Recipe: Preparing Multilingual Speech Datasets for TTS Training







This recipe describes how we prepared the datasets to train the Parler TTS mini v1.1 multilingual that you can try here.
Ingredients
We used 2 multilingual open-source datasets covering French, Polish, German, Dutch, Italian, Portuguese, and Spanish:
What is Parler TTS?
Parler-TTS is a lightweight text-to-speech (TTS) model capable of generating high-quality, natural-sounding speech in the style of a given speaker (gender, tone, speaking style, etc.). It reproduces the work presented in the paper "Natural Language Guidance of High-Fidelity Text-to-Speech with Synthetic Annotations" by Dan Lyth and Simon King from Stability AI and the University of Edinburgh, respectively.
The Parler TTS project is an open-source project initiated by Hugging Face. You can learn more about it at huggingface.co/parler-tts.
Model Performance
For evaluation, we generated a test set containing 40 samples per language. The description prompts followed the same structure used during model training. While these controlled samples help establish a baseline for model capabilities, they may not fully represent real-world performance, especially when prompts deviate significantly from the training format.
Here are the Word Error Rate (WER) results across languages:
| Language | WER (%) |
|---|---|
| Spanish | 0.70 |
| German | 1.13 |
| English | 1.19 |
| French | 2.31 |
| Italian | 3.16 |
| Polish | 4.02 |
| Dutch | 4.38 |
| Portuguese | 5.08 |
Prerequisites
The original Parler-TTS tokenizer was specifically tailored for English. Due to its limited vocabulary and absence of a byte fallback mechanism—a system that maps parts of words not found in the tokenizer's vocabulary to tokens—it wasn't ideal for multilingual training.
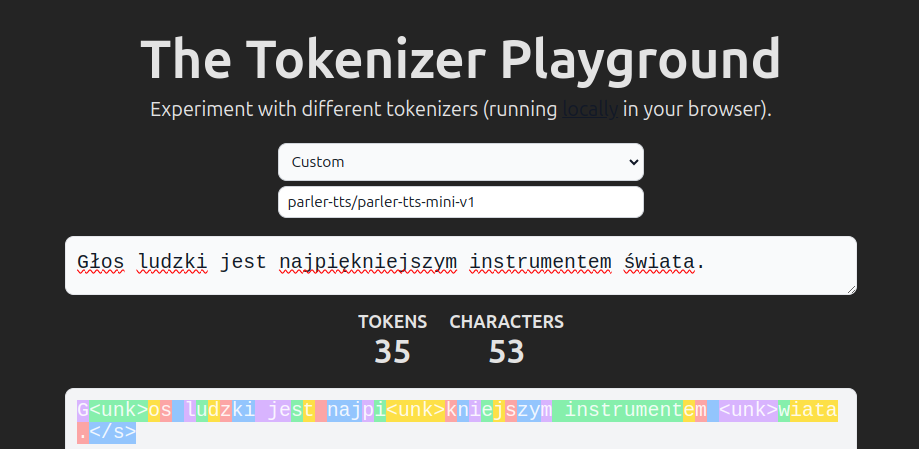
Parler-TTS v1.1 employs an improved tokenizer that incorporates byte fallback. You can explore the functionality of this tokenizer with different languages in the Tokenizer Playground by selecting parler-tts/parler-tts-mini-v1.1 as your custom tokenizer.
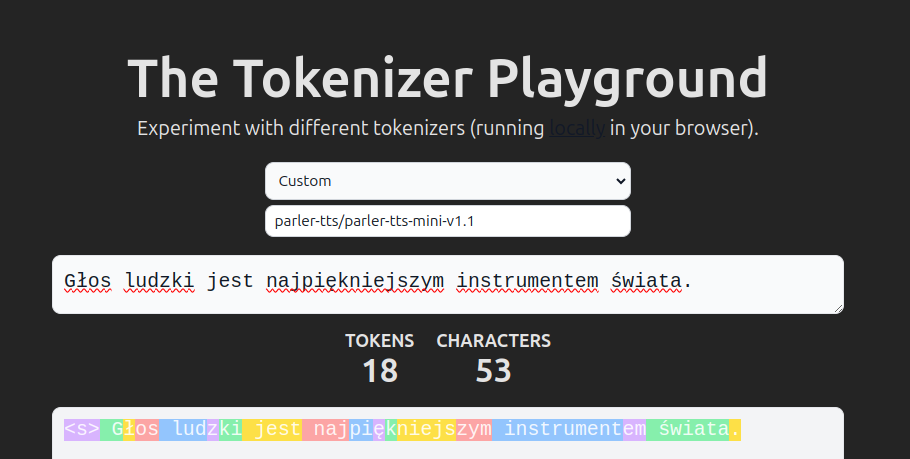
Note: Parler-TTS v1.1 now employs two distinct tokenizers, one for descriptions and another for prompts.
Method
1. Update Phonemizer and Add Punctuation Restoration
We've transitioned from the g2p library to phonemizer with espeak-ng backend to significantly expand our language support capabilities.
The switch to ESpeak-NG as our phonemization backend brings support for over 100 languages and variants, including:
- Germanic: English, German, Dutch, Swedish, Danish, Norwegian
- Romance: French, Spanish, Italian, Portuguese, Romanian
- Slavic: Russian, Polish, Czech, Slovak, Croatian, Serbian
- Asian Languages: Mandarin, Japanese (Hiragana), Korean, Vietnamese
- Indic Languages: Hindi, Bengali, Tamil, Telugu
- Semitic: Arabic, Hebrew
- African Languages: Swahili, Zulu, Afrikaans
If you want to work on a dataset with a language that is not currently supported by dataspeech, you need to:
- Update the phonemizer
- Update the casing model (using spaCy under the hood)
- Update the punctuation restoration model (currently using deepmultilingualpunctuation)
- You can find fine-tuned versions on the hub or fine-tune your own version
- Punctuation restoration and casing scripts are available here
2. Initial Cleaning
The cleaning process focuses on removing low-quality samples that could negatively impact model training. This includes samples with mismatched audio-text pairs, poor audio quality, or incorrect transcriptions.
Calculate Levenshtein similarity score for each sample
- Levenshtein distance measures how different two strings are by counting the minimum number of single-character operations (insertions, deletions, substitutions)
- We normalize this to a 0-1 similarity score where 1 means perfect match
- This helps verify the quality of transcriptions
Remove samples with Levenshtein similarity score < 0.9
- This eliminates incorrect/incomplete transcriptions
- A score of 0.9 means the strings are 90% similar, allowing for minor variations while filtering out major discrepancies
- We only performed this cleaning on the CML-TTS dataset
- You can find the cleaned version at huggingface.co/datasets/PHBJT/cml-tts-filtered
Here are some exemples of invalid samples that were present in the initial dataset:
| Original dataset transcript | Recomputed transcript | Audio sample | Score |
|---|---|---|---|
| omstreken. Het derde | van het derde boek | 0.32 | |
| Não peço mais ao | fim do capítulo vinte sete gravado por felipe valle | 0.18 |
3. Annotation Process
Now that we have annotated and clean our multilingual audio datasets, we can generate natural language descriptions from the annotations, as indicated in the dataspeech library:
Prepare transcription data
- Use existing transcriptions from datasets
- Restore punctuation and casing on transcriptions (both are very important)
Generate sample descriptions (handled within dataspeech's utility scripts)
- Calculate sentence metrics (speech rate, etc.)
- Feed metrics into LLM
- Generate descriptive text for each sample
These datasets were used to train Parler TTS mini V1.1 multilingual alongside with LibriTTS-R English dataset.
If you want to fine tune Parler TTS mini V1.1 in any other language, a training recipe is available in the Parler-TTS library.




