RAG vs Fine-Tuning for LLMs: A Comprehensive Guide with Examples




Large Language Models (LLMs) have revolutionized natural language processing, but their effectiveness can be further enhanced through specialized techniques. This article explores two such methods: Retrieval-Augmented Generation (RAG) and Fine-Tuning. By understanding these approaches, data scientists and AI practitioners can make informed decisions about which technique to employ for their specific use cases.
Introduction
The world of artificial intelligence is rapidly evolving, with LLMs at the forefront of this transformation. As these models become more sophisticated, the need for techniques to tailor them to specific tasks or domains has grown. RAG and Fine-Tuning have emerged as two prominent methods to achieve this goal. What exactly are these techniques, and how do they differ? This article aims to demystify RAG and Fine-Tuning, providing a comprehensive overview of their mechanisms, advantages, and ideal use cases.
What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation, introduced by Meta in 2020, is an architectural framework that connects an LLM to a curated, dynamic database. This connection allows the model to access and incorporate up-to-date and reliable information into its responses. But how does this process actually work?
When a user submits a query, the RAG system first searches its database for relevant information. This retrieved data is then combined with the original query and fed into the LLM. Finally, the model generates a response using both its pre-trained knowledge and the context provided by the retrieved information. This approach enables the LLM to produce more accurate and contextually relevant outputs.
One of the key advantages of RAG is its ability to enhance security and data privacy. Unlike other methods that may expose sensitive information, RAG keeps proprietary data within a secured database environment, allowing for strict access control. This feature makes RAG particularly attractive for enterprises dealing with confidential information.
The Power of Fine-Tuning
Fine-Tuning involves training an LLM on a smaller, specialized dataset to adjust its parameters for specific tasks or domains. This process allows the model to become more proficient in handling particular types of queries or generating domain-specific content. But what makes Fine-Tuning so effective?
By aligning the model with the nuances and terminologies of a niche domain, Fine-Tuning significantly improves the model's performance on specific tasks. For instance, a study by Snorkel AI demonstrated that a fine-tuned model achieved the same quality as a GPT-3 model while being 1,400 times smaller and requiring less than 1% of the ground truth labels.
However, Fine-Tuning is not without its challenges. It requires significant computational resources and a high-quality, labeled dataset. Moreover, fine-tuned models may lose some of their general capabilities as they become more specialized. These factors must be carefully considered when deciding whether to employ Fine-Tuning.
Choosing the Right Approach
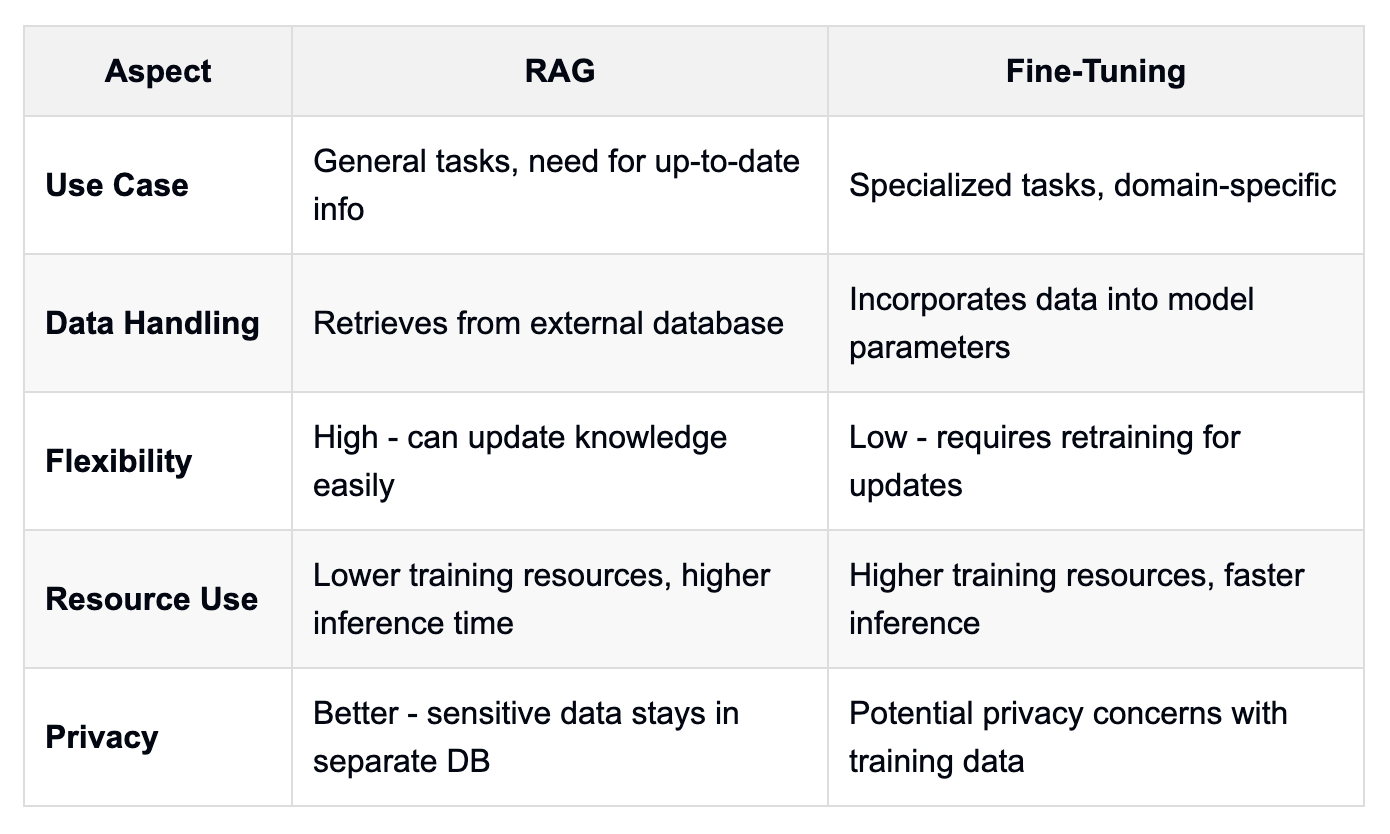
How can practitioners determine whether to use RAG or Fine-Tuning for their specific use case? The decision often depends on various factors, including security requirements, available resources, and the specificity of the task at hand.
RAG is generally preferred for most enterprise use cases due to its scalability, security, and ability to incorporate up-to-date information. It's particularly useful when dealing with sensitive data or when the task requires access to frequently updated information. According to a 2024 interview with Maxime Beauchemin, creator of Apache Airflow and Superset, RAG has proven effective in enabling AI-powered capabilities in business intelligence tools.
On the other hand, Fine-Tuning shines in highly specialized tasks or when aiming for a smaller, more efficient model. It's particularly effective when dealing with niche domains that require deep understanding of specific terminologies or contexts. However, it's important to note that Fine-Tuning requires more resources and may result in the loss of some general capabilities.
Examples of RAG and Fine-Tuning in Action
Let's explore some concrete examples to illustrate the application of RAG and Fine-Tuning:
RAG Example: A financial advisor chatbot. Imagine a chatbot designed to provide personalized financial advice. Using RAG, the chatbot can access a database containing up-to-date market data, individual client portfolios, and financial regulations. When a user asks, "What's the best investment strategy for me right now?", the chatbot retrieves relevant information about the user's financial situation, current market trends, and applicable regulations. It then uses this context to generate a tailored response.
Fine-Tuning Example: A medical diagnosis assistant. Consider an LLM fine-tuned on a dataset of medical reports and diagnoses. This model becomes specialized in understanding medical terminology and identifying potential diagnoses based on symptoms. When a doctor inputs a patient's symptoms, the fine-tuned model can suggest possible diagnoses and recommend further tests, drawing on its specialized training in the medical domain.
Hybrid Approach: A legal document analyzer. In some cases, a combination of RAG and Fine-Tuning can be beneficial. For a legal document analyzer, the base model could be fine-tuned on legal terminology and document structures. Then, RAG could be used to retrieve relevant case laws and regulations from a constantly updated database. This approach combines the specialized understanding from Fine-Tuning with the up-to-date information access of RAG.
The Role of Data Pipelines
Regardless of whether RAG or Fine-Tuning is chosen, the development of robust data pipelines is crucial. These pipelines ensure that the models are fed with high-quality, relevant data. But what exactly do these pipelines entail?
For RAG, data pipelines often involve the development of vector databases, embedding vectors, and semantic layers. These components work together to efficiently retrieve and process relevant information for the LLM. The complexity of these pipelines highlights the importance of having a strong data infrastructure in place.
In the case of Fine-Tuning, data pipelines focus on preparing and processing the specialized dataset used for training. This involves tasks such as data cleaning, labeling, and augmentation. The quality of this dataset directly impacts the performance of the fine-tuned model, underscoring the critical role of data preparation in the Fine-Tuning process.Large Language Models (LLMs) have revolutionized natural language processing, but their effectiveness can be further enhanced through specialized techniques. This article explores two such methods: Retrieval-Augmented Generation (RAG) and Fine-Tuning. By understanding these approaches, data scientists and AI practitioners can make informed decisions about which technique to employ for their specific use cases.
Introduction
The world of artificial intelligence is rapidly evolving, with LLMs at the forefront of this transformation. As these models become more sophisticated, the need for techniques to tailor them to specific tasks or domains has grown. RAG and Fine-Tuning have emerged as two prominent methods to achieve this goal. What exactly are these techniques, and how do they differ? This article aims to demystify RAG and Fine-Tuning, providing a comprehensive overview of their mechanisms, advantages, and ideal use cases.
What is Retrieval-Augmented Generation (RAG)?
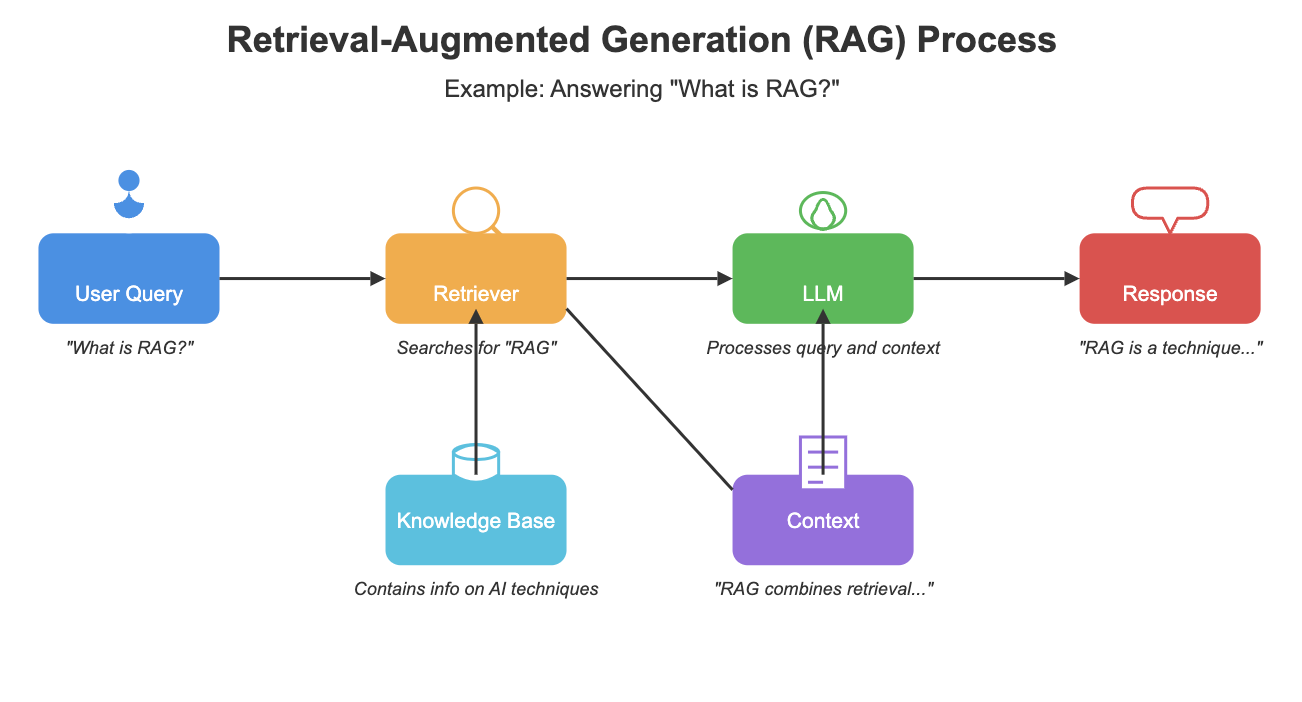
Retrieval-Augmented Generation, introduced by Meta in 2020, is an architectural framework that connects an LLM to a curated, dynamic database. This connection allows the model to access and incorporate up-to-date and reliable information into its responses. But how does this process actually work?
When a user submits a query, the RAG system first searches its database for relevant information. This retrieved data is then combined with the original query and fed into the LLM. Finally, the model generates a response using both its pre-trained knowledge and the context provided by the retrieved information. This approach enables the LLM to produce more accurate and contextually relevant outputs.
One of the key advantages of RAG is its ability to enhance security and data privacy. Unlike other methods that may expose sensitive information, RAG keeps proprietary data within a secured database environment, allowing for strict access control. This feature makes RAG particularly attractive for enterprises dealing with confidential information.
The Power of Fine-Tuning
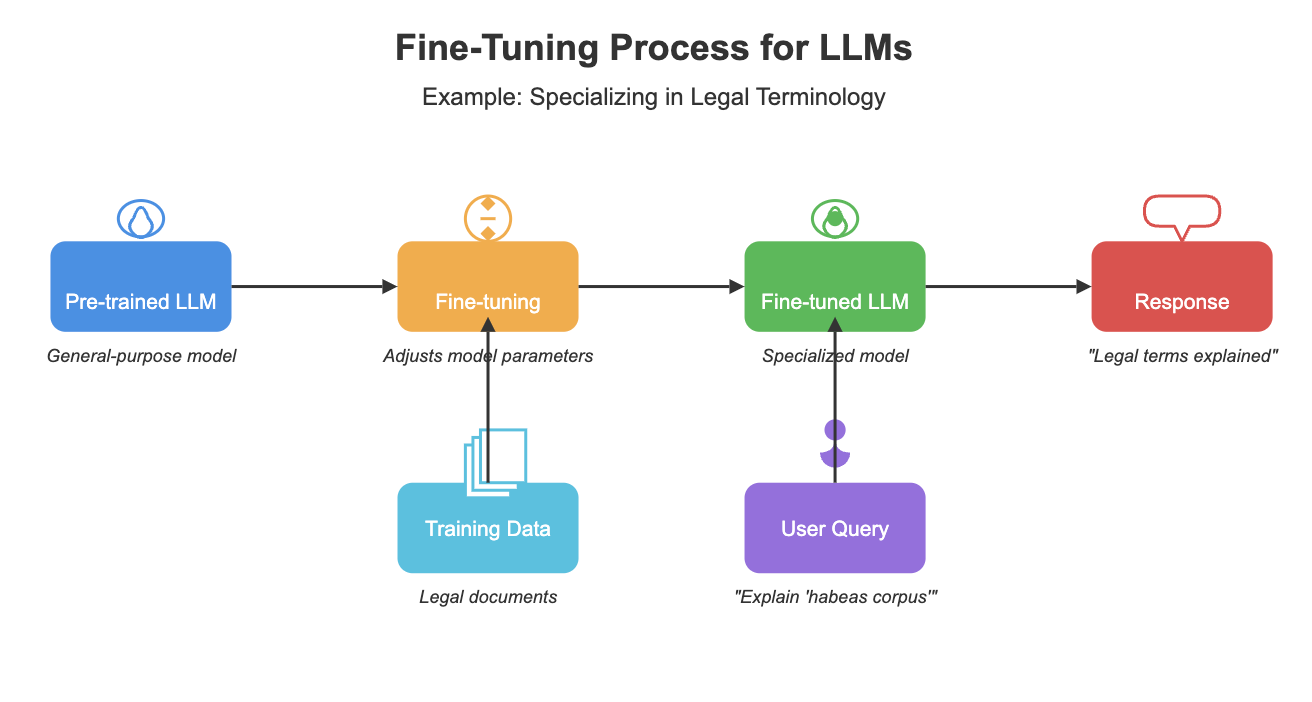
Fine-Tuning involves training an LLM on a smaller, specialized dataset to adjust its parameters for specific tasks or domains. This process allows the model to become more proficient in handling particular types of queries or generating domain-specific content. But what makes Fine-Tuning so effective?
By aligning the model with the nuances and terminologies of a niche domain, Fine-Tuning significantly improves the model's performance on specific tasks. For instance, a study by Snorkel AI demonstrated that a fine-tuned model achieved the same quality as a GPT-3 model while being 1,400 times smaller and requiring less than 1% of the ground truth labels.
However, Fine-Tuning is not without its challenges. It requires significant computational resources and a high-quality, labeled dataset. Moreover, fine-tuned models may lose some of their general capabilities as they become more specialized. These factors must be carefully considered when deciding whether to employ Fine-Tuning.
Choosing the Right Approach
How can practitioners determine whether to use RAG or Fine-Tuning for their specific use case? The decision often depends on various factors, including security requirements, available resources, and the specificity of the task at hand.