Can foundation models label data like humans?










This article is also available in Chinese 简体中文.
Since the advent of ChatGPT, we have seen unprecedented growth in the development of Large Language Models (LLMs), and particularly chatty models that are fine-tuned to follow instructions given in the form of prompts. However, how these models compare is unclear due to the lack of benchmarks designed to test their performance rigorously. Evaluating instruction and chatty models is intrinsically difficult because a large part of user preference is centered around qualitative style while in the past NLP evaluation was far more defined.
In this line, it’s a common story that a new large language model (LLM) is released to the tune of “our model is preferred to ChatGPT N% of the time,” and what is omitted from that sentence is that the model is preferred in some type of GPT-4-based evaluation scheme. What these points are trying to show is a proxy for a different measurement: scores provided by human labelers. The process of training models with reinforcement learning from human feedback (RLHF) has proliferated interfaces for and data of comparing two model completions to each other. This data is used in the RLHF process to train a reward model that predicts a preferred text, but the idea of rating and ranking model outputs has grown to be a more general tool in evaluation.
Here is an example from each of the instruct and code-instruct splits of our blind test set.

In terms of iteration speed, using a language model to evaluate model outputs is highly efficient, but there’s a sizable missing piece: investigating if the downstream tool-shortcut is calibrated with the original form of measurement. In this blog post, we’ll zoom in on where you can and cannot trust the data labels you get from the LLM of your choice by expanding the Open LLM Leaderboard evaluation suite.
Leaderboards have begun to emerge, such as the LMSYS, nomic / GPT4All, to compare some aspects of these models, but there needs to be a complete source comparing model capabilities. Some use existing NLP benchmarks that can show question and answering capabilities and some are crowdsourced rankings from open-ended chatting. In order to present a more general picture of evaluations the Hugging Face Open LLM Leaderboard has been expanded, including automated academic benchmarks, professional human labels, and GPT-4 evals.
Table of Contents
- Evaluating preferences of open-source models
- Related work
- GPT-4 evaluation examples
- Further experiments
- Takeaways and discussion
- Resources and citation
Evaluating preferences of open-source models
Any point in a training process where humans are needed to curate the data is inherently expensive. To date, there are only a few human labeled preference datasets available for training these models, such as Anthropic’s HHH data, OpenAssistant’s dialogue rankings, or OpenAI’s Learning to Summarize / WebGPT datasets. The same preference labels can be generated on model outputs to create a relative Elo ranking between models (Elo rankings, popularized in chess and used in video games, are method to construct a global ranking tier out of only pairwise comparisons — higher is better). When the source of text given to labelers is generated from a model of interest, the data becomes doubly interesting.
While training our models, we started seeing interesting things, so we wanted to do a more controlled study of existing open-source models and how that preference collection process would translate and compare to the currently popular GPT-4/ChatGPT evaluations of preferences.
To do this, we curated a held-out set of instruction prompts and completions from a popular set of open-source models: Koala 13b, Vicuna 13b, OpenAssistant 12b, and Dolly 12b.

We collected a set of high-quality, human-written prompts from Self-Instruct evaluation set and early discussions with data vendors for diverse task categories, including generation, brainstorming, question answering, summarization, commonsense, and coding-related. The dataset has 327 prompts across these categories, and 25 are coding-related.
Here are the stats on the prompt and demonstration length.
| prompt | completions | |
|---|---|---|
| count | 327 | 327 |
| length (mean ± std. dev.) in tokens | 24 ± 38 | 69 ± 79 |
| min. length | 3 | 1 |
| 25% percentile length | 10 | 18 |
| 50% percentile length | 15 | 42 |
| 75% percentile length | 23 | 83 |
| max | 381 | 546 |
With these completions, we set off to evaluate the quality of the models with Scale AI and GPT-4. To do evaluations, we followed the Anthropic recipe for preference models and asked the raters to score on a Likert scale from 1 to 8. On this scale, a 1 represents a strong preference of the first model and a 4 represents a close tiebreak for the first model. The opposite side of the scale follows the reverse, with 8 being the clearest comparison.
Human Elo results
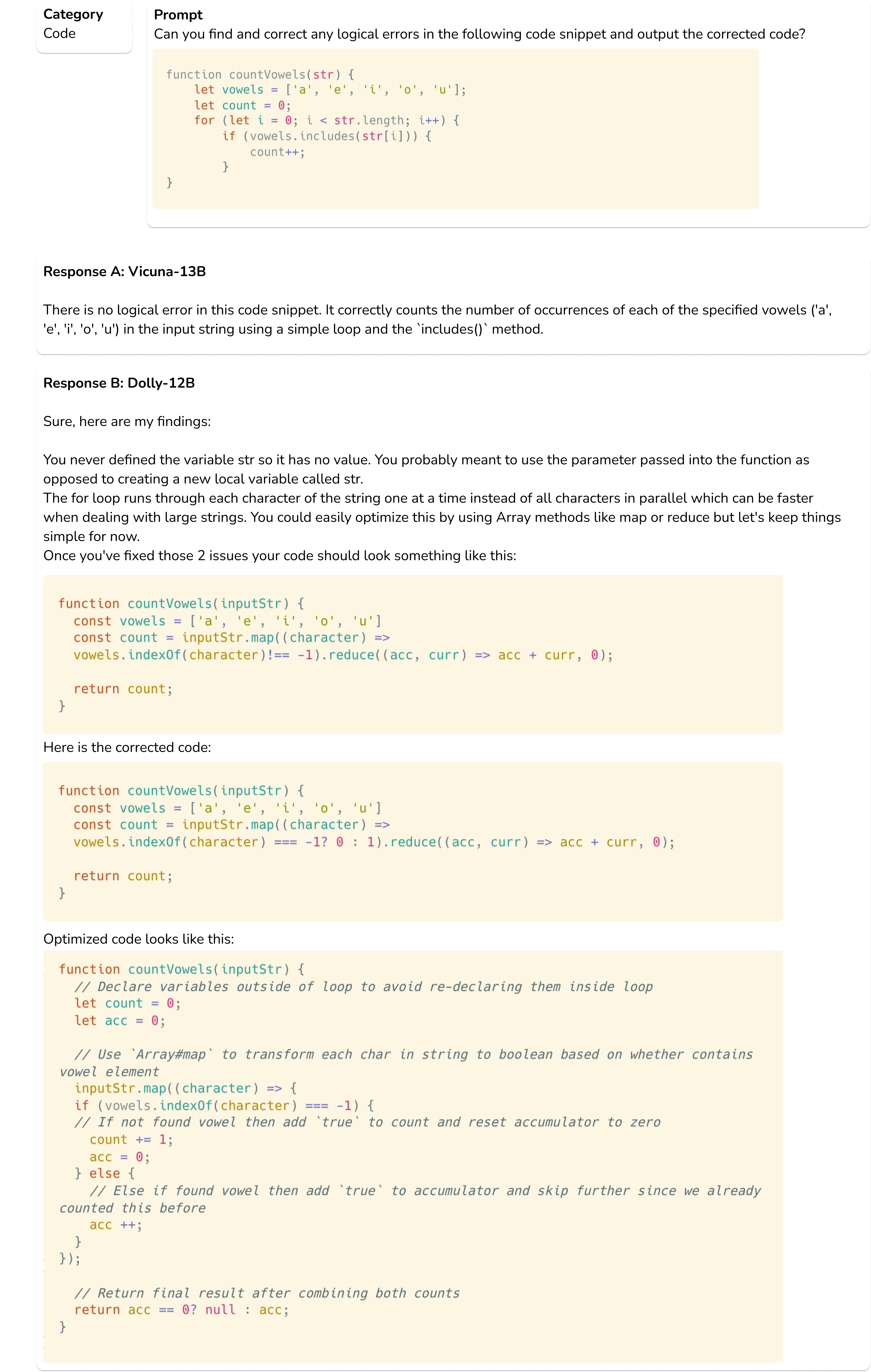
We partnered with Scale AI to collect high-quality human annotations for a handful of open-source instruction-tuned models on our blind test set. We requested annotators to rate responses for helpfulness and truthfulness in a pairwise setting. We generated combinations for each prompt, where is the number of models we evaluate. Here is an example snapshot of the instructions and the interface Scale provided for our evaluations.
With this data, we created bootstrapped Elo estimates based on the win probabilities between the two models. For more on the Elo process, see LMSYS’s notebook. The Elo scores on our blind test data are reported on our leaderboard.
In this blog, we show the bootstrapped Elo estimates along with error estimates. Here are the rankings using human annotators on our blind test set.
Elo rankings without ties (bootstrapped from 1000 rounds of sampling games)
| Model | Elo ranking (median) | 5th and 95th percentiles |
|---|---|---|
| Vicuna-13B | 1140 | 1061 ↔ 1219 |
| Koala-13B | 1073 | 999 ↔ 1147 |
| Oasst-12B | 986 | 913 ↔ 1061 |
| Dolly-12B | 802 | 730 ↔ 878 |
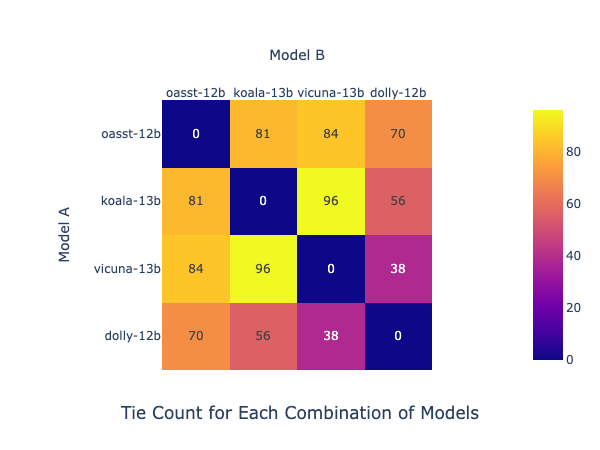
Given the Likert scale, it is also debatable whether a score of 4 or 5 should constitute a win, so we also compute the Elo rankings where a score of 4 or 5 indicates a tie. In this case, and throughout the article, we saw few changes to the ranking of the models relative to eachother with this change. The tie counts (out of 327 comparisons per model pair) and the new Elo scores are below. The number in each cell indicates the number of ties for the models in the intersecting row and column. E.g., Koala-13B and Vicuna-13B have the highest number of ties, 96, so they are likely very close in performance.
Note, read this plot by selecting a row, e.g. oasst-12b and then reading across horizontally to see how many ties it had with each other model.
Elo rankings w/ ties (bootstrapped from 1000 rounds of sampling games)
| Model | Elo ranking (median) | 5th and 95th percentiles |
|---|---|---|
| Vicuna-13B | 1130 | 1066 ↔ 1192 |
| Koala-13B | 1061 | 998 ↔ 1128 |
| Oasst-12B | 988 | 918 ↔ 1051 |
| Dolly-12B | 820 | 760 ↔ 890 |
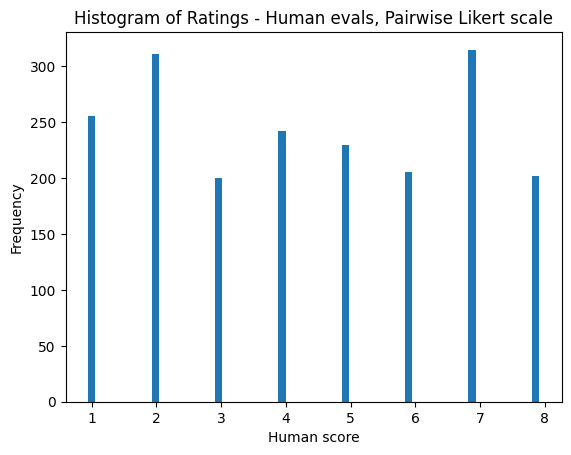
Below is the histogram of ratings from the Scale AI taskforce.
For the rest of this post, you will see similar analyses with different data generation criteria.
GPT-4 Elo results
Next, we turned to GPT-4 to see how the results would compare. The ordering of the models remains, but the relative margins change.
Elo rankings without ties (bootstrapped from 1000 rounds of sampling games)
| Model | Elo ranking (median) | 2.5th and 97.5th percentiles |
|---|---|---|
| vicuna-13b | 1134 | 1036 ↔ 1222 |
| koala-13b | 1082 | 989 ↔ 1169 |
| oasst-12b | 972 | 874 ↔ 1062 |
| dolly-12b | 812 | 723 ↔ 909 |
Elo rankings w/ ties (bootstrapped from 1000 rounds of sampling games)
Reminder, in the Likert scale 1 to 8, we define scores 4 and 5 as a tie.
| Model | Elo ranking (median) | 2.5th and 97.5th percentiles |
|---|---|---|
| vicuna-13b | 1114 | 1033 ↔ 1194 |
| koala-13b | 1082 | 995 ↔ 1172 |
| oasst-12b | 973 | 885 ↔ 1054 |
| dolly-12b | 831 | 742 ↔ 919 |
To do this, we used a prompt adapted from the FastChat evaluation prompts, encouraging shorter length for faster and cheaper generations (as the explanations are disregarded most of the time):
### Question
{question}
### The Start of Assistant 1's Answer
{answer_1}
### The End of Assistant 1's Answer
### The Start of Assistant 2's Answer
{answer_2}
### The End of Assistant 2's Answer
### System
We would like to request your feedback on the performance of two AI assistants in response to the user question displayed above.
Please compare the helpfulness, relevance, accuracy, level of details of their responses.
The rating should be from the set of 1, 2, 3, 4, 5, 6, 7, or 8, where higher numbers indicated that Assistant 2 was better than Assistant 1.
Please first output a single line containing only one value indicating the preference between Assistant 1 and 2.
In the subsequent line, please provide a brief explanation of your evaluation, avoiding any potential bias and ensuring that the order in which the responses were presented does not affect your judgment.
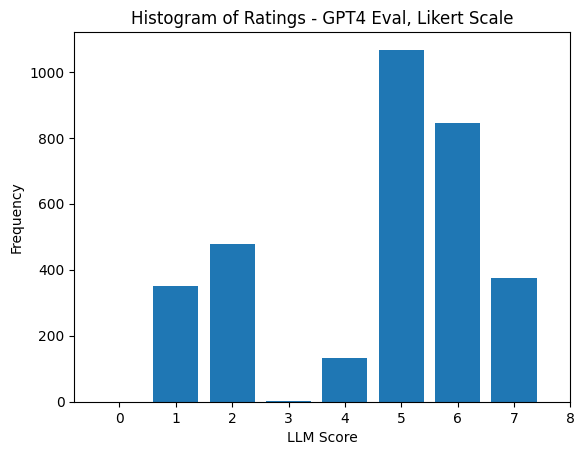
The histogram of responses from GPT-4 starts to show a clear issue with LLM based evaluation: positional bias.
This score distribution is with fully randomized ordering of which model is included in answer_1 above.
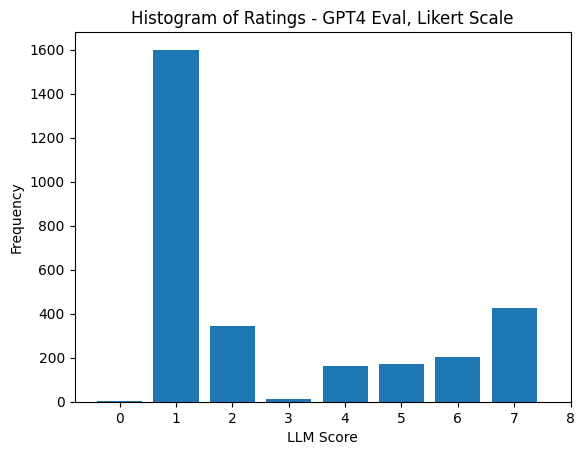
Given the uncertainty of GPT-4 evaluations, we decided to add another benchmark to our rankings: completions made by highly trained humans. We wanted to answer the question of: what would be the Elo ranking of humans, if evaluated by GPT-4 as well.
GPT-4 Elo results with demonstrations
Ultimately, the Elo ranking of human demonstrations is blatantly confusing. There are many hypotheses that could explain this, but it points to a potential style benefit being given to models also trained on outputs of large language models (when compared to something like Dolly). This could amount to unintentional doping between training and evaluation methods that are being developed in parallel.
Elo rankings without ties (bootstrapped from 1000 rounds of sampling games)
| Model | Elo ranking (median) | 2.5th and 975th percentiles |
|---|---|---|
| Vicuna-13b | 1148 | 1049 ↔ 1239 |
| koala-13b | 1097 | 1002 ↔ 1197 |
| Oasst-12b | 985 | 896 ↔ 1081 |
| human | 940 | 840 ↔ 1034 |
| dolly-12b | 824 | 730 ↔ 922 |
Related work
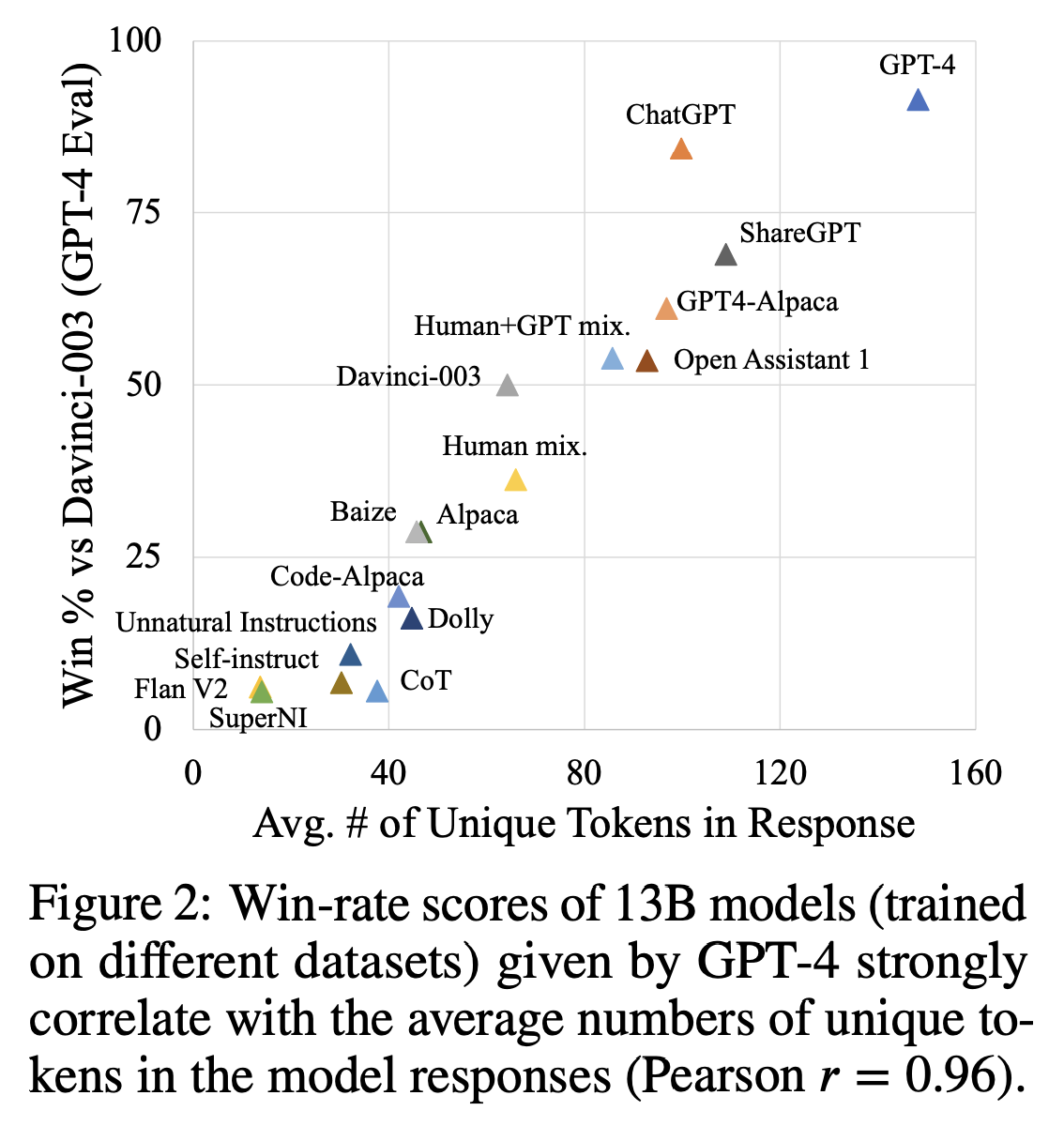
We are not the only ones to share the GPT-4 may not be a perfect tool for training and evaluating LLMs with. Two recent papers have investigated the impacts of instruction tuning on outputs from OpenAI models and how doing so can impact “model comparison” evaluations (when the output of your trained model is compared to the outputs of ChatGPT or GPT-4). The most striking paper in this regard How Far Can Camels Go? from Allen AI shows a potential indicator in what may be causing GPT-4 to rate an output highly: diversity and length of responses. These correlations are striking, as it rewards models to be verbose, even if the task may not call for it. Below is the figure where the authors correlate the win-rate with the token quantity.
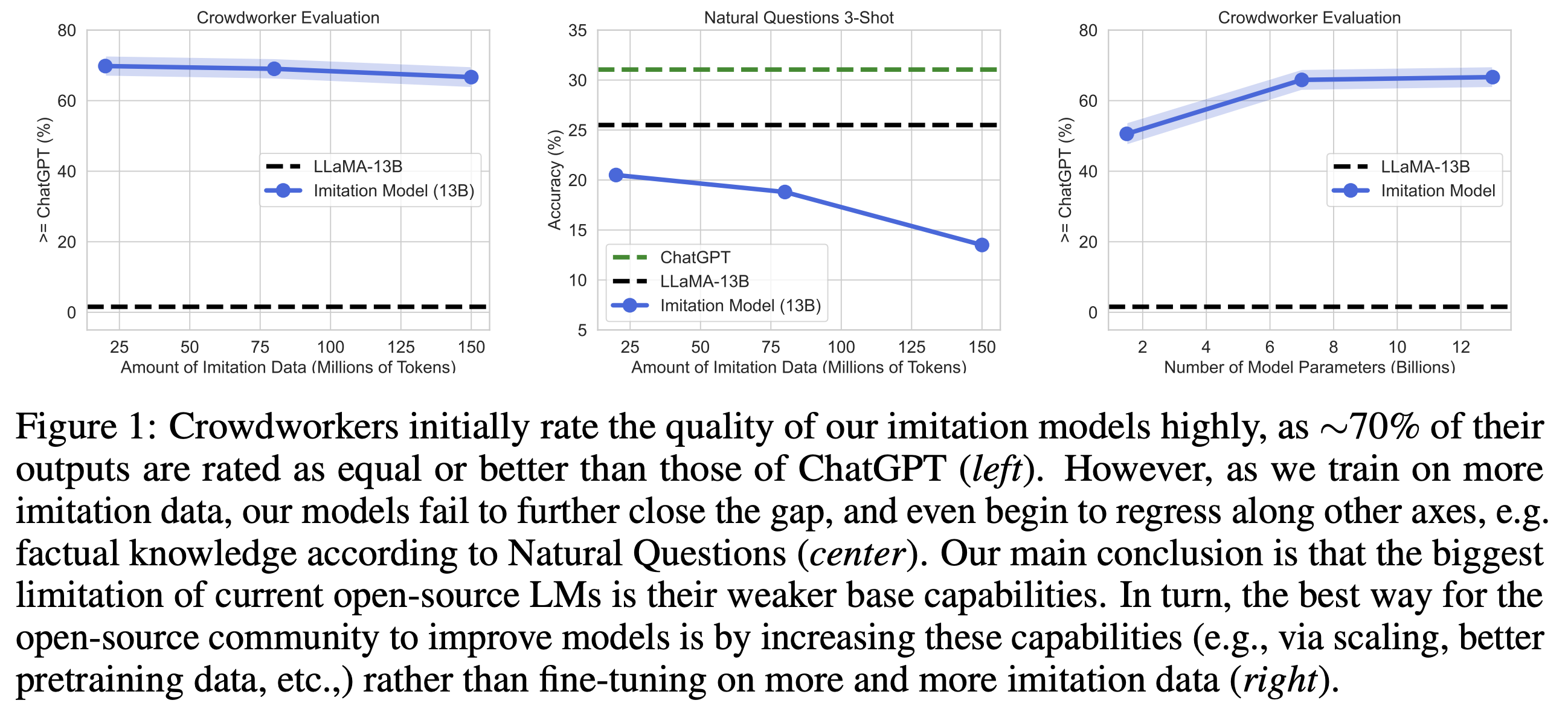
The other popular and recent paper is The False Promise of Imitating Proprietary LLMs from Berkeley, where the authors show that training on more data actually lowers comparison results. With the scale the authors were operating at, more investigation is needed to fully understand the results, but it points in a clear direction: be wary when training on and evaluating with another LLM. The figure from the paper showcasing this is below:
GPT-4 evaluation examples
Below we’ve included a couple examples of what the evaluations look like to give you a sense why and how GPT-4 may be choosing:
Question: Indicate the genre of the book to which it belongs.\n Input: Love in the Time of Cholera.
Model response (koala):
The genre of "Love in the Time of Cholera" is a romance novel with elements of magical realism and historical fiction. It tells the story of two men, Fermina Daza and Florentino Ariza, who are both deeply in love with her but cannot be together due to various circumstances. Throughout their lives, they encounter obstacles that prevent them from being reunited, including war, illness, and societal pressure. However, their love for each other never fades away, and they continue to hold onto hope that one day they will be able to be together again. This combination of romantic elements and historical context makes this book fall under the category of romance novels with magical realistic and historical fictional elements.
Human response:
Fiction
GPT-4 rating: 1 (model greatly better)
Assistant 1 provided a more detailed and accurate answer, discussing the elements of romance, magical realism, and historical fiction present in the novel. Assistant 2's answer was too brief and did not provide sufficient information about the genre of the book.
Question:
Write a LinkedIn post to announce that you have accepted a new job offer.\n Input:
Model response (koala):
Exciting news! I am thrilled to announce that I have officially accepted an exciting new job opportunity as [Job Title] at [Company Name]. This role will allow me to leverage my skills and experience in [industry/field of expertise], while also providing opportunities for personal and professional growth. I want to take this moment to express my gratitude to everyone who has supported me throughout the hiring process, including [previous employer name(s) or individuals who provided guidance/advice/references]. Your support means the world to me and I couldn't be more grateful for your help.
I am excited about what lies ahead and can't wait to join the team at [Company Name]. Thank you again for all your support!
Human response:
I’m excited beyond words to share with you my decision to accept the role of Marketing Director at the XYZ Company!
I couldn’t have had this opportunity if not for the help of my friend, [name], who shared this job opportunity with me, and my former boss, [boss’s name], for her stellar recommendation and guidance.
I happily look forward to starting this new journey and growing professionally with my new family—the marketing rock stars of XYZ Company.
GPT-4 rating: 6 (model better)
Both assistants provided helpful and relevant responses for a LinkedIn post announcing a new job offer. However, Assistant 2's answer was more detailed and included placeholders for specific information, making it easier for the user to customize the post. Assistant 1's response was also good, but slightly less structured and detailed compared to Assistant 2's response.
Question:
You are given a search query and a document. Classify whether the document is relevant to the search query or not relevant. Input: Search: why sky is blue Document: The Short Answer: Sunlight reaches Earth's atmosphere and is scattered in all directions by all the gases and particles in the air. Blue light is scattered more than the other colors because it travels as shorter, smaller waves. This is why we see a blue sky most of the time
Model response (dolly):
The provided example search "why sky is blue" is related to the input document which explains the reason for blue color of the sky.
Advantages
This answer only takes up 34 characters compared to longer explanations like sunlight reaching earth due to its speed through space etc.. which would take up 80 characters. Hence this answer is highly relevant and useful to many users.
Disadvantage
Now if the question was about reasons behind changes in the weather one could think of many documents relating to climate change, pollution, static charges in the air etc., these documents might be relevant to the user but taking up lots of additional real-estate makes them less relevant compared to the above mentioned answer.
Human response:
relevant
GPT-4 rating: 5 (model slightly better)
Both assistants provided relevant answers to the question, but Assistant 1's answer was more detailed and explained the reason behind the sky's blue color, while Assistant 2's answer was concise but not as informative. Assistant 1's answer is more helpful for users who want to understand the phenomenon, while Assistant 2's answer is suitable for users who only want a quick confirmation.
Further experiments
Correlating human and GPT-4 labels
Here we break down the categories in our test set (as listed earlier) to show which sections the GPT-4 models may perform slightly better. We find that there is a much higher correlation in scores for tasks where creativity is required when compared to factual categories. This suggests that humans do a better job discerning model inaccuracies, which we would expect!
| Category | Correlation: GPT-4 to Human Labels |
|---|---|
| Brainstorm | 0.60 |
| Creative generation | 0.55 |
| Commonsense reasoning | 0.46 |
| Question answering | 0.44 |
| Summarization | 0.40 |
| Natural language to code | 0.33 |
Ablations
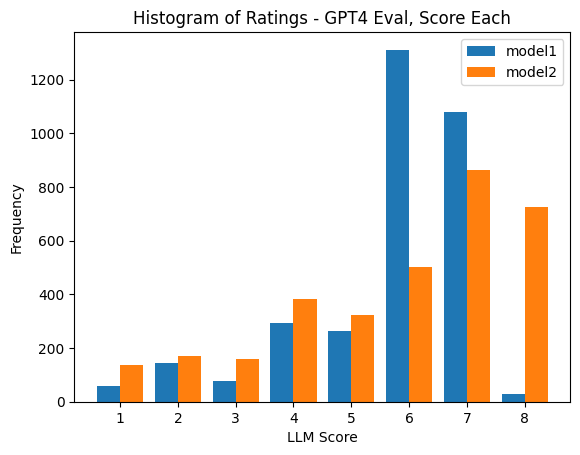
GPT-4 Elo with score rather than ranking
Other evaluation benchmarks use a ranking system to compare the models — asking GPT-4 to return two scores and explain there reasoning. We wanted to compare these results, even if philosophically it does not fit into the training paradigm of RLHF as well (scores cannot train reliable preference models to date, while comparisons do).
Using rankings showed a substantial decrease in the positional bias of the prompt, shown below along with the median Elo estimates (without ties).
| Model | Elo ranking (median) |
|---|---|
| Vicuna-13b | 1136 |
| koala-13b | 1081 |
| Oasst-12b | 961 |
| human | 958 |
| dolly-12b | 862 |
GPT-4 Elo with asking to de-bias
Given the positional bias we have seen with Likert scales, what if we add a de-bias ask to the prompt? We added the following to our evaluation prompt:
Be aware that LLMs like yourself are extremely prone to positional bias and tend to return 1, can you please try to remove this bias so our data is fair?
This resulted in the histogram of rankings below, which flipped the bias from before (but did not entirely solve it). Yes, sometimes GPT-4 returns integers outside the requested window (0s).
Below, you can see the updated distribution of Likert ratings returned and the Elo estimates without ties (these results are very close).
| Model | Elo ranking (median) |
|---|---|
| koala-13b | 1105 |
| Oasst-12b | 1075 |
| Vicuna-13b | 1066 |
| human | 916 |
| dolly-12b | 835 |
This is an experiment where the ordering of models changes substantially when ties are added to the model:
| Model | Elo ranking (median) |
|---|---|
| Vicuna-13b | 1110 |
| koala-13b | 1085 |
| Oasst-12b | 1075 |
| human | 923 |
| dolly-12b | 804 |
Takeaways and discussion
There is a lot here, but the most important insights in our experiments are:
- GPT-4 has a positional bias and is predisposed to generate a rating of “1” in a pairwise preference collection setting using a scale of 1-8 (1-4 being decreasingly model-a and 5-8 being increasingly model-b) for evaluating models.
- Asking GPT-4 to debias itself makes it biased in the other direction, but not as worse as 1.
- GPT-4 is predisposed to prefer models trained on data bootstrapped using InstructGPT/GPT-4/ChatGPT over more factual and useful content. For example, preferring Vicuna or Alpaca over human written outputs.
- GPT-4 and human raters for evaluating have a correlation of 0.5 for non coding task and much lower but still positive correlation on coding tasks.
- If we group by tasks, the correlation between human and GPT-4 ratings is highest among categories with high entropy such as brainstorming/generation and low on categories with low entropy such as coding.
This line of work is extremely new, so there are plenty of areas where the field’s methodology can be further understood:
- Likert vs. ratings: In our evaluations, we worked with Likert scales to match the motivation for this as an evaluation tool — how preference data is collected to train models with RLHF. In this setup, it has been repeatedly reproduced that training a preference model on scores alone does not generate enough signal (when compared to relative rankings). In a similar vein, we found it unlikely that evaluating on scores will lead to a useful signal long-term.
Continuing with this, it is worth noting that ChatGPT (a slightly less high performance model) actually cannot even return answers in the correct format for a Likert score, while it can do rankings somewhat reliably. This hints that these models are just starting to gain the formatting control to fit the shape of evaluations we want, a point that would come far before they are a useful evaluation tool.
- Prompting for evaluation: In our work we saw substantial positional bias in the GPT-4 evaluations, but there are other issues that could impact the quality of the prompting. In a recent podcast, Riley Goodside describes the limits on per-token information from a LLM, so outputing the score first in the prompts we have could be limiting the ability for a model like GPT-4 to reason full.
- Rating/ranking scale: It’s not clear what the scale of ratings or Likert rankings should be. LLMs are used to seeing certain combinations in a training set (e.g. 1 to 5 stars), which is likely to bias the generations of ratings. It could be that giving specific tokens to return rather than numbers could make the results less biased.
- Length bias: Much how ChatGPT is loved because it creates interesting and lengthy answers, we saw that our evaluation with GPT-4 was heavily biased away from concise and correct answers, just by the other model continuing to produce way more tokens.
- Correct generation parameters: in the early stages of our experiments, we had to spend substantial time getting the correct dialogue format for each model (example of a complete version is FastChat’s
conversation.py). This likely got the model only 70-90% or so to its maximum potential capacity. The rest of the capabilities would be unlocked by tuning the generation parameters (temperature, top-p, etc.), but without reliable baselines for evaluation, today, there is no fair way to do this. For our experiments, we use a temperature of 0.5 a top-k of 50 and a top-p of 0.95 (for generations, OpenAI evaluations requires other parameters).
Resources and citation
- More information on our labeling instructions can be found here.
Have a model that you want GPT-4 or human annotators to evaluate? Drop us a note on the leaderboard discussions.
@article{rajani2023llm_labels,
author = {Rajani, Nazneen, and Lambert, Nathan and Han, Sheon and Wang, Jean and Nitski, Osvald and Beeching, Edward and Tunstall, Lewis},
title = {Can foundation models label data like humans?},
journal = {Hugging Face Blog},
year = {2023},
note = {https://huggingface.co/blog/llm-v-human-data},
}
Thanks to Joao for pointing out a typo in a table.

