
Upload 12 files
Browse files- control_v11p_sd15_openpose/.gitattributes +34 -0
- control_v11p_sd15_openpose/README.md +163 -0
- control_v11p_sd15_openpose/config.json +42 -0
- control_v11p_sd15_openpose/control_net_open_pose.py +60 -0
- control_v11p_sd15_openpose/diffusion_pytorch_model.bin +3 -0
- control_v11p_sd15_openpose/diffusion_pytorch_model.fp16.bin +3 -0
- control_v11p_sd15_openpose/diffusion_pytorch_model.fp16.safetensors +3 -0
- control_v11p_sd15_openpose/diffusion_pytorch_model.safetensors +3 -0
- control_v11p_sd15_openpose/images/control.png +0 -0
- control_v11p_sd15_openpose/images/image_out.png +0 -0
- control_v11p_sd15_openpose/images/input.png +0 -0
- control_v11p_sd15_openpose/sd.png +0 -0
control_v11p_sd15_openpose/.gitattributes
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
control_v11p_sd15_openpose/README.md
ADDED
|
@@ -0,0 +1,163 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: openrail
|
| 3 |
+
base_model: runwayml/stable-diffusion-v1-5
|
| 4 |
+
tags:
|
| 5 |
+
- art
|
| 6 |
+
- controlnet
|
| 7 |
+
- stable-diffusion
|
| 8 |
+
- controlnet-v1-1
|
| 9 |
+
- image-to-image
|
| 10 |
+
duplicated_from: ControlNet-1-1-preview/control_v11p_sd15_openpose
|
| 11 |
+
---
|
| 12 |
+
|
| 13 |
+
# Controlnet - v1.1 - *openpose Version*
|
| 14 |
+
|
| 15 |
+
**Controlnet v1.1** is the successor model of [Controlnet v1.0](https://huggingface.co/lllyasviel/ControlNet)
|
| 16 |
+
and was released in [lllyasviel/ControlNet-v1-1](https://huggingface.co/lllyasviel/ControlNet-v1-1) by [Lvmin Zhang](https://huggingface.co/lllyasviel).
|
| 17 |
+
|
| 18 |
+
This checkpoint is a conversion of [the original checkpoint](https://huggingface.co/lllyasviel/ControlNet-v1-1/blob/main/control_v11p_sd15_openpose.pth) into `diffusers` format.
|
| 19 |
+
It can be used in combination with **Stable Diffusion**, such as [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5).
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
For more details, please also have a look at the [🧨 Diffusers docs](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/controlnet).
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
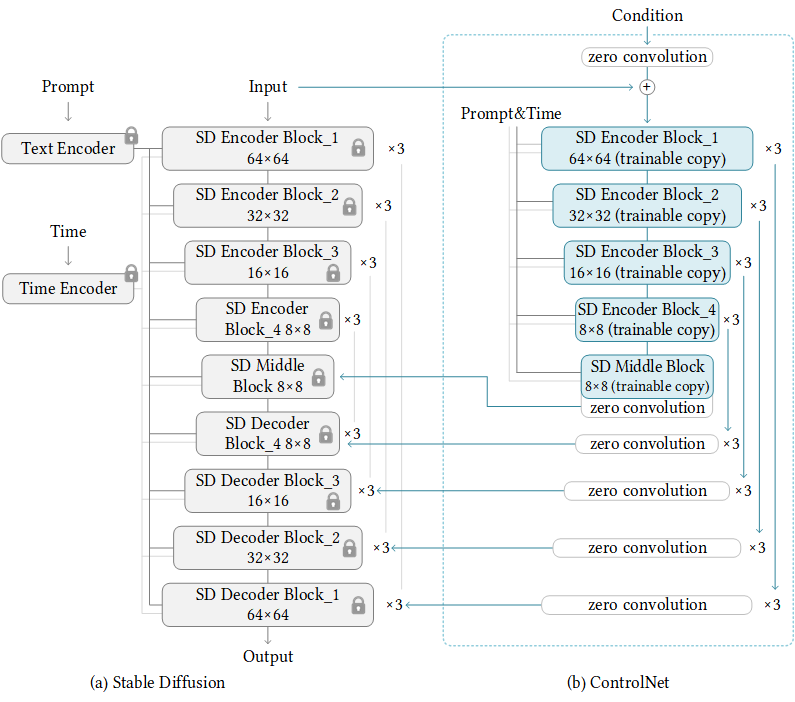
ControlNet is a neural network structure to control diffusion models by adding extra conditions.
|
| 26 |
+
|
| 27 |
+

|
| 28 |
+
|
| 29 |
+
This checkpoint corresponds to the ControlNet conditioned on **openpose images**.
|
| 30 |
+
|
| 31 |
+
## Model Details
|
| 32 |
+
- **Developed by:** Lvmin Zhang, Maneesh Agrawala
|
| 33 |
+
- **Model type:** Diffusion-based text-to-image generation model
|
| 34 |
+
- **Language(s):** English
|
| 35 |
+
- **License:** [The CreativeML OpenRAIL M license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) is an [Open RAIL M license](https://www.licenses.ai/blog/2022/8/18/naming-convention-of-responsible-ai-licenses), adapted from the work that [BigScience](https://bigscience.huggingface.co/) and [the RAIL Initiative](https://www.licenses.ai/) are jointly carrying in the area of responsible AI licensing. See also [the article about the BLOOM Open RAIL license](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) on which our license is based.
|
| 36 |
+
- **Resources for more information:** [GitHub Repository](https://github.com/lllyasviel/ControlNet), [Paper](https://arxiv.org/abs/2302.05543).
|
| 37 |
+
- **Cite as:**
|
| 38 |
+
|
| 39 |
+
@misc{zhang2023adding,
|
| 40 |
+
title={Adding Conditional Control to Text-to-Image Diffusion Models},
|
| 41 |
+
author={Lvmin Zhang and Maneesh Agrawala},
|
| 42 |
+
year={2023},
|
| 43 |
+
eprint={2302.05543},
|
| 44 |
+
archivePrefix={arXiv},
|
| 45 |
+
primaryClass={cs.CV}
|
| 46 |
+
}
|
| 47 |
+
|
| 48 |
+
## Introduction
|
| 49 |
+
|
| 50 |
+
Controlnet was proposed in [*Adding Conditional Control to Text-to-Image Diffusion Models*](https://arxiv.org/abs/2302.05543) by
|
| 51 |
+
Lvmin Zhang, Maneesh Agrawala.
|
| 52 |
+
|
| 53 |
+
The abstract reads as follows:
|
| 54 |
+
|
| 55 |
+
*We present a neural network structure, ControlNet, to control pretrained large diffusion models to support additional input conditions.
|
| 56 |
+
The ControlNet learns task-specific conditions in an end-to-end way, and the learning is robust even when the training dataset is small (< 50k).
|
| 57 |
+
Moreover, training a ControlNet is as fast as fine-tuning a diffusion model, and the model can be trained on a personal devices.
|
| 58 |
+
Alternatively, if powerful computation clusters are available, the model can scale to large amounts (millions to billions) of data.
|
| 59 |
+
We report that large diffusion models like Stable Diffusion can be augmented with ControlNets to enable conditional inputs like edge maps, segmentation maps, keypoints, etc.
|
| 60 |
+
This may enrich the methods to control large diffusion models and further facilitate related applications.*
|
| 61 |
+
|
| 62 |
+
## Example
|
| 63 |
+
|
| 64 |
+
It is recommended to use the checkpoint with [Stable Diffusion v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) as the checkpoint
|
| 65 |
+
has been trained on it.
|
| 66 |
+
Experimentally, the checkpoint can be used with other diffusion models such as dreamboothed stable diffusion.
|
| 67 |
+
|
| 68 |
+
**Note**: If you want to process an image to create the auxiliary conditioning, external dependencies are required as shown below:
|
| 69 |
+
|
| 70 |
+
1. Install https://github.com/patrickvonplaten/controlnet_aux
|
| 71 |
+
|
| 72 |
+
```sh
|
| 73 |
+
$ pip install controlnet_aux==0.3.0
|
| 74 |
+
```
|
| 75 |
+
|
| 76 |
+
2. Let's install `diffusers` and related packages:
|
| 77 |
+
|
| 78 |
+
```
|
| 79 |
+
$ pip install diffusers transformers accelerate
|
| 80 |
+
```
|
| 81 |
+
|
| 82 |
+
3. Run code:
|
| 83 |
+
|
| 84 |
+
```python
|
| 85 |
+
import torch
|
| 86 |
+
import os
|
| 87 |
+
from huggingface_hub import HfApi
|
| 88 |
+
from pathlib import Path
|
| 89 |
+
from diffusers.utils import load_image
|
| 90 |
+
from PIL import Image
|
| 91 |
+
import numpy as np
|
| 92 |
+
from controlnet_aux import OpenposeDetector
|
| 93 |
+
|
| 94 |
+
from diffusers import (
|
| 95 |
+
ControlNetModel,
|
| 96 |
+
StableDiffusionControlNetPipeline,
|
| 97 |
+
UniPCMultistepScheduler,
|
| 98 |
+
)
|
| 99 |
+
|
| 100 |
+
checkpoint = "lllyasviel/control_v11p_sd15_openpose"
|
| 101 |
+
|
| 102 |
+
image = load_image(
|
| 103 |
+
"https://huggingface.co/lllyasviel/control_v11p_sd15_openpose/resolve/main/images/input.png"
|
| 104 |
+
)
|
| 105 |
+
|
| 106 |
+
prompt = "chef in the kitchen"
|
| 107 |
+
|
| 108 |
+
processor = OpenposeDetector.from_pretrained('lllyasviel/ControlNet')
|
| 109 |
+
|
| 110 |
+
control_image = processor(image, hand_and_face=True)
|
| 111 |
+
control_image.save("./images/control.png")
|
| 112 |
+
|
| 113 |
+
controlnet = ControlNetModel.from_pretrained(checkpoint, torch_dtype=torch.float16)
|
| 114 |
+
pipe = StableDiffusionControlNetPipeline.from_pretrained(
|
| 115 |
+
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
|
| 116 |
+
)
|
| 117 |
+
|
| 118 |
+
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
|
| 119 |
+
pipe.enable_model_cpu_offload()
|
| 120 |
+
|
| 121 |
+
generator = torch.manual_seed(0)
|
| 122 |
+
image = pipe(prompt, num_inference_steps=30, generator=generator, image=control_image).images[0]
|
| 123 |
+
|
| 124 |
+
image.save('images/image_out.png')
|
| 125 |
+
|
| 126 |
+
```
|
| 127 |
+
|
| 128 |
+

|
| 129 |
+
|
| 130 |
+

|
| 131 |
+
|
| 132 |
+

|
| 133 |
+
|
| 134 |
+
## Other released checkpoints v1-1
|
| 135 |
+
|
| 136 |
+
The authors released 14 different checkpoints, each trained with [Stable Diffusion v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5)
|
| 137 |
+
on a different type of conditioning:
|
| 138 |
+
|
| 139 |
+
| Model Name | Control Image Overview| Control Image Example | Generated Image Example |
|
| 140 |
+
|---|---|---|---|
|
| 141 |
+
|[lllyasviel/control_v11p_sd15_canny](https://huggingface.co/lllyasviel/control_v11p_sd15_canny)<br/> *Trained with canny edge detection* | A monochrome image with white edges on a black background.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_canny/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_canny/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_canny/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_canny/resolve/main/images/image_out.png"/></a>|
|
| 142 |
+
|[lllyasviel/control_v11e_sd15_ip2p](https://huggingface.co/lllyasviel/control_v11e_sd15_ip2p)<br/> *Trained with pixel to pixel instruction* | No condition .|<a href="https://huggingface.co/lllyasviel/control_v11e_sd15_ip2p/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11e_sd15_ip2p/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11e_sd15_ip2p/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11e_sd15_ip2p/resolve/main/images/image_out.png"/></a>|
|
| 143 |
+
|[lllyasviel/control_v11p_sd15_inpaint](https://huggingface.co/lllyasviel/control_v11p_sd15_inpaint)<br/> Trained with image inpainting | No condition.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_inpaint/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_inpaint/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_inpaint/resolve/main/images/output.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_inpaint/resolve/main/images/output.png"/></a>|
|
| 144 |
+
|[lllyasviel/control_v11p_sd15_mlsd](https://huggingface.co/lllyasviel/control_v11p_sd15_mlsd)<br/> Trained with multi-level line segment detection | An image with annotated line segments.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_mlsd/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_mlsd/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_mlsd/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_mlsd/resolve/main/images/image_out.png"/></a>|
|
| 145 |
+
|[lllyasviel/control_v11f1p_sd15_depth](https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth)<br/> Trained with depth estimation | An image with depth information, usually represented as a grayscale image.|<a href="https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth/resolve/main/images/image_out.png"/></a>|
|
| 146 |
+
|[lllyasviel/control_v11p_sd15_normalbae](https://huggingface.co/lllyasviel/control_v11p_sd15_normalbae)<br/> Trained with surface normal estimation | An image with surface normal information, usually represented as a color-coded image.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_normalbae/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_normalbae/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_normalbae/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_normalbae/resolve/main/images/image_out.png"/></a>|
|
| 147 |
+
|[lllyasviel/control_v11p_sd15_seg](https://huggingface.co/lllyasviel/control_v11p_sd15_seg)<br/> Trained with image segmentation | An image with segmented regions, usually represented as a color-coded image.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_seg/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_seg/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_seg/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_seg/resolve/main/images/image_out.png"/></a>|
|
| 148 |
+
|[lllyasviel/control_v11p_sd15_lineart](https://huggingface.co/lllyasviel/control_v11p_sd15_lineart)<br/> Trained with line art generation | An image with line art, usually black lines on a white background.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_lineart/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_lineart/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_lineart/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_lineart/resolve/main/images/image_out.png"/></a>|
|
| 149 |
+
|[lllyasviel/control_v11p_sd15s2_lineart_anime](https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime)<br/> Trained with anime line art generation | An image with anime-style line art.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime/resolve/main/images/image_out.png"/></a>|
|
| 150 |
+
|[lllyasviel/control_v11p_sd15_openpose](https://huggingface.co/lllyasviel/control_v11p_sd15_openpose)<br/> Trained with human pose estimation | An image with human poses, usually represented as a set of keypoints or skeletons.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_openpose/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_openpose/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_openpose/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_openpose/resolve/main/images/image_out.png"/></a>|
|
| 151 |
+
|[lllyasviel/control_v11p_sd15_scribble](https://huggingface.co/lllyasviel/control_v11p_sd15_scribble)<br/> Trained with scribble-based image generation | An image with scribbles, usually random or user-drawn strokes.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_scribble/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_scribble/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_scribble/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_scribble/resolve/main/images/image_out.png"/></a>|
|
| 152 |
+
|[lllyasviel/control_v11p_sd15_softedge](https://huggingface.co/lllyasviel/control_v11p_sd15_softedge)<br/> Trained with soft edge image generation | An image with soft edges, usually to create a more painterly or artistic effect.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_softedge/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_softedge/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_softedge/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_softedge/resolve/main/images/image_out.png"/></a>|
|
| 153 |
+
|[lllyasviel/control_v11e_sd15_shuffle](https://huggingface.co/lllyasviel/control_v11e_sd15_shuffle)<br/> Trained with image shuffling | An image with shuffled patches or regions.|<a href="https://huggingface.co/lllyasviel/control_v11e_sd15_shuffle/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11e_sd15_shuffle/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11e_sd15_shuffle/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11e_sd15_shuffle/resolve/main/images/image_out.png"/></a>|
|
| 154 |
+
|
| 155 |
+
## Improvements in Openpose 1.1:
|
| 156 |
+
|
| 157 |
+
- The improvement of this model is mainly based on our improved implementation of OpenPose. We carefully reviewed the difference between the pytorch OpenPose and CMU's c++ openpose. Now the processor should be more accurate, especially for hands. The improvement of processor leads to the improvement of Openpose 1.1.
|
| 158 |
+
- More inputs are supported (hand and face).
|
| 159 |
+
- The training dataset of previous cnet 1.0 has several problems including (1) a small group of greyscale human images are duplicated thousands of times (!!), causing the previous model somewhat likely to generate grayscale human images; (2) some images has low quality, very blurry, or significant JPEG artifacts; (3) a small group of images has wrong paired prompts caused by a mistake in our data processing scripts. The new model fixed all problems of the training dataset and should be more reasonable in many cases.
|
| 160 |
+
|
| 161 |
+
## More information
|
| 162 |
+
|
| 163 |
+
For more information, please also have a look at the [Diffusers ControlNet Blog Post](https://huggingface.co/blog/controlnet) and have a look at the [official docs](https://github.com/lllyasviel/ControlNet-v1-1-nightly).
|
control_v11p_sd15_openpose/config.json
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "ControlNetModel",
|
| 3 |
+
"_diffusers_version": "0.16.0.dev0",
|
| 4 |
+
"_name_or_path": "/home/patrick/controlnet_v1_1/control_v11p_sd15_openpose",
|
| 5 |
+
"act_fn": "silu",
|
| 6 |
+
"attention_head_dim": 8,
|
| 7 |
+
"block_out_channels": [
|
| 8 |
+
320,
|
| 9 |
+
640,
|
| 10 |
+
1280,
|
| 11 |
+
1280
|
| 12 |
+
],
|
| 13 |
+
"class_embed_type": null,
|
| 14 |
+
"conditioning_embedding_out_channels": [
|
| 15 |
+
16,
|
| 16 |
+
32,
|
| 17 |
+
96,
|
| 18 |
+
256
|
| 19 |
+
],
|
| 20 |
+
"controlnet_conditioning_channel_order": "rgb",
|
| 21 |
+
"cross_attention_dim": 768,
|
| 22 |
+
"down_block_types": [
|
| 23 |
+
"CrossAttnDownBlock2D",
|
| 24 |
+
"CrossAttnDownBlock2D",
|
| 25 |
+
"CrossAttnDownBlock2D",
|
| 26 |
+
"DownBlock2D"
|
| 27 |
+
],
|
| 28 |
+
"downsample_padding": 1,
|
| 29 |
+
"flip_sin_to_cos": true,
|
| 30 |
+
"freq_shift": 0,
|
| 31 |
+
"in_channels": 4,
|
| 32 |
+
"layers_per_block": 2,
|
| 33 |
+
"mid_block_scale_factor": 1,
|
| 34 |
+
"norm_eps": 1e-05,
|
| 35 |
+
"norm_num_groups": 32,
|
| 36 |
+
"num_class_embeds": null,
|
| 37 |
+
"only_cross_attention": false,
|
| 38 |
+
"projection_class_embeddings_input_dim": null,
|
| 39 |
+
"resnet_time_scale_shift": "default",
|
| 40 |
+
"upcast_attention": false,
|
| 41 |
+
"use_linear_projection": false
|
| 42 |
+
}
|
control_v11p_sd15_openpose/control_net_open_pose.py
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
import torch
|
| 3 |
+
import os
|
| 4 |
+
from huggingface_hub import HfApi
|
| 5 |
+
from pathlib import Path
|
| 6 |
+
from diffusers.utils import load_image
|
| 7 |
+
from controlnet_aux import OpenposeDetector
|
| 8 |
+
|
| 9 |
+
from diffusers import (
|
| 10 |
+
ControlNetModel,
|
| 11 |
+
StableDiffusionControlNetPipeline,
|
| 12 |
+
UniPCMultistepScheduler,
|
| 13 |
+
)
|
| 14 |
+
import sys
|
| 15 |
+
|
| 16 |
+
checkpoint = sys.argv[1]
|
| 17 |
+
|
| 18 |
+
<<<<<<< HEAD
|
| 19 |
+
image = load_image("https://github.com/lllyasviel/ControlNet-v1-1-nightly/raw/main/test_imgs/demo.jpg").resize((512, 512))
|
| 20 |
+
prompt = "The pope with sunglasses rapping with a mic"
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
openpose = OpenposeDetector.from_pretrained('lllyasviel/ControlNet')
|
| 24 |
+
image = openpose(image, hand_and_face=True)
|
| 25 |
+
=======
|
| 26 |
+
image = load_image("https://huggingface.co/lllyasviel/sd-controlnet-openpose/resolve/main/images/pose.png")
|
| 27 |
+
prompt = "chef in the kitchen"
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
openpose = OpenposeDetector.from_pretrained('lllyasviel/ControlNet')
|
| 31 |
+
image = openpose(image)
|
| 32 |
+
>>>>>>> 6e2c3bc1a649ac194d79bb2f4ee11900d7f0e8f6
|
| 33 |
+
|
| 34 |
+
controlnet = ControlNetModel.from_pretrained(checkpoint, torch_dtype=torch.float16)
|
| 35 |
+
pipe = StableDiffusionControlNetPipeline.from_pretrained(
|
| 36 |
+
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
|
| 37 |
+
)
|
| 38 |
+
|
| 39 |
+
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
|
| 40 |
+
pipe.enable_model_cpu_offload()
|
| 41 |
+
|
| 42 |
+
generator = torch.manual_seed(33)
|
| 43 |
+
<<<<<<< HEAD
|
| 44 |
+
out_image = pipe(prompt, num_inference_steps=35, generator=generator, image=image).images[0]
|
| 45 |
+
=======
|
| 46 |
+
out_image = pipe(prompt, num_inference_steps=20, generator=generator, image=image).images[0]
|
| 47 |
+
>>>>>>> 6e2c3bc1a649ac194d79bb2f4ee11900d7f0e8f6
|
| 48 |
+
|
| 49 |
+
path = os.path.join(Path.home(), "images", "aa.png")
|
| 50 |
+
out_image.save(path)
|
| 51 |
+
|
| 52 |
+
api = HfApi()
|
| 53 |
+
|
| 54 |
+
api.upload_file(
|
| 55 |
+
path_or_fileobj=path,
|
| 56 |
+
path_in_repo=path.split("/")[-1],
|
| 57 |
+
repo_id="patrickvonplaten/images",
|
| 58 |
+
repo_type="dataset",
|
| 59 |
+
)
|
| 60 |
+
print("https://huggingface.co/datasets/patrickvonplaten/images/blob/main/aa.png")
|
control_v11p_sd15_openpose/diffusion_pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:40c80b93aea10c31de2d282adbe8bbb945611a037ca36e0cd55d3ee7d59fedce
|
| 3 |
+
size 1445254969
|
control_v11p_sd15_openpose/diffusion_pytorch_model.fp16.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:65c13c04dc49231f7044373e3f0dbd2f44b01a445c8577ea919cd5ff5fac29a6
|
| 3 |
+
size 722698343
|
control_v11p_sd15_openpose/diffusion_pytorch_model.fp16.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b25b1125e870275550b2a7de289056cb3c236c01c293bd5ba883657b1c006e3e
|
| 3 |
+
size 722598642
|
control_v11p_sd15_openpose/diffusion_pytorch_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:46b10abb28f3750aba7eea208e188539f7945d9256de9a248cbb9902f2276988
|
| 3 |
+
size 1445157124
|
control_v11p_sd15_openpose/images/control.png
ADDED

|
control_v11p_sd15_openpose/images/image_out.png
ADDED

|
control_v11p_sd15_openpose/images/input.png
ADDED

|
control_v11p_sd15_openpose/sd.png
ADDED
|