
Initial model upload
Browse files- checkpoint-45/README.md +202 -0
- checkpoint-45/adapter_config.json +26 -0
- checkpoint-45/adapter_model.safetensors +3 -0
- checkpoint-45/additional_config.json +1 -0
- checkpoint-45/configuration.json +14 -0
- checkpoint-45/generation_config.json +11 -0
- checkpoint-45/optimizer.pt +3 -0
- checkpoint-45/rng_state.pth +3 -0
- checkpoint-45/scheduler.pt +3 -0
- checkpoint-45/sft_args.json +244 -0
- checkpoint-45/trainer_state.json +142 -0
- checkpoint-45/training_args.bin +3 -0
- images/eval_acc.png +0 -0
- images/eval_loss.png +0 -0
- images/eval_runtime.png +0 -0
- images/eval_samples_per_second.png +0 -0
- images/eval_steps_per_second.png +0 -0
- images/train_acc.png +0 -0
- images/train_epoch.png +0 -0
- images/train_grad_norm.png +0 -0
- images/train_learning_rate.png +0 -0
- images/train_loss.png +0 -0
- images/train_memory(GiB).png +0 -0
- images/train_total_flos.png +0 -0
- images/train_train_loss.png +0 -0
- images/train_train_runtime.png +0 -0
- images/train_train_samples_per_second.png +0 -0
- images/train_train_speed(iter_s).png +0 -0
- images/train_train_steps_per_second.png +0 -0
- logging.jsonl +13 -0
- runs/events.out.tfevents.1725876447.8e952411ac7f.14553.0 +3 -0
- sft_args.json +244 -0
- training_args.json +153 -0
checkpoint-45/README.md
ADDED
|
@@ -0,0 +1,202 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
base_model: /root/.cache/modelscope/hub/qwen/Qwen2-VL-7B-Instruct
|
| 3 |
+
library_name: peft
|
| 4 |
+
---
|
| 5 |
+
|
| 6 |
+
# Model Card for Model ID
|
| 7 |
+
|
| 8 |
+
<!-- Provide a quick summary of what the model is/does. -->
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
## Model Details
|
| 13 |
+
|
| 14 |
+
### Model Description
|
| 15 |
+
|
| 16 |
+
<!-- Provide a longer summary of what this model is. -->
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
- **Developed by:** [More Information Needed]
|
| 21 |
+
- **Funded by [optional]:** [More Information Needed]
|
| 22 |
+
- **Shared by [optional]:** [More Information Needed]
|
| 23 |
+
- **Model type:** [More Information Needed]
|
| 24 |
+
- **Language(s) (NLP):** [More Information Needed]
|
| 25 |
+
- **License:** [More Information Needed]
|
| 26 |
+
- **Finetuned from model [optional]:** [More Information Needed]
|
| 27 |
+
|
| 28 |
+
### Model Sources [optional]
|
| 29 |
+
|
| 30 |
+
<!-- Provide the basic links for the model. -->
|
| 31 |
+
|
| 32 |
+
- **Repository:** [More Information Needed]
|
| 33 |
+
- **Paper [optional]:** [More Information Needed]
|
| 34 |
+
- **Demo [optional]:** [More Information Needed]
|
| 35 |
+
|
| 36 |
+
## Uses
|
| 37 |
+
|
| 38 |
+
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
|
| 39 |
+
|
| 40 |
+
### Direct Use
|
| 41 |
+
|
| 42 |
+
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
|
| 43 |
+
|
| 44 |
+
[More Information Needed]
|
| 45 |
+
|
| 46 |
+
### Downstream Use [optional]
|
| 47 |
+
|
| 48 |
+
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
|
| 49 |
+
|
| 50 |
+
[More Information Needed]
|
| 51 |
+
|
| 52 |
+
### Out-of-Scope Use
|
| 53 |
+
|
| 54 |
+
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
|
| 55 |
+
|
| 56 |
+
[More Information Needed]
|
| 57 |
+
|
| 58 |
+
## Bias, Risks, and Limitations
|
| 59 |
+
|
| 60 |
+
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
|
| 61 |
+
|
| 62 |
+
[More Information Needed]
|
| 63 |
+
|
| 64 |
+
### Recommendations
|
| 65 |
+
|
| 66 |
+
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
|
| 67 |
+
|
| 68 |
+
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
|
| 69 |
+
|
| 70 |
+
## How to Get Started with the Model
|
| 71 |
+
|
| 72 |
+
Use the code below to get started with the model.
|
| 73 |
+
|
| 74 |
+
[More Information Needed]
|
| 75 |
+
|
| 76 |
+
## Training Details
|
| 77 |
+
|
| 78 |
+
### Training Data
|
| 79 |
+
|
| 80 |
+
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
|
| 81 |
+
|
| 82 |
+
[More Information Needed]
|
| 83 |
+
|
| 84 |
+
### Training Procedure
|
| 85 |
+
|
| 86 |
+
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
|
| 87 |
+
|
| 88 |
+
#### Preprocessing [optional]
|
| 89 |
+
|
| 90 |
+
[More Information Needed]
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
#### Training Hyperparameters
|
| 94 |
+
|
| 95 |
+
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
|
| 96 |
+
|
| 97 |
+
#### Speeds, Sizes, Times [optional]
|
| 98 |
+
|
| 99 |
+
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
|
| 100 |
+
|
| 101 |
+
[More Information Needed]
|
| 102 |
+
|
| 103 |
+
## Evaluation
|
| 104 |
+
|
| 105 |
+
<!-- This section describes the evaluation protocols and provides the results. -->
|
| 106 |
+
|
| 107 |
+
### Testing Data, Factors & Metrics
|
| 108 |
+
|
| 109 |
+
#### Testing Data
|
| 110 |
+
|
| 111 |
+
<!-- This should link to a Dataset Card if possible. -->
|
| 112 |
+
|
| 113 |
+
[More Information Needed]
|
| 114 |
+
|
| 115 |
+
#### Factors
|
| 116 |
+
|
| 117 |
+
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
|
| 118 |
+
|
| 119 |
+
[More Information Needed]
|
| 120 |
+
|
| 121 |
+
#### Metrics
|
| 122 |
+
|
| 123 |
+
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
|
| 124 |
+
|
| 125 |
+
[More Information Needed]
|
| 126 |
+
|
| 127 |
+
### Results
|
| 128 |
+
|
| 129 |
+
[More Information Needed]
|
| 130 |
+
|
| 131 |
+
#### Summary
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
## Model Examination [optional]
|
| 136 |
+
|
| 137 |
+
<!-- Relevant interpretability work for the model goes here -->
|
| 138 |
+
|
| 139 |
+
[More Information Needed]
|
| 140 |
+
|
| 141 |
+
## Environmental Impact
|
| 142 |
+
|
| 143 |
+
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
|
| 144 |
+
|
| 145 |
+
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
|
| 146 |
+
|
| 147 |
+
- **Hardware Type:** [More Information Needed]
|
| 148 |
+
- **Hours used:** [More Information Needed]
|
| 149 |
+
- **Cloud Provider:** [More Information Needed]
|
| 150 |
+
- **Compute Region:** [More Information Needed]
|
| 151 |
+
- **Carbon Emitted:** [More Information Needed]
|
| 152 |
+
|
| 153 |
+
## Technical Specifications [optional]
|
| 154 |
+
|
| 155 |
+
### Model Architecture and Objective
|
| 156 |
+
|
| 157 |
+
[More Information Needed]
|
| 158 |
+
|
| 159 |
+
### Compute Infrastructure
|
| 160 |
+
|
| 161 |
+
[More Information Needed]
|
| 162 |
+
|
| 163 |
+
#### Hardware
|
| 164 |
+
|
| 165 |
+
[More Information Needed]
|
| 166 |
+
|
| 167 |
+
#### Software
|
| 168 |
+
|
| 169 |
+
[More Information Needed]
|
| 170 |
+
|
| 171 |
+
## Citation [optional]
|
| 172 |
+
|
| 173 |
+
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
|
| 174 |
+
|
| 175 |
+
**BibTeX:**
|
| 176 |
+
|
| 177 |
+
[More Information Needed]
|
| 178 |
+
|
| 179 |
+
**APA:**
|
| 180 |
+
|
| 181 |
+
[More Information Needed]
|
| 182 |
+
|
| 183 |
+
## Glossary [optional]
|
| 184 |
+
|
| 185 |
+
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
|
| 186 |
+
|
| 187 |
+
[More Information Needed]
|
| 188 |
+
|
| 189 |
+
## More Information [optional]
|
| 190 |
+
|
| 191 |
+
[More Information Needed]
|
| 192 |
+
|
| 193 |
+
## Model Card Authors [optional]
|
| 194 |
+
|
| 195 |
+
[More Information Needed]
|
| 196 |
+
|
| 197 |
+
## Model Card Contact
|
| 198 |
+
|
| 199 |
+
[More Information Needed]
|
| 200 |
+
### Framework versions
|
| 201 |
+
|
| 202 |
+
- PEFT 0.12.0
|
checkpoint-45/adapter_config.json
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"alpha_pattern": {},
|
| 3 |
+
"auto_mapping": null,
|
| 4 |
+
"base_model_name_or_path": "/root/.cache/modelscope/hub/qwen/Qwen2-VL-7B-Instruct",
|
| 5 |
+
"bias": "none",
|
| 6 |
+
"fan_in_fan_out": false,
|
| 7 |
+
"inference_mode": true,
|
| 8 |
+
"init_lora_weights": true,
|
| 9 |
+
"layer_replication": null,
|
| 10 |
+
"layers_pattern": null,
|
| 11 |
+
"layers_to_transform": null,
|
| 12 |
+
"loftq_config": {},
|
| 13 |
+
"lora_alpha": 32,
|
| 14 |
+
"lora_dropout": 0.05,
|
| 15 |
+
"megatron_config": null,
|
| 16 |
+
"megatron_core": "megatron.core",
|
| 17 |
+
"modules_to_save": [],
|
| 18 |
+
"peft_type": "LORA",
|
| 19 |
+
"r": 8,
|
| 20 |
+
"rank_pattern": {},
|
| 21 |
+
"revision": null,
|
| 22 |
+
"target_modules": "^(model)(?!.*(lm_head|output|emb|wte|shared)).*",
|
| 23 |
+
"task_type": "CAUSAL_LM",
|
| 24 |
+
"use_dora": false,
|
| 25 |
+
"use_rslora": false
|
| 26 |
+
}
|
checkpoint-45/adapter_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0b24dad4ce65e32a16a510881666a4aa74fa48770db8d2b62a33b89c4d254c30
|
| 3 |
+
size 80792096
|
checkpoint-45/additional_config.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"lora_dtype": null, "lorap_lr_ratio": null, "lorap_emb_lr": 1e-06}
|
checkpoint-45/configuration.json
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"framework": "pytorch",
|
| 3 |
+
"task": "image-text-to-text",
|
| 4 |
+
"allow_remote": true,
|
| 5 |
+
"adapter_cfg": {
|
| 6 |
+
"model_id_or_path": "qwen/Qwen2-VL-7B-Instruct",
|
| 7 |
+
"model_revision": "master",
|
| 8 |
+
"sft_type": "lora",
|
| 9 |
+
"tuner_backend": "peft",
|
| 10 |
+
"template_type": "qwen2-vl",
|
| 11 |
+
"dtype": "bf16",
|
| 12 |
+
"system": "You are a helpful assistant."
|
| 13 |
+
}
|
| 14 |
+
}
|
checkpoint-45/generation_config.json
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token_id": 151643,
|
| 3 |
+
"do_sample": true,
|
| 4 |
+
"eos_token_id": 151645,
|
| 5 |
+
"max_new_tokens": 2048,
|
| 6 |
+
"pad_token_id": 151643,
|
| 7 |
+
"temperature": 0.01,
|
| 8 |
+
"top_k": 1,
|
| 9 |
+
"top_p": 0.001,
|
| 10 |
+
"transformers_version": "4.45.0.dev0"
|
| 11 |
+
}
|
checkpoint-45/optimizer.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:44696fdb374fb59a8a79d721c49d62887579b41b57b0ec18cede3d69f284529a
|
| 3 |
+
size 161810282
|
checkpoint-45/rng_state.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5ef27693e8c6e3e442c7ede4fb192233f1699444a12fc9bcac9d2639636e2f5e
|
| 3 |
+
size 14244
|
checkpoint-45/scheduler.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4e263c1ebbfad3b137dc95d038c7d450a9c91a9eea444a4a6b3bd99ae958ae3a
|
| 3 |
+
size 1064
|
checkpoint-45/sft_args.json
ADDED
|
@@ -0,0 +1,244 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"model_type": "qwen2-vl-7b-instruct",
|
| 3 |
+
"model_id_or_path": "qwen/Qwen2-VL-7B-Instruct",
|
| 4 |
+
"model_revision": "master",
|
| 5 |
+
"full_determinism": false,
|
| 6 |
+
"sft_type": "lora",
|
| 7 |
+
"freeze_parameters": [],
|
| 8 |
+
"freeze_vit": false,
|
| 9 |
+
"freeze_parameters_ratio": 0.0,
|
| 10 |
+
"additional_trainable_parameters": [],
|
| 11 |
+
"tuner_backend": "peft",
|
| 12 |
+
"template_type": "qwen2-vl",
|
| 13 |
+
"output_dir": "/content/output/qwen2-vl-7b-instruct/v2-20240909-100714",
|
| 14 |
+
"add_output_dir_suffix": true,
|
| 15 |
+
"ddp_backend": null,
|
| 16 |
+
"ddp_find_unused_parameters": null,
|
| 17 |
+
"ddp_broadcast_buffers": null,
|
| 18 |
+
"ddp_timeout": 1800,
|
| 19 |
+
"seed": 42,
|
| 20 |
+
"resume_from_checkpoint": null,
|
| 21 |
+
"resume_only_model": false,
|
| 22 |
+
"ignore_data_skip": false,
|
| 23 |
+
"dtype": "bf16",
|
| 24 |
+
"packing": false,
|
| 25 |
+
"train_backend": "transformers",
|
| 26 |
+
"tp": 1,
|
| 27 |
+
"pp": 1,
|
| 28 |
+
"min_lr": null,
|
| 29 |
+
"sequence_parallel": false,
|
| 30 |
+
"model_kwargs": null,
|
| 31 |
+
"loss_name": null,
|
| 32 |
+
"dataset": [
|
| 33 |
+
"/content/HebQwen.jsonl"
|
| 34 |
+
],
|
| 35 |
+
"val_dataset": [],
|
| 36 |
+
"dataset_seed": 42,
|
| 37 |
+
"dataset_test_ratio": 0.01,
|
| 38 |
+
"use_loss_scale": false,
|
| 39 |
+
"loss_scale_config_path": "/content/swift/swift/llm/agent/default_loss_scale_config.json",
|
| 40 |
+
"system": "You are a helpful assistant.",
|
| 41 |
+
"tools_prompt": "react_en",
|
| 42 |
+
"max_length": 2048,
|
| 43 |
+
"truncation_strategy": "delete",
|
| 44 |
+
"check_dataset_strategy": "none",
|
| 45 |
+
"streaming": false,
|
| 46 |
+
"streaming_val_size": 0,
|
| 47 |
+
"streaming_buffer_size": 16384,
|
| 48 |
+
"model_name": [
|
| 49 |
+
null,
|
| 50 |
+
null
|
| 51 |
+
],
|
| 52 |
+
"model_author": [
|
| 53 |
+
null,
|
| 54 |
+
null
|
| 55 |
+
],
|
| 56 |
+
"quant_method": null,
|
| 57 |
+
"quantization_bit": 0,
|
| 58 |
+
"hqq_axis": 0,
|
| 59 |
+
"hqq_dynamic_config_path": null,
|
| 60 |
+
"bnb_4bit_comp_dtype": "bf16",
|
| 61 |
+
"bnb_4bit_quant_type": "nf4",
|
| 62 |
+
"bnb_4bit_use_double_quant": true,
|
| 63 |
+
"bnb_4bit_quant_storage": null,
|
| 64 |
+
"rescale_image": -1,
|
| 65 |
+
"target_modules": "^(model)(?!.*(lm_head|output|emb|wte|shared)).*",
|
| 66 |
+
"target_regex": null,
|
| 67 |
+
"modules_to_save": [],
|
| 68 |
+
"lora_rank": 8,
|
| 69 |
+
"lora_alpha": 32,
|
| 70 |
+
"lora_dropout": 0.05,
|
| 71 |
+
"lora_bias_trainable": "none",
|
| 72 |
+
"lora_dtype": null,
|
| 73 |
+
"lora_lr_ratio": null,
|
| 74 |
+
"use_rslora": false,
|
| 75 |
+
"use_dora": false,
|
| 76 |
+
"init_lora_weights": true,
|
| 77 |
+
"fourier_n_frequency": 2000,
|
| 78 |
+
"fourier_scaling": 300.0,
|
| 79 |
+
"rope_scaling": null,
|
| 80 |
+
"boft_block_size": 4,
|
| 81 |
+
"boft_block_num": 0,
|
| 82 |
+
"boft_n_butterfly_factor": 1,
|
| 83 |
+
"boft_dropout": 0.0,
|
| 84 |
+
"vera_rank": 256,
|
| 85 |
+
"vera_projection_prng_key": 0,
|
| 86 |
+
"vera_dropout": 0.0,
|
| 87 |
+
"vera_d_initial": 0.1,
|
| 88 |
+
"adapter_act": "gelu",
|
| 89 |
+
"adapter_length": 128,
|
| 90 |
+
"use_galore": false,
|
| 91 |
+
"galore_target_modules": null,
|
| 92 |
+
"galore_rank": 128,
|
| 93 |
+
"galore_update_proj_gap": 50,
|
| 94 |
+
"galore_scale": 1.0,
|
| 95 |
+
"galore_proj_type": "std",
|
| 96 |
+
"galore_optim_per_parameter": false,
|
| 97 |
+
"galore_with_embedding": false,
|
| 98 |
+
"galore_quantization": false,
|
| 99 |
+
"galore_proj_quant": false,
|
| 100 |
+
"galore_proj_bits": 4,
|
| 101 |
+
"galore_proj_group_size": 256,
|
| 102 |
+
"galore_cos_threshold": 0.4,
|
| 103 |
+
"galore_gamma_proj": 2,
|
| 104 |
+
"galore_queue_size": 5,
|
| 105 |
+
"adalora_target_r": 8,
|
| 106 |
+
"adalora_init_r": 12,
|
| 107 |
+
"adalora_tinit": 0,
|
| 108 |
+
"adalora_tfinal": 0,
|
| 109 |
+
"adalora_deltaT": 1,
|
| 110 |
+
"adalora_beta1": 0.85,
|
| 111 |
+
"adalora_beta2": 0.85,
|
| 112 |
+
"adalora_orth_reg_weight": 0.5,
|
| 113 |
+
"ia3_feedforward_modules": [],
|
| 114 |
+
"llamapro_num_new_blocks": 4,
|
| 115 |
+
"llamapro_num_groups": null,
|
| 116 |
+
"neftune_noise_alpha": null,
|
| 117 |
+
"neftune_backend": "transformers",
|
| 118 |
+
"lisa_activated_layers": 0,
|
| 119 |
+
"lisa_step_interval": 20,
|
| 120 |
+
"reft_layer_key": null,
|
| 121 |
+
"reft_layers": null,
|
| 122 |
+
"reft_rank": 4,
|
| 123 |
+
"reft_intervention_type": "LoreftIntervention",
|
| 124 |
+
"reft_args": null,
|
| 125 |
+
"use_liger": false,
|
| 126 |
+
"gradient_checkpointing": true,
|
| 127 |
+
"deepspeed": null,
|
| 128 |
+
"batch_size": 1,
|
| 129 |
+
"eval_batch_size": 1,
|
| 130 |
+
"auto_find_batch_size": false,
|
| 131 |
+
"num_train_epochs": 1,
|
| 132 |
+
"max_steps": -1,
|
| 133 |
+
"optim": "adamw_torch",
|
| 134 |
+
"adam_beta1": 0.9,
|
| 135 |
+
"adam_beta2": 0.95,
|
| 136 |
+
"adam_epsilon": 1e-08,
|
| 137 |
+
"learning_rate": 0.0001,
|
| 138 |
+
"weight_decay": 0.1,
|
| 139 |
+
"gradient_accumulation_steps": 16,
|
| 140 |
+
"max_grad_norm": 1,
|
| 141 |
+
"predict_with_generate": false,
|
| 142 |
+
"lr_scheduler_type": "cosine",
|
| 143 |
+
"lr_scheduler_kwargs": {},
|
| 144 |
+
"warmup_ratio": 0.05,
|
| 145 |
+
"warmup_steps": 0,
|
| 146 |
+
"eval_steps": 50,
|
| 147 |
+
"save_steps": 50,
|
| 148 |
+
"save_only_model": false,
|
| 149 |
+
"save_total_limit": 2,
|
| 150 |
+
"logging_steps": 5,
|
| 151 |
+
"acc_steps": 1,
|
| 152 |
+
"dataloader_num_workers": 1,
|
| 153 |
+
"dataloader_pin_memory": true,
|
| 154 |
+
"dataloader_drop_last": false,
|
| 155 |
+
"push_to_hub": false,
|
| 156 |
+
"hub_model_id": null,
|
| 157 |
+
"hub_token": null,
|
| 158 |
+
"hub_private_repo": false,
|
| 159 |
+
"hub_strategy": "every_save",
|
| 160 |
+
"test_oom_error": false,
|
| 161 |
+
"disable_tqdm": false,
|
| 162 |
+
"lazy_tokenize": true,
|
| 163 |
+
"preprocess_num_proc": 1,
|
| 164 |
+
"use_flash_attn": null,
|
| 165 |
+
"ignore_args_error": false,
|
| 166 |
+
"check_model_is_latest": true,
|
| 167 |
+
"logging_dir": "/content/output/qwen2-vl-7b-instruct/v2-20240909-100714/runs",
|
| 168 |
+
"report_to": [
|
| 169 |
+
"tensorboard"
|
| 170 |
+
],
|
| 171 |
+
"acc_strategy": "token",
|
| 172 |
+
"save_on_each_node": false,
|
| 173 |
+
"evaluation_strategy": "steps",
|
| 174 |
+
"save_strategy": "steps",
|
| 175 |
+
"save_safetensors": true,
|
| 176 |
+
"gpu_memory_fraction": null,
|
| 177 |
+
"include_num_input_tokens_seen": false,
|
| 178 |
+
"local_repo_path": null,
|
| 179 |
+
"custom_register_path": null,
|
| 180 |
+
"custom_dataset_info": null,
|
| 181 |
+
"device_map_config": null,
|
| 182 |
+
"device_max_memory": [],
|
| 183 |
+
"max_new_tokens": 2048,
|
| 184 |
+
"do_sample": null,
|
| 185 |
+
"temperature": null,
|
| 186 |
+
"top_k": null,
|
| 187 |
+
"top_p": null,
|
| 188 |
+
"repetition_penalty": null,
|
| 189 |
+
"num_beams": 1,
|
| 190 |
+
"fsdp": "",
|
| 191 |
+
"fsdp_config": null,
|
| 192 |
+
"sequence_parallel_size": 1,
|
| 193 |
+
"model_layer_cls_name": null,
|
| 194 |
+
"metric_warmup_step": 0,
|
| 195 |
+
"fsdp_num": 1,
|
| 196 |
+
"per_device_train_batch_size": null,
|
| 197 |
+
"per_device_eval_batch_size": null,
|
| 198 |
+
"eval_strategy": null,
|
| 199 |
+
"self_cognition_sample": 0,
|
| 200 |
+
"train_dataset_mix_ratio": 0.0,
|
| 201 |
+
"train_dataset_mix_ds": [
|
| 202 |
+
"ms-bench"
|
| 203 |
+
],
|
| 204 |
+
"train_dataset_sample": -1,
|
| 205 |
+
"val_dataset_sample": null,
|
| 206 |
+
"safe_serialization": null,
|
| 207 |
+
"only_save_model": null,
|
| 208 |
+
"neftune_alpha": null,
|
| 209 |
+
"deepspeed_config_path": null,
|
| 210 |
+
"model_cache_dir": null,
|
| 211 |
+
"lora_dropout_p": null,
|
| 212 |
+
"lora_target_modules": [],
|
| 213 |
+
"lora_target_regex": null,
|
| 214 |
+
"lora_modules_to_save": [],
|
| 215 |
+
"boft_target_modules": [],
|
| 216 |
+
"boft_modules_to_save": [],
|
| 217 |
+
"vera_target_modules": [],
|
| 218 |
+
"vera_modules_to_save": [],
|
| 219 |
+
"ia3_target_modules": [],
|
| 220 |
+
"ia3_modules_to_save": [],
|
| 221 |
+
"custom_train_dataset_path": [],
|
| 222 |
+
"custom_val_dataset_path": [],
|
| 223 |
+
"device_map_config_path": null,
|
| 224 |
+
"push_hub_strategy": null,
|
| 225 |
+
"use_self_cognition": false,
|
| 226 |
+
"is_multimodal": true,
|
| 227 |
+
"is_vision": true,
|
| 228 |
+
"lora_use_embedding": false,
|
| 229 |
+
"lora_use_all": false,
|
| 230 |
+
"lora_m2s_use_embedding": false,
|
| 231 |
+
"lora_m2s_use_ln": false,
|
| 232 |
+
"torch_dtype": "torch.bfloat16",
|
| 233 |
+
"fp16": false,
|
| 234 |
+
"bf16": true,
|
| 235 |
+
"rank": -1,
|
| 236 |
+
"local_rank": -1,
|
| 237 |
+
"world_size": 1,
|
| 238 |
+
"local_world_size": 1,
|
| 239 |
+
"bnb_4bit_compute_dtype": "torch.bfloat16",
|
| 240 |
+
"load_in_4bit": false,
|
| 241 |
+
"load_in_8bit": false,
|
| 242 |
+
"train_sampler_random": true,
|
| 243 |
+
"training_args": "Seq2SeqTrainingArguments(output_dir='/content/output/qwen2-vl-7b-instruct/v2-20240909-100714', overwrite_output_dir=False, do_train=False, do_eval=True, do_predict=False, eval_strategy=<IntervalStrategy.STEPS: 'steps'>, prediction_loss_only=False, per_device_train_batch_size=1, per_device_eval_batch_size=1, per_gpu_train_batch_size=None, per_gpu_eval_batch_size=None, gradient_accumulation_steps=16, eval_accumulation_steps=None, eval_delay=0, torch_empty_cache_steps=None, learning_rate=0.0001, weight_decay=0.1, adam_beta1=0.9, adam_beta2=0.95, adam_epsilon=1e-08, max_grad_norm=1, num_train_epochs=1, max_steps=-1, lr_scheduler_type=<SchedulerType.COSINE: 'cosine'>, lr_scheduler_kwargs={}, warmup_ratio=0.05, warmup_steps=0, log_level='passive', log_level_replica='warning', log_on_each_node=True, logging_dir='/content/output/qwen2-vl-7b-instruct/v2-20240909-100714/runs', logging_strategy=<IntervalStrategy.STEPS: 'steps'>, logging_first_step=True, logging_steps=5, logging_nan_inf_filter=True, save_strategy=<IntervalStrategy.STEPS: 'steps'>, save_steps=50, save_total_limit=2, save_safetensors=True, save_on_each_node=False, save_only_model=False, restore_callback_states_from_checkpoint=False, no_cuda=False, use_cpu=False, use_mps_device=False, seed=42, data_seed=None, jit_mode_eval=False, use_ipex=False, bf16=True, fp16=False, fp16_opt_level='O1', half_precision_backend='auto', bf16_full_eval=False, fp16_full_eval=False, tf32=None, local_rank=0, ddp_backend=None, tpu_num_cores=None, tpu_metrics_debug=False, debug=[], dataloader_drop_last=False, eval_steps=50, dataloader_num_workers=1, dataloader_prefetch_factor=None, past_index=-1, run_name='/content/output/qwen2-vl-7b-instruct/v2-20240909-100714', disable_tqdm=False, remove_unused_columns=False, label_names=None, load_best_model_at_end=False, metric_for_best_model='loss', greater_is_better=False, ignore_data_skip=False, fsdp=[], fsdp_min_num_params=0, fsdp_config={'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}, fsdp_transformer_layer_cls_to_wrap=None, accelerator_config=AcceleratorConfig(split_batches=False, dispatch_batches=False, even_batches=True, use_seedable_sampler=True, non_blocking=False, gradient_accumulation_kwargs=None, use_configured_state=False), deepspeed=None, label_smoothing_factor=0.0, optim=<OptimizerNames.ADAMW_TORCH: 'adamw_torch'>, optim_args=None, adafactor=False, group_by_length=False, length_column_name='length', report_to=['tensorboard'], ddp_find_unused_parameters=None, ddp_bucket_cap_mb=None, ddp_broadcast_buffers=None, dataloader_pin_memory=True, dataloader_persistent_workers=False, skip_memory_metrics=True, use_legacy_prediction_loop=False, push_to_hub=False, resume_from_checkpoint=None, hub_model_id=None, hub_strategy=<HubStrategy.EVERY_SAVE: 'every_save'>, hub_token=None, hub_private_repo=False, hub_always_push=False, gradient_checkpointing=True, gradient_checkpointing_kwargs=None, include_inputs_for_metrics=False, eval_do_concat_batches=True, fp16_backend='auto', evaluation_strategy=None, push_to_hub_model_id=None, push_to_hub_organization=None, push_to_hub_token=None, mp_parameters='', auto_find_batch_size=False, full_determinism=False, torchdynamo=None, ray_scope='last', ddp_timeout=1800, torch_compile=False, torch_compile_backend=None, torch_compile_mode=None, dispatch_batches=None, split_batches=None, include_tokens_per_second=False, include_num_input_tokens_seen=False, neftune_noise_alpha=None, optim_target_modules=None, batch_eval_metrics=False, eval_on_start=False, use_liger_kernel=False, eval_use_gather_object=False, sortish_sampler=True, predict_with_generate=False, generation_max_length=None, generation_num_beams=None, generation_config=GenerationConfig {\n \"bos_token_id\": 151643,\n \"do_sample\": true,\n \"eos_token_id\": 151645,\n \"max_new_tokens\": 2048,\n \"pad_token_id\": 151643,\n \"temperature\": 0.01,\n \"top_k\": 1,\n \"top_p\": 0.001\n}\n, train_sampler_random=True, acc_strategy='token', loss_name=None, additional_saved_files=[], metric_warmup_step=0, train_dataset_sample=-1)"
|
| 244 |
+
}
|
checkpoint-45/trainer_state.json
ADDED
|
@@ -0,0 +1,142 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"best_metric": 0.50872844,
|
| 3 |
+
"best_model_checkpoint": "/content/output/qwen2-vl-7b-instruct/v2-20240909-100714/checkpoint-45",
|
| 4 |
+
"epoch": 0.993103448275862,
|
| 5 |
+
"eval_steps": 50,
|
| 6 |
+
"global_step": 45,
|
| 7 |
+
"is_hyper_param_search": false,
|
| 8 |
+
"is_local_process_zero": true,
|
| 9 |
+
"is_world_process_zero": true,
|
| 10 |
+
"log_history": [
|
| 11 |
+
{
|
| 12 |
+
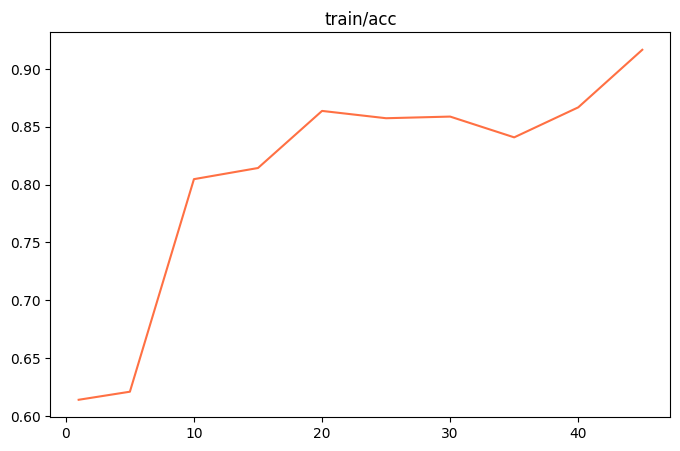
"acc": 0.61398816,
|
| 13 |
+
"epoch": 0.022068965517241378,
|
| 14 |
+
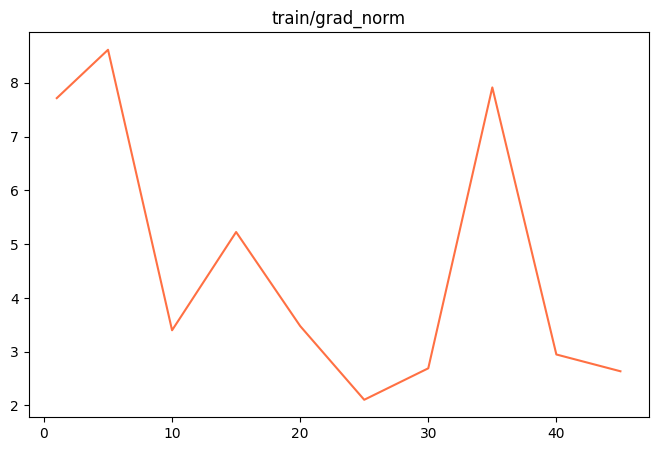
"grad_norm": 7.717197895050049,
|
| 15 |
+
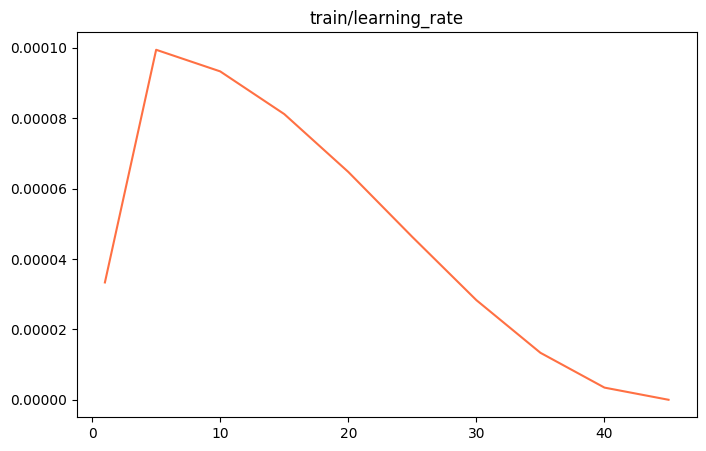
"learning_rate": 3.3333333333333335e-05,
|
| 16 |
+
"loss": 2.87438893,
|
| 17 |
+
"memory(GiB)": 20.29,
|
| 18 |
+
"step": 1,
|
| 19 |
+
"train_speed(iter/s)": 0.066629
|
| 20 |
+
},
|
| 21 |
+
{
|
| 22 |
+
"acc": 0.62096363,
|
| 23 |
+
"epoch": 0.1103448275862069,
|
| 24 |
+
"grad_norm": 8.616560935974121,
|
| 25 |
+
"learning_rate": 9.944154131125642e-05,
|
| 26 |
+
"loss": 2.60930538,
|
| 27 |
+
"memory(GiB)": 22.58,
|
| 28 |
+
"step": 5,
|
| 29 |
+
"train_speed(iter/s)": 0.075138
|
| 30 |
+
},
|
| 31 |
+
{
|
| 32 |
+
"acc": 0.80472717,
|
| 33 |
+
"epoch": 0.2206896551724138,
|
| 34 |
+
"grad_norm": 3.399202346801758,
|
| 35 |
+
"learning_rate": 9.330127018922194e-05,
|
| 36 |
+
"loss": 0.68508205,
|
| 37 |
+
"memory(GiB)": 23.35,
|
| 38 |
+
"step": 10,
|
| 39 |
+
"train_speed(iter/s)": 0.076348
|
| 40 |
+
},
|
| 41 |
+
{
|
| 42 |
+
"acc": 0.81436024,
|
| 43 |
+
"epoch": 0.3310344827586207,
|
| 44 |
+
"grad_norm": 5.226686477661133,
|
| 45 |
+
"learning_rate": 8.117449009293668e-05,
|
| 46 |
+
"loss": 0.69332366,
|
| 47 |
+
"memory(GiB)": 24.12,
|
| 48 |
+
"step": 15,
|
| 49 |
+
"train_speed(iter/s)": 0.076737
|
| 50 |
+
},
|
| 51 |
+
{
|
| 52 |
+
"acc": 0.86372032,
|
| 53 |
+
"epoch": 0.4413793103448276,
|
| 54 |
+
"grad_norm": 3.478239059448242,
|
| 55 |
+
"learning_rate": 6.473775872054521e-05,
|
| 56 |
+
"loss": 0.57136168,
|
| 57 |
+
"memory(GiB)": 24.12,
|
| 58 |
+
"step": 20,
|
| 59 |
+
"train_speed(iter/s)": 0.076946
|
| 60 |
+
},
|
| 61 |
+
{
|
| 62 |
+
"acc": 0.85740089,
|
| 63 |
+
"epoch": 0.5517241379310345,
|
| 64 |
+
"grad_norm": 2.1063661575317383,
|
| 65 |
+
"learning_rate": 4.626349532067879e-05,
|
| 66 |
+
"loss": 0.51958747,
|
| 67 |
+
"memory(GiB)": 24.91,
|
| 68 |
+
"step": 25,
|
| 69 |
+
"train_speed(iter/s)": 0.077061
|
| 70 |
+
},
|
| 71 |
+
{
|
| 72 |
+
"acc": 0.85881948,
|
| 73 |
+
"epoch": 0.6620689655172414,
|
| 74 |
+
"grad_norm": 2.6917998790740967,
|
| 75 |
+
"learning_rate": 2.8305813044122097e-05,
|
| 76 |
+
"loss": 0.51737795,
|
| 77 |
+
"memory(GiB)": 24.91,
|
| 78 |
+
"step": 30,
|
| 79 |
+
"train_speed(iter/s)": 0.077142
|
| 80 |
+
},
|
| 81 |
+
{
|
| 82 |
+
"acc": 0.84086313,
|
| 83 |
+
"epoch": 0.7724137931034483,
|
| 84 |
+
"grad_norm": 7.916348934173584,
|
| 85 |
+
"learning_rate": 1.3347406408508695e-05,
|
| 86 |
+
"loss": 0.72901492,
|
| 87 |
+
"memory(GiB)": 24.91,
|
| 88 |
+
"step": 35,
|
| 89 |
+
"train_speed(iter/s)": 0.077198
|
| 90 |
+
},
|
| 91 |
+
{
|
| 92 |
+
"acc": 0.86680059,
|
| 93 |
+
"epoch": 0.8827586206896552,
|
| 94 |
+
"grad_norm": 2.948944568634033,
|
| 95 |
+
"learning_rate": 3.4563125677897932e-06,
|
| 96 |
+
"loss": 0.43249173,
|
| 97 |
+
"memory(GiB)": 24.91,
|
| 98 |
+
"step": 40,
|
| 99 |
+
"train_speed(iter/s)": 0.077243
|
| 100 |
+
},
|
| 101 |
+
{
|
| 102 |
+
"acc": 0.91657734,
|
| 103 |
+
"epoch": 0.993103448275862,
|
| 104 |
+
"grad_norm": 2.6367099285125732,
|
| 105 |
+
"learning_rate": 0.0,
|
| 106 |
+
"loss": 0.34231672,
|
| 107 |
+
"memory(GiB)": 24.91,
|
| 108 |
+
"step": 45,
|
| 109 |
+
"train_speed(iter/s)": 0.077273
|
| 110 |
+
},
|
| 111 |
+
{
|
| 112 |
+
"epoch": 0.993103448275862,
|
| 113 |
+
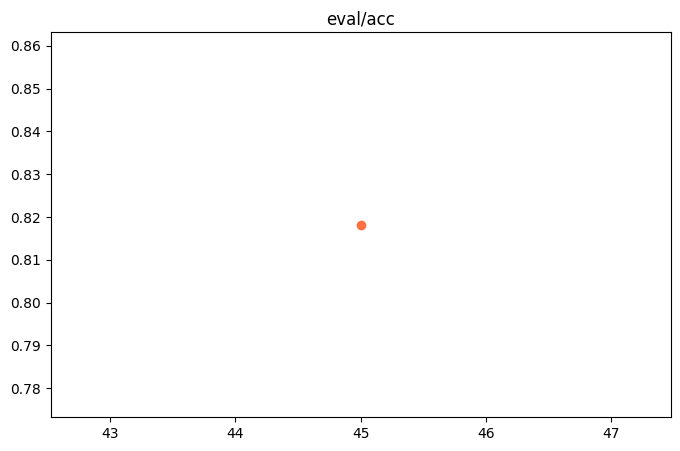
"eval_acc": 0.8181818181818182,
|
| 114 |
+
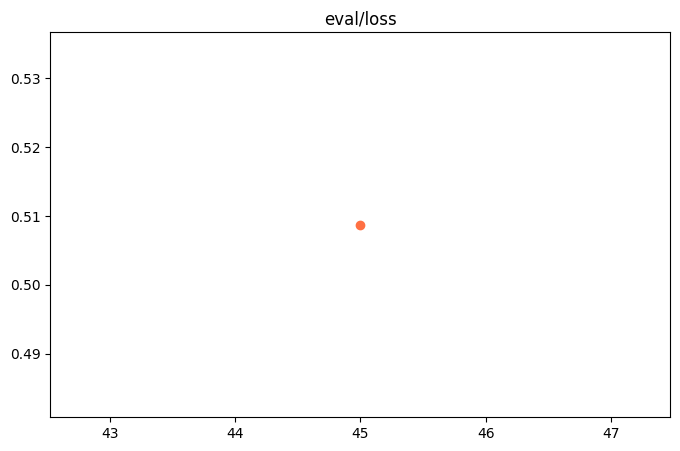
"eval_loss": 0.5087284445762634,
|
| 115 |
+
"eval_runtime": 3.4104,
|
| 116 |
+
"eval_samples_per_second": 2.053,
|
| 117 |
+
"eval_steps_per_second": 2.053,
|
| 118 |
+
"step": 45
|
| 119 |
+
}
|
| 120 |
+
],
|
| 121 |
+
"logging_steps": 5,
|
| 122 |
+
"max_steps": 45,
|
| 123 |
+
"num_input_tokens_seen": 0,
|
| 124 |
+
"num_train_epochs": 1,
|
| 125 |
+
"save_steps": 50,
|
| 126 |
+
"stateful_callbacks": {
|
| 127 |
+
"TrainerControl": {
|
| 128 |
+
"args": {
|
| 129 |
+
"should_epoch_stop": false,
|
| 130 |
+
"should_evaluate": false,
|
| 131 |
+
"should_log": false,
|
| 132 |
+
"should_save": true,
|
| 133 |
+
"should_training_stop": true
|
| 134 |
+
},
|
| 135 |
+
"attributes": {}
|
| 136 |
+
}
|
| 137 |
+
},
|
| 138 |
+
"total_flos": 4.488065503664026e+16,
|
| 139 |
+
"train_batch_size": 1,
|
| 140 |
+
"trial_name": null,
|
| 141 |
+
"trial_params": null
|
| 142 |
+
}
|
checkpoint-45/training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2c2508c7a374e9d5d3ede8c60e5ae128e7478c0510497c08865f6c3e3591a412
|
| 3 |
+
size 7288
|
images/eval_acc.png
ADDED
|
images/eval_loss.png
ADDED
|
images/eval_runtime.png
ADDED
|
images/eval_samples_per_second.png
ADDED
|
images/eval_steps_per_second.png
ADDED

|
images/train_acc.png
ADDED
|
images/train_epoch.png
ADDED
|
images/train_grad_norm.png
ADDED
|
images/train_learning_rate.png
ADDED
|
images/train_loss.png
ADDED
|
images/train_memory(GiB).png
ADDED
.png)
|
images/train_total_flos.png
ADDED
|
images/train_train_loss.png
ADDED
|
images/train_train_runtime.png
ADDED
|
images/train_train_samples_per_second.png
ADDED
|
images/train_train_speed(iter_s).png
ADDED
.png)
|
images/train_train_steps_per_second.png
ADDED
|
logging.jsonl
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"loss": 2.87438893, "acc": 0.61398816, "grad_norm": 7.7171979, "learning_rate": 3.333e-05, "memory(GiB)": 20.29, "train_speed(iter/s)": 0.066629, "epoch": 0.02206897, "global_step/max_steps": "1/45", "percentage": "2.22%", "elapsed_time": "14s", "remaining_time": "10m 38s"}
|
| 2 |
+
{"loss": 2.60930538, "acc": 0.62096363, "grad_norm": 8.61656094, "learning_rate": 9.944e-05, "memory(GiB)": 22.58, "train_speed(iter/s)": 0.075138, "epoch": 0.11034483, "global_step/max_steps": "5/45", "percentage": "11.11%", "elapsed_time": "1m 6s", "remaining_time": "8m 48s"}
|
| 3 |
+
{"loss": 0.68508205, "acc": 0.80472717, "grad_norm": 3.39920235, "learning_rate": 9.33e-05, "memory(GiB)": 23.35, "train_speed(iter/s)": 0.076348, "epoch": 0.22068966, "global_step/max_steps": "10/45", "percentage": "22.22%", "elapsed_time": "2m 10s", "remaining_time": "7m 36s"}
|
| 4 |
+
{"loss": 0.69332366, "acc": 0.81436024, "grad_norm": 5.22668648, "learning_rate": 8.117e-05, "memory(GiB)": 24.12, "train_speed(iter/s)": 0.076737, "epoch": 0.33103448, "global_step/max_steps": "15/45", "percentage": "33.33%", "elapsed_time": "3m 14s", "remaining_time": "6m 29s"}
|
| 5 |
+
{"loss": 0.57136168, "acc": 0.86372032, "grad_norm": 3.47823906, "learning_rate": 6.474e-05, "memory(GiB)": 24.12, "train_speed(iter/s)": 0.076946, "epoch": 0.44137931, "global_step/max_steps": "20/45", "percentage": "44.44%", "elapsed_time": "4m 19s", "remaining_time": "5m 24s"}
|
| 6 |
+
{"loss": 0.51958747, "acc": 0.85740089, "grad_norm": 2.10636616, "learning_rate": 4.626e-05, "memory(GiB)": 24.91, "train_speed(iter/s)": 0.077061, "epoch": 0.55172414, "global_step/max_steps": "25/45", "percentage": "55.56%", "elapsed_time": "5m 23s", "remaining_time": "4m 19s"}
|
| 7 |
+
{"loss": 0.51737795, "acc": 0.85881948, "grad_norm": 2.69179988, "learning_rate": 2.831e-05, "memory(GiB)": 24.91, "train_speed(iter/s)": 0.077142, "epoch": 0.66206897, "global_step/max_steps": "30/45", "percentage": "66.67%", "elapsed_time": "6m 28s", "remaining_time": "3m 14s"}
|
| 8 |
+
{"loss": 0.72901492, "acc": 0.84086313, "grad_norm": 7.91634893, "learning_rate": 1.335e-05, "memory(GiB)": 24.91, "train_speed(iter/s)": 0.077198, "epoch": 0.77241379, "global_step/max_steps": "35/45", "percentage": "77.78%", "elapsed_time": "7m 32s", "remaining_time": "2m 9s"}
|
| 9 |
+
{"loss": 0.43249173, "acc": 0.86680059, "grad_norm": 2.94894457, "learning_rate": 3.46e-06, "memory(GiB)": 24.91, "train_speed(iter/s)": 0.077243, "epoch": 0.88275862, "global_step/max_steps": "40/45", "percentage": "88.89%", "elapsed_time": "8m 37s", "remaining_time": "1m 4s"}
|
| 10 |
+
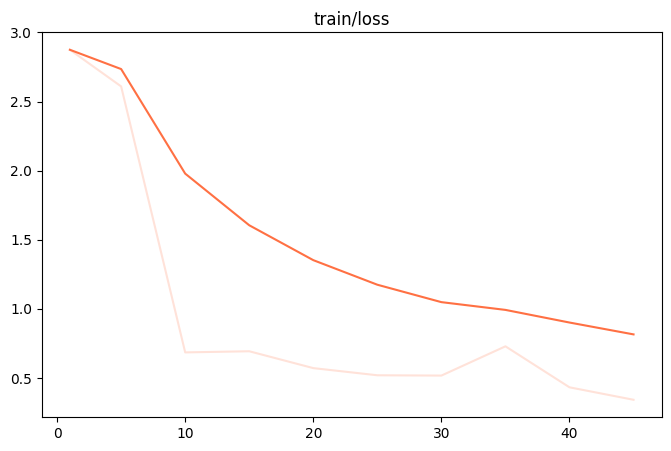
{"loss": 0.34231672, "acc": 0.91657734, "grad_norm": 2.63670993, "learning_rate": 0.0, "memory(GiB)": 24.91, "train_speed(iter/s)": 0.077273, "epoch": 0.99310345, "global_step/max_steps": "45/45", "percentage": "100.00%", "elapsed_time": "9m 41s", "remaining_time": "0s"}
|
| 11 |
+
{"eval_loss": 0.50872844, "eval_acc": 0.81818182, "eval_runtime": 3.4104, "eval_samples_per_second": 2.053, "eval_steps_per_second": 2.053, "epoch": 0.99310345, "global_step/max_steps": "45/45", "percentage": "100.00%", "elapsed_time": "9m 45s", "remaining_time": "0s"}
|
| 12 |
+
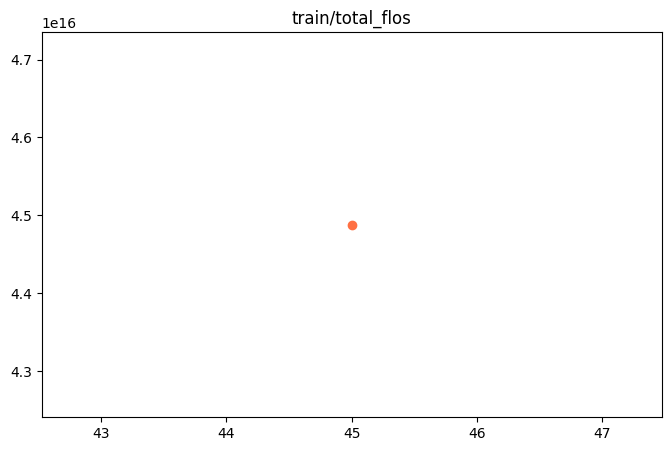
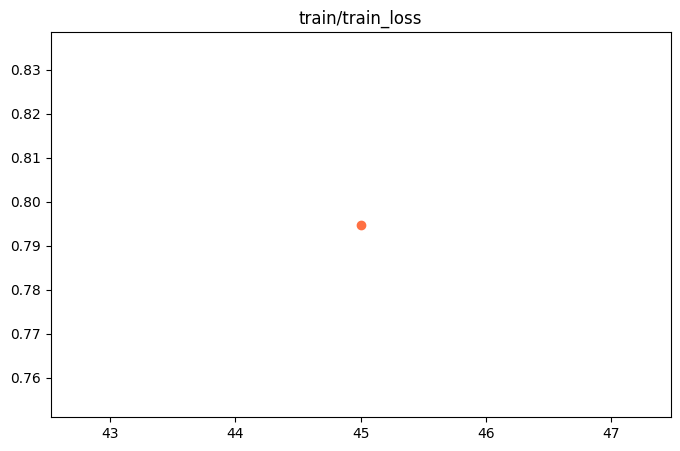
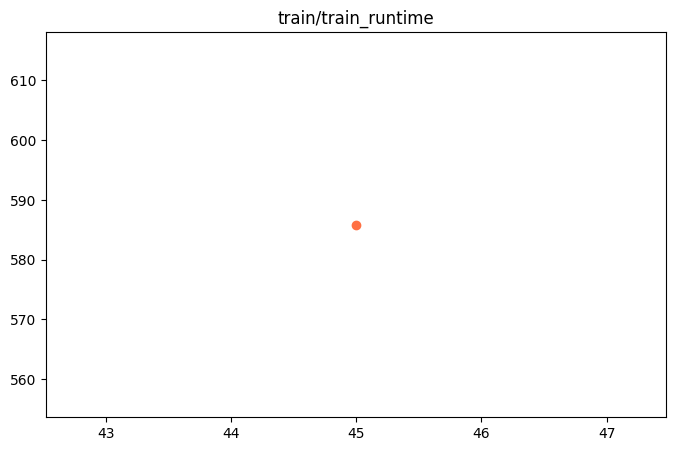
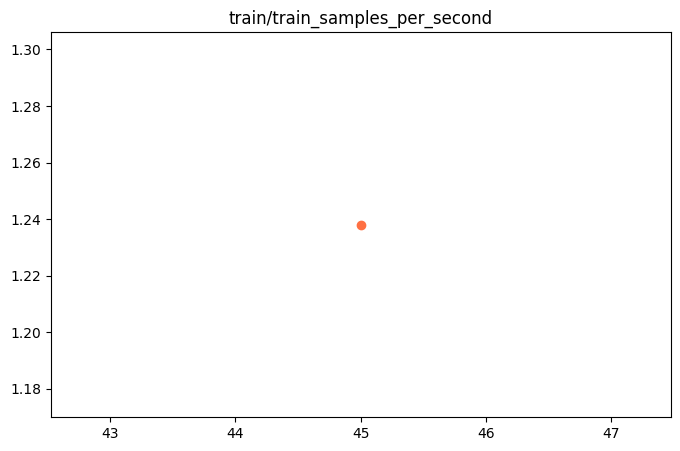
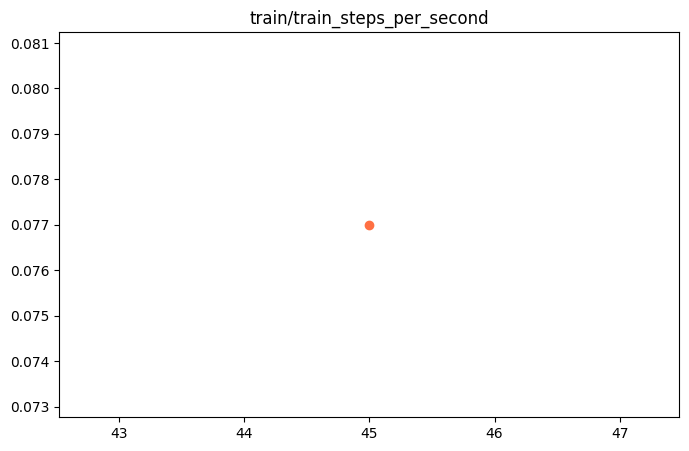
{"train_runtime": 585.8499, "train_samples_per_second": 1.238, "train_steps_per_second": 0.077, "total_flos": 4.488065503664026e+16, "train_loss": 0.79476425, "epoch": 0.99310345, "global_step/max_steps": "45/45", "percentage": "100.00%", "elapsed_time": "9m 45s", "remaining_time": "0s"}
|
| 13 |
+
{"memory": {"cuda": "24.91GiB"}, "last_model_checkpoint": "/content/output/qwen2-vl-7b-instruct/v2-20240909-100714/checkpoint-45", "best_model_checkpoint": "/content/output/qwen2-vl-7b-instruct/v2-20240909-100714/checkpoint-45", "best_metric": 0.50872844, "global_step": 45, "log_history": [{"loss": 2.87438893, "acc": 0.61398816, "grad_norm": 7.717197895050049, "learning_rate": 3.3333333333333335e-05, "memory(GiB)": 20.29, "train_speed(iter/s)": 0.066629, "epoch": 0.022068965517241378, "step": 1}, {"loss": 2.60930538, "acc": 0.62096363, "grad_norm": 8.616560935974121, "learning_rate": 9.944154131125642e-05, "memory(GiB)": 22.58, "train_speed(iter/s)": 0.075138, "epoch": 0.1103448275862069, "step": 5}, {"loss": 0.68508205, "acc": 0.80472717, "grad_norm": 3.399202346801758, "learning_rate": 9.330127018922194e-05, "memory(GiB)": 23.35, "train_speed(iter/s)": 0.076348, "epoch": 0.2206896551724138, "step": 10}, {"loss": 0.69332366, "acc": 0.81436024, "grad_norm": 5.226686477661133, "learning_rate": 8.117449009293668e-05, "memory(GiB)": 24.12, "train_speed(iter/s)": 0.076737, "epoch": 0.3310344827586207, "step": 15}, {"loss": 0.57136168, "acc": 0.86372032, "grad_norm": 3.478239059448242, "learning_rate": 6.473775872054521e-05, "memory(GiB)": 24.12, "train_speed(iter/s)": 0.076946, "epoch": 0.4413793103448276, "step": 20}, {"loss": 0.51958747, "acc": 0.85740089, "grad_norm": 2.1063661575317383, "learning_rate": 4.626349532067879e-05, "memory(GiB)": 24.91, "train_speed(iter/s)": 0.077061, "epoch": 0.5517241379310345, "step": 25}, {"loss": 0.51737795, "acc": 0.85881948, "grad_norm": 2.6917998790740967, "learning_rate": 2.8305813044122097e-05, "memory(GiB)": 24.91, "train_speed(iter/s)": 0.077142, "epoch": 0.6620689655172414, "step": 30}, {"loss": 0.72901492, "acc": 0.84086313, "grad_norm": 7.916348934173584, "learning_rate": 1.3347406408508695e-05, "memory(GiB)": 24.91, "train_speed(iter/s)": 0.077198, "epoch": 0.7724137931034483, "step": 35}, {"loss": 0.43249173, "acc": 0.86680059, "grad_norm": 2.948944568634033, "learning_rate": 3.4563125677897932e-06, "memory(GiB)": 24.91, "train_speed(iter/s)": 0.077243, "epoch": 0.8827586206896552, "step": 40}, {"loss": 0.34231672, "acc": 0.91657734, "grad_norm": 2.6367099285125732, "learning_rate": 0.0, "memory(GiB)": 24.91, "train_speed(iter/s)": 0.077273, "epoch": 0.993103448275862, "step": 45}, {"eval_loss": 0.5087284445762634, "eval_acc": 0.8181818181818182, "eval_runtime": 3.4104, "eval_samples_per_second": 2.053, "eval_steps_per_second": 2.053, "epoch": 0.993103448275862, "step": 45}, {"train_runtime": 585.8499, "train_samples_per_second": 1.238, "train_steps_per_second": 0.077, "total_flos": 4.488065503664026e+16, "train_loss": 0.7947642538282607, "epoch": 0.993103448275862, "step": 45}], "model_info": "PeftModelForCausalLM: 8311.5607M Params (20.1851M Trainable [0.2429%]), 0.0019M Buffers.", "dataset_info": null, "train_time": {"train_runtime": 585.8499, "n_train_samples": 725, "train_samples_per_second": 1.2375183472763245}}
|
runs/events.out.tfevents.1725876447.8e952411ac7f.14553.0
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b1e57eafa0306c03db3b7cc3ba4bf4ff599a994f44cb3a38480e8f860ce128a7
|
| 3 |
+
size 12057
|
sft_args.json
ADDED
|
@@ -0,0 +1,244 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"model_type": "qwen2-vl-7b-instruct",
|
| 3 |
+
"model_id_or_path": "qwen/Qwen2-VL-7B-Instruct",
|
| 4 |
+
"model_revision": "master",
|
| 5 |
+
"full_determinism": false,
|
| 6 |
+
"sft_type": "lora",
|
| 7 |
+
"freeze_parameters": [],
|
| 8 |
+
"freeze_vit": false,
|
| 9 |
+
"freeze_parameters_ratio": 0.0,
|
| 10 |
+
"additional_trainable_parameters": [],
|
| 11 |
+
"tuner_backend": "peft",
|
| 12 |
+
"template_type": "qwen2-vl",
|
| 13 |
+
"output_dir": "/content/output/qwen2-vl-7b-instruct/v2-20240909-100714",
|
| 14 |
+
"add_output_dir_suffix": true,
|
| 15 |
+
"ddp_backend": null,
|
| 16 |
+
"ddp_find_unused_parameters": null,
|
| 17 |
+
"ddp_broadcast_buffers": null,
|
| 18 |
+
"ddp_timeout": 1800,
|
| 19 |
+
"seed": 42,
|
| 20 |
+
"resume_from_checkpoint": null,
|
| 21 |
+
"resume_only_model": false,
|
| 22 |
+
"ignore_data_skip": false,
|
| 23 |
+
"dtype": "bf16",
|
| 24 |
+
"packing": false,
|
| 25 |
+
"train_backend": "transformers",
|
| 26 |
+
"tp": 1,
|
| 27 |
+
"pp": 1,
|
| 28 |
+
"min_lr": null,
|
| 29 |
+
"sequence_parallel": false,
|
| 30 |
+
"model_kwargs": null,
|
| 31 |
+
"loss_name": null,
|
| 32 |
+
"dataset": [
|
| 33 |
+
"/content/HebQwen.jsonl"
|
| 34 |
+
],
|
| 35 |
+
"val_dataset": [],
|
| 36 |
+
"dataset_seed": 42,
|
| 37 |
+
"dataset_test_ratio": 0.01,
|
| 38 |
+
"use_loss_scale": false,
|
| 39 |
+
"loss_scale_config_path": "/content/swift/swift/llm/agent/default_loss_scale_config.json",
|
| 40 |
+
"system": "You are a helpful assistant.",
|
| 41 |
+
"tools_prompt": "react_en",
|
| 42 |
+
"max_length": 2048,
|
| 43 |
+
"truncation_strategy": "delete",
|
| 44 |
+
"check_dataset_strategy": "none",
|
| 45 |
+
"streaming": false,
|
| 46 |
+
"streaming_val_size": 0,
|
| 47 |
+
"streaming_buffer_size": 16384,
|
| 48 |
+
"model_name": [
|
| 49 |
+
null,
|
| 50 |
+
null
|
| 51 |
+
],
|
| 52 |
+
"model_author": [
|
| 53 |
+
null,
|
| 54 |
+
null
|
| 55 |
+
],
|
| 56 |
+
"quant_method": null,
|
| 57 |
+
"quantization_bit": 0,
|
| 58 |
+
"hqq_axis": 0,
|
| 59 |
+
"hqq_dynamic_config_path": null,
|
| 60 |
+
"bnb_4bit_comp_dtype": "bf16",
|
| 61 |
+
"bnb_4bit_quant_type": "nf4",
|
| 62 |
+
"bnb_4bit_use_double_quant": true,
|
| 63 |
+
"bnb_4bit_quant_storage": null,
|
| 64 |
+
"rescale_image": -1,
|
| 65 |
+
"target_modules": "^(model)(?!.*(lm_head|output|emb|wte|shared)).*",
|
| 66 |
+
"target_regex": null,
|
| 67 |
+
"modules_to_save": [],
|
| 68 |
+
"lora_rank": 8,
|
| 69 |
+
"lora_alpha": 32,
|
| 70 |
+
"lora_dropout": 0.05,
|
| 71 |
+
"lora_bias_trainable": "none",
|
| 72 |
+
"lora_dtype": null,
|
| 73 |
+
"lora_lr_ratio": null,
|
| 74 |
+
"use_rslora": false,
|
| 75 |
+
"use_dora": false,
|
| 76 |
+
"init_lora_weights": true,
|
| 77 |
+
"fourier_n_frequency": 2000,
|
| 78 |
+
"fourier_scaling": 300.0,
|
| 79 |
+
"rope_scaling": null,
|
| 80 |
+
"boft_block_size": 4,
|
| 81 |
+
"boft_block_num": 0,
|
| 82 |
+
"boft_n_butterfly_factor": 1,
|
| 83 |
+
"boft_dropout": 0.0,
|
| 84 |
+
"vera_rank": 256,
|
| 85 |
+
"vera_projection_prng_key": 0,
|
| 86 |
+
"vera_dropout": 0.0,
|
| 87 |
+
"vera_d_initial": 0.1,
|
| 88 |
+
"adapter_act": "gelu",
|
| 89 |
+
"adapter_length": 128,
|
| 90 |
+
"use_galore": false,
|
| 91 |
+
"galore_target_modules": null,
|
| 92 |
+
"galore_rank": 128,
|
| 93 |
+
"galore_update_proj_gap": 50,
|
| 94 |
+
"galore_scale": 1.0,
|
| 95 |
+
"galore_proj_type": "std",
|
| 96 |
+
"galore_optim_per_parameter": false,
|
| 97 |
+
"galore_with_embedding": false,
|
| 98 |
+
"galore_quantization": false,
|
| 99 |
+
"galore_proj_quant": false,
|
| 100 |
+
"galore_proj_bits": 4,
|
| 101 |
+
"galore_proj_group_size": 256,
|
| 102 |
+
"galore_cos_threshold": 0.4,
|
| 103 |
+
"galore_gamma_proj": 2,
|
| 104 |
+
"galore_queue_size": 5,
|
| 105 |
+
"adalora_target_r": 8,
|
| 106 |
+
"adalora_init_r": 12,
|
| 107 |
+
"adalora_tinit": 0,
|
| 108 |
+
"adalora_tfinal": 0,
|
| 109 |
+
"adalora_deltaT": 1,
|
| 110 |
+
"adalora_beta1": 0.85,
|
| 111 |
+
"adalora_beta2": 0.85,
|
| 112 |
+
"adalora_orth_reg_weight": 0.5,
|
| 113 |
+
"ia3_feedforward_modules": [],
|
| 114 |
+
"llamapro_num_new_blocks": 4,
|
| 115 |
+
"llamapro_num_groups": null,
|
| 116 |
+
"neftune_noise_alpha": null,
|
| 117 |
+
"neftune_backend": "transformers",
|
| 118 |
+
"lisa_activated_layers": 0,
|
| 119 |
+
"lisa_step_interval": 20,
|
| 120 |
+
"reft_layer_key": null,
|
| 121 |
+
"reft_layers": null,
|
| 122 |
+
"reft_rank": 4,
|
| 123 |
+
"reft_intervention_type": "LoreftIntervention",
|
| 124 |
+
"reft_args": null,
|
| 125 |
+
"use_liger": false,
|
| 126 |
+
"gradient_checkpointing": true,
|
| 127 |
+
"deepspeed": null,
|
| 128 |
+
"batch_size": 1,
|
| 129 |
+
"eval_batch_size": 1,
|
| 130 |
+
"auto_find_batch_size": false,
|
| 131 |
+
"num_train_epochs": 1,
|
| 132 |
+
"max_steps": -1,
|
| 133 |
+
"optim": "adamw_torch",
|
| 134 |
+
"adam_beta1": 0.9,
|
| 135 |
+
"adam_beta2": 0.95,
|
| 136 |
+
"adam_epsilon": 1e-08,
|
| 137 |
+
"learning_rate": 0.0001,
|
| 138 |
+
"weight_decay": 0.1,
|
| 139 |
+
"gradient_accumulation_steps": 16,
|
| 140 |
+
"max_grad_norm": 1,
|
| 141 |
+
"predict_with_generate": false,
|
| 142 |
+
"lr_scheduler_type": "cosine",
|
| 143 |
+
"lr_scheduler_kwargs": {},
|
| 144 |
+
"warmup_ratio": 0.05,
|
| 145 |
+
"warmup_steps": 0,
|
| 146 |
+
"eval_steps": 50,
|
| 147 |
+
"save_steps": 50,
|
| 148 |
+
"save_only_model": false,
|
| 149 |
+
"save_total_limit": 2,
|
| 150 |
+
"logging_steps": 5,
|
| 151 |
+
"acc_steps": 1,
|
| 152 |
+
"dataloader_num_workers": 1,
|
| 153 |
+
"dataloader_pin_memory": true,
|
| 154 |
+
"dataloader_drop_last": false,
|
| 155 |
+
"push_to_hub": false,
|
| 156 |
+
"hub_model_id": null,
|
| 157 |
+
"hub_token": null,
|
| 158 |
+
"hub_private_repo": false,
|
| 159 |
+
"hub_strategy": "every_save",
|
| 160 |
+
"test_oom_error": false,
|
| 161 |
+
"disable_tqdm": false,
|
| 162 |
+
"lazy_tokenize": true,
|
| 163 |
+
"preprocess_num_proc": 1,
|
| 164 |
+
"use_flash_attn": null,
|
| 165 |
+
"ignore_args_error": false,
|
| 166 |
+
"check_model_is_latest": true,
|
| 167 |
+
"logging_dir": "/content/output/qwen2-vl-7b-instruct/v2-20240909-100714/runs",
|
| 168 |
+
"report_to": [
|
| 169 |
+
"tensorboard"
|
| 170 |
+
],
|
| 171 |
+
"acc_strategy": "token",
|
| 172 |
+
"save_on_each_node": false,
|
| 173 |
+
"evaluation_strategy": "steps",
|
| 174 |
+
"save_strategy": "steps",
|
| 175 |
+
"save_safetensors": true,
|
| 176 |
+
"gpu_memory_fraction": null,
|
| 177 |
+
"include_num_input_tokens_seen": false,
|
| 178 |
+
"local_repo_path": null,
|
| 179 |
+
"custom_register_path": null,
|
| 180 |
+
"custom_dataset_info": null,
|
| 181 |
+
"device_map_config": null,
|
| 182 |
+
"device_max_memory": [],
|
| 183 |
+
"max_new_tokens": 2048,
|
| 184 |
+
"do_sample": null,
|
| 185 |
+
"temperature": null,
|
| 186 |
+
"top_k": null,
|
| 187 |
+
"top_p": null,
|
| 188 |
+
"repetition_penalty": null,
|
| 189 |
+
"num_beams": 1,
|
| 190 |
+
"fsdp": "",
|
| 191 |
+
"fsdp_config": null,
|
| 192 |
+
"sequence_parallel_size": 1,
|
| 193 |
+
"model_layer_cls_name": null,
|
| 194 |
+
"metric_warmup_step": 0,
|
| 195 |
+
"fsdp_num": 1,
|
| 196 |
+
"per_device_train_batch_size": null,
|
| 197 |
+
"per_device_eval_batch_size": null,
|
| 198 |
+
"eval_strategy": null,
|
| 199 |
+
"self_cognition_sample": 0,
|
| 200 |
+
"train_dataset_mix_ratio": 0.0,
|
| 201 |
+
"train_dataset_mix_ds": [
|
| 202 |
+
"ms-bench"
|
| 203 |
+
],
|
| 204 |
+
"train_dataset_sample": -1,
|
| 205 |
+
"val_dataset_sample": null,
|
| 206 |
+
"safe_serialization": null,
|
| 207 |
+
"only_save_model": null,
|
| 208 |
+
"neftune_alpha": null,
|
| 209 |
+
"deepspeed_config_path": null,
|
| 210 |
+
"model_cache_dir": null,
|
| 211 |
+
"lora_dropout_p": null,
|
| 212 |
+
"lora_target_modules": [],
|
| 213 |
+
"lora_target_regex": null,
|
| 214 |
+
"lora_modules_to_save": [],
|
| 215 |
+
"boft_target_modules": [],
|
| 216 |
+
"boft_modules_to_save": [],
|
| 217 |
+
"vera_target_modules": [],
|
| 218 |
+
"vera_modules_to_save": [],
|
| 219 |
+
"ia3_target_modules": [],
|
| 220 |
+
"ia3_modules_to_save": [],
|
| 221 |
+
"custom_train_dataset_path": [],
|
| 222 |
+
"custom_val_dataset_path": [],
|
| 223 |
+
"device_map_config_path": null,
|
| 224 |
+
"push_hub_strategy": null,
|
| 225 |
+
"use_self_cognition": false,
|
| 226 |
+
"is_multimodal": true,
|
| 227 |
+
"is_vision": true,
|
| 228 |
+
"lora_use_embedding": false,
|
| 229 |
+
"lora_use_all": false,
|
| 230 |
+
"lora_m2s_use_embedding": false,
|
| 231 |
+
"lora_m2s_use_ln": false,
|
| 232 |
+
"torch_dtype": "torch.bfloat16",
|
| 233 |
+
"fp16": false,
|
| 234 |
+
"bf16": true,
|
| 235 |
+
"rank": -1,
|
| 236 |
+
"local_rank": -1,
|
| 237 |
+
"world_size": 1,
|
| 238 |
+
"local_world_size": 1,
|
| 239 |
+
"bnb_4bit_compute_dtype": "torch.bfloat16",
|
| 240 |
+
"load_in_4bit": false,
|
| 241 |
+
"load_in_8bit": false,
|
| 242 |
+
"train_sampler_random": true,
|
| 243 |
+
"training_args": "Seq2SeqTrainingArguments(output_dir='/content/output/qwen2-vl-7b-instruct/v2-20240909-100714', overwrite_output_dir=False, do_train=False, do_eval=True, do_predict=False, eval_strategy=<IntervalStrategy.STEPS: 'steps'>, prediction_loss_only=False, per_device_train_batch_size=1, per_device_eval_batch_size=1, per_gpu_train_batch_size=None, per_gpu_eval_batch_size=None, gradient_accumulation_steps=16, eval_accumulation_steps=None, eval_delay=0, torch_empty_cache_steps=None, learning_rate=0.0001, weight_decay=0.1, adam_beta1=0.9, adam_beta2=0.95, adam_epsilon=1e-08, max_grad_norm=1, num_train_epochs=1, max_steps=-1, lr_scheduler_type=<SchedulerType.COSINE: 'cosine'>, lr_scheduler_kwargs={}, warmup_ratio=0.05, warmup_steps=0, log_level='passive', log_level_replica='warning', log_on_each_node=True, logging_dir='/content/output/qwen2-vl-7b-instruct/v2-20240909-100714/runs', logging_strategy=<IntervalStrategy.STEPS: 'steps'>, logging_first_step=True, logging_steps=5, logging_nan_inf_filter=True, save_strategy=<IntervalStrategy.STEPS: 'steps'>, save_steps=50, save_total_limit=2, save_safetensors=True, save_on_each_node=False, save_only_model=False, restore_callback_states_from_checkpoint=False, no_cuda=False, use_cpu=False, use_mps_device=False, seed=42, data_seed=None, jit_mode_eval=False, use_ipex=False, bf16=True, fp16=False, fp16_opt_level='O1', half_precision_backend='auto', bf16_full_eval=False, fp16_full_eval=False, tf32=None, local_rank=0, ddp_backend=None, tpu_num_cores=None, tpu_metrics_debug=False, debug=[], dataloader_drop_last=False, eval_steps=50, dataloader_num_workers=1, dataloader_prefetch_factor=None, past_index=-1, run_name='/content/output/qwen2-vl-7b-instruct/v2-20240909-100714', disable_tqdm=False, remove_unused_columns=False, label_names=None, load_best_model_at_end=False, metric_for_best_model='loss', greater_is_better=False, ignore_data_skip=False, fsdp=[], fsdp_min_num_params=0, fsdp_config={'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}, fsdp_transformer_layer_cls_to_wrap=None, accelerator_config=AcceleratorConfig(split_batches=False, dispatch_batches=False, even_batches=True, use_seedable_sampler=True, non_blocking=False, gradient_accumulation_kwargs=None, use_configured_state=False), deepspeed=None, label_smoothing_factor=0.0, optim=<OptimizerNames.ADAMW_TORCH: 'adamw_torch'>, optim_args=None, adafactor=False, group_by_length=False, length_column_name='length', report_to=['tensorboard'], ddp_find_unused_parameters=None, ddp_bucket_cap_mb=None, ddp_broadcast_buffers=None, dataloader_pin_memory=True, dataloader_persistent_workers=False, skip_memory_metrics=True, use_legacy_prediction_loop=False, push_to_hub=False, resume_from_checkpoint=None, hub_model_id=None, hub_strategy=<HubStrategy.EVERY_SAVE: 'every_save'>, hub_token=None, hub_private_repo=False, hub_always_push=False, gradient_checkpointing=True, gradient_checkpointing_kwargs=None, include_inputs_for_metrics=False, eval_do_concat_batches=True, fp16_backend='auto', evaluation_strategy=None, push_to_hub_model_id=None, push_to_hub_organization=None, push_to_hub_token=None, mp_parameters='', auto_find_batch_size=False, full_determinism=False, torchdynamo=None, ray_scope='last', ddp_timeout=1800, torch_compile=False, torch_compile_backend=None, torch_compile_mode=None, dispatch_batches=None, split_batches=None, include_tokens_per_second=False, include_num_input_tokens_seen=False, neftune_noise_alpha=None, optim_target_modules=None, batch_eval_metrics=False, eval_on_start=False, use_liger_kernel=False, eval_use_gather_object=False, sortish_sampler=True, predict_with_generate=False, generation_max_length=None, generation_num_beams=None, generation_config=GenerationConfig {\n \"bos_token_id\": 151643,\n \"do_sample\": true,\n \"eos_token_id\": 151645,\n \"max_new_tokens\": 2048,\n \"pad_token_id\": 151643,\n \"temperature\": 0.01,\n \"top_k\": 1,\n \"top_p\": 0.001\n}\n, train_sampler_random=True, acc_strategy='token', loss_name=None, additional_saved_files=[], metric_warmup_step=0, train_dataset_sample=-1)"
|
| 244 |
+
}
|
training_args.json
ADDED
|
@@ -0,0 +1,153 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"output_dir": "/content/output/qwen2-vl-7b-instruct/v2-20240909-100714",
|
| 3 |
+
"overwrite_output_dir": false,
|
| 4 |
+
"do_train": false,
|
| 5 |
+
"do_eval": true,
|
| 6 |
+
"do_predict": false,
|
| 7 |
+
"eval_strategy": "steps",
|
| 8 |
+
"prediction_loss_only": false,
|
| 9 |
+
"per_device_train_batch_size": 1,
|
| 10 |
+
"per_device_eval_batch_size": 1,
|
| 11 |
+
"per_gpu_train_batch_size": null,
|
| 12 |
+
"per_gpu_eval_batch_size": null,
|
| 13 |
+
"gradient_accumulation_steps": 16,
|
| 14 |
+
"eval_accumulation_steps": null,
|
| 15 |
+
"eval_delay": 0,
|
| 16 |
+
"torch_empty_cache_steps": null,
|
| 17 |
+
"learning_rate": 0.0001,
|
| 18 |
+
"weight_decay": 0.1,
|
| 19 |
+
"adam_beta1": 0.9,
|
| 20 |
+
"adam_beta2": 0.95,
|
| 21 |
+
"adam_epsilon": 1e-08,
|
| 22 |
+
"max_grad_norm": 1,
|
| 23 |
+
"num_train_epochs": 1,
|
| 24 |
+
"max_steps": -1,
|
| 25 |
+
"lr_scheduler_type": "cosine",
|
| 26 |
+
"lr_scheduler_kwargs": {},
|
| 27 |
+
"warmup_ratio": 0.05,
|
| 28 |
+
"warmup_steps": 0,
|
| 29 |
+
"log_level": "passive",
|
| 30 |
+
"log_level_replica": "warning",
|
| 31 |
+
"log_on_each_node": true,
|
| 32 |
+
"logging_dir": "/content/output/qwen2-vl-7b-instruct/v2-20240909-100714/runs",
|
| 33 |
+
"logging_strategy": "steps",
|
| 34 |
+
"logging_first_step": true,
|
| 35 |
+
"logging_steps": 5,
|
| 36 |
+
"logging_nan_inf_filter": true,
|
| 37 |
+
"save_strategy": "steps",
|
| 38 |
+
"save_steps": 50,
|
| 39 |
+
"save_total_limit": 2,
|
| 40 |
+
"save_safetensors": true,
|
| 41 |
+
"save_on_each_node": false,
|
| 42 |
+
"save_only_model": false,
|
| 43 |
+
"restore_callback_states_from_checkpoint": false,
|
| 44 |
+
"no_cuda": false,
|
| 45 |
+
"use_cpu": false,
|
| 46 |
+
"use_mps_device": false,
|
| 47 |
+
"seed": 42,
|
| 48 |
+
"data_seed": null,
|
| 49 |
+
"jit_mode_eval": false,
|
| 50 |
+
"use_ipex": false,
|
| 51 |
+
"bf16": true,
|
| 52 |
+
"fp16": false,
|
| 53 |
+
"fp16_opt_level": "O1",
|
| 54 |
+
"half_precision_backend": "auto",
|
| 55 |
+
"bf16_full_eval": false,
|
| 56 |
+
"fp16_full_eval": false,
|
| 57 |
+
"tf32": null,
|
| 58 |
+
"local_rank": 0,
|
| 59 |
+
"ddp_backend": null,
|
| 60 |
+
"tpu_num_cores": null,
|
| 61 |
+
"tpu_metrics_debug": false,
|
| 62 |
+
"debug": [],
|
| 63 |
+
"dataloader_drop_last": false,
|
| 64 |
+
"eval_steps": 50,
|
| 65 |
+
"dataloader_num_workers": 1,
|
| 66 |
+
"dataloader_prefetch_factor": null,
|
| 67 |
+
"past_index": -1,
|
| 68 |
+
"run_name": "/content/output/qwen2-vl-7b-instruct/v2-20240909-100714",
|
| 69 |
+
"disable_tqdm": false,
|
| 70 |
+
"remove_unused_columns": false,
|
| 71 |
+
"label_names": null,
|
| 72 |
+
"load_best_model_at_end": false,
|
| 73 |
+
"metric_for_best_model": "loss",
|
| 74 |
+
"greater_is_better": false,
|
| 75 |
+
"ignore_data_skip": false,
|
| 76 |
+
"fsdp": [],
|
| 77 |
+
"fsdp_min_num_params": 0,
|
| 78 |
+
"fsdp_config": {
|
| 79 |
+
"min_num_params": 0,
|
| 80 |
+
"xla": false,
|
| 81 |
+
"xla_fsdp_v2": false,
|
| 82 |
+
"xla_fsdp_grad_ckpt": false
|
| 83 |
+
},
|
| 84 |
+
"fsdp_transformer_layer_cls_to_wrap": null,
|
| 85 |
+
"accelerator_config": "AcceleratorConfig(split_batches=False, dispatch_batches=False, even_batches=True, use_seedable_sampler=True, non_blocking=False, gradient_accumulation_kwargs=None, use_configured_state=False)",
|
| 86 |
+
"deepspeed": null,
|
| 87 |
+
"label_smoothing_factor": 0.0,
|
| 88 |
+
"optim": "adamw_torch",
|
| 89 |
+
"optim_args": null,
|
| 90 |
+
"adafactor": false,
|
| 91 |
+
"group_by_length": false,
|
| 92 |
+
"length_column_name": "length",
|
| 93 |
+
"report_to": [
|
| 94 |
+
"tensorboard"
|
| 95 |
+
],
|
| 96 |
+
"ddp_find_unused_parameters": null,
|
| 97 |
+
"ddp_bucket_cap_mb": null,
|
| 98 |
+
"ddp_broadcast_buffers": null,
|
| 99 |
+
"dataloader_pin_memory": true,
|
| 100 |
+
"dataloader_persistent_workers": false,
|
| 101 |
+
"skip_memory_metrics": true,
|
| 102 |
+
"use_legacy_prediction_loop": false,
|
| 103 |
+
"push_to_hub": false,
|
| 104 |
+
"resume_from_checkpoint": null,
|
| 105 |
+
"hub_model_id": null,
|
| 106 |
+
"hub_strategy": "every_save",
|
| 107 |
+
"hub_token": null,
|
| 108 |
+
"hub_private_repo": false,
|
| 109 |
+
"hub_always_push": false,
|
| 110 |
+
"gradient_checkpointing": true,
|
| 111 |
+
"gradient_checkpointing_kwargs": null,
|
| 112 |
+
"include_inputs_for_metrics": false,
|
| 113 |
+
"eval_do_concat_batches": true,
|
| 114 |
+
"fp16_backend": "auto",
|
| 115 |
+
"evaluation_strategy": null,
|
| 116 |
+
"push_to_hub_model_id": null,
|
| 117 |
+
"push_to_hub_organization": null,
|
| 118 |
+
"push_to_hub_token": null,
|
| 119 |
+
"mp_parameters": "",
|
| 120 |
+
"auto_find_batch_size": false,
|
| 121 |
+
"full_determinism": false,
|
| 122 |
+
"torchdynamo": null,
|
| 123 |
+
"ray_scope": "last",
|
| 124 |
+
"ddp_timeout": 1800,
|
| 125 |
+
"torch_compile": false,
|
| 126 |
+
"torch_compile_backend": null,
|
| 127 |
+
"torch_compile_mode": null,
|
| 128 |
+
"dispatch_batches": null,
|
| 129 |
+
"split_batches": null,
|
| 130 |
+
"include_tokens_per_second": false,
|
| 131 |
+
"include_num_input_tokens_seen": false,
|
| 132 |
+
"neftune_noise_alpha": null,
|
| 133 |
+
"optim_target_modules": null,
|
| 134 |
+
"batch_eval_metrics": false,
|
| 135 |
+
"eval_on_start": false,
|
| 136 |
+
"use_liger_kernel": false,
|
| 137 |
+
"eval_use_gather_object": false,
|
| 138 |
+
"sortish_sampler": true,
|
| 139 |
+
"predict_with_generate": false,
|
| 140 |
+
"generation_max_length": null,
|
| 141 |
+
"generation_num_beams": null,
|
| 142 |
+
"generation_config": "GenerationConfig {\n \"bos_token_id\": 151643,\n \"do_sample\": true,\n \"eos_token_id\": 151645,\n \"max_new_tokens\": 2048,\n \"pad_token_id\": 151643,\n \"temperature\": 0.01,\n \"top_k\": 1,\n \"top_p\": 0.001\n}\n",
|
| 143 |
+
"train_sampler_random": true,
|
| 144 |
+
"acc_strategy": "token",
|
| 145 |
+
"loss_name": null,
|
| 146 |
+
"additional_saved_files": [],
|
| 147 |
+
"metric_warmup_step": 0,
|
| 148 |
+
"train_dataset_sample": -1,
|
| 149 |
+
"distributed_state": "Distributed environment: NO\nNum processes: 1\nProcess index: 0\nLocal process index: 0\nDevice: cuda\n",
|
| 150 |
+
"_n_gpu": 1,
|
| 151 |
+
"__cached__setup_devices": "device(type='cuda', index=0)",
|
| 152 |
+
"deepspeed_plugin": null
|
| 153 |
+
}
|