Datasets:

File size: 5,135 Bytes
9de44b2 3ff05d5 9de44b2 3ff05d5 9de44b2 3ff05d5 9dfc060 3ff05d5 9dfc060 3ff05d5 9de44b2 3ff05d5 9de44b2 3ff05d5 9de44b2 3ff05d5 9de44b2 3ff05d5 9de44b2 3ff05d5 9de44b2 3ff05d5 ba6f747 9de44b2 3ff05d5 9de44b2 3ff05d5 9de44b2 3ff05d5 9de44b2 3ff05d5 9de44b2 821a98a 1ab0d1c 821a98a b047d61 821a98a b047d61 821a98a b047d61 821a98a 0dac0ec 821a98a 21af414 0dac0ec 21af414 0dac0ec 21af414 821a98a |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 |
---
language:
- en
license: mit
configs:
- config_name: FinDER
data_files:
- split: corpus
path: FinDER/corpus.jsonl.gz
- split: queries
path: FinDER/queries.jsonl.gz
- config_name: ConvFinQA
data_files:
- split: corpus
path: ConvFinQA/corpus.jsonl.gz
- split: queries
path: ConvFinQA/queries.jsonl.gz
- config_name: FinQA
data_files:
- split: corpus
path: FinQA/corpus.jsonl.gz
- split: queries
path: FinQA/queries.jsonl.gz
- config_name: FinQABench
data_files:
- split: corpus
path: FinQABench/corpus.jsonl.gz
- split: queries
path: FinQABench/queries.jsonl.gz
- config_name: FinanceBench
data_files:
- split: corpus
path: FinanceBench/corpus.jsonl.gz
- split: queries
path: FinanceBench/queries.jsonl.gz
- config_name: MultiHiertt
data_files:
- split: corpus
path: MultiHeirtt/corpus.jsonl.gz
- split: queries
path: MultiHeirtt/queries.jsonl.gz
- config_name: TATQA
data_files:
- split: corpus
path: TATQA/corpus.jsonl.gz
- split: queries
path: TATQA/queries.jsonl.gz
---
# Dataset Card for FinanceRAG
## Dataset Summary
The detailed description of dataset and reference will be added after the competition in [Kaggle/FinanceRAG Challenge](https://www.kaggle.com/competitions/icaif-24-finance-rag-challenge)
## Datasets
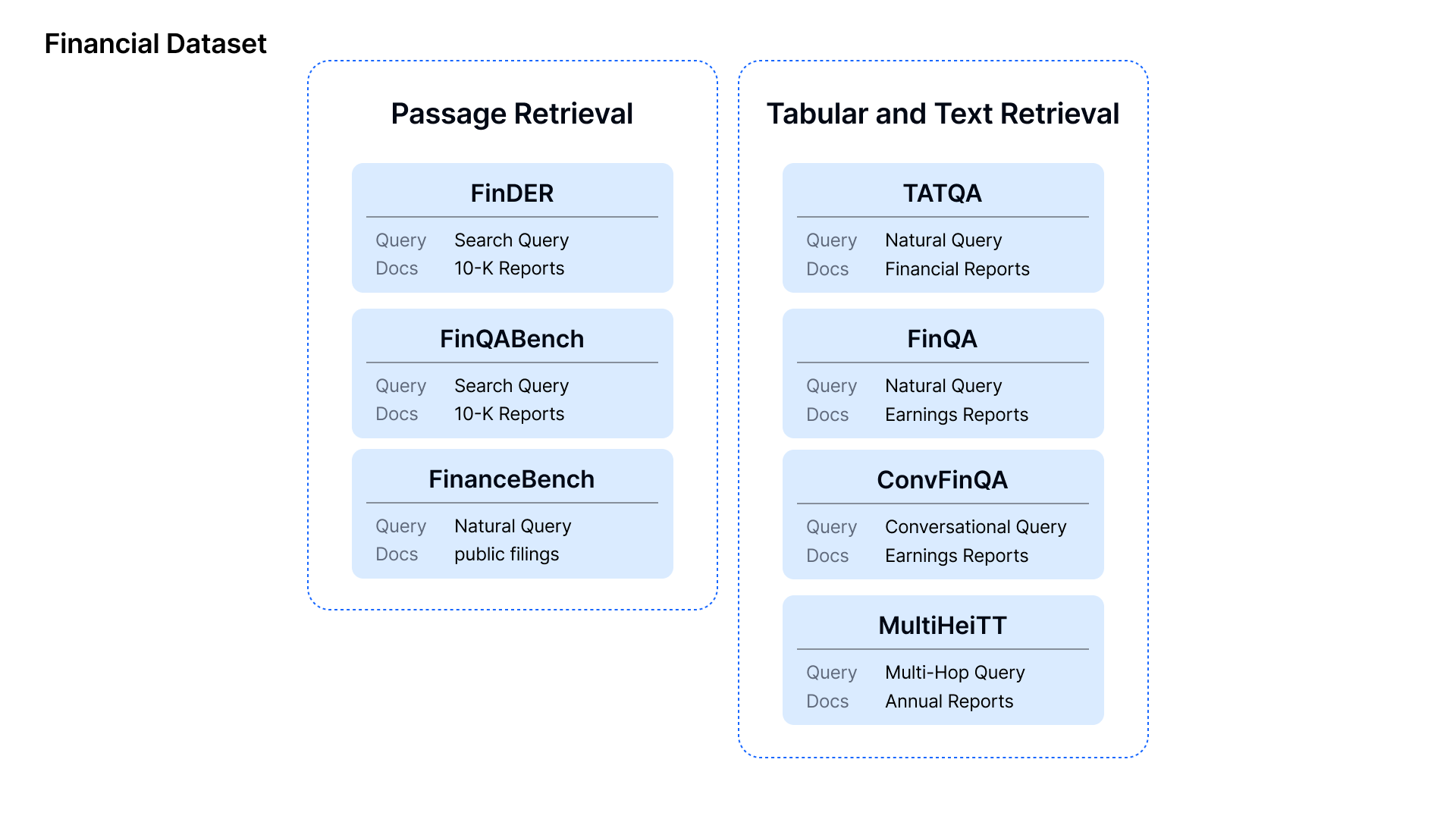
1. **Passage Retrieval**:
- **FinDER**: Involves retrieving relevant sections from **10-K Reports** and financial disclosures based on **Search Queries** that simulate real-world questions asked by financial professionals, using domain-specific jargon and abbreviations.
- **FinQABench**: Focuses on testing AI models' ability to answer **Search Queries** over **10-K Reports** with accuracy, evaluating the system's ability to detect hallucinations and ensure factual correctness in generated answers.
- **FinanceBench**: Uses **Natural Queries** to retrieve relevant information from public filings like **10-K** and **Annual Reports**. The aim is to evaluate how well systems handle straightforward, real-world financial questions.
2. **Tabular and Text Retrieval**:
- **TATQA**: Requires participants to answer **Natural Queries** that involve numerical reasoning over hybrid data, which combines tables and text from **Financial Reports**. Tasks include basic arithmetic, comparisons, and logical reasoning.
- **FinQA**: Demands answering complex **Natural Queries** over **Earnings Reports** using multi-step numerical reasoning. Participants must accurately extract and calculate data from both textual and tabular sources.
- **ConvFinQA**: Involves handling **Conversational Queries** where participants answer multi-turn questions based on **Earnings Reports**, maintaining context and accuracy across multiple interactions.
- **MultiHiertt**: Focuses on **Multi-Hop Queries**, requiring participants to retrieve and reason over hierarchical tables and unstructured text from **Annual Reports**, making this one of the more complex reasoning tasks involving multiple steps across various document sections.
## Files
For each dataset, you are provided with two files:
* **corpus.jsonl** - This is a `JSONLines` file containing the context corpus. Each line in the file represents a single document in `JSON` format.
* **queries.jsonl** - This is a `JSONLines` file containing the queries. Each line in this file represents one query in `JSON` format.
Both files follow the jsonlines format, where each line corresponds to a separate data instance in `JSON` format.
Here’s an expanded description including explanations for each line:
- **_id**: A unique identifier for the context/query.
- **title**: The title or headline of the context/query.
- **text**: The full body of the document/query, containing the main content.
### How to Use
The following code demonstrates how to load a specific subset (in this case, **FinDER**) from the **FinanceRAG** dataset on Hugging Face. In this example, we are loading the `corpus` split, which contains the document data relevant for financial analysis.
The `load_dataset` function is used to retrieve the dataset, and a loop is set up to print the first document entry from the dataset, which includes fields like `_id`, `title`, and `text`.
Each document provides detailed descriptions from financial reports, which participants can use for tasks such as retrieval and answering financial queries.
``` python
from datasets import load_dataset
# Loading a specific subset (i.e. FinDER) and a split (corpus, queries)
dataset = load_dataset("Linq-AI-Research/FinanceRAG", "FinDER", split="corpus")
for example in dataset:
print(example)
break
```
Here is an example result of `python` output of **FinDER** from the `corpus` split:
```json
{
'_id' : 'ADBE20230004',
'title': 'ADBE OVERVIEW',
'text': 'Adobe is a global technology company with a mission to change the world through personalized digital experiences...'
}
``` |