
End of training
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- README.md +21 -0
- checkpoint-1000/optimizer.bin +3 -0
- checkpoint-1000/pytorch_model.bin +3 -0
- checkpoint-1000/random_states_0.pkl +3 -0
- checkpoint-1000/scheduler.bin +3 -0
- checkpoint-1500/optimizer.bin +3 -0
- checkpoint-1500/pytorch_model.bin +3 -0
- checkpoint-1500/random_states_0.pkl +3 -0
- checkpoint-1500/scheduler.bin +3 -0
- checkpoint-2000/optimizer.bin +3 -0
- checkpoint-2000/pytorch_model.bin +3 -0
- checkpoint-2000/random_states_0.pkl +3 -0
- checkpoint-2000/scheduler.bin +3 -0
- checkpoint-2500/optimizer.bin +3 -0
- checkpoint-2500/pytorch_model.bin +3 -0
- checkpoint-2500/random_states_0.pkl +3 -0
- checkpoint-2500/scheduler.bin +3 -0
- checkpoint-3000/optimizer.bin +3 -0
- checkpoint-3000/pytorch_model.bin +3 -0
- checkpoint-3000/random_states_0.pkl +3 -0
- checkpoint-3000/scheduler.bin +3 -0
- checkpoint-500/optimizer.bin +3 -0
- checkpoint-500/pytorch_model.bin +3 -0
- checkpoint-500/random_states_0.pkl +3 -0
- checkpoint-500/scheduler.bin +3 -0
- feature_extractor/preprocessor_config.json +28 -0
- image_0.png +0 -0
- image_1.png +0 -0
- image_2.png +0 -0
- image_3.png +0 -0
- learned_embeds-steps-1000.bin +3 -0
- learned_embeds-steps-1500.bin +3 -0
- learned_embeds-steps-2000.bin +3 -0
- learned_embeds-steps-2500.bin +3 -0
- learned_embeds-steps-3000.bin +3 -0
- learned_embeds-steps-500.bin +3 -0
- learned_embeds.bin +3 -0
- logs/textual_inversion/1682912968.7033062/events.out.tfevents.1682912968.hal-dgx.143782.1 +3 -0
- logs/textual_inversion/1682912968.7088115/hparams.yml +45 -0
- logs/textual_inversion/events.out.tfevents.1682912968.hal-dgx.143782.0 +3 -0
- model_index.json +33 -0
- safety_checker/config.json +181 -0
- safety_checker/pytorch_model.bin +3 -0
- scheduler/scheduler_config.json +14 -0
- text_encoder/config.json +25 -0
- text_encoder/pytorch_model.bin +3 -0
- tokenizer/added_tokens.json +34 -0
- tokenizer/merges.txt +0 -0
- tokenizer/special_tokens_map.json +24 -0
- tokenizer/tokenizer_config.json +34 -0
README.md
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
---
|
| 3 |
+
license: creativeml-openrail-m
|
| 4 |
+
base_model: runwayml/stable-diffusion-v1-5
|
| 5 |
+
tags:
|
| 6 |
+
- stable-diffusion
|
| 7 |
+
- stable-diffusion-diffusers
|
| 8 |
+
- text-to-image
|
| 9 |
+
- diffusers
|
| 10 |
+
- textual_inversion
|
| 11 |
+
inference: true
|
| 12 |
+
---
|
| 13 |
+
|
| 14 |
+
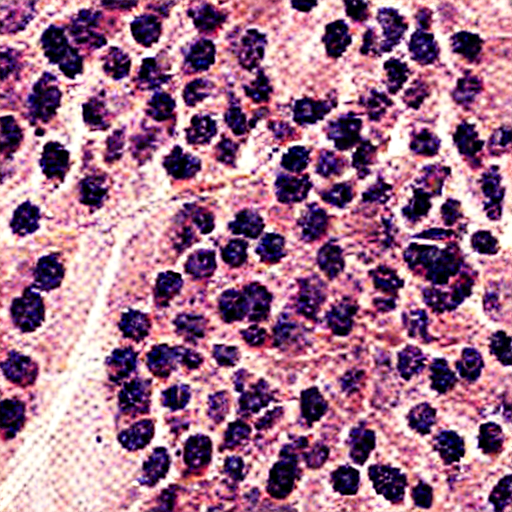
# Textual inversion text2image fine-tuning - anic87/textual_inversion_normal
|
| 15 |
+
These are textual inversion adaption weights for runwayml/stable-diffusion-v1-5. You can find some example images in the following.
|
| 16 |
+
|
| 17 |
+

|
| 18 |
+

|
| 19 |
+

|
| 20 |
+

|
| 21 |
+
|
checkpoint-1000/optimizer.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4c2c9fa56c175b225befe80a8510db60239f9bdf353ec1bc68b0997744dac325
|
| 3 |
+
size 303760867
|
checkpoint-1000/pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b191dcd6a04fa579b1564220f92c4db20f6ba906a8feeafb4b0e03434de5de1a
|
| 3 |
+
size 492415863
|
checkpoint-1000/random_states_0.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ea8bf3606873ff6ed2ec4ccf64e88224fb4f6d6c30328e8e9c00d98061e1495a
|
| 3 |
+
size 14631
|
checkpoint-1000/scheduler.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:eca71f9cb08b312b8992e31dcababd7ade6c163c6a2b62ce39f88941b1a97965
|
| 3 |
+
size 559
|
checkpoint-1500/optimizer.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3aff62b02ef13fc3daa3f96c2c220c27c4b911a33d7d2ae44c54be8cace4dd8a
|
| 3 |
+
size 303760867
|
checkpoint-1500/pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d62b4288bd03547fb5ce6abce08a5eb8a7625c575e843dd0b4f34c53fbda538b
|
| 3 |
+
size 492415863
|
checkpoint-1500/random_states_0.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5b9b5107be8a5e5b93c15c92b58c59f0b894141b2c525cf23c227ed86be530ca
|
| 3 |
+
size 14567
|
checkpoint-1500/scheduler.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:86431682026edff2768e59082dc0528f66e75d63530f38d10dbee6fbd99424ae
|
| 3 |
+
size 559
|
checkpoint-2000/optimizer.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d136042dff7e29a56f75b074d7dfec3dd8a36438288669362c59a9868c7a9f12
|
| 3 |
+
size 303760867
|
checkpoint-2000/pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:616351fcabfdb101ca3d2dcf9f8409ada338c4329b44359644066a0a19e645ec
|
| 3 |
+
size 492415863
|
checkpoint-2000/random_states_0.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7a9b1763a0f446ff0cf04e91f85da3a428585f1047da81e94310ea96c31f6ee5
|
| 3 |
+
size 14567
|
checkpoint-2000/scheduler.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:413c91b53679579e0e64f5749494f302822890e691f35a71d35455d1266caa05
|
| 3 |
+
size 559
|
checkpoint-2500/optimizer.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:65f0c5752f47c0eb2ecc865720c89111c8c0243c1831aae4c26e9afcbd1334bc
|
| 3 |
+
size 303760867
|
checkpoint-2500/pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:864309b78736f40de6ff3e805f1ce08098b7e39be83a08458628d268725fe1c6
|
| 3 |
+
size 492415863
|
checkpoint-2500/random_states_0.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:90315e79b633fb50e4949926e1e65fbbed0c040c88a13a2704f664796d3dae56
|
| 3 |
+
size 14567
|
checkpoint-2500/scheduler.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:00bc6004c5f3e1f025cb16f16f2d7e2ce6fbc1a395d340dc68998cafc4508bb0
|
| 3 |
+
size 559
|
checkpoint-3000/optimizer.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b1ab695accb38f42f2e4ff7927f47cd0e33fb6e9b3456bec20eaebe49a018bef
|
| 3 |
+
size 303760867
|
checkpoint-3000/pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5e7d784e042f6b2e2c67245084aeab73f00369d7f331eade9d30a0fc2af1532e
|
| 3 |
+
size 492415863
|
checkpoint-3000/random_states_0.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:eecd3d1b1bb7d215c3696502a68809be7f369204c4fc10adfaf90c8d5d38a01c
|
| 3 |
+
size 14567
|
checkpoint-3000/scheduler.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:06bd87680b9ba3e457d5445aa18e4a8acf174a8b7a80ceb7f4d9509a9a4eb197
|
| 3 |
+
size 559
|
checkpoint-500/optimizer.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fd543626dc3b646681146c682e733cd5a56b16552bdd862de3693eab4f757e1d
|
| 3 |
+
size 303760867
|
checkpoint-500/pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:afefd15e6a4a4b326774e7cb77b8c566b86856c709c7baa05041f4ce59bd5889
|
| 3 |
+
size 492415863
|
checkpoint-500/random_states_0.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:31aa71e3430d298c85dfe641bbbf48ddb83db3a08bd0bd2991cad5333775fd9f
|
| 3 |
+
size 14567
|
checkpoint-500/scheduler.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b3eacc7ed448cfb54f908b30c183eb2abc1a6cdf075cf4f5f1de91dbb65b7ac4
|
| 3 |
+
size 559
|
feature_extractor/preprocessor_config.json
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"crop_size": {
|
| 3 |
+
"height": 224,
|
| 4 |
+
"width": 224
|
| 5 |
+
},
|
| 6 |
+
"do_center_crop": true,
|
| 7 |
+
"do_convert_rgb": true,
|
| 8 |
+
"do_normalize": true,
|
| 9 |
+
"do_rescale": true,
|
| 10 |
+
"do_resize": true,
|
| 11 |
+
"feature_extractor_type": "CLIPFeatureExtractor",
|
| 12 |
+
"image_mean": [
|
| 13 |
+
0.48145466,
|
| 14 |
+
0.4578275,
|
| 15 |
+
0.40821073
|
| 16 |
+
],
|
| 17 |
+
"image_processor_type": "CLIPFeatureExtractor",
|
| 18 |
+
"image_std": [
|
| 19 |
+
0.26862954,
|
| 20 |
+
0.26130258,
|
| 21 |
+
0.27577711
|
| 22 |
+
],
|
| 23 |
+
"resample": 3,
|
| 24 |
+
"rescale_factor": 0.00392156862745098,
|
| 25 |
+
"size": {
|
| 26 |
+
"shortest_edge": 224
|
| 27 |
+
}
|
| 28 |
+
}
|
image_0.png
ADDED
|
image_1.png
ADDED

|
image_2.png
ADDED

|
image_3.png
ADDED

|
learned_embeds-steps-1000.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:46ef9bd5c6bbb28edcc00281d253fa083e5badcd91b51507770ee588e0196162
|
| 3 |
+
size 99051
|
learned_embeds-steps-1500.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:26cd8964c75970ce40912aa6bb38bab6a20abf726cb485d2e41d779f34814483
|
| 3 |
+
size 99051
|
learned_embeds-steps-2000.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:095d4f8263bd65b95804d47ccb7722e8b1c40b3050a9e6590de79f1cfe69412c
|
| 3 |
+
size 99051
|
learned_embeds-steps-2500.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c84a0cc402d0c40e3a5279bf55863be538b244d85deedfde5eef7b6ca2d06d16
|
| 3 |
+
size 99051
|
learned_embeds-steps-3000.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7d87fae97e85f66036b9e18cb9c53b6ad0d5b9d8d3fc0feb4995af0219a329a6
|
| 3 |
+
size 99051
|
learned_embeds-steps-500.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8734e834bd52c7167b96f082af476fbb65a07f5936e4efbb1b60da2bde52b9e6
|
| 3 |
+
size 99051
|
learned_embeds.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7d87fae97e85f66036b9e18cb9c53b6ad0d5b9d8d3fc0feb4995af0219a329a6
|
| 3 |
+
size 99051
|
logs/textual_inversion/1682912968.7033062/events.out.tfevents.1682912968.hal-dgx.143782.1
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2436581675cdd8d4c5c09f5b35dd60e392e51a8f3517100b2c2d04643653f59b
|
| 3 |
+
size 2293
|
logs/textual_inversion/1682912968.7088115/hparams.yml
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
adam_beta1: 0.9
|
| 2 |
+
adam_beta2: 0.999
|
| 3 |
+
adam_epsilon: 1.0e-08
|
| 4 |
+
adam_weight_decay: 0.01
|
| 5 |
+
allow_tf32: false
|
| 6 |
+
center_crop: false
|
| 7 |
+
checkpointing_steps: 500
|
| 8 |
+
checkpoints_total_limit: null
|
| 9 |
+
dataloader_num_workers: 0
|
| 10 |
+
enable_xformers_memory_efficient_attention: false
|
| 11 |
+
gradient_accumulation_steps: 4
|
| 12 |
+
gradient_checkpointing: false
|
| 13 |
+
hub_model_id: null
|
| 14 |
+
hub_token: null
|
| 15 |
+
initializer_token: situ
|
| 16 |
+
learnable_property: object
|
| 17 |
+
learning_rate: 0.005
|
| 18 |
+
local_rank: -1
|
| 19 |
+
logging_dir: logs
|
| 20 |
+
lr_scheduler: constant
|
| 21 |
+
lr_warmup_steps: 0
|
| 22 |
+
max_train_steps: 3000
|
| 23 |
+
mixed_precision: 'no'
|
| 24 |
+
num_train_epochs: 1
|
| 25 |
+
num_validation_images: 4
|
| 26 |
+
num_vectors: 32
|
| 27 |
+
only_save_embeds: true
|
| 28 |
+
output_dir: textual_inversion_normal
|
| 29 |
+
placeholder_token: <noncancerous-tissue>
|
| 30 |
+
pretrained_model_name_or_path: runwayml/stable-diffusion-v1-5
|
| 31 |
+
push_to_hub: true
|
| 32 |
+
repeats: 100
|
| 33 |
+
report_to: tensorboard
|
| 34 |
+
resolution: 512
|
| 35 |
+
resume_from_checkpoint: null
|
| 36 |
+
revision: null
|
| 37 |
+
save_steps: 500
|
| 38 |
+
scale_lr: false
|
| 39 |
+
seed: null
|
| 40 |
+
tokenizer_name: null
|
| 41 |
+
train_batch_size: 1
|
| 42 |
+
train_data_dir: /projects/ac67/projects/textual_inversion/img/pcam/normal/
|
| 43 |
+
validation_epochs: null
|
| 44 |
+
validation_prompt: <noncancerous-tissue>
|
| 45 |
+
validation_steps: 100
|
logs/textual_inversion/events.out.tfevents.1682912968.hal-dgx.143782.0
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ea92e10b59741d72853f57b3953ed7a2eb009787f406684df4a2d66eb7b63c2c
|
| 3 |
+
size 63095852
|
model_index.json
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "StableDiffusionPipeline",
|
| 3 |
+
"_diffusers_version": "0.17.0.dev0",
|
| 4 |
+
"feature_extractor": [
|
| 5 |
+
"transformers",
|
| 6 |
+
"CLIPFeatureExtractor"
|
| 7 |
+
],
|
| 8 |
+
"requires_safety_checker": true,
|
| 9 |
+
"safety_checker": [
|
| 10 |
+
"stable_diffusion",
|
| 11 |
+
"StableDiffusionSafetyChecker"
|
| 12 |
+
],
|
| 13 |
+
"scheduler": [
|
| 14 |
+
"diffusers",
|
| 15 |
+
"PNDMScheduler"
|
| 16 |
+
],
|
| 17 |
+
"text_encoder": [
|
| 18 |
+
"transformers",
|
| 19 |
+
"CLIPTextModel"
|
| 20 |
+
],
|
| 21 |
+
"tokenizer": [
|
| 22 |
+
"transformers",
|
| 23 |
+
"CLIPTokenizer"
|
| 24 |
+
],
|
| 25 |
+
"unet": [
|
| 26 |
+
"diffusers",
|
| 27 |
+
"UNet2DConditionModel"
|
| 28 |
+
],
|
| 29 |
+
"vae": [
|
| 30 |
+
"diffusers",
|
| 31 |
+
"AutoencoderKL"
|
| 32 |
+
]
|
| 33 |
+
}
|
safety_checker/config.json
ADDED
|
@@ -0,0 +1,181 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_commit_hash": "39593d5650112b4cc580433f6b0435385882d819",
|
| 3 |
+
"_name_or_path": "/projects/ac67/projects/textual_inversion/hub/models--runwayml--stable-diffusion-v1-5/snapshots/39593d5650112b4cc580433f6b0435385882d819/safety_checker",
|
| 4 |
+
"architectures": [
|
| 5 |
+
"StableDiffusionSafetyChecker"
|
| 6 |
+
],
|
| 7 |
+
"initializer_factor": 1.0,
|
| 8 |
+
"logit_scale_init_value": 2.6592,
|
| 9 |
+
"model_type": "clip",
|
| 10 |
+
"projection_dim": 768,
|
| 11 |
+
"text_config": {
|
| 12 |
+
"_name_or_path": "",
|
| 13 |
+
"add_cross_attention": false,
|
| 14 |
+
"architectures": null,
|
| 15 |
+
"attention_dropout": 0.0,
|
| 16 |
+
"bad_words_ids": null,
|
| 17 |
+
"begin_suppress_tokens": null,
|
| 18 |
+
"bos_token_id": 0,
|
| 19 |
+
"chunk_size_feed_forward": 0,
|
| 20 |
+
"cross_attention_hidden_size": null,
|
| 21 |
+
"decoder_start_token_id": null,
|
| 22 |
+
"diversity_penalty": 0.0,
|
| 23 |
+
"do_sample": false,
|
| 24 |
+
"dropout": 0.0,
|
| 25 |
+
"early_stopping": false,
|
| 26 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 27 |
+
"eos_token_id": 2,
|
| 28 |
+
"exponential_decay_length_penalty": null,
|
| 29 |
+
"finetuning_task": null,
|
| 30 |
+
"forced_bos_token_id": null,
|
| 31 |
+
"forced_eos_token_id": null,
|
| 32 |
+
"hidden_act": "quick_gelu",
|
| 33 |
+
"hidden_size": 768,
|
| 34 |
+
"id2label": {
|
| 35 |
+
"0": "LABEL_0",
|
| 36 |
+
"1": "LABEL_1"
|
| 37 |
+
},
|
| 38 |
+
"initializer_factor": 1.0,
|
| 39 |
+
"initializer_range": 0.02,
|
| 40 |
+
"intermediate_size": 3072,
|
| 41 |
+
"is_decoder": false,
|
| 42 |
+
"is_encoder_decoder": false,
|
| 43 |
+
"label2id": {
|
| 44 |
+
"LABEL_0": 0,
|
| 45 |
+
"LABEL_1": 1
|
| 46 |
+
},
|
| 47 |
+
"layer_norm_eps": 1e-05,
|
| 48 |
+
"length_penalty": 1.0,
|
| 49 |
+
"max_length": 20,
|
| 50 |
+
"max_position_embeddings": 77,
|
| 51 |
+
"min_length": 0,
|
| 52 |
+
"model_type": "clip_text_model",
|
| 53 |
+
"no_repeat_ngram_size": 0,
|
| 54 |
+
"num_attention_heads": 12,
|
| 55 |
+
"num_beam_groups": 1,
|
| 56 |
+
"num_beams": 1,
|
| 57 |
+
"num_hidden_layers": 12,
|
| 58 |
+
"num_return_sequences": 1,
|
| 59 |
+
"output_attentions": false,
|
| 60 |
+
"output_hidden_states": false,
|
| 61 |
+
"output_scores": false,
|
| 62 |
+
"pad_token_id": 1,
|
| 63 |
+
"prefix": null,
|
| 64 |
+
"problem_type": null,
|
| 65 |
+
"projection_dim": 512,
|
| 66 |
+
"pruned_heads": {},
|
| 67 |
+
"remove_invalid_values": false,
|
| 68 |
+
"repetition_penalty": 1.0,
|
| 69 |
+
"return_dict": true,
|
| 70 |
+
"return_dict_in_generate": false,
|
| 71 |
+
"sep_token_id": null,
|
| 72 |
+
"suppress_tokens": null,
|
| 73 |
+
"task_specific_params": null,
|
| 74 |
+
"temperature": 1.0,
|
| 75 |
+
"tf_legacy_loss": false,
|
| 76 |
+
"tie_encoder_decoder": false,
|
| 77 |
+
"tie_word_embeddings": true,
|
| 78 |
+
"tokenizer_class": null,
|
| 79 |
+
"top_k": 50,
|
| 80 |
+
"top_p": 1.0,
|
| 81 |
+
"torch_dtype": null,
|
| 82 |
+
"torchscript": false,
|
| 83 |
+
"transformers_version": "4.26.1",
|
| 84 |
+
"typical_p": 1.0,
|
| 85 |
+
"use_bfloat16": false,
|
| 86 |
+
"vocab_size": 49408
|
| 87 |
+
},
|
| 88 |
+
"text_config_dict": {
|
| 89 |
+
"hidden_size": 768,
|
| 90 |
+
"intermediate_size": 3072,
|
| 91 |
+
"num_attention_heads": 12,
|
| 92 |
+
"num_hidden_layers": 12
|
| 93 |
+
},
|
| 94 |
+
"torch_dtype": "float32",
|
| 95 |
+
"transformers_version": null,
|
| 96 |
+
"vision_config": {
|
| 97 |
+
"_name_or_path": "",
|
| 98 |
+
"add_cross_attention": false,
|
| 99 |
+
"architectures": null,
|
| 100 |
+
"attention_dropout": 0.0,
|
| 101 |
+
"bad_words_ids": null,
|
| 102 |
+
"begin_suppress_tokens": null,
|
| 103 |
+
"bos_token_id": null,
|
| 104 |
+
"chunk_size_feed_forward": 0,
|
| 105 |
+
"cross_attention_hidden_size": null,
|
| 106 |
+
"decoder_start_token_id": null,
|
| 107 |
+
"diversity_penalty": 0.0,
|
| 108 |
+
"do_sample": false,
|
| 109 |
+
"dropout": 0.0,
|
| 110 |
+
"early_stopping": false,
|
| 111 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 112 |
+
"eos_token_id": null,
|
| 113 |
+
"exponential_decay_length_penalty": null,
|
| 114 |
+
"finetuning_task": null,
|
| 115 |
+
"forced_bos_token_id": null,
|
| 116 |
+
"forced_eos_token_id": null,
|
| 117 |
+
"hidden_act": "quick_gelu",
|
| 118 |
+
"hidden_size": 1024,
|
| 119 |
+
"id2label": {
|
| 120 |
+
"0": "LABEL_0",
|
| 121 |
+
"1": "LABEL_1"
|
| 122 |
+
},
|
| 123 |
+
"image_size": 224,
|
| 124 |
+
"initializer_factor": 1.0,
|
| 125 |
+
"initializer_range": 0.02,
|
| 126 |
+
"intermediate_size": 4096,
|
| 127 |
+
"is_decoder": false,
|
| 128 |
+
"is_encoder_decoder": false,
|
| 129 |
+
"label2id": {
|
| 130 |
+
"LABEL_0": 0,
|
| 131 |
+
"LABEL_1": 1
|
| 132 |
+
},
|
| 133 |
+
"layer_norm_eps": 1e-05,
|
| 134 |
+
"length_penalty": 1.0,
|
| 135 |
+
"max_length": 20,
|
| 136 |
+
"min_length": 0,
|
| 137 |
+
"model_type": "clip_vision_model",
|
| 138 |
+
"no_repeat_ngram_size": 0,
|
| 139 |
+
"num_attention_heads": 16,
|
| 140 |
+
"num_beam_groups": 1,
|
| 141 |
+
"num_beams": 1,
|
| 142 |
+
"num_channels": 3,
|
| 143 |
+
"num_hidden_layers": 24,
|
| 144 |
+
"num_return_sequences": 1,
|
| 145 |
+
"output_attentions": false,
|
| 146 |
+
"output_hidden_states": false,
|
| 147 |
+
"output_scores": false,
|
| 148 |
+
"pad_token_id": null,
|
| 149 |
+
"patch_size": 14,
|
| 150 |
+
"prefix": null,
|
| 151 |
+
"problem_type": null,
|
| 152 |
+
"projection_dim": 512,
|
| 153 |
+
"pruned_heads": {},
|
| 154 |
+
"remove_invalid_values": false,
|
| 155 |
+
"repetition_penalty": 1.0,
|
| 156 |
+
"return_dict": true,
|
| 157 |
+
"return_dict_in_generate": false,
|
| 158 |
+
"sep_token_id": null,
|
| 159 |
+
"suppress_tokens": null,
|
| 160 |
+
"task_specific_params": null,
|
| 161 |
+
"temperature": 1.0,
|
| 162 |
+
"tf_legacy_loss": false,
|
| 163 |
+
"tie_encoder_decoder": false,
|
| 164 |
+
"tie_word_embeddings": true,
|
| 165 |
+
"tokenizer_class": null,
|
| 166 |
+
"top_k": 50,
|
| 167 |
+
"top_p": 1.0,
|
| 168 |
+
"torch_dtype": null,
|
| 169 |
+
"torchscript": false,
|
| 170 |
+
"transformers_version": "4.26.1",
|
| 171 |
+
"typical_p": 1.0,
|
| 172 |
+
"use_bfloat16": false
|
| 173 |
+
},
|
| 174 |
+
"vision_config_dict": {
|
| 175 |
+
"hidden_size": 1024,
|
| 176 |
+
"intermediate_size": 4096,
|
| 177 |
+
"num_attention_heads": 16,
|
| 178 |
+
"num_hidden_layers": 24,
|
| 179 |
+
"patch_size": 14
|
| 180 |
+
}
|
| 181 |
+
}
|
safety_checker/pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:193490b58ef62739077262e833bf091c66c29488058681ac25cf7df3d8190974
|
| 3 |
+
size 1216061799
|
scheduler/scheduler_config.json
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "PNDMScheduler",
|
| 3 |
+
"_diffusers_version": "0.17.0.dev0",
|
| 4 |
+
"beta_end": 0.012,
|
| 5 |
+
"beta_schedule": "scaled_linear",
|
| 6 |
+
"beta_start": 0.00085,
|
| 7 |
+
"clip_sample": false,
|
| 8 |
+
"num_train_timesteps": 1000,
|
| 9 |
+
"prediction_type": "epsilon",
|
| 10 |
+
"set_alpha_to_one": false,
|
| 11 |
+
"skip_prk_steps": true,
|
| 12 |
+
"steps_offset": 1,
|
| 13 |
+
"trained_betas": null
|
| 14 |
+
}
|
text_encoder/config.json
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "runwayml/stable-diffusion-v1-5",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"CLIPTextModel"
|
| 5 |
+
],
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"bos_token_id": 0,
|
| 8 |
+
"dropout": 0.0,
|
| 9 |
+
"eos_token_id": 2,
|
| 10 |
+
"hidden_act": "quick_gelu",
|
| 11 |
+
"hidden_size": 768,
|
| 12 |
+
"initializer_factor": 1.0,
|
| 13 |
+
"initializer_range": 0.02,
|
| 14 |
+
"intermediate_size": 3072,
|
| 15 |
+
"layer_norm_eps": 1e-05,
|
| 16 |
+
"max_position_embeddings": 77,
|
| 17 |
+
"model_type": "clip_text_model",
|
| 18 |
+
"num_attention_heads": 12,
|
| 19 |
+
"num_hidden_layers": 12,
|
| 20 |
+
"pad_token_id": 1,
|
| 21 |
+
"projection_dim": 768,
|
| 22 |
+
"torch_dtype": "float32",
|
| 23 |
+
"transformers_version": "4.26.1",
|
| 24 |
+
"vocab_size": 49440
|
| 25 |
+
}
|
text_encoder/pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:81102fba9b42d333c4655e179a64b5ec9ef15c0c1b79e617a52f81bc7027b94b
|
| 3 |
+
size 492406391
|
tokenizer/added_tokens.json
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"<noncancerous-tissue>": 49408,
|
| 3 |
+
"<noncancerous-tissue>_1": 49409,
|
| 4 |
+
"<noncancerous-tissue>_10": 49418,
|
| 5 |
+
"<noncancerous-tissue>_11": 49419,
|
| 6 |
+
"<noncancerous-tissue>_12": 49420,
|
| 7 |
+
"<noncancerous-tissue>_13": 49421,
|
| 8 |
+
"<noncancerous-tissue>_14": 49422,
|
| 9 |
+
"<noncancerous-tissue>_15": 49423,
|
| 10 |
+
"<noncancerous-tissue>_16": 49424,
|
| 11 |
+
"<noncancerous-tissue>_17": 49425,
|
| 12 |
+
"<noncancerous-tissue>_18": 49426,
|
| 13 |
+
"<noncancerous-tissue>_19": 49427,
|
| 14 |
+
"<noncancerous-tissue>_2": 49410,
|
| 15 |
+
"<noncancerous-tissue>_20": 49428,
|
| 16 |
+
"<noncancerous-tissue>_21": 49429,
|
| 17 |
+
"<noncancerous-tissue>_22": 49430,
|
| 18 |
+
"<noncancerous-tissue>_23": 49431,
|
| 19 |
+
"<noncancerous-tissue>_24": 49432,
|
| 20 |
+
"<noncancerous-tissue>_25": 49433,
|
| 21 |
+
"<noncancerous-tissue>_26": 49434,
|
| 22 |
+
"<noncancerous-tissue>_27": 49435,
|
| 23 |
+
"<noncancerous-tissue>_28": 49436,
|
| 24 |
+
"<noncancerous-tissue>_29": 49437,
|
| 25 |
+
"<noncancerous-tissue>_3": 49411,
|
| 26 |
+
"<noncancerous-tissue>_30": 49438,
|
| 27 |
+
"<noncancerous-tissue>_31": 49439,
|
| 28 |
+
"<noncancerous-tissue>_4": 49412,
|
| 29 |
+
"<noncancerous-tissue>_5": 49413,
|
| 30 |
+
"<noncancerous-tissue>_6": 49414,
|
| 31 |
+
"<noncancerous-tissue>_7": 49415,
|
| 32 |
+
"<noncancerous-tissue>_8": 49416,
|
| 33 |
+
"<noncancerous-tissue>_9": 49417
|
| 34 |
+
}
|
tokenizer/merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer/special_tokens_map.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<|startoftext|>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": true,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "<|endoftext|>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": true,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": "<|endoftext|>",
|
| 17 |
+
"unk_token": {
|
| 18 |
+
"content": "<|endoftext|>",
|
| 19 |
+
"lstrip": false,
|
| 20 |
+
"normalized": true,
|
| 21 |
+
"rstrip": false,
|
| 22 |
+
"single_word": false
|
| 23 |
+
}
|
| 24 |
+
}
|
tokenizer/tokenizer_config.json
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"bos_token": {
|
| 4 |
+
"__type": "AddedToken",
|
| 5 |
+
"content": "<|startoftext|>",
|
| 6 |
+
"lstrip": false,
|
| 7 |
+
"normalized": true,
|
| 8 |
+
"rstrip": false,
|
| 9 |
+
"single_word": false
|
| 10 |
+
},
|
| 11 |
+
"do_lower_case": true,
|
| 12 |
+
"eos_token": {
|
| 13 |
+
"__type": "AddedToken",
|
| 14 |
+
"content": "<|endoftext|>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": true,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false
|
| 19 |
+
},
|
| 20 |
+
"errors": "replace",
|
| 21 |
+
"model_max_length": 77,
|
| 22 |
+
"name_or_path": "runwayml/stable-diffusion-v1-5",
|
| 23 |
+
"pad_token": "<|endoftext|>",
|
| 24 |
+
"special_tokens_map_file": "./special_tokens_map.json",
|
| 25 |
+
"tokenizer_class": "CLIPTokenizer",
|
| 26 |
+
"unk_token": {
|
| 27 |
+
"__type": "AddedToken",
|
| 28 |
+
"content": "<|endoftext|>",
|
| 29 |
+
"lstrip": false,
|
| 30 |
+
"normalized": true,
|
| 31 |
+
"rstrip": false,
|
| 32 |
+
"single_word": false
|
| 33 |
+
}
|
| 34 |
+
}
|