
Update README.md
Browse files
README.md
CHANGED
|
@@ -38,4 +38,95 @@ tags:
|
|
| 38 |
- devign
|
| 39 |
- defect detection
|
| 40 |
- code
|
| 41 |
-
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 38 |
- devign
|
| 39 |
- defect detection
|
| 40 |
- code
|
| 41 |
+
---
|
| 42 |
+
|
| 43 |
+
# VulBERTa MLP Devign
|
| 44 |
+
## VulBERTa: Simplified Source Code Pre-Training for Vulnerability Detection
|
| 45 |
+
|
| 46 |
+
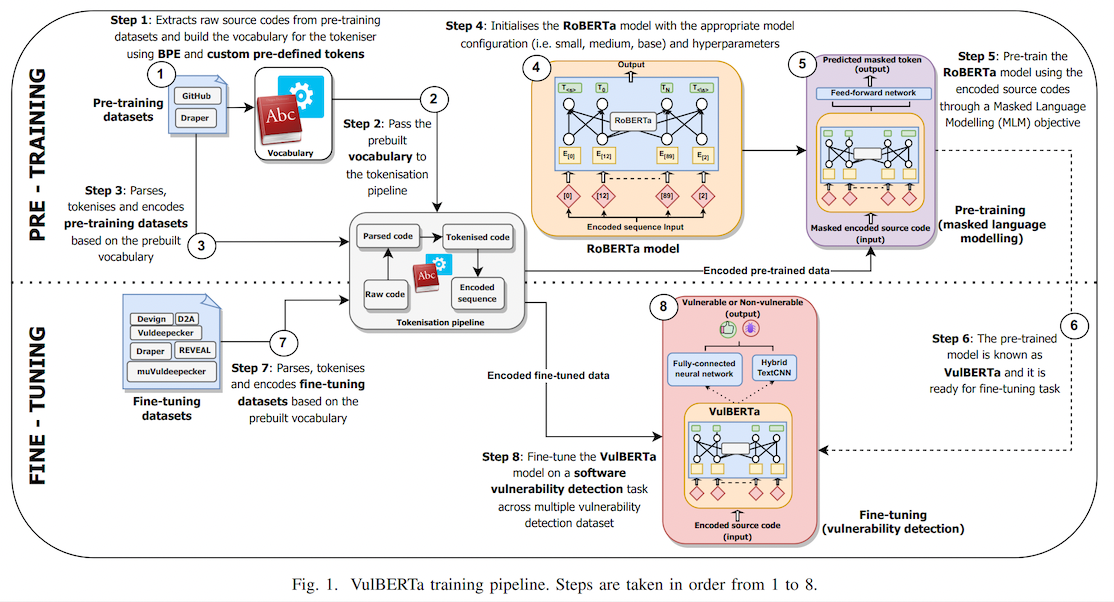
|
| 47 |
+
|
| 48 |
+
## Overview
|
| 49 |
+
This model is the unofficial HuggingFace version of "VulBERTa" with an MLP classification head, trained on CodeXGlue Devign, by Hazim Hanif & Sergio Maffeis (Imperial College London).
|
| 50 |
+
|
| 51 |
+
> This paper presents presents VulBERTa, a deep learning approach to detect security vulnerabilities in source code. Our approach pre-trains a RoBERTa model with a custom tokenisation pipeline on real-world code from open-source C/C++ projects. The model learns a deep knowledge representation of the code syntax and semantics, which we leverage to train vulnerability detection classifiers. We evaluate our approach on binary and multi-class vulnerability detection tasks across several datasets (Vuldeepecker, Draper, REVEAL and muVuldeepecker) and benchmarks (CodeXGLUE and D2A). The evaluation results show that VulBERTa achieves state-of-the-art performance and outperforms existing approaches across different datasets, despite its conceptual simplicity, and limited cost in terms of size of training data and number of model parameters.
|
| 52 |
+
|
| 53 |
+
## Usage
|
| 54 |
+
*You must install libclang for tokenization.*
|
| 55 |
+
|
| 56 |
+
```bash
|
| 57 |
+
pip install libclang
|
| 58 |
+
```
|
| 59 |
+
|
| 60 |
+
Note that due to the custom tokenizer, you must pass `trust_remote_code=True` when instantiating the model.
|
| 61 |
+
Example:
|
| 62 |
+
```
|
| 63 |
+
from transformers import pipeline
|
| 64 |
+
pipe = pipeline("text-classification", model="claudios/VulBERTa-MLP-Devign", trust_remote_code=True, return_all_scores=True)
|
| 65 |
+
pipe("static void filter_mirror_setup(NetFilterState *nf, Error **errp)\n{\n MirrorState *s = FILTER_MIRROR(nf);\n Chardev *chr;\n chr = qemu_chr_find(s->outdev);\n if (chr == NULL) {\n error_set(errp, ERROR_CLASS_DEVICE_NOT_FOUND,\n \"Device '%s' not found\", s->outdev);\n qemu_chr_fe_init(&s->chr_out, chr, errp);")
|
| 66 |
+
>> [[{'label': 'LABEL_0', 'score': 0.014685827307403088},
|
| 67 |
+
{'label': 'LABEL_1', 'score': 0.985314130783081}]]
|
| 68 |
+
```
|
| 69 |
+
|
| 70 |
+
## Data
|
| 71 |
+
We provide all data required by VulBERTa.
|
| 72 |
+
This includes:
|
| 73 |
+
- Tokenizer training data
|
| 74 |
+
- Pre-training data
|
| 75 |
+
- Fine-tuning data
|
| 76 |
+
|
| 77 |
+
Please refer to the [data](https://github.com/ICL-ml4csec/VulBERTa/tree/main/data "data") directory for further instructions and details.
|
| 78 |
+
|
| 79 |
+
## Models
|
| 80 |
+
We provide all models pre-trained and fine-tuned by VulBERTa.
|
| 81 |
+
This includes:
|
| 82 |
+
- Trained tokenisers
|
| 83 |
+
- Pre-trained VulBERTa model (core representation knowledge)
|
| 84 |
+
- Fine-tuned VulBERTa-MLP and VulBERTa-CNN models
|
| 85 |
+
|
| 86 |
+
Please refer to the [models](https://github.com/ICL-ml4csec/VulBERTa/tree/main/models "models") directory for further instructions and details.
|
| 87 |
+
|
| 88 |
+
## Pre-requisites and requirements
|
| 89 |
+
|
| 90 |
+
In general, we used this version of packages when running the experiments:
|
| 91 |
+
|
| 92 |
+
- Python 3.8.5
|
| 93 |
+
- Pytorch 1.7.0
|
| 94 |
+
- Transformers 4.4.1
|
| 95 |
+
- Tokenizers 0.10.1
|
| 96 |
+
- Libclang (any version > 12.0 should work. https://pypi.org/project/libclang/)
|
| 97 |
+
|
| 98 |
+
For an exhaustive list of all the packages, please refer to [requirements.txt](https://github.com/ICL-ml4csec/VulBERTa/blob/main/requirements.txt "requirements.txt") file.
|
| 99 |
+
|
| 100 |
+
## How to use
|
| 101 |
+
|
| 102 |
+
In our project, we uses Jupyterlab notebook to run experiments.
|
| 103 |
+
Therefore, we separate each task into different notebook:
|
| 104 |
+
|
| 105 |
+
- [Pretraining_VulBERTa.ipynb](https://github.com/ICL-ml4csec/VulBERTa/blob/main/Pretraining_VulBERTa.ipynb "Pretraining_VulBERTa.ipynb") - Pre-trains the core VulBERTa knowledge representation model using DrapGH dataset.
|
| 106 |
+
- [Finetuning_VulBERTa-MLP.ipynb](https://github.com/ICL-ml4csec/VulBERTa/blob/main/Finetuning_VulBERTa-MLP.ipynb "Finetuning_VulBERTa-MLP.ipynb") - Fine-tunes the VulBERTa-MLP model on a specific vulnerability detection dataset.
|
| 107 |
+
- [Evaluation_VulBERTa-MLP.ipynb](https://github.com/ICL-ml4csec/VulBERTa/blob/main/Evaluation_VulBERTa-MLP.ipynb "Evaluation_VulBERTa-MLP.ipynb") - Evaluates the fine-tuned VulBERTa-MLP models on testing set of a specific vulnerability detection dataset.
|
| 108 |
+
- [Finetuning+evaluation_VulBERTa-CNN](https://github.com/ICL-ml4csec/VulBERTa/blob/main/Finetuning%2Bevaluation_VulBERTa-CNN.ipynb "Finetuning+evaluation_VulBERTa-CNN.ipynb") - Fine-tunes VulBERTa-CNN models and evaluates it on a testing set of a specific vulnerability detection dataset.
|
| 109 |
+
|
| 110 |
+
## Running VulBERTa-CNN or VulBERTa-MLP on arbitrary codes
|
| 111 |
+
|
| 112 |
+
Coming soon!
|
| 113 |
+
|
| 114 |
+
## Citation
|
| 115 |
+
|
| 116 |
+
Accepted as conference paper (oral presentation) at the International Joint Conference on Neural Networks (IJCNN) 2022.
|
| 117 |
+
Link to paper: https://ieeexplore.ieee.org/document/9892280
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
```bibtex
|
| 121 |
+
@INPROCEEDINGS{hanif2022vulberta,
|
| 122 |
+
author={Hanif, Hazim and Maffeis, Sergio},
|
| 123 |
+
booktitle={2022 International Joint Conference on Neural Networks (IJCNN)},
|
| 124 |
+
title={VulBERTa: Simplified Source Code Pre-Training for Vulnerability Detection},
|
| 125 |
+
year={2022},
|
| 126 |
+
volume={},
|
| 127 |
+
number={},
|
| 128 |
+
pages={1-8},
|
| 129 |
+
doi={10.1109/IJCNN55064.2022.9892280}
|
| 130 |
+
|
| 131 |
+
}
|
| 132 |
+
```
|