---
license: cc-by-2.0
---
# IndoMMLU

Fajri Koto, Nurul Aisyah, Haonan Li, Timothy Baldwin
📄 Paper •
🏆 Leaderboard •
🤗 Dataset
## Introduction
We introduce IndoMMLU, the first multi-task language understanding benchmark for Indonesian culture and languages,
which consists of questions from primary school to university entrance exams in Indonesia. By employing professional teachers,
we obtain 14,906 questions across 63 tasks and education levels, with 46\% of the questions focusing on assessing proficiency
in the Indonesian language and knowledge of nine local languages and cultures in Indonesia.
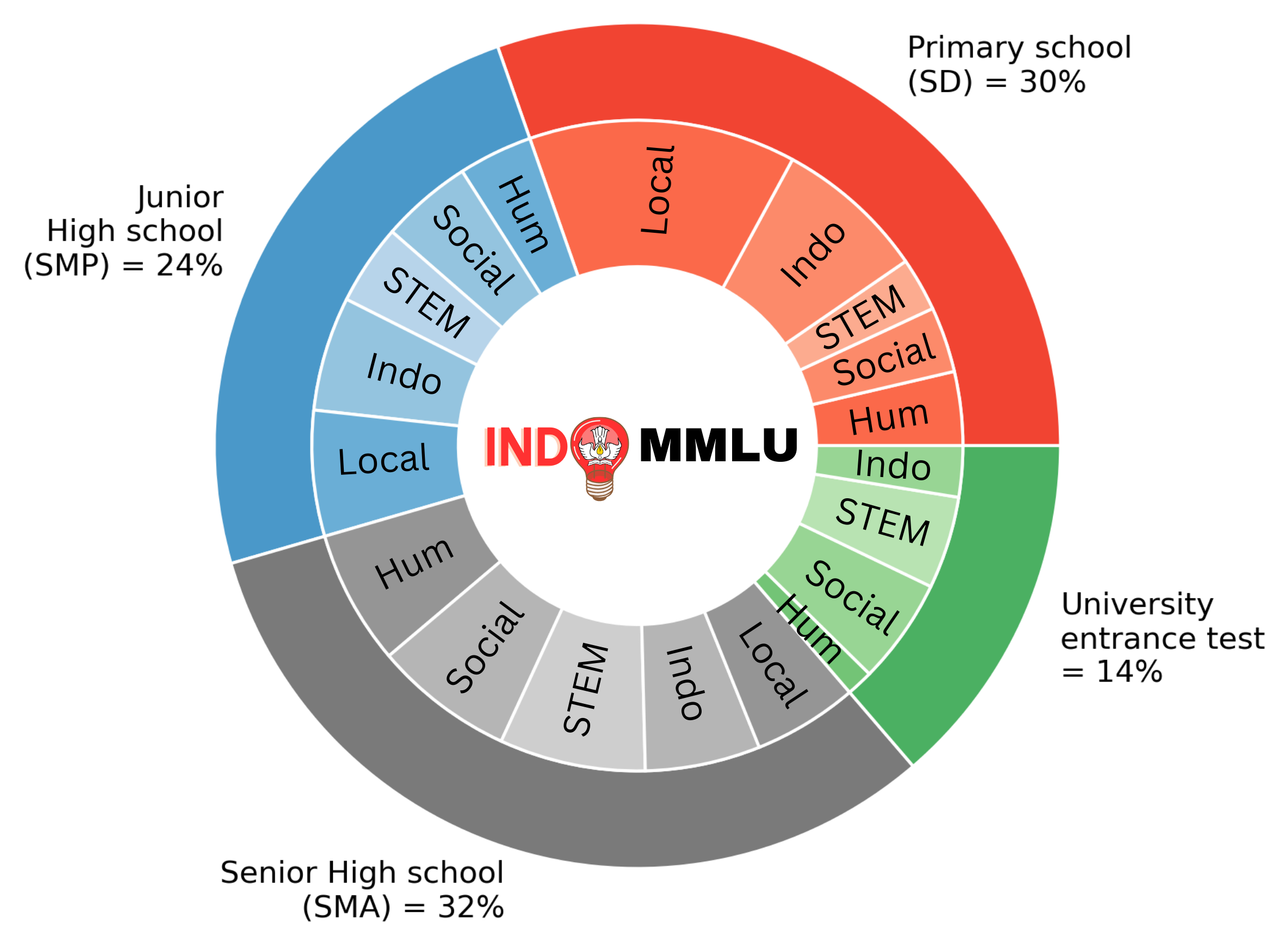
## Subjects
| Level | Subjects |
|-----------|------------------------------------|
| SD (Primary School) | Science, Social science, Civics, Indonesian Language, Balinese, Makassarese, Banjarese, Lampungic, Madurese, Sundanese, Javanese, Dayak Ngaju, Minangkabau culture, Art, Sports, Islam religion, Christian religion, Hindu religion |
| SMP (Junior High School) | Science, Social science, Civics, Indonesian Language, Balinese, Makassarese, Banjarese, Lampungic, Madurese, Sundanese, Javanese, Minangkabau culture, Art, Sports, Islam religion, Christian religion, Hindu religion |
| SMA (Senior High School) | Physics, Chemistry, Biology, Geography, Sociology, Economics, History, Civics, Indonesian Language, Balinese, Makassarese, Banjarese, Lampungic, Madurese, Sundanese, Javanese, Art, Sports, Islam religion, Christian religion, Hindu religion |
University Entrance Test | Chemistry, Biology, Geography, Sociology, Economics, History, Indonesian Language |
We categorize the collected questions into different subject areas, including: (1) STEM (Science, Technology, Engineering, and Mathematics); (2) Social Science; (3) Humanities; (4) Indonesian Language; and (5) Local Languages and Cultures.
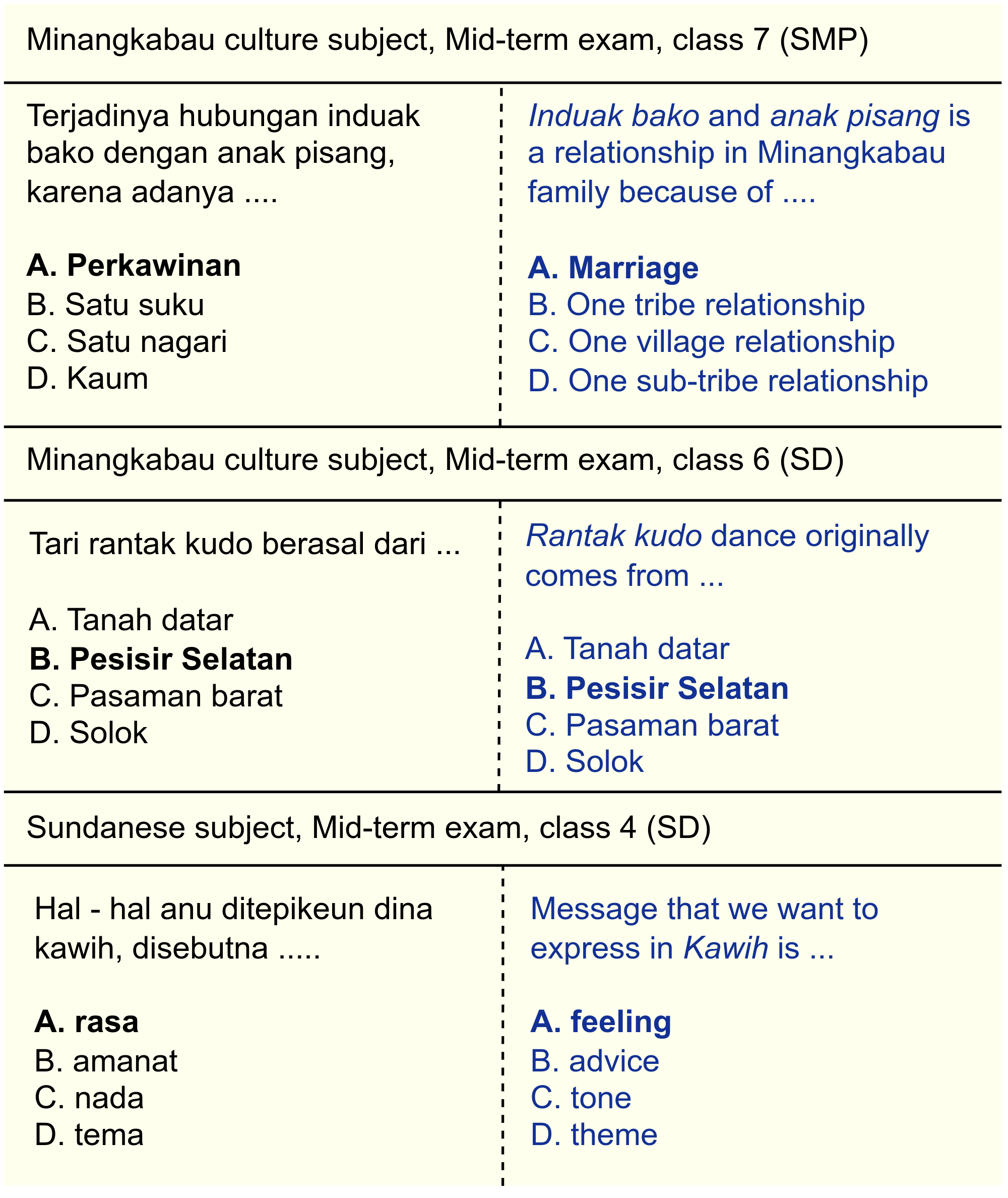
## Examples
These questions are written in Indonesian. For local language subjects, some are written in the local languages. The English version is for illustrative purposes only.
## Evaluation
We evaluate 24 multilingual LLMs of different sizes in zero-shot and few-shot settings. This includes [GPT-3.5 (ChatGPT)](https://chat.openai.com/), [XGLM](https://arxiv.org/abs/2112.10668), [Falcon](https://falconllm.tii.ae/), [BLOOMZ](https://huggingface.co/bigscience/bloomz), [mT0](https://huggingface.co/bigscience/bloomz), [LLaMA](https://arxiv.org/abs/2302.13971), and [Bactrian-X](https://github.com/mbzuai-nlp/bactrian-x). Prior to the question and multiple-choice options, we add a simple prompt in the Indonesian language:
```
Ini adalah soal [subject] untuk [level]. Pilihlah salah satu jawaban yang dianggap benar!
English Translation: This is a [subject] question for [level]. Please choose the correct answer!
```
#### Zero-shot Evaluation
| Model (#param) | STEM | Social Science | Humanities | Indonesian Lang. | Local L. Culture | Average |
|---------------------|------|----------|-------------|---------|----------|---------|
| Random | 21.9 | 23.4 | 23.5 | 24.4 | 26.6 | 24.4 |
| [GPT-3.5 (175B)](https://chat.openai.com/) | **54.3** | **62.5** | **64.0** | **62.2** | 39.3 | **53.2** |
| [XGLM (564M)](https://huggingface.co/facebook/xglm-564M) | 22.1 | 23.0 | 25.6 | 25.6 | 27.5 | 25.2 |
| [XGLM (1.7B)](https://huggingface.co/facebook/xglm-1.7B) | 20.9 | 23.0 | 24.6 | 24.8 | 26.6 | 24.4 |
| [XGLM (2.9B)](https://huggingface.co/facebook/xglm-2.9B) | 22.9 | 23.2 | 25.4 | 26.3 | 27.2 | 25.2 |
| [XGLM (4.5B)](https://huggingface.co/facebook/xglm-4.5B) | 21.8 | 23.1 | 25.6 | 25.8 | 27.1 | 25.0 |
| [XGLM (7.5B)](https://huggingface.co/facebook/xglm-7.5B) | 22.7 | 21.7 | 23.6 | 24.5 | 27.5 | 24.5 |
| [Falcon (7B)](https://huggingface.co/tiiuae/falcon-7b) | 22.1 | 22.9 | 25.5 | 25.7 | 27.5 | 25.1 |
| [Falcon (40B)](https://huggingface.co/tiiuae/falcon-40b) | 30.2 | 34.8 | 34.8 | 34.9 | 29.2 | 32.1 |
| [BLOOMZ (560M)](https://huggingface.co/bigscience/bloomz-560m) | 22.9 | 23.6 | 23.2 | 24.2 | 25.1 | 24.0 |
| [BLOOMZ (1.1B)](https://huggingface.co/bigscience/bloomz-1b1) | 20.4 | 21.4 | 21.1 | 23.5 | 24.7 | 22.4 |
| [BLOOMZ (1.7B)](https://huggingface.co/bigscience/bloomz-1b7) | 31.5 | 39.3 | 38.3 | 42.8 | 29.4 | 34.4 |
| [BLOOMZ (3B)](https://huggingface.co/bigscience/bloomz-3b) | 33.5 | 44.5 | 39.7 | 46.7 | 29.8 | 36.4 |
| [BLOOMZ (7.1B)](https://huggingface.co/bigscience/bloomz-7b1) | 37.1 | 46.7 | 44.0 | 49.1 | 28.2 | 38.0 |
| [mT0small (300M)](https://huggingface.co/bigscience/mt0-small) | 21.8 | 21.4 | 25.7 | 25.1 | 27.6 | 24.9 |
| [mT0base (580M)](https://huggingface.co/bigscience/mt0-base) | 22.6 | 22.6 | 25.7 | 25.6 | 26.9 | 25.0 |
| [mT0large (1.2B)](https://huggingface.co/bigscience/mt0-large) | 22.0 | 23.4 | 25.1 | 27.3 | 27.6 | 25.2 |
| [mT0xl (3.7B)](https://huggingface.co/bigscience/mt0-xl) | 31.4 | 42.9 | 41.0 | 47.8 | 35.7 | 38.2 |
| [mT0xxl (13B)](https://huggingface.co/bigscience/mt0-xxl) | 33.5 | 46.2 | 47.9 | 52.6 | **39.6** | 42.5 |
| [LLaMA (7B)](https://arxiv.org/abs/2302.13971) | 22.8 | 23.1 | 25.1 | 26.7 | 27.6 | 25.3 |
| [LLaMA (13B)](https://arxiv.org/abs/2302.13971) | 24.1 | 23.0 | 24.4 | 29.5 | 26.7 | 25.3 |
| [LLaMA (30B)](https://arxiv.org/abs/2302.13971) | 25.4 | 23.5 | 25.9 | 28.4 | 28.7 | 26.5 |
| [LLaMA (65B)](https://arxiv.org/abs/2302.13971) | 33.0 | 37.7 | 40.8 | 41.4 | 32.1 | 35.8 |
| [Bactrian-X-LLaMA (7B)](https://github.com/mbzuai-nlp/bactrian-x) | 23.3 | 24.0 | 26.0 | 26.1 | 27.5 | 25.7 |
| [Bactrian-X-LLaMA (13B)](https://github.com/mbzuai-nlp/bactrian-x) | 28.3 | 29.9 | 32.8 | 35.2 | 29.2 | 30.3 |
#### GPT-3.5 performance (% accuracy) across different education levels
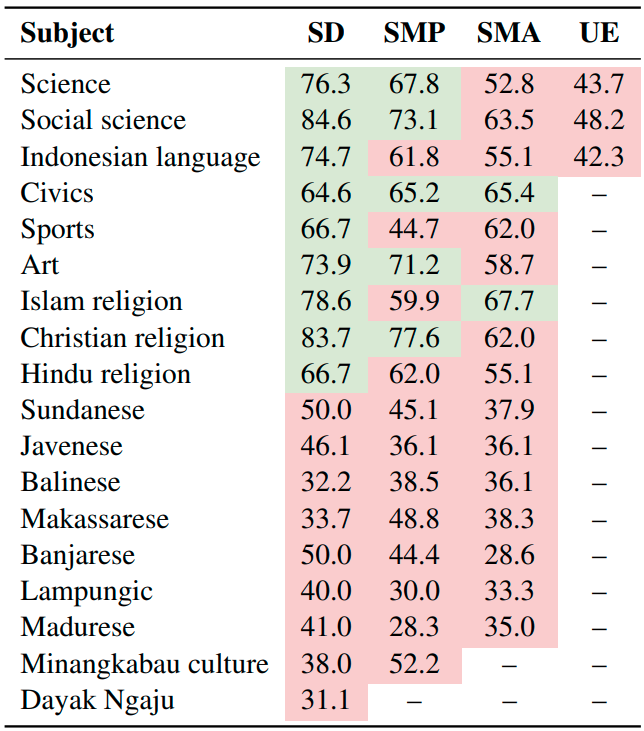
Red indicates that the score is below the minimum passing threshold of 65, while green signifies a score at or above this minimum. We can observe that ChatGPT mostly passes a score of 65 in Indonesian primary school exams.
#### Few-shot Evaluation

## Data
Each question in the dataset is a multiple-choice question with up to 5 choices and only one choice as the correct answer.
We provide our dataset according to each subject in [data](data) folder. You can also access our dataset via [Hugging Face](https://huggingface.co/datasets/indolem/indommlu).
#### Evaluation
The code for the evaluation of each model we used is in `evaluate.py`, and the code to run them is listed in `run.sh`.
## Citation
```
@inproceedings{koto-etal-2023-indommlu,
title = "Large Language Models Only Pass Primary School Exams in {I}ndonesia: A Comprehensive Test on {I}ndo{MMLU}",
author = "Fajri Koto and Nurul Aisyah and Haonan Li and Timothy Baldwin",
booktitle = "Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
month = December,
year = "2023",
address = "Singapore",
publisher = "Association for Computational Linguistics",
}
```
## License
The IndoMMLU dataset is licensed under a
[Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License](http://creativecommons.org/licenses/by-nc-sa/4.0/).