
File size: 5,820 Bytes
e189beb db01457 c60ac86 db01457 c60ac86 e189beb db01457 e189beb db01457 c3e0d53 e189beb c60ac86 e189beb db01457 e189beb c60ac86 e189beb e93f381 b0f1be3 e93f381 b0f1be3 e93f381 e189beb db01457 e189beb db01457 e189beb db01457 e189beb c83c22a e189beb db01457 e189beb db01457 e189beb c83c22a e189beb c60ac86 9dbbdda db01457 e189beb 27d7335 db01457 e189beb db01457 e189beb db01457 e189beb db01457 e189beb c60ac86 e189beb c83c22a e189beb db01457 e189beb db01457 e189beb c83c22a e189beb db01457 e189beb db01457 e189beb c83c22a e189beb db01457 e189beb db01457 e189beb c83c22a e189beb c83c22a e189beb db01457 e189beb db01457 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 |
---
tags:
- vision
- coin
- clip
- coin-retrieval
- coin-recognition
- coin-search-engine
- multi-modal learning
widget:
- src: >-
https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-dog-music.png
candidate_labels: playing music, playing sports
example_title: Cat & Dog
license: apache-2.0
library_name: transformers
pipeline_tag: feature-extraction
---
# Coin-CLIP 🪙 : Enhancing Coin Image Retrieval with CLIP
## Model Details / 模型细节
This model (**Coin-CLIP**) is built upon
OpenAI's **[CLIP](https://huggingface.co/openai/clip-vit-base-patch32) (ViT-B/32)** model and fine-tuned on
a dataset of more than `340,000` coin images using contrastive learning techniques. This specialized model is designed to significantly improve feature extraction for coin images, leading to more accurate image-based search capabilities. Coin-CLIP combines the power of Visual Transformer (ViT) with CLIP's multimodal learning capabilities, specifically tailored for the numismatic domain.
**Key Features:**
- State-of-the-art coin image retrieval;
- Enhanced feature extraction for numismatic images;
- Seamless integration with CLIP's multimodal learning.
本模型(**Coin-CLIP**)
在 OpenAI 的 **[CLIP](https://huggingface.co/openai/clip-vit-base-patch32) (ViT-B/32)** 模型基础上,利用对比学习技术在超过 `340,000` 张硬币图片数据上微调得到的。
**Coin-CLIP** 旨在提高模型针对硬币图片的特征提取能力,从而实现更准确的以图搜图功能。该模型结合了视觉变换器(ViT)的强大功能和 CLIP 的多模态学习能力,并专门针对硬币图片进行了优化。
## Comparison: Coin-CLIP vs. CLIP / 效果对比
#### Example 1 (Left: Coin-CLIP; Right: CLIP)
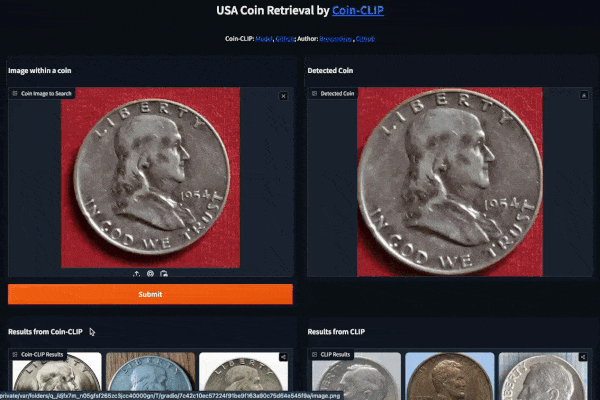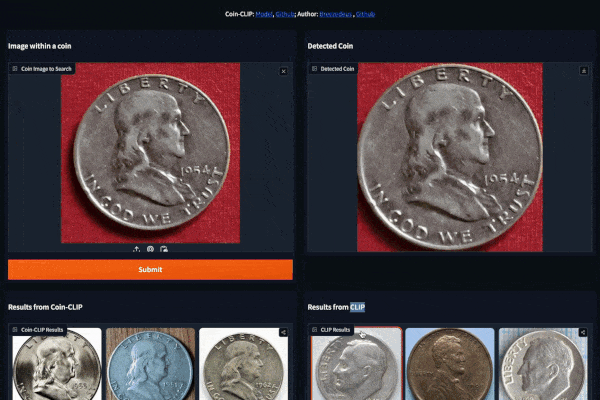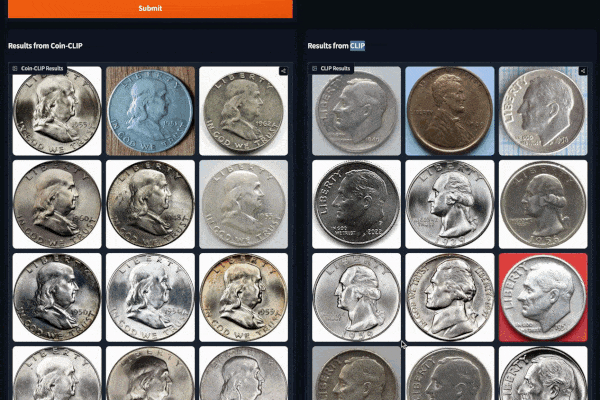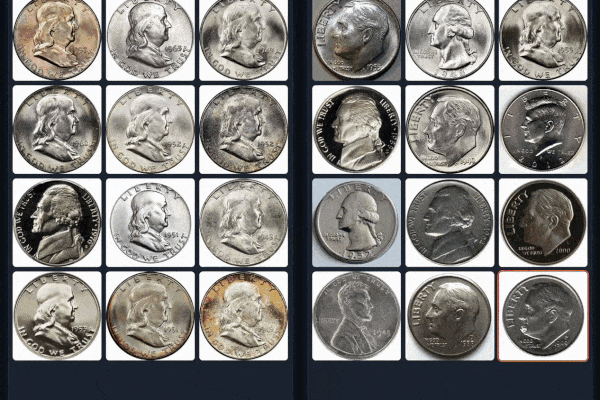
#### Example 2 (Left: Coin-CLIP; Right: CLIP)
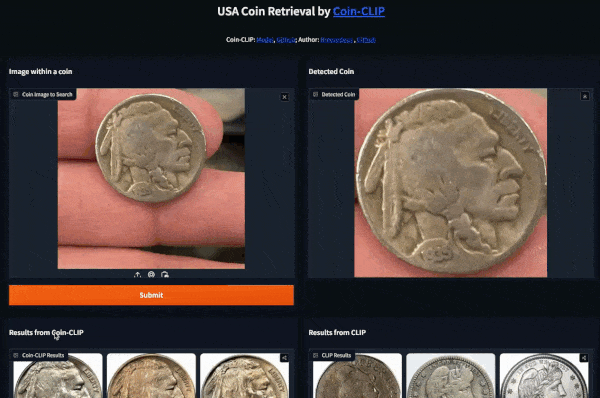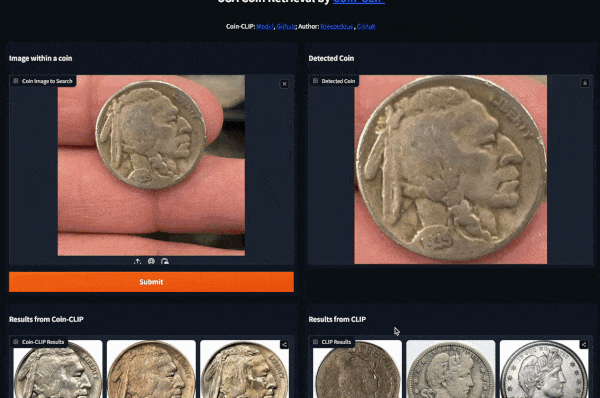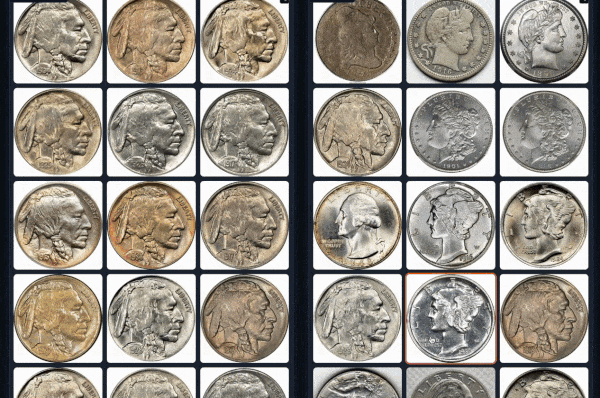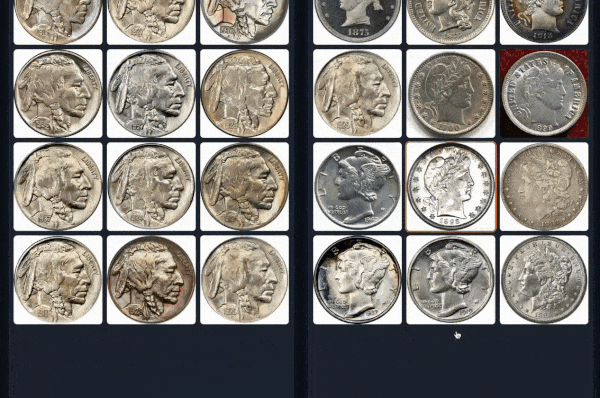
More examples can be found: [breezedeus/Coin-CLIP: Coin CLIP](https://github.com/breezedeus/Coin-CLIP) .
## Usage and Limitations / 使用和限制
- **Usage**: This model is primarily used for extracting representation vectors from coin images, enabling efficient and precise image-based searches in a coin image database.
- **Limitations**: As the model is trained specifically on coin images, it may not perform well on non-coin images.
- **用途**:此模型主要用于提取硬币图片的表示向量,以实现在硬币图像库中进行高效、精确的以图搜图。
- **限制**:由于模型是针对硬币图像进行训练的,因此在处理非硬币图像时可能效果不佳。
## Documents / 文档
- Base Model: [openai/clip-vit-base-patch32](https://huggingface.co/openai/clip-vit-base-patch32)
## Model Use / 模型使用
### Transformers
```python
from PIL import Image
import requests
import torch.nn.functional as F
from transformers import CLIPProcessor, CLIPModel
model = CLIPModel.from_pretrained("breezedeus/coin-clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("breezedeus/coin-clip-vit-base-patch32")
image_fp = "path/to/coin_image.jpg"
image = Image.open(image_fp).convert("RGB")
inputs = processor(images=image, return_tensors="pt")
img_features = model.get_image_features(**inputs)
img_features = F.normalize(img_features, dim=1)
```
### Tool / 工具
To further simplify the use of the **Coin-CLIP** model, we provide a simple Python library [breezedeus/Coin-CLIP: Coin CLIP](https://github.com/breezedeus/Coin-CLIP) for quickly building a coin image retrieval engine.
为了进一步简化 **Coin-CLIP** 模型的使用,我们提供了一个简单的 Python 库 [breezedeus/Coin-CLIP: Coin CLIP](https://github.com/breezedeus/Coin-CLIP),以便快速构建硬币图像检索引擎。
#### Install
```bash
pip install coin_clip
```
#### Extract Feature Vectors
```python
from coin_clip import CoinClip
# Automatically download the model from Huggingface
model = CoinClip(model_name='breezedeus/coin-clip-vit-base-patch32')
images = ['examples/10_back.jpg', 'examples/16_back.jpg']
img_feats, success_ids = model.get_image_features(images)
print(img_feats.shape) # --> (2, 512)
```
More Tools can be found: [breezedeus/Coin-CLIP: Coin CLIP](https://github.com/breezedeus/Coin-CLIP) .
## Training Data / 训练数据
The model was trained on a specialized coin image dataset. This dataset includes images of various currencies' coins.
本模型使用的是专门的硬币图像数据集进行训练。这个数据集包含了多种货币的硬币图片。
## Training Process / 训练过程
The model was fine-tuned on the OpenAI CLIP (ViT-B/32) pretrained model using a coin image dataset. The training process involved Contrastive Learning fine-tuning techniques and parameter settings.
模型是在 OpenAI 的 CLIP (ViT-B/32) 预训练模型的基础上,使用硬币图像数据集进行微调。训练过程采用了对比学习的微调技巧和参数设置。
## Performance / 性能
This model demonstrates excellent performance in coin image retrieval tasks.
该模型在硬币图像检索任务上展现了优异的性能。
## Feedback / 反馈
> Where to send questions or comments about the model.
Welcome to contact the author [Breezedeus](https://www.breezedeus.com/join-group).
欢迎联系作者 [Breezedeus](https://www.breezedeus.com/join-group) 。 |