IDEFICS 简介: 最先进视觉语言模型的开源复现

















中文翻译: MatrixYao 校对: zhongdongy
本文也提供英文版本 English。
我们很高兴发布 IDEFICS ( Image-aware Decoder Enhanced à la Flamingo with Ininterleaved Cross-attention S ) 这一开放视觉语言模型。 IDEFICS 基于 Flamingo,Flamingo 作为最先进的视觉语言模型,最初由 DeepMind 开发,但目前尚未公开发布。与 GPT-4 类似,该模型接受任意图像和文本输入序列并生成输出文本。IDEFICS 仅基于公开可用的数据和模型 (LLaMA v1 和 OpenCLIP) 构建,它有两个变体: 基础模型和指令模型。每个变体又各有 90 亿参数和 800 亿参数两个版本。
最先进的人工智能模型的开发应该更加透明。IDEFICS 的目标是重现并向 AI 社区提供与 Flamingo 等大型私有模型的能力相媲美的公开模型。因此,我们采取了很多措施,以增强其透明度: 我们只使用公开数据,并提供工具以供大家探索训练数据集; 我们分享我们在系统构建过程中的 在技术上犯过的错误及学到的教训,并在模型最终发布前使用对抗性提示来评估模型的危害性。我们希望 IDEFICS 能够与 OpenFlamingo (Flamingo 的另一个 90 亿参数的开放的复现模型) 等模型一起,为更开放的多模态 AI 系统研究奠定坚实的基础。
IDEFICS 是什么?
IDEFICS 是一个 800 亿参数的多模态模型,其接受图像和文本序列作为输入,并生成连贯的文本作为输出。它可用于回答有关图像的问题、描述视觉内容、创建基于多张图像的故事等。
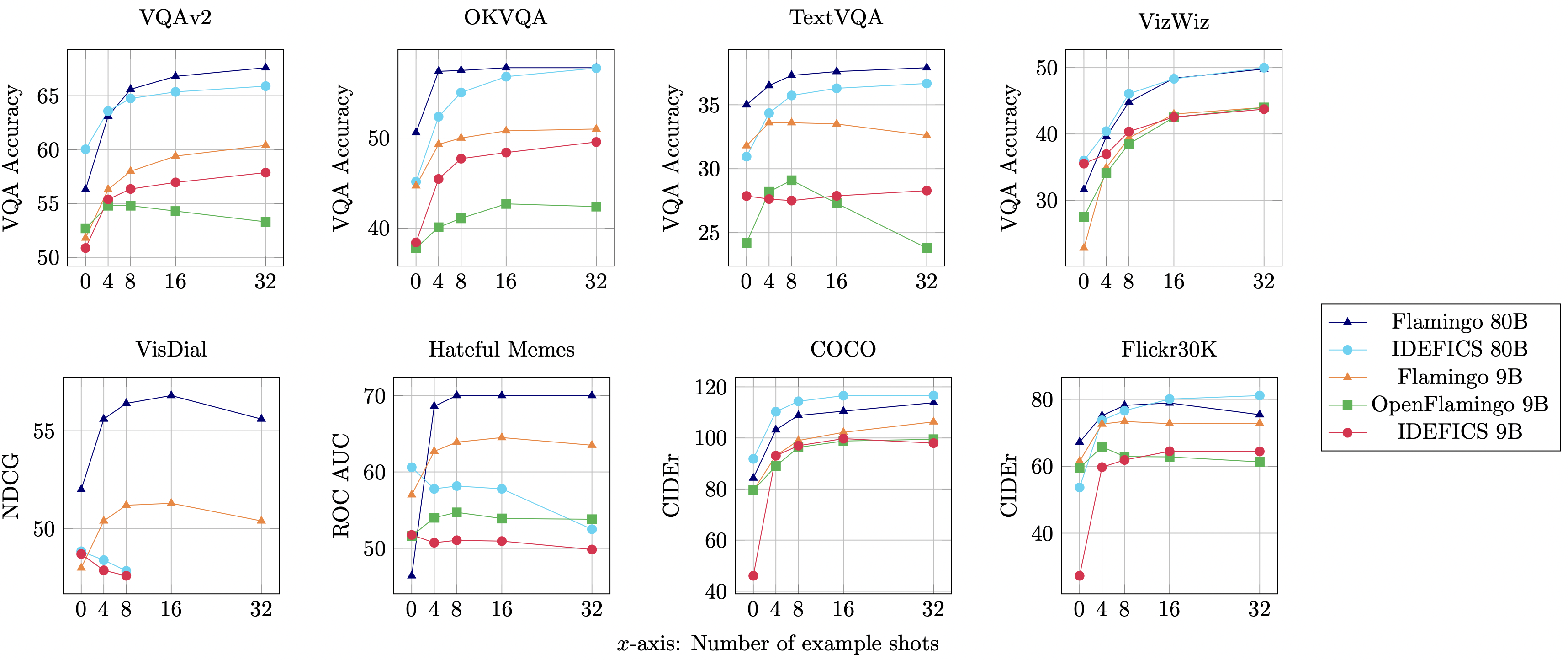
IDEFICS 是 Flamingo 的开放复刻版,在各种图像文本理解基准上的性能可与原始闭源模型相媲美。它有两个版本 - 800 亿参数版和 90 亿参数版。
我们还提供了两个指令微调变体 idefics-80B-instruct 及 idefics-9B-instruct,可用于对话场景。
训练数据
IDEFICS 基于由多个公开可用的数据集组成的混合数据集训练而得,它们是: 维基百科、公开多模态数据集 (Public Multimodal Dataset) 和 LAION,以及我们创建的名为 OBELICS 的新的 115B 词元数据集。OBELICS 由从网络上抓取的 1.41 亿个图文文档组成,其中包含 3.53 亿张图像。
我们提供了 OBELICS 的 交互式可视化 页面,以供大家使用 Nomic AI 来探索数据集的内容。

你可在 模型卡 和我们的 研究论文 中找到 IDEFICS 架构、训练方法及评估数据等详细信息,以及数据集相关的信息。此外,我们还记录了在模型训练过程中得到的 所思、所想、所学,为大家了解 IDEFICS 的研发提供了宝贵的视角。
伦理评估
在项目开始时,经过一系列讨论,我们制定了一份 伦理章程,以帮助指导项目期间的决策。该章程规定了我们在执行项目和发布模型过程中所努力追求的价值观,包括自我批判、透明和公平。
作为发布流程的一部分,我们内部对模型的潜在偏见进行了评估,方法是用对抗性图像和文本来提示模型,这些图像和文本可能会触发一些我们不希望模型做出的反应 (这一过程称为红队)。
请通过 演示应用 来试一试 IDEFICS,也可以查看相应的 模型卡 和 数据集卡,并通过社区栏告诉我们你的反馈!我们致力于改进这些模型,并让机器学习社区能够用上大型多模态人工智能模型。
许可证
该模型建立在两个预训练模型之上: laion/CLIP-ViT-H-14-laion2B-s32B-b79K 和 huggyllama/llama-65b。第一个是在 MIT 许可证下发布的。而第二个是在一个特定的研究性非商用许可证下发布的,因此,用户需遵照该许可的要求直接填写 Meta 的表单 来申请访问它。
这两个预训练的模型通过我们的新训练的参数相互连接。训练时,连接部分的参数会随机初始化,且其与两个冻结的基础模型无关。这一部分权重是在 MIT 许可证下发布的。
IDEFICS 入门
IDEFICS 模型已上传至 Hugging Face Hub,最新版本的 transformers 也已支持该模型。以下是一个如何使用 IDEFICS 的代码示例:
import torch
from transformers import IdeficsForVisionText2Text, AutoProcessor
device = "cuda" if torch.cuda.is_available() else "cpu"
checkpoint = "HuggingFaceM4/idefics-9b-instruct"
model = IdeficsForVisionText2Text.from_pretrained(checkpoint, torch_dtype=torch.bfloat16).to(device)
processor = AutoProcessor.from_pretrained(checkpoint)
# We feed to the model an arbitrary sequence of text strings and images. Images can be either URLs or PIL Images.
prompts = [
[
"User: What is in this image?",
"https://upload.wikimedia.org/wikipedia/commons/8/86/Id%C3%A9fix.JPG",
"<end_of_utterance>",
"\nAssistant: This picture depicts Idefix, the dog of Obelix in Asterix and Obelix. Idefix is running on the ground.<end_of_utterance>",
"\nUser:",
"https://static.wikia.nocookie.net/asterix/images/2/25/R22b.gif/revision/latest?cb=20110815073052",
"And who is that?<end_of_utterance>",
"\nAssistant:",
],
]
# --batched mode
inputs = processor(prompts, add_end_of_utterance_token=False, return_tensors="pt").to(device)
# --single sample mode
# inputs = processor(prompts[0], return_tensors="pt").to(device)
# Generation args
exit_condition = processor.tokenizer("<end_of_utterance>", add_special_tokens=False).input_ids
bad_words_ids = processor.tokenizer(["<image>", "<fake_token_around_image>"], add_special_tokens=False).input_ids
generated_ids = model.generate(**inputs, eos_token_id=exit_condition, bad_words_ids=bad_words_ids, max_length=100)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
for i, t in enumerate(generated_text):
print(f"{i}:\n{t}\n")







