

readme: add initial version
Browse files- README.md +117 -0
- delpher-corpus.urls +23 -0
- figures/delpher_corpus_stats.png +0 -0
- figures/training_loss.png +0 -0
README.md
ADDED
|
@@ -0,0 +1,117 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Language Model for Historic Dutch
|
| 2 |
+
|
| 3 |
+
In this repository we open source a language model for Historic Dutch, trained on the
|
| 4 |
+
[Delpher Corpus](https://www.delpher.nl/over-delpher/delpher-open-krantenarchief/download-teksten-kranten-1618-1879\),
|
| 5 |
+
that include digitized texts from Dutch newspapers, ranging from 1618 to 1879.
|
| 6 |
+
|
| 7 |
+
# Changelog
|
| 8 |
+
|
| 9 |
+
* 13.12.2021: Initial version of this repository.
|
| 10 |
+
|
| 11 |
+
# Model Zoo
|
| 12 |
+
|
| 13 |
+
The following models for Historic Dutch are available on the Hugging Face Model Hub:
|
| 14 |
+
|
| 15 |
+
| Model identifier | Model Hub link
|
| 16 |
+
| -------------------------------------- | -------------------------------------------------------------------
|
| 17 |
+
| `dbmdz/bert-base-historic-dutch-cased` | [here](https://huggingface.co/dbmdz/bert-base-historic-dutch-cased)
|
| 18 |
+
|
| 19 |
+
# Stats
|
| 20 |
+
|
| 21 |
+
The download urls for all archives can be found [here](delpher-corpus.urls).
|
| 22 |
+
|
| 23 |
+
We then used the awesome `alto-tools` from [this](https://github.com/cneud/alto-tools)
|
| 24 |
+
repository to extract plain text. The following table shows the size overview per year range:
|
| 25 |
+
|
| 26 |
+
| Period | Extracted plain text size
|
| 27 |
+
| --------- | -------------------------:
|
| 28 |
+
| 1618-1699 | 170MB
|
| 29 |
+
| 1700-1709 | 103MB
|
| 30 |
+
| 1710-1719 | 65MB
|
| 31 |
+
| 1720-1729 | 137MB
|
| 32 |
+
| 1730-1739 | 144MB
|
| 33 |
+
| 1740-1749 | 188MB
|
| 34 |
+
| 1750-1759 | 171MB
|
| 35 |
+
| 1760-1769 | 235MB
|
| 36 |
+
| 1770-1779 | 271MB
|
| 37 |
+
| 1780-1789 | 414MB
|
| 38 |
+
| 1790-1799 | 614MB
|
| 39 |
+
| 1800-1809 | 734MB
|
| 40 |
+
| 1810-1819 | 807MB
|
| 41 |
+
| 1820-1829 | 987MB
|
| 42 |
+
| 1830-1839 | 1.7GB
|
| 43 |
+
| 1840-1849 | 2.2GB
|
| 44 |
+
| 1850-1854 | 1.3GB
|
| 45 |
+
| 1855-1859 | 1.7GB
|
| 46 |
+
| 1860-1864 | 2.0GB
|
| 47 |
+
| 1865-1869 | 2.3GB
|
| 48 |
+
| 1870-1874 | 1.9GB
|
| 49 |
+
| 1875-1876 | 867MB
|
| 50 |
+
| 1877-1879 | 1.9GB
|
| 51 |
+
|
| 52 |
+
The total training corpus consists of 427,181,269 sentences and 3,509,581,683 tokens (counted via `wc`),
|
| 53 |
+
resulting in a total corpus size of 21GB.
|
| 54 |
+
|
| 55 |
+
The following figure shows an overview of the number of chars per year distribution:
|
| 56 |
+
|
| 57 |
+

|
| 58 |
+
|
| 59 |
+
# Language Model Pretraining
|
| 60 |
+
|
| 61 |
+
We use the official [BERT](https://github.com/google-research/bert) implementation using the following command
|
| 62 |
+
to train the model:
|
| 63 |
+
|
| 64 |
+
```bash
|
| 65 |
+
python3 run_pretraining.py --input_file gs://delpher-bert/tfrecords/*.tfrecord \
|
| 66 |
+
--output_dir gs://delpher-bert/bert-base-historic-dutch-cased \
|
| 67 |
+
--bert_config_file ./config.json \
|
| 68 |
+
--max_seq_length=512 \
|
| 69 |
+
--max_predictions_per_seq=75 \
|
| 70 |
+
--do_train=True \
|
| 71 |
+
--train_batch_size=128 \
|
| 72 |
+
--num_train_steps=3000000 \
|
| 73 |
+
--learning_rate=1e-4 \
|
| 74 |
+
--save_checkpoints_steps=100000 \
|
| 75 |
+
--keep_checkpoint_max=20 \
|
| 76 |
+
--use_tpu=True \
|
| 77 |
+
--tpu_name=electra-2 \
|
| 78 |
+
--num_tpu_cores=32
|
| 79 |
+
```
|
| 80 |
+
|
| 81 |
+
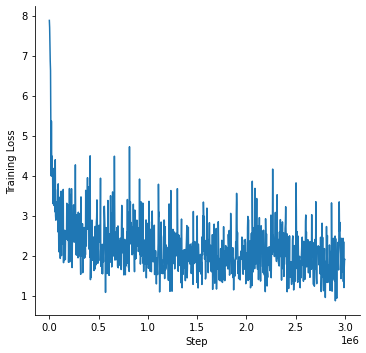
We train the model for 3M steps using a total batch size of 128 on a v3-32 TPU. The pretraining loss curve can be seen
|
| 82 |
+
in the next figure:
|
| 83 |
+
|
| 84 |
+

|
| 85 |
+
|
| 86 |
+
# Evaluation
|
| 87 |
+
|
| 88 |
+
We evaluate our model on the preprocessed Europeana NER dataset for Dutch, that was presented in the
|
| 89 |
+
["Data Centric Domain Adaptation for Historical Text with OCR Errors"](https://github.com/stefan-it/historic-domain-adaptation-icdar) paper.
|
| 90 |
+
|
| 91 |
+
The data is available in their repository. We perform a hyper-parameter search for:
|
| 92 |
+
|
| 93 |
+
* Batch sizes: `[4, 8]`
|
| 94 |
+
* Learning rates: `[3e-5, 5e-5]`
|
| 95 |
+
* Number of epochs: `[5, 10]`
|
| 96 |
+
|
| 97 |
+
and report averaged F1-Score over 5 runs with different seeds. We also include [hmBERT](https://github.com/stefan-it/clef-hipe/blob/main/hlms.md) as baseline model.
|
| 98 |
+
|
| 99 |
+
Results:
|
| 100 |
+
|
| 101 |
+
| Model | F1-Score (Dev / Test)
|
| 102 |
+
| ------------------- | ---------------------
|
| 103 |
+
| hmBERT | (82.73) / 81.34
|
| 104 |
+
| Maerz et al. (2021) | - / 84.2
|
| 105 |
+
| Ours | (89.73) / 87.45
|
| 106 |
+
|
| 107 |
+
# License
|
| 108 |
+
|
| 109 |
+
All models are licensed under [MIT](LICENSE).
|
| 110 |
+
|
| 111 |
+
# Acknowledgments
|
| 112 |
+
|
| 113 |
+
Research supported with Cloud TPUs from Google's TPU Research Cloud (TRC) program, previously known as
|
| 114 |
+
TensorFlow Research Cloud (TFRC). Many thanks for providing access to the TRC ❤️
|
| 115 |
+
|
| 116 |
+
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
|
| 117 |
+
it is possible to download both cased and uncased models from their S3 storage 🤗
|
delpher-corpus.urls
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
https://resolver.kb.nl/resolve?urn=DATA:kranten:kranten_pd_180x.zip
|
| 2 |
+
https://resolver.kb.nl/resolve?urn=DATA:kranten:kranten_pd_181x.zip
|
| 3 |
+
https://resolver.kb.nl/resolve?urn=DATA:kranten:kranten_pd_174x.zip
|
| 4 |
+
https://resolver.kb.nl/resolve?urn=DATA:kranten:kranten_pd_1875-6.zip
|
| 5 |
+
https://resolver.kb.nl/resolve?urn=DATA:kranten:kranten_pd_175x.zip
|
| 6 |
+
https://resolver.kb.nl/resolve?urn=DATA:kranten:kranten_pd_16xx.zip
|
| 7 |
+
https://resolver.kb.nl/resolve?urn=DATA:kranten:kranten_pd_170x.zip
|
| 8 |
+
https://resolver.kb.nl/resolve?urn=DATA:kranten:kranten_pd_1870-4.zip
|
| 9 |
+
https://resolver.kb.nl/resolve?urn=DATA:kranten:kranten_pd_183x.zip
|
| 10 |
+
https://resolver.kb.nl/resolve?urn=DATA:kranten:kranten_pd_173x.zip
|
| 11 |
+
https://resolver.kb.nl/resolve?urn=DATA:kranten:kranten_pd_172x.zip
|
| 12 |
+
https://resolver.kb.nl/resolve?urn=DATA:kranten:kranten_pd_1855-9.zip
|
| 13 |
+
https://resolver.kb.nl/resolve?urn=DATA:kranten:kranten_pd_184x.zip
|
| 14 |
+
https://resolver.kb.nl/resolve?urn=DATA:kranten:kranten_pd_176x.zip
|
| 15 |
+
https://resolver.kb.nl/resolve?urn=DATA:kranten:kranten_pd_1865-9.zip
|
| 16 |
+
https://resolver.kb.nl/resolve?urn=DATA:kranten:kranten_pd_1860-4.zip
|
| 17 |
+
https://resolver.kb.nl/resolve?urn=DATA:kranten:kranten_pd_182x.zip
|
| 18 |
+
https://resolver.kb.nl/resolve?urn=DATA:kranten:kranten_pd_1877-9.zip
|
| 19 |
+
https://resolver.kb.nl/resolve?urn=DATA:kranten:kranten_pd_177x.zip
|
| 20 |
+
https://resolver.kb.nl/resolve?urn=DATA:kranten:kranten_pd_1850-4.zip
|
| 21 |
+
https://resolver.kb.nl/resolve?urn=DATA:kranten:kranten_pd_178x.zip
|
| 22 |
+
https://resolver.kb.nl/resolve?urn=DATA:kranten:kranten_pd_171x.zip
|
| 23 |
+
https://resolver.kb.nl/resolve?urn=DATA:kranten:kranten_pd_179x.zip
|
figures/delpher_corpus_stats.png
ADDED

|
figures/training_loss.png
ADDED
|