

Update README.md
Browse files
README.md
CHANGED
|
@@ -26,7 +26,7 @@ Here we also compare `shisa-base-7b-v1` to other recently-released similar class
|
|
| 26 |
|
| 27 |
|
| 28 |
## Tokenizer
|
| 29 |
-
As mentioned in the introduction, our tokenizer is an extended version of the Mistral 7B tokenizer, with a vocab size of 120073 and aligned to
|
| 30 |
|
| 31 |
We use the "Fast" tokenizer, which should be the default for `AutoTokenizer`, but if you have problems, make sure to check `tokenizer.is_fast` or to initialize with `use_fast=True`.
|
| 32 |
|
|
@@ -101,7 +101,7 @@ Mistralのトークン化器を12万トークンまで拡張し、日本語の
|
|
| 101 |
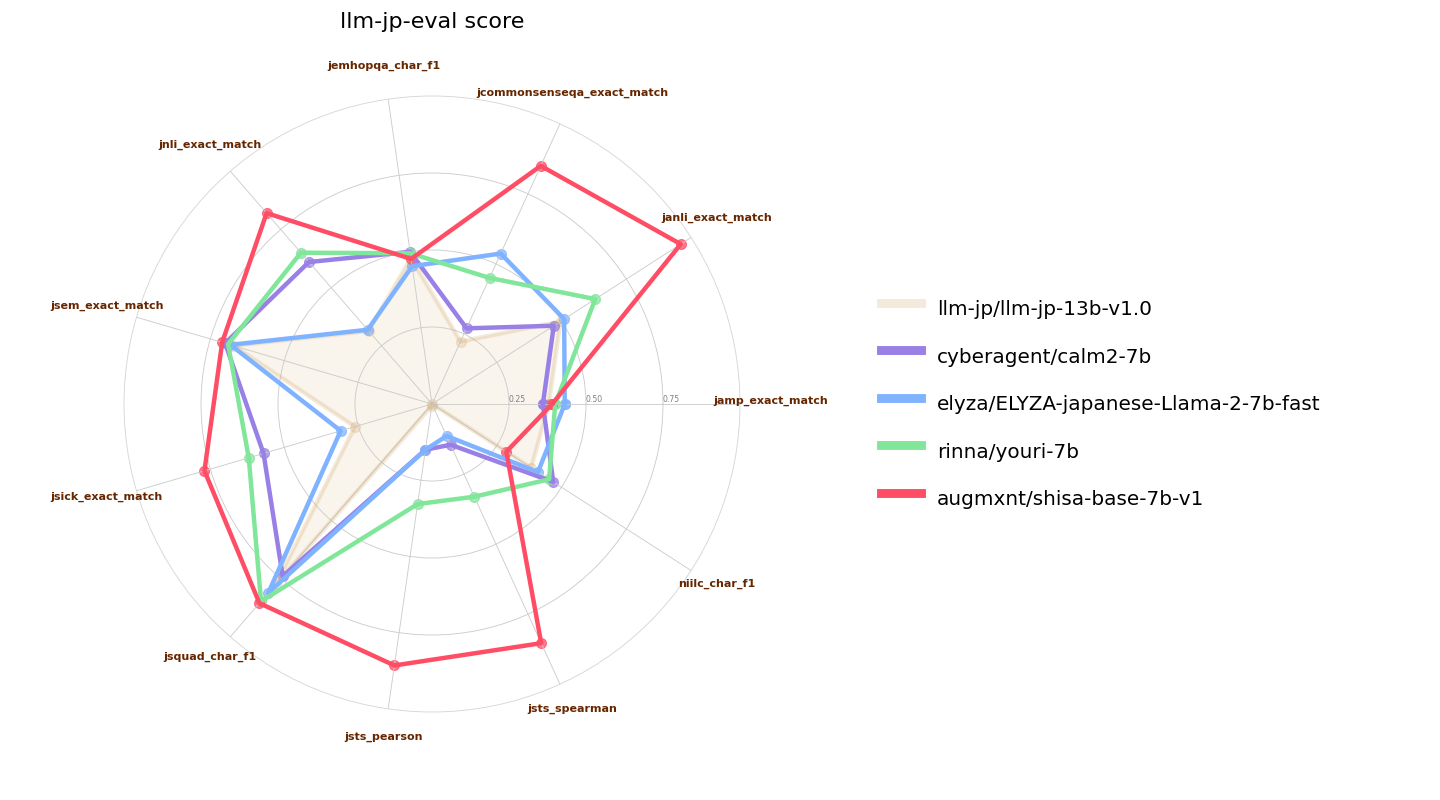
![7B llm-jp-eval パフォーマンス]()
|
| 102 |
|
| 103 |
## トークン化器
|
| 104 |
-
序文で触れたように、私たちのトークン化器はMistral 7Bトークン化器の拡張版で、語彙サイズは120073であり、
|
| 105 |
|
| 106 |
私たちは「Fast」トークン化器を使用しており、これは`AutoTokenizer`のデフォルトであるべきですが、問題がある場合は`tokenizer.is_fast`をチェックするか、`use_fast=True`で初期化することを確認してください。
|
| 107 |
|
|
|
|
| 26 |

|
| 27 |
|
| 28 |
## Tokenizer
|
| 29 |
+
As mentioned in the introduction, our tokenizer is an extended version of the Mistral 7B tokenizer, with a vocab size of 120073 and aligned to 120128 for better performance. The remaining unused tokens are assigned as average-weighted `<|extra_{idx}|>` tokens.
|
| 30 |
|
| 31 |
We use the "Fast" tokenizer, which should be the default for `AutoTokenizer`, but if you have problems, make sure to check `tokenizer.is_fast` or to initialize with `use_fast=True`.
|
| 32 |
|
|
|
|
| 101 |
![7B llm-jp-eval パフォーマンス]()
|
| 102 |
|
| 103 |
## トークン化器
|
| 104 |
+
序文で触れたように、私たちのトークン化器はMistral 7Bトークン化器の拡張版で、語彙サイズは120073であり、120128に合わせられています。残りの未使用トークンは、平均重み付けされた`<|extra_{idx}|>`トークンとして割り当てられています。
|
| 105 |
|
| 106 |
私たちは「Fast」トークン化器を使用しており、これは`AutoTokenizer`のデフォルトであるべきですが、問題がある場合は`tokenizer.is_fast`をチェックするか、`use_fast=True`で初期化することを確認してください。
|
| 107 |
|