
Commit
•
4ad32d0
1
Parent(s):
8170922
Upload folder using huggingface_hub
Browse files- .gitignore +8 -0
- README.md +63 -0
- assets/img/alpaca_blog.png +0 -0
- assets/img/mtbench_hf.png +0 -0
- main.py +203 -0
- outputs/alpacaeval/Mistral-ORPO-alpha.json +0 -0
- outputs/alpacaeval/Mistral-ORPO-beta.json +0 -0
- outputs/mtbench/Mistral-ORPO-alpha.jsonl +0 -0
- outputs/mtbench/Mistral-ORPO-beta.jsonl +0 -0
- requirements.txt +114 -0
- runpod.sh +24 -0
- scripts/run_mistral_orpo_beta.sh +20 -0
- scripts/run_mistral_orpo_capybara.sh +22 -0
- src/accelerate/ds2.yaml +21 -0
- src/args.py +34 -0
- src/orpo_trainer.py +83 -0
- src/utils.py +20 -0
- trl/test_orpo_trainer_demo.py +95 -0
.gitignore
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
wandb
|
| 2 |
+
src/__pycache__
|
| 3 |
+
scripts/run_orpo.sh
|
| 4 |
+
src/accelerate/fsdp.yaml
|
| 5 |
+
scripts/run_orpo.sh
|
| 6 |
+
src/__pycache__/args.cpython-311.pyc
|
| 7 |
+
src/__pycache__/utils.cpython-311.pyc
|
| 8 |
+
src/accelerate/fsdp.yaml
|
README.md
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# **ORPO**
|
| 2 |
+
|
| 3 |
+
### **`Updates (24.03.25)`**
|
| 4 |
+
- [X] Sample script for ORPOTrainer in 🤗<a class="link" href="https://github.com/huggingface/trl">TRL</a> is added to `trl/test_orpo_trainer_demo.py`
|
| 5 |
+
- [X] New model, 🤗<a class="link" href="https://huggingface.co/kaist-ai/mistral-orpo-capybara-7k">kaist-ai/mistral-orpo-capybara-7k</a>, is added to 🤗<a class="link" href="https://huggingface.co/collections/kaist-ai/orpo-65efef87544ba100aef30013">ORPO Collection</a>
|
| 6 |
+
- [X] Now you can try ORPO in 🤗<a class="link" href="https://github.com/huggingface/trl">TRL</a> and <a class="link" href="https://github.com/OpenAccess-AI-Collective/axolotl">Axolotl</a>🔥
|
| 7 |
+
- [X] We are making general guideline for training LLMs with ORPO, stay tuned🔥
|
| 8 |
+
- [X] **Mistral-ORPO-β** achieved a 14.7% in the length-controlled (LC) win rate on <a class="link" href="https://tatsu-lab.github.io/alpaca_eval/">official AlpacaEval Leaderboard</a>🔥
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
This is the official repository for <a class="link" href="https://arxiv.org/abs/2403.07691">**ORPO: Monolithic Preference Optimization without Reference Model**</a>. The detailed results in the paper can be found in:
|
| 13 |
+
- [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=kaist-ai%2Fmistral-orpo-beta)
|
| 14 |
+
- [AlpacaEval](#alpacaeval)
|
| 15 |
+
- [MT-Bench](#mt-bench)
|
| 16 |
+
- [IFEval](#ifeval)
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
### **`Model Checkpoints`**
|
| 20 |
+
|
| 21 |
+
Our models trained with ORPO can be found in:
|
| 22 |
+
|
| 23 |
+
- [X] **Mistral-ORPO-Capybara-7k**: 🤗 <a class="link" href="https://huggingface.co/kaist-ai/mistral-orpo-capybara-7k">kaist-ai/mistral-orpo-capybara-7k</a>
|
| 24 |
+
- [X] **Mistral-ORPO-⍺**: 🤗 <a class="link" href="https://huggingface.co/kaist-ai/mistral-orpo-alpha">kaist-ai/mistral-orpo-alpha</a>
|
| 25 |
+
- [X] **Mistral-ORPO-β**: 🤗 <a class="link" href="https://huggingface.co/kaist-ai/mistral-orpo-beta">kaist-ai/mistral-orpo-beta</a>
|
| 26 |
+
|
| 27 |
+
And the corresponding logs for the average log probabilities of chosen/rejected responses during training are reported in:
|
| 28 |
+
|
| 29 |
+
- [X] **Mistral-ORPO-Capybara-7k**: TBU
|
| 30 |
+
- [X] **Mistral-ORPO-⍺**: <a class="link" href="https://wandb.ai/jiwooya1000/PREF/reports/Mistral-ORPO-7B-Training-Log--Vmlldzo3MTE1NzE0?accessToken=rms6o4mg5vo3feu1bvbpk632m4cspe19l0u1p4he3othx5bgean82chn9neiile6">Wandb Report for Mistral-ORPO-⍺</a>
|
| 31 |
+
- [X] **Mistral-ORPO-β**: <a class="link" href="https://wandb.ai/jiwooya1000/PREF/reports/Mistral-ORPO-7B-Training-Log--Vmlldzo3MTE3MzMy?accessToken=dij4qbp6dcrofsanzbgobjsne9el8a2zkly2u5z82rxisd4wiwv1rhp0s2dub11e">Wandb Report for Mistral-ORPO-β</a>
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
### **`AlpacaEval`**
|
| 36 |
+
|
| 37 |
+
<figure>
|
| 38 |
+
<img class="png" src="/assets/img/alpaca_blog.png" alt="Description of the image">
|
| 39 |
+
<figcaption><b>Figure 1.</b> AlpacaEval 2.0 score for the models trained with different alignment methods.</figcaption>
|
| 40 |
+
</figure>
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
### **`MT-Bench`**
|
| 45 |
+
|
| 46 |
+
<figure>
|
| 47 |
+
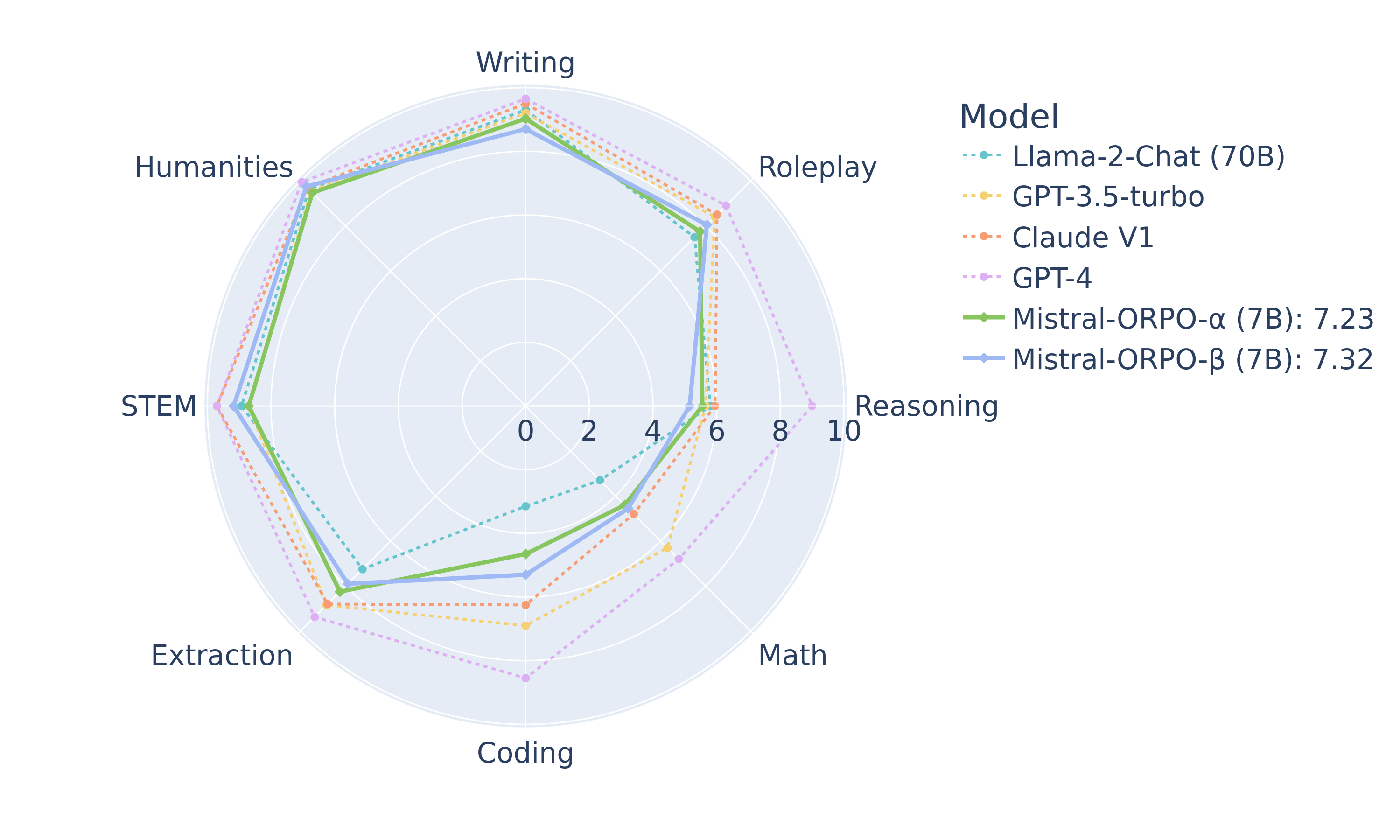
<img class="png" src="/assets/img/mtbench_hf.png" alt="Description of the image">
|
| 48 |
+
<figcaption><b>Figure 2.</b> MT-Bench result by category.</figcaption>
|
| 49 |
+
</figure>
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
### **`IFEval`**
|
| 54 |
+
|
| 55 |
+
IFEval scores are measured with <a class="link" href="https://github.com/EleutherAI/lm-evaluation-harness">EleutherAI/lm-evaluation-harness</a> by applying the chat template. The scores for Llama-2-Chat (70B), Zephyr-β (7B), and Mixtral-8X7B-Instruct-v0.1 are originally reported in <a class="link" href="https://twitter.com/wiskojo/status/1739767758462877823">this tweet</a>.
|
| 56 |
+
|
| 57 |
+
| **Model Type** | **Prompt-Strict** | **Prompt-Loose** | **Inst-Strict** | **Inst-Loose** |
|
| 58 |
+
|--------------------|:-----------------:|:----------------:|:---------------:|----------------|
|
| 59 |
+
| **Llama-2-Chat (70B)** | 0.4436 | 0.5342 | 0.5468 | 0.6319 |
|
| 60 |
+
| **Zephyr-β (7B)** | 0.4233 | 0.4547 | 0.5492 | 0.5767 |
|
| 61 |
+
| **Mixtral-8X7B-Instruct-v0.1** | 0.5213 | **0.5712** | 0.6343 | **0.6823** |
|
| 62 |
+
| **Mistral-ORPO-⍺ (7B)** | 0.5009 | 0.5083 | 0.5995 | 0.6163 |
|
| 63 |
+
| **Mistral-ORPO-β (7B)** | **0.5287** | 0.5564 | **0.6355** | 0.6619 |
|
assets/img/alpaca_blog.png
ADDED
|
assets/img/mtbench_hf.png
ADDED
|
main.py
ADDED
|
@@ -0,0 +1,203 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import os
|
| 3 |
+
import time
|
| 4 |
+
import wandb
|
| 5 |
+
import torch
|
| 6 |
+
import argparse
|
| 7 |
+
from datasets import load_dataset
|
| 8 |
+
from typing import List, Dict, Union
|
| 9 |
+
from transformers import (
|
| 10 |
+
AutoTokenizer,
|
| 11 |
+
AutoModelForCausalLM,
|
| 12 |
+
TrainingArguments,
|
| 13 |
+
DataCollatorForLanguageModeling
|
| 14 |
+
)
|
| 15 |
+
|
| 16 |
+
from src.args import default_args
|
| 17 |
+
from src.orpo_trainer import ORPOTrainer
|
| 18 |
+
from src.utils import preprocess_logits_for_metrics, dataset_split_selector
|
| 19 |
+
|
| 20 |
+
class ORPO(object):
|
| 21 |
+
def __init__(self, args) -> None:
|
| 22 |
+
self.start = time.gmtime()
|
| 23 |
+
self.args = args
|
| 24 |
+
|
| 25 |
+
# Load Tokenizer
|
| 26 |
+
print(">>> 1. Loading Tokenizer")
|
| 27 |
+
self.tokenizer = AutoTokenizer.from_pretrained(self.args.model_name, cache_dir=self.args.cache_dir)
|
| 28 |
+
if self.tokenizer.chat_template is None:
|
| 29 |
+
self.tokenizer.chat_template = "{% for message in messages %}\n{% if message['role'] == 'user' %}\n{{ '<|user|>\n' + message['content'] + eos_token }}\n{% elif message['role'] == 'system' %}\n{{ '<|system|>\n' + message['content'] + eos_token }}\n{% elif message['role'] == 'assistant' %}\n{{ '<|assistant|>\n' + message['content'] + eos_token }}\n{% endif %}\n{% if loop.last and add_generation_prompt %}\n{{ '<|assistant|>' }}\n{% endif %}\n{% endfor %}"
|
| 30 |
+
print(" 1-1. Chat Template Applied (<|user|> <|assistant|>)")
|
| 31 |
+
else:
|
| 32 |
+
pass
|
| 33 |
+
self.tokenizer.pad_token_id = self.tokenizer.eos_token_id
|
| 34 |
+
|
| 35 |
+
# Load Model
|
| 36 |
+
print(">>> 2. Loading Model")
|
| 37 |
+
if self.args.flash_attention_2:
|
| 38 |
+
self.model = AutoModelForCausalLM.from_pretrained(self.args.model_name,
|
| 39 |
+
cache_dir=self.args.cache_dir,
|
| 40 |
+
torch_dtype=torch.bfloat16,
|
| 41 |
+
attn_implementation="flash_attention_2")
|
| 42 |
+
else:
|
| 43 |
+
self.model = AutoModelForCausalLM.from_pretrained(self.args.model_name,
|
| 44 |
+
cache_dir=self.args.cache_dir,
|
| 45 |
+
torch_dtype=torch.bfloat16)
|
| 46 |
+
|
| 47 |
+
# Load Dataset
|
| 48 |
+
print(">>> 3. Loading Dataset")
|
| 49 |
+
self.data = load_dataset(self.args.data_name, cache_dir=self.args.cache_dir)
|
| 50 |
+
|
| 51 |
+
# Preprocess Dataset
|
| 52 |
+
print(">>> 4. Filtering and Preprocessing Dataset")
|
| 53 |
+
data_split = dataset_split_selector(self.data)
|
| 54 |
+
|
| 55 |
+
if len(data_split) == 1:
|
| 56 |
+
self.is_test = False
|
| 57 |
+
train_split = data_split[0]
|
| 58 |
+
print(f" >>> Test Set = {self.is_test}")
|
| 59 |
+
else:
|
| 60 |
+
self.is_test = True
|
| 61 |
+
train_split = data_split[0]
|
| 62 |
+
test_split = data_split[1]
|
| 63 |
+
|
| 64 |
+
test = self.data[test_split].filter(self.filter_dataset)
|
| 65 |
+
self.test = test.map(self.preprocess_dataset, batched=True, num_proc=self.args.num_proc, remove_columns=self.data[test_split].column_names)
|
| 66 |
+
|
| 67 |
+
train = self.data[train_split].filter(self.filter_dataset).select(range(self.args.max_samples))
|
| 68 |
+
print(f"\n\n>>> {len(train)} / {len(self.data[train_split])} rows left after filtering by prompt length.")
|
| 69 |
+
self.train = train.map(self.preprocess_dataset, batched=True, num_proc=self.args.num_proc, remove_columns=self.data[train_split].column_names)
|
| 70 |
+
|
| 71 |
+
# Set WANDB & Logging Configurations
|
| 72 |
+
self.run_name = f"{self.args.model_name.split('/')[-1]}-{self.args.data_name.split('/')[-1]}-lambda{self.args.alpha}-ORPO-{self.start.tm_mday}-{self.start.tm_hour}-{self.start.tm_min}"
|
| 73 |
+
self.save_dir = os.path.join('./checkpoints/', f"{self.args.data_name.split('/')[-1]}/{self.run_name}")
|
| 74 |
+
self.log_dir = os.path.join('./checkpoints/', f"{self.args.data_name.split('/')[-1]}/{self.run_name}/logs")
|
| 75 |
+
|
| 76 |
+
os.makedirs(self.save_dir, exist_ok=True)
|
| 77 |
+
os.makedirs(self.log_dir, exist_ok=True)
|
| 78 |
+
|
| 79 |
+
def preprocess_dataset(self, examples: Union[List, Dict]):
|
| 80 |
+
if ('instruction' in examples.keys()) or ('question' in examples.keys()):
|
| 81 |
+
prompt_key = 'instruction' if 'instruction' in examples.keys() else 'question'
|
| 82 |
+
prompt = [self.tokenizer.apply_chat_template([{'role': 'user', 'content': item}], tokenize=False, add_generation_prompt=True) for item in examples[prompt_key]]
|
| 83 |
+
chosen = [self.tokenizer.apply_chat_template([{'role': 'user', 'content': item_prompt}, {'role': 'assistant', 'content': item_chosen}], tokenize=False) for item_prompt, item_chosen in zip(examples[prompt_key], examples['chosen'])]
|
| 84 |
+
rejected = [self.tokenizer.apply_chat_template([{'role': 'user', 'content': item_prompt}, {'role': 'assistant', 'content': item_rejected}], tokenize=False) for item_prompt, item_rejected in zip(examples[prompt_key], examples['rejected'])]
|
| 85 |
+
else:
|
| 86 |
+
prompt = [self.tokenizer.apply_chat_template([item[0]], tokenize=False, add_generation_prompt=True) for item in examples['chosen']]
|
| 87 |
+
chosen = [self.tokenizer.apply_chat_template(item, tokenize=False) for item in examples['chosen']]
|
| 88 |
+
rejected = [self.tokenizer.apply_chat_template(item, tokenize=False) for item in examples['rejected']]
|
| 89 |
+
|
| 90 |
+
model_inputs = self.tokenizer(prompt,
|
| 91 |
+
max_length=self.args.response_max_length,
|
| 92 |
+
padding='max_length',
|
| 93 |
+
truncation=True,
|
| 94 |
+
return_tensors='pt')
|
| 95 |
+
pos_labels = self.tokenizer(chosen,
|
| 96 |
+
max_length=self.args.response_max_length,
|
| 97 |
+
padding='max_length',
|
| 98 |
+
truncation=True,
|
| 99 |
+
return_tensors='pt')
|
| 100 |
+
neg_labels = self.tokenizer(rejected,
|
| 101 |
+
max_length=self.args.response_max_length,
|
| 102 |
+
padding='max_length',
|
| 103 |
+
truncation=True,
|
| 104 |
+
return_tensors='pt')
|
| 105 |
+
|
| 106 |
+
model_inputs['positive_input_ids'] = pos_labels['input_ids']
|
| 107 |
+
model_inputs['positive_attention_mask'] = pos_labels['attention_mask']
|
| 108 |
+
|
| 109 |
+
model_inputs['negative_input_ids'] = neg_labels['input_ids']
|
| 110 |
+
model_inputs['negative_attention_mask'] = neg_labels['attention_mask']
|
| 111 |
+
|
| 112 |
+
return model_inputs
|
| 113 |
+
|
| 114 |
+
def filter_dataset(self, examples: Union[List, Dict]):
|
| 115 |
+
if 'instruction' in examples.keys():
|
| 116 |
+
query = examples['instruction']
|
| 117 |
+
prompt_length = self.tokenizer.apply_chat_template([{'content': query, 'role': 'user'}], tokenize=True, add_generation_prompt=True, return_tensors='pt').size(-1)
|
| 118 |
+
elif 'question' in examples.keys():
|
| 119 |
+
query = examples['question']
|
| 120 |
+
prompt_length = self.tokenizer.apply_chat_template([{'content': query, 'role': 'user'}], tokenize=True, add_generation_prompt=True, return_tensors='pt').size(-1)
|
| 121 |
+
else:
|
| 122 |
+
prompt_length = self.tokenizer.apply_chat_template([examples['chosen'][0]], tokenize=True, add_generation_prompt=True, return_tensors='pt').size(-1)
|
| 123 |
+
|
| 124 |
+
if prompt_length < self.args.prompt_max_length:
|
| 125 |
+
return True
|
| 126 |
+
else:
|
| 127 |
+
return False
|
| 128 |
+
|
| 129 |
+
def prepare_trainer(self):
|
| 130 |
+
wandb.init(name=self.run_name)
|
| 131 |
+
arguments = TrainingArguments(
|
| 132 |
+
output_dir=self.save_dir, # The output directory
|
| 133 |
+
logging_dir=self.log_dir,
|
| 134 |
+
logging_steps=50,
|
| 135 |
+
learning_rate=self.args.lr,
|
| 136 |
+
overwrite_output_dir=True, # overwrite the content of the output directory
|
| 137 |
+
num_train_epochs=self.args.num_train_epochs, # number of training epochs
|
| 138 |
+
per_device_train_batch_size=self.args.per_device_train_batch_size, # batch size for training
|
| 139 |
+
per_device_eval_batch_size=self.args.per_device_eval_batch_size, # batch size for evaluation
|
| 140 |
+
evaluation_strategy=self.args.evaluation_strategy if self.is_test else 'no', # batch size for evaluation
|
| 141 |
+
save_strategy=self.args.evaluation_strategy,
|
| 142 |
+
optim=self.args.optim,
|
| 143 |
+
warmup_steps=self.args.warmup_steps,
|
| 144 |
+
gradient_accumulation_steps=self.args.gradient_accumulation_steps,
|
| 145 |
+
gradient_checkpointing=True, #if ('llama' in self.args.model_name.lower()) or ('mistral' in self.args.model_name.lower()) else False,
|
| 146 |
+
gradient_checkpointing_kwargs={'use_reentrant':True},
|
| 147 |
+
load_best_model_at_end=self.is_test,
|
| 148 |
+
do_train=True,
|
| 149 |
+
do_eval=self.is_test,
|
| 150 |
+
lr_scheduler_type=self.args.lr_scheduler_type,
|
| 151 |
+
remove_unused_columns=False,
|
| 152 |
+
report_to='wandb',
|
| 153 |
+
run_name=self.run_name,
|
| 154 |
+
bf16=True
|
| 155 |
+
)
|
| 156 |
+
|
| 157 |
+
data_collator = DataCollatorForLanguageModeling(tokenizer=self.tokenizer, mlm=False)
|
| 158 |
+
|
| 159 |
+
self.trainer = ORPOTrainer(
|
| 160 |
+
model=self.model,
|
| 161 |
+
alpha=self.args.alpha,
|
| 162 |
+
pad=self.tokenizer.pad_token_id,
|
| 163 |
+
args=arguments,
|
| 164 |
+
train_dataset=self.train,
|
| 165 |
+
eval_dataset=self.test if self.is_test else None,
|
| 166 |
+
data_collator=data_collator,
|
| 167 |
+
preprocess_logits_for_metrics=preprocess_logits_for_metrics
|
| 168 |
+
)
|
| 169 |
+
|
| 170 |
+
def run(self):
|
| 171 |
+
print(">>> 5. Preparing ORPOTrainer")
|
| 172 |
+
self.prepare_trainer()
|
| 173 |
+
self.trainer.train()
|
| 174 |
+
|
| 175 |
+
# Saving code for FSDP
|
| 176 |
+
if self.trainer.is_fsdp_enabled:
|
| 177 |
+
self.trainer.accelerator.state.fsdp_plugin.set_state_dict_type("FULL_STATE_DICT")
|
| 178 |
+
self.trainer.save_model()
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
if __name__ == '__main__':
|
| 182 |
+
parser = argparse.ArgumentParser("ORPO")
|
| 183 |
+
args = default_args(parser)
|
| 184 |
+
|
| 185 |
+
# Set WANDB configurations
|
| 186 |
+
if args.wandb_entity is not None and args.wandb_project_name is not None:
|
| 187 |
+
os.environ["WANDB_ENTITY"] = args.wandb_entity
|
| 188 |
+
os.environ["WANDB_PROJECT"] = args.wandb_project_name
|
| 189 |
+
else:
|
| 190 |
+
pass
|
| 191 |
+
os.environ["TOKENIZERS_PARALLELISM"] = 'false'
|
| 192 |
+
|
| 193 |
+
print("================================================================================================\n")
|
| 194 |
+
print(f">>> Fine-tuning {args.model_name} with ORPO on {args.data_name}\n")
|
| 195 |
+
print("================================================================================================")
|
| 196 |
+
print("\n\n>>> Summary:")
|
| 197 |
+
print(f" - Lambda : {args.alpha}")
|
| 198 |
+
print(f" - Training Epochs : {args.num_train_epochs}")
|
| 199 |
+
print(f" - Prompt Max Length : {args.prompt_max_length}")
|
| 200 |
+
print(f" - Response Max Length : {args.response_max_length}")
|
| 201 |
+
|
| 202 |
+
item = ORPO(args=args)
|
| 203 |
+
item.run()
|
outputs/alpacaeval/Mistral-ORPO-alpha.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
outputs/alpacaeval/Mistral-ORPO-beta.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
outputs/mtbench/Mistral-ORPO-alpha.jsonl
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
outputs/mtbench/Mistral-ORPO-beta.jsonl
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
requirements.txt
ADDED
|
@@ -0,0 +1,114 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
accelerate @ file:///home/conda/feedstock_root/build_artifacts/accelerate_1710334587919/work
|
| 2 |
+
aiohttp @ file:///croot/aiohttp_1707342283163/work
|
| 3 |
+
aiosignal @ file:///tmp/build/80754af9/aiosignal_1637843061372/work
|
| 4 |
+
appdirs==1.4.4
|
| 5 |
+
asttokens @ file:///home/conda/feedstock_root/build_artifacts/asttokens_1698341106958/work
|
| 6 |
+
attrs @ file:///croot/attrs_1695717823297/work
|
| 7 |
+
bitsandbytes==0.43.0
|
| 8 |
+
Bottleneck @ file:///croot/bottleneck_1707864210935/work
|
| 9 |
+
Brotli @ file:///work/ci_py311/brotli-split_1676830125088/work
|
| 10 |
+
cachetools==5.3.3
|
| 11 |
+
certifi @ file:///home/conda/feedstock_root/build_artifacts/certifi_1707022139797/work/certifi
|
| 12 |
+
cffi @ file:///croot/cffi_1700254295673/work
|
| 13 |
+
charset-normalizer @ file:///tmp/build/80754af9/charset-normalizer_1630003229654/work
|
| 14 |
+
click @ file:///croot/click_1698129812380/work
|
| 15 |
+
comm @ file:///home/conda/feedstock_root/build_artifacts/comm_1710320294760/work
|
| 16 |
+
datasets @ file:///home/conda/feedstock_root/build_artifacts/datasets_1709395865330/work
|
| 17 |
+
debugpy @ file:///croot/debugpy_1690905042057/work
|
| 18 |
+
decorator @ file:///home/conda/feedstock_root/build_artifacts/decorator_1641555617451/work
|
| 19 |
+
dill @ file:///croot/dill_1692271232022/work
|
| 20 |
+
docker-pycreds @ file:///Users/ktietz/demo/mc3/conda-bld/docker-pycreds_1630654474270/work
|
| 21 |
+
einops==0.7.0
|
| 22 |
+
exceptiongroup @ file:///home/conda/feedstock_root/build_artifacts/exceptiongroup_1704921103267/work
|
| 23 |
+
executing @ file:///home/conda/feedstock_root/build_artifacts/executing_1698579936712/work
|
| 24 |
+
filelock @ file:///croot/filelock_1700591183607/work
|
| 25 |
+
flash-attn==2.5.6
|
| 26 |
+
frozenlist @ file:///croot/frozenlist_1698702560391/work
|
| 27 |
+
fsspec==2023.4.0
|
| 28 |
+
gitdb @ file:///tmp/build/80754af9/gitdb_1617117951232/work
|
| 29 |
+
GitPython @ file:///croot/gitpython_1696936983078/work
|
| 30 |
+
gmpy2 @ file:///work/ci_py311/gmpy2_1676839849213/work
|
| 31 |
+
huggingface-hub @ file:///croot/huggingface_hub_1708634519519/work
|
| 32 |
+
idna @ file:///work/ci_py311/idna_1676822698822/work
|
| 33 |
+
importlib_metadata @ file:///home/conda/feedstock_root/build_artifacts/importlib-metadata_1709821103657/work
|
| 34 |
+
ipykernel @ file:///home/conda/feedstock_root/build_artifacts/ipykernel_1708996548741/work
|
| 35 |
+
ipython @ file:///home/conda/feedstock_root/build_artifacts/ipython_1709559745751/work
|
| 36 |
+
jedi @ file:///home/conda/feedstock_root/build_artifacts/jedi_1696326070614/work
|
| 37 |
+
Jinja2==3.1.2
|
| 38 |
+
jupyter_client @ file:///home/conda/feedstock_root/build_artifacts/jupyter_client_1710255804825/work
|
| 39 |
+
jupyter_core @ file:///home/conda/feedstock_root/build_artifacts/jupyter_core_1710257359434/work
|
| 40 |
+
MarkupSafe @ file:///croot/markupsafe_1704205993651/work
|
| 41 |
+
matplotlib-inline @ file:///home/conda/feedstock_root/build_artifacts/matplotlib-inline_1660814786464/work
|
| 42 |
+
mkl-fft @ file:///croot/mkl_fft_1695058164594/work
|
| 43 |
+
mkl-random @ file:///croot/mkl_random_1695059800811/work
|
| 44 |
+
mkl-service==2.4.0
|
| 45 |
+
mpmath @ file:///croot/mpmath_1690848262763/work
|
| 46 |
+
multidict @ file:///croot/multidict_1701096859099/work
|
| 47 |
+
multiprocess @ file:///croot/multiprocess_1692294385131/work
|
| 48 |
+
nest_asyncio @ file:///home/conda/feedstock_root/build_artifacts/nest-asyncio_1705850609492/work
|
| 49 |
+
networkx==3.2.1
|
| 50 |
+
ninja==1.11.1.1
|
| 51 |
+
numexpr @ file:///croot/numexpr_1696515281613/work
|
| 52 |
+
numpy @ file:///croot/numpy_and_numpy_base_1708638617955/work/dist/numpy-1.26.4-cp311-cp311-linux_x86_64.whl#sha256=5f96f274d410a1682519282ae769c877d32fdbf171aa8badec7bf5e1d3a1748a
|
| 53 |
+
nvidia-cublas-cu11==11.11.3.6
|
| 54 |
+
nvidia-cuda-cupti-cu11==11.8.87
|
| 55 |
+
nvidia-cuda-nvrtc-cu11==11.8.89
|
| 56 |
+
nvidia-cuda-runtime-cu11==11.8.89
|
| 57 |
+
nvidia-cudnn-cu11==8.7.0.84
|
| 58 |
+
nvidia-cufft-cu11==10.9.0.58
|
| 59 |
+
nvidia-curand-cu11==10.3.0.86
|
| 60 |
+
nvidia-cusolver-cu11==11.4.1.48
|
| 61 |
+
nvidia-cusparse-cu11==11.7.5.86
|
| 62 |
+
nvidia-ml-py==12.535.133
|
| 63 |
+
nvidia-nccl-cu11==2.19.3
|
| 64 |
+
nvidia-nvtx-cu11==11.8.86
|
| 65 |
+
nvitop==1.3.2
|
| 66 |
+
packaging @ file:///croot/packaging_1693575174725/work
|
| 67 |
+
pandas @ file:///croot/pandas_1709590491089/work/dist/pandas-2.2.1-cp311-cp311-linux_x86_64.whl#sha256=0a2793a31a0135a35735e1431d453a06186a3a7c607d9b441d9bd5f0fe4ded31
|
| 68 |
+
parso @ file:///home/conda/feedstock_root/build_artifacts/parso_1638334955874/work
|
| 69 |
+
pathtools @ file:///Users/ktietz/demo/mc3/conda-bld/pathtools_1629713893697/work
|
| 70 |
+
pexpect @ file:///home/conda/feedstock_root/build_artifacts/pexpect_1706113125309/work
|
| 71 |
+
pickleshare @ file:///home/conda/feedstock_root/build_artifacts/pickleshare_1602536217715/work
|
| 72 |
+
pillow==10.2.0
|
| 73 |
+
platformdirs @ file:///home/conda/feedstock_root/build_artifacts/platformdirs_1706713388748/work
|
| 74 |
+
prompt-toolkit @ file:///home/conda/feedstock_root/build_artifacts/prompt-toolkit_1702399386289/work
|
| 75 |
+
protobuf==3.20.3
|
| 76 |
+
psutil @ file:///work/ci_py311_2/psutil_1679337388738/work
|
| 77 |
+
ptyprocess @ file:///home/conda/feedstock_root/build_artifacts/ptyprocess_1609419310487/work/dist/ptyprocess-0.7.0-py2.py3-none-any.whl
|
| 78 |
+
pure-eval @ file:///home/conda/feedstock_root/build_artifacts/pure_eval_1642875951954/work
|
| 79 |
+
pyarrow @ file:///croot/pyarrow_1707330824290/work/python
|
| 80 |
+
pyarrow-hotfix @ file:///home/conda/feedstock_root/build_artifacts/pyarrow-hotfix_1700596371886/work
|
| 81 |
+
pycparser @ file:///tmp/build/80754af9/pycparser_1636541352034/work
|
| 82 |
+
Pygments @ file:///home/conda/feedstock_root/build_artifacts/pygments_1700607939962/work
|
| 83 |
+
PySocks @ file:///work/ci_py311/pysocks_1676822712504/work
|
| 84 |
+
python-dateutil @ file:///tmp/build/80754af9/python-dateutil_1626374649649/work
|
| 85 |
+
pytz @ file:///croot/pytz_1695131579487/work
|
| 86 |
+
PyYAML @ file:///croot/pyyaml_1698096049011/work
|
| 87 |
+
pyzmq @ file:///croot/pyzmq_1705605076900/work
|
| 88 |
+
regex @ file:///croot/regex_1696515298636/work
|
| 89 |
+
requests @ file:///croot/requests_1707355572290/work
|
| 90 |
+
safetensors @ file:///croot/safetensors_1708633833937/work
|
| 91 |
+
sentry-sdk @ file:///work/ci_py311/sentry-sdk_1676862120883/work
|
| 92 |
+
setproctitle @ file:///work/ci_py311/setproctitle_1676838789127/work
|
| 93 |
+
six @ file:///tmp/build/80754af9/six_1644875935023/work
|
| 94 |
+
smmap @ file:///tmp/build/80754af9/smmap_1611694433573/work
|
| 95 |
+
stack-data @ file:///home/conda/feedstock_root/build_artifacts/stack_data_1669632077133/work
|
| 96 |
+
sympy @ file:///croot/sympy_1701397643339/work
|
| 97 |
+
termcolor==2.4.0
|
| 98 |
+
tokenizers @ file:///croot/tokenizers_1708633814160/work
|
| 99 |
+
torch==2.2.1+cu118
|
| 100 |
+
torchaudio==2.2.1+cu118
|
| 101 |
+
torchvision==0.17.1+cu118
|
| 102 |
+
tornado @ file:///croot/tornado_1696936946304/work
|
| 103 |
+
tqdm @ file:///croot/tqdm_1679561862951/work
|
| 104 |
+
traitlets @ file:///home/conda/feedstock_root/build_artifacts/traitlets_1710254411456/work
|
| 105 |
+
transformers @ file:///home/conda/feedstock_root/build_artifacts/transformers_1709308155748/work
|
| 106 |
+
triton==2.2.0
|
| 107 |
+
typing_extensions==4.8.0
|
| 108 |
+
tzdata @ file:///croot/python-tzdata_1690578112552/work
|
| 109 |
+
urllib3 @ file:///croot/urllib3_1707770551213/work
|
| 110 |
+
wandb @ file:///home/conda/feedstock_root/build_artifacts/wandb_1707246480133/work
|
| 111 |
+
wcwidth @ file:///home/conda/feedstock_root/build_artifacts/wcwidth_1704731205417/work
|
| 112 |
+
xxhash @ file:///work/ci_py311/python-xxhash_1676842384694/work
|
| 113 |
+
yarl @ file:///croot/yarl_1701105127787/work
|
| 114 |
+
zipp @ file:///home/conda/feedstock_root/build_artifacts/zipp_1695255097490/work
|
runpod.sh
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
pip install datasets accelerate wandb transformers bitsandbytes sentencepiece
|
| 2 |
+
git clone https://github.com/burtenshaw/orpo.git
|
| 3 |
+
cd orpo
|
| 4 |
+
sed -i 's/num_processes: 2/num_processes: 1/' ./src/accelerate/fsdp.yaml
|
| 5 |
+
sed -i 's/--num_proc", default=8/--num_proc", default=1/' ./src/args.py
|
| 6 |
+
wandb login $WANDB_TOKEN
|
| 7 |
+
wandb init -p $WANDB_PROJECT
|
| 8 |
+
accelerate launch --config_file ./src/accelerate/fsdp.yaml main.py \
|
| 9 |
+
--lr $LEARNING_RATE \
|
| 10 |
+
--warmup_steps 100 \
|
| 11 |
+
--model_name $MODEL_ID \
|
| 12 |
+
--data_name $DATASET \
|
| 13 |
+
--num_train_epochs $EPOCH \
|
| 14 |
+
--max_samples $MAX_SAMPLES \
|
| 15 |
+
--prompt_max_length 128 \
|
| 16 |
+
--response_max_length 2048 \
|
| 17 |
+
--per_device_train_batch_size 4 \
|
| 18 |
+
--per_device_eval_batch_size 4 \
|
| 19 |
+
--gradient_accumulation_steps 1 \
|
| 20 |
+
--num_proc 1
|
| 21 |
+
cd $OUTPUT
|
| 22 |
+
cd */
|
| 23 |
+
huggingface-cli login --token $TOKEN
|
| 24 |
+
huggingface-cli upload $NEW_MODEL . .
|
scripts/run_mistral_orpo_beta.sh
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
# Mistral-ORPO series are trained on 4 * A100s
|
| 4 |
+
|
| 5 |
+
accelerate launch --config_file ./src/accelerate/fsdp.yaml main.py \
|
| 6 |
+
--lr 5e-6 \
|
| 7 |
+
--lr_scheduler_type inverse_sqrt \
|
| 8 |
+
--alpha 0.1 \
|
| 9 |
+
--torch_compile False \
|
| 10 |
+
--warmup_steps 200 \
|
| 11 |
+
--model_name mistralai/Mistral-7B-v0.1 \
|
| 12 |
+
--data_name argilla/ultrafeedback-binarized-preferences-cleaned \
|
| 13 |
+
--num_train_epochs 5 \
|
| 14 |
+
--prompt_max_length 1792 \
|
| 15 |
+
--response_max_length 2048 \
|
| 16 |
+
--per_device_train_batch_size 8 \
|
| 17 |
+
--per_device_eval_batch_size 8 \
|
| 18 |
+
--gradient_accumulation_steps 1 \
|
| 19 |
+
--num_proc 8 \
|
| 20 |
+
--flash_attention_2
|
scripts/run_mistral_orpo_capybara.sh
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
# Mistral-ORPO series are trained on 4 * A100s
|
| 4 |
+
|
| 5 |
+
accelerate launch --config_file ./src/accelerate/fsdp.yaml main.py \
|
| 6 |
+
--lr 5e-6 \
|
| 7 |
+
--torch_compile False \
|
| 8 |
+
--alpha 0.05 \
|
| 9 |
+
--lr_scheduler_type inverse_sqrt \
|
| 10 |
+
--cache_dir /projects/hf_cache/ \
|
| 11 |
+
--warmup_steps 100 \
|
| 12 |
+
--model_name mistralai/Mistral-7B-v0.1 \
|
| 13 |
+
--data_name argilla/distilabel-capybara-dpo-7k-binarized \
|
| 14 |
+
--num_train_epochs 3 \
|
| 15 |
+
--optim adamw_bnb_8bit \
|
| 16 |
+
--gradient_accumulation_steps 1 \
|
| 17 |
+
--prompt_max_length 1792 \
|
| 18 |
+
--response_max_length 2048 \
|
| 19 |
+
--per_device_train_batch_size 8 \
|
| 20 |
+
--per_device_eval_batch_size 8 \
|
| 21 |
+
--num_proc 8 \
|
| 22 |
+
--flash_attention_2
|
src/accelerate/ds2.yaml
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
compute_environment: LOCAL_MACHINE
|
| 2 |
+
debug: false
|
| 3 |
+
deepspeed_config:
|
| 4 |
+
gradient_accumulation_steps: 1
|
| 5 |
+
offload_optimizer_device: none
|
| 6 |
+
offload_param_device: none
|
| 7 |
+
zero3_init_flag: false
|
| 8 |
+
zero_stage: 2
|
| 9 |
+
distributed_type: DEEPSPEED
|
| 10 |
+
downcast_bf16: 'no'
|
| 11 |
+
machine_rank: 0
|
| 12 |
+
main_training_function: main
|
| 13 |
+
mixed_precision: bf16
|
| 14 |
+
num_machines: 1
|
| 15 |
+
num_processes: 2
|
| 16 |
+
rdzv_backend: static
|
| 17 |
+
same_network: true
|
| 18 |
+
tpu_env: []
|
| 19 |
+
tpu_use_cluster: false
|
| 20 |
+
tpu_use_sudo: false
|
| 21 |
+
use_cpu: false
|
src/args.py
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
def default_args(parser):
|
| 2 |
+
parser.add_argument("--cache_dir", default=None, type=str)
|
| 3 |
+
parser.add_argument("--save_dir", default='./saved', type=str)
|
| 4 |
+
parser.add_argument("--data_name", default='HuggingfaceH4/UltraFeedback', type=str)
|
| 5 |
+
parser.add_argument("--model_name", default="gpt2", type=str)
|
| 6 |
+
|
| 7 |
+
# Training Arguments
|
| 8 |
+
parser.add_argument("--torch_compile", default=False, type=bool)
|
| 9 |
+
parser.add_argument("--flash_attention_2", action='store_true')
|
| 10 |
+
parser.add_argument("--lr_scheduler_type", default="cosine", type=str)
|
| 11 |
+
parser.add_argument("--optim", default="paged_adamw_32bit", type=str)
|
| 12 |
+
parser.add_argument("--overwrite_output_dir", default=True, type=bool)
|
| 13 |
+
parser.add_argument("--lr", default=2e-5, type=float)
|
| 14 |
+
parser.add_argument("--num_proc", default=1, type=int)
|
| 15 |
+
parser.add_argument("--num_train_epochs", default=10, type=int)
|
| 16 |
+
parser.add_argument("--per_device_train_batch_size", default=2, type=int)
|
| 17 |
+
parser.add_argument("--per_device_eval_batch_size", default=2, type=int)
|
| 18 |
+
parser.add_argument("--warmup_steps", default=5000, type=int)
|
| 19 |
+
parser.add_argument("--evaluation_strategy", default='epoch', type=str)
|
| 20 |
+
parser.add_argument("--do_eval", action='store_true')
|
| 21 |
+
parser.add_argument("--gradient_accumulation_steps", default=1, type=int)
|
| 22 |
+
parser.add_argument("--save_strategy", default='epoch', type=str)
|
| 23 |
+
parser.add_argument("--prompt_max_length", default=256, type=int)
|
| 24 |
+
parser.add_argument("--response_max_length", default=1024, type=int)
|
| 25 |
+
parser.add_argument("--alpha", default=1.0, type=float, help="Hyperparameter for weighting L_OR")
|
| 26 |
+
|
| 27 |
+
# Wandb Configurations
|
| 28 |
+
parser.add_argument("--wandb_entity", default=None, type=str)
|
| 29 |
+
parser.add_argument("--wandb_project_name", default=None, type=str)
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
args = parser.parse_args()
|
| 33 |
+
|
| 34 |
+
return args
|
src/orpo_trainer.py
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import torch
|
| 3 |
+
import wandb
|
| 4 |
+
from transformers import Trainer
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class ORPOTrainer(Trainer):
|
| 8 |
+
def __init__(self, alpha, pad, *args, **kwargs):
|
| 9 |
+
super().__init__(*args, **kwargs)
|
| 10 |
+
self.pad = pad
|
| 11 |
+
self.alpha = alpha
|
| 12 |
+
self.loss_fct = torch.nn.CrossEntropyLoss(reduction='none')
|
| 13 |
+
print("Pad Token ID: ", self.pad)
|
| 14 |
+
|
| 15 |
+
def compute_custom_loss(self, logits, labels):
|
| 16 |
+
|
| 17 |
+
logits = logits.contiguous()
|
| 18 |
+
|
| 19 |
+
if labels is not None:
|
| 20 |
+
# move labels to correct device to enable model parallelism
|
| 21 |
+
labels = labels.to(logits.device)
|
| 22 |
+
# Shift so that tokens < n predict n
|
| 23 |
+
shift_logits = logits[..., :-1, :].contiguous()
|
| 24 |
+
shift_labels = labels[..., 1:].contiguous()
|
| 25 |
+
|
| 26 |
+
# Flatten the tokens
|
| 27 |
+
loss = self.loss_fct(shift_logits.transpose(2, 1), shift_labels).mean(dim=-1)
|
| 28 |
+
|
| 29 |
+
return loss
|
| 30 |
+
|
| 31 |
+
def compute_logps(self, prompt_attention_mask, chosen_inputs, chosen_attention_mask, logits):
|
| 32 |
+
mask = chosen_attention_mask[:, :-1] - prompt_attention_mask[:, 1:]
|
| 33 |
+
per_token_logps = torch.gather(logits[:, :-1, :].log_softmax(-1), dim=2,
|
| 34 |
+
index=(mask * chosen_inputs[:, 1:]).unsqueeze(2)).squeeze(2)
|
| 35 |
+
return torch.mul(per_token_logps, mask.to(dtype=torch.bfloat16)).sum(dim=1).to(dtype=torch.float64) / mask.sum(dim=1).to(dtype=torch.float64)
|
| 36 |
+
|
| 37 |
+
def compute_loss(self, model, inputs, return_outputs=False):
|
| 38 |
+
if self.label_smoother is not None and "labels" in inputs:
|
| 39 |
+
labels = inputs.pop("labels")
|
| 40 |
+
else:
|
| 41 |
+
labels = None
|
| 42 |
+
|
| 43 |
+
# Generate the hidden states for 'chosen' and 'reject'
|
| 44 |
+
neg_labels = inputs['negative_input_ids'].clone()
|
| 45 |
+
pos_labels = inputs['positive_input_ids'].clone()
|
| 46 |
+
|
| 47 |
+
neg_labels[neg_labels == self.pad] = -100
|
| 48 |
+
pos_labels[pos_labels == self.pad] = -100
|
| 49 |
+
|
| 50 |
+
outputs_neg = model(**{'input_ids': inputs['negative_input_ids'],
|
| 51 |
+
'attention_mask': inputs['negative_attention_mask'],
|
| 52 |
+
'labels': neg_labels,}, output_hidden_states=True)
|
| 53 |
+
outputs_pos = model(**{'input_ids': inputs['positive_input_ids'],
|
| 54 |
+
'attention_mask': inputs['positive_attention_mask'],
|
| 55 |
+
'labels': pos_labels,}, output_hidden_states=True)
|
| 56 |
+
|
| 57 |
+
# Calculate NLL loss
|
| 58 |
+
pos_loss = self.compute_custom_loss(logits=outputs_pos.logits, labels=inputs['positive_input_ids'])
|
| 59 |
+
|
| 60 |
+
# Calculate Log Probability
|
| 61 |
+
pos_prob = self.compute_logps(prompt_attention_mask=inputs['attention_mask'],
|
| 62 |
+
chosen_inputs=inputs['positive_input_ids'],
|
| 63 |
+
chosen_attention_mask=inputs['positive_attention_mask'],
|
| 64 |
+
logits=outputs_pos.logits)
|
| 65 |
+
neg_prob = self.compute_logps(prompt_attention_mask=inputs['attention_mask'],
|
| 66 |
+
chosen_inputs=inputs['negative_input_ids'],
|
| 67 |
+
chosen_attention_mask=inputs['negative_attention_mask'],
|
| 68 |
+
logits=outputs_neg.logits)
|
| 69 |
+
|
| 70 |
+
# Calculate log odds
|
| 71 |
+
log_odds = (pos_prob - neg_prob) - (torch.log(1 - torch.exp(pos_prob)) - torch.log(1 - torch.exp(neg_prob)))
|
| 72 |
+
sig_ratio = torch.nn.functional.sigmoid(log_odds)
|
| 73 |
+
ratio = torch.log(sig_ratio)
|
| 74 |
+
|
| 75 |
+
# Calculate the Final Loss
|
| 76 |
+
loss = torch.mean(pos_loss - self.alpha * ratio).to(dtype=torch.bfloat16)
|
| 77 |
+
|
| 78 |
+
wandb.log({'Positive Geometric Mean': torch.mean(pos_prob).item(),
|
| 79 |
+
'Negative Geometric Mean': torch.mean(neg_prob).item(),
|
| 80 |
+
'Log Odds Ratio': torch.mean(ratio).item(),
|
| 81 |
+
'Log Odds': torch.mean(log_odds).item()})
|
| 82 |
+
|
| 83 |
+
return (loss, outputs_pos) if return_outputs else loss
|
src/utils.py
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
from typing import List
|
| 3 |
+
|
| 4 |
+
def preprocess_logits_for_metrics(logits, labels):
|
| 5 |
+
if isinstance(logits, tuple):
|
| 6 |
+
logits = logits[0]
|
| 7 |
+
return logits.argmax(dim=-1)
|
| 8 |
+
|
| 9 |
+
def dataset_split_selector(data) -> List:
|
| 10 |
+
"""
|
| 11 |
+
This is a function for automating the process of selecting data split.
|
| 12 |
+
Will be further updated.
|
| 13 |
+
"""
|
| 14 |
+
if len(data.keys()) == 1:
|
| 15 |
+
return ['train']
|
| 16 |
+
else:
|
| 17 |
+
if 'train_prefs' in data.keys():
|
| 18 |
+
return ['train_prefs', 'test_prefs']
|
| 19 |
+
else:
|
| 20 |
+
return ['train', 'test']
|
trl/test_orpo_trainer_demo.py
ADDED
|
@@ -0,0 +1,95 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
from dataclasses import dataclass, field
|
| 3 |
+
from typing import Optional
|
| 4 |
+
|
| 5 |
+
import os
|
| 6 |
+
import torch
|
| 7 |
+
from datasets import load_dataset
|
| 8 |
+
from tqdm import tqdm
|
| 9 |
+
from transformers import AutoTokenizer, HfArgumentParser, pipeline
|
| 10 |
+
|
| 11 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 12 |
+
from trl import ORPOConfig, ORPOTrainer, set_seed
|
| 13 |
+
from trl.core import LengthSampler
|
| 14 |
+
|
| 15 |
+
# This code is built on top of the example code from Huggingface TRL Team
|
| 16 |
+
|
| 17 |
+
tqdm.pandas()
|
| 18 |
+
|
| 19 |
+
@dataclass
|
| 20 |
+
class ScriptArguments:
|
| 21 |
+
model_name: Optional[str] = field(default="microsoft/phi-2", metadata={"help": "the model name"})
|
| 22 |
+
optim: Optional[str] = field(default="adamw_torch", metadata={"help": "the model name"})
|
| 23 |
+
data_name: Optional[str] = field(default="argilla/ultrafeedback-binarized-preferences-cleaned", metadata={"help": "the model name"})
|
| 24 |
+
cache_dir: Optional[str] = field(default="", metadata={"help": "the model name"})
|
| 25 |
+
log_with: Optional[str] = field(default='wandb', metadata={"help": "use 'wandb' to log with wandb"})
|
| 26 |
+
output_dir: Optional[str] = field(default='', metadata={"help": "use 'wandb' to log with wandb"})
|
| 27 |
+
learning_rate: Optional[float] = field(default=1.41e-5, metadata={"help": "the learning rate"})
|
| 28 |
+
lr_scheduler_type: Optional[str] = field(default='cosine', metadata={"help": "the learning rate scheduler"})
|
| 29 |
+
per_device_train_batch_size: Optional[int] = field(default=4, metadata={"help": "the batch size"})
|
| 30 |
+
num_train_epochs: Optional[int] = field(default=5, metadata={"help": "the batch size"})
|
| 31 |
+
beta: Optional[float] = field(default=0.25, metadata={"help": "weighting hyperparameter for L_OR"})
|
| 32 |
+
gradient_accumulation_steps: Optional[int] = field(
|
| 33 |
+
default=1, metadata={"help": "the number of gradient accumulation steps"}
|
| 34 |
+
)
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
parser = HfArgumentParser(ScriptArguments)
|
| 38 |
+
script_args = parser.parse_args_into_dataclasses()[0]
|
| 39 |
+
|
| 40 |
+
config = ORPOConfig(
|
| 41 |
+
output_dir=script_args.output_dir,
|
| 42 |
+
max_prompt_length=1024,
|
| 43 |
+
max_length=2048,
|
| 44 |
+
logging_steps=100,
|
| 45 |
+
save_strategy='no',
|
| 46 |
+
max_completion_length=2048,
|
| 47 |
+
per_device_train_batch_size=script_args.per_device_train_batch_size,
|
| 48 |
+
remove_unused_columns=False,
|
| 49 |
+
gradient_accumulation_steps=script_args.gradient_accumulation_steps,
|
| 50 |
+
learning_rate=script_args.learning_rate,
|
| 51 |
+
optim=script_args.optim,
|
| 52 |
+
lr_scheduler_type=script_args.lr_scheduler_type,
|
| 53 |
+
gradient_checkpointing=True,
|
| 54 |
+
gradient_checkpointing_kwargs={'use_reentrant':True},
|
| 55 |
+
beta=script_args.beta,
|
| 56 |
+
report_to='wandb',
|
| 57 |
+
num_train_epochs=script_args.num_train_epochs,
|
| 58 |
+
bf16=True,
|
| 59 |
+
do_eval=False
|
| 60 |
+
)
|
| 61 |
+
|
| 62 |
+
model = AutoModelForCausalLM.from_pretrained(script_args.model_name,
|
| 63 |
+
cache_dir=script_args.cache_dir,
|
| 64 |
+
attn_implementation='flash_attention_2',
|
| 65 |
+
torch_dtype=torch.bfloat16)
|
| 66 |
+
tokenizer = AutoTokenizer.from_pretrained(script_args.model_name,
|
| 67 |
+
cache_dir=script_args.cache_dir)
|
| 68 |
+
tokenizer.pad_token_id = tokenizer.eos_token_id
|
| 69 |
+
tokenizer.chat_template = "{% for message in messages %}\n{% if message['role'] == 'user' %}\n{{ '<|user|>\n' + message['content'] + eos_token }}\n{% elif message['role'] == 'system' %}\n{{ '<|system|>\n' + message['content'] + eos_token }}\n{% elif message['role'] == 'assistant' %}\n{{ '<|assistant|>\n' + message['content'] + eos_token }}\n{% endif %}\n{% if loop.last and add_generation_prompt %}\n{{ '<|assistant|>' }}\n{% endif %}\n{% endfor %}"
|
| 70 |
+
|
| 71 |
+
def build_dataset(tokenizer):
|
| 72 |
+
ds_train = load_dataset(script_args.data_name, split="train",
|
| 73 |
+
cache_dir=script_args.cache_dir)
|
| 74 |
+
|
| 75 |
+
def chat_template_to_text(sample):
|
| 76 |
+
sample["chosen"] = [item_chosen[1]['content'] for item_chosen in sample['chosen']]
|
| 77 |
+
sample["rejected"] = [item_rejected[1]['content'] for item_rejected in sample['rejected']]
|
| 78 |
+
sample['prompt'] = [tokenizer.apply_chat_template([{'role': 'user', 'content': item_prompt}], tokenize=False, add_generation_prompt=True) for item_prompt in sample['prompt']]
|
| 79 |
+
|
| 80 |
+
return sample
|
| 81 |
+
|
| 82 |
+
ds_train = ds_train.map(chat_template_to_text, batched=True, num_proc=8)
|
| 83 |
+
|
| 84 |
+
return ds_train
|
| 85 |
+
|
| 86 |
+
train = build_dataset(tokenizer=tokenizer)
|
| 87 |
+
|
| 88 |
+
trainer = ORPOTrainer(
|
| 89 |
+
model=model,
|
| 90 |
+
args=config,
|
| 91 |
+
tokenizer=tokenizer,
|
| 92 |
+
train_dataset=train
|
| 93 |
+
)
|
| 94 |
+
|
| 95 |
+
trainer.train()
|