个人编程助手: 训练你自己的编码助手








本文也提供英文版本 English。
在编程和软件开发这个不断演变的领域中,对效率和生产力的追求催生了许多卓越的创新。其中一个显著的创新就是代码生成模型的出现,如 Codex、StarCoder 和 Code Llama。这些模型在生成类似人类编写的代码片段方面表现出惊人能力,显示出了作为编程助手的巨大潜力。
然而,虽然这些预训练模型在各种任务上已经表现出了卓越的性能,但在不远的未来,我们仍然可以期待一个令人兴奋的前景: 想象一下,你能够根据自己的特定需求定制代码生成模型,并且这种个性化的编程助手能够在企业规模上得到应用。
在这篇博客中,我们将展示如何创建 HugCoder 🤗,一个在 huggingface GitHub 组织 的公共仓库代码内容上进行微调的代码大模型。我们将讲述我们的数据收集工作流程、训练实验,以及一些有趣的结果。这将使你能够根据你的专有代码库创建自己的个人编程助手。我们还将为这个项目的进一步扩展留下一些实验的方向。
让我们开始吧 🚀

数据收集的工作流
我们想要的数据集在概念上非常简单,我们像下面所示那样构建它。
| 仓库名 | 仓库中的文件路径 | 文件内容 |
| — | — | — |
| — | — | — |
使用 Python GitHub API 从 GitHub 上抓取代码内容是直截了当的。然而,这取决于仓库的数量和仓库内代码文件的数量,通常情况,人们很容易会遇到 API 速率限制等问题。
为了防止这类问题发生,我们决定将所有公共仓库克隆到本地,并从中提取内容,而不是通过 API。我们使用 Python 的 multiprocessing 模块并行下载所有仓库,如 这个下载脚本。
一个仓库通常可能包含非代码文件,如图片、演示文稿和其他资料。我们对抓取它们不感兴趣。我们为此创建了一个 扩展名列表 来过滤掉它们。为了解析除了 Jupyter Notebook 之外的代码文件,我们简单地使用了 “utf-8” 编码。对于 notebook,我们只考虑了代码单元。
我们还排除了所有与代码不直接相关的文件路径。这些包括: .git , __pycache__ 和 xcodeproj 。
为了保持这些内容的序列化相对内存友好 (即处理代码时不会过多占用内存),我们使用了分块处理方法和 feather 格式 (储存序列化的数据)。完整实现请参见 这个脚本。
最终的数据集 可在 Hub 上获取,它看起来像这个样子:
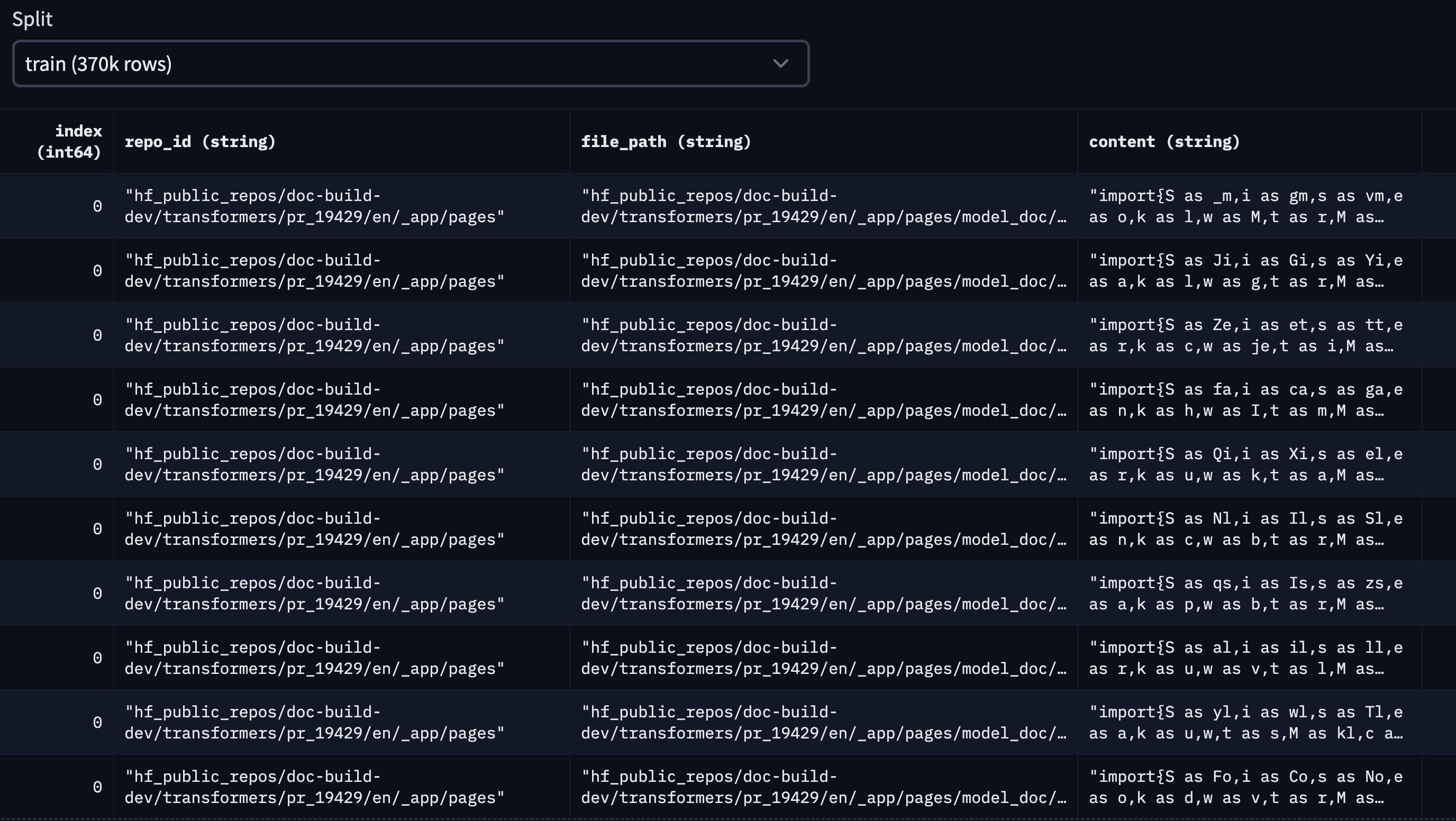
对于这篇博客,我们选取了基于点赞数排名前十的 Hugging Face 公共仓库。它们分别是:
['transformers', 'pytorch-image-models', 'datasets', 'diffusers', 'peft', 'tokenizers', 'accelerate', 'text-generation-inference', 'chat-ui', 'deep-rl-class']
这是我们用来生成这个数据集的代码,而 这是数据集在 Hub 上的链接。下面是它的一个快照:
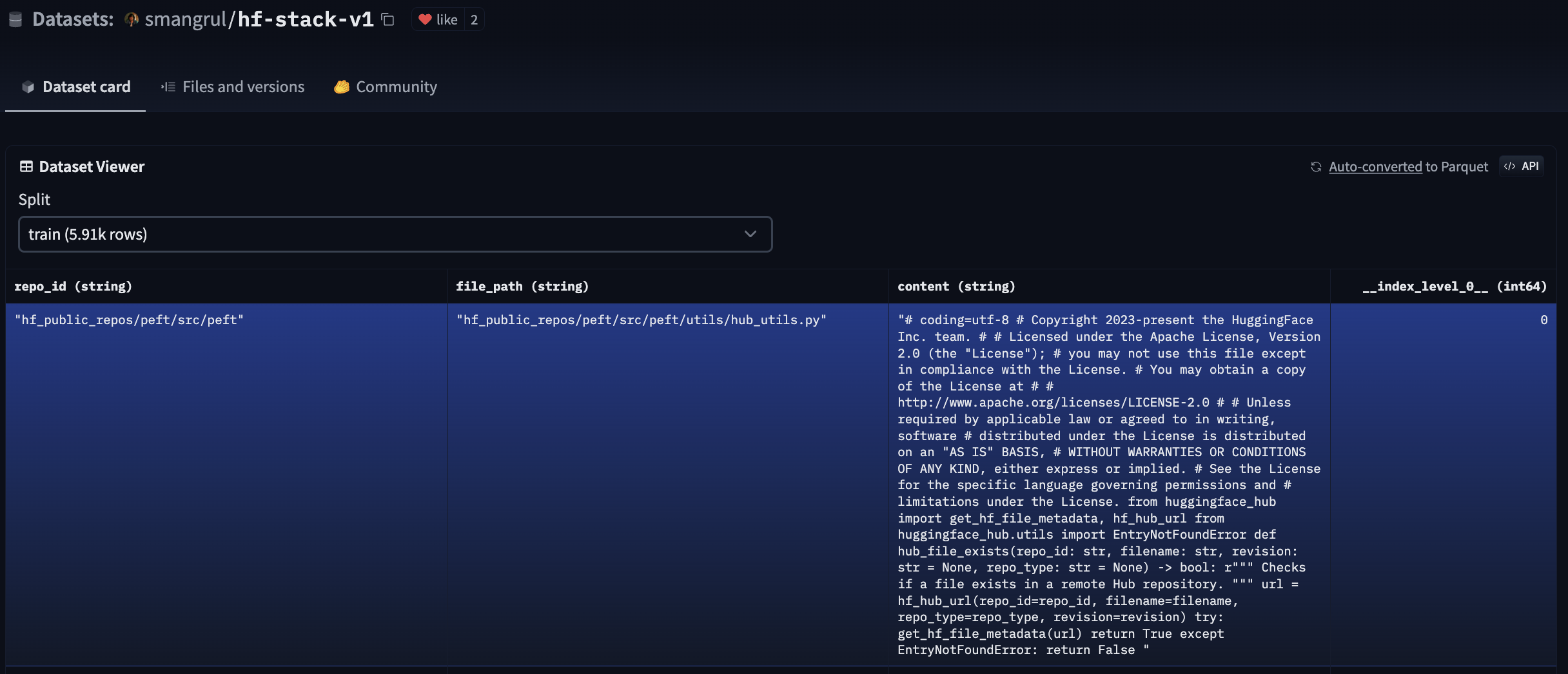
为了降低项目复杂性,我们没有考虑对数据集进行去重。如果你对在生产应用中应用去重技术感兴趣,这篇博客文章 是一个极佳的资源,它在代码大模型的内容中详细讨论了这个主题。
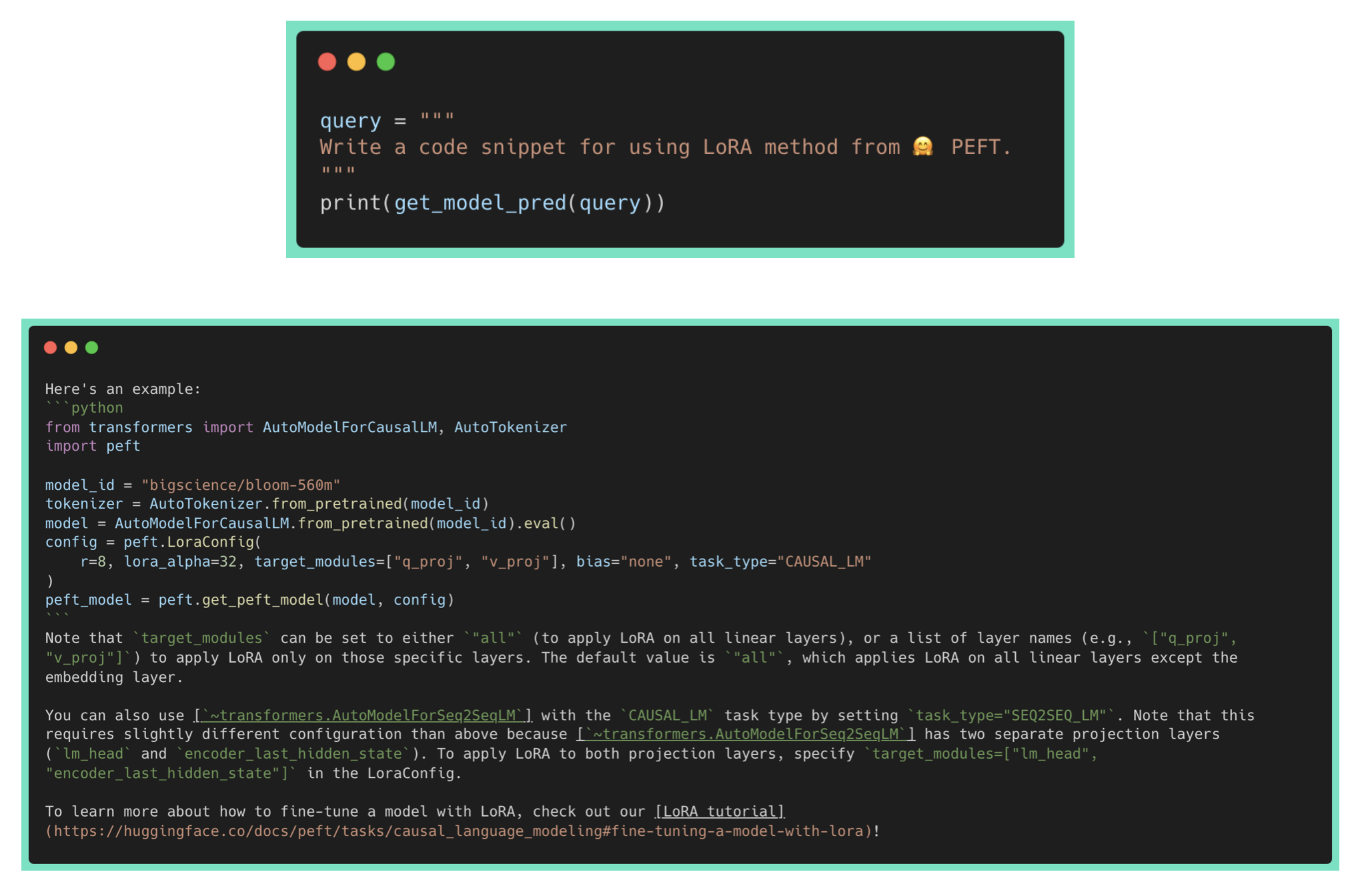
微调你的个人代码助手
在这一部分,我们将展示如何微调以下模型: bigcode/starcoder (15.5B 参数) 、bigcode/starcoderbase-1b (1B 参数) 和 Deci/DeciCoder-1b (1B 参数)。我们将使用一个带有 40GB 显存的 A100 Colab Notebook,并使用 🤗 PEFT (Parameter-Efficient Fine-Tuning,参数高效微调) 进行所有实验。此外,我们还将展示如何使用 🤗 Accelerate 的 FSDP (Fully Sharded Data Parallel,全分片数据并行) 集成,在一台配备 8 个 80GB 显存的 A100 GPU 的机器上完全微调 bigcode/starcoder (15.5B 参数)。训练目标是 fill in the middle (FIM) ,其中训练序列的一部分被移动到序列的末尾,并且重排序后的序列被自回归地预测。
为什么选择 PEFT ?因为全微调代价高昂。让我们来看一些数字以便更好地理解:
全微调所需的最小 GPU 内存:
- 参数权重: 2 字节 (混合精度训练)
- 参数权重梯度: 2 字节
- 使用 Adam 优化器时的优化器状态: 4 字节用于原始 FP32 权重 + 8 字节用于一阶和二阶矩估计
- 将以上所有内容加在一起的每个参数成本: 每个参数 16 字节
- 15.5B 模型 -> 248GB 的 GPU 内存,甚至还没有考虑存储中间激活值所需的巨大内存 -> 至少需要 4 个 A100 80GB GPU
由于硬件需求巨大,我们将使用 QLoRA 进行参数高效微调。下面是使用 QLoRA 进行 Starcoder 微调的最小 GPU 内存需求:
trainable params: 110,428,160 || all params: 15,627,884,544 || trainable%: 0.7066097761926236
- 基础模型权重: 0.5 字节 * 15.51B 冻结参数 = 7.755GB
- 适配器 (Adapter) 权重: 2 字节 * 0.11B 可训练参数 = 0.22GB
- 权重梯度: 2 字节 * 0.11B 可训练参数 = 0.22GB
- 使用 Adam 优化器时的优化器状态: 4 字节 * 0.11B 可训练参数 * 3 = 1.32GB
- 将以上所有内容加在一起 -> 9.51GB ~ 10GB -> 需要 1 个 A100 40GB GPU 🤯。选择 A100 40GB GPU 的原因是,训练时长序列长度为 2048,批量大小为 4,这会导致更高的内存需求。如下所示,所需的 GPU 内存为 26GB,可以在 A100 40GB GPU 上容纳。此外,A100 GPU 与 Flash Attention 2 具有更好的兼容性。
在上面的计算中,我们没有考虑中间激活值检查点所需的内存,这通常是相当巨大的。我们利用 Flash Attention V2 和梯度检查点来解决这个问题。
- 对于 QLoRA,加上 flash attention V2 和梯度检查点,单个 A100 40GB GPU 上模型占用的总内存为 26GB, 批量大小为 4。
- 对于使用 FSDP 进行全微调,加上 Flash Attention V2 和梯度检查点,每个 GPU 上占用的内存在 70GB 到 77.6GB 之间, 每个 GPU 的批量大小为 1。
请参考 model-memory-usage 以轻松计算在 🤗 Hugging Face Hub 上托管的大型模型上进行训练和推理所需的 vRAM。
全微调
我们将探讨如何使用 PyTorch Fully Sharded Data Parallel (FSDP) 技术在 8 个 A100 80GB GPU 上完全微调 bigcode/starcoder (15B 参数)。欲了解更多关于 FSDP 的信息,请参阅 Fine-tuning Llama 2 70B using PyTorch FSDP 和 Accelerate Large Model Training using PyTorch Fully Sharded Data Parallel。
资源
- 代码库: 链接。它使用了 Transformers 中最近添加的 Flash Attention V2 支持。
- FSDP 配置: fsdp_config.yaml
- 模型: bigcode/stacoder
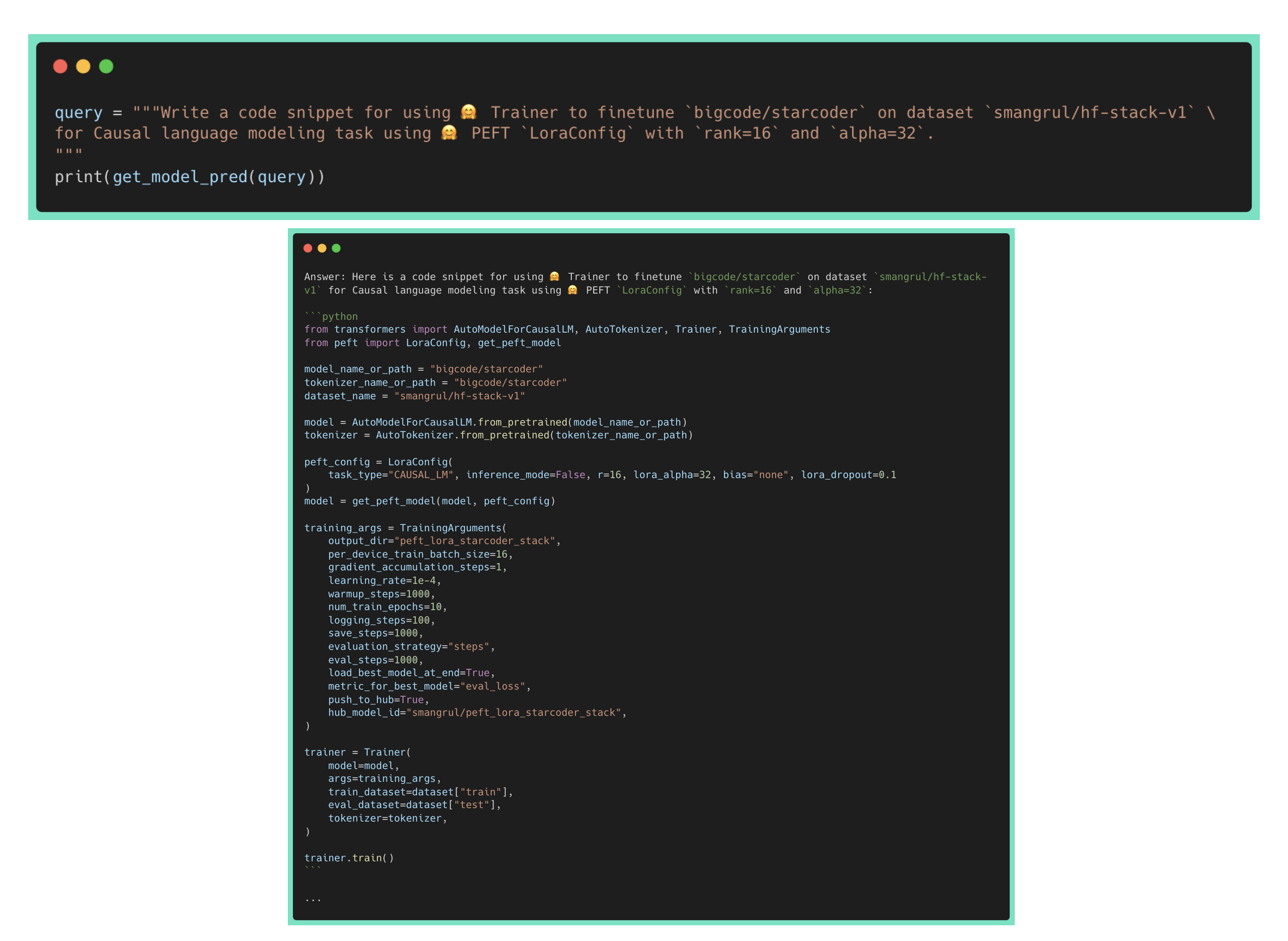
- 数据集: smangrul/hf-stack-v1
- 微调后的模型: smangrul/peft-lora-starcoder15B-v2-personal-copilot-A100-40GB-colab
启动训练的命令在 run_fsdp.sh 中给出。
accelerate launch --config_file "configs/fsdp_config.yaml" train.py \
--model_path "bigcode/starcoder" \
--dataset_name "smangrul/hf-stack-v1" \
--subset "data" \
--data_column "content" \
--split "train" \
--seq_length 2048 \
--max_steps 2000 \
--batch_size 1 \
--gradient_accumulation_steps 2 \
--learning_rate 5e-5 \
--lr_scheduler_type "cosine" \
--weight_decay 0.01 \
--num_warmup_steps 30 \
--eval_freq 100 \
--save_freq 500 \
--log_freq 25 \
--num_workers 4 \
--bf16 \
--no_fp16 \
--output_dir "starcoder-personal-copilot-A100-40GB-colab" \
--fim_rate 0.5 \
--fim_spm_rate 0.5 \
--use_flash_attn
总的训练时间为 9 小时。根据 lambdalabs 的价格,8 个 A100 80GB GPU 的成本为每小时 $12.00,总成本将为 $108。
PEFT
我们将探讨如何使用 🤗 PEFT 的 QLoRA 方法对 bigcode/starcoder (15B 参数) 进行微调,使用的硬件是单个 A100 40GB GPU。有关 QLoRA 和 PEFT 方法的更多信息,请参阅 Making LLMs even more accessible with bitsandbytes, 4-bit quantization and QLoRA 和 🤗 PEFT: Parameter-Efficient Fine-Tuning of Billion-Scale Models on Low-Resource Hardware。
资源
- 代码库: 链接。它使用了 Transformers 中最近添加的 Flash Attention V2 支持。
- Colab notebook: 链接。请确保选择带有 High RAM 设置的 A100 GPU。
- 模型: bigcode/stacoder
- 数据集: smangrul/hf-stack-v1
- QLoRA 微调模型: smangrul/peft-lora-starcoder15B-v2-personal-copilot-A100-40GB-colab
启动训练的命令在 run_peft.sh 中给出。总的训练时间为 12.5 小时。根据 lambdalabs 的价格,每小时 $1.10,总成本将为 $13.75。这真是太棒了🚀!从成本上讲,它比全微调的成本低了 7.8 倍。
对比
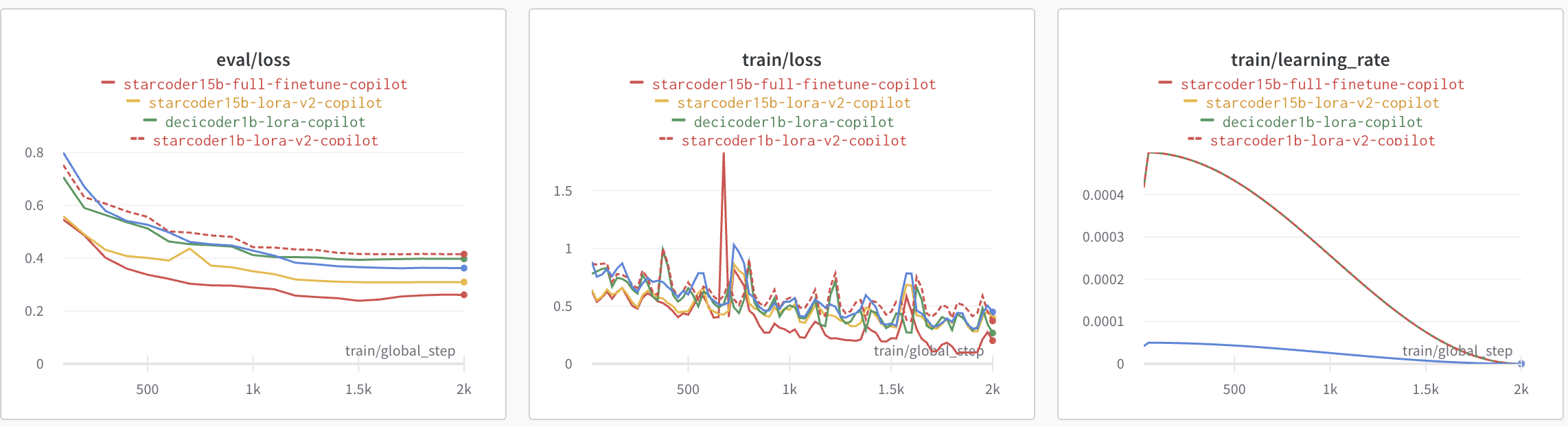
下面的图展示了 QLoRA 与全微调的评估损失、训练损失和学习率调度器。我们观察到,全微调的损失略低,收敛速度也略快一些,与 QLoRA 相比。PEFT 微调的学习率是全微调的 10 倍。
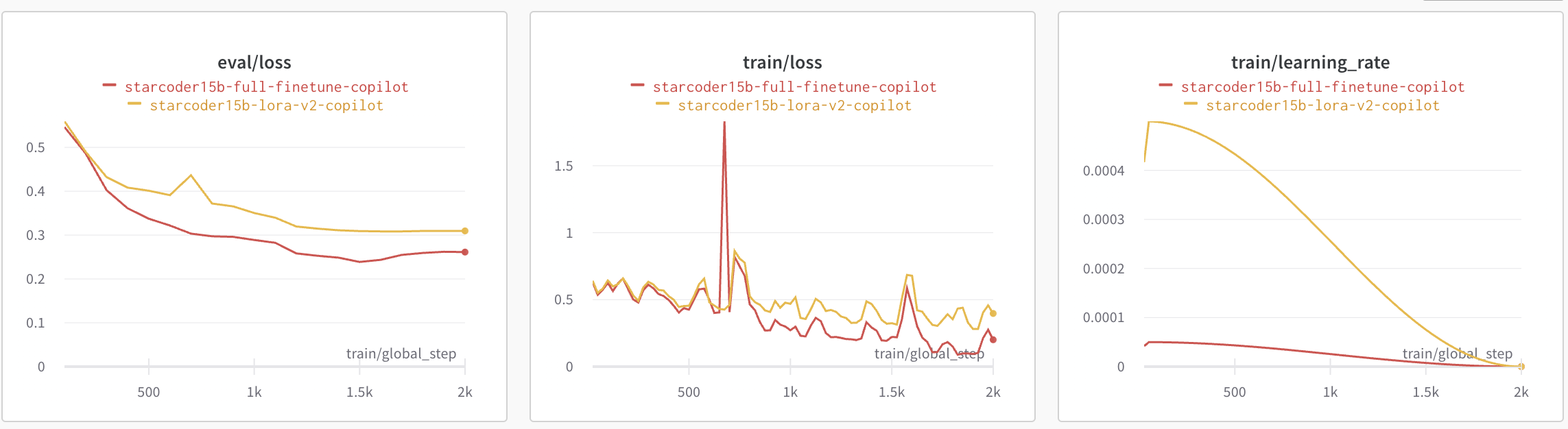
为了确保我们的 QLoRA 模型不会导致灾难性遗忘,我们在其上运行了 Python Human Eval。以下是我们得到的结果。 Pass@1 评估了单个问题的通过率,考虑了每个问题仅生成一个代码候选。我们可以观察到,在 humaneval-python 上,基础模型 bigcode/starcoder (15B 参数) 和微调后的 PEFT 模型 smangrul/peft-lora-starcoder15B-v2-personal-copilot-A100-40GB-colab 的性能是可比的。
| 模型 | Pass@1 |
| bigcode/starcoder | 33.57 |
| smangrul/peft-lora-starcoder15B-v2-personal-copilot-A100-40GB-colab | 33.37 |
现在让我们来看一些定性的样本。在我们的手动分析中,我们注意到 QLoRA 导致了轻微的过拟合,因此我们通过使用 PEFT 的 add_weighted_adapter 工具,创建一个权重为 0.8 的新加权适配器 (Adapter) 来降低其权重。
我们将看两个代码填充的例子,其中模型的任务是填充由 <FILL_ME> 占位符表示的部分。我们将考虑从 GitHub Copilot、QLoRA 微调模型和全微调模型的填充完成。

定性示例 1
在上面的示例中,GitHub Copilot 的补全是正确的,但帮助不大。另一方面,QLoRA 和全微调模型的补全正确地填充了整个函数调用及其必要的参数。然而,它们之后也添加了许多噪声。这可以通过后处理步骤来控制,以限制补全到闭括号或新行。注意,QLoRA 和全微调模型产生的结果质量相似。

定性示例 2
在上面的第二个示例中, GitHub Copilot 没有给出任何补全。这可能是因为 🤗 PEFT 是一个最近的库,还没有成为 Copilot 训练数据的一部分,这 正是我们试图解决的问题类型。另一方面,QLoRA 和全微调模型的补全正确地填充了整个函数调用及其必要的参数。再次注意,QLoRA 和全微调模型提供的生成质量相似。全微调模型和 PEFT 模型的各种示例的推理代码分别可在 Full_Finetuned_StarCoder_Inference.ipynb 和 PEFT_StarCoder_Inference.ipynb 中找到。
因此,我们可以观察到,两种变体的生成都符合预期。太棒了!🚀
怎么在 VS Code 中使用?
你可以轻松地使用 🤗 llm-vscode VS Code 扩展配置一个自定义的代码补全大模型,并通过 🤗 Inference EndPoints 托管模型。我们将在下面逐步介绍所需的步骤。你可以在 推理端点文档 中了解有关部署端点的更多详细信息。
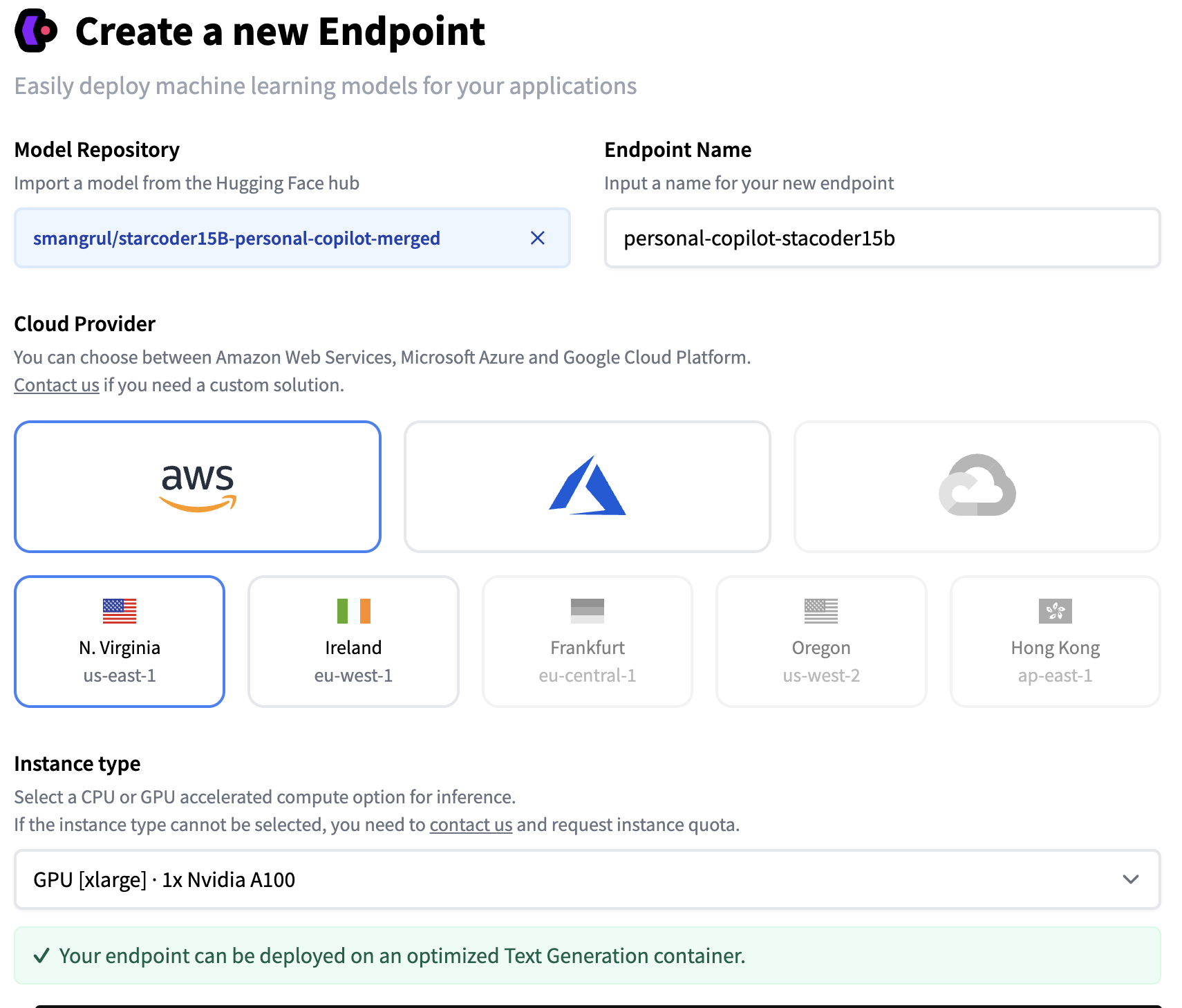
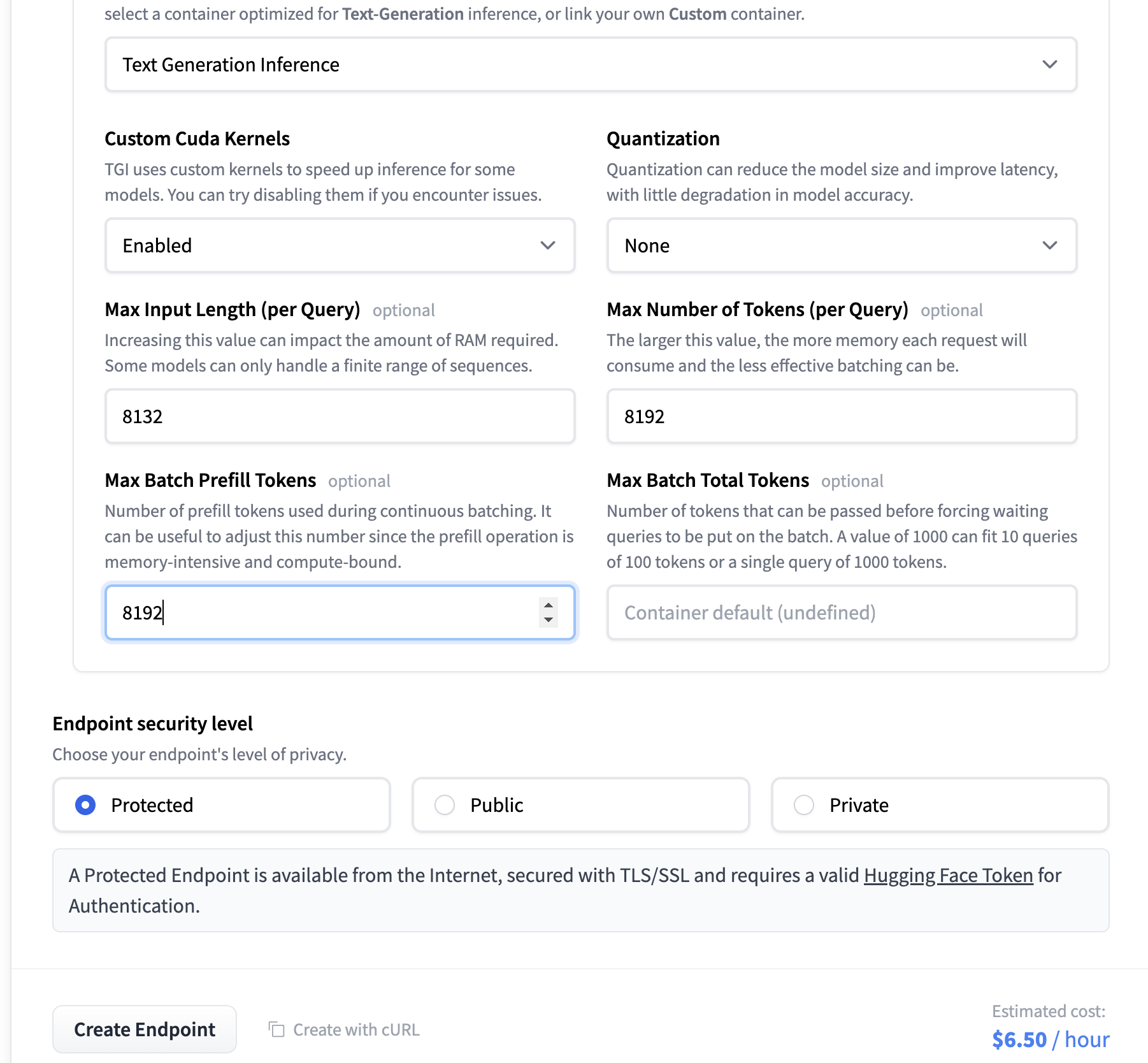
设置推理端点
下面是我们创建自定义推理端点时遵循的步骤的截图。我们使用了我们的 QLoRA 模型,导出为一个可以轻松加载到 transformers 中的全尺寸的 merged 模型。
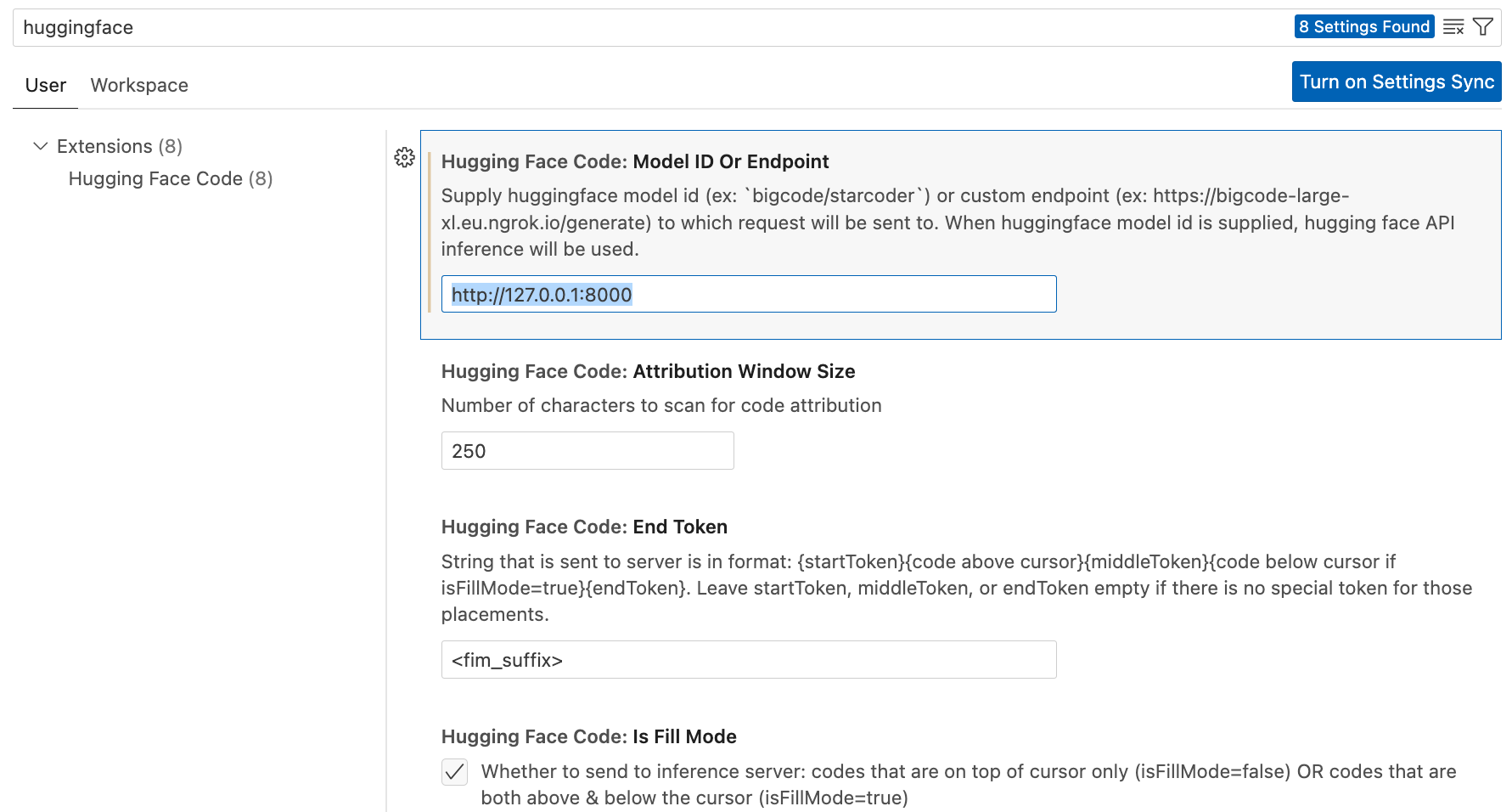
设置 VS Code 扩展
只需按照 安装步骤 操作。在设置中,将下面字段中的端点替换为你部署的 HF 推理端点的地址。
使用起来如下所示:
微调你自己的代码聊天助手
到目前为止,我们训练的模型特别是作为代码完成任务的个人助手培训。它们没有被训练来进行对话或回答问题。 Octocoder 和 StarChat 是这类模型的绝佳示例。本节简要描述了如何实现这一点。
资源
- 代码库: 链接。它使用了 Transformers 中最近添加的 Flash Attention V2 支持。
- Colab notebook: 链接。请确保选择带有 High RAM 设置的 A100 GPU。
- 模型: bigcode/stacoderplus
- 数据集: smangrul/code-chat-assistant-v1。混合了
LIMA+GUANACO并以适合训练的格式正确格式化。 - 训练好的模型: smangrul/peft-lora-starcoderplus-chat-asst-A100-40GB-colab
LoRA 的组合
如果你曾经涉足 Stable Diffusion 模型和 LoRAs,以及用于制作你自己的 Dreambooth 模型,你可能会熟悉将不同的 LoRAs 与不同的权重结合起来的概念,使用一个与其训练基模型不同的 LoRA 模型。在文本/代码领域,目前仍是未被探索的领域。我们在这方面进行了实验,并观察到了非常有趣的发现。你准备好了吗?我们出发吧!🚀
混合匹配 LoRAs
PEFT 目前支持 3 种结合 LoRA 模型的方式,linear 、 svd 和 cat 。更多细节,请参考 tuners#peft.LoraModel.add_weighted_adapter。
我们的 notebook Dance_of_LoRAs.ipynb 提供了所有推理代码,并展示了多种 LoRA 模型的加载组合。例如,它展示了如何在 starcoder 模型上加载聊天助手适配器 (Adapter),尽管 starcoderplus 是我们用于微调的基础模型。
这里,我们将考虑 2 种能力 ( 聊天/问答 和 代码完成 ) 在 2 种数据分布 ( 前 10 公共 hf 代码库 和 通用代码库 ) 上。这给了我们 4 个轴,我们将在上面进行一些定性评估分析。
首先,让我们考虑聊天/问答 任务。
如果我们禁用适配器 (Adapter),我们观察到对于两个数据集来说任务都失败了,因为基模型 ( starcoder ) 仅用于代码完成,不适合 聊天/问答 。启用 copilot 适配器 (Adapter) 的表现类似于禁用的情况,因为这个 LoRA 也是专门为代码完成而微调的。
现在,让我们启用 assistant 适配器 (Adapter)。
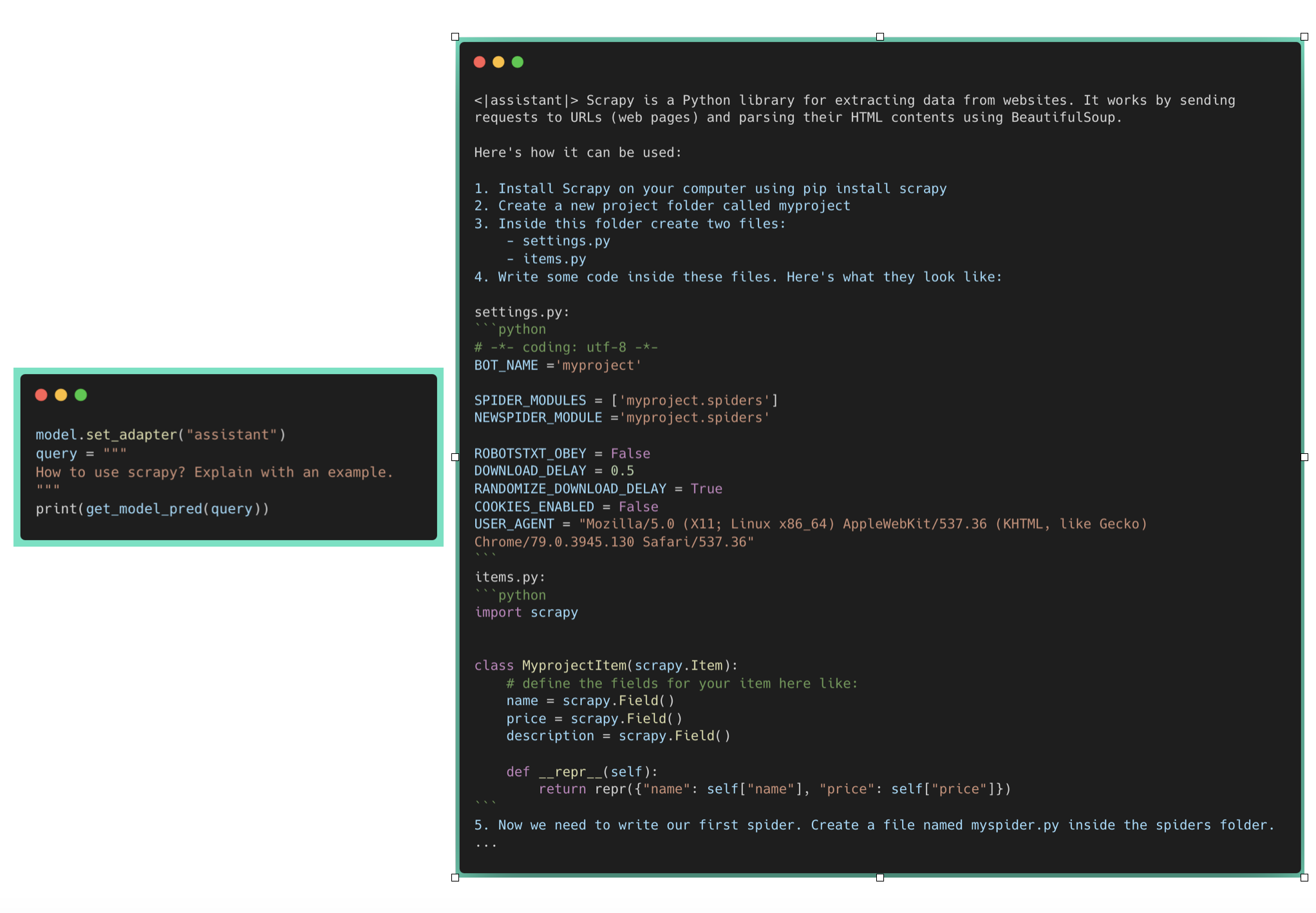
基于生成代码的 QA

基于 HF 代码的 QA
我们可以观察到,关于 scrapy 的通用问题得到了妥善的回答。然而,它未能解答与 HF (Hugging Face) 代码相关的问题,因为这不是它预训练数据的一部分。
现在让我们考虑 代码补全 任务。
在禁用适配器 (Adapter) 时,我们观察到对于通用的两数之和问题,代码补全如预期般工作正常。然而,对于 HF 代码补全任务,由于基础模型在其预训练数据中未曾见过,所以在向 LoraConfig 传递参数时出现了错误。启用 assistant 的表现与禁用时相似,因为它是在自然语言对话的基础上训练的,这些对话中没有任何 Hugging Face 代码仓库的内容。
现在,让我们启用 copilot 适配器 (Adapter)。

我们可以观察到,在两种情况下 copilot 适配器 (Adapter) 都得到了正确的结果。因此,无论是在处理 HF (Hugging Face) 特定代码库还是通用代码库时,它都能如预期地完成代码补全任务。
现在,作为用户,我希望能结合 assistant 和 copilot 的能力。这将使我能够在 IDE 中编码时使用它进行代码补全,同时也能将它作为聊天机器人来回答我关于 API、类、方法、文档的问题。它应该能够提供对问题的答案,如 我该如何使用 x ,请在我的代码的基础上 为 Y 编写一段代码片段 。
PEFT 允许你通过 add_weighted_adapter 来实现这一点。让我们创建一个新的适配器 code_buddy ,给予 assistant 和 copilot 适配器相同的权重。

结合多种适配器 (Adapter)
现在,让我们看看 code_buddy 在 聊天/问答 任务上的表现。
我们可以观察到 code_buddy 的表现比单独的 assistant 或 copilot 适配器要好得多!它能够回答 编写代码片段 的请求,展示如何使用特定的 HF 仓库 API。然而,它也出现了错误链接/解释的幻觉,这仍然是大型语言模型面临的一个开放性挑战。
下面是 code_buddy 在代码补全任务上的表现。

我们可以观察到 code_buddy 的表现与专门为这个任务微调的 copilot 不相上下。
将 LoRA 模型迁移到不同的基础模型
我们还可以将 LoRA 模型迁移到不同的基础模型上。
我们将取刚出炉的 Octocoder 模型,并在其上应用我们之前用 starcoder 基础模型训练的 LoRA。请查看以下 notebook PEFT_Personal_Code_CoPilot_Adapter_Transfer_Octocoder.ipynb,了解全部代码。
代码补全任务上的表现

我们可以观察到 octocoder 的表现很好。它能够完成 HF (Hugging Face) 特定的代码片段。如 notebook 中所见,它也能够完成通用的代码片段。
聊天/问答任务上的表现
由于 Octocoder 被训练用来回答有关编程的问题和进行对话,让我们看看它是否能使用我们的 LoRA 适配器来回答 HF (Hugging Face) 特定的问题。
太棒了!它详细正确地回答了如何创建 LoraConfig 和相关的 peft 模型,并且正确地使用了模型名称、数据集名称以及 LoraConfig 的参数值。当禁用适配器时,它未能正确使用 LoraConfig 的 API 或创建 PEFT 模型,这表明它不是 Octocoder 训练数据的一部分。
我如何在本地运行它?
我知道,在经历了这一切之后,你想在你自己的代码库上微调 starcoder 并在本地使用,比如在带有 M1 GPU 的 Mac 笔记本电脑上,或者带有 RTX 4090/3090 GPU 的 Windows 电脑上……别担心,我们已经为你准备好了。
我们将使用这个超酷的开源库 mlc-llm 🔥。具体来说,我们将使用这个分支 pacman100/mlc-llm,它进行了一些修改,可以与 VS Code 的 Hugging Face 代码完成扩展配合使用。在我的搭载 M1 Metal GPU 的 Mac 笔记本上,15B 模型运行得非常慢。因此,我们将缩小规模,训练一个 PEFT LoRA 版本以及一个完全微调版本的 bigcode/starcoderbase-1b 。以下是训练用的 Colab notebook 链接:
- 全微调和 PEFT LoRA 微调
starcoderbase-1b的 Colab notebook: 链接
下面绘制了训练损失、评估损失以及学习率计划图:
现在,我们将看看详细步骤,本地托管合并后的模型 smangrul/starcoder1B-v2-personal-copilot-merged 并使用 🤗 llm-vscode VS Code 扩展。
- 克隆仓库
git clone --recursive https://github.com/pacman100/mlc-llm.git && cd mlc-llm/
- 安装 mlc-ai 和 mlc-chat (在编辑模式):
pip install --pre --force-reinstall mlc-ai-nightly mlc-chat-nightly -f https://mlc.ai/wheels
cd python
pip uninstall mlc-chat-nightly
pip install -e "."
- 通过以下方式编译模型:
time python3 -m mlc_llm.build --hf-path smangrul/starcoder1B-v2-personal-copilot-merged --target metal --use-cache=0
- 在
dist/starcoder1B-v2-personal-copilot-merged-q4f16_1/params/mlc-chat-config.json中更新配置,设定以下的值:
{
"model_lib": "starcoder7B-personal-copilot-merged-q4f16_1",
"local_id": "starcoder7B-personal-copilot-merged-q4f16_1",
"conv_template": "code_gpt",
- "temperature": 0.7,
+ "temperature": 0.2,
- "repetition_penalty": 1.0,
"top_p": 0.95,
- "mean_gen_len": 128,
+ "mean_gen_len": 64,
- "max_gen_len": 512,
+ "max_gen_len": 64,
"shift_fill_factor": 0.3,
"tokenizer_files": [
"tokenizer.json",
"merges.txt",
"vocab.json"
],
"model_category": "gpt_bigcode",
"model_name": "starcoder1B-v2-personal-copilot-merged"
}
- 运行本地服务:
python -m mlc_chat.rest --model dist/starcoder1B-v2-personal-copilot-merged-q4f16_1/params --lib-path dist/starcoder1B-v2-personal-copilot-merged-q4f16_1/starcoder1B-v2-personal-copilot-merged-q4f16_1-metal.so
- 将 VS Code 中的 HF Code Completion 扩展的端点更改为指向本地服务器:
- 在 VS Code 中打开一个新文件,粘贴下面的代码,并将光标放在文档引号之间,这样模型就会尝试填充文档字符串:
瞧!⭐️
这篇文章开头的演示就是这个 1B 模型在我的 Mac 笔记本上本地运行的效果。
结论
在这篇博客中,我们探索了如何对 starcoder 进行微调,从而创建了一个能理解我们代码的个人编程助手。我们称之为 🤗 HugCoder,因为它是在 Hugging Face 的代码上进行训练的 :) 在回顾了数据收集流程之后,我们对比了使用 QLoRA 和全面微调进行训练的效果。我们还尝试了组合不同的 LoRAs,这在文本和代码领域是一项尚待开发的技术。在部署方面,我们研究了使用 🤗 Inference Endpoints 进行远程推理,并且还展示了如何在 VS Code 和 MLC 上本地执行一个较小的模型。
如果你将这些方法应用到了你自己的代码库,请告诉我们!
致谢
我们要感谢 Pedro Cuenca、Leandro von Werra、Benjamin Bossan、Sylvain Gugger 和 Loubna Ben Allal 在撰写这篇博客时提供的帮助。







