---
library_name: transformers
license: cc-by-nc-sa-4.0
language:
- ja
- en
base_model:
- llm-jp/llm-jp-3-13b
---
# Model Card for Model ID
llm-jp-3-13bモデルをichikaraデータセットでSFTしたモデルです。
アップロードされているファイルはLoraアダプタのみです。
HF_TOKEN, WB_TOKENはご自身のものに書き換えてください。
## How to Get Started with the Model
- Jupyter Notebook
[Training-Inference-code.ipynb](https://huggingface.co/chocopan/llm-jp-3-13b-finetune-4bit/blob/main/Training-Inference-code.ipynb)
- Training Dataset
ichikara-instruction-003-merge.json
- Test Dataset
ELYZA-tasks-100-TV (not included)
### File Tree
```
/workspace
|--Training-Inference-code.ipynb
|--models/models--llm-jp--llm-jp-3-13b/snapshots/cd3823f4c1fcbb0ad2e2af46036ab1b0ca13192a
|--ichikara-instruction-003-merge.json
`--elyza-tasks-100-TV_0.jsonl
```
### Usage
Execute following code in Google Colab
```python
!pip install -U pip
!pip install -U transformers
!pip install -U bitsandbytes
!pip install -U accelerate
!pip install -U datasets
!pip install -U peft
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import PeftModel
import torch
import bitsandbytes as bnb # bitsandbytesをインポート
import json
import re
from tqdm import tqdm
from sklearn.metrics import f1_score
# ベースモデルとLoRAアダプタのID
model_id = "llm-jp/llm-jp-3-13b"
adapter_id = "chocopan/llm-jp-3-13b-finetune-4bit"
# トークナイザーのロード
tokenizer = AutoTokenizer.from_pretrained(model_id)
# モデルのロード (4bit量子化)
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True, # 4bit量子化を有効にする
bnb_4bit_use_double_quant=True, # double quantizationを使用 (さらにメモリ効率を高める)
bnb_4bit_quant_type="nf4", # 量子化のタイプ (NF4が推奨)
torch_dtype=torch.bfloat16, # bfloat16を使用
device_map="auto" # デバイスマップ
)
# LoRAアダプタのロード
model = PeftModel.from_pretrained(model, adapter_id)
model.eval()
# タスクとなるデータの読み込み。
# 事前にデータをアップロードしてください。
datasets = []
with open("./elyza-tasks-100-TV_0.jsonl", "r") as f:
item = ""
for line in f:
line = line.strip()
item += line
if item.endswith("}"):
datasets.append(json.loads(item))
item = ""
# 推論の実行
results = []
for dt in tqdm(datasets):
input_text = dt["input"]
prompt = f"""### 指示
{input}
### 回答
"""
inputs = tokenizer([prompt], return_tensors="pt").to(model.device)
# Remove token_type_ids from inputs if present
if "token_type_ids" in inputs:
del inputs["token_type_ids"]
outputs = model.generate(**inputs, max_new_tokens=512, use_cache=True, do_sample=False, repetition_penalty=1.2)
prediction = tokenizer.decode(outputs[0], skip_special_tokens=True).split('\n### 回答')[-1]
prediction = re.sub(r"[*#]", "", prediction).strip() # 前後の空白を削除
results.append({
"task_id": dt.get("task_id", None), # task_idがない場合への対応
"input": input_text,
"prediction": prediction,
"expected": dt.get("output", None) # 期待データ
})
# 評価
exact_match_count = 0
total_count = 0
f1_scores = []
for result in results:
if result["expected"] is None: # 期待データがない場合はスキップ
continue
total_count += 1
expected = result["expected"].strip() # 前後の空白を削除
prediction = result["prediction"].strip() # 前後の空白を削除
if prediction == expected:
exact_match_count += 1
# F1スコアの計算 (単語単位)
expected_words = expected.split()
prediction_words = prediction.split()
if len(expected_words) == 0 and len(prediction_words) == 0:
f1 = 1.0 # 両方空の場合は1.0
elif len(expected_words) == 0 or len(prediction_words) == 0:
f1 = 0.0 # 片方が空の場合は0.0
else:
f1 = f1_score(expected_words, prediction_words, average='micro') # 単語単位のF1スコア
f1_scores.append(f1)
# 評価結果の出力
exact_match_rate = exact_match_count / total_count if total_count > 0 else 0
average_f1 = sum(f1_scores) / len(f1_scores) if len(f1_scores) > 0 else 0
print(f"Exact Match Rate: {exact_match_rate:.4f}")
print(f"Average F1 Score: {average_f1:.4f}")
# 結果をjsonlで保存 (評価結果も追加)
json_file_id = re.sub(".*/", "", adapter_id)
with open(f"/content/{json_file_id}_output.jsonl", 'w', encoding='utf-8') as f:
for result in results:
result["exact_match"] = 1 if result["prediction"].strip() == result["expected"].strip() else 0 if result["expected"] is not None else None
f.write(json.dumps(result, ensure_ascii=False) + '\n')
```
## Training Details
```
training_arguments = TrainingArguments(
output_dir=new_model_id,
per_device_train_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=2,
logging_strategy="steps",
logging_steps=10,
warmup_steps=10,
save_steps=100,
save_total_limit = 2,
max_steps = -1,
learning_rate=5e-5,
fp16=False,
bf16=True,
seed = 1001,
group_by_length=True,
report_to="wandb"
)
```
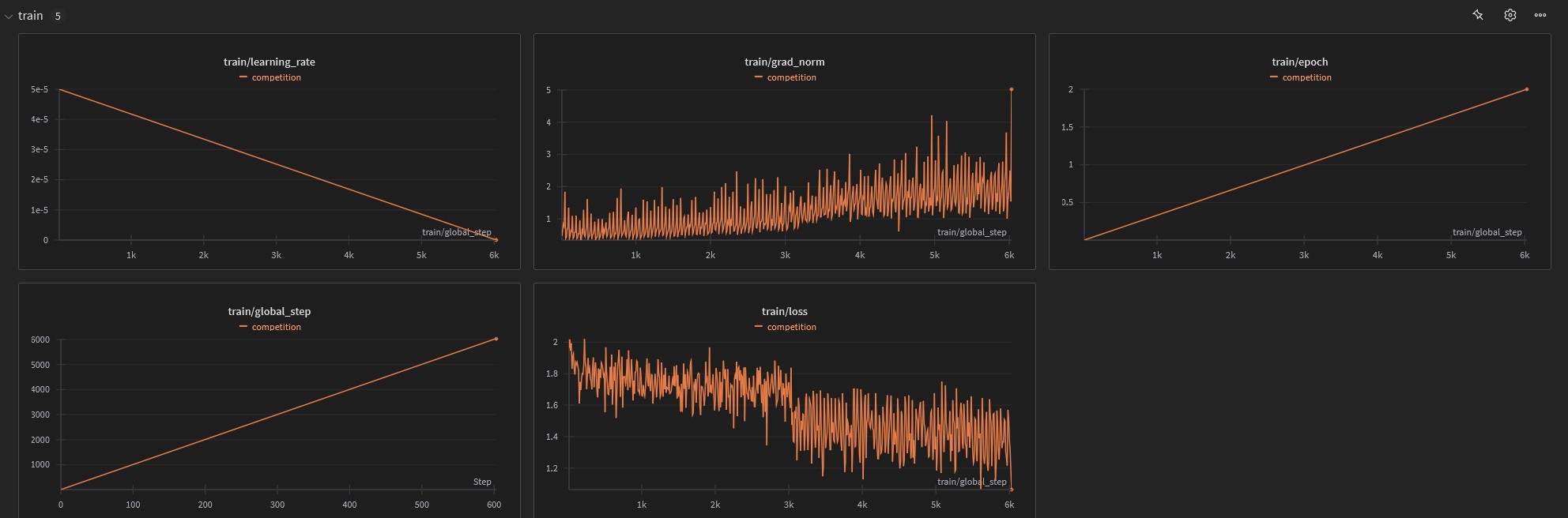
### Training Results
Training Time: 5:52:48
Total steps: 6030 steps
Epoch: 2
### Training Dataset
- LMのための日本語インストラクションデータ(ichikara-instruction)
[https://liat-aip.sakura.ne.jp/wp/llm](https://liat-aip.sakura.ne.jp/wp/llm)
のための日本語インストラクションデータ作成/llmのための日本語インストラクションデータ-公開/
関根聡, 安藤まや, 後藤美知子, 鈴木久美, 河原大輔, 井之上直也, 乾健太郎. ichikara-instruction: LLMのための日本語インストラクションデータの構築. 言語処理学会第30回年次大会(2024)
上記datasetをすべてマージし、IDを連番になるよう振りなおしています。
LICENCE: CC-BY-NC-SA
#### Hardware
Google Cloud Platform
L4 GPU 24GB
RAM 48GB
#### Software
transformers==4.46.3
trl==0.12.2
Others: latast