

Upload Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU.md
Browse files
Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU.md
ADDED
|
@@ -0,0 +1,174 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 在一张 24 GB 的消费级显卡上用 RLHF 微调 20B LLMs
|
| 2 |
+
|
| 3 |
+
我们很高兴正式发布 `trl` 与 `peft` 的集成,使任何人都可以更轻松地使用强化学习进行大型语言模型 (LLM) 微调!在这篇文章中,我们解释了为什么这是现有微调方法的有竞争力的替代方案。
|
| 4 |
+
|
| 5 |
+
请注意,`peft` 是一种通用工具,可以应用于许多 ML 用例,但它对 RLHF 特别有趣,因为这种方法特别需要内存!
|
| 6 |
+
|
| 7 |
+
如果你想直接深入研究代码,请直接在 [TRL 的文档页面](https://huggingface.co/docs/trl/main/en/sentiment_tuning_peft)直接查看示例脚本。
|
| 8 |
+
|
| 9 |
+
# 介绍
|
| 10 |
+
|
| 11 |
+
## LLMs & RLHF
|
| 12 |
+
|
| 13 |
+
LLM 结合 RLHF(人类反馈强化学习)似乎是构建非常强大的 AI 系统(例如 ChatGPT)的下一个首选方法。
|
| 14 |
+
|
| 15 |
+
使用 RLHF 训练语言模型通常包括以下三个步骤:
|
| 16 |
+
|
| 17 |
+
1. 在特定领域或指令和人类示范语料库上微调预训练的 LLM;
|
| 18 |
+
2. 收集人类标注的数据集,训练一个奖励模型;
|
| 19 |
+
3. 使用 RL(例如 PPO),用此数据集和奖励模型进一步微调步骤 1 中的 LLM。
|
| 20 |
+
|
| 21 |
+
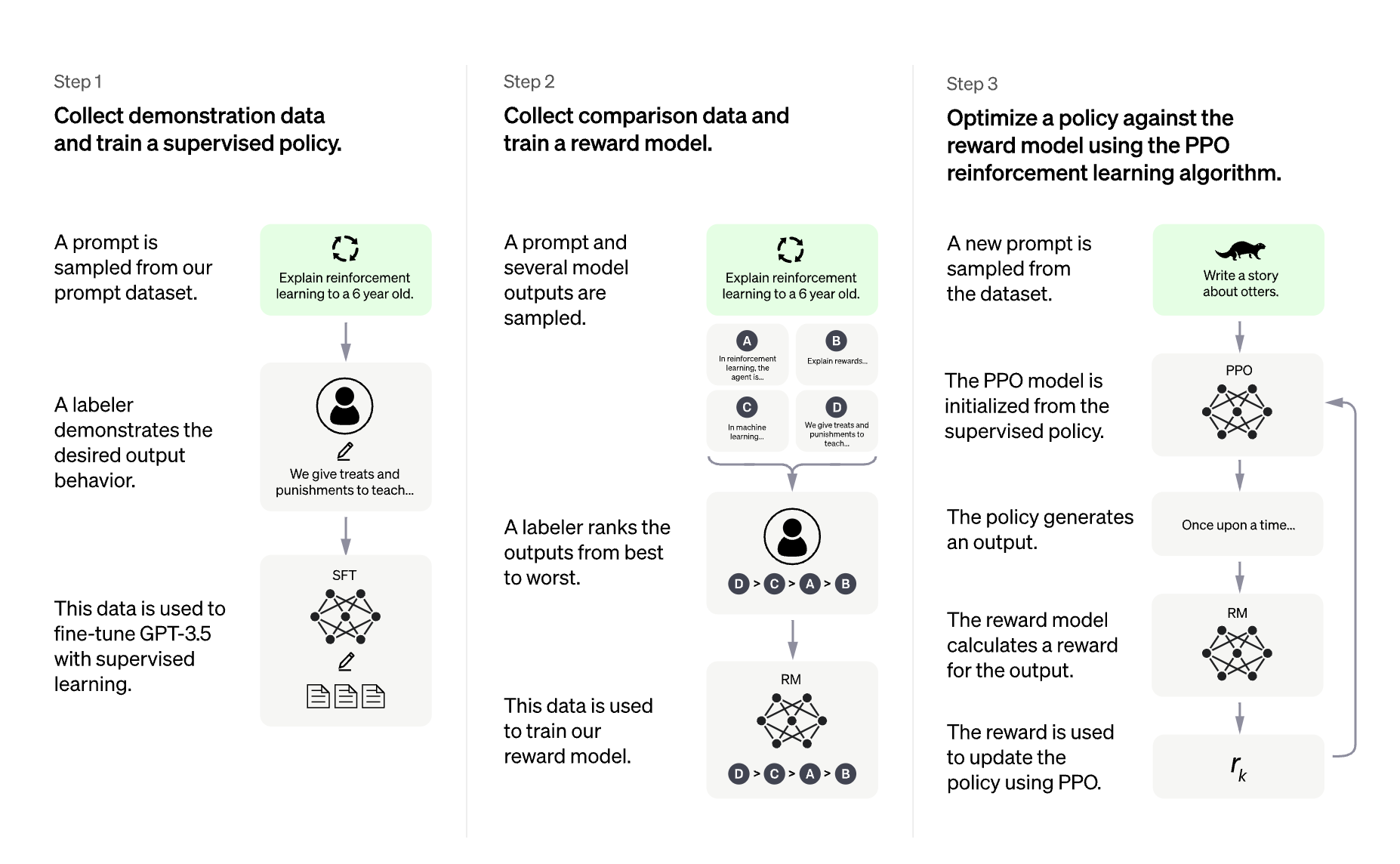
|
| 22 |
+
|
| 23 |
+
*ChatGPT 的训练协议概述,从数据收集到 RL 部分。 资料来源:[OpenAI 的 ChatGPT 博文](https://openai.com/blog/chatgpt)*
|
| 24 |
+
|
| 25 |
+
基础 LLM 的选择在这里是至关重要的。在撰写本文时,可以“开箱即用”地用于许多任务的“最佳”开源 LLM 是指令微调 LLMs。著名的模型有:[BLOOMZ](https://huggingface.co/bigscience/bloomz) [Flan-T5](https://huggingface.co/google/flan-t5-xxl)、[Flan-UL2](https://huggingface.co/google/flan-ul2) 和 [OPT-IML](https://huggingface.co/facebook/opt-iml-max-30b)。这些模型的缺点是它们的尺寸。要获得一个像样的模型,你至少需要玩 10B+ 级别的模型,在全精度情况下这将需要高达 40GB GPU 内存,只是为了将模型装在单个 GPU 设备上而不进行任何训练!
|
| 26 |
+
|
| 27 |
+
## 什么是 TRL?
|
| 28 |
+
|
| 29 |
+
`trl` 库的目的是使 RL 的步骤更容易和灵活,让每个人可以在他们自己的数据集和训练设置上用 RL 微调 LM。在许多其他应用程序中,你可以使用此算法微调模型以生成[正面电影评论](https://huggingface.co/docs/trl/sentiment_tuning)、进行[受控生成](https://github.com/lvwerra/trl/blob/main/examples/sentiment/notebooks/gpt2-sentiment-control.ipynb)或[降低模型的毒性](https://huggingface.co/docs/trl/detoxifying_a_lm)。
|
| 30 |
+
|
| 31 |
+
使用 `trl` 你可以在分布式管理器或者单个设备上运行最受欢迎的深度强化学习算法之一:[PPO](https://huggingface.co/deep-rl-course/unit8/introduction?fw=pt)。我们利用 Hugging Face 生态系统中的 `accelerate` 来实现这一点,这样任何用户都可以将实验扩大到一个有趣的规模。
|
| 32 |
+
|
| 33 |
+
使用 RL 微调语言模型大致遵循下面详述的协议。这需要有 2 个原始模型的副本;为避免活跃模型与其原始行为/分布偏离太多,你需要在每个优化步骤中计算参考模型的 logits 。这对优化过程增加了硬约束,因为你始终需要每个 GPU 设备至少有两个模型副本。如果模型的尺寸变大,在单个 GPU 上安装设置会变得越来越棘手。
|
| 34 |
+
|
| 35 |
+

|
| 36 |
+
|
| 37 |
+
*TRL中 PPO 训练设置概述*
|
| 38 |
+
|
| 39 |
+
在 `trl` 中,你还可以在参考模型和活跃模型之间使用共享层以避免整个副本。 模型解毒示例中展示了此功能的具体示例。
|
| 40 |
+
|
| 41 |
+
## 大规模训练
|
| 42 |
+
|
| 43 |
+
大规模训练是具有挑战性的。第一个挑战是在可用的 GPU 设备上拟合模型,及其优化器状态。 单个参数占用的 GPU 内存量取决于其“精度”(或更具体地说是 `dtype`)。 最常见的 `dtype` 是 `float32`(32 位)、`float16` 和 `bfloat16`(16 位)。 最近,“奇异的”精度支持开箱即用的训练和推理(具有特定条件和约束),例如 `int8`(8 位)。 简而言之,要在 GPU 设备上加载一个模型,每十亿个参数在 float32 精度上需要 4GB,在 float16 上需要 2GB,在 int8 上需要 1GB。 如果你想了解关于这个话题的更多信息,请查看这篇研究深入的文章:https://huggingface.co/blog/hf-bitsandbytes-integration。
|
| 44 |
+
|
| 45 |
+
如果您使用 AdamW 优化器,每个参数需要 8 个字节(例如,如果您的模型有 1B 个参数,则模型的完整 AdamW 优化器将需要 8GB GPU 内存 - [来源](https://huggingface.co/docs/transformers/v4 .20.1/en/perf_train_gpu_one))。
|
| 46 |
+
|
| 47 |
+
许多技术已经被采用以应对大规模训练上的挑战。最熟悉的范式是管道并行、张量并行和数据并行。
|
| 48 |
+
|
| 49 |
+
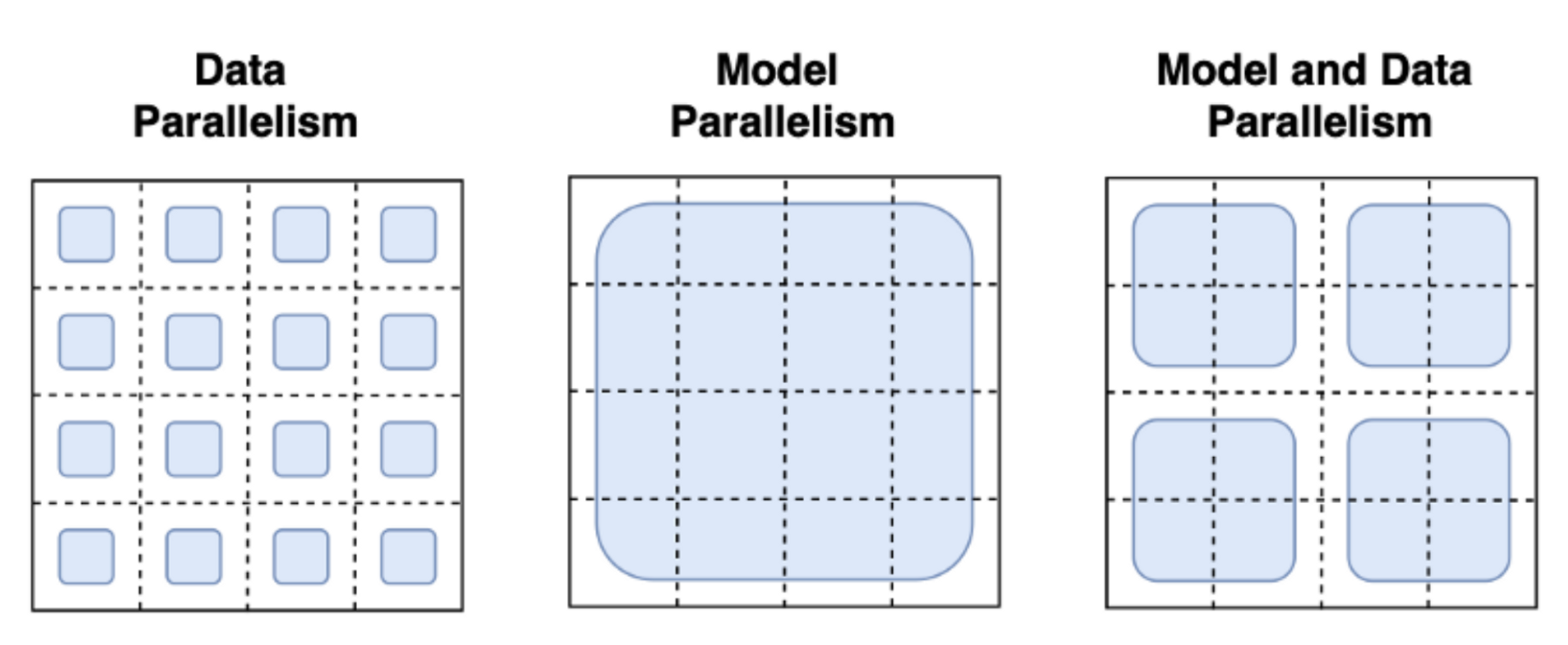
|
| 50 |
+
|
| 51 |
+
*图片来自[这篇博文](https://towardsdatascience.com/distributed-parallel-training-data-parallelism-and-model-parallelism-ec2d234e3214)*
|
| 52 |
+
|
| 53 |
+
通过数据并行性,同一模型并行托管在多台机器上,并且每个实例都被提供不同的数据批次。 这是最直接的并行策略,本质上是复制单 GPU 的情况,并且已经被 `trl` 支持。 使用管道并行和张量并行,模型本身分布在机器上:在管道并行中,模型按层拆分,而张量并行则跨 GPU 拆分张量操作(例如矩阵乘法)。使用这些模型并行策略,你需要将模型权重分片到许多设备上,这需要你定义跨进程的激活和梯度的通信协议。 这实现起来并不简单,可能需要采用一些框架,例如 [`Megatron-DeepSpeed`](https://github.com/microsoft/Megatron-DeepSpeed) 或 [`Nemo`](https://github.com/NVIDIA/NeMo)。其他对扩展训练至关重要的工具也需要被强调,例如自适应激活检查点和融合内核。 可以在[此处](https://huggingface.co/docs/transformers/v4.17.0/en/parallelism)找到有关并行范式的进一步阅读。
|
| 54 |
+
|
| 55 |
+
因此,我们问自己下面一个问题:仅用数据并行我们可以走多远?我们能否使用现有的工具在单个设备中适应超大型训练过程(包括活跃模型、参考模型和优化器状态)? 答案似乎是肯定的。 主要因素是:适配器和 8 位矩阵乘法! 让我们在以下部分中介绍这些主题:
|
| 56 |
+
|
| 57 |
+
## 8 位矩阵乘法
|
| 58 |
+
|
| 59 |
+
高效的 8 位矩阵乘法是论文 LLM.int8() 中首次引入的一种方法,旨在解决量化大规模模型时的性能下降问题。 所提出的方法将在线性层中应用的矩阵乘法分解为两个阶段:在 float16 中将被执行的异常值隐藏状态部分和在 int8 中被执行的“非异常值”部分。
|
| 60 |
+
|
| 61 |
+
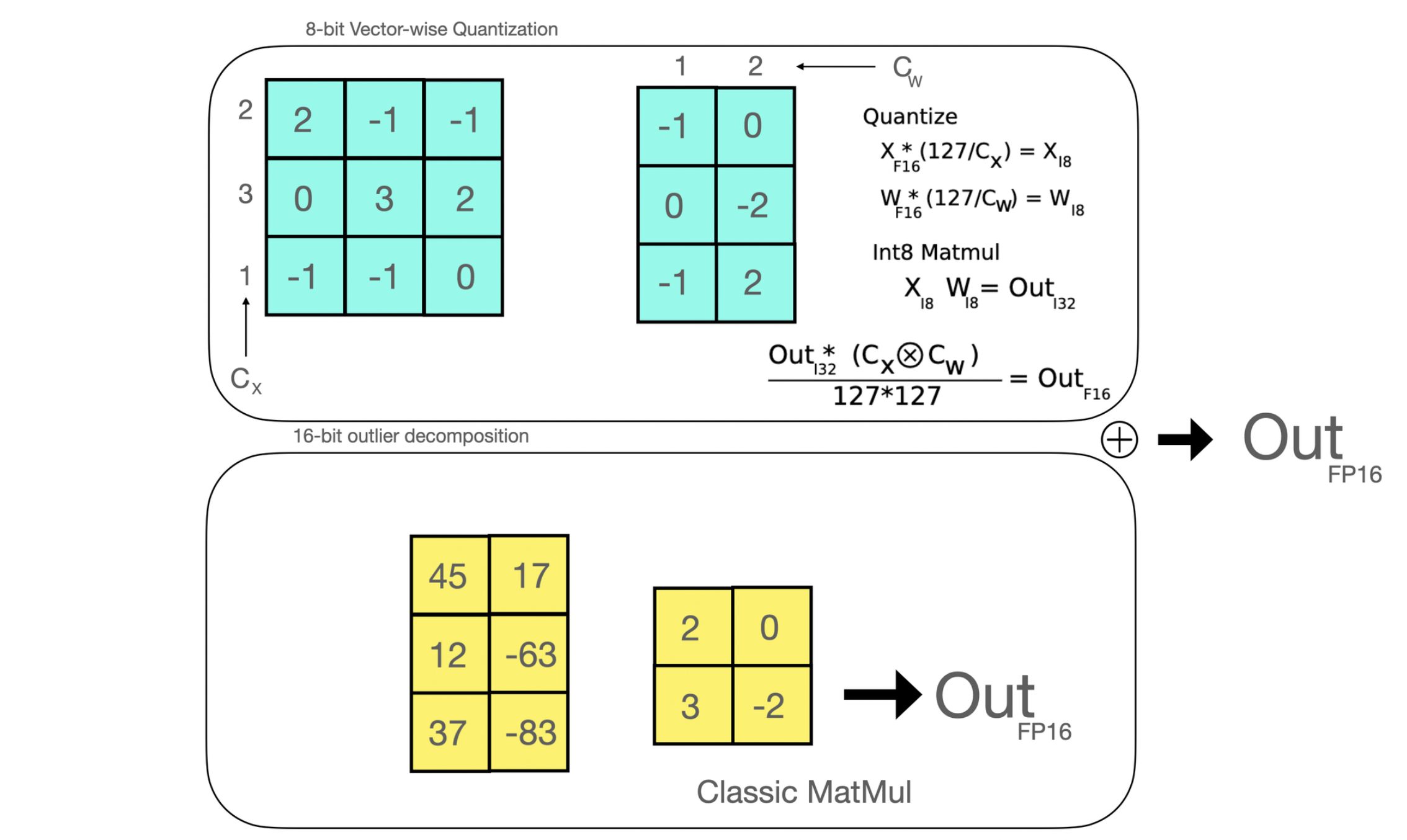
|
| 62 |
+
|
| 63 |
+
*高效的 8 位矩阵乘法是论文 [LLM.int8()](https://arxiv.org/abs/2208.07339) 中首次引入的一种方法,旨在解决量化大规模模型时的性能下降问题。 所提出的方法将在线性层中应用的矩阵乘法分解为两个阶段:在 float16 中被执行的异常值隐藏状态部分和在 int8 中被执行的“非异常值”部分。*
|
| 64 |
+
|
| 65 |
+
简而言之,如果使用 8 位矩阵乘法,则可以将全精度模型的大小减小到 4 分之一(因此,对于半精度模型,可以减小 2 分之一)。
|
| 66 |
+
|
| 67 |
+
## 低秩适配和 PEFT
|
| 68 |
+
|
| 69 |
+
在2021年,一篇叫 *LoRA: Low-Rank Adaption of Large Language Models* 的论文表明,可以通过冻结预训练权重,并创建查询和值层的注意力矩阵的低秩版本来对大型语言模型进行微调。这些低秩矩阵的参数远少于原始模型,因此可以使用更少的 GPU 内存进行微调。 作者证明,低阶适配器的微调取得了与微调完整预训练模型相当的结果。
|
| 70 |
+
|
| 71 |
+

|
| 72 |
+
|
| 73 |
+
*原始(冻结的)预训练权重(左)的输出激活由一个由权重矩阵 A 和 B 组成的低秩适配器(右)增强。*
|
| 74 |
+
|
| 75 |
+
这种技术允许使用一小部分内存来微调 LLM。 然而,也有一些缺点。由于适配器层中的额外矩阵乘法,前向和反向传递的速度大约是原来的两倍。
|
| 76 |
+
|
| 77 |
+
## 什么是 PEFT?
|
| 78 |
+
|
| 79 |
+
[Parameter-Efficient Fine-Tuning (PEFT)](https://github.com/huggingface/peft) 是一个 Hugging Face 的库,它被创造出来以支持在 LLM 上创建和微调适配器层。`peft` 与 🤗 Accelerate 无缝集成,用于利用了 DeepSpeed 和 Big Model Inference 的大规模模型。
|
| 80 |
+
|
| 81 |
+
此库支持很多先进的模型,并且有大量的例子,包括:
|
| 82 |
+
|
| 83 |
+
- 因果语言建模
|
| 84 |
+
- 条件生成
|
| 85 |
+
- 图像分类
|
| 86 |
+
- 8位 int8 训练
|
| 87 |
+
- Dreambooth 模型的低秩适配
|
| 88 |
+
- 语义分割
|
| 89 |
+
- 序列分类
|
| 90 |
+
- 词符分类
|
| 91 |
+
|
| 92 |
+
该库仍在广泛和积极的开发中,许多即将推出的功能将在未来几个月内公布。
|
| 93 |
+
|
| 94 |
+
# 使用低质适配器微调 20B 参数量的模型
|
| 95 |
+
|
| 96 |
+
现在先决条件已经解决,让我们一步步过一遍整个管道,并用图说明如何在单个 24GB GPU 上使用上述工具使用 RL 微调 20B 参数量的 LLM!
|
| 97 |
+
|
| 98 |
+
## 第一步1:在 8 位精度下加载你的活跃模型
|
| 99 |
+
|
| 100 |
+
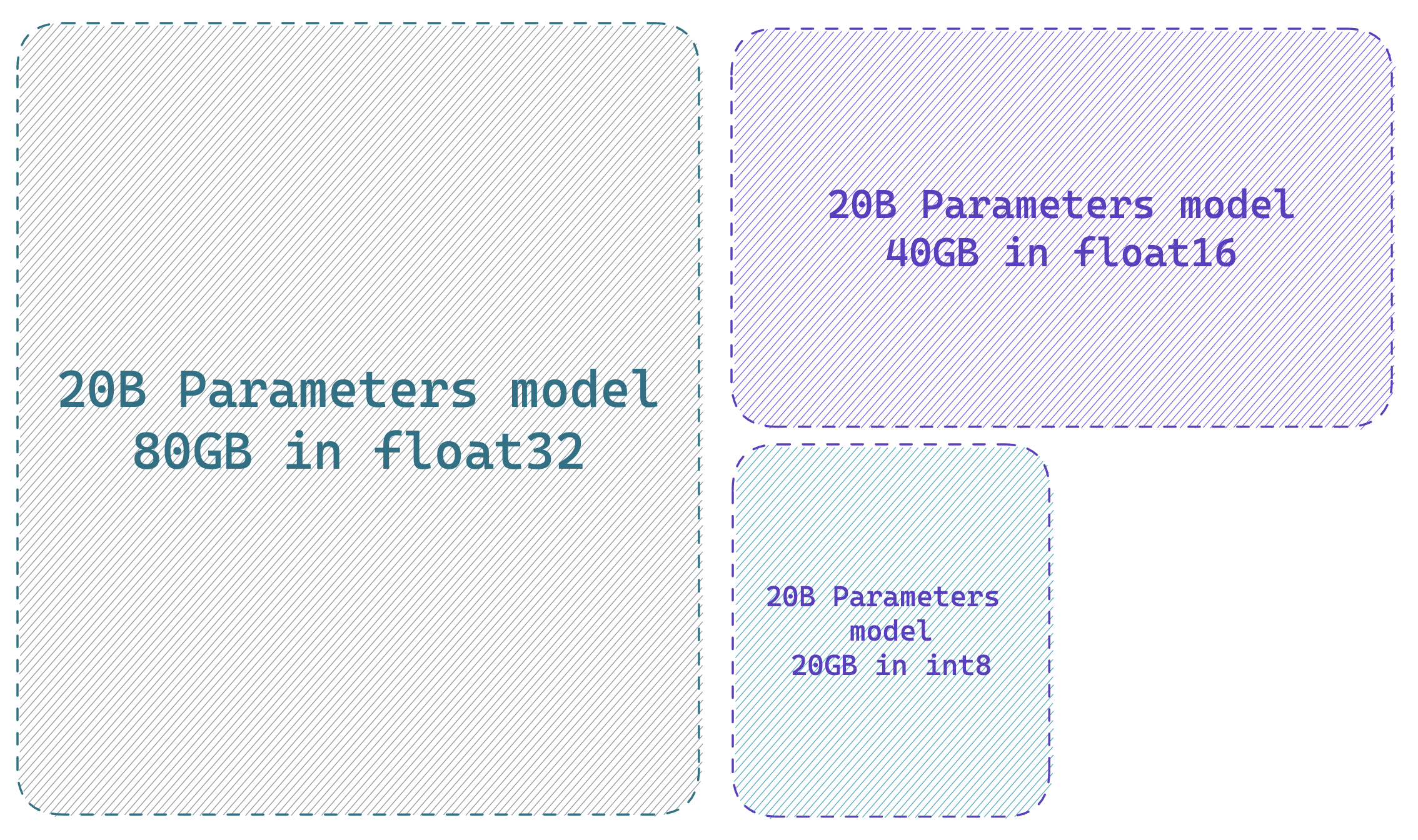
|
| 101 |
+
|
| 102 |
+
*与全精度模型相比,以 8 位精度加载模型最多可节省 4 倍的内存*
|
| 103 |
+
|
| 104 |
+
使用 `transformers` 减少 LLM 内存的“免费午餐”是使用 LLM.int8 中描述的方法,以 8 位精度加载模型。 这可以通过在调用 `from_pretrained` 方法时简单地添加标志 `load_in_8bit=True` 来执行(你可以在[此处](https://huggingface.co/docs/transformers/main/en/main_classes/quantization)阅读更多相关信息)。
|
| 105 |
+
|
| 106 |
+
如前一节所述,计算加载模型所需的 GPU 内存量的“技巧”是根据“十亿个参数量”进行思考。 由于一个字节需要 8 位,因此全精度模型(32 位 = 4 字节)每十亿个参数需要 4GB,半精度模型每十亿个参数需要 2GB,int8 ���型每十亿个参数需要 1GB。
|
| 107 |
+
|
| 108 |
+
所以首先,我们只加载 8 位的活跃模型。 让我们看看第二步需要做什么!
|
| 109 |
+
|
| 110 |
+
## 第2步:使用 `peft` 添加额外可训练的适配器
|
| 111 |
+
|
| 112 |
+
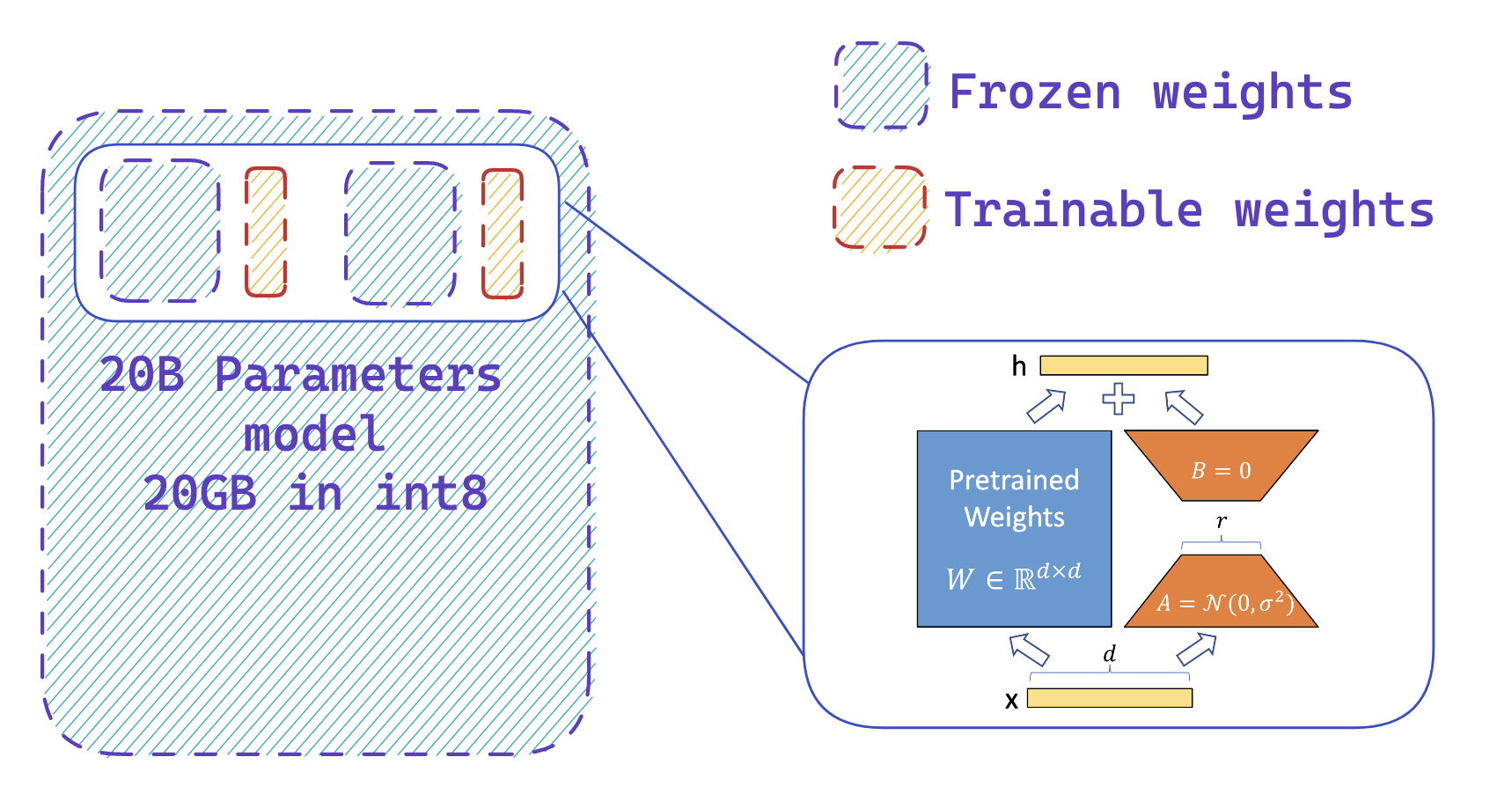
|
| 113 |
+
|
| 114 |
+
*您可以轻松地在冻结的 8 位模型上添加适配器,从而通过训练一小部分参数来减少优化器状态的内存需求*
|
| 115 |
+
|
| 116 |
+
第二步是在模型中加载适配器并使这些适配器可训练。 这可以大幅减少活跃模型所需的可训练权重的数量。 此步骤利用 `peft` 库,只需几行代码即可执行。 请注意,一旦适配器经过训练,您就可以轻松地将它们推送到 Hub 以供以后使用。
|
| 117 |
+
|
| 118 |
+
## 第3步:使用同样的模型得到参考和活跃 logits
|
| 119 |
+
|
| 120 |
+
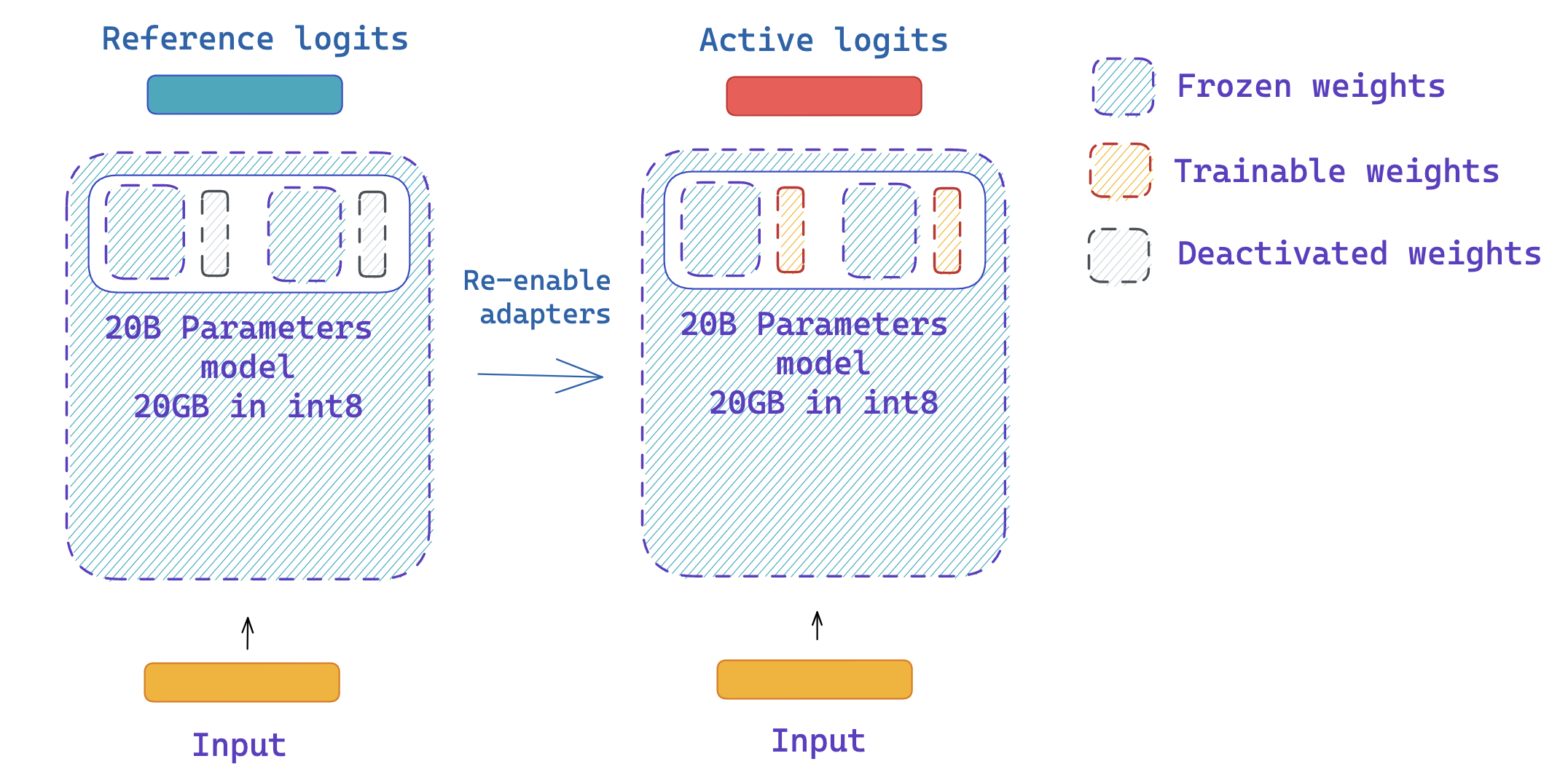
|
| 121 |
+
|
| 122 |
+
*你可以方便地使用 `peft` 关闭和使能适配器*
|
| 123 |
+
|
| 124 |
+
由于适配器可以停用,我们可以使用相同的模型来获取 PPO 的参考和活跃的 logits 值,而无需创建两个相同的模型副本! 这利用了 `peft` 库中的一个功能,即 `disable_adapters` 上下文管理器。
|
| 125 |
+
|
| 126 |
+
## 训练脚本概述
|
| 127 |
+
|
| 128 |
+
我们现在将描述如何使用 `transformers`、`peft` 和 `trl` 训练 20B 参数量的 [gpt-neox 模型](https://huggingface.co/EleutherAI/gpt-neox-20b)。 这个例子的最终目标是微调 LLM 以在内存受限的设置中生成积极的电影评论。类似的步骤可以应用于其他任务,例如对话模型。
|
| 129 |
+
|
| 130 |
+
整体来看有三个关键步骤和训练脚本:
|
| 131 |
+
|
| 132 |
+
1. **[脚本](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt-neox-20b_peft/clm_finetune_peft_imdb.py)** - 在冻结的 8 位模型上微调低秩适配器,以便在 imdb 数据集上生成文本。
|
| 133 |
+
2. **[脚本](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt-neox-20b_peft/merge_peft_adapter.py)** - 将适配器层合并到基础模型的权重中并将它们存储在 Hub 上。
|
| 134 |
+
3. **[脚本](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt-neox-20b_peft/gpt-neo-20b_sentiment_peft.py)** - 对低等级适配器进行情感微调以创建正面评价。
|
| 135 |
+
|
| 136 |
+
我们在 24GB NVIDIA 4090 GPU 上测试了这些步骤。虽然可以在 24 GB GPU 上执行整个训练过程,但在 🤗 研究集群上的单个 A100 上无法进行完整的训练过程。
|
| 137 |
+
|
| 138 |
+
训练过程的第一步是对预训练模型进行微调。 通常这需要几个高端的 80GB A100 GPU,因此我们选择训练低阶适配器。 我们将其视为一种因果语言建模设置,并针从 [imdb](https://huggingface.co/datasets/imdb) 数据集中训练了一个 epoch 的示例,该数据集具有电影评论和指明积极还是消极情绪的标签。
|
| 139 |
+
|
| 140 |
+
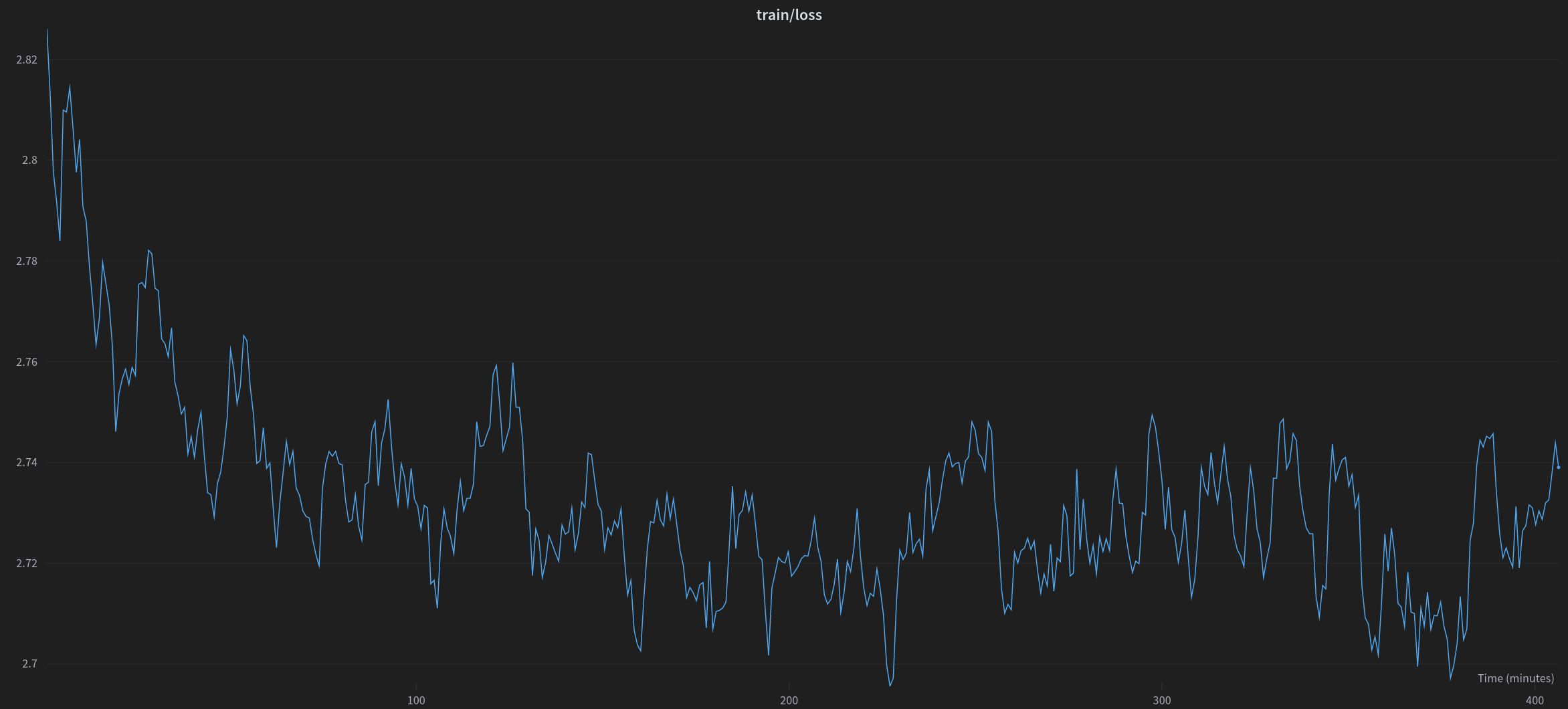
|
| 141 |
+
|
| 142 |
+
*在 imdb 数据集上训练 gpt-neox-20b 模型一个 epoch 期间的训练损失*
|
| 143 |
+
|
| 144 |
+
为了利用已经适配了的模型并使用 RL 执行进一步微调,我们首先需要组合自适应权重,这是通过加载预训练模型和 16 位浮点精度的适配器并且加和权重矩阵(应用适当的缩放比例)来实现的。
|
| 145 |
+
|
| 146 |
+
最后,我们可以在冻结的、用 imdb 微调过的模型之上微调另一个低秩适配器。我们使用一个 imdb [情感分类器](https://huggingface.co/lvwerra/distilbert-imdb)来为 RL 算法提供奖励。
|
| 147 |
+
|
| 148 |
+
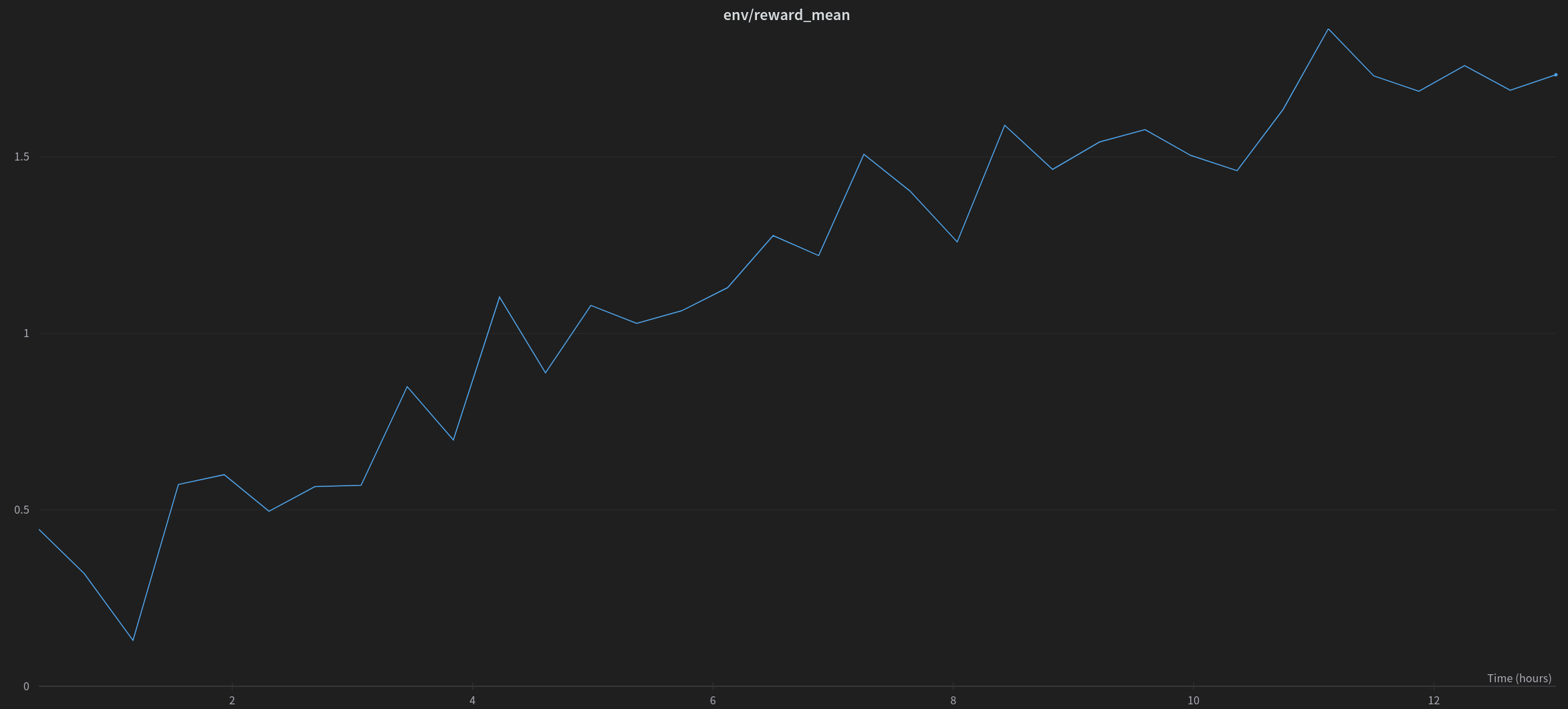
|
| 149 |
+
|
| 150 |
+
*RL 微调 peft 适配过的 20B 参数量的模型以生成积极影评时的奖励均值。*
|
| 151 |
+
|
| 152 |
+
如果您想查看更多图表和文本生成,可在[此处](https://wandb.ai/edbeeching/trl/runs/l8e7uwm6?workspace=user-edbeeching)获取此实验的完整权重和偏差报告。
|
| 153 |
+
|
| 154 |
+
# 结论
|
| 155 |
+
|
| 156 |
+
我们在 `trl` 中实现了一项新功能,允许用户利用 `peft` 和 `bitsandbytes` 库以合理的成本使用 RLHF 微调大型语言模型。 我们证明了可以在 24GB 消费级 GPU 上微调 `gpt-neo-x`(以 `bfloat16` 精度需要 40GB!),我们期望社区将广泛使用此集成来微调利用了 RLHF 的大型模型,并分享出色的工件。
|
| 157 |
+
|
| 158 |
+
我们已经为接下来的步骤确定了一些有趣的方向,以挑战这种集成的极限:
|
| 159 |
+
|
| 160 |
+
- *这将如何在多 GPU 设置中扩展?* 我们将主要探索这种集成将如何根据 GPU 的数量进行扩展,是否可以开箱即用地应用数据并行,或者是否需要在任何相关库上采用一些新功能。
|
| 161 |
+
- *我们可以利用哪些工具来提高训练速度?* 我们观察到这种集成的主要缺点是整体训练速度。 在未来,我们将持续探索使训练更快的可能方向。
|
| 162 |
+
|
| 163 |
+
# 参考
|
| 164 |
+
|
| 165 |
+
- 并行范式:https://huggingface.co/docs/transformers/v4.17.0/en/parallelism
|
| 166 |
+
- `transformers` 中的 8 位集成:https://huggingface.co/blog/hf-bitsandbytes-integration
|
| 167 |
+
- LLM.int8 论文:https://arxiv.org/abs/2208.07339
|
| 168 |
+
- 梯度检查点解释:https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-extended-features-pytorch-activation-checkpointing.html
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
> 英文原文:https://huggingface.co/blog/trl-peft
|
| 173 |
+
>
|
| 174 |
+
> 译者:AIboy1993(李旭东)
|