
| # 📷 EasyAnimate | An End-to-End Solution for High-Resolution and Long Video Generation | |
| 😊 EasyAnimate is an end-to-end solution for generating high-resolution and long videos. We can train transformer based diffusion generators, train VAEs for processing long videos, and preprocess metadata. | |
| 😊 We use DIT and transformer as a diffuser for video and image generation. | |
| 😊 Welcome! | |
| [](https://arxiv.org/abs/2405.18991) | |
| [](https://easyanimate.github.io/) | |
| [](https://modelscope.cn/studios/PAI/EasyAnimate/summary) | |
| [](https://huggingface.co/spaces/alibaba-pai/EasyAnimate) | |
| [](https://discord.gg/UzkpB4Bn) | |
| English | [简体中文](./README_zh-CN.md) | |
| # Table of Contents | |
| - [Table of Contents](#table-of-contents) | |
| - [Introduction](#introduction) | |
| - [Quick Start](#quick-start) | |
| - [Video Result](#video-result) | |
| - [How to use](#how-to-use) | |
| - [Model zoo](#model-zoo) | |
| - [TODO List](#todo-list) | |
| - [Contact Us](#contact-us) | |
| - [Reference](#reference) | |
| - [License](#license) | |
| # Introduction | |
| EasyAnimate is a pipeline based on the transformer architecture, designed for generating AI images and videos, and for training baseline models and Lora models for Diffusion Transformer. We support direct prediction from pre-trained EasyAnimate models, allowing for the generation of videos with various resolutions, approximately 6 seconds in length, at 8fps (EasyAnimateV5, 1 to 49 frames). Additionally, users can train their own baseline and Lora models for specific style transformations. | |
| We will support quick pull-ups from different platforms, refer to [Quick Start](#quick-start). | |
| **New Features:** | |
| - **Updated to v5**, supporting video generation up to 1024x1024, 49 frames, 6s, 8fps, with expanded model scale to 12B, incorporating the MMDIT structure, and enabling control models with diverse inputs; supports bilingual predictions in Chinese and English. [2024.11.08] | |
| - **Updated to v4**, allowing for video generation up to 1024x1024, 144 frames, 6s, 24fps; supports video generation from text, image, and video, with a single model handling resolutions from 512 to 1280; bilingual predictions in Chinese and English enabled. [2024.08.15] | |
| - **Updated to v3**, supporting video generation up to 960x960, 144 frames, 6s, 24fps, from text and image. [2024.07.01] | |
| - **ModelScope-Sora “Data Director” Creative Race** — The third Data-Juicer Big Model Data Challenge is now officially launched! Utilizing EasyAnimate as the base model, it explores the impact of data processing on model training. Visit the [competition website](https://tianchi.aliyun.com/competition/entrance/532219) for details. [2024.06.17] | |
| - **Updated to v2**, supporting video generation up to 768x768, 144 frames, 6s, 24fps. [2024.05.26] | |
| - **Code Created!** Now supporting Windows and Linux. [2024.04.12] | |
| Function: | |
| - [Data Preprocessing](#data-preprocess) | |
| - [Train VAE](#vae-train) | |
| - [Train DiT](#dit-train) | |
| - [Video Generation](#video-gen) | |
| Our UI interface is as follows: | |
| 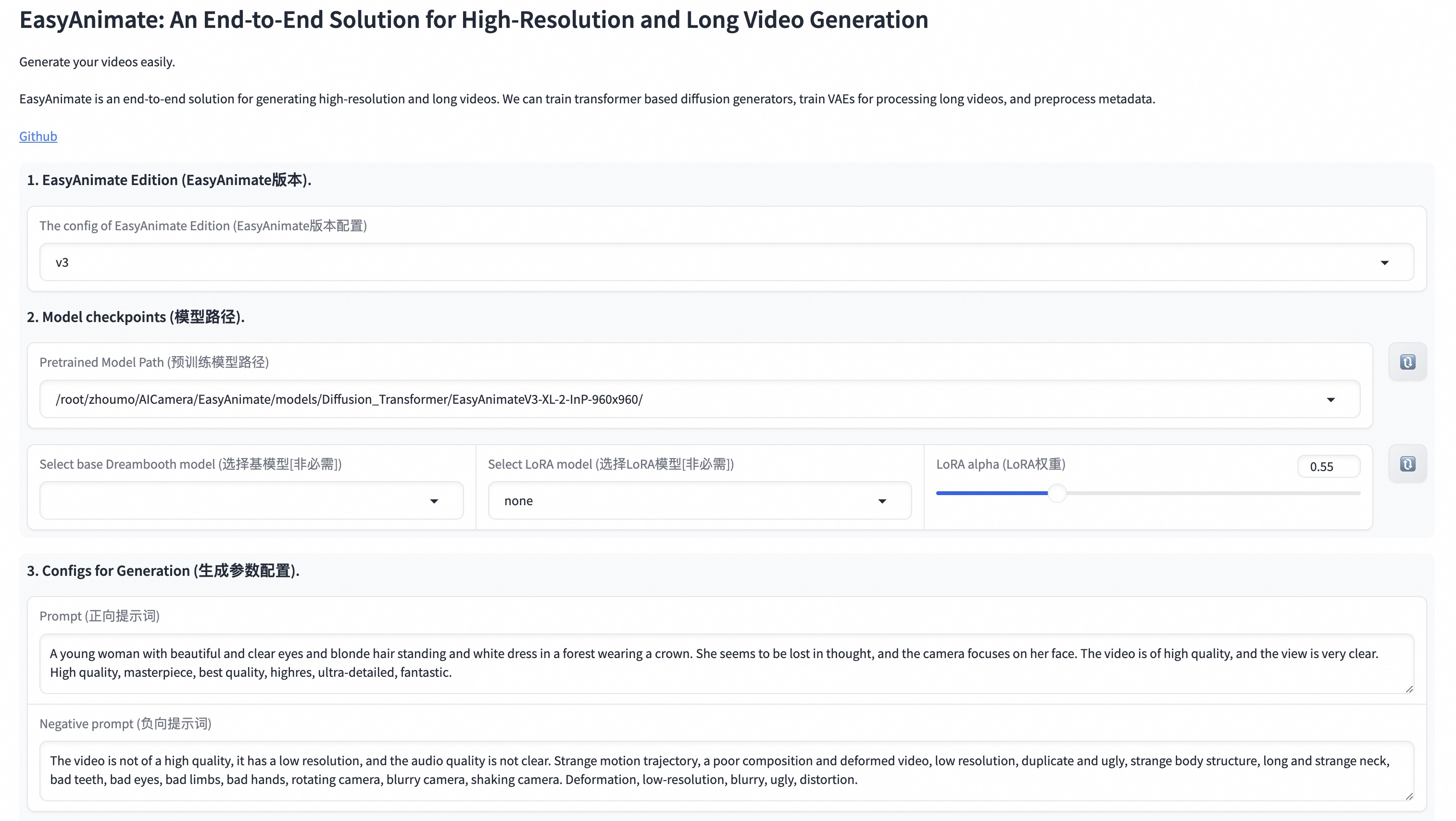 | |
| # Quick Start | |
| ### 1. Cloud usage: AliyunDSW/Docker | |
| #### a. From AliyunDSW | |
| DSW has free GPU time, which can be applied once by a user and is valid for 3 months after applying. | |
| Aliyun provide free GPU time in [Freetier](https://free.aliyun.com/?product=9602825&crowd=enterprise&spm=5176.28055625.J_5831864660.1.e939154aRgha4e&scm=20140722.M_9974135.P_110.MO_1806-ID_9974135-MID_9974135-CID_30683-ST_8512-V_1), get it and use in Aliyun PAI-DSW to start EasyAnimate within 5min! | |
| [](https://gallery.pai-ml.com/#/preview/deepLearning/cv/easyanimate) | |
| #### b. From ComfyUI | |
| Our ComfyUI is as follows, please refer to [ComfyUI README](comfyui/README.md) for details. | |
| 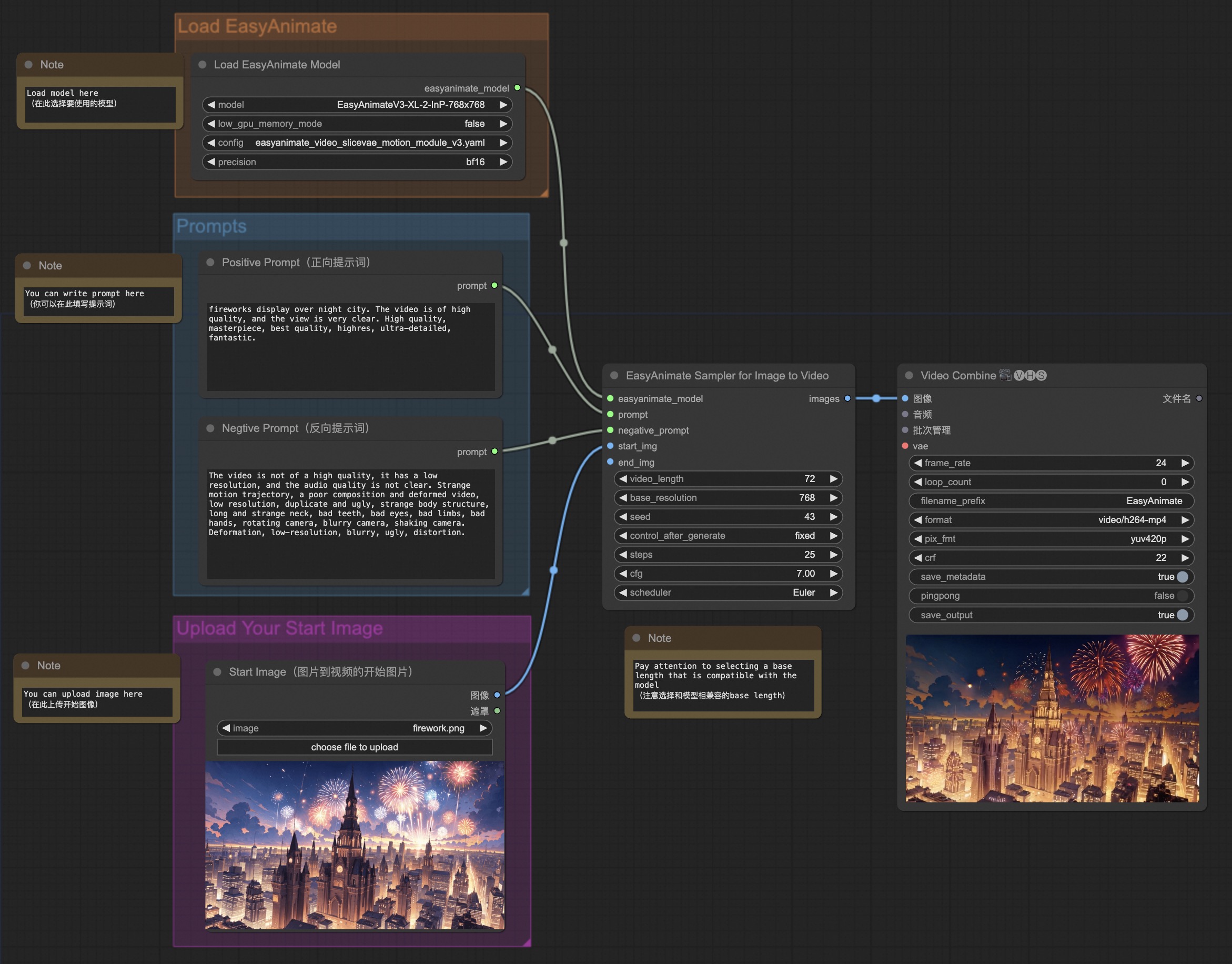 | |
| #### c. From docker | |
| If you are using docker, please make sure that the graphics card driver and CUDA environment have been installed correctly in your machine. | |
| Then execute the following commands in this way: | |
| ``` | |
| # pull image | |
| docker pull mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate | |
| # enter image | |
| docker run -it -p 7860:7860 --network host --gpus all --security-opt seccomp:unconfined --shm-size 200g mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate | |
| # clone code | |
| git clone https://github.com/aigc-apps/EasyAnimate.git | |
| # enter EasyAnimate's dir | |
| cd EasyAnimate | |
| # download weights | |
| mkdir models/Diffusion_Transformer | |
| mkdir models/Motion_Module | |
| mkdir models/Personalized_Model | |
| # Please use the hugginface link or modelscope link to download the EasyAnimateV5 model. | |
| # I2V models | |
| # https://huggingface.co/alibaba-pai/EasyAnimateV5-12b-zh-InP | |
| # https://modelscope.cn/models/PAI/EasyAnimateV5-12b-zh-InP | |
| # T2V models | |
| # https://huggingface.co/alibaba-pai/EasyAnimateV5-12b-zh | |
| # https://modelscope.cn/models/PAI/EasyAnimateV5-12b-zh | |
| ``` | |
| ### 2. Local install: Environment Check/Downloading/Installation | |
| #### a. Environment Check | |
| We have verified EasyAnimate execution on the following environment: | |
| The detailed of Windows: | |
| - OS: Windows 10 | |
| - python: python3.10 & python3.11 | |
| - pytorch: torch2.2.0 | |
| - CUDA: 11.8 & 12.1 | |
| - CUDNN: 8+ | |
| - GPU: Nvidia-3060 12G | |
| The detailed of Linux: | |
| - OS: Ubuntu 20.04, CentOS | |
| - python: python3.10 & python3.11 | |
| - pytorch: torch2.2.0 | |
| - CUDA: 11.8 & 12.1 | |
| - CUDNN: 8+ | |
| - GPU:Nvidia-V100 16G & Nvidia-A10 24G & Nvidia-A100 40G & Nvidia-A100 80G | |
| We need about 60GB available on disk (for saving weights), please check! | |
| The video size for EasyAnimateV5-12B can be generated by different GPU Memory, including: | |
| | GPU memory | 384x672x72 | 384x672x49 | 576x1008x25 | 576x1008x49 | 768x1344x25 | 768x1344x49 | | |
| |------------|------------|------------|------------|------------|------------|------------| | |
| | 16GB | 🧡 | 🧡 | ❌ | ❌ | ❌ | ❌ | | |
| | 24GB | 🧡 | 🧡 | 🧡 | 🧡 | ❌ | ❌ | | |
| | 40GB | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | | |
| | 80GB | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | | |
| ✅ indicates it can run under "model_cpu_offload", 🧡 represents it can run under "model_cpu_offload_and_qfloat8", ⭕️ indicates it can run under "sequential_cpu_offload", ❌ means it can't run. Please note that running with sequential_cpu_offload will be slower. | |
| Some GPUs that do not support torch.bfloat16, such as 2080ti and V100, require changing the weight_dtype in app.py and predict files to torch.float16 in order to run. | |
| The generation time for EasyAnimateV5-12B using different GPUs over 25 steps is as follows: | |
| | GPU | 384x672x72 | 384x672x49 | 576x1008x25 | 576x1008x49 | 768x1344x25 | 768x1344x49 | | |
| |-----------|------------------|------------------|------------------|------------------|------------------|-----------------| | |
| | A10 24GB | ~120s (4.8s/it) | ~240s (9.6s/it) | ~320s (12.7s/it) | ~750s (29.8s/it) | ❌ | ❌ | | |
| | A100 80GB | ~45s (1.75s/it) | ~90s (3.7s/it) | ~120s (4.7s/it) | ~300s (11.4s/it) | ~265s (10.6s/it) | ~710s (28.3s/it) | | |
| (⭕️) indicates it can run with low_gpu_memory_mode=True, but at a slower speed, and ❌ means it can't run. | |
| <details> | |
| <summary>(Obsolete) EasyAnimateV3:</summary> | |
| The video size for EasyAnimateV3 can be generated by different GPU Memory, including: | |
| | GPU memory | 384x672x72 | 384x672x144 | 576x1008x72 | 576x1008x144 | 720x1280x72 | 720x1280x144 | | |
| |------------|------------|-------------|-------------|--------------|-------------|--------------| | |
| | 12GB | ⭕️ | ⭕️ | ⭕️ | ⭕️ | ❌ | ❌ | | |
| | 16GB | ✅ | ✅ | ⭕️ | ⭕️ | ⭕️ | ❌ | | |
| | 24GB | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | | |
| | 40GB | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | | |
| | 80GB | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | | |
| </details> | |
| #### b. Weights | |
| We'd better place the [weights](#model-zoo) along the specified path: | |
| EasyAnimateV5: | |
| ``` | |
| 📦 models/ | |
| ├── 📂 Diffusion_Transformer/ | |
| │ ├── 📂 EasyAnimateV5-12b-zh-InP/ | |
| │ └── 📂 EasyAnimateV5-12b-zh/ | |
| ├── 📂 Personalized_Model/ | |
| │ └── your trained trainformer model / your trained lora model (for UI load) | |
| ``` | |
| # 视频作品 | |
| The results displayed are all based on image. | |
| ### EasyAnimateV5-12b-zh-InP | |
| #### I2V | |
| <table border="0" style="width: 100%; text-align: left; margin-top: 20px;"> | |
| <tr> | |
| <td> | |
| <video src="https://github.com/user-attachments/assets/bb393b7c-ba33-494c-ab06-b314adea9fc1" width="100%" controls autoplay loop></video> | |
| </td> | |
| <td> | |
| <video src="https://github.com/user-attachments/assets/cb0d0253-919d-4dd6-9dc1-5cd94443c7f1" width="100%" controls autoplay loop></video> | |
| </td> | |
| <td> | |
| <video src="https://github.com/user-attachments/assets/09ed361f-c0c5-4025-aad7-71fe1a1a52b1" width="100%" controls autoplay loop></video> | |
| </td> | |
| <td> | |
| <video src="https://github.com/user-attachments/assets/9f42848d-34eb-473f-97ea-a5ebd0268106" width="100%" controls autoplay loop></video> | |
| </td> | |
| </tr> | |
| </table> | |
| <table border="0" style="width: 100%; text-align: left; margin-top: 20px;"> | |
| <tr> | |
| <td> | |
| <video src="https://github.com/user-attachments/assets/903fda91-a0bd-48ee-bf64-fff4e4d96f17" width="100%" controls autoplay loop></video> | |
| </td> | |
| <td> | |
| <video src="https://github.com/user-attachments/assets/407c6628-9688-44b6-b12d-77de10fbbe95" width="100%" controls autoplay loop></video> | |
| </td> | |
| <td> | |
| <video src="https://github.com/user-attachments/assets/ccf30ec1-91d2-4d82-9ce0-fcc585fc2f21" width="100%" controls autoplay loop></video> | |
| </td> | |
| <td> | |
| <video src="https://github.com/user-attachments/assets/5dfe0f92-7d0d-43e0-b7df-0ff7b325663c" width="100%" controls autoplay loop></video> | |
| </td> | |
| </tr> | |
| </table> | |
| <table border="0" style="width: 100%; text-align: left; margin-top: 20px;"> | |
| <tr> | |
| <td> | |
| <video src="https://github.com/user-attachments/assets/2b542b85-be19-4537-9607-9d28ea7e932e" width="100%" controls autoplay loop></video> | |
| </td> | |
| <td> | |
| <video src="https://github.com/user-attachments/assets/c1662745-752d-4ad2-92bc-fe53734347b2" width="100%" controls autoplay loop></video> | |
| </td> | |
| <td> | |
| <video src="https://github.com/user-attachments/assets/8bec3d66-50a3-4af5-a381-be2c865825a0" width="100%" controls autoplay loop></video> | |
| </td> | |
| <td> | |
| <video src="https://github.com/user-attachments/assets/bcec22f4-732c-446f-958c-2ebbfd8f94be" width="100%" controls autoplay loop></video> | |
| </td> | |
| </tr> | |
| </table> | |
| #### T2V | |
| <table border="0" style="width: 100%; text-align: left; margin-top: 20px;"> | |
| <tr> | |
| <td> | |
| <video src="https://github.com/user-attachments/assets/eccb0797-4feb-48e9-91d3-5769ce30142b" width="100%" controls autoplay loop></video> | |
| </td> | |
| <td> | |
| <video src="https://github.com/user-attachments/assets/76b3db64-9c7a-4d38-8854-dba940240ceb" width="100%" controls autoplay loop></video> | |
| </td> | |
| <td> | |
| <video src="https://github.com/user-attachments/assets/0b8fab66-8de7-44ff-bd43-8f701bad6bb7" width="100%" controls autoplay loop></video> | |
| </td> | |
| <td> | |
| <video src="https://github.com/user-attachments/assets/9fbddf5f-7fcd-4cc6-9d7c-3bdf1d4ce59e" width="100%" controls autoplay loop></video> | |
| </td> | |
| </tr> | |
| </table> | |
| <table border="0" style="width: 100%; text-align: left; margin-top: 20px;"> | |
| <tr> | |
| <td> | |
| <video src="https://github.com/user-attachments/assets/19c1742b-e417-45ac-97d6-8bf3a80d8e13" width="100%" controls autoplay loop></video> | |
| </td> | |
| <td> | |
| <video src="https://github.com/user-attachments/assets/641e56c8-a3d9-489d-a3a6-42c50a9aeca1" width="100%" controls autoplay loop></video> | |
| </td> | |
| <td> | |
| <video src="https://github.com/user-attachments/assets/2b16be76-518b-44c6-a69b-5c49d76df365" width="100%" controls autoplay loop></video> | |
| </td> | |
| <td> | |
| <video src="https://github.com/user-attachments/assets/e7d9c0fc-136f-405c-9fab-629389e196be" width="100%" controls autoplay loop></video> | |
| </td> | |
| </tr> | |
| </table> | |
| ### EasyAnimateV5-12b-zh-Control | |
| <table border="0" style="width: 100%; text-align: left; margin-top: 20px;"> | |
| <tr> | |
| <td> | |
| <video src="https://github.com/user-attachments/assets/53002ce2-dd18-4d4f-8135-b6f68364cabd" width="100%" controls autoplay loop></video> | |
| </td> | |
| <td> | |
| <video src="https://github.com/user-attachments/assets/fce43c0b-81fa-4ab2-9ca7-78d786f520e6" width="100%" controls autoplay loop></video> | |
| </td> | |
| <td> | |
| <video src="https://github.com/user-attachments/assets/b208b92c-5add-4ece-a200-3dbbe47b93c3" width="100%" controls autoplay loop></video> | |
| </td> | |
| <tr> | |
| <td> | |
| <video src="https://github.com/user-attachments/assets/3aec95d5-d240-49fb-a9e9-914446c7a4cf" width="100%" controls autoplay loop></video> | |
| </td> | |
| <td> | |
| <video src="https://github.com/user-attachments/assets/60fa063b-5c1f-485f-b663-09bd6669de3f" width="100%" controls autoplay loop></video> | |
| </td> | |
| <td> | |
| <video src="https://github.com/user-attachments/assets/4adde728-8397-42f3-8a2a-23f7b39e9a1e" width="100%" controls autoplay loop></video> | |
| </td> | |
| </tr> | |
| </table> | |
| # How to use | |
| <h3 id="video-gen">1. Inference </h3> | |
| #### a. Using Python Code | |
| - Step 1: Download the corresponding [weights](#model-zoo) and place them in the models folder. | |
| - Step 2: Modify prompt, neg_prompt, guidance_scale, and seed in the predict_t2v.py file. | |
| - Step 3: Run the predict_t2v.py file, wait for the generated results, and save the results in the samples/easyanimate-videos folder. | |
| - Step 4: If you want to combine other backbones you have trained with Lora, modify the predict_t2v.py and Lora_path in predict_t2v.py depending on the situation. | |
| #### b. Using webui | |
| - Step 1: Download the corresponding [weights](#model-zoo) and place them in the models folder. | |
| - Step 2: Run the app.py file to enter the graph page. | |
| - Step 3: Select the generated model based on the page, fill in prompt, neg_prompt, guidance_scale, and seed, click on generate, wait for the generated result, and save the result in the samples folder. | |
| #### c. From ComfyUI | |
| Please refer to [ComfyUI README](comfyui/README.md) for details. | |
| #### d. GPU Memory Saving Schemes | |
| Due to the large parameters of EasyAnimateV5, we need to consider GPU memory saving schemes to conserve memory. We provide a `GPU_memory_mode` option for each prediction file, which can be selected from `model_cpu_offload`, `model_cpu_offload_and_qfloat8`, and `sequential_cpu_offload`. | |
| - `model_cpu_offload` indicates that the entire model will be offloaded to the CPU after use, saving some GPU memory. | |
| - `model_cpu_offload_and_qfloat8` indicates that the entire model will be offloaded to the CPU after use, and the transformer model is quantized to float8, saving even more GPU memory. | |
| - `sequential_cpu_offload` means that each layer of the model will be offloaded to the CPU after use, which is slower but saves a substantial amount of GPU memory. | |
| ### 2. Model Training | |
| A complete EasyAnimate training pipeline should include data preprocessing, Video VAE training, and Video DiT training. Among these, Video VAE training is optional because we have already provided a pre-trained Video VAE. | |
| <h4 id="data-preprocess">a. data preprocessing</h4> | |
| We have provided a simple demo of training the Lora model through image data, which can be found in the [wiki](https://github.com/aigc-apps/EasyAnimate/wiki/Training-Lora) for details. | |
| A complete data preprocessing link for long video segmentation, cleaning, and description can refer to [README](./easyanimate/video_caption/README.md) in the video captions section. | |
| If you want to train a text to image and video generation model. You need to arrange the dataset in this format. | |
| ``` | |
| 📦 project/ | |
| ├── 📂 datasets/ | |
| │ ├── 📂 internal_datasets/ | |
| │ ├── 📂 train/ | |
| │ │ ├── 📄 00000001.mp4 | |
| │ │ ├── 📄 00000002.jpg | |
| │ │ └── 📄 ..... | |
| │ └── 📄 json_of_internal_datasets.json | |
| ``` | |
| The json_of_internal_datasets.json is a standard JSON file. The file_path in the json can to be set as relative path, as shown in below: | |
| ```json | |
| [ | |
| { | |
| "file_path": "train/00000001.mp4", | |
| "text": "A group of young men in suits and sunglasses are walking down a city street.", | |
| "type": "video" | |
| }, | |
| { | |
| "file_path": "train/00000002.jpg", | |
| "text": "A group of young men in suits and sunglasses are walking down a city street.", | |
| "type": "image" | |
| }, | |
| ..... | |
| ] | |
| ``` | |
| You can also set the path as absolute path as follow: | |
| ```json | |
| [ | |
| { | |
| "file_path": "/mnt/data/videos/00000001.mp4", | |
| "text": "A group of young men in suits and sunglasses are walking down a city street.", | |
| "type": "video" | |
| }, | |
| { | |
| "file_path": "/mnt/data/train/00000001.jpg", | |
| "text": "A group of young men in suits and sunglasses are walking down a city street.", | |
| "type": "image" | |
| }, | |
| ..... | |
| ] | |
| ``` | |
| <h4 id="vae-train">b. Video VAE training (optional)</h4> | |
| Video VAE training is an optional option as we have already provided pre trained Video VAEs. | |
| If you want to train video vae, you can refer to [README](easyanimate/vae/README.md) in the video vae section. | |
| <h4 id="dit-train">c. Video DiT training </h4> | |
| If the data format is relative path during data preprocessing, please set ```scripts/train.sh``` as follow. | |
| ``` | |
| export DATASET_NAME="datasets/internal_datasets/" | |
| export DATASET_META_NAME="datasets/internal_datasets/json_of_internal_datasets.json" | |
| ``` | |
| If the data format is absolute path during data preprocessing, please set ```scripts/train.sh``` as follow. | |
| ``` | |
| export DATASET_NAME="" | |
| export DATASET_META_NAME="/mnt/data/json_of_internal_datasets.json" | |
| ``` | |
| Then, we run scripts/train.sh. | |
| ```sh | |
| sh scripts/train.sh | |
| ``` | |
| For details on setting some parameters, please refer to [Readme Train](scripts/README_TRAIN.md) and [Readme Lora](scripts/README_TRAIN_LORA.md). | |
| <details> | |
| <summary>(Obsolete) EasyAnimateV1:</summary> | |
| If you want to train EasyAnimateV1. Please switch to the git branch v1. | |
| </details> | |
| # Model zoo | |
| EasyAnimateV5: | |
| 7B: | |
| | Name | Type | Storage Space | Hugging Face | Model Scope | Description | | |
| |--|--|--|--|--|--| | |
| | EasyAnimateV5-7b-zh-InP | EasyAnimateV5 | 22 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5-7b-zh-InP) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV5-7b-zh-InP) | Official 7B image-to-video weights. Supports video prediction at multiple resolutions (512, 768, 1024), trained with 49 frames at 8 frames per second, and supports bilingual prediction in Chinese and English. | | |
| | EasyAnimateV5-7b-zh | EasyAnimateV5 | 22 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5-7b-zh) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV5-7b-zh) | Official 7B text-to-video weights. Supports video prediction at multiple resolutions (512, 768, 1024), trained with 49 frames at 8 frames per second, and supports bilingual prediction in Chinese and English. | | |
| 12B: | |
| | Name | Type | Storage Space | Hugging Face | Model Scope | Description | | |
| |--|--|--|--|--|--| | |
| | EasyAnimateV5-12b-zh-InP | EasyAnimateV5 | 34 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5-12b-zh-InP) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV5-12b-zh-InP) | Official image-to-video weights. Supports video prediction at multiple resolutions (512, 768, 1024), trained with 49 frames at 8 frames per second, and supports bilingual prediction in Chinese and English. | | |
| | EasyAnimateV5-12b-zh-Control | EasyAnimateV5 | 34 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5-12b-zh-Control) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV5-12b-zh-Control) | Official video control weights, supporting various control conditions such as Canny, Depth, Pose, MLSD, etc. Supports video prediction at multiple resolutions (512, 768, 1024) and is trained with 49 frames at 8 frames per second. Bilingual prediction in Chinese and English is supported. | | |
| | EasyAnimateV5-12b-zh | EasyAnimateV5 | 34 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5-12b-zh) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV5-12b-zh) | Official text-to-video weights. Supports video prediction at multiple resolutions (512, 768, 1024), trained with 49 frames at 8 frames per second, and supports bilingual prediction in Chinese and English. | | |
| <details> | |
| <summary>(Obsolete) EasyAnimateV4:</summary> | |
| | Name | Type | Storage Space | Hugging Face | Model Scope | Description | | |
| |--|--|--|--|--|--| | |
| | EasyAnimateV4-XL-2-InP.tar.gz | EasyAnimateV4 | Before extraction: 8.9 GB \/ After extraction: 14.0 GB |[🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV4-XL-2-InP)| [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV4-XL-2-InP)| | Our official graph-generated video model is capable of predicting videos at multiple resolutions (512, 768, 1024, 1280) and has been trained on 144 frames at a rate of 24 frames per second. | | |
| </details> | |
| <details> | |
| <summary>(Obsolete) EasyAnimateV3:</summary> | |
| | Name | Type | Storage Space | Hugging Face | Model Scope | Description | | |
| |--|--|--|--|--|--| | |
| | EasyAnimateV3-XL-2-InP-512x512.tar | EasyAnimateV3 | 18.2GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV3-XL-2-InP-512x512)| [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV3-XL-2-InP-512x512) | EasyAnimateV3 official weights for 512x512 text and image to video resolution. Training with 144 frames and fps 24 | | |
| | EasyAnimateV3-XL-2-InP-768x768.tar | EasyAnimateV3 | 18.2GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV3-XL-2-InP-768x768) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV3-XL-2-InP-768x768) | EasyAnimateV3 official weights for 768x768 text and image to video resolution. Training with 144 frames and fps 24 | | |
| | EasyAnimateV3-XL-2-InP-960x960.tar | EasyAnimateV3 | 18.2GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV3-XL-2-InP-960x960) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV3-XL-2-InP-960x960) | EasyAnimateV3 official weights for 960x960 text and image to video resolution. Training with 144 frames and fps 24 | | |
| </details> | |
| <details> | |
| <summary>(Obsolete) EasyAnimateV2:</summary> | |
| | Name | Type | Storage Space | Url | Hugging Face | Model Scope | Description | | |
| |--|--|--|--|--|--|--| | |
| | EasyAnimateV2-XL-2-512x512.tar | EasyAnimateV2 | 16.2GB | - | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV2-XL-2-512x512)| [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV2-XL-2-512x512)| EasyAnimateV2 official weights for 512x512 resolution. Training with 144 frames and fps 24 | | |
| | EasyAnimateV2-XL-2-768x768.tar | EasyAnimateV2 | 16.2GB | - | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV2-XL-2-768x768) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV2-XL-2-768x768)| EasyAnimateV2 official weights for 768x768 resolution. Training with 144 frames and fps 24 | | |
| | easyanimatev2_minimalism_lora.safetensors | Lora of Pixart | 485.1MB | [Download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Personalized_Model/easyanimatev2_minimalism_lora.safetensors)| - | - | A lora training with a specifial type images. Images can be downloaded from [Url](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/v2/Minimalism.zip). | | |
| </details> | |
| <details> | |
| <summary>(Obsolete) EasyAnimateV1:</summary> | |
| ### 1、Motion Weights | |
| | Name | Type | Storage Space | Url | Description | | |
| |--|--|--|--|--| | |
| | easyanimate_v1_mm.safetensors | Motion Module | 4.1GB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Motion_Module/easyanimate_v1_mm.safetensors) | Training with 80 frames and fps 12 | | |
| ### 2、Other Weights | |
| | Name | Type | Storage Space | Url | Description | | |
| |--|--|--|--|--| | |
| | PixArt-XL-2-512x512.tar | Pixart | 11.4GB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Diffusion_Transformer/PixArt-XL-2-512x512.tar)| Pixart-Alpha official weights | | |
| | easyanimate_portrait.safetensors | Checkpoint of Pixart | 2.3GB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Personalized_Model/easyanimate_portrait.safetensors) | Training with internal portrait datasets | | |
| | easyanimate_portrait_lora.safetensors | Lora of Pixart | 654.0MB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Personalized_Model/easyanimate_portrait_lora.safetensors)| Training with internal portrait datasets | | |
| </details> | |
| # TODO List | |
| - Support model with larger params. | |
| # Contact Us | |
| 1. Use Dingding to search group 77450006752 or Scan to join | |
| 2. You need to scan the image to join the WeChat group or if it is expired, add this student as a friend first to invite you. | |
| <img src="https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/group/dd.png" alt="ding group" width="30%"/> | |
| <img src="https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/group/wechat.jpg" alt="Wechat group" width="30%"/> | |
| <img src="https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/group/person.jpg" alt="Person" width="30%"/> | |
| # Reference | |
| - CogVideo: https://github.com/THUDM/CogVideo/ | |
| - Flux: https://github.com/black-forest-labs/flux | |
| - magvit: https://github.com/google-research/magvit | |
| - PixArt: https://github.com/PixArt-alpha/PixArt-alpha | |
| - Open-Sora-Plan: https://github.com/PKU-YuanGroup/Open-Sora-Plan | |
| - Open-Sora: https://github.com/hpcaitech/Open-Sora | |
| - Animatediff: https://github.com/guoyww/AnimateDiff | |
| - ComfyUI-EasyAnimateWrapper: https://github.com/kijai/ComfyUI-EasyAnimateWrapper | |
| - HunYuan DiT: https://github.com/tencent/HunyuanDiT | |
| # License | |
| This project is licensed under the [Apache License (Version 2.0)](https://github.com/modelscope/modelscope/blob/master/LICENSE). | |