

Commit
•
6deb185
1
Parent(s):
8280bef
rename to shisa-base-7b-v1
Browse files
README.md
CHANGED
|
@@ -4,7 +4,7 @@ language:
|
|
| 4 |
- en
|
| 5 |
- ja
|
| 6 |
---
|
| 7 |
-
`
|
| 8 |
|
| 9 |
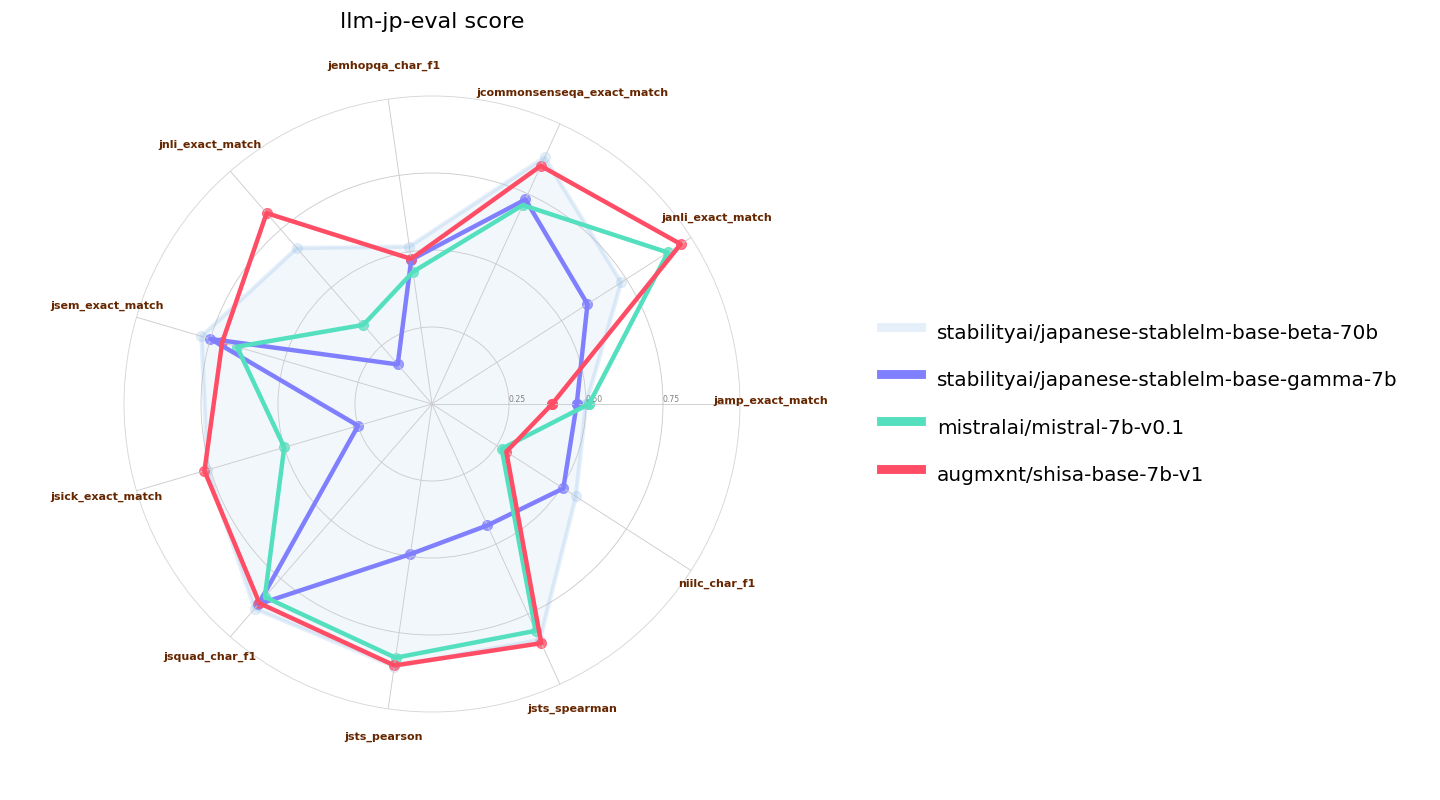
We have extended the Mistral tokenizer to 120k tokens to improve Japanese efficiency. Our tokenizer achieves ~2.3 characters per token in JA, versus the base Mistral 7B tokenizer which is <1 character per token. Code for our implementation is available in our [Shisa repo](https://github.com/AUGMXNT/shisa).
|
| 10 |
|
|
@@ -19,7 +19,7 @@ We used a slightly modified [llm-jp-eval](https://github.com/llm-jp/llm-jp-eval)
|
|
| 19 |
|
| 20 |
|
| 21 |
|
| 22 |
-
Here we also compare `
|
| 23 |
|
| 24 |
|
| 25 |
|
|
@@ -32,7 +32,7 @@ Japanese efficiency from sampling 50K items (~85M characters) from the JA subset
|
|
| 32 |
|
| 33 |
| LLM | Tokenizer | Vocab Size | Avg Char/Token |
|
| 34 |
|:----------------------------------------------|:----------------------------------------------------|-------------:|-----------------:|
|
| 35 |
-
| *Shisa 7B (AUGMXNT)* | *augmxnt/
|
| 36 |
| OpenCALM (CyberAgent) | cyberagent/open-calm-7b | 52000 | 2.17 |
|
| 37 |
| Japanese LargeLM (LINE) | line-corporation/japanese-large-lm-3.6b | 51200 | 2.14 |
|
| 38 |
| CALM2-7B (CyberAgent) | cyberagent/calm2-7b | 65000 | 2.00 |
|
|
@@ -54,7 +54,7 @@ We also test English efficiency using a sampling of 50K items (~177M characters)
|
|
| 54 |
| Qwen 14B (Qwen) | Qwen/Qwen-14B | 151851 | 4.47 |
|
| 55 |
| weblab-10b (Matsuo Lab) | EleutherAI/gpt-neox-20b | 50254 | 4.45 |
|
| 56 |
| Japanese StableLM Alpha (Stability AI) | [novelai/nerdstash-tokenizer-v1](https://huggingface.co/NovelAI/nerdstash-tokenizer-v1) | 65535 | 4.15 |
|
| 57 |
-
| *Shisa 7B (AUGMXNT)* | *augmxnt/
|
| 58 |
| CALM2-7B (CyberAgent) | cyberagent/calm2-7b | 65000 | 4.12 |
|
| 59 |
| Japanese StableLM Beta JAVocab (Stability AI) | stabilityai/japanese-stablelm-base-ja_vocab-beta-7b | 49247 | 4.01 |
|
| 60 |
| Japanese StableLM Gamma (Stability AI) | mistralai/Mistral-7B-v0.1 | 32000 | 4.01 |
|
|
@@ -79,7 +79,7 @@ And of course, thanks to the [Mistral AI](https://huggingface.co/mistralai) for
|
|
| 79 |
|
| 80 |
---
|
| 81 |
|
| 82 |
-
`
|
| 83 |
|
| 84 |
Mistralのトークン化器を12万トークンまで拡張し、日本語の効率を向上させました。私たちのトークン化器はJAでトークンあたり約2.3文字を実現しており、基本的なMistral 7Bのトークン化器はトークンあたり<1文字です。私たちの実装のコードは、[Shisaリポジトリ](https://github.com/AUGMXNT/shisa)で利用可能です。
|
| 85 |
|
|
@@ -94,7 +94,7 @@ Mistralのトークン化器を12万トークンまで拡張し、日本語の
|
|
| 94 |
|
| 95 |
![Mistral llm-jp-eval 比較]()
|
| 96 |
|
| 97 |
-
ここでは、`
|
| 98 |
|
| 99 |
![7B llm-jp-eval パフォーマンス]()
|
| 100 |
|
|
@@ -107,7 +107,7 @@ Mistralのトークン化器を12万トークンまで拡張し、日本語の
|
|
| 107 |
|
| 108 |
| LLM | トークン化器 | 語彙サイズ | 1トークンあたりの平均文字数 |
|
| 109 |
|:----------------------------------------------|:----------------------------------------------------|-------------:|-----------------:|
|
| 110 |
-
| *Shisa 7B (AUGMXNT)* | *augmxnt/
|
| 111 |
| OpenCALM (CyberAgent) | cyberagent/open-calm-7b | 52000 | 2.17 |
|
| 112 |
| Japanese LargeLM (LINE) | line-corporation/japanese-large-lm-3.6b | 51200 | 2.14 |
|
| 113 |
| CALM2-7B (CyberAgent) | cyberagent/calm2-7b | 65000 | 2.00 |
|
|
@@ -129,7 +129,7 @@ Mistralのトークン化器を12万トークンまで拡張し、日本語の
|
|
| 129 |
| Qwen 14B (Qwen) | Qwen/Qwen-14B | 151851 | 4.47 |
|
| 130 |
| weblab-10b (Matsuo Lab) | EleutherAI/gpt-neox-20b | 50254 | 4.45 |
|
| 131 |
| Japanese StableLM Alpha (Stability AI) | [novelai/nerdstash-tokenizer-v1](https://huggingface.co/NovelAI/nerdstash-tokenizer-v1) | 65535 | 4.15 |
|
| 132 |
-
| *Shisa 7B (AUGMXNT)* | *augmxnt/
|
| 133 |
| CALM2-7B (CyberAgent) | cyberagent/calm2-7b | 65000 | 4.12 |
|
| 134 |
| Japanese StableLM Beta JAVocab (Stability AI) | stabilityai/japanese-stablelm-base-ja_vocab-beta-7b | 49247 | 4.01 |
|
| 135 |
| Japanese StableLM Gamma (Stability AI) | mistralai/Mistral-7B-v0.1 | 32000 | 4.01 |
|
|
|
|
| 4 |
- en
|
| 5 |
- ja
|
| 6 |
---
|
| 7 |
+
`shisa-base-7b-v1` takes [Mistral 7B](https://huggingface.co/mistralai/Mistral-7B-v0.1) and adds an additional 8B tokens of primarily Japanese pre-training. Japanese tokens were sourced from [MADLAD-400](https://github.com/google-research/google-research/tree/master/madlad_400), using [DSIR](https://github.com/p-lambda/dsir), along with 10% English tokens sampled from a mix of MADLAD-400 EN and various open datasources added in to prevent catastrophic forgetting.
|
| 8 |
|
| 9 |
We have extended the Mistral tokenizer to 120k tokens to improve Japanese efficiency. Our tokenizer achieves ~2.3 characters per token in JA, versus the base Mistral 7B tokenizer which is <1 character per token. Code for our implementation is available in our [Shisa repo](https://github.com/AUGMXNT/shisa).
|
| 10 |
|
|
|
|
| 19 |
|
| 20 |

|
| 21 |
|
| 22 |
+
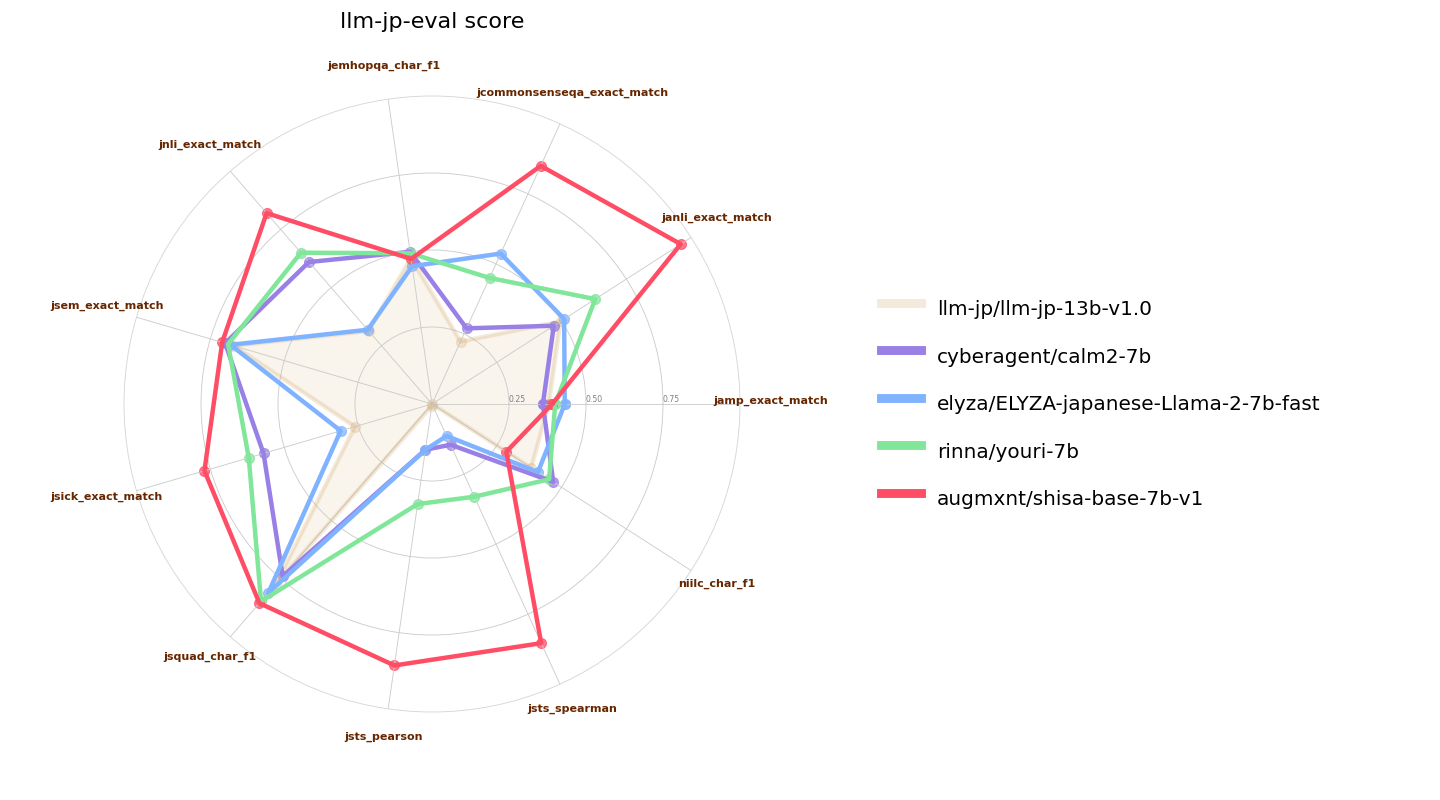
Here we also compare `shisa-base-7b-v1` to other recently-released similar classed (7B parameter) Japanese-tuned models. [ELYZA 7B fast model](https://huggingface.co/elyza/ELYZA-japanese-Llama-2-7b-fast) and [Youri 7B](https://huggingface.co/rinna/youri-7b) are Llama 2 7B models with 18B and 40B of additional pre-training respectively, and [CALM2-7B](https://huggingface.co/cyberagent/calm2-7b) and [llm-jp-13b]() are pretrained models with 1.3T and 300B JA/EN tokens of pre-training:
|
| 23 |
|
| 24 |

|
| 25 |
|
|
|
|
| 32 |
|
| 33 |
| LLM | Tokenizer | Vocab Size | Avg Char/Token |
|
| 34 |
|:----------------------------------------------|:----------------------------------------------------|-------------:|-----------------:|
|
| 35 |
+
| *Shisa 7B (AUGMXNT)* | *augmxnt/shisa-base-7b-v1* | *120073* | *2.31* |
|
| 36 |
| OpenCALM (CyberAgent) | cyberagent/open-calm-7b | 52000 | 2.17 |
|
| 37 |
| Japanese LargeLM (LINE) | line-corporation/japanese-large-lm-3.6b | 51200 | 2.14 |
|
| 38 |
| CALM2-7B (CyberAgent) | cyberagent/calm2-7b | 65000 | 2.00 |
|
|
|
|
| 54 |
| Qwen 14B (Qwen) | Qwen/Qwen-14B | 151851 | 4.47 |
|
| 55 |
| weblab-10b (Matsuo Lab) | EleutherAI/gpt-neox-20b | 50254 | 4.45 |
|
| 56 |
| Japanese StableLM Alpha (Stability AI) | [novelai/nerdstash-tokenizer-v1](https://huggingface.co/NovelAI/nerdstash-tokenizer-v1) | 65535 | 4.15 |
|
| 57 |
+
| *Shisa 7B (AUGMXNT)* | *augmxnt/shisa-base-7b-v1* | *120073* | *4.12* |
|
| 58 |
| CALM2-7B (CyberAgent) | cyberagent/calm2-7b | 65000 | 4.12 |
|
| 59 |
| Japanese StableLM Beta JAVocab (Stability AI) | stabilityai/japanese-stablelm-base-ja_vocab-beta-7b | 49247 | 4.01 |
|
| 60 |
| Japanese StableLM Gamma (Stability AI) | mistralai/Mistral-7B-v0.1 | 32000 | 4.01 |
|
|
|
|
| 79 |
|
| 80 |
---
|
| 81 |
|
| 82 |
+
`shisa-base-7b-v1`は、[Mistral 7B](https://huggingface.co/mistralai/Mistral-7B-v0.1)を基にして、主に日本語の事前トレーニングのために追加で80億トークンを追加しています。日本語トークンは、[MADLAD-400](https://github.com/google-research/google-research/tree/master/madlad_400)から取得し、[DSIR](https://github.com/p-lambda/dsir)を使用しています。さらに、MADLAD-400 ENと様々なオープンデータソースからの英語トークンの10%を追加し、壊滅的忘却を防ぐために組み込んでいます。
|
| 83 |
|
| 84 |
Mistralのトークン化器を12万トークンまで拡張し、日本語の効率を向上させました。私たちのトークン化器はJAでトークンあたり約2.3文字を実現しており、基本的なMistral 7Bのトークン化器はトークンあたり<1文字です。私たちの実装のコードは、[Shisaリポジトリ](https://github.com/AUGMXNT/shisa)で利用可能です。
|
| 85 |
|
|
|
|
| 94 |
|
| 95 |
![Mistral llm-jp-eval 比較]()
|
| 96 |
|
| 97 |
+
ここでは、`shisa-base-7b-v1`を他の最近リリースされた同じクラス(7Bパラメータ)の日本語チューニングモデルとも比較します。[ELYZA 7B fast model](https://huggingface.co/elyza/ELYZA-japanese-Llama-2-7b-fast)および[Youri 7B](https://huggingface.co/rinna/youri-7b)はLlama 2 7Bモデルで、それぞれ180億と400億の追加事前トレーニングがあります。また、[CALM2-7B](https://huggingface.co/cyberagent/calm2-7b)と[llm-jp-13b]()は、1.3Tおよび3000億JA/ENトークンの事前トレーニングを行ったプリトレーニングモデルです。
|
| 98 |
|
| 99 |
![7B llm-jp-eval パフォーマンス]()
|
| 100 |
|
|
|
|
| 107 |
|
| 108 |
| LLM | トークン化器 | 語彙サイズ | 1トークンあたりの平均文字数 |
|
| 109 |
|:----------------------------------------------|:----------------------------------------------------|-------------:|-----------------:|
|
| 110 |
+
| *Shisa 7B (AUGMXNT)* | *augmxnt/shisa-base-7b-v1* | *120073* | *2.31* |
|
| 111 |
| OpenCALM (CyberAgent) | cyberagent/open-calm-7b | 52000 | 2.17 |
|
| 112 |
| Japanese LargeLM (LINE) | line-corporation/japanese-large-lm-3.6b | 51200 | 2.14 |
|
| 113 |
| CALM2-7B (CyberAgent) | cyberagent/calm2-7b | 65000 | 2.00 |
|
|
|
|
| 129 |
| Qwen 14B (Qwen) | Qwen/Qwen-14B | 151851 | 4.47 |
|
| 130 |
| weblab-10b (Matsuo Lab) | EleutherAI/gpt-neox-20b | 50254 | 4.45 |
|
| 131 |
| Japanese StableLM Alpha (Stability AI) | [novelai/nerdstash-tokenizer-v1](https://huggingface.co/NovelAI/nerdstash-tokenizer-v1) | 65535 | 4.15 |
|
| 132 |
+
| *Shisa 7B (AUGMXNT)* | *augmxnt/shisa-base-7b-v1* | *120073* | *4.12* |
|
| 133 |
| CALM2-7B (CyberAgent) | cyberagent/calm2-7b | 65000 | 4.12 |
|
| 134 |
| Japanese StableLM Beta JAVocab (Stability AI) | stabilityai/japanese-stablelm-base-ja_vocab-beta-7b | 49247 | 4.01 |
|
| 135 |
| Japanese StableLM Gamma (Stability AI) | mistralai/Mistral-7B-v0.1 | 32000 | 4.01 |
|