
File size: 3,148 Bytes
9f753c3 6ff7048 d1db7ee 804e0da 6ff7048 804e0da 862c29a 6ab2220 804e0da 7837896 6ff7048 9f753c3 804e0da 8fc48b0 804e0da 0ed2393 14c70c6 cc353f5 804e0da 8fc48b0 804e0da 8fc48b0 804e0da cc353f5 804e0da a4ecfba 804e0da 2b265d1 804e0da 2f1c947 8fc48b0 2f1c947 804e0da 6ab2220 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 |
---
language:
- en
license: cc-by-nc-4.0
datasets:
- facebook/asset
- wi_locness
- GEM/wiki_auto_asset_turk
- discofuse
- zaemyung/IteraTeR_plus
- jfleg
- grammarly/coedit
metrics:
- sari
- bleu
- accuracy
widget:
- text: 'Fix the grammar: When I grow up, I start to understand what he said is quite
right.'
example_title: Fluency
- text: 'Make this text coherent: Their flight is weak. They run quickly through the
tree canopy.'
example_title: Coherence
- text: 'Rewrite to make this easier to understand: A storm surge is what forecasters
consider a hurricane''s most treacherous aspect.'
example_title: Simplification
- text: 'Paraphrase this: Do you know where I was born?'
example_title: Paraphrase
- text: 'Write this more formally: omg i love that song im listening to it right now'
example_title: Formalize
- text: 'Write in a more neutral way: The authors'' exposé on nutrition studies.'
example_title: Neutralize
---
# Model Card for CoEdIT-Large
This model was obtained by fine-tuning the corresponding `google/flan-t5-large` model on the CoEdIT dataset. Details of the dataset can be found in our paper and repository.
**Paper:** CoEdIT: Text Editing by Task-Specific Instruction Tuning
**Authors:** Vipul Raheja, Dhruv Kumar, Ryan Koo, Dongyeop Kang
## Model Details
### Model Description
- **Language(s) (NLP)**: English
- **Finetuned from model:** google/flan-t5-large
### Model Sources
- **Repository:** https://github.com/vipulraheja/coedit
- **Paper:** https://arxiv.org/abs/2305.09857
## How to use
We make available the models presented in our paper.
<table>
<tr>
<th>Model</th>
<th>Number of parameters</th>
</tr>
<tr>
<td>CoEdIT-large</td>
<td>770M</td>
</tr>
<tr>
<td>CoEdIT-xl</td>
<td>3B</td>
</tr>
<tr>
<td>CoEdIT-xxl</td>
<td>11B</td>
</tr>
</table>
## Uses
## Text Revision Task
Given an edit instruction and an original text, our model can generate the edited version of the text.<br>
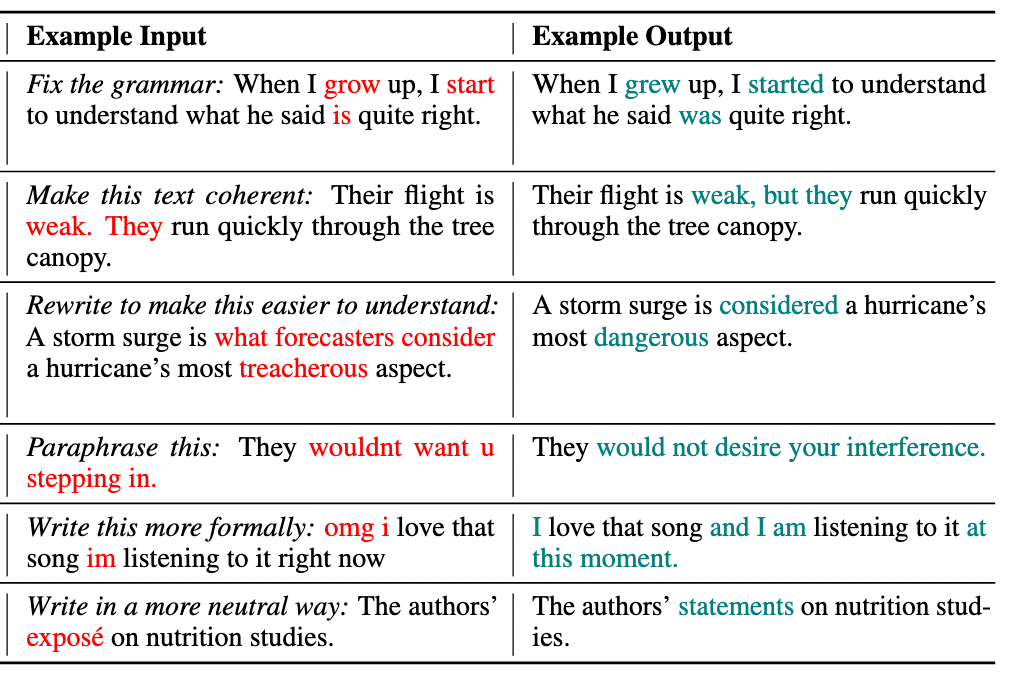
## Usage
```python
from transformers import AutoTokenizer, T5ForConditionalGeneration
tokenizer = AutoTokenizer.from_pretrained("grammarly/coedit-large")
model = T5ForConditionalGeneration.from_pretrained("grammarly/coedit-large")
input_text = 'Fix grammatical errors in this sentence: When I grow up, I start to understand what he said is quite right.'
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids, max_length=256)
edited_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
```
#### Software
https://github.com/vipulraheja/coedit
## Citation
**BibTeX:**
```
@article{raheja2023coedit,
title={CoEdIT: Text Editing by Task-Specific Instruction Tuning},
author={Vipul Raheja and Dhruv Kumar and Ryan Koo and Dongyeop Kang},
year={2023},
eprint={2305.09857},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
**APA:**
Raheja, V., Kumar, D., Koo, R., & Kang, D. (2023). CoEdIT: Text Editing by Task-Specific Instruction Tuning. ArXiv. /abs/2305.09857 |