---
license: openrail++
language:
- en
tags:
- text-to-code
- multilingual-code-generation
---

# CodeUp: A Multilingual Code Generation Llama-X Model with Parameter-Efficient Instruction-Tuning
[](https://github.com/juyongjiang/CodeUp/blob/master/LICENSE)
[](https://github.com/juyongjiang/CodeUp/blob/master/data/DATA_LICENSE)
[](https://www.python.org/downloads/release/python-390/)
[](https://github.com/psf/black)
## Table of Contents
- [Overview](#overview)
- [Dataset Preparation](#dataset-preparation)
- [Prompt Template](#prompt-template)
- [Fine-tuning](#fine-tuning)
- [Evaluation](#evaluation)
- [Citation](#citation)
- [Star History](#star-history)
## Overview
In recent years, large language models (LLMs) have demonstrated exceptional capabilities across a wide range of applications, largely due to their remarkable emergent abilities. To better align these models with human preferences, techniques such as instruction-tuning and reinforcement learning from human feedback (RLHF) have been developed for chat-based LLMs, including models like ChatGPT and GPT-4. However, except for Codex, these general-purpose LLMs primarily focus on general domains and are not specifically optimized for coding tasks. Codex, while a viable option, is a closed-source model developed by OpenAI. This underscores the need for developing open-source, instruction-following LLMs tailored to the code domain.
The development of such models, however, faces significant challenges due to the extensive number of parameters (≥ 7 billion) and the vast datasets required for training. These factors demand substantial computational resources, which can hinder training and inference on consumer hardware.
To address these challenges, our project leverages the latest powerful foundation model, `Llama` with version `X`, termed `Llama-X`, to construct high-quality instruction-following datasets for code generation tasks. We propose the development of an instruction-following multilingual code generation model based on Llama-X.
To ensure that our approach is feasible within an academic budget and can be executed on consumer hardware, such as a single RTX 3090, we are inspired by Alpaca-LoRA to integrate advanced parameter-efficient fine-tuning (PEFT) methods like `LoRA` for the code domain.
These methods facilitate the efficient adaptation of pre-trained language models (PLMs, also known as foundation models) to various downstream applications without the need to fine-tune the entire model's parameters.
The overall training pipeline for CodeUp is outlined as follows.
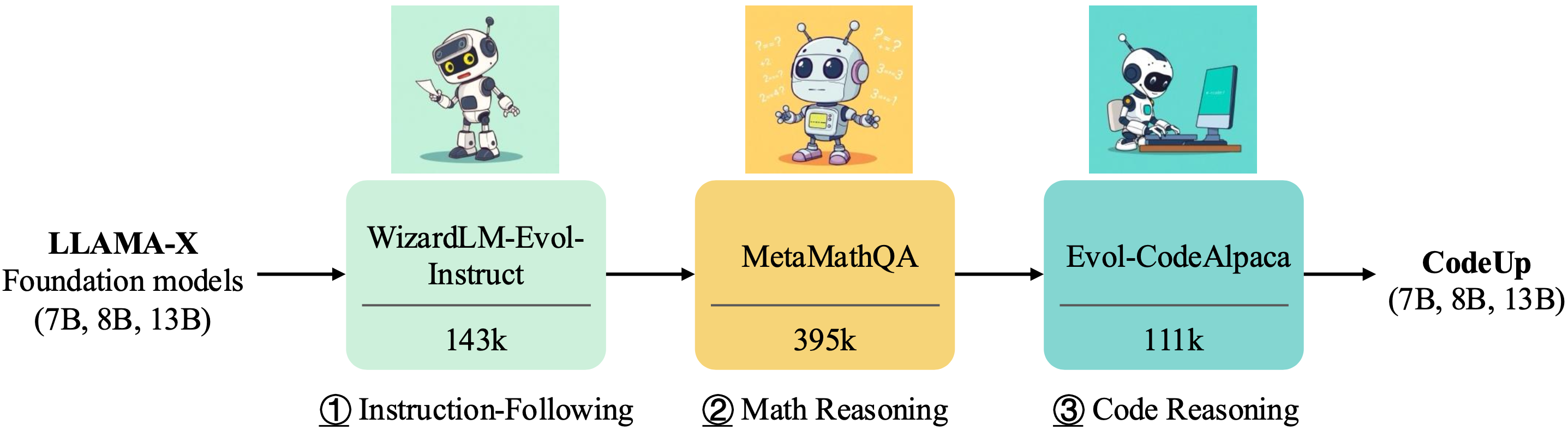
## Dataset Preparation
We employ three distinct datasets to specialize the Llama-X foundataion models for code generation:
* **[WizardLMTeam/WizardLM_evol_instruct_V2_196k](https://huggingface.co/datasets/WizardLMTeam/WizardLM_evol_instruct_V2_196k)**: This dataset comprises 143k rows of evolved data from Alpaca and ShareGPT. Due to licensing requirements, you must merge the original ShareGPT data with this dataset to obtain the complete version, which will contain approximately 196k rows.
* **[meta-math/MetaMathQA](https://huggingface.co/datasets/meta-math/MetaMathQA)**: The MetaMathQA dataset is augmented using the training sets from GSM8K and MATH, ensuring that no data from the testing sets is included.
* **[theblackcat102/evol-codealpaca-v1](https://huggingface.co/datasets/theblackcat102/evol-codealpaca-v1)**: This dataset is developed using a methodology similar to WizardCoder, with the distinction that it is open-source. It leverages the gpt-4-0314 and gpt-4-0613 models for generating and answering responses, with the majority of the generation process being handled by gpt-4-0314.
## Prompt Template
In line with previous research, we use the prompt template found in `templates/alpaca.json` for instruction-tuning the model for code generation. However, during inference, such as in the web demo, we utilize the user's instruction with an empty input field.
```
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:
```
## Fine-tuning
> [!IMPORTANT]
> We use the awesome LLaMA-Factory framework to fine-tune the Llama-X model. Installation LLaMA-Factory is mandatory. For more details, please check https://github.com/hiyouga/LLaMA-Factory.
> Eight NVIDIA A100 80G GPU will be used for fine-tuning. The adapters and merged models will be saved in `saves` and `models` folders.
```bash
# install llama-factory
conda create -n llamafactory python=3.11
conda activate llamafactory
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
```
Then, run the following commands:
```bash
# 1. instruction-following
llamafactory-cli train codeup/llama3_lora_sft_instruct.yaml
llamafactory-cli export codeup/llama3_lora_sft_merge_instruct.yaml
# 2. math reasoning
llamafactory-cli train codeup/llama3_lora_sft_math.yaml
llamafactory-cli export codeup/llama3_lora_sft_merge_math.yaml
# 3. code reasoning
llamafactory-cli train codeup/llama3_lora_sft_code.yaml
llamafactory-cli export codeup/llama3_lora_sft_merge_code.yaml
```
or
```bash
bash run_train_codeup.sh 2>&1 | tee train_codeup.log
```
The training and evaluation loss of CodeUp at each stage is shown below.
| ① sft-instruct | ② sft-math | ③ sft-code |
| -- | -- | -- |
| 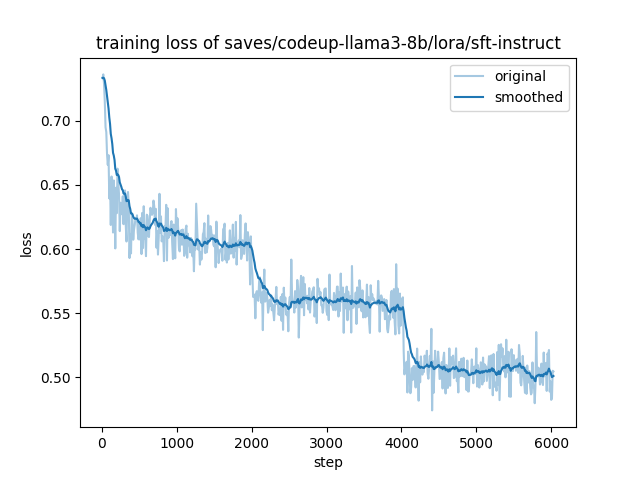 |
| 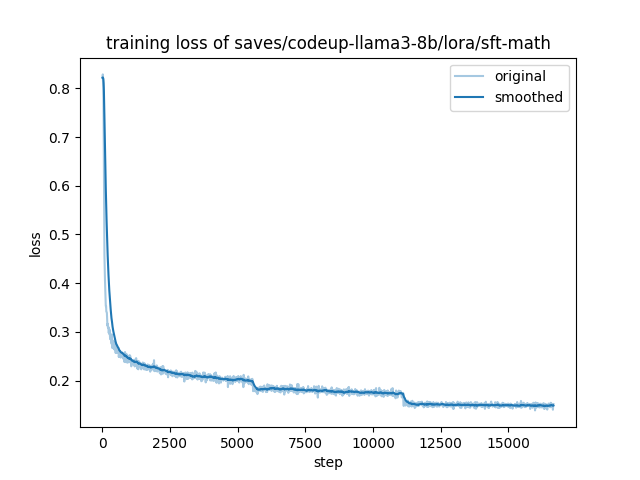 |
| 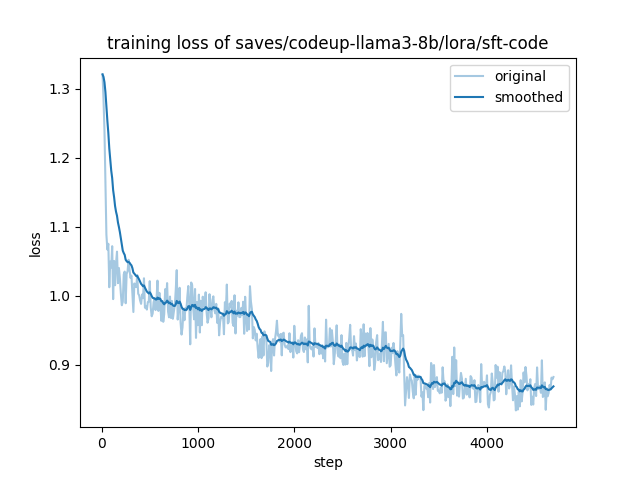 |
|
|
| 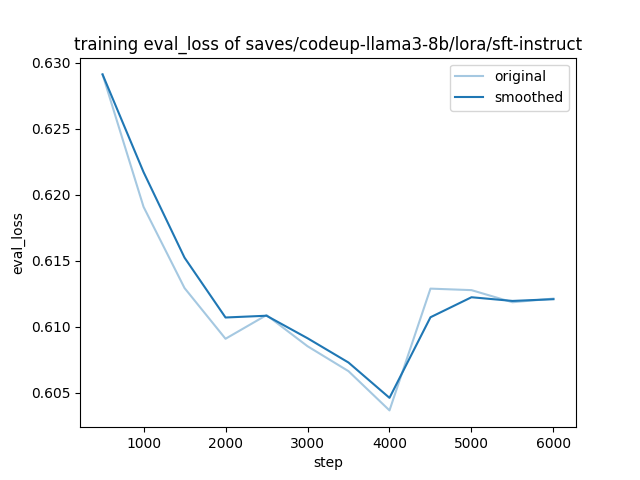 |
| 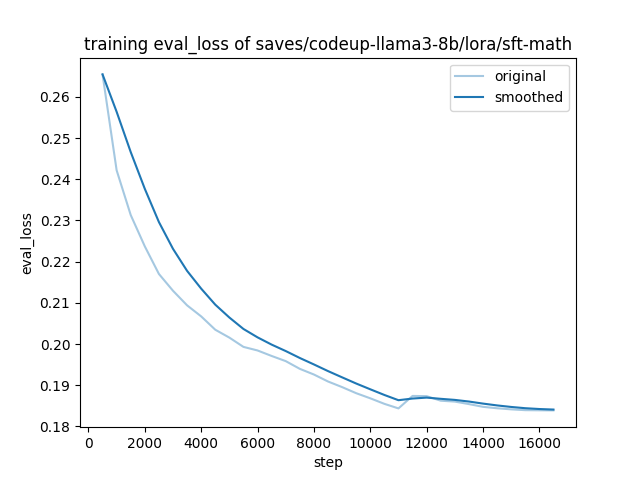 |
| 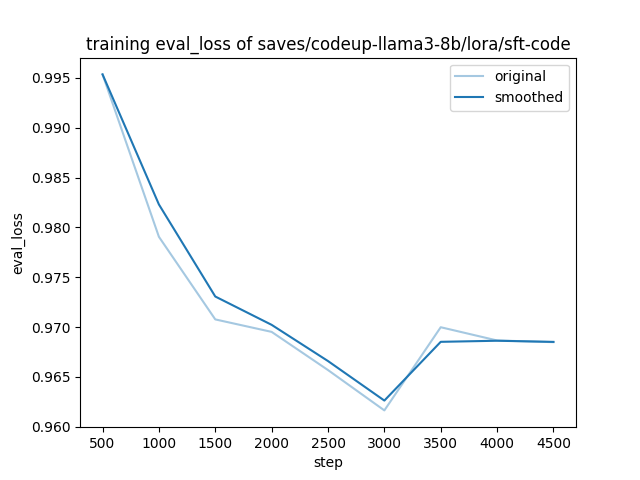 |
## Evaluation
> [!IMPORTANT]
> We use the evaluation script from the SelfCodeAlign repository to fine-tune the Llama-X model. For more details, please check https://github.com/bigcode-project/selfcodealign.
> One NVIDIA A100 80G GPU will be used for evaluation.
```bash
conda create -n selfcodealign python=3.10.0
conda activate selfcodealgin
git clone git@github.com:bigcode-project/selfcodealign.git
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -e .
# Failed to initialize NumPy: _ARRAY_API not found and BERTModel weight initialization issue
pip install --force-reinstall -v "numpy==1.25.2" -i https://pypi.tuna.tsinghua.edu.cn/simple
# fast_tokenizer = TokenizerFast.from_file(fast_tokenizer_file) Exception: data did not match any variant of untagged enum ModelWrapper at line 1251003 column
pip install --upgrade "transformers>=4.45" -i https://pypi.tuna.tsinghua.edu.cn/simple
```
Then, run the following commands:
```bash
bash run_eval_codeup.sh
```
The batch inference using [vLLM](https://docs.vllm.ai/en/latest/) can significantly speed up the evaluation. The greedy decoding strategy will be adopted and can be completed within 20 seconds.
The Pass@1 (%) of the CodeUp versus Meta-LLaMA-3-8B base model on the HumanEval and EvalPlus benchmarks using greedy decoding is reported in Table below.
| Model | Instruction Data | HumanEval | HumanEval+ | MBPP | MBPP+ |
| --- | --- | --- | --- | --- | --- |
| LLaMA3 8B | - | 0.262 | 0.232 | 0.003 | 0.003 |
| CodeUp | ③ Code | 0.384 | 0.360 | 0.356 | 0.263 |
| | ③ Code + ① Instruct | 0.445 | 0.378 | 0.383 | 0.291 |
| | ③ Code + ② Math | 0.317 | 0.293 | 0.371 | 0.281 |
| | ③ Code + ② Math + ① Instruct | **0.482** | **0.402** | **0.414** | **0.306** |
Here are the insights we have observed:
* **(③ Code + ① Instruct) > (③ Code) Enhancing Code Generation through Instruction Training**: Training the base model with both text-based instructions and code data (③ Code + ① Instruct) yields better results than using code data alone (③ Code). This approach ensures the model comprehends instructions effectively before learning to generate code.
* **(③ Code + ② Math) < (③ Code) Impact of Math Reasoning on Code Generation**: Integrating math reasoning data with code data (③ Code + ② Math) is less effective than using only code data (③ Code). The disparity in data distribution between mathematical reasoning and code reasoning complicates the model's ability to translate mathematical logic into coding structures.
* **(③ Code + ② Math + ① Instruct) > (③ Code + ① Instruct) Leveraging Instruction and Math for Enhanced Coding**: When a model already excels in following instructions, combining math reasoning, code, and instruction data (③ Code + ② Math + ① Instruct) surpasses the results obtained by using only instruction and code data (③ Code + ① Instruct). The model efficiently acquires useful mathematical logic, which enhances its coding capabilities.
## Citation
> [!IMPORTANT]
>
> If you use the data or code in this repo, please consider citing the following paper:
```BibTex
@misc{codeup,
author = {Juyong Jiang and Sunghun Kim},
title = {CodeUp: A Multilingual Code Generation Llama-X Model with Parameter-Efficient Instruction-Tuning},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/juyongjiang/CodeUp}},
}
@article{jiang2024survey,
title={A Survey on Large Language Models for Code Generation},
author={Jiang, Juyong and Wang, Fan and Shen, Jiasi and Kim, Sungju and Kim, Sunghun},
journal={arXiv preprint arXiv:2406.00515},
year={2024}
}
```
## Star History
[](https://star-history.com/#juyongjiang/CodeUp&Date)
|
## Evaluation
> [!IMPORTANT]
> We use the evaluation script from the SelfCodeAlign repository to fine-tune the Llama-X model. For more details, please check https://github.com/bigcode-project/selfcodealign.
> One NVIDIA A100 80G GPU will be used for evaluation.
```bash
conda create -n selfcodealign python=3.10.0
conda activate selfcodealgin
git clone git@github.com:bigcode-project/selfcodealign.git
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -e .
# Failed to initialize NumPy: _ARRAY_API not found and BERTModel weight initialization issue
pip install --force-reinstall -v "numpy==1.25.2" -i https://pypi.tuna.tsinghua.edu.cn/simple
# fast_tokenizer = TokenizerFast.from_file(fast_tokenizer_file) Exception: data did not match any variant of untagged enum ModelWrapper at line 1251003 column
pip install --upgrade "transformers>=4.45" -i https://pypi.tuna.tsinghua.edu.cn/simple
```
Then, run the following commands:
```bash
bash run_eval_codeup.sh
```
The batch inference using [vLLM](https://docs.vllm.ai/en/latest/) can significantly speed up the evaluation. The greedy decoding strategy will be adopted and can be completed within 20 seconds.
The Pass@1 (%) of the CodeUp versus Meta-LLaMA-3-8B base model on the HumanEval and EvalPlus benchmarks using greedy decoding is reported in Table below.
| Model | Instruction Data | HumanEval | HumanEval+ | MBPP | MBPP+ |
| --- | --- | --- | --- | --- | --- |
| LLaMA3 8B | - | 0.262 | 0.232 | 0.003 | 0.003 |
| CodeUp | ③ Code | 0.384 | 0.360 | 0.356 | 0.263 |
| | ③ Code + ① Instruct | 0.445 | 0.378 | 0.383 | 0.291 |
| | ③ Code + ② Math | 0.317 | 0.293 | 0.371 | 0.281 |
| | ③ Code + ② Math + ① Instruct | **0.482** | **0.402** | **0.414** | **0.306** |
Here are the insights we have observed:
* **(③ Code + ① Instruct) > (③ Code) Enhancing Code Generation through Instruction Training**: Training the base model with both text-based instructions and code data (③ Code + ① Instruct) yields better results than using code data alone (③ Code). This approach ensures the model comprehends instructions effectively before learning to generate code.
* **(③ Code + ② Math) < (③ Code) Impact of Math Reasoning on Code Generation**: Integrating math reasoning data with code data (③ Code + ② Math) is less effective than using only code data (③ Code). The disparity in data distribution between mathematical reasoning and code reasoning complicates the model's ability to translate mathematical logic into coding structures.
* **(③ Code + ② Math + ① Instruct) > (③ Code + ① Instruct) Leveraging Instruction and Math for Enhanced Coding**: When a model already excels in following instructions, combining math reasoning, code, and instruction data (③ Code + ② Math + ① Instruct) surpasses the results obtained by using only instruction and code data (③ Code + ① Instruct). The model efficiently acquires useful mathematical logic, which enhances its coding capabilities.
## Citation
> [!IMPORTANT]
>
> If you use the data or code in this repo, please consider citing the following paper:
```BibTex
@misc{codeup,
author = {Juyong Jiang and Sunghun Kim},
title = {CodeUp: A Multilingual Code Generation Llama-X Model with Parameter-Efficient Instruction-Tuning},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/juyongjiang/CodeUp}},
}
@article{jiang2024survey,
title={A Survey on Large Language Models for Code Generation},
author={Jiang, Juyong and Wang, Fan and Shen, Jiasi and Kim, Sungju and Kim, Sunghun},
journal={arXiv preprint arXiv:2406.00515},
year={2024}
}
```
## Star History
[](https://star-history.com/#juyongjiang/CodeUp&Date)