

Commit
•
7eb703e
1
Parent(s):
b568ef2
Update README.md
Browse files
README.md
CHANGED
|
@@ -154,12 +154,15 @@ language:
|
|
| 154 |
|
| 155 |
[XEUS - A Cross-lingual Encoder for Universal Speech]()
|
| 156 |
|
| 157 |
-
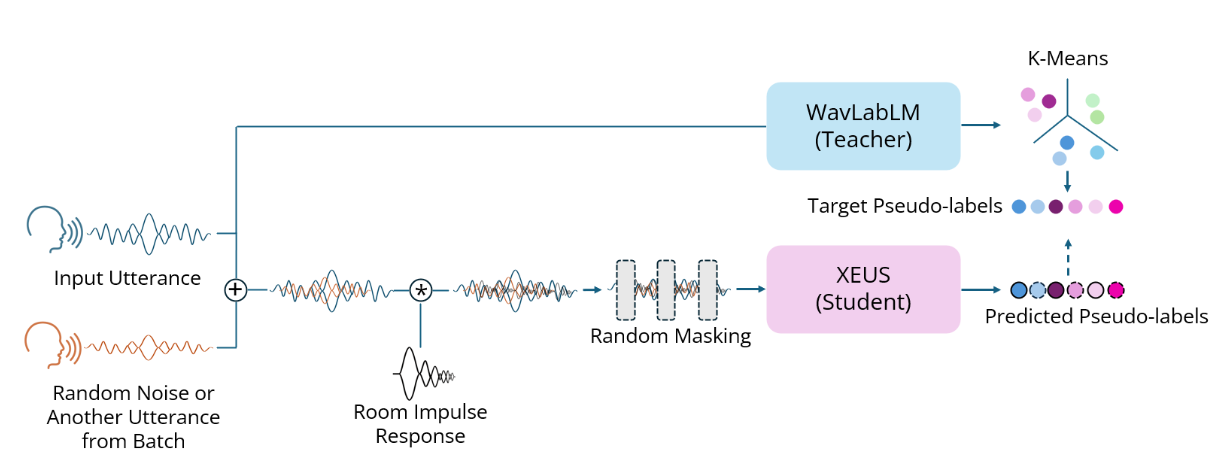
XEUS is a large-scale multilingual speech encoder by Carnegie Mellon University's [WAVLab]() that covers over **4000** languages. It is pre-trained on over 1 million hours of publicly available speech datasets. It can be requires fine-tuning to be used in downstream tasks such as Speech Recognition or Translation. XEUS uses the [E-Branchformer]() architecture and is trained using [HuBERT]()-style masked prediction of discrete speech tokens. During training, the input speech is also augmented with acoustic noise and reverberation, making XEUS more robust. The total model size is 577M parameters.
|
| 158 |
|
| 159 |
XEUS tops the [ML-SUPERB]() multilingual speech recognition leaderboard, outperforming [MMS](), [w2v-BERT 2.0](), and [XLS-R](). XEUS also sets a new state-of-the-art on 4 tasks in the monolingual [SUPERB]() benchmark.
|
| 160 |
|
| 161 |
More information about XEUS, including ***download links for our crawled 4000-language dataset***, can be found in the [project page]().
|
| 162 |
|
|
|
|
|
|
|
|
|
|
| 163 |
## Requirements
|
| 164 |
|
| 165 |
The code for XEUS is still in progress of being merged into the main ESPnet repo. It can instead be used from the following fork:
|
|
|
|
| 154 |
|
| 155 |
[XEUS - A Cross-lingual Encoder for Universal Speech]()
|
| 156 |
|
| 157 |
+
XEUS is a large-scale multilingual speech encoder by Carnegie Mellon University's [WAVLab]() that covers over **4000** languages. It is pre-trained on over 1 million hours of publicly available speech datasets. It can be requires fine-tuning to be used in downstream tasks such as Speech Recognition or Translation. XEUS uses the [E-Branchformer]() architecture and is trained using [HuBERT]()-style masked prediction of discrete speech tokens extracted from [WavLabLM](). During training, the input speech is also augmented with acoustic noise and reverberation, making XEUS more robust. The total model size is 577M parameters.
|
| 158 |
|
| 159 |
XEUS tops the [ML-SUPERB]() multilingual speech recognition leaderboard, outperforming [MMS](), [w2v-BERT 2.0](), and [XLS-R](). XEUS also sets a new state-of-the-art on 4 tasks in the monolingual [SUPERB]() benchmark.
|
| 160 |
|
| 161 |
More information about XEUS, including ***download links for our crawled 4000-language dataset***, can be found in the [project page]().
|
| 162 |
|
| 163 |
+
|
| 164 |
+
|
| 165 |
+
|
| 166 |
## Requirements
|
| 167 |
|
| 168 |
The code for XEUS is still in progress of being merged into the main ESPnet repo. It can instead be used from the following fork:
|