Model description | Example output | Banchmark results | How to use | Training and finetuning
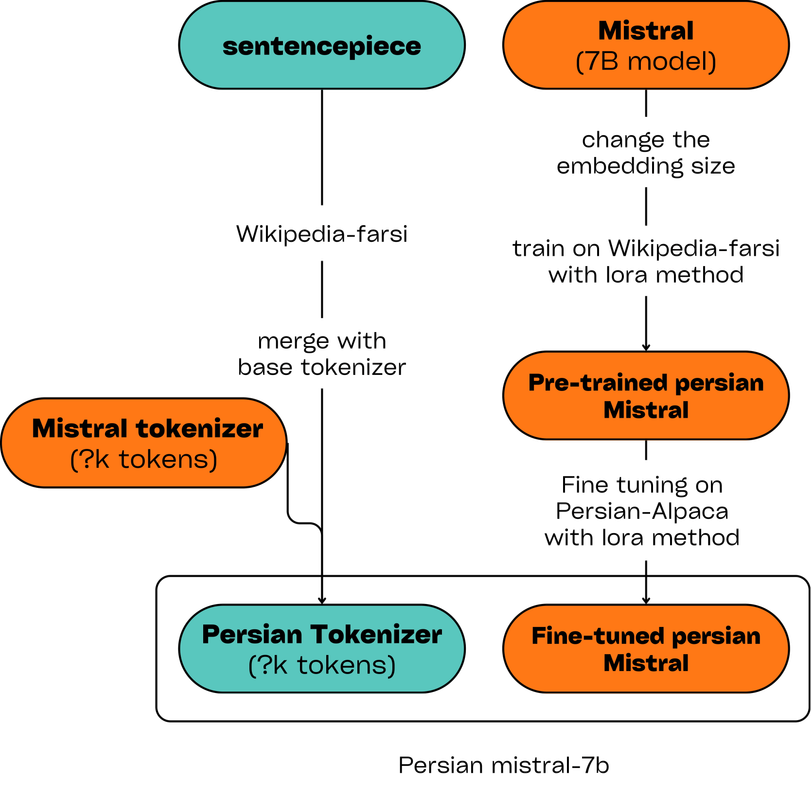
---- # Model description >Jamba is a state-of-the-art, hybrid SSM-Transformer LLM. It delivers throughput gains over traditional Transformer-based models, while outperforming or matching the leading models of its size class on most common benchmarks.Jamba is the first production-scale Mamba implementation, which opens up interesting research and application opportunities. While this initial experimentation shows encouraging gains, we expect these to be further enhanced with future optimizations and explorations.This model card is for the base version of Jamba. It’s a pretrained, mixture-of-experts (MoE) generative text model, with 12B active parameters and a total of 52B parameters across all experts. It supports a 256K context length, and can fit up to 140K tokens on a single 80GB GPU. ---- # Example output: **Example 1:** - Input: "سلام، خوبی؟" - Output: "سلام، خوشحالم که با شما صحبت می کنم. چطور می توانم به شما کمک کنم؟" **Example 2:** - Input: "سلام، خوبی؟" - Output: "سلام، خوشحالم که با شما صحبت می کنم. چطور می توانم به شما کمک کنم؟" ---- # Banchmark results | model | dataset | score | |---------------|-------------------|--------| | base-model-7b | ARC-easy |41.92% | | base-model-7b | ARC-easy |39.12% | | fa-model-7b | ARC-easy |37.89% | | base-model-7b | ARC-challenge |37.12% | | fa-model-7b | ARC-challenge |39.29% | ---- # How to use ```python from transformers import AutoTokenizer, AutoModelForCausalLM tokenizer = AutoTokenizer.from_pretrained("aidal/Persian-Mistral-7B") model = AutoModelForCausalLM.from_pretrained("aidal/Persian-Mistral-7B") input_text = "پایتخت ایران کجاست؟" input_ids = tokenizer(input_text, return_tensors="pt") outputs = model.generate(**input_ids) print(tokenizer.decode(outputs[0])) ``` ---- # Training and finetuning - **Extend tokenzer:** The base Mistral tokenizer does not support Persian. As an initial step, we trained a SentencePiece tokenizer on the Farsi Wikipedia corpus and subsequently integrated it with the Mistral tokenizer. - **Pre-training:** In the following step, we expanded the embedding layer of the base model to match the size of the Persian tokenizer. We then employed the LoRA method to train the model on three distinct datasets: Wikipedia-Farsi, an Islamic book collection, and content from Khamenei.ir. - **Instruction Fine-tuning:** For the final step, we fine-tuned the model using the LoRA method on a translated version of the Stanford-alpaca to enhance the model's question-answering capabilities. - This diagram illustrates the steps described above: -