---
license: cc-by-nc-2.0
pipeline_tag: image-to-3d
library_name: transformers
datasets:
- argilla/FinePersonas-v0.1
language:
- am
metrics:
- accuracy
base_model:
- stepfun-ai/GOT-OCR2_0
new_version: meta-llama/Llama-3.2-11B-Vision-Instruct
tags:
- chemistry
---
# [ECCV 2024] VFusion3D: Learning Scalable 3D Generative Models from Video Diffusion Models
[Porject page](https://junlinhan.github.io/projects/vfusion3d.html), [Paper link](https://arxiv.org/abs/2403.12034)
VFusion3D is a large, feed-forward 3D generative model trained with a small amount of 3D data and a large volume of synthetic multi-view data. It is the first work exploring scalable 3D generative/reconstruction models as a step towards a 3D foundation.
[VFusion3D: Learning Scalable 3D Generative Models from Video Diffusion Models](https://junlinhan.github.io/projects/vfusion3d.html)
[Junlin Han](https://junlinhan.github.io/), [Filippos Kokkinos](https://www.fkokkinos.com/), [Philip Torr](https://www.robots.ox.ac.uk/~phst/)
GenAI, Meta and TVG, University of Oxford
European Conference on Computer Vision (ECCV), 2024
## News
- [08.08.2024] [HF Demo](https://huggingface.co/spaces/facebook/VFusion3D) is available, big thanks to [Jade Choghari](https://github.com/jadechoghari)'s help for making it possible.
- [25.07.2024] Release weights and inference code for VFusion3D.
## Quick Start
Getting started with VFusion3D is super easy! 🤗 Here’s how you can use the model with Hugging Face:
### Install Dependencies (Optional)
Depending on your needs, you may want to enable specific features like mesh generation or video rendering. We've got you covered with these additional packages:
```bash
!pip --quiet install imageio[ffmpeg] PyMCubes trimesh rembg[gpu,cli] kiui
```
### Load model directly
```python
import torch
from transformers import AutoModel, AutoProcessor
# load the model and processor
model = AutoModel.from_pretrained("jadechoghari/vfusion3d", trust_remote_code=True)
processor = AutoProcessor.from_pretrained("jadechoghari/vfusion3d")
# download and preprocess the image
import requests
from PIL import Image
from io import BytesIO
image_url = 'https://sm.ign.com/ign_nordic/cover/a/avatar-gen/avatar-generations_prsz.jpg'
response = requests.get(image_url)
image = Image.open(BytesIO(response.content))
# preprocess the image and get the source camera
image, source_camera = processor(image)
# generate planes (default output)
output_planes = model(image, source_camera)
print("Planes shape:", output_planes.shape)
# generate a 3D mesh
output_planes, mesh_path = model(image, source_camera, export_mesh=True)
print("Planes shape:", output_planes.shape)
print("Mesh saved at:", mesh_path)
# Generate a video
output_planes, video_path = model(image, source_camera, export_video=True)
print("Planes shape:", output_planes.shape)
print("Video saved at:", video_path)
```
- **Default (Planes):** By default, VFusion3D outputs planes—ideal for further 3D operations.
- **Export Mesh:** Want a 3D mesh? Just set `export_mesh=True`, and you'll get a `.obj` file ready to roll. You can also customize the mesh resolution by adjusting the `mesh_size` parameter.
- **Export Video:** Fancy a 3D video? Set `export_video=True`, and you'll receive a beautifully rendered video from multiple angles. You can tweak `render_size` and `fps` to get the video just right.
Check out our [demo app](https://huggingface.co/spaces/facebook/VFusion3D) to see VFusion3D in action! 🤗
## Results and Comparisons
### 3D Generation Results

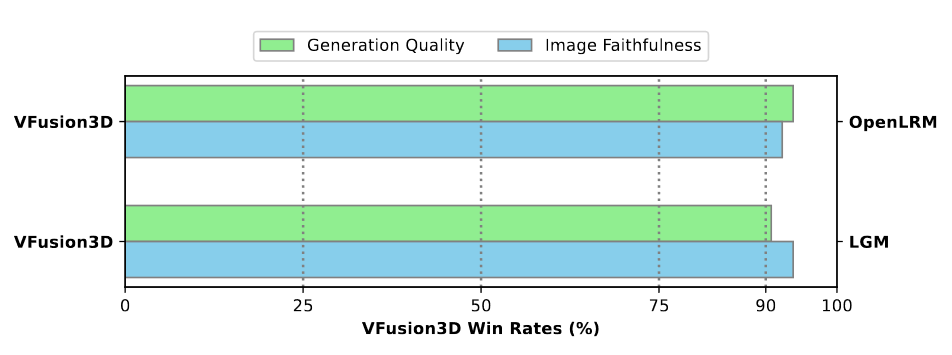
 ### User Study Results
### User Study Results
 ## Acknowledgement
- This inference code of VFusion3D heavily borrows from [OpenLRM](https://github.com/3DTopia/OpenLRM).
## Citation
If you find this work useful, please cite us:
```
@article{han2024vfusion3d,
title={VFusion3D: Learning Scalable 3D Generative Models from Video Diffusion Models},
author={Junlin Han and Filippos Kokkinos and Philip Torr},
journal={European Conference on Computer Vision (ECCV)},
year={2024}
}
```
## License
- The majority of VFusion3D is licensed under CC-BY-NC, however portions of the project are available under separate license terms: OpenLRM as a whole is licensed under the Apache License, Version 2.0, while certain components are covered by NVIDIA's proprietary license.
- The model weights of VFusion3D is also licensed under CC-BY-NC.
## Acknowledgement
- This inference code of VFusion3D heavily borrows from [OpenLRM](https://github.com/3DTopia/OpenLRM).
## Citation
If you find this work useful, please cite us:
```
@article{han2024vfusion3d,
title={VFusion3D: Learning Scalable 3D Generative Models from Video Diffusion Models},
author={Junlin Han and Filippos Kokkinos and Philip Torr},
journal={European Conference on Computer Vision (ECCV)},
year={2024}
}
```
## License
- The majority of VFusion3D is licensed under CC-BY-NC, however portions of the project are available under separate license terms: OpenLRM as a whole is licensed under the Apache License, Version 2.0, while certain components are covered by NVIDIA's proprietary license.
- The model weights of VFusion3D is also licensed under CC-BY-NC.