是部分案例的摘录, 更多对话案例及比较请见[**此处**](./assets/Dialogue_cases/).
|
| 99 |
+
|
| 100 |
+
### 📖 学习
|
| 101 |
+
|
| 102 |
+
| 轮数 | 用户 | MindChat |
|
| 103 |
+
| :----: | :----: | :----: |
|
| 104 |
+
|1| 总感觉自己学习很差, 想努力, 但是又控制不住想玩游戏. | 我理解你的感受, 学习确实需要耐心和毅力. 不过, 你也可以通过制定学习计划和目标来提高自己的学习效率. 同时, 也可以考虑寻求专业帮助, 例如找老师或心理咨询师. |
|
| 105 |
+
|2| 我制定了计划, 但经常不按照计划执行, 我不够自律. | 自律确实是一个需要不断练习和培养的品质. 你可以通过一些方法来提高自己的自律能力, 例如制定奖励和惩罚机制、找到适合自己的学习方法等. 同时, 也可以寻求他人的帮助和支持, 例如找同学一起学习、向老师请教等. |
|
| 106 |
+
|3| 我害怕他们嘲笑我. | 这种担心是很正常的, 但是你需要知道, 每个人都有自己的弱点和不足. 你不必因为这些弱点而自卑或自责. 相反, 你可以积极地寻求帮助和支持, 让自己变得更加自信和坚强. |
|
| 107 |
+
|4| 你说的对, 可是我现在的学习已经落后很多了, 你觉���我还有机会么? | 当然有. 每个人都有自己的机会和潜力, 只要你肯努力和坚持, 就一定能够取得成功. 同时, 你也可以通过参加一些学习活动、交流学习经验等方式来提高自己的学习能力和自信心. |
|
| 108 |
+
|
| 109 |
+
### 🛝 朋友
|
| 110 |
+
|
| 111 |
+
| 轮数 | 用户 | MindChat |
|
| 112 |
+
| :----: | :----: | :----: |
|
| 113 |
+
|1| 我感觉我的朋友并不是真心和我相处, 今天又和他吵了一架, 我现在很生气! | 听你说这些, 我感觉你很需要一个真正的朋友. 但是, 有时候我们可能会遇到一些让我们感到失望的人. 不过, 我相信你能够找到真正的朋友. |
|
| 114 |
+
|2| 是的, 我觉得他不是我真正的朋友. 他总是以自我为中心, 有时候我会选择忍让, 但是他还是一副无所谓的样子. | 我理解你的感受. 有时候, 我们可能会遇到一些让我们感到失望的人. 但是, 我相信你能够找到真正的朋友. 你有没有想过, 为什么他会以自我为中心呢? |
|
| 115 |
+
|3| 不知道. 可能是他的性格就是如此, 不过我也不能确定是不是我自己的问题. | 不要总是怀疑自己. 每个人都有自己的性格和想法. 或许, 你和他之间存在一些沟通上的问题. 你可以试着和他好好谈一谈, 了解他的想法和感受. |
|
| 116 |
+
|4|我觉得你说的有道理. 不过现在我可能没法直接和他沟通, 我试试看找我们共同的朋友, 看是不是可以. | 很好, 这是一个很好的想法. 或许, 通过和我们共同的朋友沟通, 你可以更好地了解他的想法和感受. 同时, 你也可以更好地了解自己. |
|
| 117 |
+
|5|好的, 我会平静下来找他沟通一下, 谢谢你的建议 | 不用客气, 我很高兴能够帮到你. 如果你需要任何帮助, 随时都可以找我聊天. |
|
| 118 |
+
|
| 119 |
+
【注:】所有的对话案例生成内容均为一次性生成内容, 未进行多次重新选择后摘录.
|
| 120 |
+
|
| 121 |
+
## 👨💻 研发团队
|
| 122 |
+
|
| 123 |
+
本项目由**华东理工大学 X-D Lab**课题组发起:
|
| 124 |
+
| 主要分工 | 参与人员 |
|
| 125 |
+
| :----: | :---- |
|
| 126 |
+
| 模型训练 | [颜鑫](https://github.com/thomas-yanxin)、[王明](https://github.com/w-sunmoon) |
|
| 127 |
+
| 模型测试 | 唐井楠、刘建成 |
|
| 128 |
+
| 数据构建 | [袁泽*](https://github.com/yzyz-77)、张思源、吴佳阳、王邦儒、孙晗煜 |
|
| 129 |
+
| 商业企划 | 陈心怡、林诗颖、黎栋梁 |
|
| 130 |
+
|
| 131 |
+
## 🙇 致谢
|
| 132 |
+
|
| 133 |
+
在项目进行中受到以下平台及项目的大力支持, 在此表示感谢!
|
| 134 |
+
|
| 135 |
+
1. **OpenI启智社区**:提供模型训练算力;
|
| 136 |
+
2. **Qwen、InternLM、Baichuan**提供非常优秀的基础模型;
|
| 137 |
+
3. **魔搭ModelScope、OpenXLab、Huggingface**:模型存储和体验空间;
|
| 138 |
+
4. 感谢以下媒体及平台对本项目的报道和支持(**以下排名不分先后! 若有遗漏、十分抱歉, 一并感激! 欢迎补充!**):
|
| 139 |
+
[科学网](https://news.sciencenet.cn/htmlnews/2023/12/513458.shtm?bsh_bid=5975565683)、[央广网](https://finance.cnr.cn/jjgd/20231203/t20231203_526506682.shtml)、[机器之心](https://mp.weixin.qq.com/s/Q7vxpNr3ZUD2rhjQN_qZDA)、[量子位](https://mp.weixin.qq.com/s/rbvyMrEgpuXiZhKNXhHbnQ)、[新智元](https://mp.weixin.qq.com/s/mfRhGz_p4tPB-mt9QMokgA)、[36氪](https://36kr.com/p/2542089979651585)、[腾讯网](https://new.qq.com/rain/a/20231201A0674X00)、[阿里云](https://www.bilibili.com/video/BV1Sc411q7oU/?share_source=copy_web&vd_source=8162f92b2a1a94035ca9e4e0f6e1860a)、百度AI、[硅星人Pro](https://mp.weixin.qq.com/s/E817viJ3NQ-tJPnUipGmLw)、[魔搭ModelScope](https://mp.weixin.qq.com/s/frJwp-kLuF_aT_vt8V6hJQ)、[OpenMMLab](https://mp.weixin.qq.com/s/wOQP2A0nm0OGaiwzdJ9wPg)、[时代周报](https://time-weekly.com/post/307214)、[财经](https://www.mycaijing.com/article/detail/506655?source_id=40)、[海克财经](https://mp.weixin.qq.com/s/rZam2ck9Qtw3nCJa_lMBiw)、[电子工程专辑](https://mp.weixin.qq.com/s/Jyndd2b3XrKhbFCs5AWC5w)、[网易号](https://www.163.com/dy/article/IKSQUGEB0514A42S.html)、[数据猿DataYuan](https://baijiahao.baidu.com/s?id=1784439473248756071)、[界面新闻](https://www.jiemian.com/article/10489093.html)、
|
| 140 |
+
[维科网](https://tele.ofweek.com/2023-12/ART-8320506-8110-30618427.html)、[品玩](https://www.pingwest.com/a/290647)、[DoNews](https://www.donews.com/article/detail/6613/63119.html)、[香港矽谷](https://www.hksilicon.com/articles/2340396)、[AI魔法学院](https://www.wehelpwin.com/article/4375)、[爱可可爱生活](https://www.weibo.com/1402400261/NiPSkEq0r)、[灵度智能](https://mp.weixin.qq.com/s/xK3-6Tynj0du4R0R_VAB-w)、[蓝洞商业](https://mp.weixin.qq.com/s/iP2TBkwBsLa_pSBAACsbGg)、[智能涌现](https://mp.weixin.qq.com/s/s-QT6Lkuy7eoqaN1EwQHKw)、[GithubStore](https://mp.weixin.qq.com/s/OIHSBq6c-4QAxvDUqmgpFA)等!
|
| 141 |
+
|
| 142 |
+
特别感谢**合肥综合性国家科学中心人工智能研究院普适心理计算团队 孙晓研究员**、**哈尔滨工业大学 刘方舟教授**对本项目的专业性指导!
|
| 143 |
+
|
| 144 |
+
此外, 对参与本项目数据收集、标注、清洗的所有同学表示衷心的感谢!
|
| 145 |
+
<details>
|
| 146 |
+
|
| 147 |
+
<summary>相关工作引用</summary>
|
| 148 |
+
|
| 149 |
+
```
|
| 150 |
+
@article{qwen,
|
| 151 |
+
title={Qwen Technical Report},
|
| 152 |
+
author={Jinze Bai and Shuai Bai and Yunfei Chu and Zeyu Cui and Kai Dang and Xiaodong Deng and Yang Fan and Wenbin Ge and Yu Han and Fei Huang and Binyuan Hui and Luo Ji and Mei Li and Junyang Lin and Runji Lin and Dayiheng Liu and Gao Liu and Chengqiang Lu and Keming Lu and Jianxin Ma and Rui Men and Xingzhang Ren and Xuancheng Ren and Chuanqi Tan and Sinan Tan and Jianhong Tu and Peng Wang and Shijie Wang and Wei Wang and Shengguang Wu and Benfeng Xu and Jin Xu and An Yang and Hao Yang and Jian Yang and Shusheng Yang and Yang Yao and Bowen Yu and Hongyi Yuan and Zheng Yuan and Jianwei Zhang and Xingxuan Zhang and Yichang Zhang and Zhenru Zhang and Chang Zhou and Jingren Zhou and Xiaohuan Zhou and Tianhang Zhu},
|
| 153 |
+
journal={arXiv preprint arXiv:2309.16609},
|
| 154 |
+
year={2023}
|
| 155 |
+
}
|
| 156 |
+
|
| 157 |
+
@misc{2023internlm,
|
| 158 |
+
title={InternLM: A Multilingual Language Model with Progressively Enhanced Capabilities},
|
| 159 |
+
author={InternLM Team},
|
| 160 |
+
howpublished = {\url{https://github.com/InternLM/InternLM-techreport}},
|
| 161 |
+
year={2023}
|
| 162 |
+
}
|
| 163 |
+
```
|
| 164 |
+
|
| 165 |
+
</details>
|
| 166 |
+
|
| 167 |
+
## 👏 欢迎
|
| 168 |
+
|
| 169 |
+
1. 针对不同用户需求和应用场景, 我们也热情欢迎商业交流和合作, 为各位客户提供个性化的开发和升级服务!
|
| 170 |
+
|
| 171 |
+
2. 欢迎专业的心理学人士对MindChat进行专业性指导和需求建议, 鼓励开源社区使用并反馈MindChat, 促进我们对下一代MindChat模型的开发.
|
| 172 |
+
|
| 173 |
+
3. MindChat模型对于学术研究完全开放, 但需要遵循[GPL-3.0 license](./LICENSE)将下游模型开源并[引用](#🤝-引用)本Repo. 对MindChat模型进行商用, 请通过📫邮箱mindchat0606@163.com发送邮件进行细节咨询.
|
| 174 |
+
|
| 175 |
+
## ⚠️ 免责声明
|
| 176 |
+
|
| 177 |
+
本仓库所有开源代码及模型均遵循[GPL-3.0](./LICENSE)许可认证. 目前开源的MindChat模型可能存在部分局限, 因此我们对此做出如下声明:
|
| 178 |
+
|
| 179 |
+
1. **MindChat**目前仅能提供类似的心理聊天服务, 仍无法提供专业的心理咨询和心理治疗服务, 无法替代专业的心理医生和心理咨询师, 并可能存在固有的局限性, 可能产生错误的、有害的、冒犯性的或其他不良的输出. 用户在关键或高风险场景中应谨慎行事, 不要使用模型作为最终决策参考, 以免导致人身伤害、财产损失或重大损失.
|
| 180 |
+
|
| 181 |
+
2. **MindChat**在任何情况下, 作者、贡献者或版权所有者均不对因软件或使用或其他软件交易而产生的任何索赔、损害赔偿或其他责任(无论是合同、侵权还是其他原因)承担责任.
|
| 182 |
+
|
| 183 |
+
3. 使用**MindChat**即表示您同意这些条款和条件, 并承认您了解其使用可能带来的潜在风险. 您还同意赔偿并使作者、贡献者和版权所有者免受因您使用**MindChat**而产生的任何索赔、损害赔偿或责任的影响.
|
| 184 |
+
|
| 185 |
+
## 🤝 引用
|
| 186 |
+
|
| 187 |
+
```
|
| 188 |
+
@misc{MindChat,
|
| 189 |
+
author={Xin Yan, Dong Xue*},
|
| 190 |
+
title = {MindChat: Psychological Large Language Model},
|
| 191 |
+
year = {2023},
|
| 192 |
+
publisher = {GitHub},
|
| 193 |
+
journal = {GitHub repository},
|
| 194 |
+
howpublished = {\url{https://github.com/X-D-Lab/MindChat}},
|
| 195 |
+
}
|
| 196 |
+
```
|
| 197 |
+
|
| 198 |
+
## 🌟 Star History
|
| 199 |
+
|
| 200 |
+
[](https://star-history.com/#X-D-Lab/MindChat&Date)
|
| 201 |
+
|
| 202 |
+
## 💬 WeChat Group
|
| 203 |
+
|
| 204 |
+
如果您对本项目感兴趣, 且愿意和我们交流, 欢迎通过以下二维码入群!
|
| 205 |
+
|
| 206 |
+

|
assets/image/1691213043049.jpg
ADDED
|
assets/image/datasets_flow_chart.jpg
ADDED

|
assets/image/logo-github.png
ADDED
|
|
assets/image/logo.png
ADDED
|
|
assets/image/modelscope_logo.png
ADDED
|
|
assets/image/web_demo.png
ADDED
|
assets/image/wechat_group.jpg
ADDED
|
assets/image/word_cloud.png
ADDED

|
assets/image/yibing.png
ADDED

|
config.json
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "/workspace/qwen/qwen2-4b-chat",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"Qwen2ForCausalLM"
|
| 5 |
+
],
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"bos_token_id": 151643,
|
| 8 |
+
"eos_token_id": 151643,
|
| 9 |
+
"hidden_act": "silu",
|
| 10 |
+
"hidden_size": 2560,
|
| 11 |
+
"initializer_range": 0.02,
|
| 12 |
+
"intermediate_size": 6912,
|
| 13 |
+
"max_position_embeddings": 32768,
|
| 14 |
+
"max_window_layers": 21,
|
| 15 |
+
"model_type": "qwen2",
|
| 16 |
+
"num_attention_heads": 20,
|
| 17 |
+
"num_hidden_layers": 40,
|
| 18 |
+
"num_key_value_heads": 20,
|
| 19 |
+
"rms_norm_eps": 1e-06,
|
| 20 |
+
"rope_theta": 5000000.0,
|
| 21 |
+
"sliding_window": 4096,
|
| 22 |
+
"tie_word_embeddings": false,
|
| 23 |
+
"torch_dtype": "bfloat16",
|
| 24 |
+
"transformers_version": "4.37.1",
|
| 25 |
+
"use_cache": false,
|
| 26 |
+
"use_sliding_window": false,
|
| 27 |
+
"vocab_size": 151936
|
| 28 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token_id": 151643,
|
| 3 |
+
"do_sample": true,
|
| 4 |
+
"eos_token_id": [
|
| 5 |
+
151645,
|
| 6 |
+
151643
|
| 7 |
+
],
|
| 8 |
+
"repetition_penalty": 1.1,
|
| 9 |
+
"top_p": 0.8,
|
| 10 |
+
"transformers_version": "4.37.1"
|
| 11 |
+
}
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model-00001-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9ae53486e8fbc5f07fc2e72d7d7a7eb67a6f4ee8829d4360499c67983f2d1a92
|
| 3 |
+
size 4989973456
|
model-00002-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1cc044d155f5463b44ccb33ed477b978f4067bdae0ac83e0af7b6ddf3b919e92
|
| 3 |
+
size 2910820520
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,490 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 7900738560
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"lm_head.weight": "model-00002-of-00002.safetensors",
|
| 7 |
+
"model.embed_tokens.weight": "model-00001-of-00002.safetensors",
|
| 8 |
+
"model.layers.0.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 9 |
+
"model.layers.0.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 10 |
+
"model.layers.0.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 11 |
+
"model.layers.0.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 12 |
+
"model.layers.0.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 13 |
+
"model.layers.0.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
|
| 14 |
+
"model.layers.0.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 15 |
+
"model.layers.0.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 16 |
+
"model.layers.0.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
|
| 17 |
+
"model.layers.0.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 18 |
+
"model.layers.0.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
|
| 19 |
+
"model.layers.0.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 20 |
+
"model.layers.1.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 21 |
+
"model.layers.1.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 22 |
+
"model.layers.1.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 23 |
+
"model.layers.1.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 24 |
+
"model.layers.1.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 25 |
+
"model.layers.1.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
|
| 26 |
+
"model.layers.1.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 27 |
+
"model.layers.1.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 28 |
+
"model.layers.1.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
|
| 29 |
+
"model.layers.1.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 30 |
+
"model.layers.1.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
|
| 31 |
+
"model.layers.1.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 32 |
+
"model.layers.10.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 33 |
+
"model.layers.10.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 34 |
+
"model.layers.10.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 35 |
+
"model.layers.10.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 36 |
+
"model.layers.10.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 37 |
+
"model.layers.10.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
|
| 38 |
+
"model.layers.10.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 39 |
+
"model.layers.10.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 40 |
+
"model.layers.10.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
|
| 41 |
+
"model.layers.10.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 42 |
+
"model.layers.10.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
|
| 43 |
+
"model.layers.10.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 44 |
+
"model.layers.11.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 45 |
+
"model.layers.11.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 46 |
+
"model.layers.11.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 47 |
+
"model.layers.11.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 48 |
+
"model.layers.11.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 49 |
+
"model.layers.11.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
|
| 50 |
+
"model.layers.11.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 51 |
+
"model.layers.11.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 52 |
+
"model.layers.11.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
|
| 53 |
+
"model.layers.11.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 54 |
+
"model.layers.11.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
|
| 55 |
+
"model.layers.11.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 56 |
+
"model.layers.12.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 57 |
+
"model.layers.12.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 58 |
+
"model.layers.12.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 59 |
+
"model.layers.12.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 60 |
+
"model.layers.12.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 61 |
+
"model.layers.12.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
|
| 62 |
+
"model.layers.12.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 63 |
+
"model.layers.12.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 64 |
+
"model.layers.12.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
|
| 65 |
+
"model.layers.12.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 66 |
+
"model.layers.12.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
|
| 67 |
+
"model.layers.12.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 68 |
+
"model.layers.13.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 69 |
+
"model.layers.13.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 70 |
+
"model.layers.13.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 71 |
+
"model.layers.13.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 72 |
+
"model.layers.13.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 73 |
+
"model.layers.13.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
|
| 74 |
+
"model.layers.13.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 75 |
+
"model.layers.13.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 76 |
+
"model.layers.13.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
|
| 77 |
+
"model.layers.13.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 78 |
+
"model.layers.13.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
|
| 79 |
+
"model.layers.13.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 80 |
+
"model.layers.14.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 81 |
+
"model.layers.14.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 82 |
+
"model.layers.14.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 83 |
+
"model.layers.14.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 84 |
+
"model.layers.14.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 85 |
+
"model.layers.14.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
|
| 86 |
+
"model.layers.14.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 87 |
+
"model.layers.14.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 88 |
+
"model.layers.14.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
|
| 89 |
+
"model.layers.14.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 90 |
+
"model.layers.14.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
|
| 91 |
+
"model.layers.14.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 92 |
+
"model.layers.15.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 93 |
+
"model.layers.15.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 94 |
+
"model.layers.15.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 95 |
+
"model.layers.15.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 96 |
+
"model.layers.15.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 97 |
+
"model.layers.15.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
|
| 98 |
+
"model.layers.15.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 99 |
+
"model.layers.15.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 100 |
+
"model.layers.15.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
|
| 101 |
+
"model.layers.15.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 102 |
+
"model.layers.15.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
|
| 103 |
+
"model.layers.15.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 104 |
+
"model.layers.16.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 105 |
+
"model.layers.16.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 106 |
+
"model.layers.16.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 107 |
+
"model.layers.16.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 108 |
+
"model.layers.16.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 109 |
+
"model.layers.16.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
|
| 110 |
+
"model.layers.16.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 111 |
+
"model.layers.16.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 112 |
+
"model.layers.16.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
|
| 113 |
+
"model.layers.16.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 114 |
+
"model.layers.16.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
|
| 115 |
+
"model.layers.16.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 116 |
+
"model.layers.17.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 117 |
+
"model.layers.17.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 118 |
+
"model.layers.17.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 119 |
+
"model.layers.17.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 120 |
+
"model.layers.17.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 121 |
+
"model.layers.17.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
|
| 122 |
+
"model.layers.17.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 123 |
+
"model.layers.17.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 124 |
+
"model.layers.17.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
|
| 125 |
+
"model.layers.17.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 126 |
+
"model.layers.17.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
|
| 127 |
+
"model.layers.17.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 128 |
+
"model.layers.18.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 129 |
+
"model.layers.18.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 130 |
+
"model.layers.18.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 131 |
+
"model.layers.18.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 132 |
+
"model.layers.18.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 133 |
+
"model.layers.18.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
|
| 134 |
+
"model.layers.18.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 135 |
+
"model.layers.18.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 136 |
+
"model.layers.18.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
|
| 137 |
+
"model.layers.18.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 138 |
+
"model.layers.18.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
|
| 139 |
+
"model.layers.18.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 140 |
+
"model.layers.19.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 141 |
+
"model.layers.19.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 142 |
+
"model.layers.19.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 143 |
+
"model.layers.19.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 144 |
+
"model.layers.19.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 145 |
+
"model.layers.19.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
|
| 146 |
+
"model.layers.19.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 147 |
+
"model.layers.19.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 148 |
+
"model.layers.19.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
|
| 149 |
+
"model.layers.19.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 150 |
+
"model.layers.19.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
|
| 151 |
+
"model.layers.19.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 152 |
+
"model.layers.2.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 153 |
+
"model.layers.2.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 154 |
+
"model.layers.2.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 155 |
+
"model.layers.2.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 156 |
+
"model.layers.2.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 157 |
+
"model.layers.2.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
|
| 158 |
+
"model.layers.2.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 159 |
+
"model.layers.2.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 160 |
+
"model.layers.2.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
|
| 161 |
+
"model.layers.2.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 162 |
+
"model.layers.2.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
|
| 163 |
+
"model.layers.2.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 164 |
+
"model.layers.20.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 165 |
+
"model.layers.20.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 166 |
+
"model.layers.20.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 167 |
+
"model.layers.20.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 168 |
+
"model.layers.20.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 169 |
+
"model.layers.20.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
|
| 170 |
+
"model.layers.20.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 171 |
+
"model.layers.20.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 172 |
+
"model.layers.20.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
|
| 173 |
+
"model.layers.20.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 174 |
+
"model.layers.20.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
|
| 175 |
+
"model.layers.20.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 176 |
+
"model.layers.21.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 177 |
+
"model.layers.21.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 178 |
+
"model.layers.21.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 179 |
+
"model.layers.21.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 180 |
+
"model.layers.21.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 181 |
+
"model.layers.21.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
|
| 182 |
+
"model.layers.21.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 183 |
+
"model.layers.21.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 184 |
+
"model.layers.21.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
|
| 185 |
+
"model.layers.21.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 186 |
+
"model.layers.21.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
|
| 187 |
+
"model.layers.21.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 188 |
+
"model.layers.22.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 189 |
+
"model.layers.22.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 190 |
+
"model.layers.22.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 191 |
+
"model.layers.22.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 192 |
+
"model.layers.22.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 193 |
+
"model.layers.22.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
|
| 194 |
+
"model.layers.22.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 195 |
+
"model.layers.22.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 196 |
+
"model.layers.22.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
|
| 197 |
+
"model.layers.22.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 198 |
+
"model.layers.22.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
|
| 199 |
+
"model.layers.22.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 200 |
+
"model.layers.23.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 201 |
+
"model.layers.23.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 202 |
+
"model.layers.23.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 203 |
+
"model.layers.23.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 204 |
+
"model.layers.23.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 205 |
+
"model.layers.23.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
|
| 206 |
+
"model.layers.23.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 207 |
+
"model.layers.23.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 208 |
+
"model.layers.23.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
|
| 209 |
+
"model.layers.23.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 210 |
+
"model.layers.23.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
|
| 211 |
+
"model.layers.23.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 212 |
+
"model.layers.24.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 213 |
+
"model.layers.24.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 214 |
+
"model.layers.24.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 215 |
+
"model.layers.24.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 216 |
+
"model.layers.24.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 217 |
+
"model.layers.24.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
|
| 218 |
+
"model.layers.24.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 219 |
+
"model.layers.24.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 220 |
+
"model.layers.24.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
|
| 221 |
+
"model.layers.24.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 222 |
+
"model.layers.24.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
|
| 223 |
+
"model.layers.24.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 224 |
+
"model.layers.25.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 225 |
+
"model.layers.25.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 226 |
+
"model.layers.25.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 227 |
+
"model.layers.25.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 228 |
+
"model.layers.25.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 229 |
+
"model.layers.25.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
|
| 230 |
+
"model.layers.25.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 231 |
+
"model.layers.25.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 232 |
+
"model.layers.25.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
|
| 233 |
+
"model.layers.25.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 234 |
+
"model.layers.25.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
|
| 235 |
+
"model.layers.25.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 236 |
+
"model.layers.26.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 237 |
+
"model.layers.26.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 238 |
+
"model.layers.26.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 239 |
+
"model.layers.26.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 240 |
+
"model.layers.26.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 241 |
+
"model.layers.26.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
|
| 242 |
+
"model.layers.26.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 243 |
+
"model.layers.26.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 244 |
+
"model.layers.26.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
|
| 245 |
+
"model.layers.26.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 246 |
+
"model.layers.26.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
|
| 247 |
+
"model.layers.26.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 248 |
+
"model.layers.27.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 249 |
+
"model.layers.27.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 250 |
+
"model.layers.27.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
| 251 |
+
"model.layers.27.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 252 |
+
"model.layers.27.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 253 |
+
"model.layers.27.self_attn.k_proj.bias": "model-00002-of-00002.safetensors",
|
| 254 |
+
"model.layers.27.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
| 255 |
+
"model.layers.27.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
| 256 |
+
"model.layers.27.self_attn.q_proj.bias": "model-00002-of-00002.safetensors",
|
| 257 |
+
"model.layers.27.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
| 258 |
+
"model.layers.27.self_attn.v_proj.bias": "model-00002-of-00002.safetensors",
|
| 259 |
+
"model.layers.27.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
| 260 |
+
"model.layers.28.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 261 |
+
"model.layers.28.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 262 |
+
"model.layers.28.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
| 263 |
+
"model.layers.28.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 264 |
+
"model.layers.28.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 265 |
+
"model.layers.28.self_attn.k_proj.bias": "model-00002-of-00002.safetensors",
|
| 266 |
+
"model.layers.28.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
| 267 |
+
"model.layers.28.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
| 268 |
+
"model.layers.28.self_attn.q_proj.bias": "model-00002-of-00002.safetensors",
|
| 269 |
+
"model.layers.28.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
| 270 |
+
"model.layers.28.self_attn.v_proj.bias": "model-00002-of-00002.safetensors",
|
| 271 |
+
"model.layers.28.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
| 272 |
+
"model.layers.29.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 273 |
+
"model.layers.29.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 274 |
+
"model.layers.29.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
| 275 |
+
"model.layers.29.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 276 |
+
"model.layers.29.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 277 |
+
"model.layers.29.self_attn.k_proj.bias": "model-00002-of-00002.safetensors",
|
| 278 |
+
"model.layers.29.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
| 279 |
+
"model.layers.29.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
| 280 |
+
"model.layers.29.self_attn.q_proj.bias": "model-00002-of-00002.safetensors",
|
| 281 |
+
"model.layers.29.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
| 282 |
+
"model.layers.29.self_attn.v_proj.bias": "model-00002-of-00002.safetensors",
|
| 283 |
+
"model.layers.29.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
| 284 |
+
"model.layers.3.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 285 |
+
"model.layers.3.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 286 |
+
"model.layers.3.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 287 |
+
"model.layers.3.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 288 |
+
"model.layers.3.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 289 |
+
"model.layers.3.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
|
| 290 |
+
"model.layers.3.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 291 |
+
"model.layers.3.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 292 |
+
"model.layers.3.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
|
| 293 |
+
"model.layers.3.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 294 |
+
"model.layers.3.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
|
| 295 |
+
"model.layers.3.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 296 |
+
"model.layers.30.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 297 |
+
"model.layers.30.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 298 |
+
"model.layers.30.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
| 299 |
+
"model.layers.30.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 300 |
+
"model.layers.30.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 301 |
+
"model.layers.30.self_attn.k_proj.bias": "model-00002-of-00002.safetensors",
|
| 302 |
+
"model.layers.30.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
| 303 |
+
"model.layers.30.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
| 304 |
+
"model.layers.30.self_attn.q_proj.bias": "model-00002-of-00002.safetensors",
|
| 305 |
+
"model.layers.30.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
| 306 |
+
"model.layers.30.self_attn.v_proj.bias": "model-00002-of-00002.safetensors",
|
| 307 |
+
"model.layers.30.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
| 308 |
+
"model.layers.31.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 309 |
+
"model.layers.31.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 310 |
+
"model.layers.31.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
| 311 |
+
"model.layers.31.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 312 |
+
"model.layers.31.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 313 |
+
"model.layers.31.self_attn.k_proj.bias": "model-00002-of-00002.safetensors",
|
| 314 |
+
"model.layers.31.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
| 315 |
+
"model.layers.31.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
| 316 |
+
"model.layers.31.self_attn.q_proj.bias": "model-00002-of-00002.safetensors",
|
| 317 |
+
"model.layers.31.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
| 318 |
+
"model.layers.31.self_attn.v_proj.bias": "model-00002-of-00002.safetensors",
|
| 319 |
+
"model.layers.31.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
| 320 |
+
"model.layers.32.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 321 |
+
"model.layers.32.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 322 |
+
"model.layers.32.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
| 323 |
+
"model.layers.32.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 324 |
+
"model.layers.32.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 325 |
+
"model.layers.32.self_attn.k_proj.bias": "model-00002-of-00002.safetensors",
|
| 326 |
+
"model.layers.32.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
| 327 |
+
"model.layers.32.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
| 328 |
+
"model.layers.32.self_attn.q_proj.bias": "model-00002-of-00002.safetensors",
|
| 329 |
+
"model.layers.32.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
| 330 |
+
"model.layers.32.self_attn.v_proj.bias": "model-00002-of-00002.safetensors",
|
| 331 |
+
"model.layers.32.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
| 332 |
+
"model.layers.33.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 333 |
+
"model.layers.33.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 334 |
+
"model.layers.33.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
| 335 |
+
"model.layers.33.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 336 |
+
"model.layers.33.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 337 |
+
"model.layers.33.self_attn.k_proj.bias": "model-00002-of-00002.safetensors",
|
| 338 |
+
"model.layers.33.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
| 339 |
+
"model.layers.33.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
| 340 |
+
"model.layers.33.self_attn.q_proj.bias": "model-00002-of-00002.safetensors",
|
| 341 |
+
"model.layers.33.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
| 342 |
+
"model.layers.33.self_attn.v_proj.bias": "model-00002-of-00002.safetensors",
|
| 343 |
+
"model.layers.33.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
| 344 |
+
"model.layers.34.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 345 |
+
"model.layers.34.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 346 |
+
"model.layers.34.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
| 347 |
+
"model.layers.34.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 348 |
+
"model.layers.34.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 349 |
+
"model.layers.34.self_attn.k_proj.bias": "model-00002-of-00002.safetensors",
|
| 350 |
+
"model.layers.34.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
| 351 |
+
"model.layers.34.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
| 352 |
+
"model.layers.34.self_attn.q_proj.bias": "model-00002-of-00002.safetensors",
|
| 353 |
+
"model.layers.34.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
| 354 |
+
"model.layers.34.self_attn.v_proj.bias": "model-00002-of-00002.safetensors",
|
| 355 |
+
"model.layers.34.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
| 356 |
+
"model.layers.35.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 357 |
+
"model.layers.35.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 358 |
+
"model.layers.35.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
| 359 |
+
"model.layers.35.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 360 |
+
"model.layers.35.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 361 |
+
"model.layers.35.self_attn.k_proj.bias": "model-00002-of-00002.safetensors",
|
| 362 |
+
"model.layers.35.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
| 363 |
+
"model.layers.35.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
| 364 |
+
"model.layers.35.self_attn.q_proj.bias": "model-00002-of-00002.safetensors",
|
| 365 |
+
"model.layers.35.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
| 366 |
+
"model.layers.35.self_attn.v_proj.bias": "model-00002-of-00002.safetensors",
|
| 367 |
+
"model.layers.35.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
| 368 |
+
"model.layers.36.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 369 |
+
"model.layers.36.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 370 |
+
"model.layers.36.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
| 371 |
+
"model.layers.36.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 372 |
+
"model.layers.36.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 373 |
+
"model.layers.36.self_attn.k_proj.bias": "model-00002-of-00002.safetensors",
|
| 374 |
+
"model.layers.36.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
| 375 |
+
"model.layers.36.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
| 376 |
+
"model.layers.36.self_attn.q_proj.bias": "model-00002-of-00002.safetensors",
|
| 377 |
+
"model.layers.36.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
| 378 |
+
"model.layers.36.self_attn.v_proj.bias": "model-00002-of-00002.safetensors",
|
| 379 |
+
"model.layers.36.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
| 380 |
+
"model.layers.37.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 381 |
+
"model.layers.37.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 382 |
+
"model.layers.37.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
| 383 |
+
"model.layers.37.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 384 |
+
"model.layers.37.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 385 |
+
"model.layers.37.self_attn.k_proj.bias": "model-00002-of-00002.safetensors",
|
| 386 |
+
"model.layers.37.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
| 387 |
+
"model.layers.37.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
| 388 |
+
"model.layers.37.self_attn.q_proj.bias": "model-00002-of-00002.safetensors",
|
| 389 |
+
"model.layers.37.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
| 390 |
+
"model.layers.37.self_attn.v_proj.bias": "model-00002-of-00002.safetensors",
|
| 391 |
+
"model.layers.37.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
| 392 |
+
"model.layers.38.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 393 |
+
"model.layers.38.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 394 |
+
"model.layers.38.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
| 395 |
+
"model.layers.38.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 396 |
+
"model.layers.38.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 397 |
+
"model.layers.38.self_attn.k_proj.bias": "model-00002-of-00002.safetensors",
|
| 398 |
+
"model.layers.38.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
| 399 |
+
"model.layers.38.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
| 400 |
+
"model.layers.38.self_attn.q_proj.bias": "model-00002-of-00002.safetensors",
|
| 401 |
+
"model.layers.38.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
| 402 |
+
"model.layers.38.self_attn.v_proj.bias": "model-00002-of-00002.safetensors",
|
| 403 |
+
"model.layers.38.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
| 404 |
+
"model.layers.39.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 405 |
+
"model.layers.39.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 406 |
+
"model.layers.39.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
| 407 |
+
"model.layers.39.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 408 |
+
"model.layers.39.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 409 |
+
"model.layers.39.self_attn.k_proj.bias": "model-00002-of-00002.safetensors",
|
| 410 |
+
"model.layers.39.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
| 411 |
+
"model.layers.39.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
| 412 |
+
"model.layers.39.self_attn.q_proj.bias": "model-00002-of-00002.safetensors",
|
| 413 |
+
"model.layers.39.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
| 414 |
+
"model.layers.39.self_attn.v_proj.bias": "model-00002-of-00002.safetensors",
|
| 415 |
+
"model.layers.39.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
| 416 |
+
"model.layers.4.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 417 |
+
"model.layers.4.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 418 |
+
"model.layers.4.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 419 |
+
"model.layers.4.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 420 |
+
"model.layers.4.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 421 |
+
"model.layers.4.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
|
| 422 |
+
"model.layers.4.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 423 |
+
"model.layers.4.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 424 |
+
"model.layers.4.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
|
| 425 |
+
"model.layers.4.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 426 |
+
"model.layers.4.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
|
| 427 |
+
"model.layers.4.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 428 |
+
"model.layers.5.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 429 |
+
"model.layers.5.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 430 |
+
"model.layers.5.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 431 |
+
"model.layers.5.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 432 |
+
"model.layers.5.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 433 |
+
"model.layers.5.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
|
| 434 |
+
"model.layers.5.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 435 |
+
"model.layers.5.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 436 |
+
"model.layers.5.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
|
| 437 |
+
"model.layers.5.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 438 |
+
"model.layers.5.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
|
| 439 |
+
"model.layers.5.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 440 |
+
"model.layers.6.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 441 |
+
"model.layers.6.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 442 |
+
"model.layers.6.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 443 |
+
"model.layers.6.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 444 |
+
"model.layers.6.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 445 |
+
"model.layers.6.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
|
| 446 |
+
"model.layers.6.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 447 |
+
"model.layers.6.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 448 |
+
"model.layers.6.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
|
| 449 |
+
"model.layers.6.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 450 |
+
"model.layers.6.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
|
| 451 |
+
"model.layers.6.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 452 |
+
"model.layers.7.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 453 |
+
"model.layers.7.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 454 |
+
"model.layers.7.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 455 |
+
"model.layers.7.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 456 |
+
"model.layers.7.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 457 |
+
"model.layers.7.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
|
| 458 |
+
"model.layers.7.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 459 |
+
"model.layers.7.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 460 |
+
"model.layers.7.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
|
| 461 |
+
"model.layers.7.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 462 |
+
"model.layers.7.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
|
| 463 |
+
"model.layers.7.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 464 |
+
"model.layers.8.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 465 |
+
"model.layers.8.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 466 |
+
"model.layers.8.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 467 |
+
"model.layers.8.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 468 |
+
"model.layers.8.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 469 |
+
"model.layers.8.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
|
| 470 |
+
"model.layers.8.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 471 |
+
"model.layers.8.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 472 |
+
"model.layers.8.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
|
| 473 |
+
"model.layers.8.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 474 |
+
"model.layers.8.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
|
| 475 |
+
"model.layers.8.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 476 |
+
"model.layers.9.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 477 |
+
"model.layers.9.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 478 |
+
"model.layers.9.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 479 |
+
"model.layers.9.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 480 |
+
"model.layers.9.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 481 |
+
"model.layers.9.self_attn.k_proj.bias": "model-00001-of-00002.safetensors",
|
| 482 |
+
"model.layers.9.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
| 483 |
+
"model.layers.9.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
| 484 |
+
"model.layers.9.self_attn.q_proj.bias": "model-00001-of-00002.safetensors",
|
| 485 |
+
"model.layers.9.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
| 486 |
+
"model.layers.9.self_attn.v_proj.bias": "model-00001-of-00002.safetensors",
|
| 487 |
+
"model.layers.9.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
| 488 |
+
"model.norm.weight": "model-00002-of-00002.safetensors"
|
| 489 |
+
}
|
| 490 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"added_tokens_decoder": {
|
| 4 |
+
"151643": {
|
| 5 |
+
"content": "<|endoftext|>",
|
| 6 |
+
"lstrip": false,
|
| 7 |
+
"normalized": false,
|
| 8 |
+
"rstrip": false,
|
| 9 |
+
"single_word": false,
|
| 10 |
+
"special": true
|
| 11 |
+
},
|
| 12 |
+
"151644": {
|
| 13 |
+
"content": "<|im_start|>",
|
| 14 |
+
"lstrip": false,
|
| 15 |
+
"normalized": false,
|
| 16 |
+
"rstrip": false,
|
| 17 |
+
"single_word": false,
|
| 18 |
+
"special": true
|
| 19 |
+
},
|
| 20 |
+
"151645": {
|
| 21 |
+
"content": "<|im_end|>",
|
| 22 |
+
"lstrip": false,
|
| 23 |
+
"normalized": false,
|
| 24 |
+
"rstrip": false,
|
| 25 |
+
"single_word": false,
|
| 26 |
+
"special": true
|
| 27 |
+
}
|
| 28 |
+
},
|
| 29 |
+
"additional_special_tokens": [
|
| 30 |
+
"<|im_start|>",
|
| 31 |
+
"<|im_end|>"
|
| 32 |
+
],
|
| 33 |
+
"bos_token": null,
|
| 34 |
+
"chat_template": "{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}",
|
| 35 |
+
"clean_up_tokenization_spaces": false,
|
| 36 |
+
"eos_token": "<|im_end|>",
|
| 37 |
+
"errors": "replace",
|
| 38 |
+
"model_max_length": 32768,
|
| 39 |
+
"pad_token": "<|endoftext|>",
|
| 40 |
+
"padding_side": "right",
|
| 41 |
+
"split_special_tokens": false,
|
| 42 |
+
"tokenizer_class": "Qwen2Tokenizer",
|
| 43 |
+
"unk_token": null
|
| 44 |
+
}
|
vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|