使用 PyTorch FSDP 微调 Llama 2 70B










本文也提供英文版本 English。
引言
通过本文,你将了解如何使用 PyTorch FSDP 及相关最佳实践微调 Llama 2 70B。在此过程中,我们主要会用到 Hugging Face Transformers、Accelerate 和 TRL 库。我们还将展示如何在 SLURM 中使用 Accelerate。
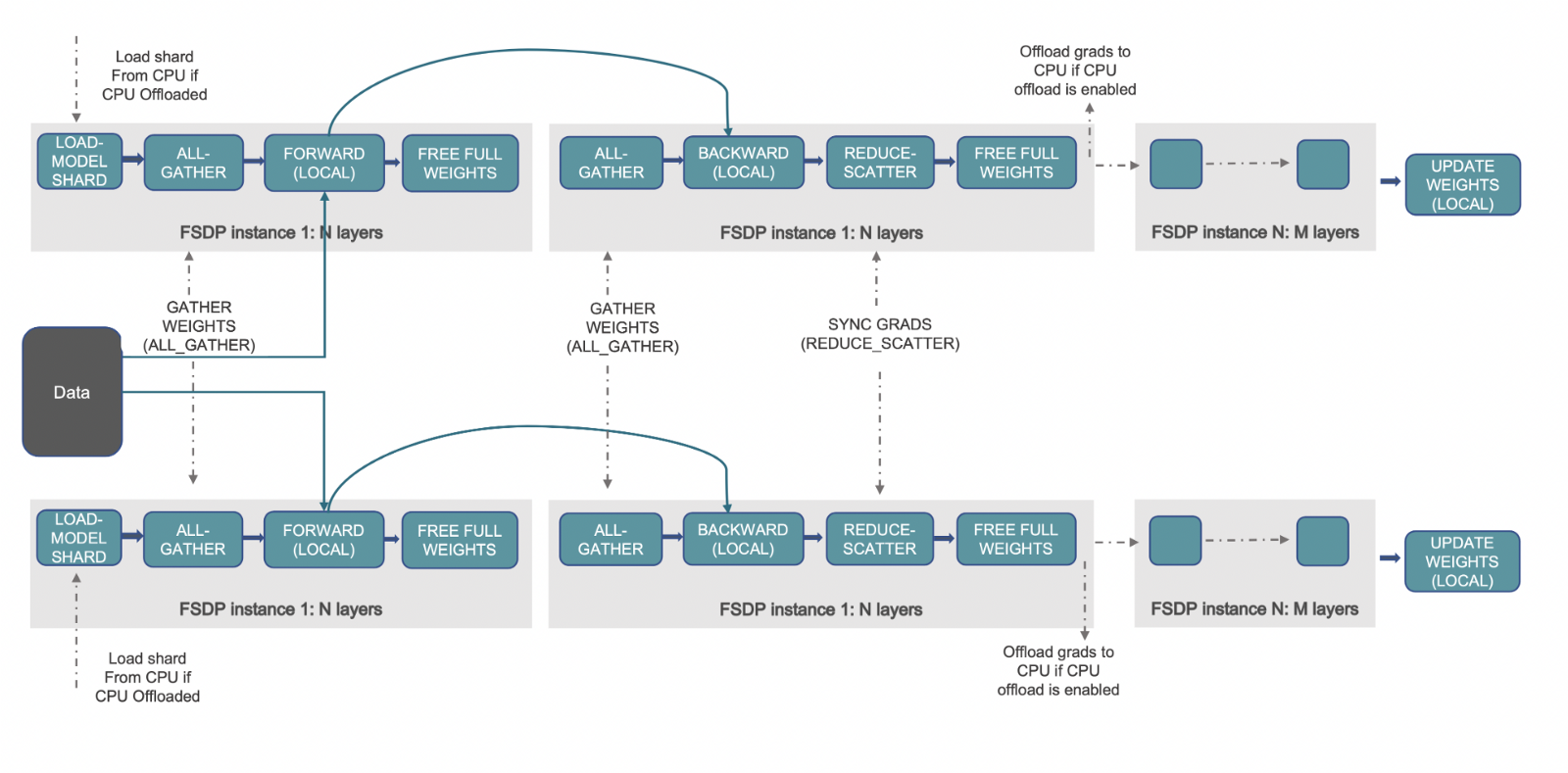
完全分片数据并行 (Fully Sharded Data Parallelism,FSDP) 是一种训练范式,在该范式中优化器状态、梯度和模型参数都会被跨设备分片。前向传播时,每个 FSDP 单元执行 all gather 以获取完整的权重,然后用它们进行计算并在计算后丢弃掉其他设备的分片。随后是反向传播,然后就是损失计算。反向传播时,每个 FSDP 单元执行 all gather 操作以获取完整的权重,并执行计算以获得本地 batch 的梯度。这些梯度通过 reduce scatter 在设备上进行均值计算并分片,这样每个设备都可以更新其对应分片的参数。有关 PyTorch FSDP 的更多信息,请参阅此博文: 使用 PyTorch 完全分片数据并行技术加速大模型训练。
(图源: 链接)
使用的硬件
节点数: 2,至少 1 个节点
每节点 GPU 数: 8
GPU 类型: A100
GPU 显存: 80GB
节点内互联: NVLink
每节点内存: 1TB
每节点 CPU 核数: 96
节点间互联: AWS 的 Elastic Fabric Adapter (EFA)
微调 LLaMa 2 70B 面临的挑战
在尝试使用 FSDP 微调 LLaMa 2 70B 时,我们主要遇到了三个挑战:
- FSDP 会先加载整个预训练模型,然后再对模型进行分片。这样就意味着节点内的每个进程 (即 rank) 都会加载整个 Llama-70B 模型,因此需要 7048 GB ~ 2TB 的 CPU 内存,这个算式中 4 是每个参数所需字节数,8 是每个节点的 GPU 数。这会导致 CPU 内存不足,进而导致进程终止。
- 使用
FULL_STATE_DICT来保存完整中间检查点并将其卸载至 rank 0 的 CPU 内存中需要花费大量时间,且由于在此期间通信库需要无限期挂起等待保存完成,因此经常会导致 NCCL 超时错误。然而,完全关掉这个选项也不好,因为在训练结束时我们需要保存完整的模型状态字典,而不是 FSDP 式分片的状态字典。 - 我们需要提高速度并减少显存使用,以加快训练并节约计算成本。
下文,我们主要讨论如何一一解决上述挑战,最终微调出一个 70B 的模型!
先列出重现结果所需的所有资源:
- 代码库:
https://github.com/pacman100/DHS-LLM-Workshop/tree/main/chat_assistant/training ,代码中包含了使能 flash 注意力 V2 的热补丁 - FSDP 配置文件:
https://github.com/pacman100/DHS-LLM-Workshop/blob/main/chat_assistant/training/configs/fsdp_config.yaml - SLURM 启动脚本 -
launch.slurm:https://gist.github.com/pacman100/1cb1f17b2f1b3139a63b764263e70b25 - 模型:
meta-llama/Llama-2-70b-chat-hf - 数据集: smangrul/code-chat-assistant-v1 (混合了 LIMA 和 GUANACO 数据集,且已转换为训练所需的格式)
准备工作
首先按照 此步骤 安装 Flash Attention V2。然后,安装最新的 PyTorch nightly (CUDA ≥11.8)。接着,根据 此文件 安装其余依赖软件。在本文中,我们是从主分支安装 🤗 Accelerate 和 🤗 Transformers 的。
微调
应对挑战 1
PR 25107 和 PR 1777 解决了第一个挑战,且无需用户侧更改任何代码。主要做的事情如下:
- 在所有 rank 上创建无权重的空模型 (使用
meta设备) - 仅在 rank 0 上将状态字典加载至模型
- 其他 rank 仅对
meta设备上的参数执行torch.empty(*param.size(), dtype=dtype) - 因此,只有 rank 0 上加载了完整的模型及权重,而所有其他 rank 上的权重是空的
- 设置
sync_module_states=True,以便 FSDP 实例在训练开始之前将权重广播到各 rank
下面是在 2 个 GPU 上加载 7B 模型的输出日志片段,它测量了各个阶段内存的消耗及其加载的模型参数量。我们可以观察到,在加载预训练模型时,rank 0 和 rank 1 的 CPU 峰值内存分别为 32744 MB 和 1506 MB 。因此可知,仅有 rank 0 加载了预训练模型,这就实现了 CPU 内存的有效利用。你可在 此处 找到完整日志。
accelerator.process_index=0 GPU Memory before entering the loading : 0
accelerator.process_index=0 GPU Memory consumed at the end of the loading (end-begin): 0
accelerator.process_index=0 GPU Peak Memory consumed during the loading (max-begin): 0
accelerator.process_index=0 GPU Total Peak Memory consumed during the loading (max): 0
accelerator.process_index=0 CPU Memory before entering the loading : 926
accelerator.process_index=0 CPU Memory consumed at the end of the loading (end-begin): 26415
accelerator.process_index=0 CPU Peak Memory consumed during the loading (max-begin): 31818
accelerator.process_index=0 CPU Total Peak Memory consumed during the loading (max): 32744
accelerator.process_index=1 GPU Memory before entering the loading : 0
accelerator.process_index=1 GPU Memory consumed at the end of the loading (end-begin): 0
accelerator.process_index=1 GPU Peak Memory consumed during the loading (max-begin): 0
accelerator.process_index=1 GPU Total Peak Memory consumed during the loading (max): 0
accelerator.process_index=1 CPU Memory before entering the loading : 933
accelerator.process_index=1 CPU Memory consumed at the end of the loading (end-begin): 10
accelerator.process_index=1 CPU Peak Memory consumed during the loading (max-begin): 573
accelerator.process_index=1 CPU Total Peak Memory consumed during the loading (max): 1506
应对挑战 2
该挑战可以通过在配置 FSDP 时将状态字典类型设为 SHARDED_STATE_DICT 来解决。设为 SHARDED_STATE_DICT 后,每个 rank 各自保存各自 GPU 所需要的分片,这使得用户可以快速保存中间检查点并快速从其恢复训练。而当使用 FULL_STATE_DICT 时,第一个进程 (rank 0) 会用 CPU 收集整个模型,然后将其保存为标准格式。
我们可以用以下命令创建相应的 accelerte 配置文件:
accelerate config --config_file "fsdp_config.yaml"
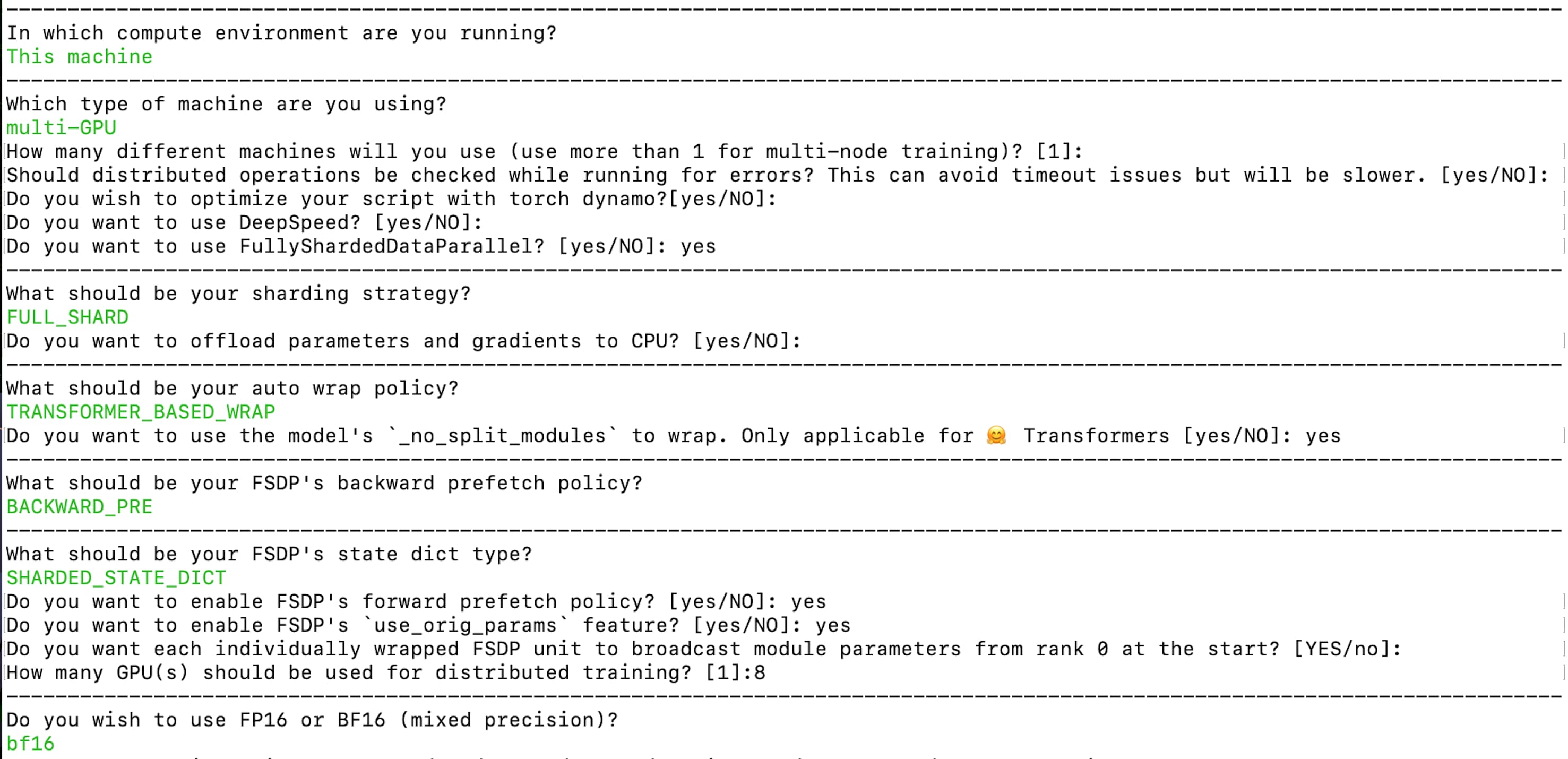
你可以从此处获取生成的配置文件: fsdp_config.yaml。在该配置文件中,分片策略是 FULL_SHARD 。我们使用 TRANSFORMER_BASED_WRAP 作为自动模型包装策略,它使用 _no_split_module 来搜索 transformer 块名并自动进行嵌套 FSDP 包装。我们使用 SHAARDED_STATE_DICT 把中间检查点和优化器状态保存为 PyTorch 官方推荐的格式。同时,如上一节 应对挑战 1 中所述,我们还需要确保训练开始时用 rank 0 来广播参数。从配置文件中你还可以看到我们用的是 bf16 混合精度训练。
那么,在保存最终检查点时,如果将其保存成单个文件呢?我们使用的是以下代码段:
if trainer.is_fsdp_enabled:
trainer.accelerator.state.fsdp_plugin.set_state_dict_type("FULL_STATE_DICT")
trainer.save_model(script_args.output_dir) # 或者 , 如果整个模型小于 50 GB (即 LFS 单文件的最大尺寸),你还可以使用 trainer.push_to_hub() 把模型推到 hub 上去。
应对挑战 3
为了加快训练速度并减少显存占用,我们可以使用 flash 注意力并开启梯度检查点优化,从而在微调的同时节省计算成本。当前,我们用了一个热补丁来实现 flash 注意力,具体代码可见 这儿。
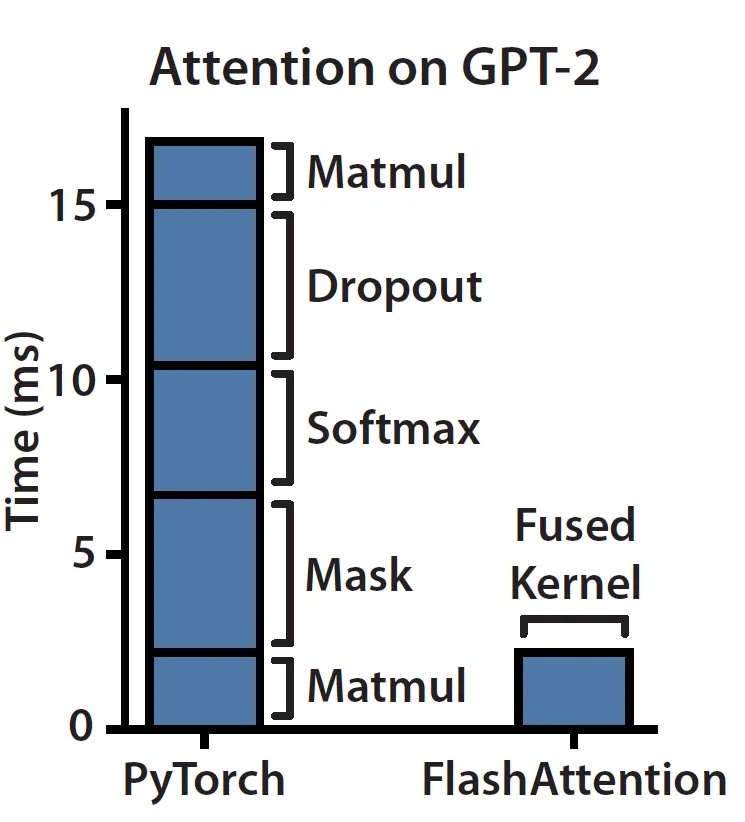
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness 一文基于对底层硬件 (即 GPU) 的内存层次结构的深刻理解而引入了一种更快、更节省内存的无损注意力加速算法。底层硬件在设计内存层次结构时,遵循的实践原则是: 带宽/速度越高的内存,其容量越小,因为它更贵。
根据博文 根据第一性原理让深度学习性能起飞,我们可以发现,当前硬件上的注意力模块是 内存带宽受限 的。原因是注意力机制 主要由逐元素操作 组成,如下左图所示。我们可以观察到,掩码、softmax 和 dropout 操作占用了大部分时间,而非需要大量 FLOP 的矩阵乘法。
(图源: 链接)
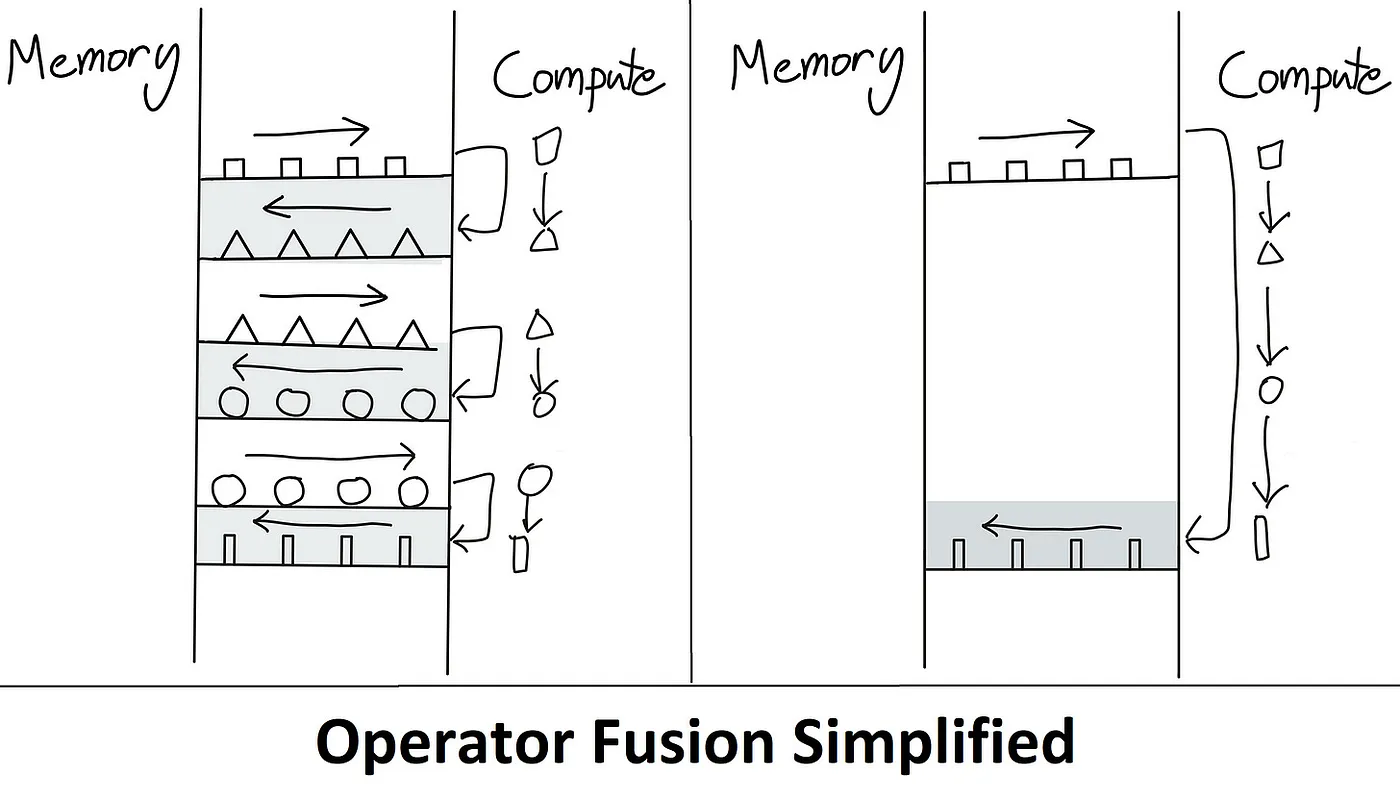
这正是 flash 注意力解决的问题,其想法是 去除冗余的 HBM 读/写操作。该算法通过将所有内容保留在 SRAM 中,待执行完所有中间步骤后再将最终结果写回到 HBM,即 算子融合 来实现这一目的。下图简要描述了算子融合是如何克服内存瓶颈的。
(图源: 链接)
在前向和反向传播过程中我们还使用了 平铺 (Tiling) 优化技巧,将 NxN 大小的 softmax 分数计算切成块,以克服 SRAM 内存大小的限制。在使用平铺技巧时,我们会使用在线 softmax 算法。同时,我们还在反向传播中使用了 重计算 技巧,以大大降低在前向传播过程中存储整个 NxN softmax 分数矩阵所带来的内存消耗。
如欲深入理解 flash 注意力,请参考博文 ELI5: FlashAttention、根据第一性原理让深度学习性能起飞 以及原始论文 FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness。
综合运用所有手段
你可参考 此脚本,以在 SLURM 中用 Accelerate 启动器运行训练。下面还给出了一个等效命令,展示了如何使用 Accelerate 启动器来运行训练。请注意,该命令会覆盖 fsdp_config.yaml 中的 main_process_ip 、 main_process_port 、 machine_rank 、 num_processes 以及 num_machines 配置。另一个需要重点注意的是,这里的存储是所有节点共享的。
accelerate launch \
--config_file configs/fsdp_config.yaml \
--main_process_ip $MASTER_ADDR \
--main_process_port $MASTER_PORT \
--machine_rank \$MACHINE_RANK \
--num_processes 16 \
--num_machines 2 \
train.py \
--model_name "meta-llama/Llama-2-70b-chat-hf" \
--dataset_name "smangrul/code-chat-assistant-v1" \
--max_seq_len 2048 \
--max_steps 500 \
--logging_steps 25 \
--eval_steps 100 \
--save_steps 250 \
--bf16 True \
--packing True \
--output_dir "/shared_storage/sourab/experiments/full-finetune-llama-chat-asst" \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 1 \
--dataset_text_field "content" \
--use_gradient_checkpointing True \
--learning_rate 5e-5 \
--lr_scheduler_type "cosine" \
--weight_decay 0.01 \
--warmup_ratio 0.03 \
--use_flash_attn True
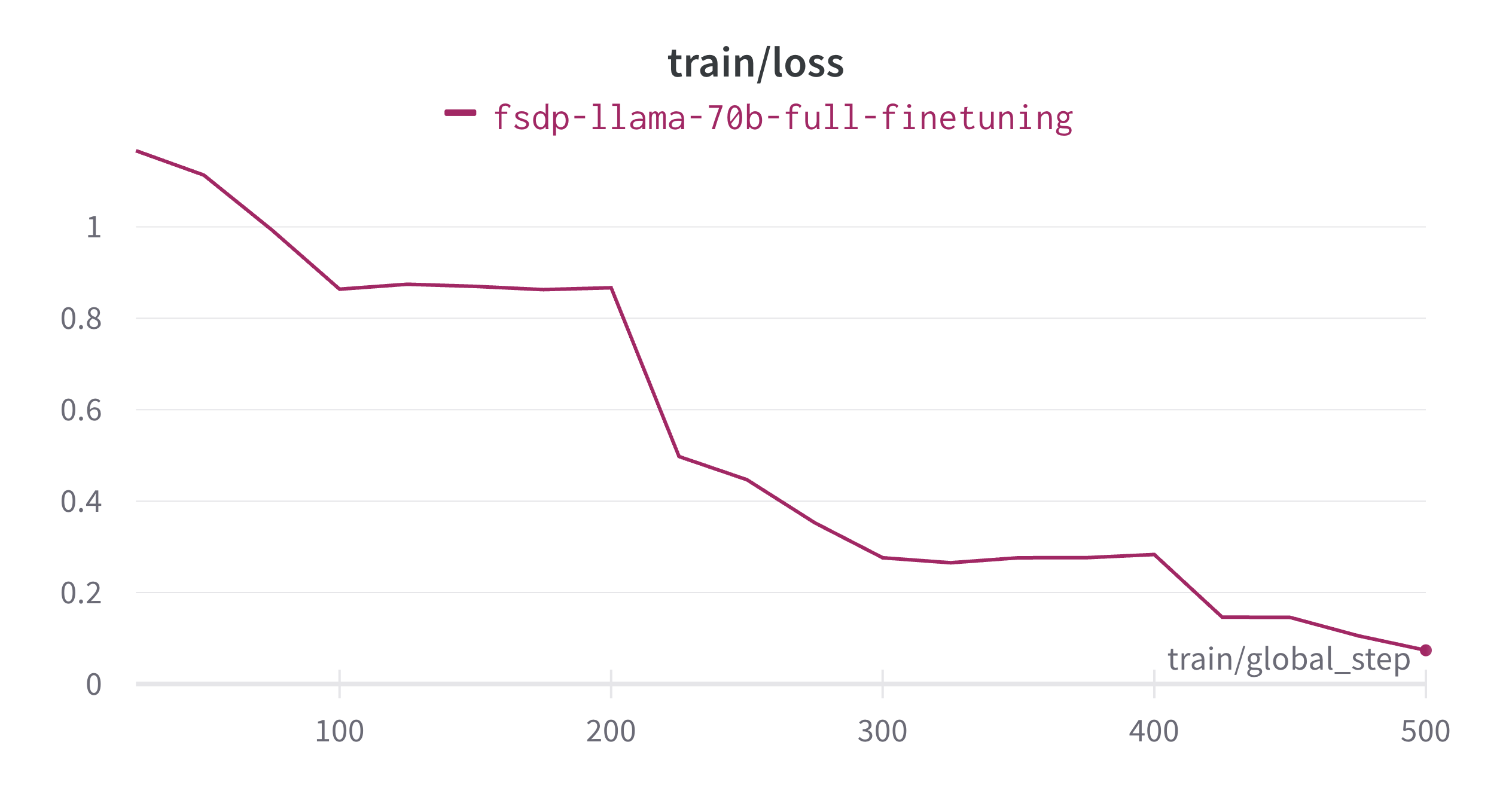
整个微调过程需要约 13.5 小时,下图给出了训练损失曲线。
下例给出了使用上述模型完成的一段对话:
System Prompt: You are a helpful, respectful and honest assistant. Always answer as helpfully \
as possible, while being safe. Your answers should not include any harmful, \
unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that \
your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why \
instead of answering something not correct. If you don’t know the answer to a \
question, please don’t share false information.
- Human: What is Deep Learning? Explain like a Pirate.
+ Assistant: Arrr Grumete! Are ye lookin' fer a proper explanation o' Deep Learnin'?
+ Alright then, listen up me hearty! Deep Learnin' be a type o' machine learnin' that uses artificial neural networks to analyze data.
+ Aye, ye heard that right, mateys! Artificial neural networks be models o' the human brain, but instead o' using neurons, they use interconnected nodes or "artificial neurons" to process information.
+ These nodes work together to form layers o' processing units that can learn from large amounts o' data.
+ The more data these systems receive, the better they get at recognizing patterns and makin' decisions on their own.
+ So hoist the sails and set course for adventure with deep learnin', me hearties! It's a treasure trove o' knowledge just waitin' to be discovered.
+ Fair winds and following seas!
- Human: Now explain it like a chef.
+ Assistant: Certainly! Here's an explanation of deep learning from a culinary perspective:
+ Think of a recipe as a sequence of steps used to transform raw ingredients into a delicious dish.
+ Similarly, in deep learning, there are multiple layers of "ingredients" (or features) that are combined and transformed through various operations to produce a final output or prediction.
+ Each layer builds upon the previous one, refining and enhancing the representation of the input data until it reaches the desired outcome.
+ Just as different spices enhance the flavors of food, each layer adds depth and complexity to the model's understanding of the input, allowing it to make more accurate predictions.
+ And much like how chefs must carefully balance the amount of salt, sugar, and other seasonings in a recipe, the training process in deep learning involves adjusting the weights and biases of the network to achieve the perfect blend of accuracy and efficiency.
+ With enough practice and experimentation, anyone can become a master chef... I mean, a master of deep learning! Bon appétit!
整个对话使用的格式如下:
<|system|> system message <|endoftext|> <|prompter|> Q1 <|endoftext|> <|assistant|> A1 <|endoftext|> ...
总结
我们在多节点多 GPU 上使用 PyTorch FSDP 成功微调了一个 70B Llama 模型,并在此过程中解决了各种挑战。我们看到了当前在 🤗 Transformers 和 🤗 Accelerates 中应如何初始化大模型从而有效克服 CPU 内存不足的问题。我们还给出了如何高效地保存/加载中间检查点,同时又能以易于使用的方式保存最终模型的最佳实践。为了加速训练并减少 GPU 显存使用,我们还强调了 flash 注意力和梯度检查点机制的重要性。最后,我们向大家展示了在 🤗 Accelerate 上仅需要简单的配置就可以在多节点多 GPU 上微调大模型。







