Finetune Stable Diffusion Models with DDPO via TRL










This article is also available in Chinese 简体中文.
Introduction
Diffusion models (e.g., DALL-E 2, Stable Diffusion) are a class of generative models that are widely successful at generating images most notably of the photorealistic kind. However, the images generated by these models may not always be on par with human preference or human intention. Thus arises the alignment problem i.e. how does one go about making sure that the outputs of a model are aligned with human preferences like “quality” or that outputs are aligned with intent that is hard to express via prompts? This is where Reinforcement Learning comes into the picture.
In the world of Large Language Models (LLMs), Reinforcement learning (RL) has proven to become a very effective tool for aligning said models to human preferences. It’s one of the main recipes behind the superior performance of systems like ChatGPT. More precisely, RL is the critical ingredient of Reinforcement Learning from Human Feedback (RLHF), which makes ChatGPT chat like human beings.
In Training Diffusion Models with Reinforcement Learning, Black et al. show how to augment diffusion models to leverage RL to fine-tune them with respect to an objective function via a method named Denoising Diffusion Policy Optimization (DDPO).
In this blog post, we discuss how DDPO came to be, a brief description of how it works, and how DDPO can be incorporated into an RLHF workflow to achieve model outputs more aligned with the human aesthetics. We then quickly switch gears to talk about how you can apply DDPO to your models with the newly integrated DDPOTrainer from the trl library and discuss our findings from running DDPO on Stable Diffusion.
The Advantages of DDPO
DDPO is not the only working answer to the question of how to attempt to fine-tune diffusion models with RL.
Before diving in, there are two key points to remember when it comes to understanding the advantages of one RL solution over the other
- Computational efficiency is key. The more complicated your data distribution gets, the higher your computational costs get.
- Approximations are nice, but because approximations are not the real thing, associated errors stack up.
Before DDPO, Reward-weighted regression (RWR) was an established way of using Reinforcement Learning to fine-tune diffusion models. RWR reuses the denoising loss function of the diffusion model along with training data sampled from the model itself and per-sample loss weighting that depends on the reward associated with the final samples. This algorithm ignores the intermediate denoising steps/samples. While this works, two things should be noted:
- Optimizing by weighing the associated loss, which is a maximum likelihood objective, is an approximate optimization
- The associated loss is not an exact maximum likelihood objective but an approximation that is derived from a reweighed variational bound
The two orders of approximation have a significant impact on both performance and the ability to handle complex objectives.
DDPO uses this method as a starting point. Rather than viewing the denoising step as a single step by only focusing on the final sample, DDPO frames the whole denoising process as a multistep Markov Decision Process (MDP) where the reward is received at the very end. This formulation in addition to using a fixed sampler paves the way for the agent policy to become an isotropic Gaussian as opposed to an arbitrarily complicated distribution. So instead of using the approximate likelihood of the final sample (which is the path RWR takes), here the exact likelihood of each denoising step which is extremely easy to compute ( ).
If you’re interested in learning more details about DDPO, we encourage you to check out the original paper and the accompanying blog post.
DDPO algorithm briefly
Given the MDP framework used to model the sequential nature of the denoising process and the rest of the considerations that follow, the tool of choice to tackle the optimization problem is a policy gradient method. Specifically Proximal Policy Optimization (PPO). The whole DDPO algorithm is pretty much the same as Proximal Policy Optimization (PPO) but as a side, the portion that stands out as highly customized is the trajectory collection portion of PPO
Here’s a diagram to summarize the flow:
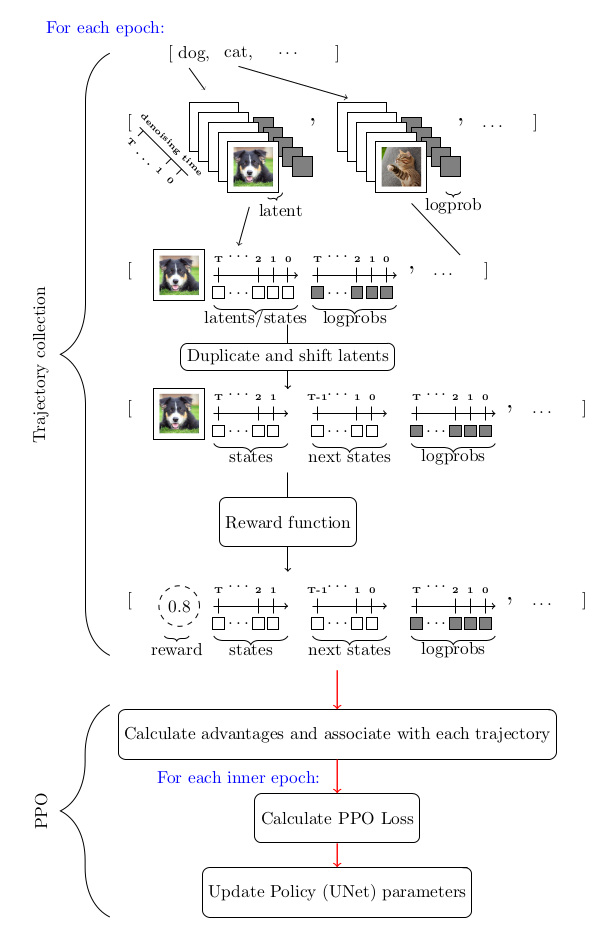
DDPO and RLHF: a mix to enforce aestheticness
The general training aspect of RLHF can roughly be broken down into the following steps:
- Supervised fine-tuning a “base” model learns to the distribution of some new data
- Gathering preference data and training a reward model using it.
- Fine-tuning the model with reinforcement learning using the reward model as a signal.
It should be noted that preference data is the primary source for capturing human feedback in the context of RLHF.
When we add DDPO to the mix, the workflow gets morphed to the following:
- Starting with a pretrained Diffusion Model
- Gathering preference data and training a reward model using it.
- Fine-tuning the model with DDPO using the reward model as a signal
Notice that step 3 from the general RLHF workflow is missing in the latter list of steps and this is because empirically it has been shown (as you will get to see yourself) that this is not needed.
To get on with our venture to get a diffusion model to output images more in line with the human perceived notion of what it means to be aesthetic, we follow these steps:
- Starting with a pretrained Stable Diffusion (SD) Model
- Training a frozen CLIP model with a trainable regression head on the Aesthetic Visual Analysis (AVA) dataset to predict how much people like an input image on average
- Fine-tuning the SD model with DDPO using the aesthetic predictor model as the reward signaller
We keep these steps in mind while moving on to actually getting these running which is described in the following sections.
Training Stable Diffusion with DDPO
Setup
To get started, when it comes to the hardware side of things and this implementation of DDPO, at the very least access to an A100 NVIDIA GPU is required for successful training. Anything below this GPU type will soon run into Out-of-memory issues.
Use pip to install the trl library
pip install trl[diffusers]
This should get the main library installed. The following dependencies are for tracking and image logging. After getting wandb installed, be sure to login to save the results to a personal account
pip install wandb torchvision
Note: you could choose to use tensorboard rather than wandb for which you’d want to install the tensorboard package via pip.
A Walkthrough
The main classes within the trl library responsible for DDPO training are the DDPOTrainer and DDPOConfig classes. See docs for more general info on the DDPOTrainer and DDPOConfig. There is an example training script in the trl repo. It uses both of these classes in tandem with default implementations of required inputs and default parameters to finetune a default pretrained Stable Diffusion Model from RunwayML .
This example script uses wandb for logging and uses an aesthetic reward model whose weights are read from a public facing HuggingFace repo (so gathering data and training the aesthetic reward model is already done for you). The default prompt dataset used is a list of animal names.
There is only one commandline flag argument that is required of the user to get things up and running. Additionally, the user is expected to have a huggingface user access token that will be used to upload the model post finetuning to HuggingFace hub.
The following bash command gets things running:
python ddpo.py --hf_user_access_token <token>
The following table contains key hyperparameters that are directly correlated with positive results:
| Parameter | Description | Recommended value for single GPU training (as of now) |
|---|---|---|
num_epochs |
The number of epochs to train for | 200 |
train_batch_size |
The batch size to use for training | 3 |
sample_batch_size |
The batch size to use for sampling | 6 |
gradient_accumulation_steps |
The number of accelerator based gradient accumulation steps to use | 1 |
sample_num_steps |
The number of steps to sample for | 50 |
sample_num_batches_per_epoch |
The number of batches to sample per epoch | 4 |
per_prompt_stat_tracking |
Whether to track stats per prompt. If false, advantages will be calculated using the mean and std of the entire batch as opposed to tracking per prompt | True |
per_prompt_stat_tracking_buffer_size |
The size of the buffer to use for tracking stats per prompt | 32 |
mixed_precision |
Mixed precision training | True |
train_learning_rate |
Learning rate | 3e-4 |
The provided script is merely a starting point. Feel free to adjust the hyperparameters or even overhaul the script to accommodate different objective functions. For instance, one could integrate a function that gauges JPEG compressibility or one that evaluates visual-text alignment using a multi-modal model, among other possibilities.
Lessons learned
- The results seem to generalize over a wide variety of prompts despite the minimally sized training prompts size. This has been thoroughly verified for the objective function that rewards aesthetics
- Attempts to try to explicitly generalize at least for the aesthetic objective function by increasing the training prompt size and varying the prompts seem to slow down the convergence rate for barely noticeable learned general behavior if at all this exists
- While LoRA is recommended and is tried and tested multiple times, the non-LoRA is something to consider, among other reasons from empirical evidence, non-Lora does seem to produce relatively more intricate images than LoRA. However, getting the right hyperparameters for a stable non-LoRA run is significantly more challenging.
- Recommendations for the config parameters for non-Lora are: set the learning rate relatively low, something around
1e-5should do the trick and setmixed_precisiontoNone
Results
The following are pre-finetuned (left) and post-finetuned (right) outputs for the prompts bear, heaven and dune (each row is for the outputs of a single prompt):
| pre-finetuned | post-finetuned |
|---|---|
 |
 |
 |
 |
 |
 |
Limitations
- Right now
trl's DDPOTrainer is limited to finetuning vanilla SD models; - In our experiments we primarily focused on LoRA which works very well. We did a few experiments with full training which can lead to better quality but finding the right hyperparameters is more challenging.
Conclusion
Diffusion models like Stable Diffusion, when fine-tuned using DDPO, can offer significant improvements in the quality of generated images as perceived by humans or any other metric once properly conceptualized as an objective function
The computational efficiency of DDPO and its ability to optimize without relying on approximations, especially over earlier methods to achieve the same goal of fine-tuning diffusion models, make it a suitable candidate for fine-tuning diffusion models like Stable Diffusion
trl library's DDPOTrainer implements DDPO for finetuning SD models.
Our experimental findings underline the strength of DDPO in generalizing across a broad range of prompts, although attempts at explicit generalization through varying prompts had mixed results. The difficulty of finding the right hyperparameters for non-LoRA setups also emerged as an important learning.
DDPO is a promising technique to align diffusion models with any reward function and we hope that with the release in TRL we can make it more accessible to the community!
Acknowledgements
Thanks to Chunte Lee for the thumbnail of this blog post.



