🤗 PEFT: Parameter-Efficient Fine-Tuning of Billion-Scale Models on Low-Resource Hardware








This article is also available in Chinese 简体中文.
Motivation
Large Language Models (LLMs) based on the transformer architecture, like GPT, T5, and BERT have achieved state-of-the-art results in various Natural Language Processing (NLP) tasks. They have also started foraying into other domains, such as Computer Vision (CV) (VIT, Stable Diffusion, LayoutLM) and Audio (Whisper, XLS-R). The conventional paradigm is large-scale pretraining on generic web-scale data, followed by fine-tuning to downstream tasks. Fine-tuning these pretrained LLMs on downstream datasets results in huge performance gains when compared to using the pretrained LLMs out-of-the-box (zero-shot inference, for example).
However, as models get larger and larger, full fine-tuning becomes infeasible to train on consumer hardware. In addition, storing and deploying fine-tuned models independently for each downstream task becomes very expensive, because fine-tuned models are the same size as the original pretrained model. Parameter-Efficient Fine-tuning (PEFT) approaches are meant to address both problems!
PEFT approaches only fine-tune a small number of (extra) model parameters while freezing most parameters of the pretrained LLMs, thereby greatly decreasing the computational and storage costs. This also overcomes the issues of catastrophic forgetting, a behaviour observed during the full finetuning of LLMs. PEFT approaches have also shown to be better than fine-tuning in the low-data regimes and generalize better to out-of-domain scenarios. It can be applied to various modalities, e.g., image classification and stable diffusion dreambooth.
It also helps in portability wherein users can tune models using PEFT methods to get tiny checkpoints worth a few MBs compared to the large checkpoints of full fine-tuning, e.g., bigscience/mt0-xxl takes up 40GB of storage and full fine-tuning will lead to 40GB checkpoints for each downstream dataset whereas using PEFT methods it would be just a few MBs for each downstream dataset all the while achieving comparable performance to full fine-tuning. The small trained weights from PEFT approaches are added on top of the pretrained LLM. So the same LLM can be used for multiple tasks by adding small weights without having to replace the entire model.
In short, PEFT approaches enable you to get performance comparable to full fine-tuning while only having a small number of trainable parameters.
Today, we are excited to introduce the 🤗 PEFT library, which provides the latest Parameter-Efficient Fine-tuning techniques seamlessly integrated with 🤗 Transformers and 🤗 Accelerate. This enables using the most popular and performant models from Transformers coupled with the simplicity and scalability of Accelerate. Below are the currently supported PEFT methods, with more coming soon:
- LoRA: LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
- Prefix Tuning: P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
- Prompt Tuning: The Power of Scale for Parameter-Efficient Prompt Tuning
- P-Tuning: GPT Understands, Too
Use Cases
We explore many interesting use cases here. These are a few of the most interesting ones:
Using 🤗 PEFT LoRA for tuning
bigscience/T0_3Bmodel (3 Billion parameters) on consumer hardware with 11GB of RAM, such as Nvidia GeForce RTX 2080 Ti, Nvidia GeForce RTX 3080, etc using 🤗 Accelerate's DeepSpeed integration: peft_lora_seq2seq_accelerate_ds_zero3_offload.py. This means you can tune such large LLMs in Google Colab.Taking the previous example a notch up by enabling INT8 tuning of the
OPT-6.7bmodel (6.7 Billion parameters) in Google Colab using 🤗 PEFT LoRA and bitsandbytes:
Stable Diffusion Dreambooth training using 🤗 PEFT on consumer hardware with 11GB of RAM, such as Nvidia GeForce RTX 2080 Ti, Nvidia GeForce RTX 3080, etc. Try out the Space demo, which should run seamlessly on a T4 instance (16GB GPU): smangrul/peft-lora-sd-dreambooth.
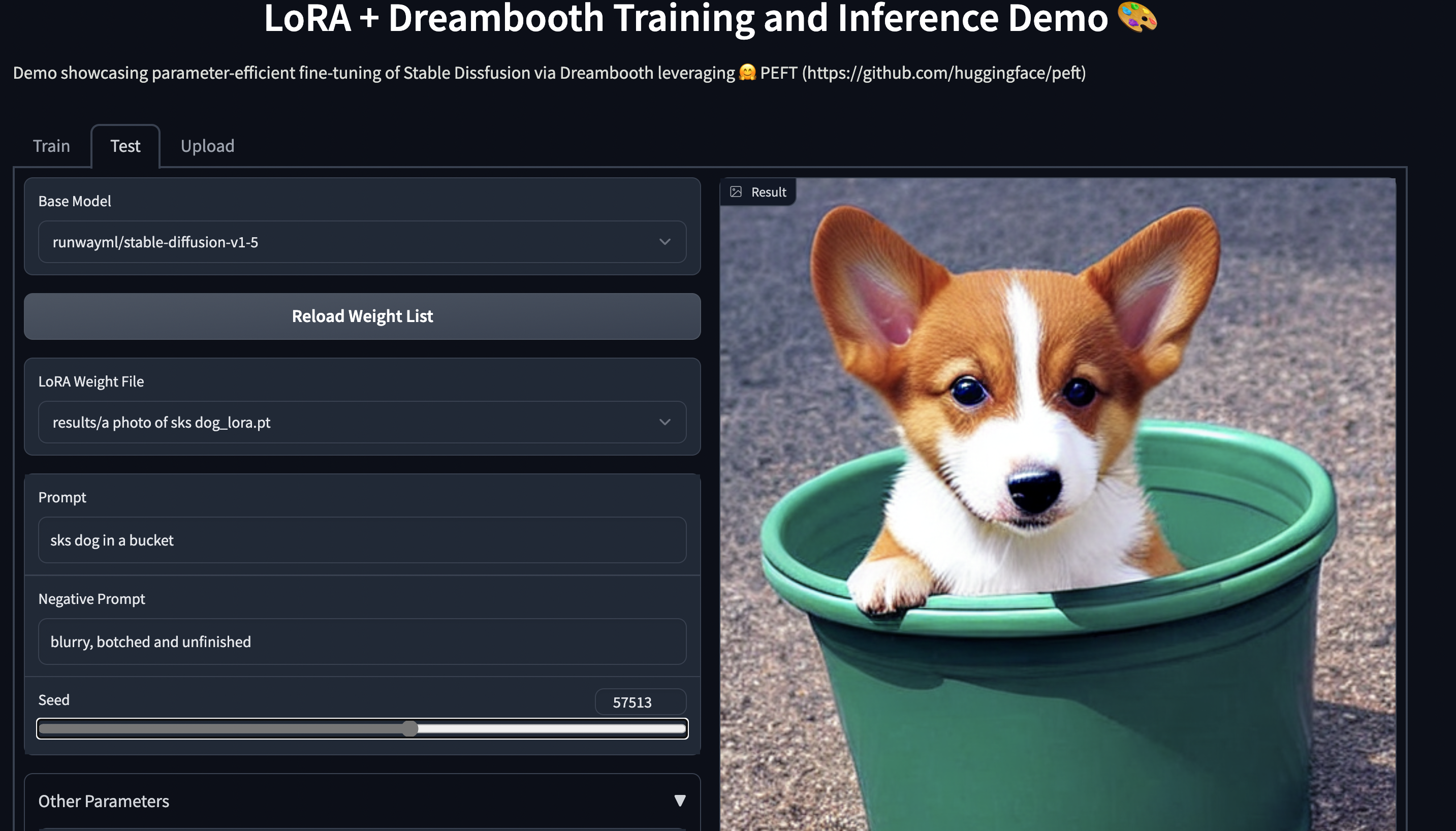
PEFT LoRA Dreambooth Gradio Space
Training your model using 🤗 PEFT
Let's consider the case of fine-tuning bigscience/mt0-large using LoRA.
- Let's get the necessary imports
from transformers import AutoModelForSeq2SeqLM
+ from peft import get_peft_model, LoraConfig, TaskType
model_name_or_path = "bigscience/mt0-large"
tokenizer_name_or_path = "bigscience/mt0-large"
- Creating config corresponding to the PEFT method
peft_config = LoraConfig(
task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1
)
- Wrapping base 🤗 Transformers model by calling
get_peft_model
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
+ model = get_peft_model(model, peft_config)
+ model.print_trainable_parameters()
# output: trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282
That's it! The rest of the training loop remains the same. Please refer example peft_lora_seq2seq.ipynb for an end-to-end example.
- When you are ready to save the model for inference, just do the following.
model.save_pretrained("output_dir")
# model.push_to_hub("my_awesome_peft_model") also works
This will only save the incremental PEFT weights that were trained. For example, you can find the bigscience/T0_3B tuned using LoRA on the twitter_complaints raft dataset here: smangrul/twitter_complaints_bigscience_T0_3B_LORA_SEQ_2_SEQ_LM. Notice that it only contains 2 files: adapter_config.json and adapter_model.bin with the latter being just 19MB.
- To load it for inference, follow the snippet below:
from transformers import AutoModelForSeq2SeqLM
+ from peft import PeftModel, PeftConfig
peft_model_id = "smangrul/twitter_complaints_bigscience_T0_3B_LORA_SEQ_2_SEQ_LM"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path)
+ model = PeftModel.from_pretrained(model, peft_model_id)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
model = model.to(device)
model.eval()
inputs = tokenizer("Tweet text : @HondaCustSvc Your customer service has been horrible during the recall process. I will never purchase a Honda again. Label :", return_tensors="pt")
with torch.no_grad():
outputs = model.generate(input_ids=inputs["input_ids"].to("cuda"), max_new_tokens=10)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True)[0])
# 'complaint'
Next steps
We've released PEFT as an efficient way of tuning large LLMs on downstream tasks and domains, saving a lot of compute and storage while achieving comparable performance to full finetuning. In the coming months, we'll be exploring more PEFT methods, such as (IA)3 and bottleneck adapters. Also, we'll focus on new use cases such as INT8 training of whisper-large model in Google Colab and tuning of RLHF components such as policy and ranker using PEFT approaches.
In the meantime, we're excited to see how industry practitioners apply PEFT to their use cases - if you have any questions or feedback, open an issue on our GitHub repo 🤗.
Happy Parameter-Efficient Fine-Tuning!