
initial commit
Browse files- .gitattributes +1 -0
- README.md +370 -0
- config.json +154 -0
- model.safetensors +3 -0
- pytorch_model.bin +3 -0
- tokenizer_config.json +1 -0
- vocab.txt +0 -0
.gitattributes
CHANGED
|
@@ -32,3 +32,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
pytorch_model.bin filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,370 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
language: ko
|
| 3 |
+
license: apache-2.0
|
| 4 |
+
tags:
|
| 5 |
+
- korean
|
| 6 |
+
---
|
| 7 |
+
|
| 8 |
+
# KcBERT: Korean comments BERT
|
| 9 |
+
|
| 10 |
+
** Updates on 2021.04.07 **
|
| 11 |
+
|
| 12 |
+
- KcELECTRA가 릴리즈 되었습니다!🤗
|
| 13 |
+
- KcELECTRA는 보다 더 많은 데이터셋, 그리고 더 큰 General vocab을 통해 KcBERT 대비 **모든 태스크에서 더 높은 성능**을 보입니다.
|
| 14 |
+
- 아래 깃헙 링크에서 직접 사용해보세요!
|
| 15 |
+
- https://github.com/Beomi/KcELECTRA
|
| 16 |
+
|
| 17 |
+
** Updates on 2021.03.14 **
|
| 18 |
+
|
| 19 |
+
- KcBERT Paper 인용 표기를 추가하였습니다.(bibtex)
|
| 20 |
+
- KcBERT-finetune Performance score를 본문에 추가하였습니다.
|
| 21 |
+
|
| 22 |
+
** Updates on 2020.12.04 **
|
| 23 |
+
|
| 24 |
+
Huggingface Transformers가 v4.0.0으로 업데이트됨에 따라 Tutorial의 코드가 일부 변경되었습니다.
|
| 25 |
+
|
| 26 |
+
업데이트된 KcBERT-Large NSMC Finetuning Colab: <a href="https://colab.research.google.com/drive/1dFC0FL-521m7CL_PSd8RLKq67jgTJVhL?usp=sharing">
|
| 27 |
+
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
|
| 28 |
+
</a>
|
| 29 |
+
|
| 30 |
+
** Updates on 2020.09.11 **
|
| 31 |
+
|
| 32 |
+
KcBERT를 Google Colab에서 TPU를 통해 학습할 수 있는 튜토리얼을 제공합니다! 아래 버튼을 눌러보세요.
|
| 33 |
+
|
| 34 |
+
Colab에서 TPU로 KcBERT Pretrain 해보기: <a href="https://colab.research.google.com/drive/1lYBYtaXqt9S733OXdXvrvC09ysKFN30W">
|
| 35 |
+
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
|
| 36 |
+
</a>
|
| 37 |
+
|
| 38 |
+
텍스트 분량만 전체 12G 텍스트 중 일부(144MB)로 줄여 학습을 진행합니다.
|
| 39 |
+
|
| 40 |
+
한국어 데이터셋/코퍼스를 좀더 쉽게 사용할 수 있는 [Korpora](https://github.com/ko-nlp/Korpora) 패키지를 사용합니다.
|
| 41 |
+
|
| 42 |
+
** Updates on 2020.09.08 **
|
| 43 |
+
|
| 44 |
+
Github Release를 통해 학습 데이터를 업로드하였습니다.
|
| 45 |
+
|
| 46 |
+
다만 한 파일당 2GB 이내의 제약으로 인해 분할압축되어있습니다.
|
| 47 |
+
|
| 48 |
+
아래 링크를 통해 받아주세요. (가입 없이 받을 수 있어요. 분할압축)
|
| 49 |
+
|
| 50 |
+
만약 한 파일로 받고싶으시거나/Kaggle에서 데이터를 살펴보고 싶으시다면 아래의 캐글 데이터셋을 이용해주세요.
|
| 51 |
+
|
| 52 |
+
- Github릴리즈: https://github.com/Beomi/KcBERT/releases/tag/TrainData_v1
|
| 53 |
+
|
| 54 |
+
** Updates on 2020.08.22 **
|
| 55 |
+
|
| 56 |
+
Pretrain Dataset 공개
|
| 57 |
+
|
| 58 |
+
- 캐글: https://www.kaggle.com/junbumlee/kcbert-pretraining-corpus-korean-news-comments (한 파일로 받을 수 있어요. 단일파일)
|
| 59 |
+
|
| 60 |
+
Kaggle에 학습을 위해 정제한(아래 `clean`처리를 거친) Dataset을 공개하였습니다!
|
| 61 |
+
|
| 62 |
+
직접 다운받으셔서 다양한 Task에 학습을 진행해보세요 :)
|
| 63 |
+
|
| 64 |
+
---
|
| 65 |
+
|
| 66 |
+
공개된 한국어 BERT는 대부분 한국어 위키, 뉴스 기사, 책 등 잘 정제된 데이터를 기반으로 학습한 모델입니다. 한편, 실제로 NSMC와 같은 댓글형 데이터셋은 정제되지 않았고 구어체 특징에 신조어가 많으며, 오탈자 등 공식적인 글쓰기에서 나타나지 않는 표현들이 빈번하게 등장합니다.
|
| 67 |
+
|
| 68 |
+
KcBERT는 위와 같은 특성의 데이터셋에 적용하기 위해, 네이버 뉴스에서 댓글과 대댓글을 수집해, 토크나이저와 BERT모델을 처음부터 학습한 Pretrained BERT 모델입니다.
|
| 69 |
+
|
| 70 |
+
KcBERT는 Huggingface의 Transformers 라이브러리를 통해 간편히 불러와 사용할 수 있습니다. (별도의 파일 다운로드가 필요하지 않습니다.)
|
| 71 |
+
|
| 72 |
+
## KcBERT Performance
|
| 73 |
+
|
| 74 |
+
- Finetune 코드는 https://github.com/Beomi/KcBERT-finetune 에서 찾아보실 수 있습니다.
|
| 75 |
+
|
| 76 |
+
| | Size<br/>(용량) | **NSMC**<br/>(acc) | **Naver NER**<br/>(F1) | **PAWS**<br/>(acc) | **KorNLI**<br/>(acc) | **KorSTS**<br/>(spearman) | **Question Pair**<br/>(acc) | **KorQuaD (Dev)**<br/>(EM/F1) |
|
| 77 |
+
| :-------------------- | :---: | :----------------: | :--------------------: | :----------------: | :------------------: | :-----------------------: | :-------------------------: | :---------------------------: |
|
| 78 |
+
| KcBERT-Base | 417M | 89.62 | 84.34 | 66.95 | 74.85 | 75.57 | 93.93 | 60.25 / 84.39 |
|
| 79 |
+
| KcBERT-Large | 1.2G | **90.68** | 85.53 | 70.15 | 76.99 | 77.49 | 94.06 | 62.16 / 86.64 |
|
| 80 |
+
| KoBERT | 351M | 89.63 | 86.11 | 80.65 | 79.00 | 79.64 | 93.93 | 52.81 / 80.27 |
|
| 81 |
+
| XLM-Roberta-Base | 1.03G | 89.49 | 86.26 | 82.95 | 79.92 | 79.09 | 93.53 | 64.70 / 88.94 |
|
| 82 |
+
| HanBERT | 614M | 90.16 | **87.31** | 82.40 | **80.89** | 83.33 | 94.19 | 78.74 / 92.02 |
|
| 83 |
+
| KoELECTRA-Base | 423M | **90.21** | 86.87 | 81.90 | 80.85 | 83.21 | 94.20 | 61.10 / 89.59 |
|
| 84 |
+
| KoELECTRA-Base-v2 | 423M | 89.70 | 87.02 | **83.90** | 80.61 | **84.30** | **94.72** | **84.34 / 92.58** |
|
| 85 |
+
| DistilKoBERT | 108M | 88.41 | 84.13 | 62.55 | 70.55 | 73.21 | 92.48 | 54.12 / 77.80 |
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
\*HanBERT의 Size는 Bert Model과 Tokenizer DB를 합친 것입니다.
|
| 89 |
+
|
| 90 |
+
\***config의 세팅을 그대로 하여 돌린 결과이며, hyperparameter tuning을 추가적으로 할 시 더 좋은 성능이 나올 수 있습니다.**
|
| 91 |
+
|
| 92 |
+
## How to use
|
| 93 |
+
|
| 94 |
+
### Requirements
|
| 95 |
+
|
| 96 |
+
- `pytorch <= 1.8.0`
|
| 97 |
+
- `transformers ~= 3.0.1`
|
| 98 |
+
- `transformers ~= 4.0.0` 도 호환됩니다.
|
| 99 |
+
- `emoji ~= 0.6.0`
|
| 100 |
+
- `soynlp ~= 0.0.493`
|
| 101 |
+
|
| 102 |
+
```python
|
| 103 |
+
from transformers import AutoTokenizer, AutoModelWithLMHead
|
| 104 |
+
|
| 105 |
+
# Base Model (108M)
|
| 106 |
+
|
| 107 |
+
tokenizer = AutoTokenizer.from_pretrained("beomi/kcbert-base")
|
| 108 |
+
|
| 109 |
+
model = AutoModelWithLMHead.from_pretrained("beomi/kcbert-base")
|
| 110 |
+
|
| 111 |
+
# Large Model (334M)
|
| 112 |
+
|
| 113 |
+
tokenizer = AutoTokenizer.from_pretrained("beomi/kcbert-large")
|
| 114 |
+
|
| 115 |
+
model = AutoModelWithLMHead.from_pretrained("beomi/kcbert-large")
|
| 116 |
+
```
|
| 117 |
+
|
| 118 |
+
### Pretrain & Finetune Colab 링크 모음
|
| 119 |
+
|
| 120 |
+
#### Pretrain Data
|
| 121 |
+
|
| 122 |
+
- [데이터셋 다운로드(Kaggle, 단일파일, 로그인 필요)](https://www.kaggle.com/junbumlee/kcbert-pretraining-corpus-korean-news-comments)
|
| 123 |
+
- [데이터셋 다운로드(Github, 압축 여러파일, 로그인 불필요)](https://github.com/Beomi/KcBERT/releases/tag/TrainData_v1)
|
| 124 |
+
|
| 125 |
+
#### Pretrain Code
|
| 126 |
+
|
| 127 |
+
Colab에서 TPU로 KcBERT Pretrain 해보기: <a href="https://colab.research.google.com/drive/1lYBYtaXqt9S733OXdXvrvC09ysKFN30W">
|
| 128 |
+
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
|
| 129 |
+
</a>
|
| 130 |
+
|
| 131 |
+
#### Finetune Samples
|
| 132 |
+
|
| 133 |
+
**KcBERT-Base** NSMC Finetuning with PyTorch-Lightning (Colab) <a href="https://colab.research.google.com/drive/1fn4sVJ82BrrInjq6y5655CYPP-1UKCLb?usp=sharing">
|
| 134 |
+
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
|
| 135 |
+
</a>
|
| 136 |
+
|
| 137 |
+
**KcBERT-Large** NSMC Finetuning with PyTorch-Lightning (Colab) <a href="https://colab.research.google.com/drive/1dFC0FL-521m7CL_PSd8RLKq67jgTJVhL?usp=sharing">
|
| 138 |
+
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
|
| 139 |
+
</a>
|
| 140 |
+
|
| 141 |
+
> 위 두 코드는 Pretrain 모델(base, large)와 batch size만 다를 뿐, 나머지 코드는 완전히 동일합니다.
|
| 142 |
+
|
| 143 |
+
## Train Data & Preprocessing
|
| 144 |
+
|
| 145 |
+
### Raw Data
|
| 146 |
+
|
| 147 |
+
학습 데이터는 2019.01.01 ~ 2020.06.15 사이에 작성된 **댓글 많은 뉴스** 기사들의 **댓글과 대댓글**을 모두 수집한 데이터입니다.
|
| 148 |
+
|
| 149 |
+
데이터 사이즈는 텍스트만 추출시 **약 15.4GB이며, 1억1천만개 이상의 문장**으로 이뤄져 있습니다.
|
| 150 |
+
|
| 151 |
+
### Preprocessing
|
| 152 |
+
|
| 153 |
+
PLM 학습을 위해서 전처리를 진행한 과정은 다음과 같습니다.
|
| 154 |
+
|
| 155 |
+
1. 한글 및 영어, 특수문자, 그리고 이모지(🥳)까지!
|
| 156 |
+
|
| 157 |
+
정규표현식을 통해 한글, 영어, 특수문자를 포함해 Emoji까지 학습 대상에 포함했습니다.
|
| 158 |
+
|
| 159 |
+
한편, 한글 범위를 `ㄱ-ㅎ가-힣` 으로 지정해 `ㄱ-힣` 내의 한자를 제외했습니다.
|
| 160 |
+
|
| 161 |
+
2. 댓글 내 중복 문자열 축약
|
| 162 |
+
|
| 163 |
+
`ㅋㅋㅋㅋㅋ`와 같이 중복된 글자를 `ㅋㅋ`와 같은 것으로 합쳤습니다.
|
| 164 |
+
|
| 165 |
+
3. Cased Model
|
| 166 |
+
|
| 167 |
+
KcBERT는 영문에 대해서는 대소문자를 유지하는 Cased model입니다.
|
| 168 |
+
|
| 169 |
+
4. 글자 단위 10글자 이하 제거
|
| 170 |
+
|
| 171 |
+
10글자 미만의 텍스트는 단일 단어로 이뤄진 경우가 많아 해당 부분을 제외했습니다.
|
| 172 |
+
|
| 173 |
+
5. 중복 제거
|
| 174 |
+
|
| 175 |
+
중복적으로 쓰인 댓글을 제거하기 위해 중복 댓글을 하나로 합쳤습니다.
|
| 176 |
+
|
| 177 |
+
이를 통해 만든 최종 학습 데이터는 **12.5GB, 8.9천만개 문장**입니다.
|
| 178 |
+
|
| 179 |
+
아래 명령어로 pip로 설치한 뒤, 아래 clean함수로 클리닝을 하면 Downstream task에서 보다 성능이 좋아집니다. (`[UNK]` 감소)
|
| 180 |
+
|
| 181 |
+
```bash
|
| 182 |
+
pip install soynlp emoji
|
| 183 |
+
```
|
| 184 |
+
|
| 185 |
+
아래 `clean` 함수를 Text data에 사용해주세요.
|
| 186 |
+
|
| 187 |
+
```python
|
| 188 |
+
import re
|
| 189 |
+
import emoji
|
| 190 |
+
from soynlp.normalizer import repeat_normalize
|
| 191 |
+
|
| 192 |
+
emojis = list({y for x in emoji.UNICODE_EMOJI.values() for y in x.keys()})
|
| 193 |
+
emojis = ''.join(emojis)
|
| 194 |
+
pattern = re.compile(f'[^ .,?!/@$%~%·∼()\x00-\x7Fㄱ-ㅣ가-힣{emojis}]+')
|
| 195 |
+
url_pattern = re.compile(
|
| 196 |
+
r'https?:\/\/(www\.)?[-a-zA-Z0-9@:%._\+~#=]{1,256}\.[a-zA-Z0-9()]{1,6}\b([-a-zA-Z0-9()@:%_\+.~#?&//=]*)')
|
| 197 |
+
|
| 198 |
+
def clean(x):
|
| 199 |
+
x = pattern.sub(' ', x)
|
| 200 |
+
x = url_pattern.sub('', x)
|
| 201 |
+
x = x.strip()
|
| 202 |
+
x = repeat_normalize(x, num_repeats=2)
|
| 203 |
+
return x
|
| 204 |
+
```
|
| 205 |
+
|
| 206 |
+
### Cleaned Data (Released on Kaggle)
|
| 207 |
+
|
| 208 |
+
원본 데이터를 위 `clean`함수로 정제한 12GB분량의 txt 파일을 아래 Kaggle Dataset에서 다운받으실 수 있습니다 :)
|
| 209 |
+
|
| 210 |
+
https://www.kaggle.com/junbumlee/kcbert-pretraining-corpus-korean-news-comments
|
| 211 |
+
|
| 212 |
+
|
| 213 |
+
## Tokenizer Train
|
| 214 |
+
|
| 215 |
+
Tokenizer는 Huggingface의 [Tokenizers](https://github.com/huggingface/tokenizers) 라이브러리를 통해 학습을 진행했습니다.
|
| 216 |
+
|
| 217 |
+
그 중 `BertWordPieceTokenizer` 를 이용해 학습을 진행했고, Vocab Size는 `30000`으로 진행했습니다.
|
| 218 |
+
|
| 219 |
+
Tokenizer를 학습하는 것에는 `1/10`로 샘플링한 데이터로 학습을 진행했고, 보다 골고루 샘플링하기 위해 일자별로 stratify를 지정한 뒤 햑습을 진행했습니다.
|
| 220 |
+
|
| 221 |
+
## BERT Model Pretrain
|
| 222 |
+
|
| 223 |
+
- KcBERT Base config
|
| 224 |
+
|
| 225 |
+
```json
|
| 226 |
+
{
|
| 227 |
+
"max_position_embeddings": 300,
|
| 228 |
+
"hidden_dropout_prob": 0.1,
|
| 229 |
+
"hidden_act": "gelu",
|
| 230 |
+
"initializer_range": 0.02,
|
| 231 |
+
"num_hidden_layers": 12,
|
| 232 |
+
"type_vocab_size": 2,
|
| 233 |
+
"vocab_size": 30000,
|
| 234 |
+
"hidden_size": 768,
|
| 235 |
+
"attention_probs_dropout_prob": 0.1,
|
| 236 |
+
"directionality": "bidi",
|
| 237 |
+
"num_attention_heads": 12,
|
| 238 |
+
"intermediate_size": 3072,
|
| 239 |
+
"architectures": [
|
| 240 |
+
"BertForMaskedLM"
|
| 241 |
+
],
|
| 242 |
+
"model_type": "bert"
|
| 243 |
+
}
|
| 244 |
+
```
|
| 245 |
+
|
| 246 |
+
- KcBERT Large config
|
| 247 |
+
|
| 248 |
+
```json
|
| 249 |
+
{
|
| 250 |
+
"type_vocab_size": 2,
|
| 251 |
+
"initializer_range": 0.02,
|
| 252 |
+
"max_position_embeddings": 300,
|
| 253 |
+
"vocab_size": 30000,
|
| 254 |
+
"hidden_size": 1024,
|
| 255 |
+
"hidden_dropout_prob": 0.1,
|
| 256 |
+
"model_type": "bert",
|
| 257 |
+
"directionality": "bidi",
|
| 258 |
+
"pad_token_id": 0,
|
| 259 |
+
"layer_norm_eps": 1e-12,
|
| 260 |
+
"hidden_act": "gelu",
|
| 261 |
+
"num_hidden_layers": 24,
|
| 262 |
+
"num_attention_heads": 16,
|
| 263 |
+
"attention_probs_dropout_prob": 0.1,
|
| 264 |
+
"intermediate_size": 4096,
|
| 265 |
+
"architectures": [
|
| 266 |
+
"BertForMaskedLM"
|
| 267 |
+
]
|
| 268 |
+
}
|
| 269 |
+
```
|
| 270 |
+
|
| 271 |
+
BERT Model Config는 Base, Large 기본 세팅값을 그대로 사용했습니다. (MLM 15% 등)
|
| 272 |
+
|
| 273 |
+
TPU `v3-8` 을 이용해 각각 3일, N일(Large는 학습 진행 중)을 진행했고, 현재 Huggingface에 공개된 모델은 1m(100만) step을 학습한 ckpt가 업로드 되어있습니다.
|
| 274 |
+
|
| 275 |
+
모델 학습 Loss는 Step에 따라 초기 200k에 가장 빠르게 Loss가 줄어들다 400k이후로는 조금씩 감소하는 것을 볼 수 있습니다.
|
| 276 |
+
|
| 277 |
+
- Base Model Loss
|
| 278 |
+
|
| 279 |
+
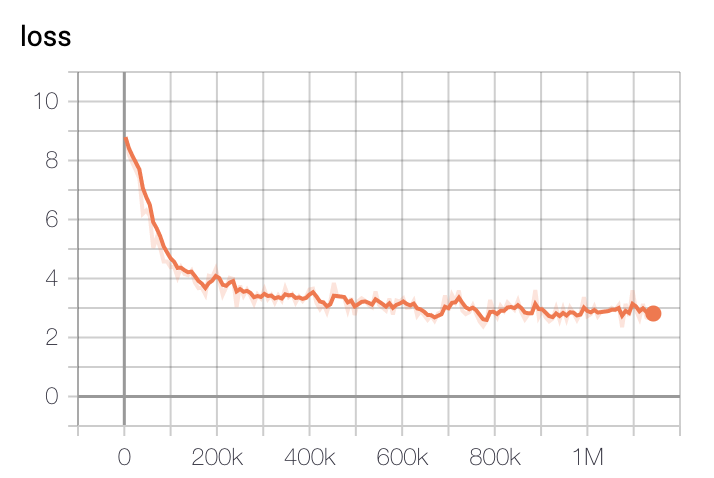
|
| 280 |
+
|
| 281 |
+
- Large Model Loss
|
| 282 |
+
|
| 283 |
+
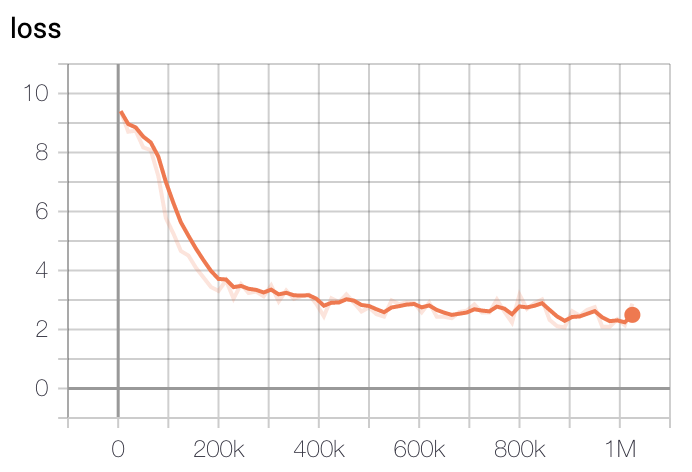
|
| 284 |
+
|
| 285 |
+
학습은 GCP의 TPU v3-8을 이용해 학습을 진행했고, 학습 시간은 Base Model 기준 2.5일정도 진행했습니다. Large Model은 약 5일정도 진행한 뒤 가장 낮은 loss를 가진 체크포인트로 정했습니다.
|
| 286 |
+
|
| 287 |
+
## Example
|
| 288 |
+
|
| 289 |
+
### HuggingFace MASK LM
|
| 290 |
+
|
| 291 |
+
[HuggingFace kcbert-base 모델](https://huggingface.co/beomi/kcbert-base?text=오늘은+날씨가+[MASK]) 에서 아래와 같이 테스트 해 볼 수 있습니다.
|
| 292 |
+
|
| 293 |
+
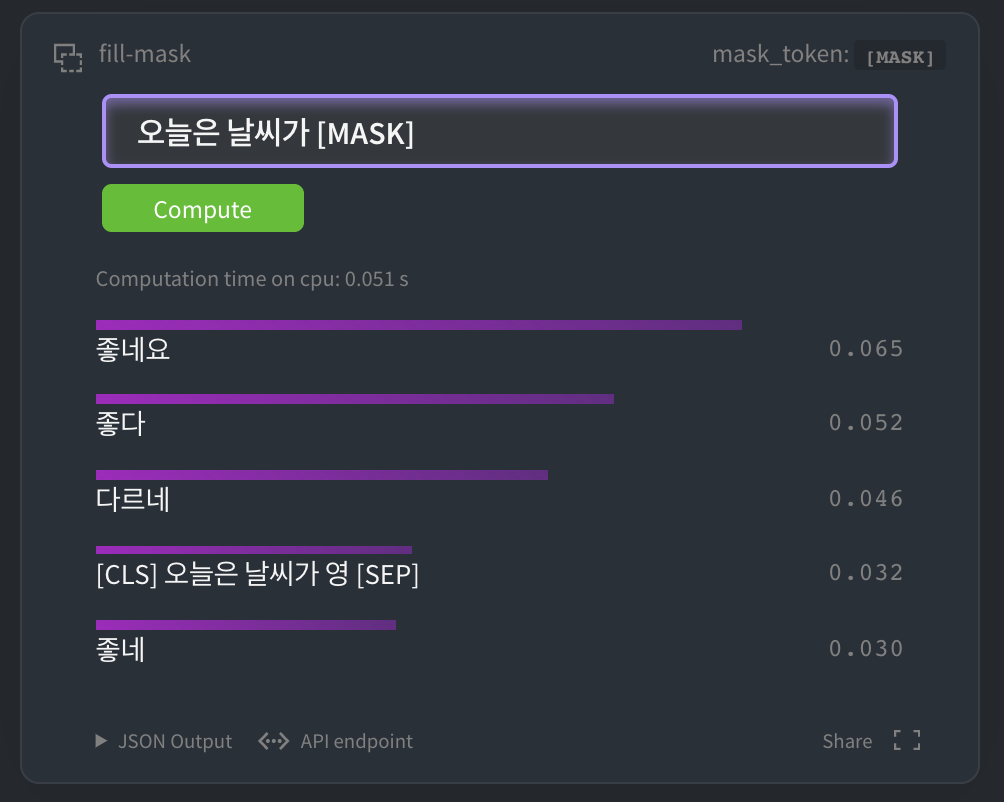
|
| 294 |
+
|
| 295 |
+
물론 [kcbert-large 모델](https://huggingface.co/beomi/kcbert-large?text=오늘은+날씨가+[MASK]) 에서도 테스트 할 수 있습니다.
|
| 296 |
+
|
| 297 |
+
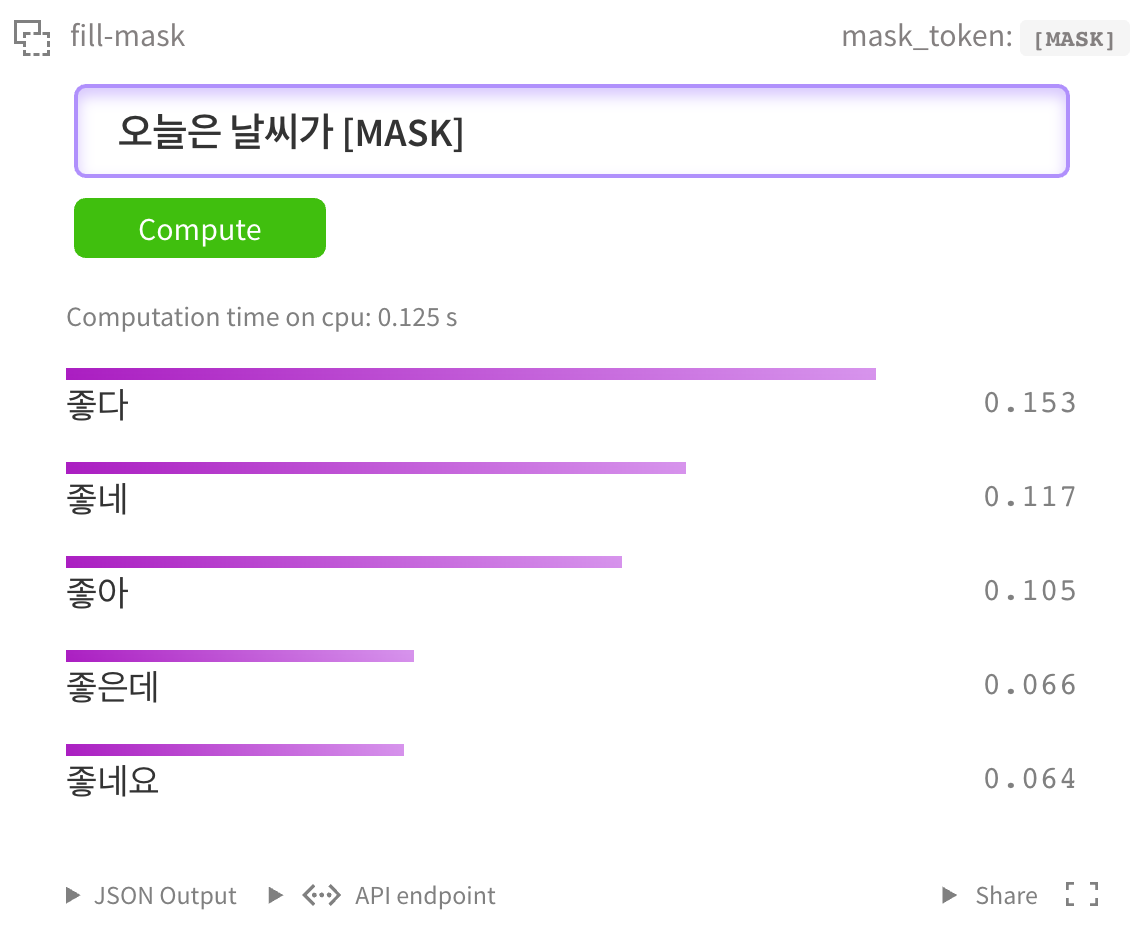
|
| 298 |
+
|
| 299 |
+
|
| 300 |
+
|
| 301 |
+
### NSMC Binary Classification
|
| 302 |
+
|
| 303 |
+
[네이버 영화평 코퍼스](https://github.com/e9t/nsmc) 데이터셋을 대상으로 Fine Tuning을 진행해 성능을 간단히 테스트해보았습니다.
|
| 304 |
+
|
| 305 |
+
Base Model을 Fine Tune하는 코드는 <a href="https://colab.research.google.com/drive/1fn4sVJ82BrrInjq6y5655CYPP-1UKCLb?usp=sharing">
|
| 306 |
+
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
|
| 307 |
+
</a> 에서 직접 실행해보실 수 있습니다.
|
| 308 |
+
|
| 309 |
+
Large Model을 Fine Tune하는 코드는 <a href="https://colab.research.google.com/drive/1dFC0FL-521m7CL_PSd8RLKq67jgTJVhL?usp=sharing">
|
| 310 |
+
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
|
| 311 |
+
</a> 에서 직접 실행해볼 수 있습니다.
|
| 312 |
+
|
| 313 |
+
- GPU는 P100 x1대 기준 1epoch에 2-3시간, TPU는 1epoch에 1시간 내로 소요됩니다.
|
| 314 |
+
- GPU RTX Titan x4대 기준 30분/epoch 소요됩니다.
|
| 315 |
+
- 예시 코드는 [pytorch-lightning](https://github.com/PyTorchLightning/pytorch-lightning)으로 개발했습니다.
|
| 316 |
+
|
| 317 |
+
#### 실험결과
|
| 318 |
+
|
| 319 |
+
- KcBERT-Base Model 실험결과: Val acc `.8905`
|
| 320 |
+
|
| 321 |
+

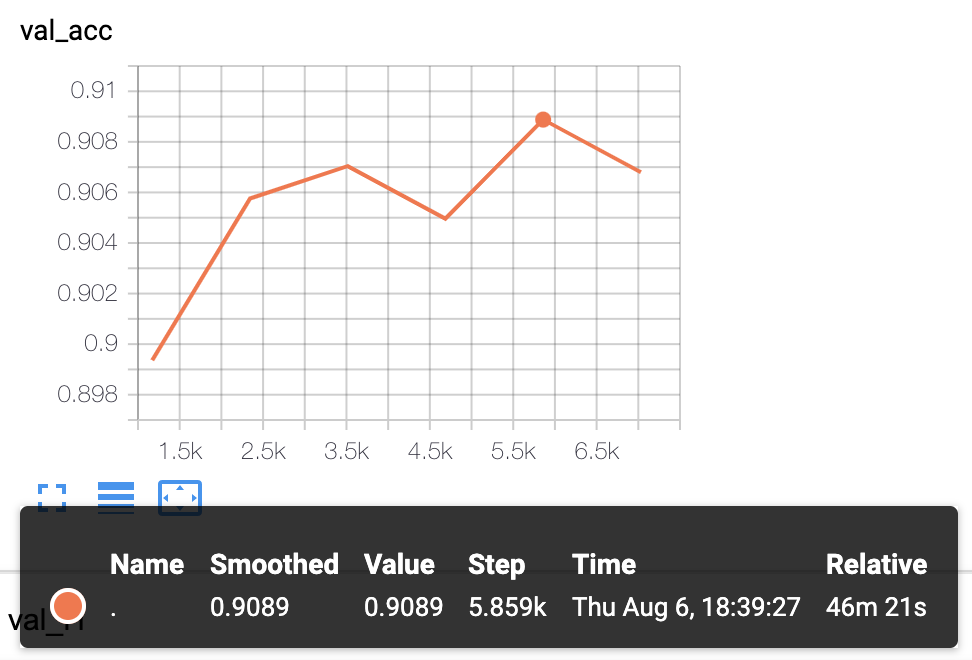
|
| 322 |
+
|
| 323 |
+
- KcBERT-Large Model 실험 결과: Val acc `.9089`
|
| 324 |
+
|
| 325 |
+
|
| 326 |
+
|
| 327 |
+
> 더 다양한 Downstream Task에 대해 테스트를 진행하고 공개할 예정입니다.
|
| 328 |
+
|
| 329 |
+
## 인용표기/Citation
|
| 330 |
+
|
| 331 |
+
KcBERT를 인용하실 때는 아래 양식을 통해 인용해주세요.
|
| 332 |
+
|
| 333 |
+
```
|
| 334 |
+
@inproceedings{lee2020kcbert,
|
| 335 |
+
title={KcBERT: Korean Comments BERT},
|
| 336 |
+
author={Lee, Junbum},
|
| 337 |
+
booktitle={Proceedings of the 32nd Annual Conference on Human and Cognitive Language Technology},
|
| 338 |
+
pages={437--440},
|
| 339 |
+
year={2020}
|
| 340 |
+
}
|
| 341 |
+
```
|
| 342 |
+
|
| 343 |
+
- 논문집 다운로드 링크: http://hclt.kr/dwn/?v=bG5iOmNvbmZlcmVuY2U7aWR4OjMy (*혹은 http://hclt.kr/symp/?lnb=conference )
|
| 344 |
+
|
| 345 |
+
## Acknowledgement
|
| 346 |
+
|
| 347 |
+
KcBERT Model을 학습하는 GCP/TPU 환경은 [TFRC](https://www.tensorflow.org/tfrc?hl=ko) 프로그램의 지원을 받았습니다.
|
| 348 |
+
|
| 349 |
+
모델 학습 과정에서 많은 조언을 주신 [Monologg](https://github.com/monologg/) 님 감사합니다 :)
|
| 350 |
+
|
| 351 |
+
## Reference
|
| 352 |
+
|
| 353 |
+
### Github Repos
|
| 354 |
+
|
| 355 |
+
- [BERT by Google](https://github.com/google-research/bert)
|
| 356 |
+
- [KoBERT by SKT](https://github.com/SKTBrain/KoBERT)
|
| 357 |
+
- [KoELECTRA by Monologg](https://github.com/monologg/KoELECTRA/)
|
| 358 |
+
|
| 359 |
+
- [Transformers by Huggingface](https://github.com/huggingface/transformers)
|
| 360 |
+
- [Tokenizers by Hugginface](https://github.com/huggingface/tokenizers)
|
| 361 |
+
|
| 362 |
+
### Papers
|
| 363 |
+
|
| 364 |
+
- [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805)
|
| 365 |
+
|
| 366 |
+
### Blogs
|
| 367 |
+
|
| 368 |
+
- [Monologg님의 KoELECTRA 학습기](https://monologg.kr/categories/NLP/ELECTRA/)
|
| 369 |
+
- [Colab에서 TPU로 BERT 처음부터 학습시키기 - Tensorflow/Google ver.](https://beomi.github.io/2020/02/26/Train-BERT-from-scratch-on-colab-TPU-Tensorflow-ver/)
|
| 370 |
+
|
config.json
ADDED
|
@@ -0,0 +1,154 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"EncoderDecoderModel"
|
| 4 |
+
],
|
| 5 |
+
"decoder": {
|
| 6 |
+
"_name_or_path": "./beomi/kcbert-base",
|
| 7 |
+
"add_cross_attention": true,
|
| 8 |
+
"architectures": [
|
| 9 |
+
"BertForMaskedLM"
|
| 10 |
+
],
|
| 11 |
+
"attention_probs_dropout_prob": 0.1,
|
| 12 |
+
"bad_words_ids": null,
|
| 13 |
+
"bos_token_id": null,
|
| 14 |
+
"chunk_size_feed_forward": 0,
|
| 15 |
+
"decoder_start_token_id": null,
|
| 16 |
+
"directionality": "bidi",
|
| 17 |
+
"do_sample": false,
|
| 18 |
+
"early_stopping": false,
|
| 19 |
+
"eos_token_id": null,
|
| 20 |
+
"finetuning_task": null,
|
| 21 |
+
"gradient_checkpointing": false,
|
| 22 |
+
"hidden_act": "gelu",
|
| 23 |
+
"hidden_dropout_prob": 0.1,
|
| 24 |
+
"hidden_size": 768,
|
| 25 |
+
"id2label": {
|
| 26 |
+
"0": "LABEL_0",
|
| 27 |
+
"1": "LABEL_1"
|
| 28 |
+
},
|
| 29 |
+
"initializer_range": 0.02,
|
| 30 |
+
"intermediate_size": 3072,
|
| 31 |
+
"is_decoder": true,
|
| 32 |
+
"is_decoder2": false,
|
| 33 |
+
"is_encoder_decoder": false,
|
| 34 |
+
"label2id": {
|
| 35 |
+
"LABEL_0": 0,
|
| 36 |
+
"LABEL_1": 1
|
| 37 |
+
},
|
| 38 |
+
"layer_norm_eps": 1e-12,
|
| 39 |
+
"length_penalty": 1.0,
|
| 40 |
+
"max_length": 20,
|
| 41 |
+
"max_position_embeddings": 300,
|
| 42 |
+
"min_length": 0,
|
| 43 |
+
"model_type": "bert",
|
| 44 |
+
"no_repeat_ngram_size": 0,
|
| 45 |
+
"num_attention_heads": 12,
|
| 46 |
+
"num_beams": 1,
|
| 47 |
+
"num_hidden_layers": 12,
|
| 48 |
+
"num_return_sequences": 1,
|
| 49 |
+
"output_attentions": false,
|
| 50 |
+
"output_hidden_states": false,
|
| 51 |
+
"pad_token_id": 0,
|
| 52 |
+
"pooler_fc_size": 768,
|
| 53 |
+
"pooler_num_attention_heads": 12,
|
| 54 |
+
"pooler_num_fc_layers": 3,
|
| 55 |
+
"pooler_size_per_head": 128,
|
| 56 |
+
"pooler_type": "first_token_transform",
|
| 57 |
+
"prefix": null,
|
| 58 |
+
"pruned_heads": {},
|
| 59 |
+
"repetition_penalty": 1.0,
|
| 60 |
+
"return_dict": false,
|
| 61 |
+
"sep_token_id": null,
|
| 62 |
+
"task_specific_params": null,
|
| 63 |
+
"temperature": 1.0,
|
| 64 |
+
"tie_encoder_decoder": false,
|
| 65 |
+
"tie_word_embeddings": true,
|
| 66 |
+
"tokenizer_class": null,
|
| 67 |
+
"top_k": 50,
|
| 68 |
+
"top_p": 1.0,
|
| 69 |
+
"torchscript": false,
|
| 70 |
+
"type_vocab_size": 2,
|
| 71 |
+
"use_bfloat16": false,
|
| 72 |
+
"use_cache": true,
|
| 73 |
+
"vocab_size": 30000,
|
| 74 |
+
"xla_device": null
|
| 75 |
+
},
|
| 76 |
+
"decoder_start_token_id": 2,
|
| 77 |
+
"early_stopping": true,
|
| 78 |
+
"encoder": {
|
| 79 |
+
"_name_or_path": "./beomi/kcbert-base",
|
| 80 |
+
"add_cross_attention": false,
|
| 81 |
+
"architectures": [
|
| 82 |
+
"BertForMaskedLM"
|
| 83 |
+
],
|
| 84 |
+
"attention_probs_dropout_prob": 0.1,
|
| 85 |
+
"bad_words_ids": null,
|
| 86 |
+
"bos_token_id": null,
|
| 87 |
+
"chunk_size_feed_forward": 0,
|
| 88 |
+
"decoder_start_token_id": null,
|
| 89 |
+
"directionality": "bidi",
|
| 90 |
+
"do_sample": false,
|
| 91 |
+
"early_stopping": false,
|
| 92 |
+
"eos_token_id": null,
|
| 93 |
+
"finetuning_task": null,
|
| 94 |
+
"gradient_checkpointing": false,
|
| 95 |
+
"hidden_act": "gelu",
|
| 96 |
+
"hidden_dropout_prob": 0.1,
|
| 97 |
+
"hidden_size": 768,
|
| 98 |
+
"id2label": {
|
| 99 |
+
"0": "LABEL_0",
|
| 100 |
+
"1": "LABEL_1"
|
| 101 |
+
},
|
| 102 |
+
"initializer_range": 0.02,
|
| 103 |
+
"intermediate_size": 3072,
|
| 104 |
+
"is_decoder": false,
|
| 105 |
+
"is_decoder2": false,
|
| 106 |
+
"is_encoder_decoder": false,
|
| 107 |
+
"label2id": {
|
| 108 |
+
"LABEL_0": 0,
|
| 109 |
+
"LABEL_1": 1
|
| 110 |
+
},
|
| 111 |
+
"layer_norm_eps": 1e-12,
|
| 112 |
+
"length_penalty": 1.0,
|
| 113 |
+
"max_length": 20,
|
| 114 |
+
"max_position_embeddings": 300,
|
| 115 |
+
"min_length": 0,
|
| 116 |
+
"model_type": "bert",
|
| 117 |
+
"no_repeat_ngram_size": 0,
|
| 118 |
+
"num_attention_heads": 12,
|
| 119 |
+
"num_beams": 1,
|
| 120 |
+
"num_hidden_layers": 12,
|
| 121 |
+
"num_return_sequences": 1,
|
| 122 |
+
"output_attentions": false,
|
| 123 |
+
"output_hidden_states": false,
|
| 124 |
+
"pad_token_id": 0,
|
| 125 |
+
"pooler_fc_size": 768,
|
| 126 |
+
"pooler_num_attention_heads": 12,
|
| 127 |
+
"pooler_num_fc_layers": 3,
|
| 128 |
+
"pooler_size_per_head": 128,
|
| 129 |
+
"pooler_type": "first_token_transform",
|
| 130 |
+
"prefix": null,
|
| 131 |
+
"pruned_heads": {},
|
| 132 |
+
"repetition_penalty": 1.0,
|
| 133 |
+
"return_dict": false,
|
| 134 |
+
"sep_token_id": null,
|
| 135 |
+
"task_specific_params": null,
|
| 136 |
+
"temperature": 1.0,
|
| 137 |
+
"tie_encoder_decoder": false,
|
| 138 |
+
"tie_word_embeddings": true,
|
| 139 |
+
"tokenizer_class": null,
|
| 140 |
+
"top_k": 50,
|
| 141 |
+
"top_p": 1.0,
|
| 142 |
+
"torchscript": false,
|
| 143 |
+
"type_vocab_size": 2,
|
| 144 |
+
"use_bfloat16": false,
|
| 145 |
+
"use_cache": true,
|
| 146 |
+
"vocab_size": 30000,
|
| 147 |
+
"xla_device": null
|
| 148 |
+
},
|
| 149 |
+
"force_bos_token_to_be_generated": true,
|
| 150 |
+
"is_encoder_decoder": true,
|
| 151 |
+
"max_length": 32,
|
| 152 |
+
"min_length": 3,
|
| 153 |
+
"model_type": "encoder-decoder"
|
| 154 |
+
}
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f9e4bf3e835047dbfa27fd8ff812d765a38debb8b68a659dcd59c4da3a611450
|
| 3 |
+
size 438192852
|
pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f5af3c1a006f7a7b8edd1b4e526f52c44e120bc14302aa216bc0b72be58906cb
|
| 3 |
+
size 1534576837
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"do_lower_case": false, "model_max_length": 300}
|
vocab.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|