使用 🤗 Optimum Intel 在英特尔至强上加速 StarCoder: Q8/Q4 及投机解码











中文翻译: MatrixYao 校对: zhongdongy
本文也提供英文版本 English。
引言
近来,随着 BigCode 的 StarCoder 以及 Meta AI 的 Code Llama 等诸多先进模型的发布,代码生成模型变得炙手可热。同时,业界也涌现出了大量的致力于优化大语言模型 (LLM) 的运行速度及易用性的工作。我们很高兴能够分享我们在英特尔至强 CPU 上优化 LLM 的最新结果,本文我们主要关注 StarCoder 这一流行的代码生成 LLM。
StarCoder 模型是一个专为帮助用户完成各种编码任务而设计的先进 LLM,其可用于代码补全、错误修复、代码摘要,甚至根据自然语言生成代码片段等用途。 StarCoder 模型是 StarCoder 模型家族的一员,该系列还有 StarCoderBase。这些代码大模型 (代码 LLM) 使用 GitHub 上的许可代码作为训练数据,其中涵盖了 80 多种编程语言、Git 提交、GitHub 问题以及 Jupyter Notebook。本文,我们将 8 比特、4 比特量化以及 辅助生成 结合起来,在英特尔第四代至强 CPU 上对 StarCoder-15B 模型实现了 7 倍以上的推理加速。
欢迎到 Hugging Face Spaces 上尝试我们的 演示应用,其运行在第四代英特尔至强可扩展处理器上。
第 1 步: 基线与评估方法
首先,我们在 PyTorch 和 Intel Extension for PyTorch (IPEX) 上运行 StarCoder (15B),并将其作为基线。
至于评估方法,目前已有不少数据集可用于评估自动代码补全的质量。本文,我们使用流行的 [Huggingface.co/datasets/openai_humaneval] 数据集来评估模型的质量和性能。HumanEval 由 164 个编程问题组成,其内容为函数接口及其对应的函数功能的文档字符串,需要模型基于此补全函数体的代码。其提示的平均长度为 139。我们使用 Bigcode Evaluation Harness 运行评估并报告 pass@1 指标。我们通过测量 HumanEval 测试集上的首词元延迟 (Time To First Token,TTFT) 和每词元延迟 (Time Per Output Token,TPOT) 来度量模型性能,并报告平均 TTFT 和 TPOT。
第四代英特尔至强处理器内置人工智能加速器,称为英特尔® 高级矩阵扩展 (Intel® Advanced Matrix Extensions,英特尔® AMX) 指令集。具体来说,其在每个 CPU 核中内置了 BFloat16 (BF16) 和 Int8 GEMM 加速器,以加速深度学习训练和推理工作负载。AMX 推理加速已集成入 PyTorch 2.0 及 Intel Extension for PyTorch (IPEX),同时这两个软件还针对其他 LLM 中常见的操作 (如层归一化、SoftMax、缩放点积等) 进行了更多的优化。
我们使用 PyTorch 和 IPEX 对 BF16 模型进行推理,以确定基线。图 1 展示了模型推理延迟的基线,表 1 展示了延迟及其对应的准确率。
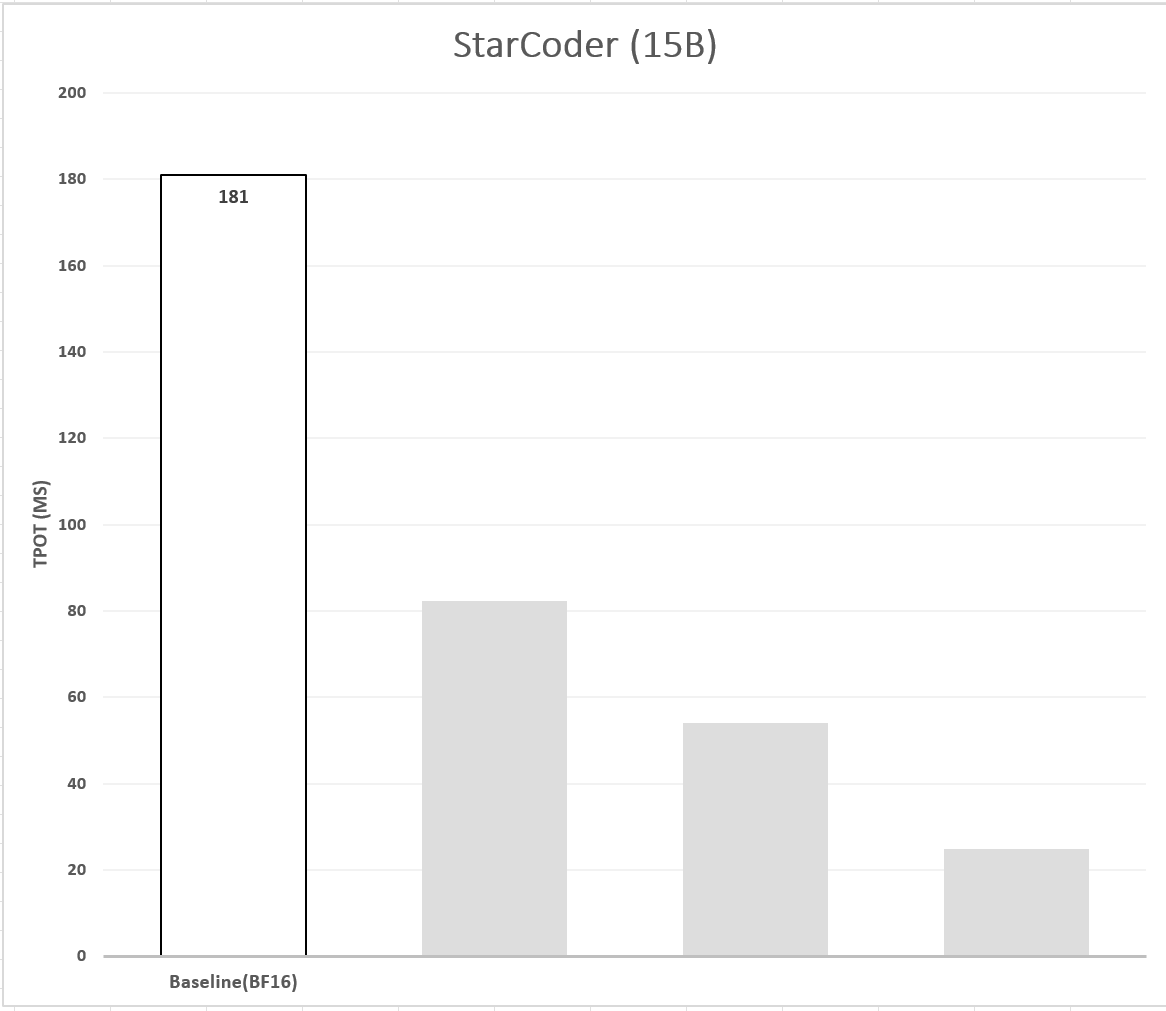
图 1: 模型延迟基线
LLM 量化
LLM 中的文本生成是以自回归的方式进行的,因此在生成每个新词元时都需要把整个模型从内存加载到 CPU。我们发现内存 (DRAM) 和 CPU 之间的带宽是词元生成的最大性能瓶颈。量化是缓解这一问题的通用方法,其可减小模型尺寸,进而减少模型权重加载时间。
本文,我们关注两种量化方法:
- 仅权重量化 (Weight Only Quantization,WOQ) - 仅量化模型的权重,但不量化激活值,且使用高精度 (如 BF16) 进行计算,因此在计算时需要对权重进行反量化。
- 静态量化 (Static Quantization,SQ) - 对权重和激活都进行量化。量化过程包括通过校准预先计算量化参数,从而使得计算能够以较低精度 (如 INT8) 执行。图 2 所示为 INT8 静态量化的计算流程。
第 2 步: 8 比特量化 (INT8)
SmoothQuant 是一种训后量化算法,其能以最小的精度损失把 LLM 量化至 INT8。由于激活的特定通道存在大量异常值,常规静态量化方法在 LLM 上表现不佳。这是因为激活是按词元量化的,因此常规静态量化会导致大的激活值截断以及小的激活值下溢。SmoothQuant 算法通过引入预量化解决了这个问题,其引入了一个额外的平滑缩放因子,将其应用于激活和权重能达到平滑激活中的异常值的作用,从而最大化量化阶数的利用率。
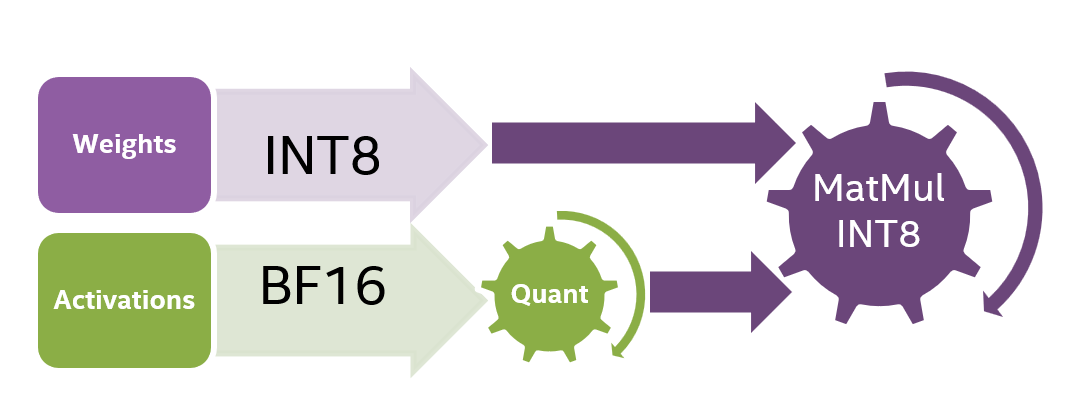
图 2:INT8 静态量化模型的计算流程
我们利用 IPEX 对 StarCoder 模型进行 SmoothQuant 量化。我们使用 MBPP 的测试子集作为校准数据集,并基于此生成了 Q8-StarCoder。评估表明,Q8-StarCoder 相对于基线没有精度损失 (事实上,甚至还有轻微的改进)。在性能方面,Q8-StarCoder 的 TTFT 有 ~2.19x 的加速,TPOT 有 ~2.20x 的加速。图 3 展示了 Q8-StarCoder 与 BF16 基线模型的延迟 (TPOT) 对比。
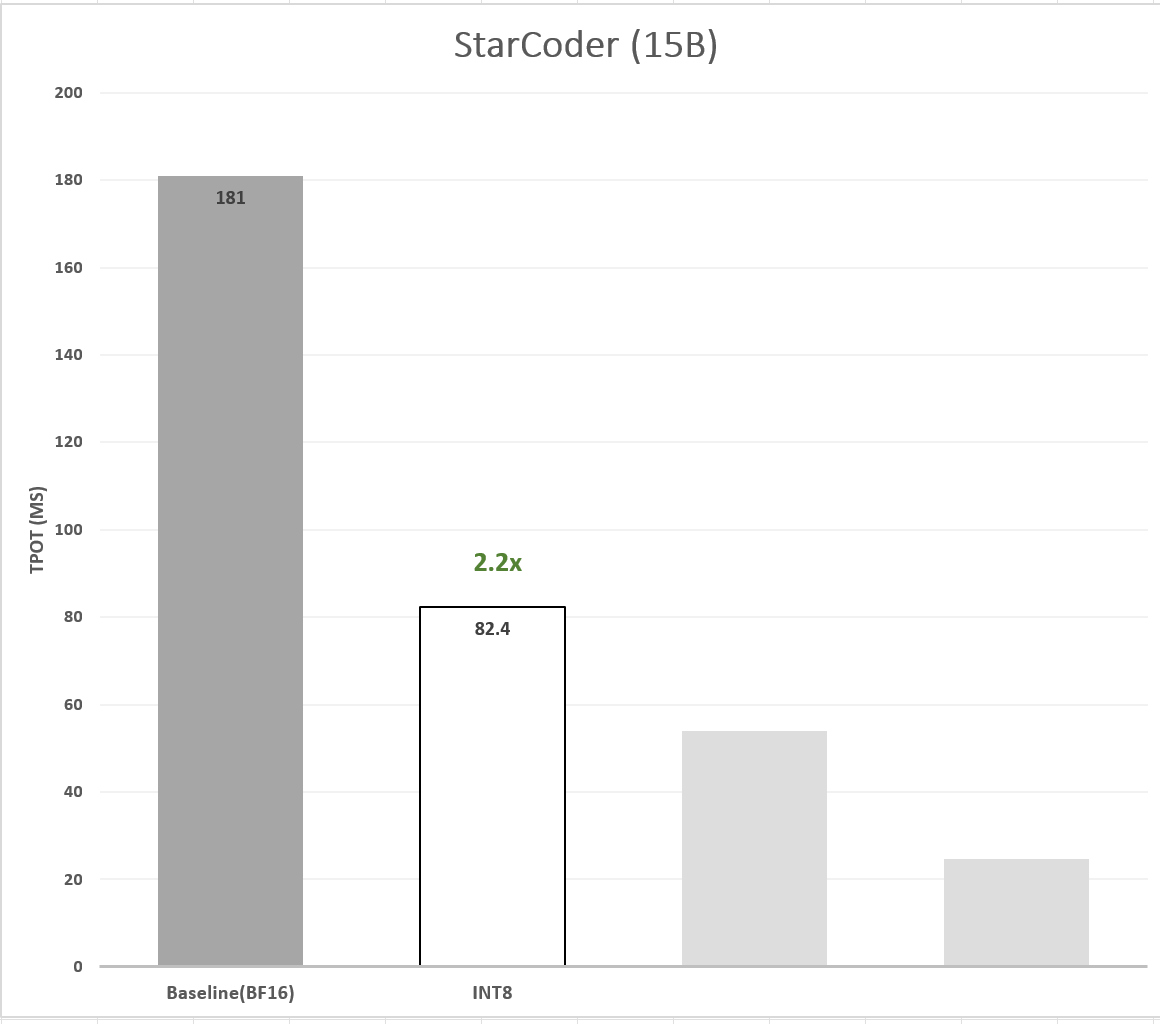
图 3:8 比特量化模型的延迟加速
第 3 步: 4 比特量化 (INT4)
尽管与 BF16 相比,INT8 将模型尺寸减小了 2 倍 (每权重 8 比特,之前每权重 16 比特),但内存带宽仍然是最大的瓶颈。为了进一步减少模型的内存加载时间,我们使用 WOQ 将模型的权重量化为 4 比特。请注意,4 比特 WOQ 需要在计算之前反量化回 16 比特 (图 4),这意味着存在额外的计算开销。
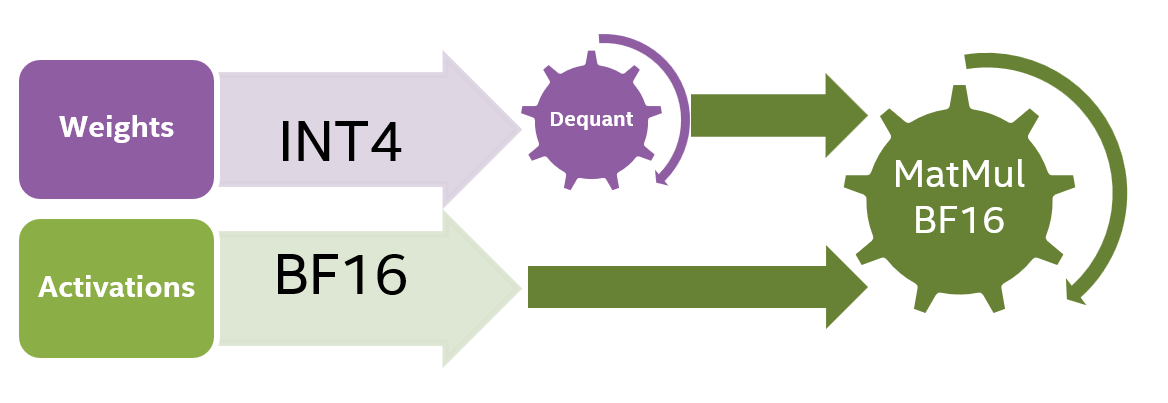
图 4:INT4 量化模型的计算流程
张量级的非对称最近舍入 (Round To Nearest,RTN) 量化是一种基本的 WOQ 技术,但它经常会面临精度降低的挑战。这篇论文 (Zhewei Yao,2022) 表明对模型权重进行分组量化有助于保持精度。为了避免精度下降,我们沿输入通道将若干个连续值 (如 128 个) 分为一组,对分组后的数据执行 4 比特量化,并按组计算缩放因子。我们发现分组 4 比特 RTN 在 HumanEval 数据集上足以保持 StarCoder 的准确性。与 BF16 基线相比,4 比特模型的 TPOT 有 3.35 倍 的加速 (图 5),但由于在计算之前需要将 4 比特反量化为 16 比特,该操作带来的额外开销使得其 TTFT 出现了 0.84 倍的减速 (表 1),这也是符合预期的。
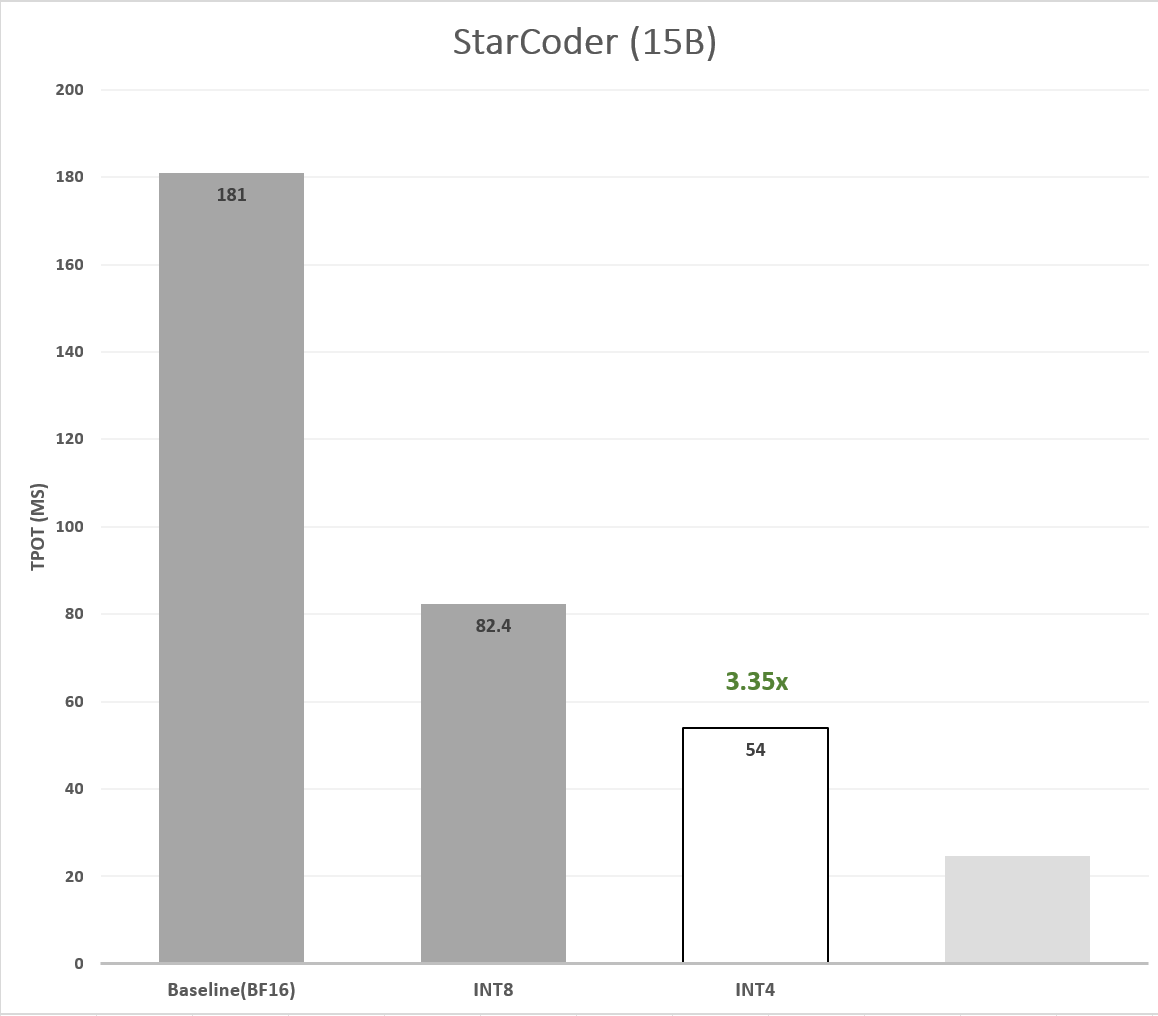
图 5:4 比特量化模型的延迟加速。
首词元和后续词元的性能瓶颈不同
生成首词元时会涉及到对整个输入提示的并行处理,当提示长度很长时,需要大量的计算资源。因此,计算成为这一阶段的瓶颈。此时,与基线 (以及引入反量化计算开销的 4 比特 WOQ) 相比,将精度从 BF16 切至 INT8 能提高性能。然而,从第二个词元开始,系统需以自回归的方式逐一生成剩下的词元,而每新生成一个词元都需要从内存中再次加载模型。此时,内存带宽变成了瓶颈,而不再是可执行操作数 (FLOPS),此时 INT4 优于 INT8 和 BF16。
第 4 步: 辅助生成 (Assisted Generation,AG)
另一种能提高推理延迟、缓解内存带宽瓶颈的方法是 辅助生成 (Assisted Generation,AG),其实际上是 投机解码 的一种实现。AG 通过更好地平衡内存和计算来缓解上述压力,其基于如下假设: 更小、更快的辅助草稿模型生成的词元与更大的目标模型生成的词元重合的概率比较高。
AG 先用小而快的草稿模型基于贪心算法生成 K 个候选词元。这些词元的生成速度更快,但其中一些可能与原始目标模型的输出词元不一致。因此,下一步,目标模型会通过一次前向传播并行检查所有 K 个候选词元的有效性。这种做法加快了解码速度,因为并行解码 K 个词元的延迟比自回归生成 K 个词元的延迟要小。
为了加速 StarCoder,我们使用 bigcode/tiny_starcoder_py 作为草稿模型。该模型与 StarCoder 架构相似,但参数量仅为 164M - 比 StarCoder 小 ~95 倍,因此速度更快。为了实现更大的加速,除了量化目标模型之外,我们还对草稿模型进行了量化。我们对草稿模型和目标模型均实验了两种量化方案: 8 比特 SmoothQuant 和 4 比特 WOQ 量化。评估结果表明,对草稿模型和目标模型均采用 8 比特 SmoothQuant 量化得到的加速最大: TPOT 加速达 ~7.30 倍 (图 6)。
我们认为该结果是合理的,分析如下:
- 草稿模型量化: 当使用 164M 参数的 8 比特量化 StarCoder 作为草稿模型时,大部分权重均可驻留在 CPU 缓存中,内存带宽瓶颈得到缓解,因为在生成每个词元时无需重复从内存中读取模型。此时,已不存在内存瓶颈,所以进一步量化为 4 比特意义已不大。同时,与量化为 4 比特 WOQ 的 StarCoder-164M 相比,我们发现量化为 8 比特的 StarCoder-164M 加速比更大。这是因为,4 比特 WOQ 虽然在内存带宽成为瓶颈的情况下具有优势,因为它的内存占用较小,但 其会带来额外的计算开销,因为需要在计算之前执行 4 比特到 16 比特的反量化操作。
- 目标模型量化: 在辅助生成场景下,目标模型需要处理草稿模型生成的 K 个词元序列。通过目标模型一次性 (并行) 对 K 个词元进行推理,而不是一个一个顺序地进行自回归处理,工作负载已从内存带宽瓶颈型转变成了计算瓶颈型。此时,我们观察到,使用 8 比特量化的目标模型比使用 4 比特模型加速比更高,因为从 4 比特到 16 比特的反量化会产生额外的计算开销。
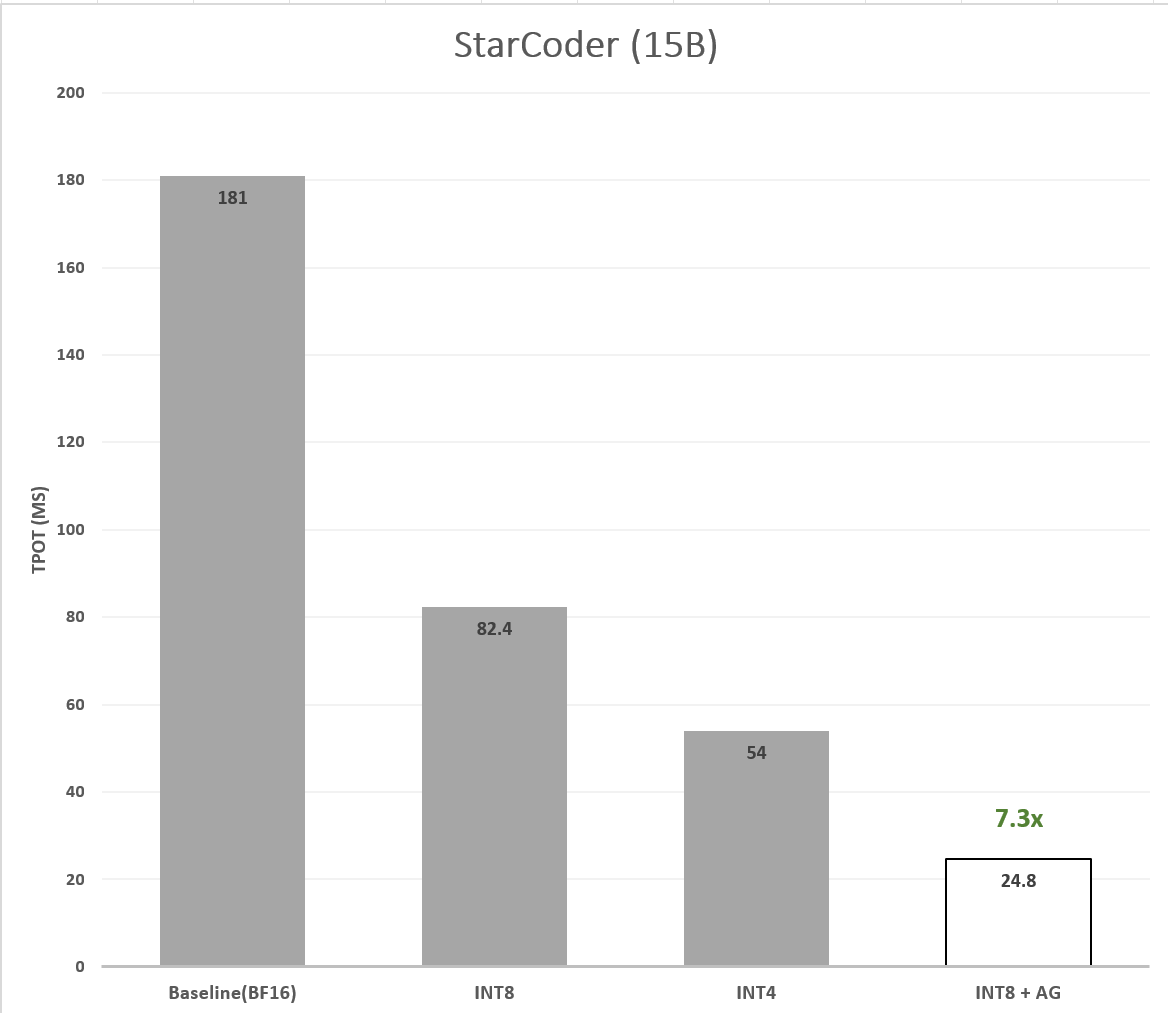
图 6: 最终优化模型的延迟加速
| StarCoder | 量化方案 | 精度 | HumanEval (pass@1) | TTFT (ms) | TTFT 加速 | TPOT (ms) | TPOT 加速 |
|---|---|---|---|---|---|---|---|
| 基线 | 无 | A16W16 | 33.54 | 357.9 | 1.00x | 181.0 | 1.00x |
| INT8 | SmoothQuant | A8W8 | 33.96 | 163.4 | 2.19x | 82.4 | 2.20x |
| INT4 | RTN (g128) | A16W4 | 32.80 | 425.1 | 0.84x | 54.0 | 3.35x |
| INT8 + AG | SmoothQuant | A8W8 | 33.96 | 183.6 | 1.95x | 24.8 | 7.30x |
表 1: 在英特尔第四代至强处理器上测得的 StarCoder 模型的准确率及延迟
如果您想要加载优化后的模型,并执行推理,可以用 optimum-intel 提供的 IPEXModelForXxx 类来替换对应的 AutoModelForXxx 类。
在开始之前,还需要确保已经安装了所需的库:
pip install --upgrade-strategy eager optimum[ipex]
- from transformers import AutoModelForCausalLM
+ from optimum.intel import IPEXModelForCausalLM
from transformers import AutoTokenizer, pipeline
- model = AutoModelForCausalLM.from_pretrained(model_id)
+ model = IPEXModelForCausalLM.from_pretrained(model_id)
tokenizer = AutoTokenizer.from_pretrained(model_id)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
results = pipe("He's a dreadful magician and")




