Accelerate 1.0.0








This article is also available in Chinese 简体中文.
What is Accelerate today?
3.5 years ago, Accelerate was a simple framework aimed at making training on multi-GPU and TPU systems easier by having a low-level abstraction that simplified a raw PyTorch training loop:
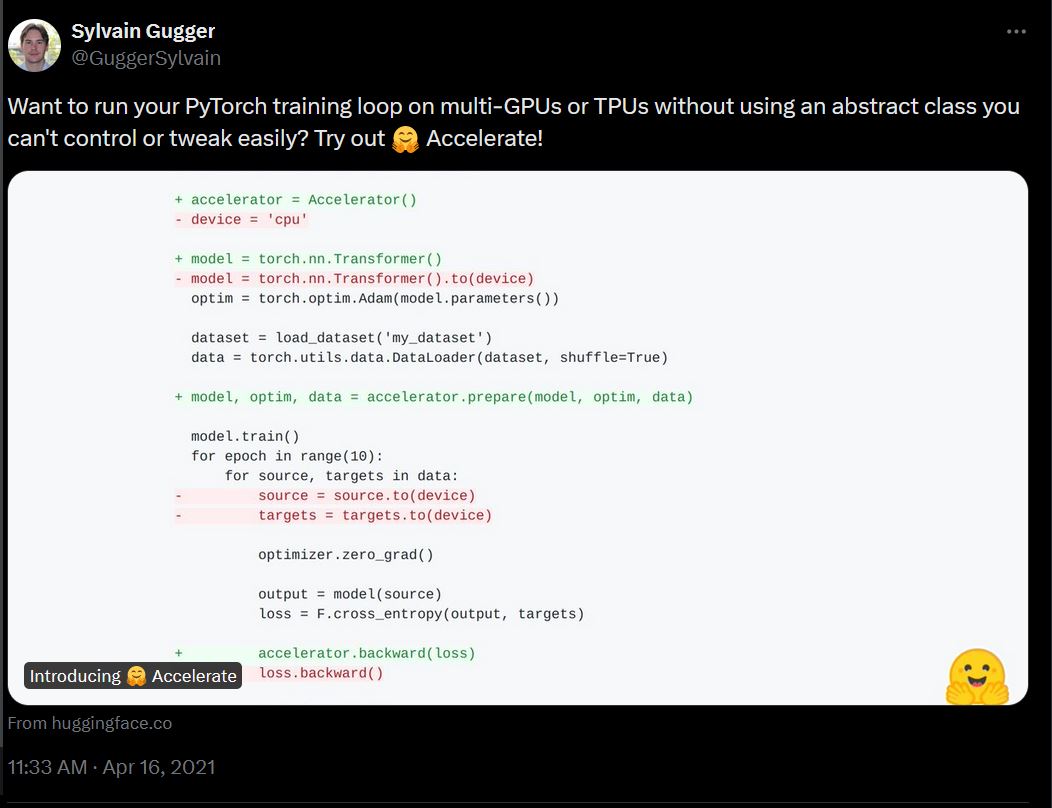
Since then, Accelerate has expanded into a multi-faceted library aimed at tackling many common problems with large-scale training and large models in an age where 405 billion parameters (Llama) are the new language model size. This involves:
- A flexible low-level training API, allowing for training on six different hardware accelerators (CPU, GPU, TPU, XPU, NPU, MLU) while maintaining 99% of your original training loop
- An easy-to-use command-line interface aimed at configuring and running scripts across different hardware configurations
- The birthplace of Big Model Inference or
device_map="auto", allowing users to not only perform inference on LLMs with multi-devices but now also aiding in training LLMs on small compute through techniques like parameter-efficient fine-tuning (PEFT)
These three facets have allowed Accelerate to become the foundation of nearly every package at Hugging Face, including transformers, diffusers, peft, trl, and more!
As the package has been stable for nearly a year, we're excited to announce that, as of today, we've published the first release candidates for Accelerate 1.0.0!
This blog will detail:
- Why did we decide to do 1.0?
- What is the future for Accelerate, and where do we see PyTorch as a whole going?
- What are the breaking changes and deprecations that occurred, and how can you migrate over easily?
Why 1.0?
The plans to release 1.0.0 have been in the works for over a year. The API has been roughly at a point where we wanted,
centering on the Accelerator side, simplifying much of the configuration and making it more extensible. However, we knew
there were a few missing pieces before we could call the "base" of Accelerate "feature complete":
- Integrating FP8 support of both MS-AMP and
TransformersEngine(read more here and here) - Supporting orchestration of multiple models when using DeepSpeed (Experimental)
torch.compilesupport for the big model inference API (requirestorch>=2.5)- Integrating
torch.distributed.pipeliningas an alternative distributed inference mechanic - Integrating
torchdata.StatefulDataLoaderas an alternative dataloader mechanic
With the changes made for 1.0, accelerate is prepared to tackle new tech integrations while keeping the user-facing API stable.
The future of Accelerate
Now that 1.0 is almost done, we can focus on new techniques coming out throughout the community and find integration paths into Accelerate, as we foresee some radical changes in the PyTorch ecosystem very soon:
- As part of the multiple-model DeepSpeed support, we found that while generally how DeepSpeed is currently could work, some heavy changes to the overall API may eventually be needed as we work to support simple wrappings to prepare models for any multiple-model training scenario.
- With torchao and torchtitan picking up steam, they hint at the future of PyTorch as a whole. Aiming at more native support for FP8 training, a new distributed sharding API, and support for a new version of FSDP, FSDPv2, we predict that much of the internals and general usage API of Accelerate will need to change (hopefully not too drastic) to meet these needs as the frameworks slowly become more stable.
- Riding on
torchao/FP8, many new frameworks are bringing in different ideas and implementations on how to make FP8 training work and be stable (transformer_engine,torchao,MS-AMP,nanotron, to name a few). Our aim with Accelerate is to house each of these implementations in one place with easy configurations to let users explore and test out each one as they please, intending to find the ones that wind up being the most stable and flexible. It's a rapidly accelerating (no pun intended) field of research, especially with NVIDIA's FP4 training support on the way, and we want to make sure that not only can we support each of these methods but aim to provide solid benchmarks for each to show their tendencies out-of-the-box (with minimal tweaking) compared to native BF16 training
We're incredibly excited about the future of distributed training in the PyTorch ecosystem, and we want to make sure that Accelerate is there every step of the way, providing a lower barrier to entry for these new techniques. By doing so, we hope the community will continue experimenting and learning together as we find the best methods for training and scaling larger models on more complex computing systems.
How to try it out
To try the first release candidate for Accelerate today, please use one of the following methods:
- pip:
pip install --pre accelerate
- Docker:
docker pull huggingface/accelerate:gpu-release-1.0.0rc1
Valid release tags are:
gpu-release-1.0.0rc1cpu-release-1.0.0rc1gpu-fp8-transformerengine-release-1.0.0rc1gpu-deepspeed-release-1.0.0rc1
Migration assistance
Below are the full details for all deprecations that are being enacted as part of this release:
- Passing in
dispatch_batches,split_batches,even_batches, anduse_seedable_samplerto theAccelerator()should now be handled by creating anaccelerate.utils.DataLoaderConfiguration()and passing this to theAccelerator()instead (Accelerator(dataloader_config=DataLoaderConfiguration(...))) Accelerator().use_fp16andAcceleratorState().use_fp16have been removed; this should be replaced by checkingaccelerator.mixed_precision == "fp16"Accelerator().autocast()no longer accepts acache_enabledargument. Instead, anAutocastKwargs()instance should be used which handles this flag (among others) passing it to theAccelerator(Accelerator(kwargs_handlers=[AutocastKwargs(cache_enabled=True)]))accelerate.utils.is_tpu_availableshould be replaced withaccelerate.utils.is_torch_xla_availableaccelerate.utils.modeling.shard_checkpointshould be replaced withsplit_torch_state_dict_into_shardsfrom thehuggingface_hublibraryaccelerate.tqdm.tqdm()no longer acceptsTrue/Falseas the first argument, and instead,main_process_onlyshould be passed in as a named argumentACCELERATE_DISABLE_RICHis no longer a valid environmental variable, and instead, one should manually enablerichtraceback by settingACCELERATE_ENABLE_RICH=1- The FSDP setting
fsdp_backward_prefetch_policyhas been replaced withfsdp_backward_prefetch
Closing thoughts
Thank you so much for using Accelerate; it's been amazing watching a small idea turn into over 100 million downloads and nearly 300,000 daily downloads over the last few years.
With this release candidate, we hope to give the community an opportunity to try it out and migrate to 1.0 before the official release.
Please stay tuned for more information by keeping an eye on the github and on socials!













