Dynamic Topic Modeling with RedPajama: A New Approach to Hierarchical Content Understanding

For a more personal take on the journey and motivation behind this dataset, check out Teaching AI to Read and Group Like I Bookmark the Web by the dataset creator.
 *Visualization of dynamic topic modeling*
*Visualization of dynamic topic modeling*
Introduction
Topic modeling at scale presents unique challenges in the era of large language models. While traditional approaches like LDA (Latent Dirichlet Allocation) have served us well, they often fall short when dealing with modern content complexity and scale. Today, I'm excited to introduce a new dataset that brings hierarchical topic modeling into the LLM era: Dynamic-Topic-RedPajama-Data-1T-100k-SubSample-max-1k-tokens.
Dataset Overview
The dataset comprises 100,000 carefully curated samples from the RedPajama-1T dataset, each annotated with a three-level hierarchical topic structure:
{
"text": "Original document content...",
"topic_level_1": "Subject Topic", # Broad domain
"topic_level_2": "High-Level Topic", # Specific focus
"topic_level_3": "Niche Topic" # Detailed theme
}
Key Statistics:
- Documents: 100,000
- Max tokens per document: 1,024
- Unique Level-1 topics: 25,178
- Unique Level-2 topics: 71,024
- Unique Level-3 topics: 92,568
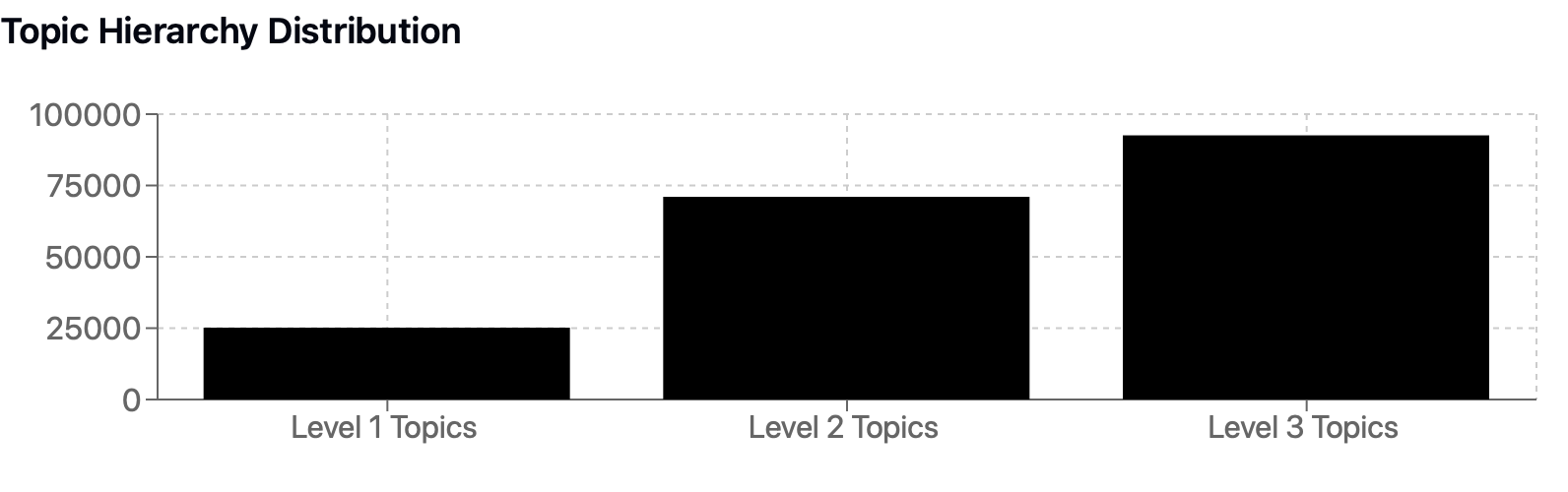 *Distribution of topics across different hierarchical levels*
*Distribution of topics across different hierarchical levels*
Technical Implementation
Document Processing Pipeline
from transformers import AutoTokenizer
import torch
def prepare_documents(texts, max_length=1024):
tokenizer = AutoTokenizer.from_pretrained("gpt2")
processed_docs = []
for text in texts:
# Truncate and tokenize
encoded = tokenizer(
text,
truncation=True,
max_length=max_length,
return_tensors="pt"
)
processed_docs.append(encoded)
return processed_docs
Topic Generation Process
The topics were generated using GPT-4o-mini through a structured prompting approach:
def generate_topics(text):
prompt = f"""
Given the following text, generate three hierarchical topics:
Text: {text}
1. Broad subject domain:
2. Specific focus area:
3. Detailed thematic element:
"""
# Generation logic here
return topics
Applications and Use Cases
Model Fine-tuning
- Training smaller, efficient topic classifiers
- Developing hierarchical classification systems
Content Organization
- Automated document categorization
- Content recommendation systems
- Knowledge base structuring
Research Applications
- Studying topic evolution in large corpora
- Cross-domain knowledge transfer
- Semantic relationship analysis
Getting Started
from datasets import load_dataset
# Load the dataset
dataset = load_dataset("AmanPriyanshu/Dynamic-Topic-RedPajama-Data-1T-100k-SubSample-max-1k-tokens")
# Basic exploration
print(f"Dataset size: {len(dataset['train'])}")
print(f"Sample entry:\n{dataset['train'][0]}")
Future Directions
- Cross-lingual Extension: Expanding to multilingual topic modeling
- Temporal Analysis: Incorporating time-based topic evolution
- Interactive Tools: Developing visualization and exploration interfaces
- Model Compression: Creating efficient topic modeling architectures
Citation
@misc{dynamic-topic-redpajama,
author = {Aman Priyanshu},
title = {Dynamic Topic RedPajama Data 1T 100k SubSample},
year = {2024},
publisher = {HuggingFace}
}
Community and Contributions
I welcome contributions and feedback from the community. Whether you're interested in extending the dataset, improving the topic generation process, or building applications on top of it, check out the Huggingface Dataset Release or join the discussion in the community forum.
Acknowledgments
This dataset builds upon the work of the RedPajama dataset team and the broader open-source AI community.