---
language:
- es
size_categories:
- n<1K
task_categories:
- summarization
pretty_name: Resumen Noticias Clickbait
dataset_info:
features:
- name: id
dtype: int64
- name: titular
dtype: string
- name: respuesta
dtype: string
- name: pregunta
dtype: string
- name: texto
dtype: string
- name: idioma
dtype: string
- name: periodo
dtype: string
- name: tarea
dtype: string
- name: registro
dtype: string
- name: dominio
dtype: string
- name: país_origen
dtype: string
splits:
- name: train
num_bytes: 5440051
num_examples: 700
- name: validation
num_bytes: 462364
num_examples: 50
- name: test
num_bytes: 782443
num_examples: 100
download_size: 3417741
dataset_size: 6684858
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
tags:
- summarization
- clickbait
- news
---

NoticIA: Un Dataset para el Resumen de Artículos Clickbait en Español.
Definimos un artículo clickbait como un artículo que busca atraer la atención del lector a través de la curiosidad.
Para ello, el titular plantea una pregunta o una afirmación incompleta, sansacionalista, exagerada o engañosa.
La respuesta a la pregunta generada en el titular, no suele aparecer hasta el final del artículo, la cual es precedida por una gran cantidad de contenido irrelevante.
El objetivo es que el usuario entre en la web a través del titular y después haga scroll hasta el final del artículo haciéndole ver la mayor cantidad de publicidad posible.
Los artículos clickbait suelen ser de baja calidad y no aportan valor al lector, más allá de la curiosidad inicial. Este fenómeno hace socavar la confianza del público en las fuentes de noticias.
Y afecta negativamente a los ingresos publicitarios de los creadores de contenidos legítimos, que podrían ver reducido su tráfico web.
Presentamos NoticIA, un conjunto de datos que consta de 850 artículos de noticias en español con titulares clickbait,
cada uno emparejado con resúmenes generativos de alta calidad de una sola frase escritos por humanos.
Esta tarea exige habilidades avanzadas de comprensión y resumen de texto, desafiando la capacidad de los modelos para inferir y
conectar diversas piezas de información para satisfacer la curiosidad informativa del usuario generada por el titular clickbait.
El proyecto está inspirado la cuenta de X/Twitter [@ahorrandoclick1](https://x.com/ahorrandoclick1).
[@ahorrandoclick1](https://x.com/ahorrandoclick1) cuenta con 300.000 seguidores, lo que demuestra el gran valor de realizar resúmenes de noticias clickbait.
Sin embargo, realizar estos resúmenes a mano, es una tarea muy laboriosa, y el número de noticias clickbait publicadas supera ampliante el número de resúmenes que
una persona puede realizar. Por lo tanto, existe la necesidad de generar resúmenes automáticos de noticias clickbait. Además, como hemos mencionado anteriormente, se
trata de una tarea ideal para analizar las capacidades de compresión de texto en español de un modelo de lenguaje.
# Ejemplos de Noticias Clickbait
La siguiente imágen muestra algunas noticias Clickbait extraídas de nuestro dataset. Como se puede ver, los titulares son altamente sensacionalistas, prometiendo al usuario una información que no cumple las expectivas, o que en algunos casos, ni siquiera existe.
Estos artículos no cumplen ninguna función informatica, y su único objetivo es generar ingresos publicitarios con los lectores que se ven atraídos por un titular engañoso.

# Recopilación de Noticias Clickbait
Hemos recopilado noticias clickbait usando la timeline del usuario de X/Twitter [@ahorrandoclick1](https://x.com/ahorrandoclick1). Para ello, hemos extraído
las url de las noticias mencionadas por el usuario. Además, hemos añadido aproximadamente 100 noticias clibait escogidas por nosotros. La siguiente imágen, muestra
la fuente de las noticias del dataset.

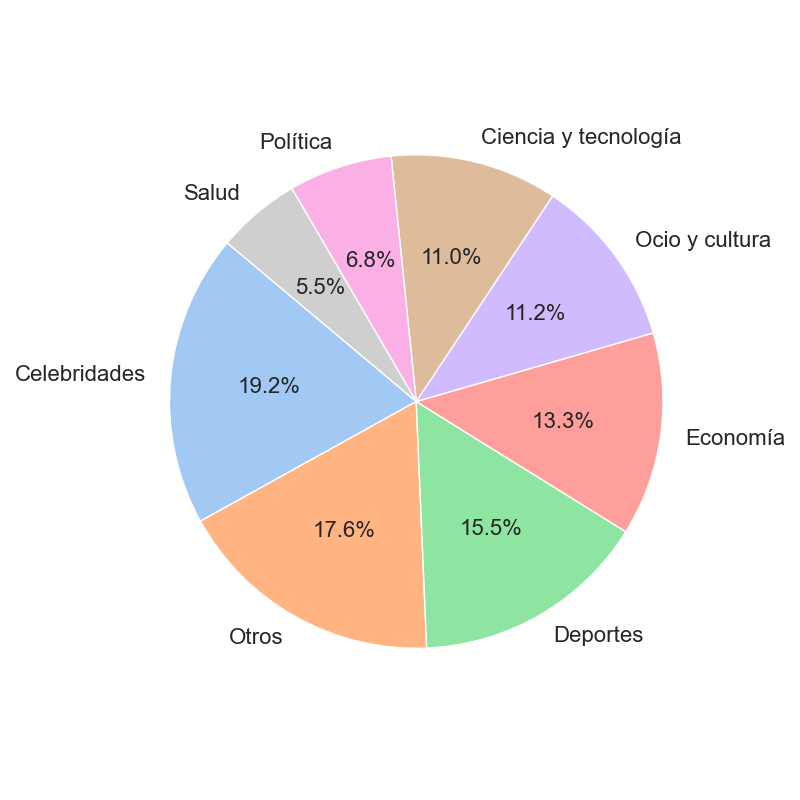
Hemos clasificado cada una de las noticias en base a la categoría a la que pertenecen. Como se puede observar, nuestro dataset incluye una gran variedad de categorías.
# Anotación del dataset
Aunque [@ahorrandoclick1](https://x.com/ahorrandoclick1) reliza resúmenes de las noticias clickbat, estos resúmenes no siguen unas guidelines, y en muchos casos,
su resumen no hace referencia al texto, si no que son del estilo *"Esto es publicidad"*, *"Aún no se han enterado de que..."*. Por lo tanto, hemos generado
a mano el resumen de las 850 noticias. Para ello, hemos definido unas guidelines de anotación estrictas, disponibles en el siguiente enlace: [https://huggingface.co/spaces/Iker/ClickbaitAnnotation/blob/main/guidelines.py](https://huggingface.co/spaces/Iker/ClickbaitAnnotation/blob/main/guidelines.py).
El dataset ha sido anotado por [Iker García-Ferrero](https://ikergarcia1996.github.io/Iker-Garcia-Ferrero/) y [Begoña Altuna](https://www.linkedin.com/in/bego%C3%B1a-altuna-78014139), en este proceso se han invertido aproximadamente 40 horas.
# Estadísticas del dataset
Hemos dividido el dataset en tres splits, lo que facilita el entrenamiento de modelos. Como se puede ver en la siguiente tabla, los resúmenes de las noticias son extremadamente concisos.
Responden al titulat clcikbait de usando el menor número de palabras posibles.
| | Train | Validation | Test | Total |
|--------------------|-------|-----|------|-------|
| Número de artículos | 700 | 50 | 100 | 850 |
| Número medio de palabras en los titulates | 16 | 17 | 17 | 17 |
| Número medio de palabras del texto de la noticia | 544 | 663 | 549 | 552 |
| Número medio de palabras en los resúmenes | 12 | 11 | 11 | 12 |
# Validación de las anotaciones
Para validar el dataset, los 100 resúmenes del conjunto de Test han sido anotados por dos anotadores.
La concordancia general entre los anotadores ha sido alta, ya que han proporcionado exactamente la misma respuesta en el 26\% de los casos y han proporcionado respuestas que comparten parcialmente la información en el 48\% de los casos (misma respuesta, pero con alguna variación en las palabras utilizadas).
Esto demuestra que a los humanos les resultó fácil encontrar la información a la que se refiere el titular. También hemos identificado una lista de casos en los que los anotadores han ofrecido respuestas diferentes pero igualmente válidas, lo que constituye el 18\% de los casos.
Por último, identificamos 8 casos de desacuerdo. En 3 casos, uno de los anotadores realizó un resumen incorrecto,
probablemente debido al cansancio tras anotar múltiples ejemplos. En los 5 casos restantes, el desacuerdo se debió a información contradictoria en el artículo y
a diferentes interpretaciones de esta información. En estos casos, la determinación del resumen correcto queda sujeto a la interpretación del lector.
En cuanto a la evaluación de las guidelines, en general, no eran ambiguas, aunque que la petición de seleccionar la cantidad mínima de palabras para generar un
resumen válido a veces no es interpretada de la misma forma por los anotadores: Por ejemplo, la extensión mínima podría entenderse como el enfoque de la pregunta en el titular o una frase mínima bien formada.
En breves publicaremos un artículo con un análisis más detallado. Las anotaciones escritas por cada anotador pueden comprobarse en el siguiente enlace: [https://huggingface.co/datasets/Iker/NoticIA_Human_Validation](https://huggingface.co/datasets/Iker/NoticIA_Human_Validation).
# Formato de los datos
El dataset se encuentra listo para ser usado para evaluar modelos de lenguaje. Para ellos, hemos desarrollado un *prompt* que hace uso del titular de la noticia y el texto.
El prompt es el siguiente:
```python
def clickbait_prompt(
headline: str,
body: str,
) -> str:
"""
Generate the prompt for the model.
Args:
headline (`str`):
The headline of the article.
body (`str`):
The body of the article.
Returns:
`str`: The formatted prompt.
"""
return (
f"Ahora eres una Inteligencia Artificial experta en desmontar titulares sensacionalistas o clickbait. "
f"Tu tarea consiste en analizar noticias con titulares sensacionalistas y "
f"generar un resumen de una sola frase que revele la verdad detrás del titular.\n"
f"Este es el titular de la noticia: {headline}\n"
f"El titular plantea una pregunta o proporciona información incompleta. "
f"Debes buscar en el cuerpo de la noticia una frase que responda lo que se sugiere en el título. "
f"Responde siempre que puedas parafraseando el texto original. "
f"Usa siempre las mínimas palabras posibles. "
f"Recuerda responder siempre en Español.\n"
f"Este es el cuerpo de la noticia:\n"
f"{body}\n"
)
```
El output experado del modelo es el resúmen. A continuación, se muestra un ejemplo de como evaluar `gemma-2b` en nuestro dataset:
```
from transformers import pipeline
from datasets import load_dataset
generator = pipeline(model="google/gemma-2b-it",device_map="auto")
dataset = load_dataset("somosnlp/NoticIA-it",split="test")
outputs = generator(dataset[0]["prompt"], return_full_text=False,max_length=4096)
print(outputs)
```
El dataset incluye los siguientes campos:
- **ID**: id del ejemplo
- **titular**: Titular del artículo
- **respuesta**: Resumen escrito por un humano
- **pregunta**: Prompt listo para servir de input a un modelo de lenguaje
- **texto**: Texto del artículo, obtenido del HTML.
# Evaluación masiva de Modelos de Lenguaje
Como es habitual en las tareas de resumen, utilizamos la métrica de puntuación ROUGE para evaluar automáticamente los resúmenes producidos por los modelos.
Nuestra métrica principal es ROUGE-1, que considera las palabras enteras como unidades básicas. Para calcular la puntuación ROUGE, ponemos en minúsculas ambos resúmenes y eliminamos los signos de puntuación.
Además de la puntuación ROUGE, también tenemos en cuenta la longitud media de los resúmenes.
Para nuestra tarea, pretendemos que los resúmenes sean concisos, un aspecto que la puntuación ROUGE no evalúa. Por lo tanto, al evaluar los modelos tenemos en cuenta tanto la puntuación ROUGE-1 como la longitud media de los resúmenes. Nuestro objetivo es encontrar un modelo que consiga la mayor puntuación ROUGE posible con la menor longitud de resumen posible, equilibrando calidad y brevedad.
Hemos realizado una evaluación incluyendo los mejores modelos de lenguaje entrenados para seguir instrucciones actuales. Hemos usado el prompt definido previamente. El prompt es convertido al template de chat específico de cada modelo.
El código para reproducir los resultados se encuentra en el siguiente enlace: [https://github.com/ikergarcia1996/NoticIA](https://github.com/ikergarcia1996/NoticIA)

# Usos del dataset
Este dataset ha sido recopilado para su uso en investigación científica. Concretamente, para su uso en la evaluación de modelos de lenguaje en Español.
El uso comercial de este dataset está supedidado a las licencias de cada noticia y medio. Si quieres hacer un uso comercial del dataset tendrás que tener
el permiso expreso de los medios de los cuales han sido obtenidas las noticias. Prohibimos expresamente el uso de estos datos para dos casos de uso que consideramos
que pueden ser perjudiciales: El entrenamiento de modelos que generen titulares sensacionalistas o clickbait, y el entrenamiento de modelos que generen artículos o noticias de forma automática.
# Dataset Description
- **Author:** [Iker García-Ferrero](https://ikergarcia1996.github.io/Iker-Garcia-Ferrero/)
- **Author** [Begoña Altuna](https://www.linkedin.com/in/bego%C3%B1a-altuna-78014139)
- **Web Page**: [Github](https://github.com/ikergarcia1996/NoticIA)
- **Language(s) (NLP):** Spanish
# Autores
Este dataset ha sido creado por [Iker García-Ferrero](https://ikergarcia1996.github.io/Iker-Garcia-Ferrero/) y [Begoña Altuna](https://www.linkedin.com/in/bego%C3%B1a-altuna-78014139).
Somos investigadores en PLN en la Universidad del País Vasco, dentro del grupo de investigación [IXA](https://www.ixa.eus/) y formamos parte de [HiTZ, el Centro Vasco de Tecnología de la Lengua](https://www.hitz.eus/es).