Binary and Scalar Embedding Quantization for Significantly Faster & Cheaper Retrieval









This article is also available in Chinese 简体中文.
We introduce the concept of embedding quantization and showcase their impact on retrieval speed, memory usage, disk space, and cost. We'll discuss how embeddings can be quantized in theory and in practice, after which we introduce a demo showing a real-life retrieval scenario of 41 million Wikipedia texts.Table of Contents
- Why Embeddings?
- Improving scalability
Why Embeddings?
Embeddings are one of the most versatile tools in natural language processing, supporting a wide variety of settings and use cases. In essence, embeddings are numerical representations of more complex objects, like text, images, audio, etc. Specifically, the objects are represented as n-dimensional vectors.
After transforming the complex objects, you can determine their similarity by calculating the similarity of the respective embeddings! This is crucial for many use cases: it serves as the backbone for recommendation systems, retrieval, one-shot or few-shot learning, outlier detection, similarity search, paraphrase detection, clustering, classification, and much more.
Embeddings may struggle to scale
However, embeddings may be challenging to scale for production use cases, which leads to expensive solutions and high latencies. Currently, many state-of-the-art models produce embeddings with 1024 dimensions, each of which is encoded in float32, i.e., they require 4 bytes per dimension. To perform retrieval over 250 million vectors, you would therefore need around 1TB of memory!
The table below gives an overview of different models, dimension size, memory requirement, and costs. Costs are computed at an estimated $3.8 per GB/mo with x2gd instances on AWS.
| Embedding Dimension | Example Models | 100M Embeddings | 250M Embeddings | 1B Embeddings |
|---|---|---|---|---|
| 384 | all-MiniLM-L6-v2 bge-small-en-v1.5 |
143.05GB $543 / mo |
357.62GB $1,358 / mo |
1430.51GB $5,435 / mo |
| 768 | all-mpnet-base-v2 bge-base-en-v1.5 jina-embeddings-v2-base-en nomic-embed-text-v1 |
286.10GB $1,087 / mo |
715.26GB $2,717 / mo |
2861.02GB $10,871 / mo |
| 1024 | bge-large-en-v1.5 mxbai-embed-large-v1 Cohere-embed-english-v3.0 |
381.46GB $1,449 / mo |
953.67GB $3,623 / mo |
3814.69GB $14,495 / mo |
| 1536 | OpenAI text-embedding-3-small | 572.20GB $2,174 / mo |
1430.51GB $5,435 / mo |
5722.04GB $21,743 / mo |
| 3072 | OpenAI text-embedding-3-large | 1144.40GB $4,348 / mo |
2861.02GB $10,871 / mo |
11444.09GB $43,487 / mo |
Improving scalability
There are several ways to approach the challenges of scaling embeddings. The most common approach is dimensionality reduction, such as PCA. However, classic dimensionality reduction -- like PCA methods -- tends to perform poorly when used with embeddings.
In recent news, Matryoshka Representation Learning (blogpost) (MRL) as used by OpenAI also allows for cheaper embeddings. With MRL, only the first n embedding dimensions are used. This approach has already been adopted by some open models like nomic-ai/nomic-embed-text-v1.5 and mixedbread-ai/mxbai-embed-2d-large-v1 (For OpenAIs text-embedding-3-large, we see a performance retention of 93.1% at 12x compression. For nomic's model, we retain 95.8% of performance at 3x compression and 90% at 6x compression.).
However, there is another new approach to achieve progress on this challenge; it does not entail dimensionality reduction, but rather a reduction in the size of each of the individual values in the embedding: Quantization. Our experiments on quantization will show that we can maintain a large amount of performance while significantly speeding up computation and saving on memory, storage, and costs. Let's dive into it!
Binary Quantization
Unlike quantization in models where you reduce the precision of weights, quantization for embeddings refers to a post-processing step for the embeddings themselves. In particular, binary quantization refers to the conversion of the float32 values in an embedding to 1-bit values, resulting in a 32x reduction in memory and storage usage.
To quantize float32 embeddings to binary, we simply threshold normalized embeddings at 0:
We can use the Hamming Distance to retrieve these binary embeddings efficiently. This is the number of positions at which the bits of two binary embeddings differ. The lower the Hamming Distance, the closer the embeddings; thus, the more relevant the document. A huge advantage of the Hamming Distance is that it can be easily calculated with 2 CPU cycles, allowing for blazingly fast performance.
Yamada et al. (2021) introduced a rescore step, which they called rerank, to boost the performance. They proposed that the float32 query embedding could be compared with the binary document embeddings using dot-product. In practice, we first retrieve rescore_multiplier * top_k results with the binary query embedding and the binary document embeddings -- i.e., the list of the first k results of the double-binary retrieval -- and then rescore that list of binary document embeddings with the float32 query embedding.
By applying this novel rescoring step, we are able to preserve up to ~96% of the total retrieval performance, while reducing the memory and disk space usage by 32x and improving the retrieval speed by up to 32x as well. Without the rescoring, we are able to preserve roughly ~92.5% of the total retrieval performance.
Binary Quantization in Sentence Transformers
Quantizing an embedding with a dimensionality of 1024 to binary would result in 1024 bits. In practice, it is much more common to store bits as bytes instead, so when we quantize to binary embeddings, we pack the bits into bytes using np.packbits.
Therefore, quantizing a float32 embedding with a dimensionality of 1024 yields an int8 or uint8 embedding with a dimensionality of 128. See two approaches of how you can produce quantized embeddings using Sentence Transformers below:
from sentence_transformers import SentenceTransformer
# 1. Load an embedding model
model = SentenceTransformer("mixedbread-ai/mxbai-embed-large-v1")
# 2a. Encode some text using "binary" quantization
binary_embeddings = model.encode(
["I am driving to the lake.", "It is a beautiful day."],
precision="binary",
)
or
from sentence_transformers import SentenceTransformer
from sentence_transformers.quantization import quantize_embeddings
# 1. Load an embedding model
model = SentenceTransformer("mixedbread-ai/mxbai-embed-large-v1")
# 2b. or, encode some text without quantization & apply quantization afterwards
embeddings = model.encode(["I am driving to the lake.", "It is a beautiful day."])
binary_embeddings = quantize_embeddings(embeddings, precision="binary")
References:
Here, you can see the differences between default float32 embeddings and binary embeddings in terms of shape, size, and numpy dtype:
>>> embeddings.shape
(2, 1024)
>>> embeddings.nbytes
8192
>>> embeddings.dtype
float32
>>> binary_embeddings.shape
(2, 128)
>>> binary_embeddings.nbytes
256
>>> binary_embeddings.dtype
int8
Note that you can also choose "ubinary" to quantize to binary using the unsigned uint8 data format. This may be a requirement depending on your vector library/database.
Binary Quantization in Vector Databases
| Vector Databases | Support |
|---|---|
| Faiss | Yes |
| USearch | Yes |
| Vespa AI | Yes |
| Milvus | Yes |
| Qdrant | Through Binary Quantization |
| Weaviate | Through Binary Quantization |
Scalar (int8) Quantization
We use a scalar quantization process to convert the float32 embeddings into int8. This involves mapping the continuous range of float32 values to the discrete set of int8 values, which can represent 256 distinct levels (from -128 to 127), as shown in the image below. This is done by using a large calibration dataset of embeddings. We compute the range of these embeddings, i.e., the min and max of each embedding dimension. From there, we calculate the steps (buckets) to categorize each value.
To further boost the retrieval performance, you can optionally apply the same rescoring step as for the binary embeddings. It is important to note that the calibration dataset greatly influences performance since it defines the quantization buckets.
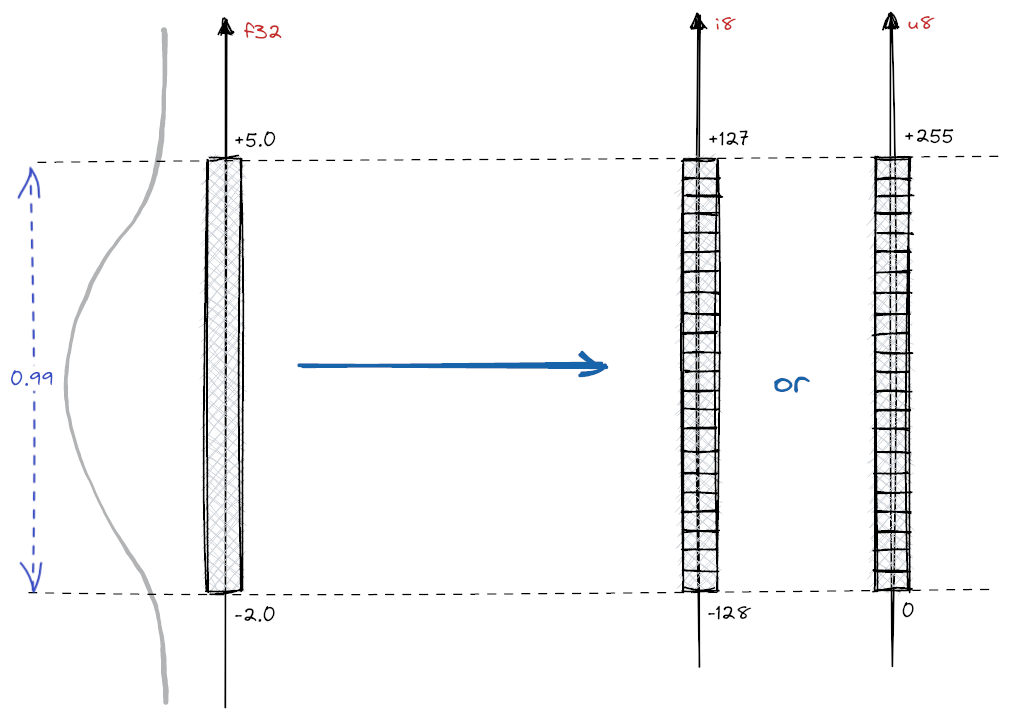 Source: https://qdrant.tech/articles/scalar-quantization/
Source: https://qdrant.tech/articles/scalar-quantization/
With scalar quantization to int8, we reduce the original float32 embeddings' precision so that each value is represented with an 8-bit integer (4x smaller). Note that this differs from the binary quantization case, where each value is represented by a single bit (32x smaller).
Scalar Quantization in Sentence Transformers
Quantizing an embedding with a dimensionality of 1024 to int8 results in 1024 bytes. In practice, we can choose either uint8 or int8. This choice is usually made depending on what your vector library/database supports.
In practice, it is recommended to provide the scalar quantization with either:
- a large set of embeddings to quantize all at once, or
minandmaxranges for each of the embedding dimensions, or- a large calibration dataset of embeddings from which the
minandmaxranges can be computed.
If none of these are the case, you will be given a warning like this:
Computing int8 quantization buckets based on 2 embeddings. int8 quantization is more stable with 'ranges' calculated from more embeddings or a 'calibration_embeddings' that can be used to calculate the buckets.
See how you can produce scalar quantized embeddings using Sentence Transformers below:
from sentence_transformers import SentenceTransformer
from sentence_transformers.quantization import quantize_embeddings
from datasets import load_dataset
# 1. Load an embedding model
model = SentenceTransformer("mixedbread-ai/mxbai-embed-large-v1")
# 2. Prepare an example calibration dataset
corpus = load_dataset("nq_open", split="train[:1000]")["question"]
calibration_embeddings = model.encode(corpus)
# 3. Encode some text without quantization & apply quantization afterwards
embeddings = model.encode(["I am driving to the lake.", "It is a beautiful day."])
int8_embeddings = quantize_embeddings(
embeddings,
precision="int8",
calibration_embeddings=calibration_embeddings,
)
References:
Here you can see the differences between default float32 embeddings and int8 scalar embeddings in terms of shape, size, and numpy dtype:
>>> embeddings.shape
(2, 1024)
>>> embeddings.nbytes
8192
>>> embeddings.dtype
float32
>>> int8_embeddings.shape
(2, 1024)
>>> int8_embeddings.nbytes
2048
>>> int8_embeddings.dtype
int8
Scalar Quantization in Vector Databases
| Vector Databases | Support |
|---|---|
| Faiss | Indirectly through IndexHNSWSQ |
| USearch | Yes |
| Vespa AI | Yes |
| OpenSearch | Yes |
| ElasticSearch | Yes |
| Milvus | Indirectly through IVF_SQ8 |
| Qdrant | Indirectly through Scalar Quantization |
Combining Binary and Scalar Quantization
Combining binary and scalar quantization is possible to get the best of both worlds: the extreme speed from binary embeddings and the great performance preservation of scalar embeddings with rescoring. See the demo below for a real-life implementation of this approach involving 41 million texts from Wikipedia. The pipeline for that setup is as follows:
- The query is embedded using the
mixedbread-ai/mxbai-embed-large-v1SentenceTransformer model. - The query is quantized to binary using the
quantize_embeddingsfunction from thesentence-transformerslibrary. - A binary index (41M binary embeddings; 5.2GB of memory/disk space) is searched using the quantized query for the top 40 documents.
- The top 40 documents are loaded on the fly from an int8 index on disk (41M int8 embeddings; 0 bytes of memory, 47.5GB of disk space).
- The top 40 documents are rescored using the float32 query and the int8 embeddings to get the top 10 documents.
- The top 10 documents are sorted by score and displayed.
Through this approach, we use 5.2GB of memory and 52GB of disk space for the indices. This is considerably less than normal retrieval, requiring 200GB of memory and 200GB of disk space. Especially as you scale up even further, this will result in notable reductions in latency and costs.
Quantization Experiments
We conducted our experiments on the retrieval subset of the MTEB containing 15 benchmarks. First, we retrieved the top k (k=100) search results with a rescore_multiplier of 4. Therefore, we retrieved 400 results in total and performed the rescoring on these top 400. For the int8 performance, we directly used the dot-product without any rescoring.
| Model | Embedding Dimension | 250M Embeddings | MTEB Retrieval (NDCG@10) | Percentage of default performance |
|---|---|---|---|---|
| Open Models | ||||
| mxbai-embed-large-v1: float32 | 1024 | 953.67GB $3623 / mo |
54.39 | 100% |
| mxbai-embed-large-v1: int8 | 1024 | 238.41GB $905 / mo |
52.79 | 97% |
| mxbai-embed-large-v1: binary | 1024 | 29.80GB $113.25 / mo |
52.46 | 96.45% |
| e5-base-v2: float32 | 768 | 286.10GB $1087 / mo |
50.77 | 100% |
| e5-base-v2: int8 | 768 | 178.81GB $679 / mo |
47.54 | 94.68% |
| e5-base-v2: binary | 768 | 22.35GB $85 / mo |
37.96 | 74.77% |
| nomic-embed-text-v1.5: float32 | 768 | 286.10GB $1087 / mo |
53.01 | 100% |
| nomic-embed-text-v1.5: binary | 768 | 22.35GB $85 / mo |
46.49 | 87.7% |
| all-MiniLM-L6-v2: float32 | 384 | 357.62GB $1358 / mo |
41.66 | 100% |
| all-MiniLM-L6-v2: int8 | 384 | 89.40GB $339 / mo |
37.82 | 90.79% |
| all-MiniLM-L6-v2: binary | 384 | 11.18GB $42 / mo |
39.07 | 93.79% |
| Proprietary Models | ||||
| Cohere-embed-english-v3.0: float32 | 1024 | 953.67GB $3623 / mo |
55.0 | 100% |
| Cohere-embed-english-v3.0: int8 | 1024 | 238.41GB $905 / mo |
55.0 | 100% |
| Cohere-embed-english-v3.0: binary | 1024 | 29.80GB $113.25 / mo |
52.3 | 94.6% |
Several key trends and benefits can be identified from the results of our quantization experiments. As expected, embedding models with higher dimension size typically generate higher storage costs per computation but achieve the best performance. Surprisingly, however, quantization to int8 already helps mxbai-embed-large-v1 and Cohere-embed-english-v3.0 achieve higher performance with lower storage usage than that of the smaller dimension size base models.
The benefits of quantization are, if anything, even more clearly visible when looking at the results obtained with binary models. In that scenario, the 1024 dimension models still outperform a now 10x more storage intensive base model, and the mxbai-embed-large-v1 even manages to hold more than 96% of performance after a 32x reduction in resource requirements. The further quantization from int8 to binary barely results in any additional loss of performance for this model.
Interestingly, we can also see that all-MiniLM-L6-v2 exhibits stronger performance on binary than on int8 quantization. A possible explanation for this could be the selection of calibration data. On e5-base-v2, we observe the effect of dimension collapse, which causes the model to only use a subspace of the latent space; when performing the quantization, the whole space collapses further, leading to high performance losses.
This shows that quantization doesn't universally work with all embedding models. It remains crucial to consider exisiting benchmark outcomes and conduct experiments to determine a given model's compatibility with quantization.
Influence of Rescoring
In this section we look at the influence of rescoring on retrieval performance. We evaluate the results based on mxbai-embed-large-v1.
Binary Rescoring
With binary embeddings, mxbai-embed-large-v1 retains 92.53% of performance on MTEB Retrieval. Just doing the rescoring without retrieving more samples pushes the performance to 96.45%. We experimented with setting therescore_multiplier from 1 to 10, but observe no further boost in performance. This indicates that the top_k search already retrieved the top candidates and the rescoring reordered these good candidates appropriately.
Scalar (Int8) Rescoring
We also evaluated the mxbai-embed-large-v1 model with int8 rescoring, as Cohere showed that Cohere-embed-english-v3.0 reached up to 100% of the performance of the float32 model with int8 quantization. For this experiment, we set the rescore_multiplier to [1, 4, 10] and got the following results:
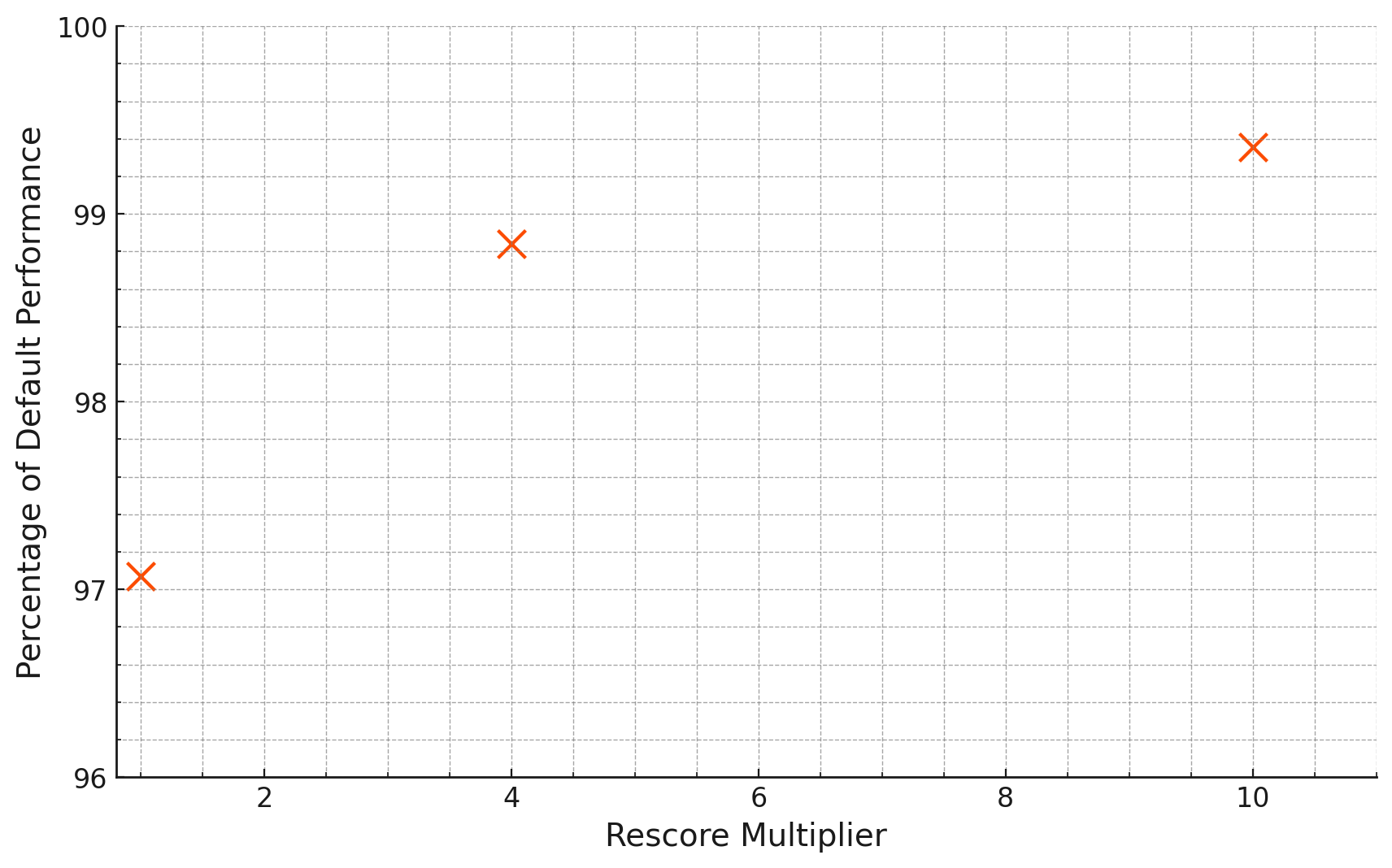
As we can see from the diagram, a higher rescore multiplier implies better retention of performance after quantization. Extrapolating from our results, we assume the relation is likely hyperbolical with performance approaching 100% as the rescore multiplier continues to rise. A rescore multiplier of 4-5 already leads to a remarkable performance retention of 99% using int8.
Retrieval Speed
We measured retrieval speed on a Google Cloud Platform a2-highgpu-4g instance using the mxbai-embed-large-v1 embeddings with 1024 dimension on the whole MTEB Retrieval. For int8 we used USearch (Version 2.9.2) and binary quantization Faiss (Version 1.8.0). Everything was computed on CPU using exact search.
| Quantization | Min | Mean | Max |
|---|---|---|---|
float32 |
1x (baseline) | 1x (baseline) | 1x (baseline) |
int8 |
2.99x speedup | 3.66x speedup | 4.8x speedup |
binary |
15.05x speedup | 24.76x speedup | 45.8x speedup |
As shown in the table, applying int8 scalar quantization results in an average speedup of 3.66x compared to full-size float32 embeddings. Additionally, binary quantization achieves a speedup of 24.76x on average. For both scalar and binary quantization, even the worst case scenario resulted in very notable speedups.
Performance Summarization
The experimental results, effects on resource use, retrieval speed, and retrieval performance by using quantization can be summarized as follows:
| float32 | int8/uint8 | binary/ubinary | |
|---|---|---|---|
| Memory & Index size savings | 1x | exactly 4x | exactly 32x |
| Retrieval Speed | 1x | up to 4x | up to 45x |
| Percentage of default performance | 100% | ~99.3% | ~96% |
Demo
The following demo showcases the retrieval efficiency using exact or approximate search by combining binary search with scalar (int8) rescoring. The solution requires 5GB of memory for the binary index and 50GB of disk space for the binary and scalar indices, considerably less than the 200GB of memory and disk space which would be required for regular float32 retrieval. Additionally, retrieval is much faster.
Try it yourself
The following scripts can be used to experiment with embedding quantization for retrieval & beyond. There are three categories:
- Recommended Retrieval:
- semantic_search_recommended.py: This script combines binary search with scalar rescoring, much like the above demo, for cheap, efficient, and performant retrieval.
- Usage:
- semantic_search_faiss.py: This script showcases regular usage of binary or scalar quantization, retrieval, and rescoring using FAISS, by using the
semantic_search_faissutility function. - semantic_search_usearch.py: This script showcases regular usage of binary or scalar quantization, retrieval, and rescoring using USearch, by using the
semantic_search_usearchutility function.
- semantic_search_faiss.py: This script showcases regular usage of binary or scalar quantization, retrieval, and rescoring using FAISS, by using the
- Benchmarks:
- semantic_search_faiss_benchmark.py: This script includes a retrieval speed benchmark of
float32retrieval, binary retrieval + rescoring, and scalar retrieval + rescoring, using FAISS. It uses thesemantic_search_faissutility function. Our benchmarks especially show show speedups forubinary. - semantic_search_usearch_benchmark.py: This script includes a retrieval speed benchmark of
float32retrieval, binary retrieval + rescoring, and scalar retrieval + rescoring, using USearch. It uses thesemantic_search_usearchutility function. Our experiments show large speedups on newer hardware, particularly forint8.
- semantic_search_faiss_benchmark.py: This script includes a retrieval speed benchmark of
Future work
We are looking forward to further advancements of binary quantization. To name a few potential improvements, we suspect that there may be room for scalar quantization smaller than int8, i.e. with 128 or 64 buckets instead of 256.
Additionally, we are excited that embedding quantization is fully perpendicular to Matryoshka Representation Learning (MRL). In other words, it is possible to shrink MRL embeddings from e.g. 1024 to 128 (which usually corresponds with a 2% reduction in performance) and then apply binary or scalar quantization. We suspect this could speed up retrieval up to 32x for a ~3% reduction in quality, or up to 256x for a ~10% reduction in quality.
Lastly, we recognize that retrieval using embedding quantization can also be combined with a separate reranker model. We imagine that a 3-step pipeline of binary search, scalar (int8) rescoring, and cross-encoder reranking allows for state-of-the-art retrieval performance at low latencies, memory usage, disk space, and costs.
Acknowledgments
This project is possible thanks to our collaboration with mixedbread.ai and the SentenceTransformers library, which allows you to easily create sentence embeddings and quantize them. If you want to use quantized embeddings in your project, now you know how!
Citation
@article{shakir2024quantization,
author = { Aamir Shakir and
Tom Aarsen and
Sean Lee
},
title = { Binary and Scalar Embedding Quantization for Significantly Faster & Cheaper Retrieval },
journal = {Hugging Face Blog},
year = {2024},
note = {https://huggingface.co/blog/embedding-quantization},
}
Resources
mixedbread-ai/mxbai-embed-large-v1SentenceTransformer.encodequantize_embeddings- Sentence Transformers docs - Embedding Quantization
- https://txt.cohere.com/int8-binary-embeddings/
- https://qdrant.tech/documentation/guides/quantization
- https://zilliz.com/learn/scalar-quantization-and-product-quantization
Companion Blogposts
To train the embedding models you're quantizing, or to stack quantization with other efficiency techniques:
- Training and Finetuning Embedding Models with Sentence Transformers: train the bi-encoder that produces the embeddings you want to quantize.
- Training and Finetuning Reranker Models with Sentence Transformers: Cross Encoder training for the rescoring step that pairs well with binary/int8 retrieval.
- Training and Finetuning Sparse Embedding Models with Sentence Transformers: SPLADE training, another axis for cheap retrieval.
- Multimodal Embedding & Reranker Models with Sentence Transformers and Training and Finetuning Multimodal Embedding & Reranker Models: multimodal embedding models can also be quantized.
- 🪆 Introduction to Matryoshka Embedding Models: truncate the embedding dimensionality first, then quantize the smaller vector so both reductions apply.
- Train 400x faster Static Embedding Models with Sentence Transformers: another route to cheap retrieval, trading model quality for throughput instead of bits-per-dim.















