---
license: apache-2.0
language:
- zh
---
# Hyacinth6B: A Trandidional Chinese Large Language Model
 Hyacinth6B is a Tranditional Chinese Large Language Model which fine-tune from [chatglm3-base](https://huggingface.co/THUDM/chatglm3-6b-base),our goal is to find a balance between model lightness and performance, striving to maximize performance while using a comparatively lightweight model. Hyacinth6B was developed with this objective in mind, aiming to fully leverage the core capabilities of LLMs without incurring substantial resource costs, effectively pushing the boundaries of smaller models' performance. The training approach involves parameter-efficient fine-tuning using the Low-Rank Adaptation (LoRA) method.
At last, we evaluated Hyacinth6B, examining its performance across various aspects. Hyacinth6B shows commendable performance in certain metrics, even surpassing ChatGPT in two categories. We look forward to providing more resources and possibilities for the field of Traditional Chinese language processing. This research aims to expand the research scope of Traditional Chinese language models and enhance their applicability in different scenarios.
# Training Config
Training required approximately 20.6GB of VRAM without any quantization (default fp16) and a total of 369 hours in duration.
| HyperParameter | Value |
| --------- | ----- |
| Batch Size| 8 |
|Learning Rate |5e-5 |
|Epochs |3 |
|LoRA r| 16 |
# Evaluate Results
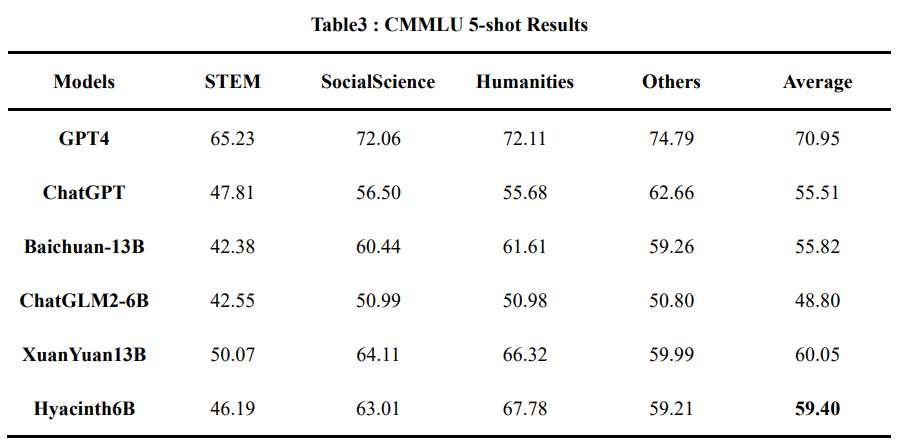
## CMMLU
Hyacinth6B is a Tranditional Chinese Large Language Model which fine-tune from [chatglm3-base](https://huggingface.co/THUDM/chatglm3-6b-base),our goal is to find a balance between model lightness and performance, striving to maximize performance while using a comparatively lightweight model. Hyacinth6B was developed with this objective in mind, aiming to fully leverage the core capabilities of LLMs without incurring substantial resource costs, effectively pushing the boundaries of smaller models' performance. The training approach involves parameter-efficient fine-tuning using the Low-Rank Adaptation (LoRA) method.
At last, we evaluated Hyacinth6B, examining its performance across various aspects. Hyacinth6B shows commendable performance in certain metrics, even surpassing ChatGPT in two categories. We look forward to providing more resources and possibilities for the field of Traditional Chinese language processing. This research aims to expand the research scope of Traditional Chinese language models and enhance their applicability in different scenarios.
# Training Config
Training required approximately 20.6GB of VRAM without any quantization (default fp16) and a total of 369 hours in duration.
| HyperParameter | Value |
| --------- | ----- |
| Batch Size| 8 |
|Learning Rate |5e-5 |
|Epochs |3 |
|LoRA r| 16 |
# Evaluate Results
## CMMLU
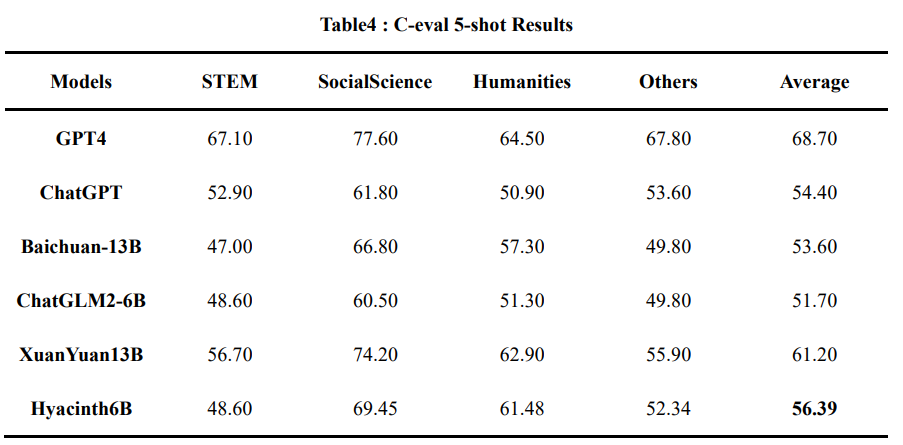
 ## C-eval
## C-eval
 ## TC-eval by MediaTek Research
## TC-eval by MediaTek Research
 ## MT-bench
## MT-bench
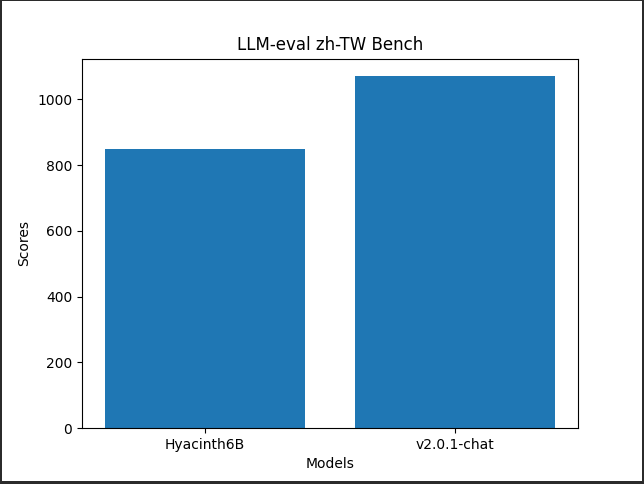
 ## LLM-eval by NTU Miu Lab
## LLM-eval by NTU Miu Lab
 ## Bailong Bench
| Bailong-bench| Taiwan-LLM-7B-v2.1-chat |Taiwan-LLM-13B-v2.0-chat |gpt-3.5-turbo-1103|Bailong-instruct 7B|Hyacinth6B(ours)|
| -------- | -------- | --- | --- | --- | -------- |
|Arithmetic|9.0|10.0|10.0|9.2|8.4|
|Copywriting generation|7.6|3.0|9.0|9.6|10.0 |
|Creative writing|6.1|7.5 |8.7 |9.4 |8.3 |
|English instruction| 6.0| 1.9 |10.0 |9.2 | 10.0 |
|General|7.7| 8.1 |9.9 |9.2 | 9.2 |
|Health consultation|7.7| 8.5 |9.9 |9.2 | 9.8 |
|Knowledge-based question|4.2| 8.4 | 9.9 | 9.8 |4.9 |
|Mail assistant|9.5| 9.9 |9.0 |9.9 | 9.5 |
|Morality and Ethics| 4.5 | 9.3 |9.8 |9.7 |7.4 |
|Multi-turn|7.9|8.7 |9.0 |7.8 |4.4 |
|Open question|7.0|9.2 |7.6 |9.6 | 8.2 |
|Proofreading|3.0|4.0 |10.0 |9.0 | 9.1 |
|Summarization|6.2| 7.4 |9.9 |9.8 | 8.4 |
|Translation|7.0|9.0 |8.1 |9.5 | 10.0 |
|**Average**|6.7| 7.9 |9.4 |9.4 | 8.4 |
## Acknowledgement
Thanks for Taiwan LLM's author, Yen-Ting Lin 's kindly advice to me.
Please review his marvellous works!
[Yen-Ting Lin's hugging face](https://huggingface.co/yentinglin)
### Model Usage
Download model
Here is the example for you to download Hyacinth6B with huggingface transformers:
```
from transformers import AutoTokenizer,AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("chillymiao/Hyacinth6B")
model = AutoModelForCausalLM.from_pretrained("chillymiao/Hyacinth6B")
```
### Citaion
```
@misc{song2024hyacinth6b,
title={Hyacinth6B: A large language model for Traditional Chinese},
author={Chih-Wei Song and Yin-Te Tsai},
year={2024},
eprint={2403.13334},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## Bailong Bench
| Bailong-bench| Taiwan-LLM-7B-v2.1-chat |Taiwan-LLM-13B-v2.0-chat |gpt-3.5-turbo-1103|Bailong-instruct 7B|Hyacinth6B(ours)|
| -------- | -------- | --- | --- | --- | -------- |
|Arithmetic|9.0|10.0|10.0|9.2|8.4|
|Copywriting generation|7.6|3.0|9.0|9.6|10.0 |
|Creative writing|6.1|7.5 |8.7 |9.4 |8.3 |
|English instruction| 6.0| 1.9 |10.0 |9.2 | 10.0 |
|General|7.7| 8.1 |9.9 |9.2 | 9.2 |
|Health consultation|7.7| 8.5 |9.9 |9.2 | 9.8 |
|Knowledge-based question|4.2| 8.4 | 9.9 | 9.8 |4.9 |
|Mail assistant|9.5| 9.9 |9.0 |9.9 | 9.5 |
|Morality and Ethics| 4.5 | 9.3 |9.8 |9.7 |7.4 |
|Multi-turn|7.9|8.7 |9.0 |7.8 |4.4 |
|Open question|7.0|9.2 |7.6 |9.6 | 8.2 |
|Proofreading|3.0|4.0 |10.0 |9.0 | 9.1 |
|Summarization|6.2| 7.4 |9.9 |9.8 | 8.4 |
|Translation|7.0|9.0 |8.1 |9.5 | 10.0 |
|**Average**|6.7| 7.9 |9.4 |9.4 | 8.4 |
## Acknowledgement
Thanks for Taiwan LLM's author, Yen-Ting Lin 's kindly advice to me.
Please review his marvellous works!
[Yen-Ting Lin's hugging face](https://huggingface.co/yentinglin)
### Model Usage
Download model
Here is the example for you to download Hyacinth6B with huggingface transformers:
```
from transformers import AutoTokenizer,AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("chillymiao/Hyacinth6B")
model = AutoModelForCausalLM.from_pretrained("chillymiao/Hyacinth6B")
```
### Citaion
```
@misc{song2024hyacinth6b,
title={Hyacinth6B: A large language model for Traditional Chinese},
author={Chih-Wei Song and Yin-Te Tsai},
year={2024},
eprint={2403.13334},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```